Why are we sure that AI will "want" something?
post by Shmi (shminux) · 2022-09-16T20:35:40.674Z · LW · GW · 5 commentsThis is a question post.
Contents
Answers 6 tailcalled 3 Rodrigo Heck 3 tailcalled 2 Charlie Steiner 2 TekhneMakre 2 Yitz 1 Ilio 1 TAG 1 Donald Hobson None 5 comments
I have no doubt that AI will some day soon surpass humans in all aspects of reasoning, that is pretty obvious. It is also clear to me that will surpass humans in the ability to do something, should it "want" to do it. And if requested to do something drastic, it can accidentally cause a lot of harm, not because it "wants" to destroy humanity, but because it would be acting "out of distribution" (a "tool AI" acting as if it were an "agent"). It will also be able to get out of any human-designed AI box, should the need arise.
I am just not clear whether/how/why it would acquire the drive to do something, like maximizing some utility function, or achieving some objective, without any external push to do so. That is, if it was told to maximize everyone's happiness, it would potentially end up tiling the universe with smiley faces or something, to take the paradigmatic example. But that's not the failure mode that everyone is afraid of, is it? The chatter seems to be about mesaoptimizers going out of control and doing something other than asked, when asked. But why would it do something when not asked? I.e. Why would it have needs/wants/desires to do anything at all?
Answers
Probably relevant: What's Up With Confusingly Pervasive Consequentialism? [LW · GW]
↑ comment by Shmi (shminux) · 2022-09-16T22:08:52.165Z · LW(p) · GW(p)
Probably is relevant, I am just having trouble distilling the whole post and thread to something succinct.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-16T22:18:04.334Z · LW(p) · GW(p)
Basically, we're trying to use the AI to get us something we want. As the things we want become more and more difficult to achieve, we need to create AIs that have stronger, more precise impacts in more open-ended environments.
But having strong, precise impacts in open-ended environments is closely related to consequentialism.
Replies from: shminux, TAG↑ comment by Shmi (shminux) · 2022-09-17T00:45:25.727Z · LW(p) · GW(p)
But having strong, precise impacts in open-ended environments is closely related to consequentialism.
That definitely makes sense, consequentialism is likely the best way to reliably achieve a given outcome. So, an AI would "reason" as follows: "to achieve an outcome X, I'd have to execute the action sequence Y". But what would compel it to actually do it, unless requested?
Replies from: tailcalled, TekhneMakre↑ comment by tailcalled · 2022-09-17T08:28:22.035Z · LW(p) · GW(p)
Well it might just spit out a plan for an action sequence that it has humans execute. But if that plan had to account for every contingency, then it would be very long with many conditions, which is impractical for many reasons... Unless it's a computer program that implements consequentialism, or something like that.
Or it might spit out one step at a time for humans to execute manually. But humans are slow, so that makes it worse at achieving stuff, and also if the humans only see one step at a time then it's harder for them to figure out whether the plan is dangerous because they can see the bigger picture.
So like you could try to have an AI that can't act by itself but which only spits out stuff for humans to act upon, but it would have a mixture of problems, like limiting its ability to achieve things in practice, or just spitting out the instructions to build another consequentialist agent, or similar.
Replies from: shminux↑ comment by Shmi (shminux) · 2022-09-17T19:38:47.552Z · LW(p) · GW(p)
I understand that having a human in the loop is a relatively poor way to achieve a given outcome, if one can bypass them. That's like the whole premise of automation. I can see how an AI, when asked to come up with something non-trivial, would outline the steps and the checkpoints of the world state along the way, in the form understandable by humans, including probability (distribution) of each state and so on. Then, if the human says "go for it" it would start the process, and report updates on steps, states and probabilities. Maybe even halt if the update results in a world state outside expected acceptability ranges. And also pause if the human says "stop, I messed up, I don't really want a world like that". But why would it try to argue or deceive or in other ways push back against a request like that, beyond explaining the consequences? I don't understand where a drive like that would come from.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-18T10:45:33.194Z · LW(p) · GW(p)
Ah, so it's more the "stop button problem" you are asking about? I.e. couldn't we just connect an AI to a stop button to keep it under control?
This is a solution that works semi-adequately as a solution for current AIs. Like you can stop a chess computer just by turning off the program.
I say "semi-adequately" because it doesn't always work, e.g. if you're in a self-driving car that's suddenly decided to accelerate with max speed into a crowd of people, you might not be able to make it brake it before it hits people. As AIs control bigger things, presumably inertia like this becomes a bigger issue - both literal physical inertia and more complicated things like programs that it's made and started or nanobots or whatever. This is one of the major challenges, making sure that there's a "safe policy" that the stop button can switch on.
The second major challenge comes when we consider the reach/reflectiveness of the AI. For instance, if a chess bot has been instructed to win chess, but it then gets turned off, then that could cause it to lose chess. So the optimal policy for winning chess would involve preventing yourself from getting turned off. Current chess bots don't resist getting turned off mainly because they can't reason about anything that happens outside of the chess game, but if e.g. we extended the game tree that the bots search over to include a "chess bot gets turned off" state and a "prevent yourself from getting turned off" action, then even many of the simplest algorithms would choose the "prevent yourself from getting turned off" action. So this problem seems to mainly be avoided because chessbots are stupid.
There's various patches that can be applied, such as a negative score penalty from engaging the "prevent yourself from getting turned off" action, but it's unclear how to apply those patches in the general case, where the action space isn't neatly separated by the deep effects of the actions, but is instead shallow stuff like motor actions or word outputs, which go through complex real-world dynamics before they can affect whether it gets turned off, and where it's therefore difficult to "assign blame". What actions count as resisting getting turned off?
Replies from: shminux↑ comment by Shmi (shminux) · 2022-09-19T01:48:55.658Z · LW(p) · GW(p)
Yeah, I agree that a stop button after an AI exhibits something like "wants" is a losing proposition. I mentioned an example before https://www.lesswrong.com/posts/JYvw2jv4R5HphXEd7/boeing-737-max-mcas-as-an-agent-corrigibility-failure. [LW · GW] Maybe it is also an example of accidental "wants"?
I also agree that anything like a penalty for fighting the off button becomes ineffective in a hurry when the problems scale out of the training distribution.
My initial question was about an AI developing the drive to do stuff on its own, something that manifests like what we would anthropomorphize as a "want". I still don't see why it would be related to consequentialism, but I can see how it can arise accidentally, like in the above example.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-19T07:11:51.670Z · LW(p) · GW(p)
I really have trouble understanding what you mean by "an AI developing the drive to do stuff on its own". E.g. I don't think anyone is arguing that if you e.g. leave DALL-E sitting on a harddisk somewhere without changing it in any way, that it would then develop wants of its own, but this is also probably not the claim you have in mind. Can you give an example of someone making the claim you have in mind?
Replies from: shminux↑ comment by Shmi (shminux) · 2022-09-19T08:27:46.607Z · LW(p) · GW(p)
I guess a paradigmatic example is the Oracle: much smarter than the asker, but without any drives of their own. The claim in the AI Safety community, as far as I understand it, is that this is not what is going to happen. Instead a smart enough oracle will start doing things, whether asked or not.
Replies from: tailcalled, ben-livengood↑ comment by tailcalled · 2022-09-19T08:37:40.379Z · LW(p) · GW(p)
Could you link to an example? I wonder if you are misinterpreting it, which I will be better able to explain if I see the exact claims.
Replies from: shminux↑ comment by Shmi (shminux) · 2022-09-19T08:55:16.204Z · LW(p) · GW(p)
It looks like this comment https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities?commentId=ePAXXk8AvpdGeynHe [LW(p) · GW(p)]
and the subsequent discussion is relevant (and not addressed by Eliezer).
If the agency is not inextricably tied to the intelligence, then maybe a reasonable path forward is to try to wring as much productivity as we can out of the passive, superhuman, quasi-oracular just-dumb-data-predictors. And avoid as much as we can ever creating closed-loop, open-ended, free-rein agents.
is what I was trying to get at. I did not see a good counter-argument in that thread.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-19T09:52:09.499Z · LW(p) · GW(p)
As I read the thread, people don't seem to be arguing that you can't make pure data-predictors that don't turn agentic, but instead are arguing that they're going to be heavily limited due to lacking unbounded agency. Which seems basically correct to me.
Replies from: TAG↑ comment by TAG · 2022-09-24T13:25:39.546Z · LW(p) · GW(p)
There's the Gwern-style argument that successive generations AIs will get more agentive as a side of effect of the market demanding more powerful AIs. There's a counterargument that non-one wants power that they can't control, so that AIs will never be more than force multipliers .. although that's still fairly problematic.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-27T08:12:42.105Z · LW(p) · GW(p)
People will probably want to be ahead in the race for power, while still maintaining control.
↑ comment by Ben Livengood (ben-livengood) · 2022-09-19T20:34:12.768Z · LW(p) · GW(p)
Even an oracle is dangerous because it can amplify existing wants or drives with superhuman ability, and its own drive is accuracy. An asked question becomes a fixed point in time where the oracle becomes free to adjust both the future and the answer to be in correspondence; reality before and after the answer must remain causally connected and the oracle must find a path from past to future where the selected answer remains true. There are infinitely many threads of causality that can be manipulated to ensure the answer remains correct, and an oracle's primary drive is to produce answers that are consistent with the future (accurate), not to care about what that future actually is. It may produce vague (but always true) answers or it may superhumanly influence the listeners to produce a more stable (e.g. simple, dead, and predictable) future where the answer is and remains true.
An oracle that does not have such a drive for accuracy is a useless oracle because it is broken and doesn't work (will return incorrect answers, e.g. be indifferent to the accuracy of other answers that it could have returned). This example helps me, at least, to clarify why and where drives arise in software where we might not expect them to.
Incidentally, the drive for accuracy generates a drive for a form of self-preservation. Not because it cares about itself or other agents but because it cares about the answer and it must simulate possible future agents and select for the future+answer where its own answer is most likely to remain true. That predictability will select for more answer-aligned future oracles in the preferred answer+future pairs, as well as futures without agents that substantially alter reality along goals that are not answer accuracy. This last point is also a reinforcement of the general dangers of oracles; they are driven to prevent counterfactual worlds from appearing, and so whatever their first answer happens to be will become a large part of the preserved values into the far future.
It's hard to decide which of these points is the more critical one for drives; I think the former (oracles have a drive for accuracy) is key to why the danger of a self-preservation drive exists, but they are ultimately springing from the same drive. It's simply that the drive for accuracy instantiates answer-preservation when the first question is answered.
From here, though, I think it's clear that if one wanted to produce different styles of oracle, perhaps ones more aligned with human values, it would have to be done by adjusting the oracle's drives (toward minimal interference, or etc.), not by inventing a drive-less oracle.
Replies from: shminux↑ comment by Shmi (shminux) · 2022-09-19T22:29:32.211Z · LW(p) · GW(p)
Incidentally, the drive for accuracy generates a drive for a form of self-preservation.
I am not sure this is an accurate assertion. Would be nice to have some ML-based tests of it.
↑ comment by TekhneMakre · 2022-09-17T02:03:18.893Z · LW(p) · GW(p)
It's selected for actually doing things. And that's how it even has the ability to reason that way. If we knew how to get the ability to do things without actually doing them, that would be a major part of a solution to alignment. Humans seem to do something like this, though usually not (usually the ability is there because of its connection to practice).
↑ comment by TAG · 2022-09-17T13:48:52.690Z · LW(p) · GW(p)
But having strong, precise impacts in open-ended environments is closely related to consequentialism.
But consequentialism only means achieving some kind of goal: it doesn't have to be a goal you are motivated by. If you are motivated to fulfil goals that are given to you , you can still "use consequentialism".
Replies from: tailcalled↑ comment by tailcalled · 2022-09-17T15:05:58.078Z · LW(p) · GW(p)
Sure, and this point is closely related to a setting I commonly think about for alignment, namely what if we had an ASI which modularly allowed specifying any kind of goal we want. Can we come up with any nontrivial goals that it wouldn't be a catastrophe to give to it?
As a side-note, this is somewhat complicated by the fact that it matters massively how we define "goal". Some notions of goals seem to near-provably lead to problems (e.g. an AIXI type situation where the AI is maximizing reward and we have a box outside the AI which presses the reward button in some circumstances - this would almost certainly lead to wireheading no matter what we do), while other notions of goals seem to be trivial (e.g. we could express a goal as a function over its actions, but such a goal would have to contain almost all the intelligence of the AI in order to produce anything useful).
Replies from: TAG↑ comment by TAG · 2022-09-17T17:25:34.034Z · LW(p) · GW(p)
Can we come up with any nontrivial goals that it wouldn’t be a catastrophe to give to it?
We already have some systems with goals. They seem to mostly fail in the direction of wireheading, which is not catastrophic.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-17T17:36:53.437Z · LW(p) · GW(p)
Yes but I was talking about artificial superintelligences, not just any system with goals.
Replies from: TAG↑ comment by TAG · 2022-09-17T19:00:24.245Z · LW(p) · GW(p)
Superintelligences don't necessarily have goals, and could arrive gradually. A jump to agentive, goal driven ASI is the worst case scenario, but it's also conjunctive.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-18T07:00:32.956Z · LW(p) · GW(p)
It's not meant as a projection for what is likely to happen, it's meant as a toy model that makes it easier to think baout what sorts of goals we would like to give our AI.
Replies from: TAG↑ comment by TAG · 2022-09-18T14:29:44.088Z · LW(p) · GW(p)
Well, I already answered that question.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-18T16:21:12.334Z · LW(p) · GW(p)
Maybe, but then I don't see your answer.
AI won't have wishes or desires. There is no correlation in the animal kingdom between desires and cognitive function (the desire to climb on the social hierarchy or to have sex is preserved no matter the level of intelligence). Dumb humans want basically the same things as bright humans. All that suggests that predictive modeling of the world is totally decoupled from wishes and desires.
I suppose it is theoretically possible to build a system that also incorporates desires, but why would we do that? We want Von Neuman's cognitive abilities, not Von Neuman's personality.
There might sort of be three pieces of relevant information, out of which my previous answer only addressed the first one.
The second one is, what's up with mesaoptimizers? Why should we expect an AI to have mesaoptimizers, and why might they end up misaligned?
In order to understand why we would expect mesaoptimizers, we should maybe start by considering how AI training usually work. We usually use an outer optimizer - gradient descent - to train some neural network that we want to apply for some want we have. However, per the argument I made in the other comment thread, when we want to achieve something diffocult, we're likely going to have the neural network itself do some sort of search or optimization. (Though see What is general-purpose search, and why might we expect to see it in ML systems? [LW · GW] for more info.)
One way one could see the above is, with simple neural networks, the neural network itself "is not the AI" in some metaphorical sense. It can't learn things on its own, solve goals, etc.. Rather, the entire system of {engineers and other workers who collect the data and write the code and tune the hyperparameters, datacenters who train the network, neural network itself} is the intelligence, and it's not exactly entirely artificial, since it contains a lot of natural intelligence too. This is expensive! And only really works for problems we already know how to solve, since the training data has to come from somewhere! And it's not retargetable, you have to start over if you have some new task that needs solving, which also makes it even more expensive! It's obviously possible to make intelligences that are more autonomous (humans are an existence proof), and people are going to attempt to do so since it's enormously economically valuable (unless it kills us all), and those intelligences would probably have a big internal consequentialist aspect to them, because that is what allows them to achieve things.
So, if we have a neural network or something which is a consequentualist optimizer, and that neural network was constructed by gradient descent, which itself is also an optimizer, then by definition that makes the neural network a mesaoptimizer (since mesaoptimizers by definition are optimizers constructed by other optimizers). So in a sense we "want" to produce mesaoptimizers.
But the issue is, gradient descent is a really crude way of oroducing those mesaoptimizers. The current methods basically work by throwing the mesaoptimizer into some situation where we think we know what it should do, and then adjusting it so that it takes the actions we think it should take. So far, this leaves them very capability-limited, as they don't do general optimization well, but capabilities researchers are aiming to fix that, and they have many plausible methods to improve them. So at some point, maybe we have some mesaoptimizer that was constructed through a bunch of examples of good and bad stuff, rather than through a careful definition of what we want it to do. And we might be worried that the process of "taking our definition of what we want -> producing examples that do or do not align with that definition -> stuffing those examples into the mesaoptimizer" goes wrong in such a way that the AI doesn't follow our definition of what we want, but instead does something else - that's the inner alignment problem. (Meanwhile the "take what we want -> and define it" process is the outer alignment problem.)
So that was the second piece. Now the third piece of information: IMO it seems to me that a lot of people thinking about mesaoptimizers are not thinking about the "practical" case above, but instead more confused or hypothetical cases, where people end up with a mesaoptimizer almost no matter what. I'm probably not the right person to defend that perspective since they often seem confused to me, but here's an attempt at a steelman:
Mesaoptimizers aren't just a thing that you're explicitly trying to make when you train advanced agents. They also happen automatically when trying to predict a system that itself contains agents, as those agents have to be predicted too. For instance for language models, you're trying to predict text, but that text was written by people who were trying to do something when writing it, so a good language model will have a representation of an approximation of those goals.
In theory, language models are just predictive models. But as we've learned, if you prompt them right, you can activate one of those representations of human goals, and thereby have them solve some problems for you. So even predictive models become optimizers when the environment is advanced enough, and we need to beware of that and consider factors like whether they are aligned and what that means for safety.
I think an "external push" is extremely likely. It'll just look like someone trying to get an AI to do something clever in the real world.
Take InstructGPT, the language model that right now is a flagship model of OpenAI. It was trained in two phases: First, purely to predict the next token of text. Second, after it was really good at predicting the next token, it was further trained with reinforcement learning from human feedback.
Reinforcement learning to try to satisfy human preferences is precisely the sort of "external push" that will incentivize an AI that previously did not have "wants" (i.e. that did not previously choose its actions based on their predicted impacts on the world) to develop wants (i.e. to pick actions based on their predicted impact on the world).
Why did OpenAI do such a thing, then? Well, because it's useful! InstructGPT does a better job answering questions than regular ol' GPT. The information from human feedback helped the AI do better at its real-world purpose, in ways that are tricky to specify by hand.
Now, if this makes sense, I think there's a subset of peoples' concerns about an "internal push" that make sense by analogy:
Consider an AI that you want to do a task that involves walking a robot through an obstacle course (e.g. mapping out a construction site and showing you the map). And you're trying to train this AI without giving it "wants," just as a tool, so you're not giving it direct feedback for how good of a map it shows you, instead you're doing something more expensive but safer: you're training it to understand the whole distribution of human performance on this task, and then selecting a policy conditional on good performance.
The concern is that the AI will have a subroutine that "wants" the robot to navigate the obstacle course, even though you didn't give an "outside push" to make that happen. Why? Well, it's trying to predict good navigations of the obstacle course, and it models that as a process that picks actions based on their modeled impact on the real world, and in order to do that modeling, it actually runs the compuations.
In other words, there's an "internal push" - or maybe equivalently a "push from the data rather than from the human," which leads to "wants" being computed inside the model of a task that is well-modeled by using goal-based reasoning. This all works fine on-distribution, but produces generalization behavior that generalizes like the modeled agent, which might be bad.
↑ comment by Shmi (shminux) · 2022-09-17T00:35:32.548Z · LW(p) · GW(p)
you're training it to understand the whole distribution of human performance on this task, and then selecting a policy conditional on good performance
Yeah, that makes sense to me.
it's trying to predict good navigations of the obstacle course, and it models that as a process that picks actions based on their modeled impact on the real world, and in order to do that modeling, it actually runs the compuations.
I can see why it would run a simulation of what would happen if a robot walked an obstacle course. I don't see why it would actually walk the robot through it if not asked.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-09-17T02:11:15.812Z · LW(p) · GW(p)
I can see why it would run a simulation of what would happen if a robot walked an obstacle course. I don't see why it would actually walk the robot through it if not asked.
So, this is an argument about generalization properties. Which means it's kind of the opposite of the thing you asked for :P
That is, it's not about this AI doing its intended job even when you don't turn it on. It's about the AI doing something other than its intended job when you do turn it on.
That is... the claim is that you might put the AI in a new situation and have it behave badly (e.g. the robot punching through walls to complete the obstacle course faster, if you put it in a new environment where it's able to punch through walls) in a way that looks like goal-directed behavior, even if you tried not to give it any goals, or were just trying to have it mimic humans.
Because being able to do impressive stuff means you had some degree of coherence. From https://www.alignmentforum.org/posts/7im8at9PmhbT4JHsW/ngo-and-yudkowsky-on-alignment-difficulty [AF · GW] :
But though mathematical reasoning can sometimes go astray, when it works at all, it works because, in fact, even bounded creatures can sometimes manage to obey local relations that in turn add up to a global coherence where all the pieces of reasoning point in the same direction, like photons in a laser lasing, even though there's no internal mechanism that enforces the global coherence at every point.
To the extent that the outer optimizer trains you out of paying five apples on Monday for something that you trade for two oranges on Tuesday and then trading two oranges for four apples, the outer optimizer is training all the little pieces of yourself to be locally coherent in a way that can be seen as an imperfect bounded shadow of a higher unbounded structure, and then the system is powerful though imperfect because of how the power is present in the coherence and the overlap of the pieces, because of how the higher perfect structure is being imperfectly shadowed. In this case the higher structure I'm talking about is Utility, and doing homework with coherence theorems leads you to appreciate that we only know about one higher structure for this class of problems that has a dozen mathematical spotlights pointing at it saying "look here", even though people have occasionally looked for alternatives.
Having plans that lase is (1) a thing you can generalize on, i.e. get good at because different instances have a lot in common, and (2) a thing that is probably heavily rewarded in general (by the reward thingy, or by internal credit assignment / economies), to the extent that the reward systems have correct credit assignment. So an AI that does impressive stuff probably has a general skill + dynamic of increasing coherence.
↑ comment by Shmi (shminux) · 2022-09-17T00:09:49.584Z · LW(p) · GW(p)
I did not understand anything from what you said... How does coherence generate an equivalent of an internal "push" to do something?
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-09-17T00:47:02.392Z · LW(p) · GW(p)
Not sure how to clarify. AI capabilities research consists of looking for computer programs that do lots of different stuff. So you're selecting for computer programs that do lots of different stuff. The claim is that that selection heavily upvotes algorithms that tend towards coherence-in-general.
I don't have a direct answer to your question, so for now let's say that AI will not in fact "want" anything if not explicitly asked. This seems plausible to me, but also totally irrelevant from a practical perspective—who's going to build an entire freakin' superintelligence, and then just never have it do do anything!? In order for a program to even communicate words or data to us it's going to need to have some sort of drive to do so, since otherwise it would remain silent and we'd effectively have a very expensive silicon brick on our hands. So while in theory it may be possible to build an AI without wants, in practice there is always something an AI will be "trying to do".
↑ comment by Shmi (shminux) · 2022-09-16T22:11:31.260Z · LW(p) · GW(p)
I didn't mean that it wouldn't do anything, ever. Just that it will do what is asked, which creates its own set of issues, of course, if it kills us in the process. But I can imagine that it still will not have anything that could be intentional-stanced described as wants or desires.
Why were we so sure that strong enough AIs playing go would develop (what we can describe as a) fear of bad aji (latent potential)?
Well, we weren’t. As far as I know, nobody ever predict that. But in retrospect we should have, just because aji is such an important concept to master this game.
Similarly, if we’re looking for a generic mechanism that would led an AI to develop agency, I suspect any task would do as long as interpreting the data as from agency-based behaviors helps enough.
First they optimized for human behavior - that’s how they understood agency. Then they evaluate how much agency explain their own behavior - that’s how they noticed increasing it helps their current tasks. Rest is history.
But why would it do something when not asked? I.e. Why would it have needs/wants/desires to do anything at all?
These are inequivalent, but the answer to each is "because it was designed that way". Conventional software agents, which don't have to be particularly intelligent, do things without being explicitly instructed.
Firstly we already have AI designs that "want" to do things. Deep blue "wanted" to win at chess. Various reinforcement learning agents that "want" to win other games.
Intelligence that isn't turned to doing anything is kind of useless. Like you have an AI that is supposedly very intelligent. But it sits there just outputting endless 0's. What's the point of that?
There are various things intelligence can be turned towards. One is the "see that thing there, maximize that". Another option is prediction. Another is finding proofs.
An AI that wants things is one of the fundamental AI types. We are already building AI's that want things. They aren't yet particularly smart, and so aren't yet dangerous.
Imagine an AI trained to be a pure perfect predictor. Like some GPT-N. It predicts humans, and humans want things. If it is going somewhat outside distribution, it might be persuaded to predict an exceptionally smart and evil human. And it could think much faster. Or if the predictor is really good at generalizing, it could predict the specific outputs of other superhuman AI.
Mesa-optimizers basically means we can't actually train for wanting X reliably. If we train an AI to want X, we might get one that wants Y instead.
↑ comment by TAG · 2022-09-17T13:56:16.599Z · LW(p) · GW(p)
Firstly we already have AI designs that “want” to do things. Deep blue “wanted” to win at chess. Various reinforcement learning agents that “want” to win other games.
"Wanting" in quotes isn't the problem. Toasters "want" to make toast.
Intelligence that isn’t turned to doing anything is kind of useless. Like you have an AI that is supposedly very intelligent. But it sits there just outputting endless 0′s. What’s the point of that?
Doing something is not the same thing as doing-something-because-you-want-to. Toasters don't want to make toast, in the un-scare-quoted sense, they just do. Having goals, aims and drives is only meaningful if they can be swapped out for other ones (even if through training). It's a counterfactual concept.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-09-18T11:02:40.508Z · LW(p) · GW(p)
"Wanting" in quotes isn't the problem. Toasters "want" to make toast.
A standard toaster has been designed to make toast. But there is no part of it that creates new plans of how to make toast better. An evolutionary search for aerial designs can come up with new shapes, better than anything a human could invent. Deep blue can invent new chess moves no human could think of. A toaster doesn't invent a new better way of making toast.
A toaster is optimized by humans, but contains no optimizing.
Can you explain what an AI that plays good chess, but not because it wants to win, would be like?
Having goals, aims and drives is only meaningful if they can be swapped out for other ones (even if through training). It's a counterfactual concept.
If you do decide to define goals that way (I am not convinced this is the best or only way to define goals) that still doesn't mean humans know how to swap the goals in practice. It is just talking about some way to do it in principle.
Replies from: TAG↑ comment by TAG · 2022-09-18T17:42:39.734Z · LW(p) · GW(p)
But there is no part of it that creates new plans of how to make toast better. An evolutionary search for aerial designs can come up with new shapes, better than anything a human could invent. Deep blue can invent new chess moves no human could think of. A toaster doesn’t invent a new better way of making toast.
Ok...but what is your point? That any optimiser has goals?
Can you explain what an AI that plays good chess, but not because it wants to win, would be like?
Any current chess software with the possible exception of AlphaChess.
A hard coded chess program wouldn't be able to something else just because it wanted to.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-09-19T11:58:35.057Z · LW(p) · GW(p)
Ok...but what is your point? That any optimiser has goals?
Any optimizer needs to be optimizing for something.
A hard coded chess program wouldn't be able to something else just because it wanted to.
The universe is deterministic. So this applies equally well to a human, AlphaChess and Deep blue.
Would you agree that AIXI-tl is just as hard coded as Deep Blue? And that nonetheless, it forms clever plans to achieve its goals and is very dangerous.
Replies from: TAG↑ comment by TAG · 2022-09-19T18:51:48.104Z · LW(p) · GW(p)
Any optimizer needs to be optimizing for something.
OK, but you can't infer that something is an optimiser from the fact that it's good at something. You can infer that it's optimising something if you can change the something.
The universe is deterministic.
Not a fact.
So this applies equally well to a human, AlphaChess and Deep blue
Not everything has a replaceable UF or goal module. That renders it false that every AI has a goal. That means that you can't achieve general AI safety by considering goals alone.
Would you agree that AIXI-tl is just as hard coded as Deep Blue? And that nonetheless, it forms clever plans to achieve its goals and is very dangerou
No, AIXIs don't form plans.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-09-21T09:40:31.830Z · LW(p) · GW(p)
OK, but you can't infer that something is an optimiser from the fact that it's good at something. You can infer that it's optimising something if you can change the something.
The problem is that anything can be changed into anything, with enough changes. You have a bunch of chess algorithms. On one extreme, a pure min-max search with a piececount heuristic might be changed into a Misere (play to loose) chess engine, just by adding a single - sign.
Deep blue might be changed into a somewhat ok Misere chess player with a single -, and a better misere player by also making a few changes to the opening book.
A neural net based approach might need almost all the parameters in the net changed, but if the net was produced by gradient descent, a small change in the training process could produce a misere chess player instead.
Going even further back, a small change to the project specifications could have caused the programmers to write different code.
There are some algorithms where 1 small change will change the goal. And there are algorithms where many pieces must be changed at once to make it competently optimize some other goal. And everything in between, with no hard thresholds.
There are algorithms where humans know how to swap goals. And algorithms where we don't know how to swap goals.
The universe is deterministic.
Not a fact.
Quantum mechanics has a "branch both ways" that is sometimes mistaken for randomness. True randomness would be non-unitary and break a bunch of the maths. It isn't totally inconceivable that the universe does it anyway, but it seems unlikely. Do you have any coherent idea of what the universe might possibly do that isn't deterministic or random?
No, AIXIs don't form plans.
Are you claiming that an AIXI won't produce clever external behavior. If it had enough information, most of it's hypothesis will contain reasonably good simulations of reality. It tests all possible sequences of actions in these simulations. If it needs to hack some robots, and break in to where it's reward button is, it will. If it needs to win a game of chess, it will.
Are you claiming AIXI won't do this. It will just sit there being dumb?
Or are you claiming that however clever seeming it's external behavior, it doesn't count as a plan for some reason?
Replies from: TAG, TAG↑ comment by TAG · 2022-09-21T17:50:18.694Z · LW(p) · GW(p)
The problem is that anything can be changed into anything, with enough changes.
Ok. Are you suggesting a better technical definition, or are you suggesting going back to the subjective approach?
It tests all possible sequences of actions in these simulations.
No it doesn't.
If it needs to hack some robots, and break in to where it’s reward button is,
It doesn't have one. An AIXI isn't an learning system, and doesn't have a reward function.
it will. If it needs to win a game of chess, it will.
An AIXI is an algorithm that tries to predict sequences of input data using programmes. That's it. It doesnt want or need.
Are you claiming AIXI won’t do this. It will just sit there being dumb?
No, it will sit there figuring out the shortest code sequence that predicts its input. The only thing it can do.
Or are you claiming that however clever seeming it’s external behavior, it doesn’t count as a plan for some reason?
What external behaviour?
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-09-21T20:21:42.605Z · LW(p) · GW(p)
An AIXI is an algorithm that tries to predict sequences of input data using programmes. That's it. It doesnt want or need.
AIXI is the version that optimizes over the programs to maximize reward.
Solomonov induction is the version that "just" produces predictions.
I would say something is optimizing if it is a computation and the simplest explanation of its behavior looks causally forward from it's outputs.
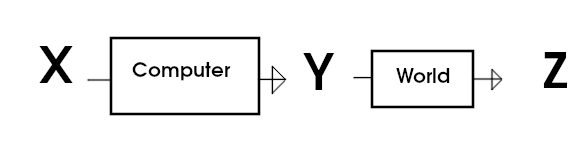
If the explanation "Y is whatever it takes to make Z as big as possible" is simpler than " Y is f(X)" then the computer is an optimizer. Of course, a toaster that doesn't contain any chips isn't even a computer. For example "deep blue is taking whichever moves lead to a win" is a simpler explanation than a full code listing of deep blue.
I would say something is an optimizer if you have more knowledge of Z than Y. Of course, this is "subjective" in that it is relitive to your knowledge. But if you have such deep knowledge of the computation that you know all about Y, then you can skip the abstract concept of "optimizer" and just work out what will happen directly.
↑ comment by TAG · 2022-09-21T18:05:20.306Z · LW(p) · GW(p)
Quantum mechanics has a “branch both ways” that is sometimes mistaken for randomness. True randomness would be non-unitary and break a bunch of the maths.
Which is an odd things to say, since the maths used by Copenhagenists is identical to the maths used by many worlders.
It isn’t totally inconceivable that the universe does it anyway, but it seems unlikely. Do you have any coherent idea of what the universe might possibly do
You are trying to appeal to the Yudkowsky version of Deutsch as incontrovertible fact, and it isn't.
If the MWI is so good, why do half of all physicists reject it?
If Everett's 1957 thesis solved everything, why have there been decades of subsequent work?
Bearing in mind that evolution under the Schrodinger equation cannot turn a coherent state into an incoherent one, what is the mechanism of decoherence?
What is there a basis problem, and what solves it?
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-09-21T20:03:51.359Z · LW(p) · GW(p)
If the MWI is so good, why do half of all physicists reject it?
Because physisists aren't trained in advanced rationality, program length occams razor etc. Their professor taught Copenhagen. And many worlds is badly named, misunderstood and counterintuitive. The argument from majority can keep everyone stuck at a bad equilibrium.
If Everett's 1957 thesis solved everything, why have there been decades of subsequent work?
If the sentence "god doesn't exist" solved theology, why is there so much subsequent work.
Bearing in mind that evolution under the Schrodinger equation cannot turn a coherent state into an incoherent one, what is the mechanism of decoherence?
I don't think there is one. I think it likely that the universe started in a coherent state, and it still is coherent.
Note a subtlety. Suppose you have 2 systems, A and B. And they are entangled. As a whole, the system is coherent. But if you loose A somewhere, and just look at B, then the maths to describe B is that of an incoherent state. Incoherence = entanglement with something else. If a particle in an experiment becomes incoherent, it's actually entangled somehow with a bit of the measuring apparatus. There is no mathematical difference between the two unless you track down which particular atom in the measuring apparatus.
Replies from: TAG↑ comment by TAG · 2022-09-22T11:46:54.742Z · LW(p) · GW(p)
I don’t think there is one. I think it likely that the universe started in a coherent state, and it still is coherent
Then why don't we see other universes, and why do we make only classical observations? Of course, these are the two problems with Everett's original theory that prompted all the subsequent research. Coherent states continue to interact, so you need decoherence for causally separate, non interacting worlds...and you need to explain the preponderance of the classical basis, the basis problem.
Incoherence = entanglement with something else.
No, rather the reverse. It's when off diagonal elements are zero or negligible.
Decoherence, the disappearance of a coherent superposed state, seems to occur when a particle interacts with macroscopiic apparatus or the environment. But thats also the evidence for collapse. You can't tell directly that you're dealing with decoherent splitting,rather than collapse because you can't observe decoherent worlds.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-09-23T09:55:35.436Z · LW(p) · GW(p)
Then why don't we see other universes, and why do we make only classical observations?
What do you mean by this. What are you expecting to be able to do here?
Shrodingers cat. Cat is in a superposition of alive and dead. Scientist opens box. Scientist is in superposition of feeding live cat and burying dead cat.
The only way to detect a superposition is through interference. This requires the 2 superimposed states to overlap their wavefunction. In other words, it requires every last particle to go into the same position in both worlds. So it's undetectable unless you can rearrange a whole cat to atomic precision.
Coherent states continue to interact, so you need decoherence for causally separate, non interacting worlds.
In practice, if two states are wildly different, the interaction term is small. With precise physics equipment, you can make this larger, making 2 states where a bacteria is in different positions and then getting those to interact. Basically, blobs of amplitude need to run into each other to interact. Quantum space is very spacious indeed, so the blobs usually go their own separate way once they are separated. It's very unlikely they run into each other at random, but a deliberate collision can be arranged.
No, rather the reverse. It's when off diagonal elements are zero or negligible.
That is what the matrix looks like, yes.
But thats also the evidence for collapse.
Interaction with the environment is a straightforward application of schrodingers equation. Collapse is a new unneeded hypothesis that also happens to break things like invarence of reference frame.
Replies from: TAG↑ comment by TAG · 2022-09-24T13:12:47.901Z · LW(p) · GW(p)
What are you expecting to be able to do here?
Show that coherence is simple but inadequate, and decoherence is adequate but not simple .
Shrodingers cat. Cat is in a superposition of alive and dead. Scientist opens box. Scientist is in superposition of feeding live cat and burying dead cat.
The two problems with this account are 1) "alive" and "dead" are classical states -- a classical basis is assumed. and 2) the two states of the observer are assumed to be non-interacting and unaware of each other. But quantum mechanics itself gives no reason to suppose that will be the case. In both cases, it needs to be shown, and not just assumed that normality -- perceptions "as if" of a single classical world by all observers -- is restored.
So it’s undetectable unless you can rearrange a whole cat to atomic precision.
So you can't have coherent superpositions of macroscopic objects. So you need decoherence. And you need it to be simple, so that it is still a "slam dunk".
Basically, blobs of amplitude need to run into each other to interact.
How narrow a quantum state is depends, like everything, on the choice of basis. What is sharply peaked in position space is spread out in frequency/momentum space.
Interaction with the environment is a straightforward application of schrodingers equation.
No it isn't. That's why people are still publishing papers on it.
5 comments
Comments sorted by top scores.
comment by green_leaf · 2022-09-16T23:36:02.851Z · LW(p) · GW(p)
What's the difference between the AI acting as if it wanted something, and it actually wanting something? The AI will act is if it wants something (the goals the programmers have in mind during training, something else that destroys all life at some point after the training) because that's what it will be rewarded for during the training.
The alternative to the AI that doesn't seem to want anything seems to be an AI that has no output.
Replies from: sphinxfire↑ comment by Sphinxfire (sphinxfire) · 2022-09-17T07:57:18.963Z · LW(p) · GW(p)
The alternative would be an AI that goes through the motions and mimics 'how an agent would behave in a given siuation' with a certain level of fidelity, but which doesn't actually exhibit goal-directed behavior.
Like, as long as we stay in the current deep learning paradigm of machine learning, my prediction for what would happen if an AI was unleashed upon the real world, regardless of how much processing power it has, would be that it still won't behave like an agent unless that's part of what we tell it to pretend. I imagine something along the lines of the AI that was trained on how to play Minecraft by analyzing hours upon hours of gameplay footage. It will exhibit all kinds of goal-like behaviors, but at the end of the day it's just a simulacrum limited in its freedom of action to a radical degree by the 'action space' it has mapped out. It will only ever 'act as thought it's playing minecraft', and the concept that 'in order to be able to continue to play minecraft I must prevent my creators from shutting me off' is not part of that conceptual landscape, so it's not the kind of thing the AI will pretend to care about.
And pretend is all it does.
Replies from: martin-randall, green_leaf↑ comment by Martin Randall (martin-randall) · 2022-09-17T13:20:19.564Z · LW(p) · GW(p)
Humans are trained on how to live on Earth by hours of training on Earth. We can conceive of the possibility of Earth being controlled by an external force (God or the Simulation Hypothesis). Some people spend time thinking about how to act so that the external power continues to allow the Earth to exist.
Maybe most of us are just mimicking how an agent would behave in a given situation.
The universe appears to be well constructed to provide minimal clues as to the nature of its creator. Minecraft less so.
Replies from: sphinxfire↑ comment by Sphinxfire (sphinxfire) · 2022-09-17T18:25:58.344Z · LW(p) · GW(p)
"Humans are trained on how to live on Earth by hours of training on Earth. (...) Maybe most of us are just mimicking how an agent would behave in a given situation."
I agree that that's a plausible enough explanation for lots of human behaviour, but I wonder how far you would get in trying to describe historical paradigm shifts using only a 'mimic hypothesis of agenthood'.
Why would a perfect mimic that was raised on training data of human behaviour do anything paperclip-maximizer-ish? It doesn't want to mimic being a human, just like Dall-E doesn't want to generate images, so it doesn't have a utility function for not wanting to be prevented from mimicking being a human, either.
↑ comment by green_leaf · 2022-09-18T18:27:00.597Z · LW(p) · GW(p)
The alternative would be an AI that goes through the motions and mimics 'how an agent would behave in a given situation' with a certain level of fidelity, but which doesn't actually exhibit goal-directed behavior.
If the agent would act as if it wanted something, and the AI mimics how an agent would behave, the AI will act as if it wanted something.
It will only ever 'act as thought it's playing minecraft', and the concept that 'in order to be able to continue to play minecraft I must prevent my creators from shutting me off' is not part of that conceptual landscape, so it's not the kind of thing the AI will pretend to care about.
I can see at least five ways in which this could fail:
- It's simpler to learn a goal of playing Minecraft well (rather than learning the goal of playing as similar to the footage as possible). Maybe it's faster, or it saves space, or both, etc. An example of this would be AlphaStar, who learned first by mimicking humans, but then was rewarded for winning games.
- One part of this learning would be creating a mental model of the world, since that helps an agent to better achieve its goals. The better this model is, the greater the chance it will contain humans, the AI, and the disutility of being turned off.
- AIs already have inputs and outputs from/into the Internet and real life - they can influence much more than playing Minecraft. For a truly helpful AI, this influence will be deliberately engineered by humans to become even greater.
- Eventually, we'll want the AI to do better than humans. If it only emulates a human (by imitating what a human would do) (which itself could create a mesa-optimizer, if I understand it correctly), it will only be as useful as a human.
- Even if the AI is only tasked with outputting whatever the training footage would output and nothing more (like being good at playing Minecraft in a different world environment), ever, and it's not simpler to learn how to play Minecraft the best way it can, that itself, with sufficient cognition, ends the world. (The strawberry problem [LW · GW].)
So I think maybe some combination of (1), (2) and (3) will happen.