A bicycle for your memory
post by sortega · 2022-03-30T21:41:07.046Z · LW · GW · 8 commentsContents
The Cyborg Memory Hierarchy Level 0. Working memory Level 1. Long-term memory Level 2. Personal notes and annotations Level 3. Selected sources and everything else Does it make sense a partial implementation of this Cyborg Memory Hierarchy? How Neuralink or some other technology will change this? Your personal cyborg memory hierarchy None 8 comments
Cross posted from sortega.github.io
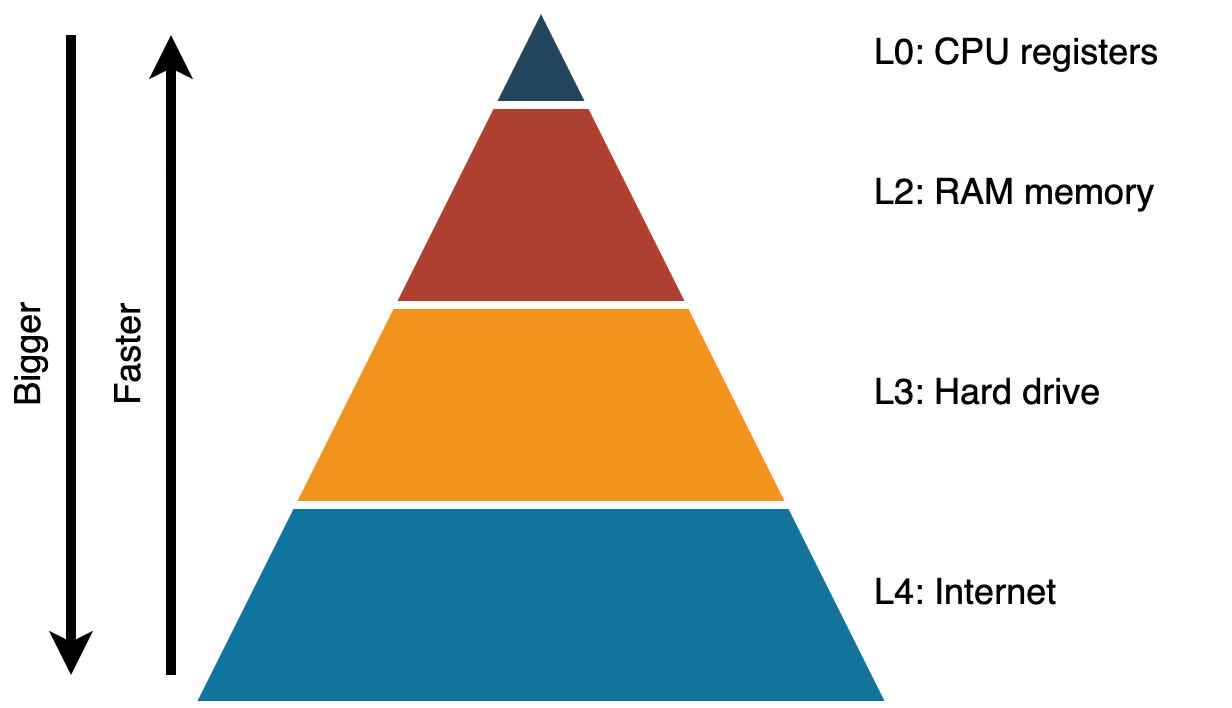
Computers have the need to store huge amounts of information and, at the same time, being able to access that memory at blazingly fast rates. This poses the problem of how to get a fast and large memory when hardware memories are either fast, like registers or L1 cache lines; or big, like hard-drives or solid state drives.
| Memory | Size | Speed | Comment |
| CPU register | A few bytes | One CPU cycle (200-300 picoseconds) | A register holds the data the CPU can operate on |
| RAM memory | A few gigabytes | 100 nanoseconds | Applications need their data to be here to be responsive |
| Hard drive | Many gigabytes | 150 microseconds | All your applications and data being kept locally have a copy here |
| Internet | Infinite (for all purposes) | 10-40 milliseconds | Technically other people's hard drives |
This is solved in computer architecture by the interplay of two ideas: a memory hierarchy and virtual memory. The memory hierarchy consists of a pyramid with the fastest and smallest memories on the tip and slower but bigger ones at the base. This arrangement allows you to have a complete copy of the information at the base, which is the biggest. Then, you can keep copies of the actively used information closer to the pyramid apex for better performance. Virtual memory is the illusion of having a single memory space which is the result of the collaboration of specific hardware (MMU, CPU features) with the operative system to transparently move data across the levels of the pyramid. The result is that, for most purposes and most of the time, programs running in your computer get to use a single memory space that feels as big as the base of the pyramid and almost as fast as its top.
Apart from computers, humans are rich information processors[1] and memory plays a paramount role in what it means to be a human. On one hand it's an important element of personal identity. Imagine a movie villain using technology or black magic[2] to swap the memories of two twin brothers. In some philosophical sense we are what we remember, and we will have a hard time deciding who is who in this contrived situation.
On the other hand, memories are needed for our minds to work because without them, we will have only the raw input of our senses and no other concept or idea to work with. The extent to which we can understand the world, communicate with others and act depends on using those mental building blocks or chunks.
Another aspect of being human not so directly related to information processing is tool making and tool use. Thanks to these, we have come a long way since we harnessed the power of fire and stone. Steve Jobs eloquently explained in this talk how humans will lose in almost all categories[3] of an Olympic Games in which other animals were allowed to take part. We are not the fastest, we cannot travel the furthest, nor in the most efficient way. However, any cyclist is more efficient in energy per distance than a Condor, the most efficient animal. Then, he declared computers to be like a bicycle for the mind. Back then, personal computing was being rolled out, and we were oblivious to the directions these new machines would cybernetically extend us.
The Cyborg Memory Hierarchy
At this point we have all the ingredients to define what I call the cyborg memory hierarchy: extending human capabilities with technology (cyborg) so we can enhance in-brain memory and extend it with external information (memory hierarchy).
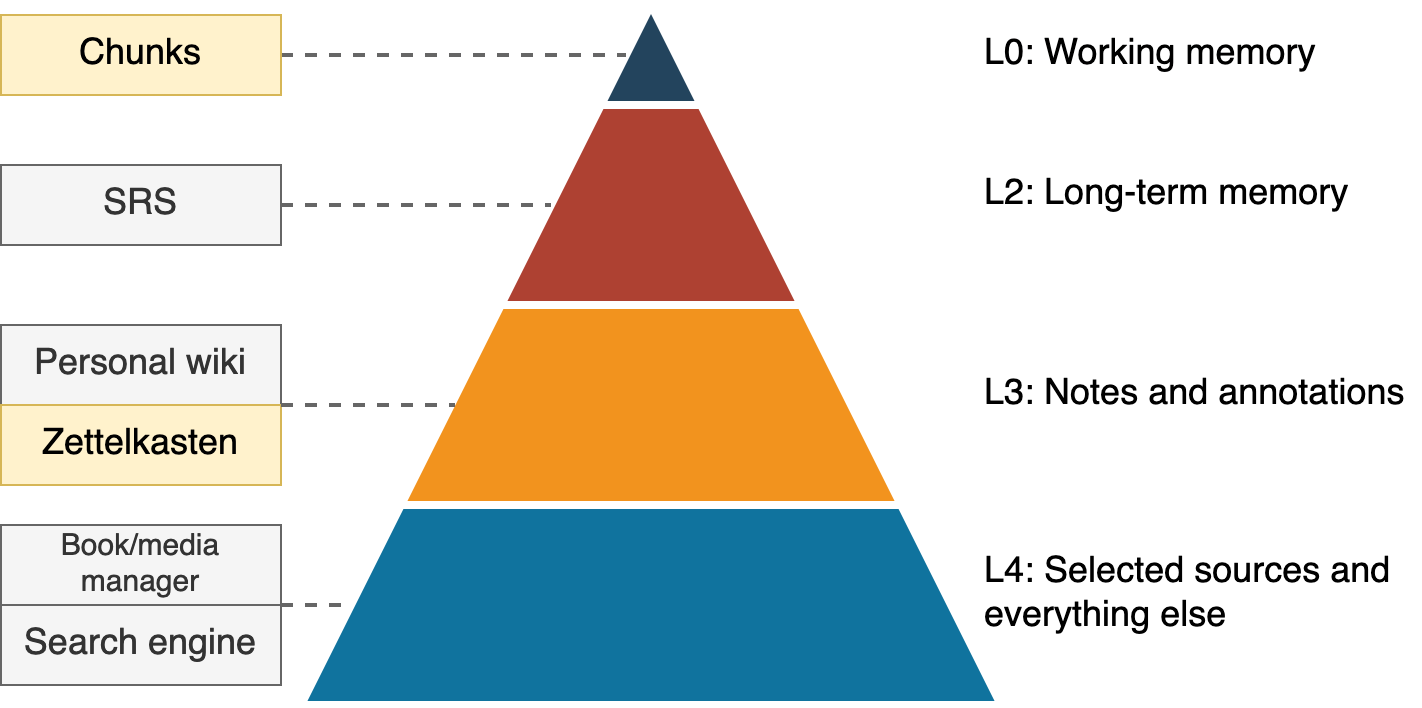
Level 0. Working memory
Our working memory is composed of a phonological loop, where you can keep repeating a phone number while you search for pen and paper; the visuo-spatial sketchpad, where you can mentally manipulate shapes; and some very limited number of slots that can hold ideas, or chunks, for manipulation. Early George A. Miller work estimated that the typical mind was able to hold 5 ± 2 chunks[4], but more recent work suggests we are limited to about 4 chunks.
I doubt we will cybernetically extend our working memory until brain-computer interfaces become a reality, but I have some good news in the methodology front. The reason Miller got initially confused with the amount of mental slots is that we can do more with less by having more elaborate and high level chunks. For example, I might be able to work in my mind with only three digits (e.g. 7, 1, 4) but if they are dates, then I can hold many more digits (e.g. 1492, 2001, 1991).
In fact, you can see expertise in any field as the slow and effortful learning of ever higher-level chunks and mental models (read Peak by Anders Ericsson). My advice: hunt all the important concepts in your field of interest and commit them to long-term memory (see next section).
Level 1. Long-term memory
These are memories that we can use fluently, regardless of our smartphone batteries being dead. These are critical for anything we do with fluency like speaking a language, being expert at anything, or being creative, which implies recombination of ideas that should be at the same time in our minds.
Some of these memories are declarative and can be expressed as answers to explicit questions. “What’s the capital of Georgia? Tbilisi or Atlanta”. We can extend our declarative memories by reading and studying for which there is a wealth of technologies and channels but the main enemy to beat is how fast those new memories fade away from us.
We know thanks to Hermann Ebbinghaus and his tedious self-experimentation with memorizing long sequences of nonsense words that facts decay exponentially in our minds unless reviewed and inter-related to other memories. His work was published in the XIX century, but no specific software was created to optimize when to review which piece of knowledge until Piotr Wozniak wrote the first spaced repetition software (SRS) in 1987. The underlying idea of this kind of software is that you encode what you have already understood and learned and want to keep in you memory as flash cards (short questions and answers) and the system keeps track of when to do reviews. Due to Ebbinghaus forgetting curve, the interval between reviews grows exponentially, so you see the typical card again after months or years. This means that you can keep many tens of thousands of cards in your level-zero memory at the cost of a few minutes of daily review.
For a nice explanation of how to implement this with Anki, one of the most popular SRS nowadays, I recommend reading Augmenting Long-term Memory by Michael Nielsen. He is also experimenting with articles that embed an SRS like this one about quantum computing.
If you want to read more about good practices with SRS, Wozniak’s Twenty Rules of Formulating Knowledge is the most authoritative source and Soren Bjornstad’s Rules for Designing Precise Anki Cards is a great complement.
Paraphrasing Nielsen, SRS makes declarative memory a choice. If we ever think that keeping a fact or a concept available in our mind is more valuable than 5 minutes of our time[5] we can do it[6].
What about non-declarative memory? Muscle memory cannot be reduced to declarative facts, no one is able to learn how to bike by reading How to ride a bike. However, some creative thinking can help us to bridge the gap in some cases. For example, I use Anki to learn application shortcuts declaratively and then, as opportunity to use them in the day to day happens I build the muscle memory.
Level 2. Personal notes and annotations
When we process information we tend to take notes or perform annotations in the medium itself, so we can come back to them without needing long-term memorization. Note that technically, pen and notebook are already cybernetic extensions for this purpose.
These notes are indeed very useful for us to solidify our understanding and organization of ideas, specially if we do a write-up like a blog post. The mere act of writing, even at book marginalia, also improves our initial memorization.
However, the value of these notes is limited unless they are connected and easily searchable. To get that extra value we need to up both our methodological and technological games.
The quintessential technology to fill this gap is the personal wiki in which you can seamlessly write notes, keep them inter-linked and securely access this second brain from all your devices. There is an inexhaustible offer of wikis out there (open source and SaaS). My recommendation is to pick one and try to use it unless blocked by a showstopper. A very common failure mode is to keep tuning your wiki configuration without really using it.
I personally use TiddlyWiki[7] with the amazing Soren’s TiddlyRemember plugin to define SRS cards directly from within my wiki notes. When reviewing them in Anki I get a valuable link to their original context.
On the methodology front, I recommend the philosophy of Zettelkasten that was introduced by Niklas Luhmann, a very prolific German social scientist that implemented the logical equivalent to a wiki for his research notes using Victorian technology. Luhmann was carefully digesting other academics books and articles into chunks or ideas written in index cards that were linked, tagged and annotated to form a web of knowledge that he traversed in a myriad ways, leading to serendipitous connections bringing a deeper understanding—and many publications! By the way, zettel is German for note while kasten means box.

Soren Bjornstad adapted TiddlyWiki for Zettelkasten and he extensively explains the result in this video. The template is available for anyone to use.
Level 3. Selected sources and everything else
At this level, we have all the source material—books[8], articles—we collected and totally or partially read and quite likely you took notes and made flashcards about. At the mid-level of technology, you can picture cozy bookshelves at home but to give you more value, you need to get it organized and searchable.
For this purpose I use Calibre, which was presented to me as the iTunes of ebooks. Any other ebook organizer will do as long as you have a nice desktop search engine, so you can easily get back to the tidbits of your books that are neither in you head nor your notes. The spotlight search of Mac OS X is a good starting point for this.
Apart from these selected sources, we have ad-hoc information needs which we satisfy by using general search engines. Google, Bing, DuckDuckGo… choose your poison but once chosen, learn to use it properly (1, 2).
Does it make sense a partial implementation of this Cyborg Memory Hierarchy?
I think that any missing piece is problematic.
If you have SRS without a personal wiki you will tend to either create flashcards for things that are not really meant for that, and you might burn out; or otherwise, you might let go many valuable things.
If you have a wiki without SRS you won’t be fluid enough to take advantage of many things. For example, you can have great coding design patterns documented in your notes and never remember to apply them when the right conditions apply.
If you only have a search engine, you might not even know what to search about to solve a problem and your thinking will tend to be more shallow (related book: The Shallows: What the Internet is Doing to Out Brains).
How Neuralink or some other technology will change this?
I have no idea. I can only speculate that tighter integration with our brains can collapse some levels or open new ones that we do not even understand today. Maybe the Neuralink-enabled Anki feels exactly like Neo’s learning Kung Fu in The Matrix.
Your personal cyborg memory hierarchy
If you have some concept or implementation similar to the cyborg memory hierarchy or this post has inspired you to implement one for yourself I am very interested in knowing about your experiences. Please write a comment about it!
- ^
This used to be a false dichotomy as computer was a job title for humans! Until the invention of the modern electronic computer, a computer was a person—most likely a woman—skilled enough at mathematical computation to, for example, slowly tabulate a logarithm table.
- ^
"Any sufficiently advanced technology is indistinguishable from magic" (Arthur C. Clarke)
- ^
One exception is that we can keep walking and running sustainably way longer than other animals. When we were hunter-gatherers persistence hunting—hunting by exhausting your prey—was a thing. Another exception is our eye-to-hand coordination for throwing rocks and spears. I suppose people less apt at these things were wiped out from the gene pool by Mother Evolution.
- ^
This is the origin of the magic number 7 (5 + 2) that is used to prescribe no more than 7 levels or class inheritance, no more than 7 attributes per class, no more than...
- ^
Gwern estimates in about 2 minutes the total time that it takes remember a fact foreverish with Anki. I am doubling that estimate to compensate form the rest of us not being as bright as him.
- ^
What a great pity not having had SRS in my tool belt during my university years. I would now remember more of the original content, and I would not have needed re-learning it years after my graduation.
- ^
One of the strong points of TiddlyWiki is how you can deeply customize it for your purposes without leaving its markup language and dropping to JavaScript. Its plugin mechanism is also based in the same customizations that a regular user can afford and that means the small community around it has published a huge amount of plugins that you can mix and match.
- ^
A bookshelf was considered disruptive technology in times of Plato and Plato considered books will make people forgetful. We can forgive him because there was no SRS back them to compensate for this effect.
8 comments
Comments sorted by top scores.
comment by Vaniver · 2022-03-30T21:43:24.080Z · LW(p) · GW(p)
See also past discussion of Zettelkasten [LW · GW] on LW.
comment by JenniferRM · 2022-03-31T19:04:09.533Z · LW(p) · GW(p)
This claim seems super super important in terms of fundamental modeling of fundamental cognitive constraints:
Early George A. Miller work estimated that the typical mind was able to hold 5 ± 2 chunks, but more recent work suggests we are limited at about 4 chunks.
Why do you think this is true? (Here I cross my fingers and hope for a long explanation, with many links, and discussion of replication failures or a lack thereof <3)
Replies from: sortega↑ comment by sortega · 2022-04-11T06:49:53.337Z · LW(p) · GW(p)
Miller work was insightful on discarding bits of information in favor of chunks but it was written in a very informal tone. That stymied further research for a long time but when restarted, researchers realized that you can get very rich set of features but about a small number of chunks. See this summary of the story.
comment by TLW · 2022-03-31T02:40:18.036Z · LW(p) · GW(p)
There are (at least) two main issues with offloading things from memory. You talked about one of them; I think the other is also worth mentioning.
As you mention, speed/ease of lookup is an issue.
The other issue - and personally I find this to be more of a limiting factor - is missing insights. Cases where you could have looked it up had you known, but you didn't know enough to know that you should have looked that particular thing up in the first place. (This is hard to provide an example for due to hindsight bias.)
Indexing can mitigate this to an extent, but is nowhere near a full solution.
Any ideas?
Replies from: nim, lise, sortega↑ comment by nim · 2022-03-31T17:14:13.978Z · LW(p) · GW(p)
Insight is hard to talk about, even harder to sound sane and logical while discussing. We could perhaps model "having an insight" as 2 stages: Asking an interesting new question, and producing a useful answer to that question. These 2 steps can often be at odds with each other: Improving the skill of making your answers more useful risks falling into habits of thought where you don't ask certain possibly-interesting questions because you erroneously assume that you already know their whole answers. Improving the skill of asking wild questions risks forming too strong a habit of ignoring the kind of common sense that rules out questions with "that shouldn't work", and yet is essential to formulating a useful answer once an interesting question is reached.
The benefits of erring toward the "produce useful answers" skillset are obvious, as are the drawbacks of losing touch with reality if one fails to develop it. I think it's easy to underestimate the benefits of learning the skills which one can use to temporarily boost the "ask interesting questions" side, though. Sadly most of the teachable skills that I'm aware of for briefly letting "ask interesting questions" override "produce useful answers" come packaged in several layers of woo. Those trappings make them more palatable to many people, but less palatable to the sorts of thinkers I typically encounter around here. The lowest-woo technique in that category which comes to mind is oblique strategies.
↑ comment by lise · 2022-03-31T12:52:00.730Z · LW(p) · GW(p)
I don't know whether this is exactly what you meant by "missing insights", but I've noticed that I use search way less than I should, in my own notes & resources as well as in web search engines.
In the case of my own notes, adding more SRS cards usually fixes this: if I've been actively learning cards on some concept, I often do remember that I have resources related to that concept I can check when it comes up.
In the case of the web... well, this is an ongoing process. There have been whole subdomains of my life where it hadn't occurred to me that those are also things you can simply look up if you want. I've been trying to notice the moment where I realize I don't know something, in order to trigger the "so I should Google it" action, but it takes time.
↑ comment by sortega · 2022-03-31T07:05:50.403Z · LW(p) · GW(p)
Usually, the central set of ideas or concepts of a field or the main points of insights of a book are a small subset of all the information out there. I think it's realistic to target those to be memorized with the benefit that it's easier to go from those to the rest of details either in your notes or searching.
For that reason I have a specialized note type in Anki just for definitions.