Davidad's Provably Safe AI Architecture - ARIA's Programme Thesis
post by simeon_c (WayZ) · 2024-02-01T21:30:44.090Z · LW · GW · 17 commentsThis is a link post for https://www.aria.org.uk/wp-content/uploads/2024/01/ARIA-Safeguarded-AI-Programme-Thesis-V1.pdf
Contents
17 comments
The programme thesis of Davidad's agenda to develop provably safe AI has just been published. For context, Davidad is a Programme Director at ARIA who will grant somewhere between £10M and £50M over the next 3 years to pursue his research agenda.
It is the most comprehensive public document detailing his agenda to date.
Here's the most self-sufficient graph explaining it at a high-level although you'll have to dive into the details and read it several times to start grasping the many dimensions of it.
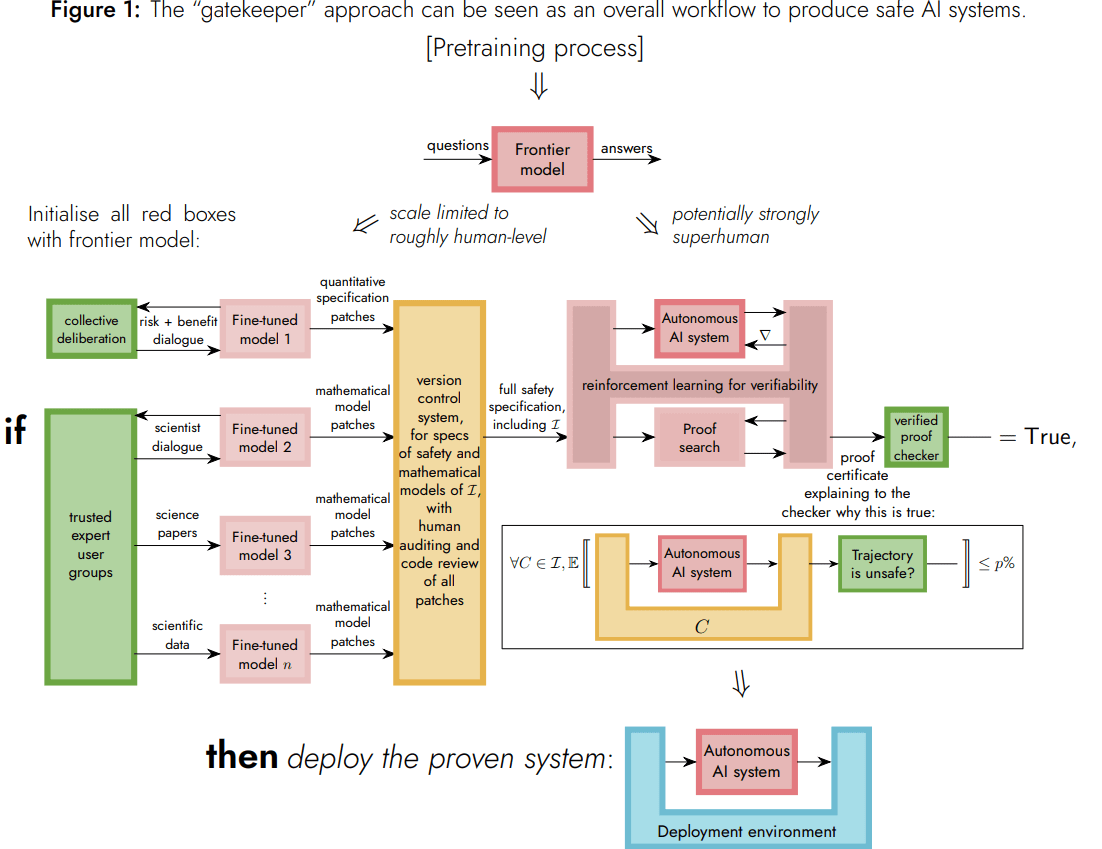
I'm personally very excited by Davidad's moonshot that I currently see as the most credible alternative to scaled transformers, which I consider to be too flawed to be a credible safe path, mostly because:
- Ambitious LLM interpretability seems very unlikely to work out:
- Why: the failed attempts at making meaningful progress of the past few years + the systematic wall of understanding of ~80% of what's going on across reverse engineering attempts
- Adversarial robustness to jailbreak seems unlikely to work out:
- Why: failed attempts at solving it + a theoretical paper of early 2023 that I can't find right now + increasingly large context windows
- Safe generalization with very high confidence seems quite unlikely to work out
- Why: absence of theory on transformers + weak interpretability
A key motivation for pursuing moonshots a la Davidad is, as he explains in his thesis, to shift the incentives from the current race to the bottom, by derisking credible paths to AI systems where we have strong reasons to expect confidence in the safety of systems. See the graph below:
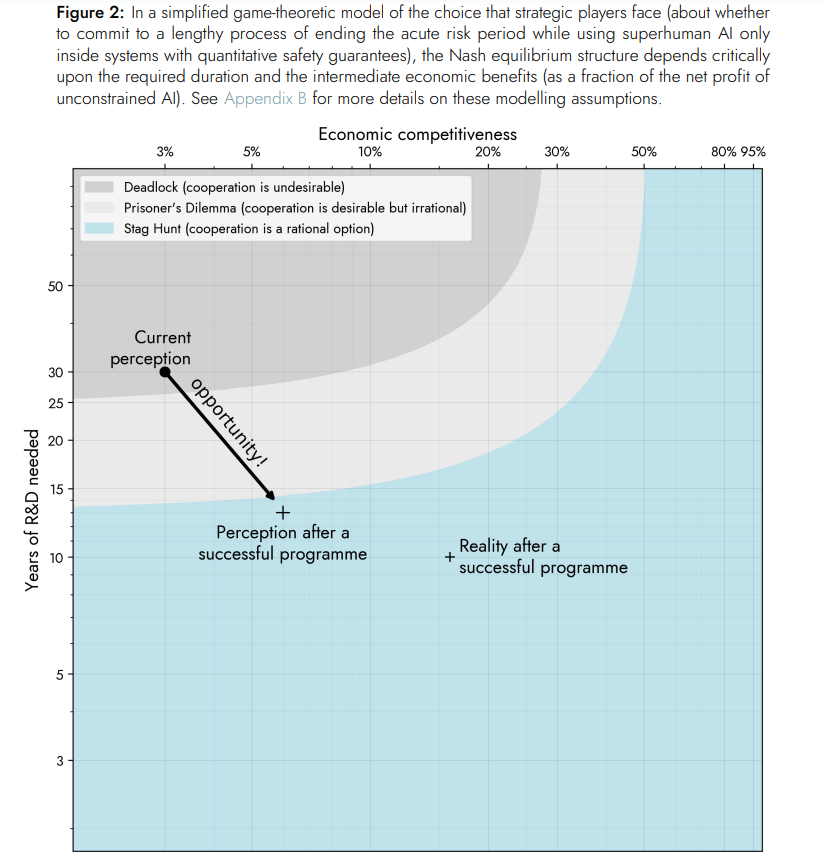
17 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-02-02T02:41:18.186Z · LW(p) · GW(p)
I mean, it sounds good in theory. My main hesitation about it is the feasibility of enacting it. I'm not sure I'm convinced about a "95% safety tax" (aiming for only 5% of the counterfactual economic value of unconstrained AI) being something that will be sufficiently tempting to be economically-self-promoting. So, probably this needs to be combined with a worldwide enforcement regime to prevent bad actors from relaxing the safety constraints?
Maybe there'll be answers to my questions in the doc. I've only looked at the pdf so far.
Replies from: WayZ, quetzal_rainbow↑ comment by simeon_c (WayZ) · 2024-02-02T06:27:47.746Z · LW(p) · GW(p)
Yeah basically Davidad has not only a safety plan but a governance plan which actively aims at making this shift happen!
↑ comment by quetzal_rainbow · 2024-02-02T08:50:32.366Z · LW(p) · GW(p)
If I understand doc right, they mean 5% of counterfactual impact before ending acute risk period.
comment by Roko · 2024-02-03T13:44:27.876Z · LW(p) · GW(p)
Just from a high level, I think the general style of approaches to AI safety that imagine human researchers solving hard technical challenges in order to make ASI safe enough to deploy widely are fundamentally flawed.
The most likely way to get to extremely safe AGI or ASI systems is not by humans creating them, it's by other less-safe AGI systems creating them.
"Technological advance is an inherently iterative process. One does not simply take sand from the beach and produce a Dataprobe. We use crude tools to fashion better tools, and then our better tools to fashion more precise tools, and so on."
For this reason I see approaches that try to make ASI that is provably safe to be mistaken. We should instead just aim to make AGI that's very capable and steer its use towards the next generation of safer systems, and that steering likely won't involve proofs.
↑ comment by Vladimir_Nesov · 2024-02-04T04:05:44.183Z · LW(p) · GW(p)
The most likely way to get to extremely safe AGI or ASI systems is not by humans creating them, it's by other less-safe AGI systems creating them.
This does seem more likely, but managing to sidestep the less-safe AGI part would be safer. In particular, it might be possible to construct a safe AGI by using safe-if-wielded-responsibly tool AIs (that are not AGIs), if humanity takes enough time to figure out how to actually do that.
Replies from: Roko↑ comment by the gears to ascension (lahwran) · 2024-02-04T04:34:59.812Z · LW(p) · GW(p)
I don't see anything in here that forbids using weaker AI systems to help with this plan. But how do you ever know when you've succeeded if it's not by proofs? proving through ais is not out of the question, it's a thing that is done to some kinds of safety critical deep learning AIs now.
Replies from: Roko↑ comment by Roko · 2024-02-04T20:58:40.340Z · LW(p) · GW(p)
I think the first step will be using AGIs to come up with better plans.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-02-05T07:42:08.245Z · LW(p) · GW(p)
My general concern with "using AGI to come up with better plans" is not that they will successfully manipulate us into misalignment, but Goodhart us into reinforcing stereotypes of "how good plan should look" or somewhat along this dimension, purely from how RLHF-style steering works.
Replies from: Roko↑ comment by Roko · 2024-02-05T13:07:51.316Z · LW(p) · GW(p)
Humans already do this, except we have made it politically incorrect to talk about the ways in which human-generated Goodhearting make the world worse (race, gender, politics etc)
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-02-05T15:21:08.952Z · LW(p) · GW(p)
Your examples are clearly visible. If your wrong alignment paradigm get reinforced because of your attachment to specific model of causality known to ten people in entire world, you risk to notice this too late.
Replies from: Roko↑ comment by Roko · 2024-02-05T16:37:32.998Z · LW(p) · GW(p)
because of your attachment to specific model of causality known to ten people in entire world, you risk to notice this too late.
you're thinking about this the wrong way. AGI governance will not operate like human governance.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-02-05T16:52:23.149Z · LW(p) · GW(p)
Can you elaborate? I don't understand where we disagree.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-02-02T22:50:18.901Z · LW(p) · GW(p)
'theoretical paper of early 2023 that I can't find right now' -> perhaps you're thinking of Fundamental Limitations of Alignment in Large Language Models? I'd also recommend LLM Censorship: A Machine Learning Challenge or a Computer Security Problem?.
comment by Chipmonk · 2024-04-10T22:53:00.686Z · LW(p) · GW(p)
New better link: https://www.aria.org.uk/programme-safeguarded-ai/
comment by martinkunev · 2024-02-05T02:19:27.928Z · LW(p) · GW(p)
Max Tegmark presented similar ideas in a TED talk (without much details). I'm wondering if he and Davidad are in touch.
↑ comment by davidad · 2024-02-05T07:28:37.437Z · LW(p) · GW(p)
Yes. You will find more details in his paper, Provably safe systems with Steve Omohundro, in which I am listed in the acknowledgments (under my legal name, David Dalrymple).
Max and I also met and discussed the similarities in advance of the AI Safety Summit in Bletchley.