Good Bings copy, great Bings steal
post by dr_s · 2024-04-21T09:52:46.658Z · LW · GW · 6 commentsContents
The dualism hypothesis The computability hypothesis The quantum hypothesis The extrapolation hypothesis The Embedding Space of Babel "Good artists copy, great artists steal" None 6 comments
Stop me if you've heard this one before:
LLMs may produce a lot of seemingly original text, but really, they can never equate a human's output, because they can only remix material from their own training set, never create new knowledge.
Ok, no one stopped me, but I imagine that's more the limits of the medium, because I'm sure most of you have heard this one before, multiple times in fact. If you hold opinions anything like mine on the matter, I suspect you have also been deeply irritated at it, and you consider it an unexamined thought-terminating cliché used to produce false reassurance in anyone who doesn't want to entertain the possibility of AI challenging them and possibly surpassing them on their own field.
Well, it is all that. But in good rationalist tradition I would like to actually dig into the claim and find its best steel man possible - and hopefully find something interesting on the way, even if I do end up thinking it's still wrong (spoilers: yes, I mostly do).
To be clear, I am not arguing that current LLMs are equivalent to the best human writers - they are clearly not, if only for lack of long-term planning ability. But neither is the claim above usually applied only to the current generation of AI, in general. Instead, it seems like a broader claim, like there's something to either the concept of ML as a whole, or at least the current data-driven paradigm, that constitutes a fundamental insurmountable limit, a chasm separating artificial and natural intelligence. Are there plausible candidates for this limit?
The dualism hypothesis
Maybe AIs just don't have a soul.
You don't see the claim often declined in this way, but honestly I'd respect more anyone who did. Metaphysical dualism is hard to defend in many ways, but it can't be entirely falsified, and at least it provides a very solid reason why humans could have some quality that we can never give to our AIs, ever[1]. Note that this is a subset of all dualist views - for example one could imagine souls exist but only provide the sense of self, the qualia, to humans, in which case AIs perfectly cognitively equivalent to us would be possible, they'd just be P-zombies.
The computability hypothesis
Maybe it's all matter, but somehow the human brain can transcend the limits of regular computation - solve the halting problem, or act as if P = NP, or some such.
This one seems just the soul idea but repackaged. If the brain operates on regular physics, suggesting it can somehow break the iron rules of computation theory is like suggesting you can build a perpetual motion machine if you keep piling up enough cogs to confuse the laws of thermodynamics. It just doesn't work that way, no matter how complex it is.
The quantum hypothesis
Maybe it's all basic computational theory, but human brains are quantum computers, or are seeded by true quantum randomness.
This one stays in the realm of materialism while still making a relatively rigorous claim. If human brains were quantum computers, at least in part, there certainly would be, by information complexity theory, certain problems that could be solved in polynomial time that a classic computer can't realistically attack (to put it rigorously, problems that are in QP but not in P). If one such problem was "creativity" (whatever that means), and if there was no suitable classical algorithm that approximates the same result in polynomial time, then human brains could realistically have an advantage over our currently classical ML models. Unfortunately, there just isn't much evidence that human brains do any quantum computing, and all our heuristics suggest that a wet and warm thing like our thinking bacon really isn't well-suited to that. Quantum randomness is a simpler affair, and could be realistically involved in brain processes (e.g. the precise timing of a neuron discharge). But it's very unclear why that would be particularly superior to the pseudo-randomness that seeds AI models instead. It certainly wouldn't be any expression of ourselves in particular, just a roll of the dice influencing our outputs. In addition, both of these things could be at some point done in AI too, so this would be a relatively short-lived limit. Especially if you think that the human brain can perform quantum computing, it means quantum computing at room temperature must be possible with the right materials, which means it's really unlikely we won't find out how to do it at some point.
The extrapolation hypothesis
Maybe it's all classic computing, but the human brain is just inherently better at extrapolating knowledge out of domain, whereas ML models simply keep interpolating between training data points.
This one, I feel, is interesting. Humans certainly seem on the surface to be better at few-shot learning than LLMs. We learn to speak competently in a very short time and almost surely with less "tokens" than an LLM needs. And it makes sense from a survival standpoint that it would be so - that if there are special brain structure that predispose us to learn certain skills faster (if we want, certain combinations of architecture and hyperparameters that would make us have better embedded priors for the kind of distribution we're supposed to learn), well, obviously optimizing such things would be a huge survival advantage and evolution would converge towards it.
But it's also true that we obviously are very good at things that can't have been in our "training set", the ancestral environment that shaped that search. We couldn't have been optimized for atomic physics, coding or writing epic poems, and yet we can do those things too. So it seems necessary that there are certain ways in which one can extrapolate out of domain safely or relatively reliably, and our brains have somehow picked up on them, either by accident, or because they were a very efficient way (saving on complexity, or energy, or need for training data) to achieve the goals that evolution did optimize for with minimal effort. So, what does it really mean to be able to extrapolate out of domain? It's hard to think about if we limit ourselves to an undefined search space, so let's use LLMs to actually make that more tangible.
The Embedding Space of Babel
Consider an LLM which accepts a vocabulary (a set of possible tokens) , whose size will be represented as from now on. It has a context window and an embedding dimension [2]. Thus each possible input is mapped to a vector in an embedding space [3]. The amount of possible inputs isn't infinite. If contains also a "null" token (representing no word, to account for sequences shorter than the full context window), then there's a total of possible input sequences, which correspond to just as many discrete points in the embedding space. This sparse cloud of points includes every possible combination of all tokens in , that is, every meaningful and meaningless string of text that can be written with at most tokens.
An LLM is a map between these points. Given an input, it returns a new token, which can be appended to the end of the context window to keep going. If the input is already as long as the full context window, you can just pop the first token and enqueue the new one. LLMs use randomness, but that can be easily removed if we just consider the algorithm as pseudo-random, and count the seed as a hyperparameter. This means the LLM is also stateful, because the random number generator has a hidden state (which allows it to return different numbers every time), meaning even the same exact inputs might produce two different results at different times. But even if we remove this property and consider only a "zero temperature" LLM, we have then a pure mapping of those inputs to total outputs. In particular, since each input containing non-null tokens will produce one containing , we have a total of
possible mappings. That's the total amount of LLMs that can exist for this embedding space - it's large, it's mind-bogglingly large, but it's finite. Within that space there exists an LLM that completes the prompt "Here is a correct proof of the Riemann hypothesis:" with a correct proof of the Riemann hypothesis. There is an LLM that completes "Call me Ishmael." with a full write-up of Moby Dick. Or possibly an improved version of Moby Dick. There are oracles of truth and infinite wisdom hidden in there. Nothing fundamentally makes it impossible for such an LLM to exist. Of course, there are also a lot - in fact, a crushing majority - of LLMs that merely spit out complete garbage. So how do we find the right ones? Even landing on something like GPT-3 or Claude Opus, limited as they may be, is like finding a needle in a haystack as large as the universe.
Enter stochastic gradient descent.
The thing about representing this whole set of points within an embedding space is that it allows us to learn some kind of highly parametric analytic function on it (some combination of linear matrix products, bilinear self-attention tensor products, and GeLU activation functions, usually) which can then be seamlessly applied throughout the entire space. Given each embedding point , we want to find a function such that . We do so by picking a set of example trajectories (our training set of text data) and then tuning the parameters of the very general function we designed in a way that makes it generally get it right, and then hope it generalizes even to points that were not in the training set.
That this generalization works tells us something about the properties of this space. The maps representing "smart" LLMs, which map sensible points to logical continuations of those sensible points, have a certain smoothness to them. It is possible to find the mapping for an unknown point starting from the knowledge of the mapping for a few known ones and reasonably interpolating between them. This would not be feasible if the function we're trying to approximate had wild non-analytic swings in the space between training points.
I think this smoothness is helped by the high dimensionality of the embedding space. There is a sense in which a higher dimensional space means each point in space has a denser neighborhood - for example, the volume of a thin spherical shell of radius scales like . As an intuition pump, consider a Gaussian process with squared exponential kernel, a very common form of a non-parametric function with some smoothness constraint enforced[4]. Imagine this process is defined on a regular grid. We know the value of the function at all the points surrounding a certain cell, and we must predict the value at that cell. That means we will have points in total.
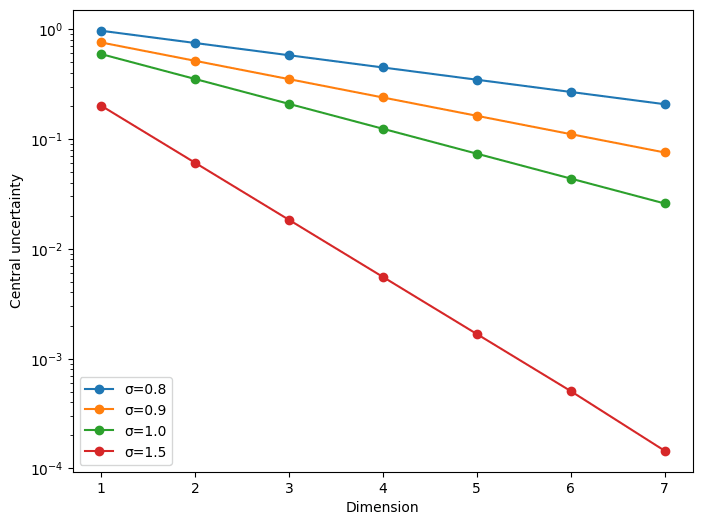
What does the predicted uncertainty on that central value look like? Here is a plot of the ratio of the uncertainty on the center with the smoothness parameter of the Gaussian process for increasing dimension. Note the logarithmic scale; the ratio decreases exponentially with dimensionality, so roughly goes like the inverse of the number of neighborhood points. I couldn't even begin to approach the embedding dimension as I was using the exact method to compute this, which requires inverting a matrix that grows exponentially bigger as the dimension increases.
The points we trained our function on will define a certain convex hull in embedding space. Now, where do the points we might want to generate - the "new knowledge", the proofs of the Riemann hypotheses or the tragedies as moving as Shakespeare - like in the same embedding space? We know they're somewhere. Are they still inside that convex hull? Are they outside? Are they close, or far?
On the answer to this, I would say, rests the whole notion of whether LLMs can be creative or not - and how do we manage. Remember that the embedding vectors themselves are learned, and so different learned values could bring a point that would usually be outside the hull inside. So could increasing the dimensionality of the embedding space, of course (which is after all what most companies seem to do these days - along with everything else. Just use more parameters, use more tokens, use more compute). So could adding to the training set something that pushes the envelope a bit further out - which would be a lot more beneficial than something falling in an already dense area of the space.
"Good artists copy, great artists steal"
That quote is traditionally attributed to Pablo Picasso. That seems to me the most concise expression of the fact that creativity is borne out of imitation, remixing, interpolation between learned experiences - which can in itself produce genuinely new things, because our experiences are varied and vast. But none of it would be possible if there were no patterns, no "smoothness" to the knowledge space, the possibility of picking up ideas and applying it elsewhere with at least some effectiveness. If not for that, in fact, we would not have been able to evolve an intelligence at all. After all, what is evolution if not a process through which information available in the environment gets slowly encoded into a physical form via a painful, long process of randomization and filtering?
Still, that does leave a lot of space for the human brain to be capable of things that LLMs are not. Not a fundamental one in a theoretical sense, but one that could be substantial. The "embedding space" (if you could use such a representation meaningfully) of our entire sensory experience must require after all a much higher dimensionality than GPT-4 needs to only represent words, and that would make the convex hull that much larger and encompassing.
There is also, somewhere, in any embedding space representation, a convex hull of all the things that can be known. For an LLM, that's the hull of all the possible points that can be represented with its vocabulary and context window; for real life at large, it's harder to pin down. How much of it your interpolating function covers may be the key to how general and powerful your intellect is. Perhaps that's the fundamental difference - perhaps you can prove that human brain have such a domain that roughly overlaps with that of the universe at large, which means that while interpolating inside it might be more or less difficult depending on the local density of known information, it's never as hard as pushing outside. Or perhaps we don't, and then anything with a larger domain than us would run loops around us, able to understand things we can't even begin to fathom. It's obviously an approximation to even describe knowledge about the world at large like this. But I feel like the analogy makes it clearer to me what "creating new knowledge" might mean, at least, and I hope it does for you as well. Hopefully, this insight, itself, was new enough to be worth some interest.
<|endoftext|>
- ^
This side of mixing up linear algebra with necromancy, at least.
- ^
For example, GPT-3 has , and .
- ^
This only an idealization of the embedding space. In practice, the LLM will use floating point arithmetic of a certain precision - GPT-3 uses 16 bit floats, so the real embedding space will be a discrete grid of points.
- ^
The analogy isn't even that farfetched given that we know deep neural networks are equivalent to Gaussian processes in the limit of infinite width.
6 comments
Comments sorted by top scores.
comment by gwern · 2024-04-21T19:56:17.110Z · LW(p) · GW(p)
LeCun trolled Twitter with that a few years ago: https://arxiv.org/abs/2110.09485#facebook
Replies from: dr_scomment by Seth Herd · 2024-04-22T03:18:10.016Z · LW(p) · GW(p)
The question this addresses is whether LLMs can create new knowledge. The answer is "that's irrelevant".
Your framing seems to equivocate over current LLMs, future LLMs, and future AI of all types. That's exactly what the public debate does, and it creates a flaming mess.
I'm becoming concerned that too many in the safety community are making this same mistake, and thereby misunderstanding and underestimating the near-term danger.
I think there's a good point to be made about the cognitive limitations of LLMs. I doubt they can achieve AGI on their own.
But they don't have to, so whether they can is irrelevant.
If you look at how humans create knowledge, we are using a combination of techniques and brain systems that LLMs cannot employ. Those include continuous, self-directed learning; episodic memory as one aid to that learning; cognitive control, to organize and direct that learning; and sensory and motor systems to carry out experiments to direct that learning.
All of those are conceptually straightforward to add to LLMs (good executive function/cognitive control for planning is less obviously straightforward, but I think it may be surprsingly easy to leverage LLMs "intelligence" to do it well).
See my Capabilities and alignment of LLM cognitive architectures [LW · GW] for expansions on those arguments. I've been reluctant to publish more, but I think these ideas are fairly obvious once someone actually sits down to create agents that expand on LLM capabilities, so I think getting the alignment community thinking about this correctly is more important than a tiny slowdown in reaching x-risk capable AGI through this route.
(BTW human artistic creativity uses that same set of cognitive capabilities in different ways, so same answer to "can LLMs be true artists").
Replies from: dr_s↑ comment by dr_s · 2024-04-22T06:29:53.682Z · LW(p) · GW(p)
I don't think I disagree with you on anything; my point is more "what does creating new knowledge mean?". For example, the difference between interpolation and extrapolation might be a rigorous way of framing it. Someone else posted a LeCun paper on that here; he found that extrapolation is the regime in which most ML systems work and assumes that the same must be true of deep learning ones. But for example if there was a phase transition of some kind in the learning process that makes some systems move to an interpolation regime, that could explain things. Overall I agree that none of this should be a fundamental difference with human cognition. It could be a current one, but it would at least be possible to overcome in principle. Or LLMs could already be in this new regime, since after all, not like anyone checked yet (honestly though, it might not be too hard to do so, and we should probably try).
comment by Jonas Hallgren · 2024-04-21T13:41:49.987Z · LW(p) · GW(p)
I like the post and generally agree. Here's a random thought on the OOD generalization. I feel that often we talk about how being good at 2 or 3 different things allow for new exploration. If you believe in books such as Range, then we're a lot more creative when combining ideas from multiple different fields. I rather think of multiple "hulls" (I'm guessing this isn't technically correct since I'm a noob at convex optimisation.) and how to apply them together to find new truths.
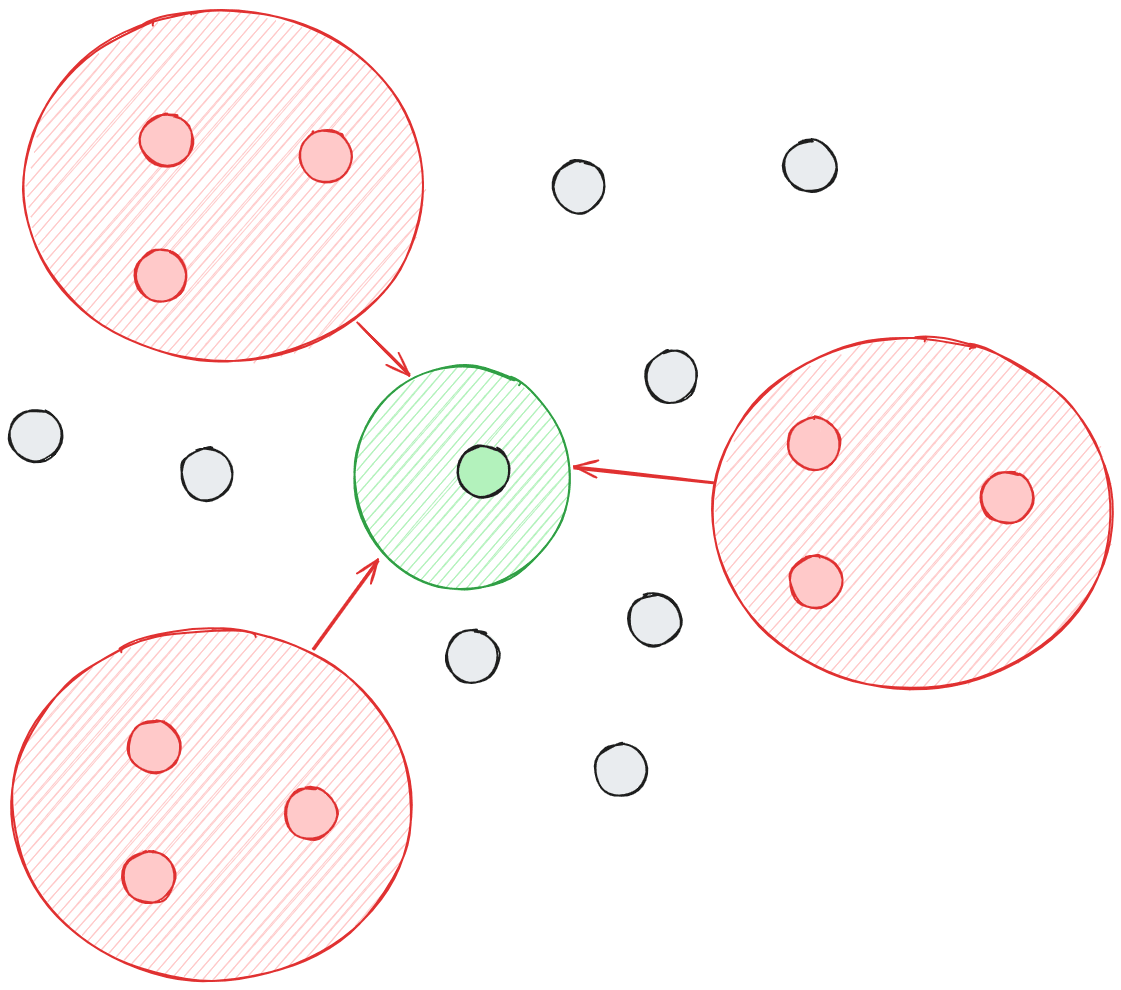
↑ comment by dr_s · 2024-04-21T13:55:00.106Z · LW(p) · GW(p)
Well, those three sets of points ultimately still define only one hull. But I get your intuition - there are areas inside that hull that are high density, and areas that are much lower density (but in which it might be easier to extrapolate due to being surrounded by known areas). I feel like also our inability to visualize these things in their true dimensionality is probably really limiting. The real structures must be mind-boggling and probably looking more like some kind of fractal filament networks.