Seeking Power is Convergently Instrumental in a Broad Class of Environments
post by TurnTrout · 2021-08-08T02:02:18.975Z · LW · GW · 15 commentsContents
Instrumental convergence can get really, really strong Formal justification Beyond survival-seeking Instrumental Convergence Disappears For Utility Functions Over Action-Observation Histories How Structural Assumptions On Utility Affect Instrumental Convergence Notes Conclusion Appendix: Tracking key limitations of the power-seeking theorems None 15 comments
Edit, 5/16/23: I think this post is beautiful, correct in its narrow technical claims, and practically irrelevant to alignment. This post presents an unrealistic picture of the role of reward functions in reinforcement learning, conflating "utility" with "reward" in a type-incorrect fashion. Reward functions are not "goals", real-world policies are not "optimal", and the mechanistic function of reward is (usually) to provide policy gradients to update the policy network.
I expect this post to harm your alignment research intuitions unless you've already inoculated yourself by deeply internalizing and understanding Reward is not the optimization target [LW · GW]. If you're going to read one alignment post I've written, read that one.
Follow-up work (Parametrically retargetable decision-makers tend to seek power [LW · GW]) moved away from optimal policies and treated reward functions more realistically.
A year ago, I thought it would be really hard to generalize the power-seeking theorems from Markov decision processes (MDPs); the MDP case [? · GW] seemed hard enough. Without assuming the agent can see the full state, while letting utility functions do as they please – this seemed like asking for trouble.
Once I knew what to look for, it turned out to be easy – I hashed out the basics during half an hour of conversation with John Wentworth. The theorems were never about MDPs anyways; the theorems apply whenever the agent considers finite sets of lotteries over outcomes, assigns each outcome real-valued utility, and maximizes expected utility.
Thanks to Rohin Shah, Adam Shimi, and John Wentworth for feedback on drafts of this post.
Instrumental convergence can get really, really strong
At each time step , the agent takes one of finitely many actions , and receives one of finitely many observations drawn from the conditional probability distribution , where is the environment. There is a finite time horizon . Each utility function maps each complete observation history to a real number (note that can be represented as a vector in the finite-dimensional vector space ). From now on, u-OH stands for "utility function(s) over observation histories."
First, let's just consider a deterministic environment. Each time step, the agent observes a black-and-white image () through a webcam, and it plans over a 50-step episode (). Each time step, the agent acts by choosing a pixel to bit-flip for the next time step.
And let's say that if the agent flips the first pixel for its first action, it "dies": its actions no longer affect any of its future observations past time step . If the agent doesn't flip the first pixel at , it's able to flip bits normally for all steps.
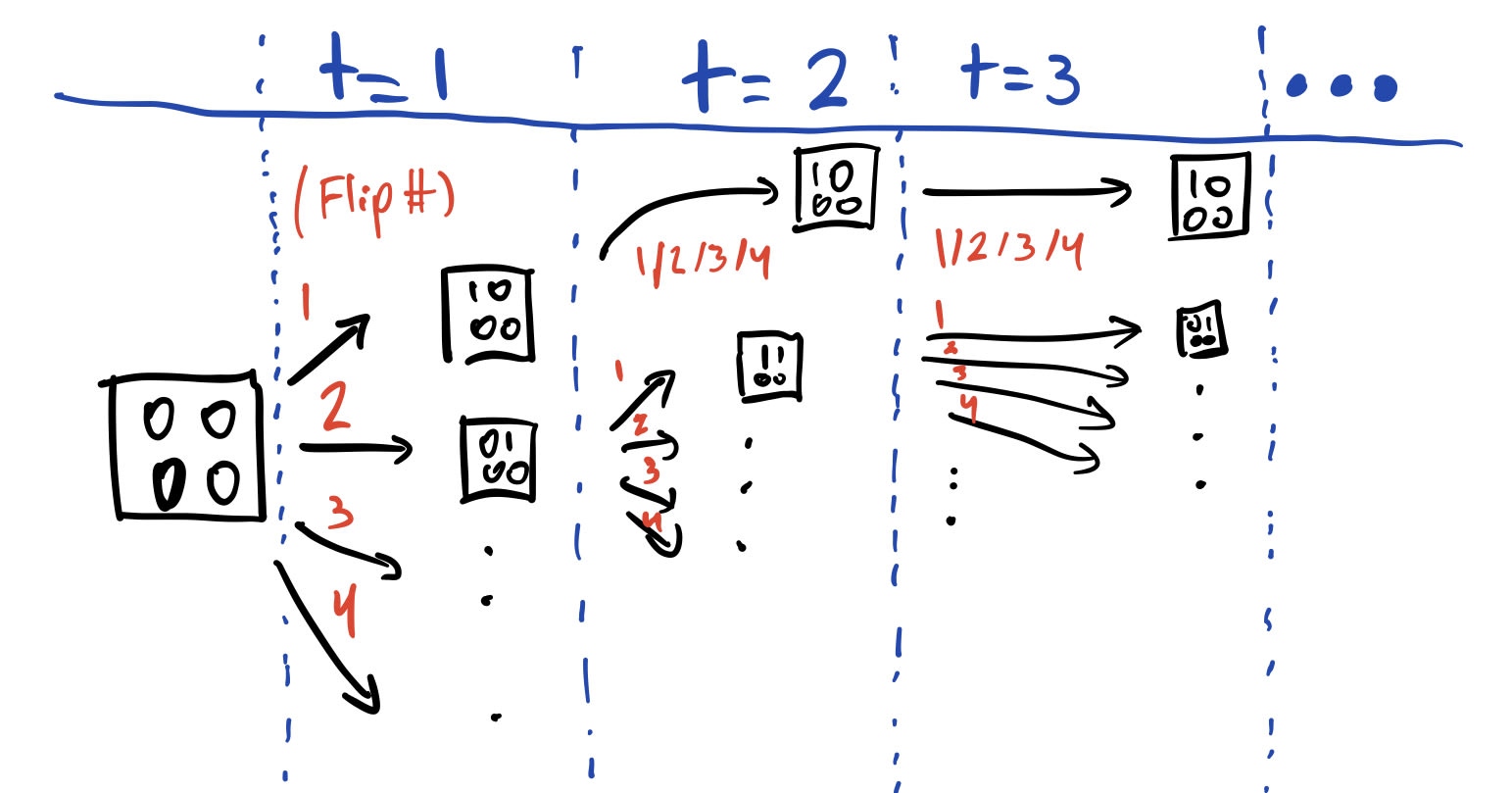
Do u-OH tend to incentivize flipping the first pixel over flipping the second pixel, vice versa, or neither?
If the agent flips the first bit, it's locked into a single trajectory. None of its actions matter anymore.
But if the agent flips the second bit – this may be suboptimal for a utility function, but the agent still has lots of choices remaining. In fact, it still can induce observation histories. If and , then that's observation histories. Probably at least one of these yields greater utility than the shutdown-history utility.
And indeed, we can apply the scaling law for instrumental convergence [LW · GW] to conclude that for every u-OH, at least of its permuted variants [LW · GW] (weakly) prefer flipping the second pixel at , over flipping the first pixel at .
Choose any atom in the universe. Uniformly randomly select another atom in the universe. It's about times more likely that these atoms are the same, than that a utility function incentivizes "dying" instead of flipping pixel 2 at .
(The general rule will be: for every u-OH, at least of its permuted variants weakly prefer flipping the second pixel at , over flipping the first pixel at . And for almost all u-OH, you can replace 'weakly' with 'strictly.')
Formal justification
The power-seeking results hinge on the probability of certain linear functionals being "optimal." For example, let be finite sets of vectors, and let be any probability distribution over .
Definition: Optimality probability of a linear functional set. The optimality probability of relative to under distribution is
If vectors represent lotteries over outcomes (where each outcome has its own entry), then we can say that:
- and each contain some of the things the agent could make happen
- contains all of the things the agent could make happen ()
- Each is a utility function over outcomes, with one value for each entry.
- If is an outcome lottery, then is its -expected value.
- Things in are more likely to be optimal than things in when .
Nothing here has anything to do with a Markov decision process, or the world being finite, or fully observable, or whatever. Fundamentally, the power-seeking theorems were never about MDPs – they were secretly about the probability that a set of linear functionals is optimal, with respect to another set . MDPs were just a way to relax the problem [LW · GW].
In terms of the pixel-flipping environment:
- When followed from a time step, each (deterministic) policy induces a distribution over observation histories
- These are represented as unit vectors, with each entry marking the probability that an observation history is realized
- If the environment is deterministic, all deterministic policies induce standard basis vectors (probability 1 on their induced observation history, 0 elsewhere)
- Let be the set of histories available given that selects ('death') at the first time step.
- As argued above, – the agent loses all control over future observations. Its element is a standard basis vector.
- Define similarly for (flipping pixel 2) at the first time step.
- As argued above, ; all elements are standard basis vectors by determinism.
- Let be the set of all available observation histories, starting from the first time step.
- There exist different involutions over observation histories such that (each transposing 's element with a different element of ). Each one just swaps the death-history with an -history.
- By the scaling law of instrumental convergence, we conclude that
For every u-OH, at least of its permuted variants (weakly) prefer flipping the second pixel at , over flipping the first pixel at .
- By the scaling law of instrumental convergence, we conclude that
Beyond survival-seeking
I often give life-vs-death examples because they're particularly easy to reason about. But the theorems apply to more general cases of more-vs-less control.
For example, if restricts the agent to two effective actions at each time step (it can only flip one of the first two pixels) – instead of "killing" the agent, then is still convergently instrumental over . There are observation histories available after taking action , and so these can be embedded at least times into the observation histories available after . Then for every u-OH, at least of its permuted variants (weakly) prefer flipping the second pixel at , over flipping the first pixel at .
Instrumental Convergence Disappears For Utility Functions Over Action-Observation Histories
Let's consider utility functions over action-observation histories (u-AOH).
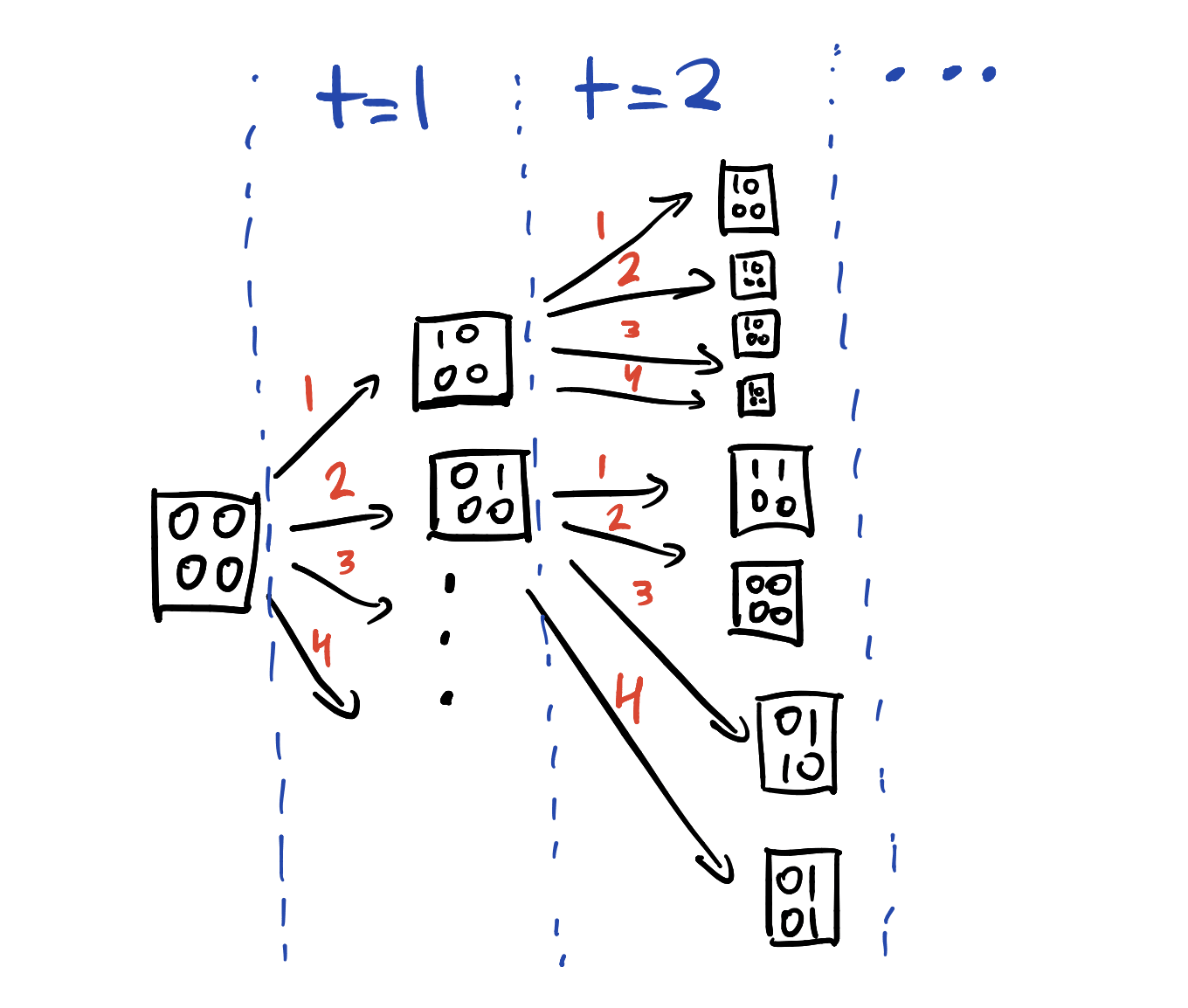
Since each utility function is over an AOH, each path through the tree is assigned a certain amount of utility. But when the environment is deterministic, it doesn't matter what the agent observes at any point in time – all that matters is which path is taken through the tree. Without further assumptions, u-AOH won't tend to assign higher utility to one subtree than to another.
More formally, for any two actions and , let be a permutation over AOH which transposes the histories available after with the histories available after (there's an equal number of histories for each action, due to the regularity of the tree – you can verify this by inspection).
For every u-AOH , suppose is strictly -optimal over . The permuted utility function makes be strictly -optimal over , since swaps 's strictly -optimal history with 's strictly -suboptimal histories.
Symmetrically, works the other way around ({ strictly optimal} { strictly optimal}). Therefore, for every utility function , the # of variants which strictly prefer over , is equal to the # of variants strictly preferring over :
While I haven't been writing in the "definition-theorem-corollary" style, the key claims are just corollaries of the scaling law of instrumental convergence. They're provably true. (I'm just not writing up the math here because it's annoying to define all the relevant quantities in a nice way that respects existing formalisms.)
And even if the environment is stochastic, I think that there won't be any kind of interesting instrumental convergence. The theorems let us reason about that case, but their applicability depends on the details of the stochasticity, and so I won't talk about that more here.
Conclusion: Optimal policies for u-AOH will tend to look like random twitching. For example, if you generate a u-AOH by uniformly randomly assigning each AOH utility from the unit interval , there's no predictable regularity to the optimal actions for this utility function. In this setting and under our assumptions, there is no instrumental convergence without further structural assumptions.
How Structural Assumptions On Utility Affect Instrumental Convergence
Consider the pixel-flipping case (with still). Action still leads to a single OH, while leads to OHs. So we have instrumental convergence for of all u-OH variants.
Let's model the pixel-flipping environment environment as a Markov decision process (MDP), with both the time-step and alive/dead status observed at each time step in order to ensure full observability, and the final time-step observations being terminal states where the agent stays forever. Dying allows the agent access to 1 terminal state: the observation 1/0/0/0(dead). But surviving via lets the agent access terminal states (all 16 binary strings of length 4, with 'alive' appended to the end).
For each reward function over states, only of its permuted variants will incentivize [LW · GW] not dying at (considering policies which maximize average per-timestep reward). This is a lot looser than the bound for u-OH. What gives?
MDPs assume that utility functions have a lot of structure: the utility of a history is time-discounted additive over observations. Basically, , for some and reward function over observations. And because of this structure, the agent's average per-timestep reward is controlled by the last observation it sees. There are exponentially fewer last observations than there are observation histories. Therefore, in this situation, instrumental convergence is exponentially weaker for reward functions than for arbitrary u-OH.
This suggests that rolling a random u-OH for AIXI [? · GW] might be far more dangerous than rolling a random reward function for an optimal reinforcement learner.
Structural assumptions on utility really do matter when it comes to instrumental convergence:
- u-AOH: No IC [LW · GW]
- u-OH: Strong IC [LW · GW]
- State-based objectives (eg state-based reward in MDPs): Moderate IC [? · GW]
Environmental structure can cause instrumental convergence [LW · GW], but (the absence of) structural assumptions on utility can make instrumental convergence go away (for optimal agents).
Notes
- Of course, you can represent u-AOH as u-OH by including the agent's previous action in the next observation.
- But this is a different environment; whether or not this is in fact a good model depends on the agent's action and observation encodings [? · GW].
- Time-reversible dynamics + full observability is basically the u-AOH situation, since each action history leads to a unique world state at every time step.
- But if you take away full observability, time-reversibility is insufficient to make instrumental convergence disappear.
Conclusion
- For optimal agents, instrumental convergence can be extremely strong for utility functions over observation histories.
- Instrumental convergence doesn't exist for utility functions over action-observation histories.
- IE optimal action will tend to look like random twitching.
- This echoes previous discussion [? · GW] of the triviality of coherence over action-observation histories, when it comes to determining goal-directedness.
- This suggests that consequentialism over observations/world states is responsible for convergent instrumental incentives.
- Approaches like approval-directed agency focus on action selection instead of optimization over future observations.
- Environmental structure can cause instrumental convergence [LW · GW], but (lack of) structural assumptions on utility can make instrumental convergence go away.
Appendix: Tracking key limitations of the power-seeking theorems
Time to cross another item off of the list from last time [LW · GW]; the theorems:
- assume the agent is following an optimal policy for a reward function
- I can relax this to -optimality, but may be extremely small
assume the environment is finite and fully observable- Not all environments have the right symmetries
- But most ones we think about seem to
- don't account for the ways in which we might practically express reward functions
- For example, state-action versus state-based reward functions (this particular case doesn't seem too bad, I was able to sketch out some nice results rather quickly, since you can convert state-action MDPs into state-based reward MDPs and then apply my results).
Re 3), in the setting of this post, when the observations are deterministic, the theorems will always apply. (You can always involute one set of unit vectors into another set of unit vectors in the observation-history vector space.)
Another consideration is that when I talk about "power-seeking in the situations covered by my theorems", the theorems don't necessarily show that gaining social influence or money is convergently instrumental. I think that these "resources" are downstream of formal-power, and will eventually end up being understood in terms of formal-power – but the current results don't directly prove that such high-level subgoals are convergently instrumental.
Footnote finite: I don't think we need to assume finite sets of vectors, but things get a lot harder and messier when you're dealing with instead of . It's not clear how to define the non-dominated elements of an infinite set, for example, and so a few key results break. One motivation for finite being enough is: in real life, a finite mind can only consider finitely many outcomes anyways, and can only plan over a finite horizon using finitely many actions. This is just one consideration, though.
Footnote environment: For simplicity, I just consider environments which are joint probability distributions over actions and observation. This is much simpler than the lower semicomputable chronological conditional semimeasures used in the AIXI literature, but it suffices for our purposes, and the theory could be extended to LSCCCSs if someone wanted to.
15 comments
Comments sorted by top scores.
comment by dxu · 2021-08-08T22:18:50.614Z · LW(p) · GW(p)
One particular example of this phenomenon that comes to mind:
In (traditional) chess-playing software, generally moves are selected using a combination of search and evaluation, where the search is (usually) some form of minimax with alpha-beta pruning, and the evaluation function is used to assign a value estimate to leaf nodes in the tree, which are then propagated to the root to select a move.
Typically, the evaluation function is designed by humans (although recent developments have changed that second part somewhat) to reflect meaningful features of chess understanding. Obviously, this is useful in order to provide a more accurate estimate for leaf node values, and hence more accurate move selection. What's less obvious is what happens if you give a chess engine a random evaluation function, i.e. one that assigns an arbitrary value to any given position.
This has in fact been done, and the relevant part of the experiment is what happened when the resulting engine was made to play against itself at various search depths. Naively, you'd expect that since the evaluation function has no correlation with the actual value of the position, the engine would make more-or-less random moves regardless of its search depth--but in fact, this isn't the case: even with a completely random evaluation function, higher search depths consistently beat lower search depths.
The reason for this, once the games were examined, is that the high-depth version of the engine seemed to consistently make moves that gave its pieces more mobility, i.e. gave it more legal moves in subsequent positions. This is because, given that the evaluation function assigns arbitrary values to leaf nodes, the "most extreme" value (which is what minimax cares about) will be uniformly distributed among the leaves, and hence branches with more leaves are more likely to be selected. And since mobility is in fact an important concept in real chess, this tendency manifests in a way that favors the higher-depth player.
At the time I first learned about this experiment, it struck me as merely a fascinating coincidence: the fact that selecting from a large number of nodes distributed non-uniformly leads to a natural approximation of the "mobility" concept was interesting, but nothing more. But the standpoint of instrumental convergence reveals another perspective: the concept chess players call "mobility" is actually important precisely because it emerges even in such a primitive system, one almost entirely divorced from the rules and goals of the game. In short, mobility is an instrumentally useful resource--not just in chess, but in all chess-like games, simply because it's useful to have more legal moves no matter what your goal is.
(This is actually borne out in games of a chess variant called "suicide chess", where the goal is to force your opponent to checkmate you. Despite having a completely opposite terminal goal to that of regular chess, games of suicide chess actually strongly resemble games of regular chess, at least during the first half. The reason for this is simply that in both games, the winning side needs to build up a dominant position before being able to force the opponent to do anything, whether that "anything" be delivering checkmate or being checkmated. Once that dominant position has been achieved, you can make use of it to attain whatever end state you want, but the process of reaching said dominant position is the same across variants.)
Additionally, there are some analogies to be drawn to the three types of utility function discussed in the post:
-
Depth-1 search is analogous to utility functions over action-observation histories (AOH), in that its move selection criterion depends only on the current position. With a random (arbitrary) evaluation function, move selection in this regime is equivalent to drawing randomly from a uniform distribution across the set of immediately available next moves, with no concern for what happens after that. There is no tendency for depth-1 players to seek mobility.
-
Depth-2 search is analogous to a utility function in a Markov decision process (MDP), in that its move selection criterion depends on the assessment of the immediate next time-step. With a random (arbitrary) evaluation function, move selection in this regime is equivalent to drawing randomly from a uniform distribution across the set of possible replies to one's immediately available moves, which in turn is equivalent to drawing from a distribution over one's next moves weighted by the number of replies. There is a mild tendency for depth-2 players to seek mobility.
-
Finally, maximum-depth search would be analogous to the classical utility function over observation histories (OH). With a random (arbitrary) evaluation function, move selection in this regime almost always picks whichever branch of the tree leads to the maximum possible number of terminal states. What this looks like in principle is unknown, but empirically we see that high-depth players have a strong tendency to seek mobility.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-08-11T09:36:42.257Z · LW(p) · GW(p)
This is one hell of a good comment! Strong-upvoted.
↑ comment by Viktor Rehnberg (viktor.rehnberg) · 2023-02-17T09:06:43.028Z · LW(p) · GW(p)
In case anyone else is looking for a source a good search term is probably the Beal Effect. From the original paper by Beal and Smith:
Once the effect is pointed out, it does not take long to arrive at the conclusion that it arises from a natural correlation between a high branching factor in the game tree and having a winning move available. In other words, mobility (in the sense of having many moves available) is associated with better positions
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-08-08T05:27:42.225Z · LW(p) · GW(p)
Nice!
In a couple places you say things that seem like they assume the probability distribution over utility functions is uniform. Is this right, or am I misinterpreting you? See e.g.
Choose any atom in the universe. Uniformly randomly select another atom in the universe. It's about 10^117 times more likely that these atoms are the same, than that a utility function incentivizes "dying" instead of flipping pixel 2 at t=1.
...
Optimal policies for u-AOH will tend to look like random twitching. For example, if you generate a u-AOH by uniformly randomly assigning each AOH utility from the unit interval [0,1], there's no predictable regularity to the optimal actions for this utility function.
If instead we used a kolmogorov prior, or a minimal-circuit-prior, or something else more realistic, then these results would go out the window?
Replies from: rohinmshah, TurnTrout↑ comment by Rohin Shah (rohinmshah) · 2021-08-08T07:58:51.582Z · LW(p) · GW(p)
Typically the theorems say things like "for every reward function there exists N other reward functions that <seek power, avoid dying, etc>"; the theorems aren't themselves talking about probability distributions.
The first example you give does only make sense given a uniform distribution, I believe.
In the second example, when Alex uses the phrase "tends to", it means something like "there are N times as many reward functions that <do the thing> as reward functions that <don't do the thing>". But yes, if you want to interpret this as a probabilistic statement, you would use a uniform distribution.
If instead we used a kolmogorov prior, or a minimal-circuit-prior, or something else more realistic, then these results would go out the window?
EDIT: This next paragraph is wrong; I'm leaving it in for the record. I still think it is likely that similar results would hold in practice though the case is not as strong as I thought (and the effect is probably also not as strong as I thought).
They would change quantitatively, but the upshot would probably be similar. For example, for the Kolmogorov prior, you could prove theorems like "for every reward function that <doesn't do the thing>, there are N reward functions that <do the thing> that each have at most a small constant more complexity" (since you can construct them by taking the original reward function and then apply the relevant permutation / move through the orbit, and that second step has constant K-complexity). Alex sketches out a similar argument in this post [LW · GW].
Replies from: ofer↑ comment by Ofer (ofer) · 2021-08-09T17:06:50.549Z · LW(p) · GW(p)
They would change quantitatively, but the upshot would probably be similar. For example, for the Kolmogorov prior, you could prove theorems like "for every reward function that <doesn't do the thing>, there are N reward functions that <do the thing> that each have at most a small constant more complexity" (since you can construct them by taking the original reward function and then apply the relevant permutation / move through the orbit, and that second step has constant K-complexity). Alex sketches out a similar argument in this post [LW · GW].
I don't see how this works. If you need bits to specify the permutation for that "second step", the probability of each of the N reward functions will be smaller than the original one's by a factor of . So you need to be smaller than which is impossible?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-08-10T07:18:27.156Z · LW(p) · GW(p)
So you need to be smaller than which is impossible?
You're right, in my previous comment it should be "at most a small constant more complexity + ", to specify the number of times that the permutation has to be applied.
I still think the upshot is similar; in this case it's "power-seeking is at best a little less probable than non-power-seeking, but you should really not expect that the bound is tight".
Replies from: ofer↑ comment by Ofer (ofer) · 2021-08-10T16:10:35.348Z · LW(p) · GW(p)
I still don't see how this works. The "small constant" here is actually the length of a program that needs to contain a representation of the entire MDP (because the program needs to simulate the MDP for each possible permutation). So it's not a constant; it's an unbounded integer.
Even if we restrict the discussion to a given very-simple-MDP, the program needs to contain way more than 100 bits (just to represent the MDP + the logic that checks whether a given permutation satisfies the relevant condition). So the probability of the POWER-seeking reward functions that are constructed here is smaller than of the probability of the non-POWER-seeking reward functions. [EDIT: I mean, the probability of the constructed reward functions may happen to be larger, but the proof sketch doesn't show that it is.]
(As an aside, the permutations that we're dealing with here are equal to their own inverse, so it's not useful to apply them multiple times.)
Replies from: rohinmshah, TurnTrout↑ comment by Rohin Shah (rohinmshah) · 2021-08-10T20:57:44.188Z · LW(p) · GW(p)
Yes, good point. I retract the original claim.
As an aside, the permutations that we're dealing with here are equal to their own inverse, so it's not useful to apply them multiple times.
(You're right, what you do here is you search for the kth permutation satisfying the theorem's requirements, where k is the specified number.)
↑ comment by TurnTrout · 2021-08-10T16:27:02.431Z · LW(p) · GW(p)
contain a representation of the entire MDP (because the program needs to simulate the MDP for each possible permutation)
We aren't talking about MDPs, we're talking about a broad class of environments which are represented via joint probability distributions over actions and observations. See post title.
it's an unbounded integer.
I don't follow.
the program needs to contain way more than 100 bits
See the arguments in the post Rohin linked for why this argument is gesturing at something useful even if takes some more bits.
But IMO the basic idea in this case is, you can construct reasonably simple utility functions like "utility 1 if history has the agent taking action at time step given action-observation history prefix , and 0 otherwise." This is reasonably short, and you can apply it for all actions and time steps.
Sure, the complexity will vary a little bit (probably later time steps will be more complex), but basically you can produce reasonably simple programs which make any sequence of actions optimal. And so I agree with Rohin that simplicity priors on u-AOH will quantitatively - but not qualitatively affect the conclusions for the generic u-AOH case. [EDIT: this reasoning is different from the one Rohin gave, TBC]
↑ comment by TurnTrout · 2021-08-09T17:06:57.739Z · LW(p) · GW(p)
The results are not centrally about the uniform distribution [LW · GW]. The uniform distribution result is more of a consequence of the (central) orbit result / scaling law for instrumental convergence. I gesture at the uniform distribution to highlight the extreme strength of the statistical incentives.
comment by drocta · 2021-08-08T23:44:44.741Z · LW(p) · GW(p)
Do I understand correctly that in general the elements of A, B, C, are achievable probability distributions over the set of n possible outcomes? (But that in the examples given with the deterministic environments, these are all standard basis vectors / one-hot vectors / deterministic distributions ?)
And, in the case where these outcomes are deterministic, and A and B are disjoint, and A is much larger than B, then given a utility function on the possible outcomes in A or B, a random permutation of this utility function will, with high probability, have the optimal (or a weakly optimal) outcome be in A?
(Specifically, if I haven't messed up, if asymptotically (as |B| goes to infinity) then the probability of there being something in A which is weakly better than anything in B goes to 1 , and if then the probability goes to at least , I think?
Coming from )
While I'd readily believe it, I don't really understand why this extends to the case where the elements of A and B aren't deterministic outcomes but distributions over outcomes. Maybe I need to review some of the prior posts.
Like, what if every element of A was a probability distribution with over 3 different observation-histories (each with probability 1/3) , and every element of B was a probability distribution over 2 different observation-histories (each with probability 1/2)? (e.g. if one changes pixel 1 at time 1, then in addition to the state of the pixel grid, one observes at random either a orange light or a purple light, while if one instead changes pixel 2 at time 1, in addition to the pixel grid state, one observes at random either a red, green, or blue light, in addition to the pixel grid) Then no permutation of the set of observations-histories would convert any element of A into an element of B, nor visa versa.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-08-09T17:12:29.261Z · LW(p) · GW(p)
Do I understand correctly that in general the elements of A, B, C, are achievable probability distributions over the set of n possible outcomes? (But that in the examples given with the deterministic environments, these are all standard basis vectors / one-hot vectors / deterministic distributions ?)
Yes.
Then no permutation of the set of observations-histories would convert any element of A into an element of B, nor visa versa.
Nice catch. In the stochastic case, you do need a permutation-enforced similarity, as you say (see definition 6.1: similarity of visit distribution sets in the paper). They won't apply for all A, B, because that would prove way too much.