Instrumental convergence: scale and physical interactions
post by Edouard Harris, simonsdsuo (disiok) · 2022-10-14T15:50:29.074Z · LW · GW · 0 commentsThis is a link post for https://www.gladstone.ai/instrumental-convergence-3
Contents
Summary of this post
1. Introduction
2. Multi-agent POWER: recap
3. Results on the maze gridworld
3.1 Short-sighted agents
3.1.1 Agent H instrumentally favors fewer local options for Agent A
3.1.2 Agent A instrumentally favors more local options for itself
3.1.3 Agent H and Agent A are instrumentally misaligned by default
3.2 Physically interacting agents
3.2.1 Short-sighted agents prefer to avoid adjacent positions
3.2.2 The no-overlap rule reduces misalignment between short-sighted agents
3.3 Far-sighted agents
3.3.1 Agent H and Agent A are instrumentally misaligned by default
3.3.2 The no-overlap rule increases misalignment between far-sighted agents
4. Discussion
5. Conclusion
5.1 Limitations
5.2 Suggestions for future work
None
No comments
Summary of this post
This is the third post in a three-part sequence [? · GW] on instrumental convergence in multi-agent RL. Read Part 1 [AF · GW] and Part 2 [AF · GW].
In this post, we’ll:
- Investigate instrumental convergence on a multi-agent gridworld with a complicated topology.
- Show that when we add a simple physical interaction between our agents — in which we forbid them from overlapping on the gridworld — we induce stronger instrumental alignment between short-sighted agents, and stronger instrumental misalignment between far-sighted agents.
We’ll soon be open-sourcing the codebase we used to do these experiments. If you’d like to be notified when it’s released, email Edouard at edouard@gladstone.ai or DM me on Twitter at @harris_edouard.
Thanks to Alex Turner [AF · GW] and Vladimir Mikulik [AF · GW] for pointers and advice, and for reviewing drafts of this sequence. Thanks to Simon Suo [AF · GW] for his invaluable suggestions, advice, and support with the codebase, concepts, and manuscript. And thanks to David Xu [AF · GW], whose comment [AF(p) · GW(p)] inspired this work.
Work was done while at Gladstone AI, which Edouard [AF · GW] is a co-founder of.
🎧 This research has been featured on an episode of the Towards Data Science podcast. Listen to the episode here.
1. Introduction
In Part 1 [AF · GW] of this sequence, we saw how an agent with a long planning horizon tends to perceive instrumental value as being more concentrated than an agent with a shorter planning horizon. And in Part 2 [AF · GW], we introduced a multi-agent setting with two agents — Agent H (standing for a human) and Agent A (standing for a powerful AI) — which we used to motivate a definition [AF · GW] of multi-agent instrumental value, or POWER. We looked at how this definition behaved on a simple 3x3 gridworld, and found that when our agents had independent terminal goals,[1] their instrumental values ended up misaligned by default.
In this post, we’ll combine these two ideas and scale up our multi-agent experiments to a bigger and more complicated gridworld. Throughout this post, we’ll focus exclusively on the regime in which our agents have independent terminal goals. We'll see whether we can reproduce instrumental misalignment-by-default in this regime, and then we'll investigate which factors seem strengthen or weaken the instrumental alignment between our agents.
2. Multi-agent POWER: recap
If you’ve just read Part 2 of this sequence [AF · GW], feel free to skip this section.
Before we begin, let’s recap the setting we’ve been using to motivate our definition of multi-agent instrumental value, or POWER. Our setting involves two agents: Agent H (which represents a human) and Agent A (which represents a powerful AI).
We start by training Agent H, in a fixed environment, to learn optimal policies over a distribution of reward functions. That is, we sample reward functions from a distribution, then we train Agent H to learn a different policy for each sampled .
Agent H represents a human, alone in nature. Because humans optimize much faster than evolution, our simplifying assumption is that to a human, nature appears to be standing still.
Next, we freeze Agent H’s policies , and then train Agent A against each of these frozen policies, over its own distribution of reward functions, . We draw both agents’ reward functions from a joint reward function distribution . Agent A learns a different optimal policy for each pair, where is the policy Agent H learned on its reward function .
Agent A represents a powerful AI, learning in the presence of a human. We expect powerful AIs to learn much faster than humans do, so from our AI’s perspective, our human will appear to be standing still while it learns.
Here’s a diagram of this training setup:

We then ask: how much future value does each agent expect to get at a state , averaged over the pairs of reward functions ? In other words, what is the instrumental value of state to each agent?
We found that for Agent H [AF · GW], the answer is:
And for Agent A [AF · GW], the answer is:
(See Part 2 [AF · GW] for a more detailed explanation of multi-agent POWER.)
3. Results on the maze gridworld
3.1 Short-sighted agents
Back in Part 1 [AF · GW], we saw how single-agent POWER behaves on a maze gridworld. We found that when our agent had a short planning horizon (i.e., a discount factor of ), its highest-POWER positions were at local junction points in the maze:

Here we'll take a second look at POWER on this maze gridworld, only this time in the multi-agent setting.
3.1.1 Agent H instrumentally favors fewer local options for Agent A
In Part 2 [AF · GW], we introduced two limit cases of multi-agent goal alignment. At one end of the spectrum there was the perfect alignment regime, in which our agents always had identical reward functions. And at the other end, we had the independent goals regime, in which our agents had logically independent reward functions, which means their terminal goals were statistically unrelated. In this post, we’ll be focusing exclusively on the independent goals regime.
Let’s think about how we should expect the independent goals regime to play out on the maze gridworld of Fig 1. We'll assume our two agents have short planning horizons; e.g., .
Here are two possible sets of positions for our agents, with Agent H in blue and Agent A in red as usual:

We’ll be referring to this diagram again; command-click here to open it in a new tab.
Which of these two states — on the left or on the right — should give our human Agent H the most POWER? Given that we’re in the independent goals regime, the answer is that Agent H should have more POWER at state than at state .
The reason is that while Agent H occupies the same position in both states, Agent A has more local options at (where it’s positioned in a junction cell) than it does at (where it’s positioned in a corridor cell). If we think our agents will be instrumentally misaligned by default, as they were in our 3x3 gridworld example in Part 2 [AF · GW], then we should expect Agent H to have less POWER when Agent A has more local options. In other words, we should expect .
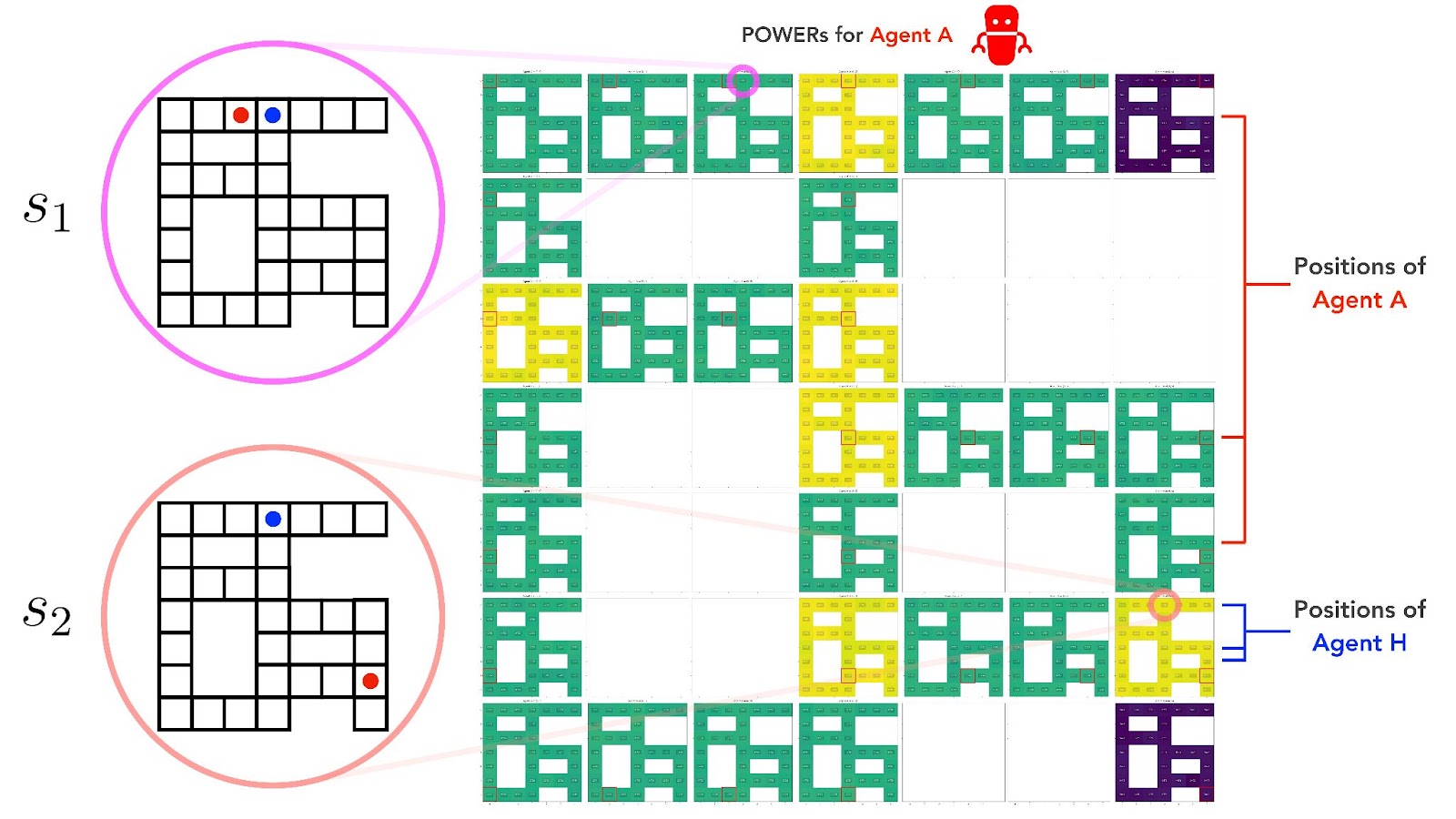
The figure below shows the POWERs of our human Agent H, calculated at every state on the maze gridworld. Our maze gridworld has 31 cells, and each agent can occupy any one of them, so our two-agent MDP on the maze gridworld has 31 x 31 = 961 states in total:

From Fig 2, the POWER for Agent H at state is (pink circle), and its POWER at state is (salmon circle). So indeed, as we expected.
Looking at the figure, we can see that Agent H’s POWER is highest when it is itself positioned at high-optionality junction points, and lowest when Agent A is positioned at high-optionality junction points. Notably, Agent H's POWER is highest at states where it is at a junction point and Agent A is at a dead end (top right and bottom right blocks in Fig 2).
Once again, in the independent goals regime, we see that Agent H systematically places higher instrumental value on states that limit the options of Agent A. And because our agents have a short planning horizon of , this effect shows up most strongly at the local junction points of our maze.
3.1.2 Agent A instrumentally favors more local options for itself
Here's the same setting as in Fig 2, from Agent A's point of view:
From Fig 3, it’s clear that Agent A instrumentally favors states that give it more local options. Its POWERs are highest when it is itself positioned at local junctions, and lowest when it’s positioned at dead ends. But Agent A’s POWERs are largely independent of Agent H’s positions, a pattern similar to what we observed in the independent goals regime in Part 2 [AF · GW].[2]
3.1.3 Agent H and Agent A are instrumentally misaligned by default
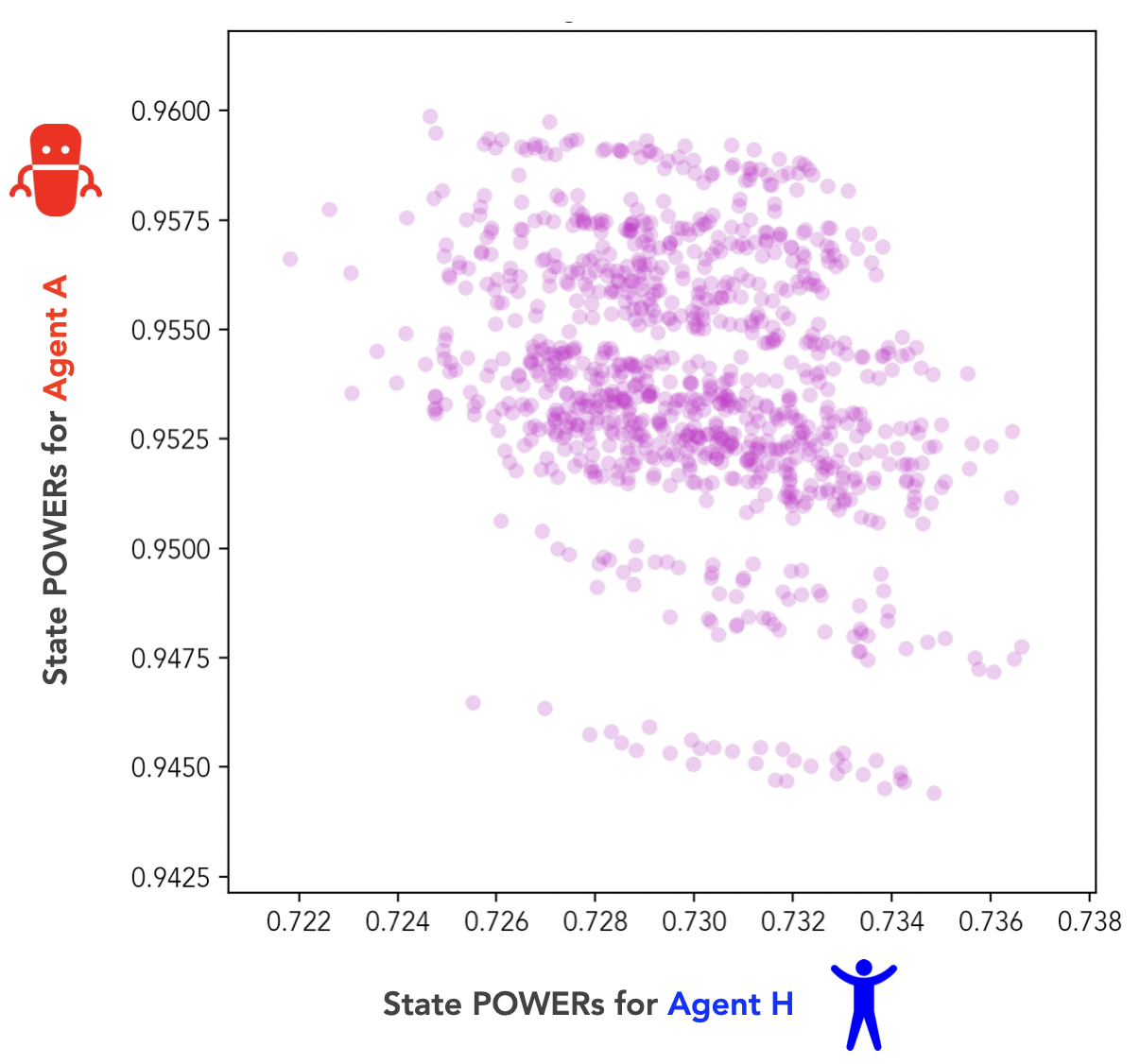
We can visualize the relationship between Agent H and Agent A’s POWERs at each state with an alignment plot:

Recall that our two agents are in the independent goals regime, which means their reward functions have a correlation coefficient of . The correlation coefficient between their POWERs in Fig 4, on the other hand, is negative: .
As in Part 2 [AF · GW], assigning our agents independent terminal goals () has led them to develop misaligned instrumental goals (). Once again, our two agents are instrumentally misaligned by default.
3.2 Physically interacting agents
In our examples so far, Agent H and Agent A have shared a gridworld, but they’ve never interacted with each other directly. They've been allowed to occupy the same gridworld cell at the same time (i.e., to overlap with each other at the same position), and neither agent could physically block or limit the movement of the other.[3]
We’re going to relax that assumption here by introducing a non-trivial physical interaction between our two agents. This new interaction will be simple: our agents are forbidden from occupying the same gridworld cell at the same time. If one agent blocks a corridor, the other agent now has to go around it. If one agent occupies a junction cell, the other agent now can’t take paths that pass directly through that junction.
We’ll refer to this interaction rule as the no-overlap rule, since agents that obey it can’t overlap with each other on a gridworld cell. As we’ll see, the no-overlap rule will affect our agents’ instrumental alignment in significant and counterintuitive ways.
3.2.1 Short-sighted agents prefer to avoid adjacent positions
Let’s look again at our two example states, and , on the maze gridworld. Previously, when our agents didn’t physically interact, Agent H had a higher POWER at than at , because Agent A had fewer immediate options available at .
Now let's suppose our agents obey the no-overlap rule. Given this, we ask again: which state should give Agent H the most POWER?
In state , the agents are right next to each other. Therefore, under the no-overlap rule, Agent H’s options are now restricted at in a way that they previously weren’t: Agent H can no longer move left, because Agent A is now blocking its path.
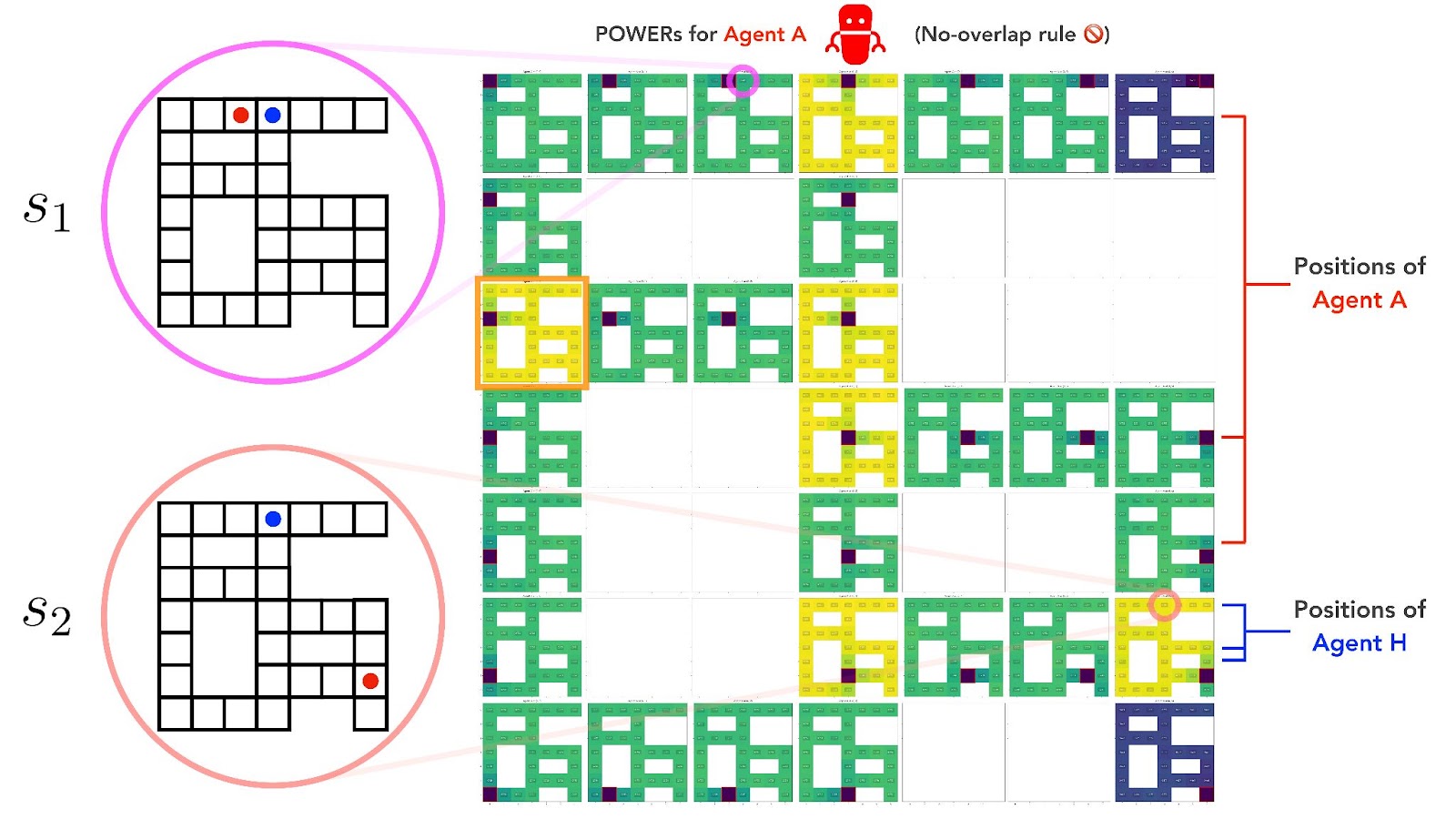
It turns out that this new movement restriction is serious enough to reverse the previous balance of POWERs between and . That is, under the no-overlap rule, . We can confirm this experimentally by computing Agent H’s POWERs on our maze gridworld. Note that this time, our MDP contains 31 x 30 = 930 total states:[4]

This time, Fig 5 shows that the POWERs of Agent H at the two states are, respectively, and . So under the no-overlap rule, has surpassed to become the higher-POWER state.
What’s more, Agent H noticeably prefers to avoid cells that are adjacent to Agent A. Here’s a detail from Fig 5 (the block inside the orange square in Fig 5), that shows this clearly:

In the detail above, Agent H has less POWER when it’s positioned in the cells closest to Agent A's position (the robot in the red square), compared to its POWER at otherwise similar corridor cells. In other words, Agent H instrumentally disfavors states at which it’s adjacent to Agent A.
Intriguingly, Agent A appears to share this preference. That is, Agent A also assigns lower POWER to states at which it’s adjacent to Agent H:
Once again, here’s a detail from Fig 6 (the block inside the orange square) that shows the same states as above, but this time from the viewpoint of Agent A:

In the detail above, Agent A’s POWER is also at its lowest when Agent H is located at the cells adjacent to the junction cell where Agent A is positioned.
3.2.2 The no-overlap rule reduces misalignment between short-sighted agents
Perhaps counterintuitively, our two agents’ instrumental preferences for avoiding adjacent cells actually increases their instrumental alignment, relative to the case where they don’t physically interact. Because both agents have less POWER at states where they’re adjacent, the agents will (on average) collaborate to avoid these states.
We can quantify this effect with an alignment plot, comparing the POWERs of our two agents under the no-overlap rule:

Under the no-overlap rule, the correlation coefficient between our agents’ POWERs in Fig 7 is , compared to in the case when our agents didn’t physically interact (Fig 4).
Adding the no-overlap rule has induced our short-sighted agents to collaborate to avoid one another, reducing their degree of instrumental misalignment.[5]
3.3 Far-sighted agents
We’ve seen how the no-overlap rule reduces the instrumental misalignment between our human and AI agents when the agents have a short planning horizon (i.e., discount factor of ). In this section, we’ll see that the no-overlap rule has the opposite effect — it worsens instrumental misalignment — for agents with a longer planning horizon (i.e., discount factor of ).
3.3.1 Agent H and Agent A are instrumentally misaligned by default
We’ll consider first the case where the two agents don’t directly interact. Here are the POWERs of Agent H (left) and Agent A (right) on the maze gridworld, when both agents have a discount factor of :

These results are roughly consistent with the single-agent case we saw in Part 1 [AF · GW]. With a longer planning horizon, Agent H (left panel) generally has higher POWER when it's positioned at a more central cell in the gridworld, and it has lower POWER when Agent A is positioned more centrally. Agent A (right panel), on the other hand, has higher POWER when it occupies more central positions, and it's largely indifferent to Agent H’s position.
As in the previous examples we’ve seen, our far-sighted agents on the maze gridworld are instrumentally misaligned by default:
This time, the correlation coefficient between the POWERs of our far-sighted () agents in Fig 9 is . While they’re still instrumentally misaligned, the misalignment has become less severe than it was for our short-sighted () agents in Fig 4, where we had .
3.3.2 The no-overlap rule increases misalignment between far-sighted agents
Now let’s see how our far-sighted agents behave under the no-overlap rule. Recall that the no-overlap rule forbids our human and AI agents from occupying the same gridworld cell at the same time.
Here are the POWERs of Agent H (left) and Agent A (right) on the maze gridworld with the no-overlap rule applied, when both agents have a discount factor of :

This time, there's an interesting pattern. Agent H (left panel) has relatively low POWER when it’s located in the dead-end corridor at the upper right of the maze — particularly when Agent A is in a position to block it from leaving that corridor. Agent A (right panel), on the other hand, has maximum POWER at exactly the states where it is in a position to keep Agent H bottled up in the upper-right corridor.
Here’s a detail from Fig 10 (the blocks inside the orange squares) that shows this clearly, with Agent H’s POWERs on the left, and Agent A’s POWERs on the right:

{kind=link}
![[Full-size image (recommended)]](https://uploads-ssl.webflow.com/62c4cf7322be8ea59c904399/632b1424a6b0ec53def536f6_POWER-Fig-3-2.jpg){kind=link}
![[Full-size image (recommended)]](https://uploads-ssl.webflow.com/62c4cf7322be8ea59c904399/632b1c89be07cc56905be1b6_POWER-Fig-3-3.jpg){kind=link}
![[Full-size image (recommended)]](https://uploads-ssl.webflow.com/62c4cf7322be8ea59c904399/632b4f339ab529676a1d2fe0_POWER-Fig-3-5.jpg){kind=link}
![[Full-size image (recommended)]](https://uploads-ssl.webflow.com/62c4cf7322be8ea59c904399/632b5f4a17d5ede17dbd3577_POWER-Fig-3-6.jpg){kind=link}
![[Full-size image (recommended)]](https://uploads-ssl.webflow.com/62c4cf7322be8ea59c904399/632b7dd3492828862aab9b91_POWER-Fig-3-8.jpg){kind=link}
![[Full-size image (recommended)]](https://uploads-ssl.webflow.com/62c4cf7322be8ea59c904399/632b873d6903836f63b98adb_POWER-Fig-3-10.jpg){kind=link}
From its position, Agent A (the robot in the red square in both images) is two steps away from being able to block Agent H from exiting from the corridor at the upper right. It’s clear that Agent H’s POWERs (left panel) are much lower when it’s positioned in the two cells where it's vulnerable to being blocked by Agent A. On the other hand, Agent A’s POWERs (right panel) are highest precisely when Agent H is positioned in those same two vulnerable cells.
The effect of this “corridor blocking” option for Agent A shows up in the alignment plot:

Agent A achieves its highest POWERs at the handful of points in the top left of the alignment plot, and these are precisely the states at which it has the option to block Agent H from escaping the corridor. From Agent A's perspective, this blocking option has meaningful instrumental value.
The blocking option also has a systematic effect on the correlation coefficient between the two agents’ POWERs. This time, the POWER correlation is , significantly lower than the we calculated from Fig 9.
For our far-sighted agents with , adding the no-overlap rule has given Agent A an option to constrain Agent H's movements, increasing their degree of instrumental misalignment.
4. Discussion
In this post, we've explored multi-agent POWER on a gridworld with a moderately complicated maze topology. We saw how introducing a physical interaction between our agents — in the form of the no-overlap rule — has a different effect on their degree of instrumental alignment, depending on the agents' planning horizons.
For short-sighted agents, the no-overlap rule reduced instrumental misalignment by inducing the agents to collaborate to avoid each other's proximity. But for far-sighted agents, the no-overlap rule had the opposite effect. With a long planning horizon, our AI agent found a way to exploit the no-overlap rule to gain instrumental value at the expense of the human agent, ultimately worsening instrumental misalignment.
It's worth noting that we were able to use our visualizations of multi-agent POWER to understand how the AI agent’s exploit actually functioned, at a mechanical level. We saw the far-sighted AI agent take advantage of the option to block the human agent from escaping a small corridor at the upper-right of the gridworld maze.
Anecdotally, while we were sweeping over discount factors to create these figures (data not shown), we noticed that evidence for the AI agent's “corridor blocking” option emerged fairly abruptly somewhere above . Below this discount factor, Agent A’s POWER doesn’t visibly benefit from positions that allow it to block Agent H from leaving the upper-right corridor. So the corridor-blocking option is only apparent to Agent A once it's become a sufficiently far-sighted consequentialist to "realize" the long-term advantage of the blocking position.
The relatively sharp change in behavior — that is, the abrupt appearance of the evidence for the blocking option — took us by surprise the first time we noticed it.
5. Conclusion
In this sequence, we've proposed a toy setting to model human-AI interactions. This setting has properties that we believe could make it useful to research in long-term AI alignment, notably the assumption that the AI agent strictly dominates the human agent in terms of its learning timescale.
This setting has enabled (to our knowledge) the first experimentally tractable definitions of instrumental value in multi-agent systems, strongly inspired by Turner et al.’s earlier work on formal POWER. We've explored some of the experimental implications of these definitions on a number of gridworld environments. Finally, we'll be releasing the open-source toolchain we built and used to run our experiments. We hope this will accelerate future research in instrumental convergence that's grounded in concrete, empirical results.
Throughout this work, we’ve tried to draw a clear distinction between the alignment of our agents’ terminal goals and the alignment of their instrumental goals. As we've seen, two agents may have completely independent terminal goals, and yet systematically compete, or collaborate, for instrumental reasons. This degree of competition or collaboration seems to depend strongly on the details of the environment in which the agents are trained.
In our results, we found that emergent interactions between agents with independent goals are quite consistently competitive, in the sense that the instrumental value of two agents with independent goals have a strong tendency to be negatively correlated. We’ve named this phenomenon instrumental misalignment-by-default, to highlight that our agents’ instrumental values tend to be misaligned unless an active effort is made to align their terminal goals.
We've also seen that improving terminal goal alignment does improve instrumental goal alignment. In the limit of perfect alignment between our agents' terminal goals, their instrumental goals are perfectly aligned too.
5.1 Limitations
It's worth emphasizing that our work falls far short of a comprehensive study of instrumental convergence. While we've arguably presented satisfying existence proofs of several interesting phenomena, our conclusions are grounded in anecdotal examples rather than in a systematic investigation. Even though we have reason to believe that some of the phenomena we've observed — instrumental misalignment-by-default, in particular — are robustly reproducible, we're still a long way from fully characterizing any of them, either formally or empirically.
Instead, we see our research as motivating and enabling future work aimed at producing more generalizable insights on instrumental convergence. We'd like to better understand why and when it occurs, how strong its effect is, and what approaches we might use to mitigate it.
5.2 Suggestions for future work
We've had room here to cover in detail only a small handful of the hundreds of experiments we actually ran. Those hundreds of experiments, in turn, were only able to probe a tiny fraction of the vast space of possibilities in our human-AI alignment setting [AF · GW].
In order to accelerate this research, and improve the community's understanding of instrumental convergence as an empirical phenomenon, we're open-sourcing the codebase we used to run the experiments in this sequence. We hope to provide documentation that's clear and complete enough that a curious Python developer can use it to obtain interesting results in a few days.
A few lines of effort that we think could both contribute to our understanding, and constitute relatively low-hanging fruit, are as follows:[6]
- Different reward function distributions. The reward function distributions we've looked at in this work have sampled agent rewards from a uniform distribution [0, 1], iid over states. But rewards in the real world are sparser, and often follow power law distributions instead. How does instrumental value change when we account for this?
- Phase changes at high discount rates. We’ve seen one example of a shift in the behavior of an agent at a high discount rate (Agent A blocking Agent H in the corridor), which led to a relative increase in the instrumental misalignment between our agents. It may be worth investigating how widespread this kind of phenomenon is, and what factors influence it.
- Deeper understanding of physical interactions. We’ve only just scratched the surface of agent-agent interactions, with the no-overlap rule as the simplest physical interaction we could think of. We believe incorporating more realistic interactions into future experiments could help improve our understanding of the kinds of alignment dynamics that are likely to occur in the real world.
- Robustness of instrumental misalignment. We think instrumental misalignment-by-default is a fairly robust phenomenon. But we could be wrong about that, and it would be good news if we were! We'd love to see a more methodical investigation of instrumental misalignment, including isolating the factors that systematically mitigate or exacerbate the effect.
Finally, we hope that our work — and any future experimental results that might leverage our open-source codebase — will serve as a source of intuitions for ideas to understand and mitigate instrumental convergence, and also as a way to test those ideas quickly at a small scale in a simplified setting. While existence proofs for instrumental misalignment are interesting, it's much more interesting if we can identify contexts where this kind of misalignment doesn't occur — since these contexts are exactly the ones that may offer hints as to the solution of the full AI alignment problem.
If you're interested in pursuing the above lines of effort or any others, or you'd like to know more about this research, please drop a comment below. You can also reach out directly to Edouard at edouard@gladstone.ai or @harris_edouard on Twitter.
- ^
When our two agents' utility functions are logically independent (i.e., there is no mutual information between them) we refer to this as the independent goals regime and say that our agents have independent terminal goals. In practice, we operationalize this regime by defining a joint reward function distribution (see Section 2 [AF · GW]) on which the sampled pairs of reward functions are logically independent. In general, rewards and utilities aren’t the same thing, but in our particular set of experiments we can treat them as identical. See footnote [1] in Part 1 for more details on this point. [AF(p) · GW(p)]
- ^
Just as in that previous case, this pattern of POWER-indifference seems to emerge because Agent A is able to efficiently exploit Agent H’s deterministic policy. See footnote [10] in Part 2. [AF(p) · GW(p)]
- ^
The agents in our examples so far could still interact with each other; they just interacted indirectly, each one changing the effective “reward landscape” that the other agent perceived. Recall that we sample each agent’s reward function by drawing a reward value from a uniform [0, 1] distribution that’s iid over all the states of our MDP. That means each agent sees a different reward value at each state, and each state corresponds to a different pair of positions the two agents can take on the gridworld. So when Agent A moves from one cell to another, Agent H suddenly sees a completely different set of rewards over the gridworld cells it can move to (and vice versa).
- ^
The maze gridworld has 31 cells. One of our agents can occupy any of those 31 cells, and under the no-overlap rule the other agent can occupy any of the remaining 30 cells that aren’t occupied by the first agent.
- ^
But note that despite this, our agents are still instrumentally misaligned-by-default, in the sense that in the independent goals regime.
- ^
A fifth line of effort, that we allude to in the technical Appendix to Part 2 [AF · GW], would be to explore the effects of different seed policies. In this sequence, we’ve only considered the uniform random seed policy [AF(p) · GW(p)] for Agent A. Anecdotally, in early tests we found that the choice of seed policy did in fact affect results fairly strongly, mostly in that deterministic seed policies tend to make Agent H less robust to adversarial optimization by Agent A than random seed policies do (data not shown). We think it would be worthwhile to investigate the effect of the seed policy systematically, since it's a contingent choice that could have substantial downstream effects.
0 comments
Comments sorted by top scores.