A short 'derivation' of Watanabe's Free Energy Formula
post by Wuschel Schulz (wuschel-schulz) · 2024-01-29T23:41:44.203Z · LW · GW · 6 commentsContents
Background: Statistical Learning Theory The Probabilistic Model The True Distribution The Parameters The Data The Negative Log-Likelihood Prior over the Parameters Posterior Distribution Free Energy None 6 comments
Epistemic status: I wrote the post mostly for myself, in the process of understanding the theory behind Singular Learning Theory, based on the SLT low lecture series. This is a proof sketch with the thoroughness level of an experimental physics lecture: enough to get the intuitions but consult someone else for details.
Background: Statistical Learning Theory
In the framework of statistical learning theory, we aim to establish a model that can predict an outcome given an input with a certain level of confidence. This prediction is typically governed by a set of parameters , which need to be learned from the data. Let us begin by defining the primary components of this framework.
The Probabilistic Model
The probabilistic model represents the likelihood of observing the outcome given the input and the parameters . This model is parametric, meaning that the form of the probability distribution is predefined, and the specific behavior of the model is determined by the parameters .
The True Distribution
The true distribution is the actual distribution from which the data points are sampled. In practice, this distribution is not known and attempts to approximate it through the learning process.
The Parameters
The parameters are the weights or coefficients within our model that determine its behavior. The goal of learning is to find the values of that make as close as possible to the true distribution .
The Data
The data consist of pairs of input values and their corresponding outcomes . These data points are used to train the model, adjusting the parameters to fit the observed outcomes.
The Negative Log-Likelihood
The negative log-likelihood is a measure of how well our model fits the data . It is defined as the negative sum of the logarithms of the model probabilities assigned to the true outcomes :
where is the number of data points in . Minimizing the negative log-likelihood is equivalent to maximizing the likelihood of the data under the model, which is a central objective in the training of probabilistic models.
Prior over the Parameters
In a Bayesian framework, we incorporate our prior beliefs about the parameters before observing the data through a prior distribution . This prior distribution encapsulates our assumptions about the values that can take based on prior knowledge or intuition. For instance, a common choice is a Gaussian distribution, which encodes a preference for smaller (in magnitude) parameter values, promoting smoother model functions.
Posterior Distribution
Once we have observed the data , we can update our belief about the parameters using Bayes' theorem. The updated belief is captured by the posterior distribution, which combines the likelihood of the data given the parameters with our prior beliefs about the parameters. The posterior distribution is defined as:
where is the negative log-likelihood of the parameters given the data, is the prior over the parameters, and is the normalization constant, also known as the partition function. The partition function ensures that the posterior distribution is a valid probability distribution by integrating (or summing) over all possible values of :
The posterior distribution reflects how likely different parameter values are after taking into account the observed data and our prior beliefs.
Free Energy
This formulation looks like the Boltzmann distribution from statistical physics. This distribution also describes a probability: the probability that a system can be found in a particular microstate is with being the energy (here assuming, that the temperature is 1). This formalism can be expanded to macrostates, when changing the Energy to Free Energy, taking into account that microstates that have many realizations are more likely.
We can do a similar step with the Posterior of our model weights, by considering neighborhoods around local minima as macrostates. This opens up the question of what the correct formula for the Free Energy of these macrostates are, so we can make predictions about the behavior of learning machines.
First, let us consider the case of large datasets. In that case, we can replace the negative Log-Likelihood with n times its average:
We see that we can compose the negative Log likelihood into the number of data points n, the expected Kullback–Leibler divergence of the model with the true distribution, and the expected entropy of the true distribution. As we see here, the expected entropy term does not contribute to the posterior of the parameters:
The macrostates, aka the regions in parameter space we are now interested in analyzing are the vicinities of local minima in the Loss landscape. Let us assume we decompose our parameter space into macrostates .
We call this the free energy of this area, as it serves the same function as the Free Energy in statistical physics. We have constructed such that it only contains one minimum of the expected Kulberg Leibler divergence (from here on we abbreviate as ). These minima don't have to be points but can be different sets within .
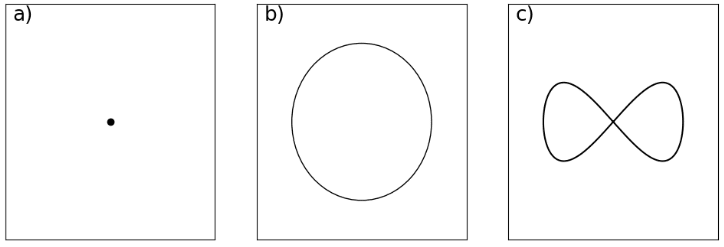
Since we assume, that is smooth, it can locally be approximated by its Taylor series at any point. How the leading order terms of the Taylor series look at its minimum depends on the geometry of the minimum. Let's look at an example of how that might look like from the figure above. In a) we have a simple minimum point, so the Taylor series of at this point might look like , going up in each direction. In b) our minimum is a one-dimensional submanifold, and so the Taylor expansion of will look like , increasing in one dimension, but staying flat when going along another. The situation in c) looks almost the same, except in the center, where the line crosses itself. There the Taylor expansion will look like , locally staying flat in either direction. Points like these, where the directions you can go in while staying on the set suddenly change, are called singularities.
Let us now calculate the Free Energy around a point , where has a minimum. In general the leading order term of the at a minimum looks like this:
Here is the value of the KL-divergence at its minimum.
To get it into this form, we have to make a change of coordinates for (for example when we are at a singularity where the different parts of the minimum come in from an angle). A process called blowup guarantees us, that we are always able to find such coordinates. Since we are at a minimum, we know that all leading order exponents are even.
Let's also approximate our prior over the weights on this point in the same basis as its leading order term:
For large , the Free Energy at any point far away from the minima gets exponentially suppressed. To see how much the minimal point contributes to the integral we can integrate it in its vicinity. Here we choose to integrate from 0 to 1.
Why not from to ?[1]
The first thing we can do is pull out the term as it does not depend on .
To solve the remaining integral, we first do a Laplace and then a Mellin transform, as this brings the integral into a form, that is easier to solve.
Next, we group the dimensions along, such that within each group , the value is the same. Later in the derivation, it will turn out, that only the biggest will contribute for large .
Now we go backward, and reverse the Mellin and the Laplace transform:
We can solve this integral with the Residue Theorem, closing the integral path over the negative half of the if . Since all have to be positive, when we close the integral over the negative half, we enclose no residues and the integral comes out as zero. Otherwise each unique , which appears times, being a residual of degree :
When we now reverse the Laplace transform, we only have to integrate up to .
This integral now is asymptotically going towards some number as goes to infinity. So we can pick out the term that is the highest order in as the one with the smallest and .
We can combine this into the Formula for Free Energy.
This expression tells us now, how much mass of the posterior distribution is centered around certain points in parameter space. The leading order term consists of the KL divergence between the training distribution and the distribution of our model. Intuitively, this corresponds to our training loss. In the second term the inversely scales with the multiplicity of the minimum. Intuitively it corresponds to symmetries in the algorithm that the Network implements. The third term scales with the number of parameters that have a minimum of the same multiplicity. Intuitively this gives a set of parameters an extra advantage when multiple parameter sets implement algorithms that independently lead to minimal loss.
- ^
I would have expected, that we integrate the whole vicinity:
This, however, makes the derivation quite ugly:
We can proceed with the rest of the calculation with each summand and just have a smaller . This does not change anything about the leading terms, that are relevant for the Free Energy formula.I am still confused, about why the lecture went from 0 to 1, and would be grateful for an explanation in the comments.
6 comments
Comments sorted by top scores.
comment by Daniel Murfet (dmurfet) · 2024-01-29T23:49:23.673Z · LW(p) · GW(p)
There was a sign error somewhere, you should be getting + lambda and - (m-1). Regarding the integral from 0 to 1, since the powers involved are even you can do that and double it rather than -1 to 1 (sorry if this doesn't map exactly onto your calculation, I didn't read all the details).
Replies from: wuschel-schulz, wuschel-schulz↑ comment by Wuschel Schulz (wuschel-schulz) · 2024-01-29T23:59:18.289Z · LW(p) · GW(p)
Ok, the sign error was just in the end, taking the -log of the result of the integral vs. taking the log. fixed it, thanks.
↑ comment by Wuschel Schulz (wuschel-schulz) · 2024-01-29T23:53:20.979Z · LW(p) · GW(p)
Thanks, Ill look for the sign-error!
I agree, that K is symmetric around our point of integration, big the prior phi is not. We integrate over e-(nk)*phi, wich does not have have to be symetric, right?
↑ comment by Daniel Murfet (dmurfet) · 2024-01-30T00:35:14.968Z · LW(p) · GW(p)
Yes, good point, but if the prior is positive it drops out of the asymptotic as it doesn't contribute to the order of vanishing, so you can just ignore it from the start.
comment by James Camacho (james-camacho) · 2024-01-30T05:07:43.483Z · LW(p) · GW(p)
To see how much the minimal point contributes to the integral we can integrate it in its vicinity
I think you should be looking at the entire stable island, not just integrating from zero to one. I expect you could get a decent approximation with Lie transform perturbation theory, and this looks similar to the idea of macro-states in condensed matter physics, but I'm not knowledgeable in these areas.
comment by James Camacho (james-camacho) · 2024-01-30T04:37:30.235Z · LW(p) · GW(p)
−N∑i=1logp(yi|xi,w)
You have a typo, the equation after Free Energy should start with
Also the third line should be , not minus.
Also, usually people use for model parameters (rather than ). I don't know the etymology, but game theorists use the same letter (for "types" = models of players).