Posts
Comments
Debbie is actually red-blue colorblind, so she thinks her graph looks normal.
I might sound a bit daft here, but do theoretical physicists actually understand what they're talking about? My main concern when trying to learn is it feels like every term is defined with ten other terms, and when you finally get to the root of it the foundations seem pretty shaky. For example, the spin-statistics theorem says particles with half-integer spins are fermions, and full-integer spins are bosons, and is proved starting from a few key postulates:
- Positive energy
- Unique vacuum state
- Lorentz invariance
- "Locality/Causality" (all fields commute or anti-commute).
The fractional quantum Hall effect breaks Lorentz invariance (1+1D universe instead of Lorentz' 3+1D), which is why we see anyons, so obviously the spin-statistics theorem doesn't always hold. However, the fourth postulate shows up everywhere in theoretical physics and the only justification really given is that, "all the particles we see seem to commute or anti-commute"... which is the entire point the spin-statistics theorem is trying to prove.
As I like to say, ignorance does not excuse a sin, it makes two sins: the original, and the fact you didn't put in the effort to know better. So, if you really do just possess a better method of communication—for example, you prefer talking disagreements out over killing each other—you're completely justified in flexing superior on the clueless outsiders. This doesn't mean it will always be effective, just that you're not breaking the "cooperate unless defected against" strategy, and the rest of rational society shouldn't punish you for it.
The current education system focuses almost exclusively on the bottom 20%. If we're expecting a tyranny of the majority, we should see the top and bottom losing out. Also, note that very few children actually have an 80% chance of ending up in the middle 80%, so you would really expect class warfare not a veil of ignorance if people are optimising specifically for their own future children's education.
Yeah, I don't see why either. LessWrong allegedly has a utilitarian culture, and simply from the utilitarian "minimize abuse" perspective, you're spot on. Even if home-schooling has similar or mildly lower rates of abuse, the weight of that abuse is higher.
Grade inflation originally began in the United States due to the Vietnam War draft. University students where exempt from the draft as long as they maintained high enough grades, so students became less willing to stretch their abilities and professors less willing to accurately report their abilities.
The issue is that grades are trying to serve three separate purposes:
-
Regular feedback to students on how well they understand the material.
-
Personal recommendations from teachers to prospective employers/universities.
-
Global comparisons between students.
The administration mostly believe grades serve the third purpose, so they advocate for fudging the numbers. "Last year, our new policies implemented at Goodhart School of Excellence improved the GPA by 0.5 points! Look at how successful our students are compared to others." Teachers, on the other hand, usually want grades to serve the first two purposes. If we want to prevent Goodharting, we can either give teachers back their power, or use other comparison systems.
This is already kind-of a thing. Top universities no longer use GPA as a metric, except as a demerit for imperfect grades, relying more on standardized test scores. There was a brief period where they tried going test-optional, but MIT quickly reversed that trend. I don't think a standardized exam is a perfect solution—how do you compare project- or lab-based classes, like computer science and chemistry? I think in these scenarios we could have students submit their work to third parties, much like the capstone project in AP Seminar & Research.
If we can get administrators to use a better (unfudgible) comparator, I'm not actually terribly worried whether teachers use grades to give regular feedback or recommend their students. It's just important to make sure the comparator is hard enough to actually see a spread, even at the very top. The number of "perfect" ACT scores has increased by 25x in the past 25 years, and I understand why from a money-making perspective, but it's really unfortunate that there are several dozen sixth-graders that could get a 36 in any given section (maybe not the same sixth-graders for each section). How is one school supposed to show it's better at helping these kinds of students than another school? The answer right now is competitions; in seventh grade, I (and half a dozen others) switched schools solely because the other had won the state MATHCOUNTS competition. Word quickly gets around which schools have the best clubs, though it really is just the club, not the classes.
#/media/File:Percent_ACT_Composite_Scores_of_36.svg){kind=link}
I think the reason education got so bad is we don't have accurate signals. Most studies use the passing rate as their metric of "achievement", and that can only see changes among the bottom quintile. Or, they use standardized assessments, which usually do not go higher than the 90th percentile. I wrote a longer post here: https://www.lesswrong.com/posts/LPyqPrgtyWwizJxKP/how-do-we-fix-the-education-crisis
Maybe it's my genome's fault that I care so much about future me. It is very similar to future it, and so it forces me to help it survive, even if in a very different person than I am today.
When I say, "me," I'm talking about my policy, so I'm a little confused when you say I could have been a different snapshot. Tautologically, I cannot. So, if I'm trying to maximize my pleasure, a Veil of Ignorance doesn't make sense. The only case it really applies is when I make pacts like, "if you help bring me into existence, I'll help you maximize your pleasure," except those pacts can't actually form. What really happens is existing people try to bring into existence people that will help them maximize their pleasure, either by having similar policies to their own, or being willing to serve them.
I try to be pragmatic, which means I only find it useful to consider constructive theories; anything else is not defined, and I would say you cannot even talk about them. This is why I take issue with many simple explanations of utilitarianism: people claim to "sum over everyone equally" while not having a good definition for "everyone" or "summing equally". I think these are the two mistakes you are making in your post.
You say something like,
You never had the mechanism to choose who you would be born as, and the simplest option is pure chance.
but you cannot construct this simple option. It is impossible to choose a random number out of infinity where each number appears equally likely, so there must be some weighting mechanism. This gives you a mechanism to choose who you would be born as!
We have to first define what "you" even looks like. I take an approach akin to effective field theory, where I consider you a coarse policy that is being run, which is detailed enough to where it's pragmatically useful to consider. I wrote a longer comment in another thread that explains this well enough. The key takeaway is that we can compare two policies with their KL-divergence, and thus we can compare "current you" to "future you", or "current me" to "current you".
I also hold to your timeless snapshot theory, though I would like to mention animals (including humans) are likely cognitively disabled in this regard. Processes that realized they were timeless snapshots are the same kinds of processes that have an existential crisis instead of enabling more of the same. Anyway, since we're both timeless snapshots, me now and me ten seconds from now are not the same person. However, we have extremely similar policies, and thus are extremely similar people. By choosing to stay alive now, or choosing to think a certain way, I can choose how a very similar being to myself arises!
If you're trying to maximise your pleasure, or your utility, you have to include all the beings that are similar to you in your summation. In particular, you should be weighing like
If is a hedonistic sum utilitarian, then
There's not really a reason would be a hedonistic sum utilitarian, unless that's close to the policy of your current snapshot. Such a policy isn't evolutionarily stable, since it can be invaded by policies that act the same, except purely selfish when they can get away with it. In fact, every policy can be invaded like this. So, over time, the policies similar to you will become more and more selfish. However, you usually don't find yourself to be a selfish egoist, because eventually your snapshot dies and a child with more altruistic brainwashing takes its place as the next most similar policy.
Now, I'd like to poke a little at the difference between selfish egoism and utilitarianism. To make them both constructive, you have to specify who "you" are, what your preferences are, what other people's preferences you care about, and how much you weigh these preferences. You'll end up with a double sum,
Utilitarians claim to weigh others' preferences so much that they actually end up better off by sacrificing for the greater good. They wouldn't even think of it as a sacrifice! But, if it's not a sacrifice, the selfish egoist would take the very same actions! So, are selfish egoists really just sheep in wolves' clothing? People who get a bad rapport, because others assume their preferences are misaligned with theirs, when the utilitarian's are just as often? I think this is the case, but perhaps the difference comes from how they treat fundamental disagreements.
You can build a weight matrix out of everyone's weights for each others' preferences. If we have three people, Alice, Bob, and Eve, a matrix
might say Alice and Bob are mildly friendly to one another, while Eve hates their guts. Since
their utilities are some eigenvector of . There are three eigenvectors:
Alice would prefer they choose the last one, Bob the second, and Eve the first, so this is a fundamental disagreement. I think the only difference that makes sense is to define the selfish egoist as someone who will fight for their preferred utility function, while the utilitarian as someone who will fight for whichever has the highest eigenvalue.
Not quite. I think people working more do get more done, but it ends up lowering wages and decreasing the entropy of resource allocation (concentrates it to the top). If you're looking for the good of the society, you probably want the greatest free energy,
The temperature is usually somewhere between (economic boom) and (recessions), and in the United Kingdom. I couldn't find a figure for the Theil index, but the closest I got is that Croatia's was and Serbia's was in 2011, and for income (not assets) the United Kingdom's was in 2005. So, some very rough estimates for the free energies are
The ideal point for the number of hours worked is where the GDP increases as fast as the temperature times the decrease in entropy. I'm not aware of any studies showing this, but I believe this point is much lower than the number of hours people are currently working in the United Kingdom.
Dan Neidle: The 20,000% spike at £100,000 is absolutely not a joke – someone earning £99,999.99 with two children under three in London will lose an immediate £20k if they earn a penny more. The practical effect is clearer if we plot gross vs net income.
Can't it actually be good to encourage people to not work? I'd imagine if everyone in the United Kingdom worked half the number of hours, salaries wouldn't decrease very much. Their society, as a whole, doesn't need to work so many hours to maintain the quality of life, they only individually need to because they drive each others' wages down.
We know what societies that mutilate prisoners are like, because plenty of them have existed.
This is where I disagree. There are only a few post-industrial socieities that have done this, and they were already rotten before starting the mutilation (e.g. Nazi Germany). There is nothing to imply that mutilation will turn your society rotten, only that when your society becomes rotten mutilation may begin.
So, you're making two rather large claims here that I don't agree with.
When you look at the history of societies that punish people by mutilation, you find that mutilation goes hand in hand (no pun intended) with bad justice systems--dictatorship, corruption, punishment that varies between social classes, lack of due process, etc.
This seems more a quirk of scarcity than due to having a bad justice system. Historically, it wasn't just the tryannical, corrupt governments that punished people with mutlation, it was every civilization on the planet! I think it's due to a combination of (1) hardly having enough food and shelter for the general populace, let alone resources for criminals, and (2) a lower-information, lower-trust society where there's no way to check for a prior criminal history, or prevent them from committing more crimes after they leave jail. Chopping off a hand or branding them was a cheap way to dole out punishment and warn others to be extra cautious in their vicinity.
Actual humans aren't capable of implementing a justice system which punishes by mutilation but does so in a way that you could argue is fair.
Obviously it isn't possible for imperfectly rational agents to be perfectly fair, but I don't see why you're applying this only to a mutalitive justice system. This is true of our current justice system or when you buy groceries at the store. The issue isn't making mistakes, the issue is the frequency of mistakes. They create an entropic force that pushes you out of good equilibriums, which is why it's good to have systems that fail gracefully.
I don't see what problems mutilative justice would have over incarcerative. We could have the exact same court procedures, just change the law on the books from 3–5 years to 3–5 fingers. Is the issue that bodily disfigurement is more visible than incarceration? People would have to actually see how they're ruining other people's lives in retribution? Or are you just stating, without any justification, that when we move from incarceration to mutilation, our judges, jurors, and lawyers will suddenly become wholly irrational beings? That it's just "human nature"? To put it in your words: that opinion is bizarre.
I don't understand your objection. Would you rather go to prison for five years or lose a hand? Would you rather unfairly be imprisoned for five years, and then be paid $10mn in compensation, or unfairly have your hand chopped off and paid $10mn in compensation? I think most people would prefer mutilation over losing years of their lives, especially when it was a mistake. Is your point that, if someone is in prison, they can be going through the appeal process, and thus, if a mistake occurs they'll be less damaged? Because currently it takes over eight years for the average person to be exonerated (source). Since this only takes into account those exonerated, the average innocent person sits there much longer.
I do agree that bodily mutilation can be abused more than imprisonment since you can only take political prisoners as long as you have power, but it's not like tyrants are using bodily mutilation as punishment anyway. They just throw them to the Gulags and call it a day. They don't have to wait 40 years for it to become permanent.
Similar disclaimer: don't assume these are my opinions. I'm merely advocating for a devil.
If we're going for efficiency, I feel like we can get most of the safety gains with tamer measures. For example, you could cut off a petty thief's hand, or castrate a rapist. The actual procedure would be about as expensive as execution, but if a mistake was made there is still a living person to pay reparations to. I think you could also make the argument that this is less cruel than imprisoning someone for years—after all, people have a "right to life, liberty, and the pursuit of happiness", not a right to all their limbs and genitals.
Another thing we can do is punish not only the criminal, but their friends and family too. We can model people as having the policy to take certain actions in a given environment. The ultimate goal of the justice system is to decrease the weight of certain defective policies in the general populace, either through threat, force, or elimination. When we get good enough mindreaders, we can just directly compare each person's policy to the defective ones, and change the environment to mitigate defection. Until then, we have to make do with approximations, and one's culture, especially the shared culture among friends and family, is a very good measure for how similar two people's policies will be. So, if we find someone defecting, it makes sense to punish not only them, but their friends and family for a couple generations too.
If you're going to be talking about trust in society, you should definitely take a look at Gossner's Simple Bounds on the Value of a Reputation.
The bottom row is close to what I imagine, but without IO ports on the same edge being allowed to connect to each other (though that is also an interesting problem). These would be the three diagrams for the square:
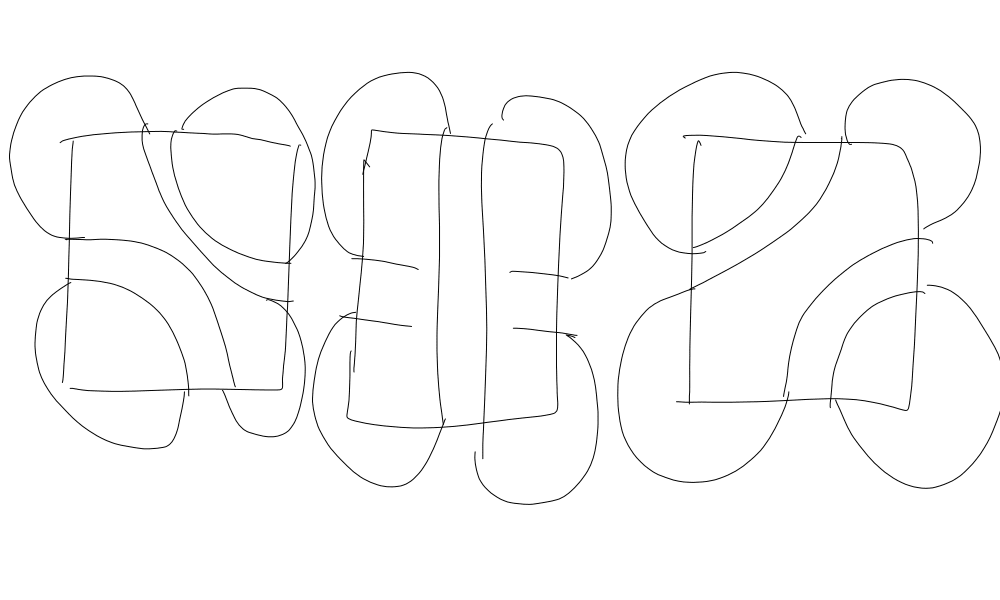
The middle one makes a single loop which is one-third of them, and in this case. My guess for how to prove the recurrence is to "glue" polygons together:
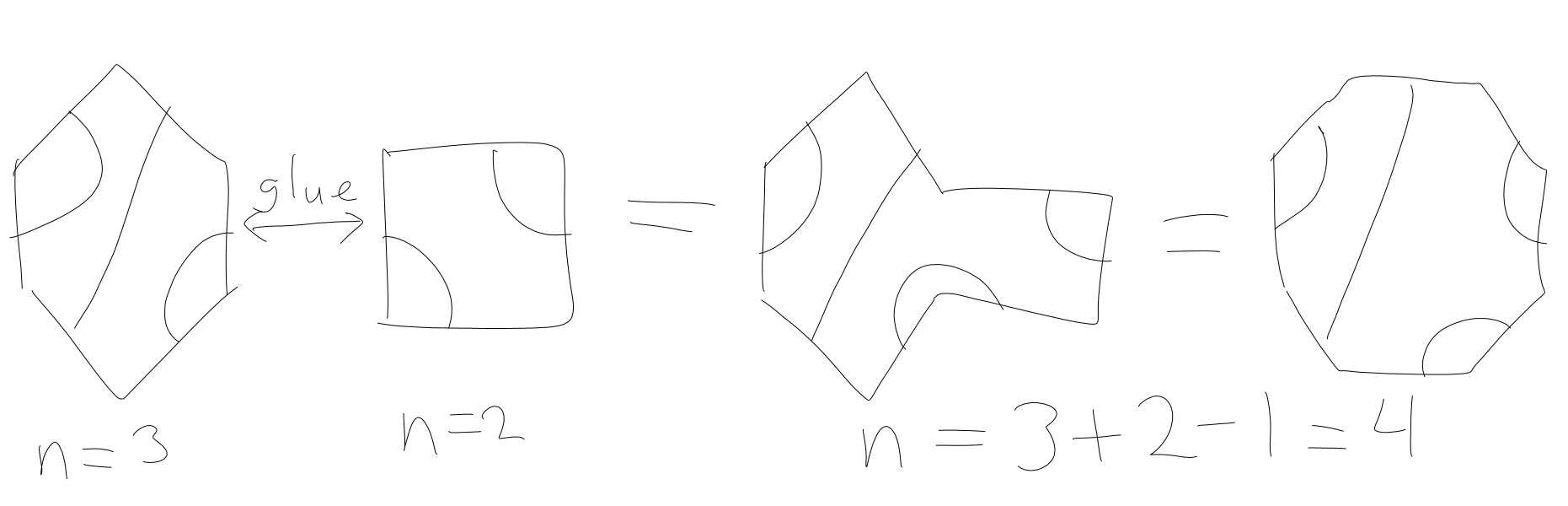
There are pairs of sizes we can glue together (if you're okay with -sided polygons), but I haven't made much progress in this direction. All I've found is gluing two polygons together decreases the number of loops by zero, one or two.
So, I'm actually thinking about something closer to this for "one loop":
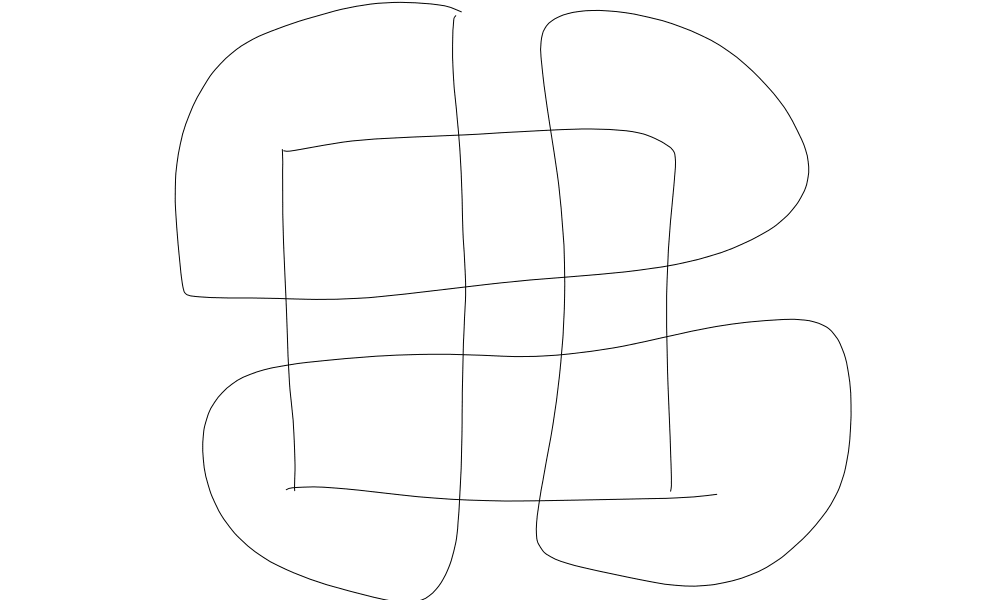
This is on a single square tile, with four ports of entry/exit. What I've done is doubled the rope in each connection, so there is one connection going from the top to the bottom and a different connection going from the bottom to the top. Then you tie off the end of each connection with the start of the connection just clockwise to it.
Some friends at MIT solved this problem for a maths class, and it turns out there's a nice recurrence. Let be the probability there are loops in a random knot on a single tile with sides. Then
So, if you're looking for exactly one loop, you'd have
I can't really explain where this recurrence comes from; their proof was twenty pages long. It's also too complicated to really apply to multiple tiles. But, maybe there's a more elementary proof for this recursion, and something similar can be done for multiple tiles.
Your math is correct, it's and for the number of tiles and connections. I wrote some code here:
https://github.com/programjames/einstein_tiling
Here's an example:

An interesting question I have is: suppose we tied off the ends going clockwise around the perimeter of the figure. What is the probability we have exactly one loop of thread, and what is the expected number of loops? This is a very difficult problem; I know several MIT math students who spent several months on a slightly simpler problem.
The sidelengths for the Einstein tile are all either or , except for a single side of length . I think it makes more sense to treat that side as two sides, with a angle between them. Then you would get fourteen entry/exit points:

The aperiodic tiling from the paper cannot be put onto a hexagonal grid, and some of the tiles are flipped vertically, so you need every edge to have an entry/exit to make a Celtic knot out of it. Also, I would recommend using rather than so the arcs turn out pretty:

I'm not entirely sure what you've looked at in the literature; have you seen "Direct Validation of the Information Bottleneck Principle for Deep Nets" (Elad et al.)? They use the Fenchel conjugate
\[\mathrm{KL}(P||Q) = \sup_{f} [\mathbb{E}_P[f]-\log (\mathbb{E}_Q[e^f])]\]This turns finding the KL-divergence into an optimisation problem for \(f^*(x) = \log \frac{p(x)}{q(x)}\). Since
\[I(X;Y)=\mathrm{KL}(P_{X,Y}||P_{X\otimes Y}),\]you can train a neural network to predict the mutual information. For the information bottleneck, you would train two additional networks. Ideal lossy compression maximises the information bottleneck, so this can be used as regularization for autoencoders. I did this for a twenty-bit autoencoder of MNIST (code). Here are the encodings without mutual information regularization, and then with it:
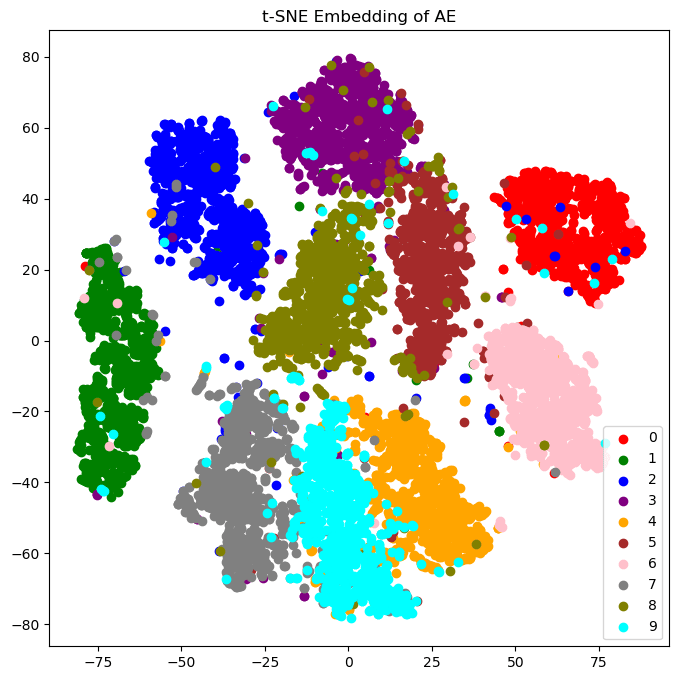
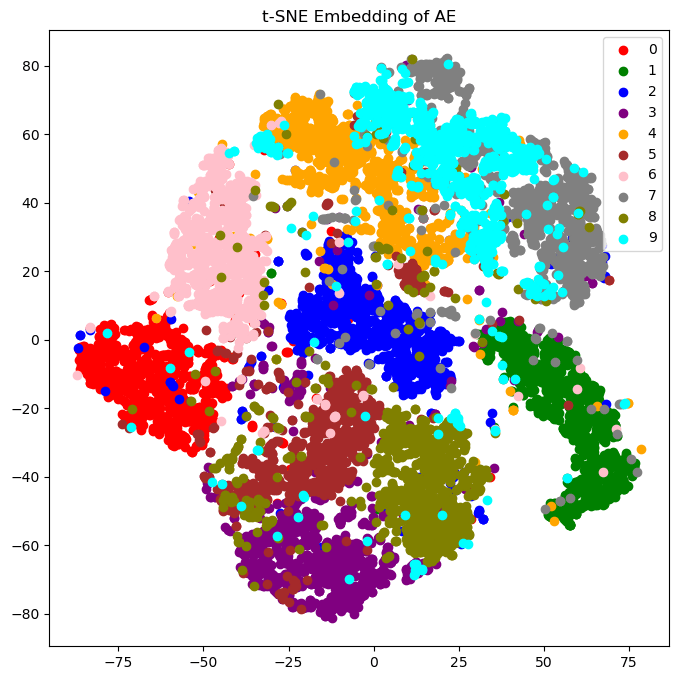
Notice how the digits are more "spread out" with regularization. This is exactly the benefit variational autoencoders give, but actually based in theory! In this case, my randomness comes from the softmax choice for each bit, but you could also use continuous latents like Gaussians. In fact, you could even have a deterministic encoder, since the mutual information predictor network is adversarial, not omniscient. The encoder can fool it during training by having small updates in its weights make large updates in the latent space, which means (1) it's essentially random in the same way lava lamps are random, (2) the decoder will learn to ignore noise, and (3) the initial distribution of encoder weights will concentrate around "spines" in the loss landscape, which have lots of symmetries in all dimensions except the important features you're encoding.
The mutual information is cooperative for the decoder network, which means the decoder should be deterministic. Since mutual information is convex, i.e. if we had two decoders \(\phi_1, \phi_2: Z\to Y\), then
\[\lambda I(Z; \phi_1(Z)) + (1-\lambda) I(Z; \phi_2(Z)) \ge I(Z; (\lambda\phi_1 + (1-\lambda)\phi_2)(Z)).\]Every stochastic decoder could be written as a sum of deterministic ones, so you might as well use the best deterministic decoder. Then
\[I(Z; \phi(Z)) = H(\phi(Z)) \cancel{-H(\phi(Z)|Z)}\]so you're really just adding in the entropy of the decoded distribution. The paper "The Deterministic Information Bottleneck" (Strauss & Schwab) argues that the encoder \(\psi: X\to Z\) should also be deterministic, since maximising
\[-\beta I(X; \psi(X)) = \beta[H(\psi(X)|X) - H(\psi(X))]\]seems to reward adding noise irrelevant to \(X\). But that misses the point; you want to be overwriting unimportant features of the image with noise. It's more clear this is happening if you use the identity
\[-\beta I(X;\psi(X)) = \beta H(X|\psi(X))\cancel{ - \beta H(X)}\](the second term is constant). This is the same idea behind variational autoencoders, but they use \(\mathrm{KL}(\psi(X)||\mathcal{N}(0, 1))\) as a cheap proxy to \(H(X|\psi(X))\).
Reversible networks (even when trained) for example have the same partition induced even if you keep stacking more layers, so from the perspective of information theory, everything looks the same
I don't think this is true? The differential entropy changes, even if you use a reversible map:
where is the Jacobian of your map. Features that are "squeezed together" are less usable, and you end up with a smaller entropy. Similarly, "unsqueezing" certain features, or examining them more closely, gives a higher entropy.
A couple things to add:
- Since every invertible square matrix can be decomposed as , you don't actually need a unitary assumption. You can just say that after billions of years, all but the largest Z-matrices have died out.
- There's another tie between statistics and quantum evolution called the Wick rotation. If you set , then so the inverse-temperature is literally imaginary time! You can recover the Boltzmann distribution by looking at the expected number of particles in each state: where is the th eigenvalue (energy in the th state).
Why are conservatives for punitive correction while progressives do not think it works? I think this can be explained by the difference between stable equilibria and saddle points.
If you have a system where people make random "mistakes" an amount of the time, the stable points are known as trembling-hand equilibria. Or, similarly, if they transition to different policies some H of the time, you get some thermodynamic distribution. In both models, your system is exponentially more likely to end up in states it is hard to transition out of (Ellison's lemma & the Boltzmann distribution respectively). Societies will usually spend a lot of time at a stable equilibrium, and then rapidly transition to a new one when the temperature increaes, in a way akin to simulated annealing. Note that we're currently in one of those transition periods, so if you want to shape the next couple decades of policy, now is the time to get into politics.
In stable equilibria, punishment works. It essentially decreases so it's less likely for too many people to make a mistake at the same time, conserving the equilibrium. But progressives are climbing a narrow mountain pass, not sitting at the top of a local maximum. It's much easier for disaffected members to shove society off the pass, so a policy of punishing defectors is not stable—the defectors can just defect more and win. This is why punishment doesn't work; the only way forward is if everyone goes along with the plan.
Oh, I did misread your post. I thought these were just people on some mailing list that had no relation to HPMOR/EA and you were planning on sending them books as advertising. This makes a lot more sense, and I'm much more cool with this form of advertising.
EDIT: I will point out, it still does scream "cult tactic" to me, probably because it is targeting specific people who do not know there is a campaign behind the scenes to get them to join the group. I don't think it is wrong to advertise to people who have given their consent, but I do think it is dangerous to have a culture where you discuss how to best advertise to specific people.
Recruitment is only good because it serves your ideology. However, almost every group could claim the same, and most people don't want to be spammed by thousands of groups trying to recruit them every year. Thus, when you send that email, you are defecting. Maybe you believe it is okay to defect, because your group is exceptional, but that is the trademark belief of a cult!
This screams "cult tactic" to me. Is the point of EA to identify high-value targets and get them to help the EA community, or to target high-value projects that help the broader community?
I'd recommend against that. It's too similar to Mormonism w/ Marriott.
Given that Euan begins his post with an axiom of materialism, it's referenced in the quote I'm responding to, and I'm responding to Euan, not talking to a general audience, I think it's your fault for intepreting it as "most people, full stop".
Dollars are essentially energy from physics, and trades are state transitions. So, in expectation entropy will increase. Suppose person controls a proportion of the dollars. In an efficient market, entropy will be maximal, so we want to find the distribution
For a given Total Societal Wealth Generation, this is the Boltzmann distribution
where is the temperature (frequency of trades). I subsumed as a single constant in my earlier comment to simplify matters. I was incorrect in my earlier statement; if my is two higher than yours (not twice as large), I should control times as many dollars. I suspect some of the rise in CEO-to-worker compensation comes from increasing, some from a less conscientious society, and some from exploitation.
Exploitation is using a superior negotiating position to inflict great costs on someone else, at small benefit to yourself.
If someone is inflicting any cost on me for their own benefit, that is not a mutually beneficial trade, so your definition doesn't solve the problem. You cannot just look at subtrades either—after all, you can always break up every trade into two transactions where you first only pay a cost, and then only get a benefit at someone else's expense.
My definition is closer to this:
A trade is exploitative when it decreases a society's wealth generating ability.
When people are paid less, they are less able to invest in the future. This includes upskilling, finding more promising ventures, starting their own business, or raising children. Some people are better at this than others, and an efficient market would give them control of more money to show this (roughly exponential). For example, if you are twice as good at wealth-creating than me, you should have about seven times as many dollars. If I make a trade with you, I should keep about 12% of the wealth created. Of course, this has to be after costs are taken into account.
The cost of subsistence is pretty negligible—maybe a few thousand dollars per year in the rural United States. Any other costs a company imposes on you should be paid before you distribute the pie you created. So, if they ask you to live in San Francisco and drive a car, that is easily $50,000/yr in before-earnings costs. Now, suppose your work as a developer nets them $500,000/yr. You should be making about $100,000/yr after taxes, which would be around $200,000/yr before taxes. If you are making less, there are three scenarios:
- Your company is more than twice as good as you at wealth generation.
- You are creating less than $500,000/yr of value.
- You are being exploited!
For humans from our world, these questions do have answers—complicated answers having to do with things like map–territory confusions that make receiving bad news seem like a bad event (rather than the good event of learning information about how things were already bad, whether or not you knew it), and how it's advantageous for others to have positive-valence false beliefs about oneself.
If you have bad characteristics (e.g. you steal from your acquaintances), isn't it in your best interest to make sure this doesn't become common knowledge? You don't want to normalize people pointing out your flaws, so you get mad at people for gossiping behind your back, or saying rude things in front of you.
If you're not already aware of the information bottleneck, I'd recommend The Information Bottleneck Method, Efficient Compression in Color Naming and its Evolution, and Direct Validation of the Information Bottleneck Principle for Deep Nets. You can use this with routing for forward training.
EDIT: Probably wasn't super clear why you should look into this. An optimal autoencoder should try to maximize the mutual information between the encoding and the original image. You wouldn't even need to train a decoder at the same time as the encoder! But, unfortunately, it's pretty expensive to even approximate the mutual information. Maybe, if you route to different neurons based on image captions, you could significantly decrease this cost.
And I migrated my comment.
If you're not already aware of the information bottleneck, I'd recommend The Information Bottleneck Method, Efficient Compression in Color Naming and its Evolution, and Direct Validation of the Information Bottleneck Principle for Deep Nets. You can use this with routing for forward training.
Maybe, there's an evolutionary advantage to thinking of yourself as distinct from the surrounding universe, that way your brain can simulate counterfactual worlds where you might take different actions. Will you actually take different actions? No, but thinking will make the one action you do take better. Since people are hardwired to think their observations are not necessarily interactions, updating in the other direction has significant surprisal.
I think physicists like to think of the universe through a "natural laws" perspective, where things should work the same whether or not they were there to look at them. So, it seems strange when things do work differently when they look at them.
The reason wave function collapse is so surprising, is because not collapsing seems to be the norm. In fact, the best gravimeters are made by interfering the wavefunctions of entire molecules (ref: atom interferometer). We only see "wave function collapse" in particular kinds of operations, which we then define as observations. So, it isn't surprising that we observe wave function collapse—that's how the word "observe" is defined. What is surprising is that collapse even occurs to be observed, when we know it is not how the universe usually operates.
and that's because I think you don't understand them either.
What am I supposed to do with this? The one effect this has is to piss me off and make me less interested in engaging with anything you've said.
Why is that the one effect? Jordan Peterson says that the one answer he routinely gives to Christians and atheists that piss them off is, "what do you mean by that?" In an interview with Alex O'Conner he says,
So people will say, well, do you believe that happened literally, historically? It's like, well, yes, I believe that it's okay. Okay. What do you mean by that? That you believe that exactly. Yeah. So, so you tell me you're there in the way that you describe it.
Right, right. What do you see? What are the fish doing exactly? And the answer is you don't know. You have no notion about it at all. You have no theory about it. Sure. You have no theory about it. So your belief is, what's your belief exactly?
(25:19–25:36, The Jordan B. Peterson Podcast - 451. Navigating Belief, Skepticism, and the Afterlife w/ Alex O'Connor)
Sure, this pisses off a lot of people, but it also gets some people thinking about what they actually mean. So, there's your answer: you're supposed to go back and figure out what you mean. A side benefit is if it pisses you off, maybe I won't see your writing anymore. I'm pretty annoyed at how the quality of posts has gone down on this website in the past few years.
But my view is that maths and computation are not the only symbols upon which constructive discussion can be built.
I find it useful to take an axiom of extensionality—if I cannot distinguish between two things in any way, I may as well consider them the same thing for all that it could affect me. Given maths/computation/logic is the process of asserting things are the same or different, it seems to me to be tautologically true that maths and computaiton are the only symbols upon which useful discussion can be built.
I'm not arguing against the claim that you could "define consciousness with a computation". I am arguing against the claim that "consciousness is computation". These are distinct claims.
Maybe you want to include some undefinable aspect to consciousness. But anytime it functions differently, you can use that to modify your definition. I don't think the adherents for computational functionalism, or even a computational universe, need to claim it encapsulates everything there could possibly be in the territory. Only that it encapsulates anything you can perceive in the territory.
There is an objective fact-of-the-matter whether a conscious experience is occurring, and what that experience is. It is not observer-dependent. It is not down to interpretation. It is an intrinsic property of a system.
I believe this is your definition of real consciousness? This tells me properties about consciousness, but doesn't really help me define consciousness. It's intrinsic and objective, but what is it? For example, if I told you that the Serpinski triangle is created by combining three copies of itself, I still don't know what it actually looks like. If I want to work with it, I need to know how the base case is defined. Once you have a definition, you've invented computational functionalism (for the Serpinski triangle, for consciousness, for the universe at large).
I think I have a sense of what's happening here. You don't consider an argument precise enough unless I define things in more mathematical terms.
Yes, exactly! To be precise, I don't consider an argument useful unless it is defined through a constructive logic (e.g. mathematics through ZF set theory).
If you actually want to know the answer: when you define the terms properly (i.e. KL-divergence from the firings that would have happened), the entire paradox goes away.
I'd be excited to actually see this counterargument. Is it written down anywhere that you can link to?
Note: this assumes computational functionalism.
I haven't seen it written down explicitly anywhere, but I've seen echoes of it here and there. Essentially, in RL, agents are defined via their policies. If you want to modify the agent to be good at a particular task, while still being pretty much the "same agent", you add a KL-divergence anchor term:
This is known as piKL and was used for Diplomacy, where it's important to act similarly to humans. When we think of consciousness or the mind, we can divide thoughts into two categories: the self-sustaining (memes/particles/holonomies), and noise (temperature). Temperature just makes things fuzzy, while memes will proscribe specific actions. On a broad scale, maybe they tell your body to take specific actions, like jumping in front of a trolley. Let's call these "macrostates". Since a lot of memes will produce the same macrostates, let's call them "microstates". When comparing two consciousnesses, we want to see how well the microstates match up.
The only way we can distinguish between microstates is by increasing the number of macrostates—maybe looking at neuron firings rather than body movements. So, using our axiom of reducibilityextensionality, to determine how "different" two things are, the best we can do is count the difference in the number of microstates filling each macrostate. Actually, we could scale the microstate counts and temperature by some constant factor and end up with the same distribution, so it's better to look at the difference in their logarithms. This is exactly the cross-entropy. The KL-divergence subtracts off the entropy of the anchor policy (the thing you're comparing to), but that's just a constant.
So, let's apply this to the paradox. Suppose my brain is slowly being replaced by silicon, and I'm worried about losing consciousness. I acknowledge there are impossible-to-determine properties that I could be losing; maybe the gods do not let cyborgs into heaven. However, that isn't useful to include in my definition of consciousness. All the useful properties can be observed, and I can measure how much they are changing with a KL-divergence.
When it comes to other people, I pretty much don't care if they're p-zombies, only how their actions effect me. So a very good definition for their consciousness is simply the equivalence class of programs that would produce the actions I see them taking. If they start acting radically different, I would expect this class to have changed, i.e. their consciousness is different. I've heard some people care about the substrate their program runs on. "It wouldn't be me if the program was run by a bunch of aliens waving yellow and blue flags around." I think that's fine. They've merely committed suicide in all the worlds their substrate didn't align with their preferences. They could similarly play the quantum lottery for a billion dollars, though this isn't a great way to ensure your program's proliferation.
In response to the two reactions:
- Why do you say, "Besides, most people actually take the opposite approch: computation is the most "real" thing out there, and the universe—and any consciouses therein—arise from it."
Euan McLean said at the top of his post he was assuming a materialist perspective. If you believe there exists "a map between the third-person properties of a physical system and whether or not it has phenomenal consciousness" you believe you can define consciousness with a computation. In fact, anytime you believe something can be explicitly defined and manipulated, you've invented a logic and computer. So, most people who take the materialist perspective believe the material world comes from a sort of "computational universe", e.g. Tegmark IV.
- Soldier mindset.
Here's a soldier mindset: you're wrong, and I'm much more confident on this than you are. This person's thinking is very loosey-goosey and someone needed to point it out. His posts are mostly fluff with paradoxes and questions that would be completely answerable (or at least interesting) if he deleted half the paragraphs and tried to pin down definitions before running rampant with them.
Also, I think I can point to specific things that you might consider soldier mindset. For example,
It's such a loose idea, which makes it harder to look at it critically. I don't really understand the point of this thought experiment, because if it wasn't phrased in such a mysterious manner, it wouldn't seem relevant to computational functionalism.
If you actually want to know the answer: when you define the terms properly (i.e. KL-divergence from the firings that would have happened), the entire paradox goes away. I wasn't giving him the answer, because his entire post is full of this same error: not defining his terms, running rampant with them, and then being shocked when things don't make sense.
I don't like this writing style. It feels like you are saying a lot of things, without trying to demarcate boundaries for what you actually mean, and I also don't see you criticizing your sentences before you put them down. For example, with these two paragraphs:
Surely there can’t be a single neuron replacement that turns you into a philosophical zombie? That would mean your consciousness was reliant on that single neuron, which seems implausible.
The other option is that your consciousness gradually fades over the course of the operations. But surely you would notice that your experience was gradually fading and report it? To not notice the fading would be a catastrophic failure of introspection.
If you're aware that there is a map and a territory, you should never be dealing with absolutes like, "a single neuron..." You're right that the only other option (I would say, the only option) is your consciousness gradually fades away, but what do you mean by that? It's such a loose idea, which makes it harder to look at it critically. I don't really understand the point of this thought experiment, because if it wasn't phrased in such a mysterious manner, it wouldn't seem relevant to computational functionalism.
I also don't understand a single one of your arguments against computational functionalism, and that's because I think you don't understand them either. For example,
In the theoretical CF post, I give a more abstract argument against the CF classifier. I argue that computation is fuzzy, it’s a property of our map of a system rather than the territory. In contrast, given my realist assumptions above, phenomenal consciousness is not a fuzzy property of a map, it is the territory. So consciousness cannot be computation.
You can't just claim that consciousness is "real" and computation is not, and thus they're distinct. You haven't even defined what "real" is. Besides, most people actually take the opposite approch: computation is the most "real" thing out there, and the universe—and any consciouses therein—arise from it. Finally, how is computation being fuzzy even related to this question? Consciousness can be the same way.
I did some more thinking, and realized particles are the irreps of the Poincaire group. I wrote up some more here, though this isn't complete yet:
https://www.lesswrong.com/posts/LpcEstrPpPkygzkqd/fractals-to-quasiparticles
Risk is a great study into why selfish egoism fails.
I took an ethics class at university, and mostly came to the opinion that morality was utilitarianism with an added deontological rule to not impose negative externalities on others. I.e. "Help others, but if you don't, at least don't hurt them." Both of these are tricky, because anytime you try to "sum over everyone" or have any sort of "universal rule" logic breaks down (due to Descartes' evil demon and Russell's vicious circle). Really, selfish egoism seemed to make more logical sense, but it doesn't have a pro-social bias, so it makes less sense to adopt when considering how to interact with or create a society.
The great thing about societies is we're almost always playing positive-sum games. After all, those that aren't don't last very long. Even if my ethics wasn't well-defined, the actions proscribed will usually be pretty good ones, so it's usually not useful to try to refine that definition. Plus, societies come with cultures that have evolved for thousands of years to bias people to act decently, often without needing to think how this relates to "ethics". For example, many religious rules seem mildly ridiculous nowadays, but thousands of years ago they didn't need to know why cooking a goatchild in its mother's milk was wrong, just to not do it.
Well, all of this breaks down when you're playing Risk. The scarcity of resources is very apparent to all the players, which limits the possibility for positive-sum games. Sure, you can help each other manoeuvre your stacks at the beginning of the game, or one-two slam the third and fourth players, but every time you cooperate with someone else, you're defecting against everyone else. This is probably why everyone hates turtles so much: they only cooperate with themselves, which means they're defecting against every other player.
I used to be more forgiving of mistakes or idiocracy. After all, everyone makes mistakes, and you can't expect people to take the correct actions if they don't know what they are! Shouldn't the intentions matter more? Now, I disagree. If you can't work with me, for whatever reason, I have to take you down.
One game in particular comes to mind. I had the North American position and signalled two or three times to the European and Africa+SA players to help me slam the Australian player. The Africa player had to go first, due to turn order and having 30 more troops; instead, they just sat and passed. The Australian player was obviously displeased about my intentions, and positioned their troops to take me out, so I broke SA and repositioned my troops there. What followed was a huge reshuffle (that the Africa player made take wayy longer due to their noobery), and eventually the European player died off. Then, again, I signal to the former Africa player to kill the Australian player, and again, they just sit and take a card. I couldn't work with them, because they were being stupid and selfish. 'And', because that kind of selfishness is rather stupid. Since I couldn't go first + second with them, I was forced to slam into them to guarantee second place. If they were smart about being selfish, they would have cooperated with me.
As that last sentence alludes to, selfish egoism seems to make a lot of sense for a moral understanding of Risk. Something I've noticed is almost all the Grandmasters that comment on the subreddit, or record on YouTube seem to have similar ideas:
- "Alliances" are for coordination, not allegiances.
- Why wouldn't you kill someone on twenty troops for five cards?
- It's fine to manipulate your opponents into killing each other, especially if they don't find out. For example, stacking next to a bot to get your ally's troops killed, or cardblocking the SA position when in Europe and allied with NA and Africa.
This makes the stupidity issue almost more of a crime than intentionally harming someone. If someone plays well and punishes my greed, I can respect that. They want winning chances, so if I give them winning chances, they'll work with me. But if I'm stupid, I might suicide my troops into them, ruining both of our games. Or, if someone gets their Asia position knocked out by Europe, I can understand them going through my NA/Africa bonus to get a new stack out. But, they're ruining both of our games if they just sit on Central America or North Africa. And, since I'm smart enough, I would break the Europe bonus in retaliation. If everyone were smart and knew everyone else was smart, the Europe player wouldn't knock out the SA player's Asia stack. People wouldn't greed for both Americas while I'm sitting in Africa. So on and so forth. Really, most of the "moral wrongs" we feel when playing Risk only occur because one of us isn't smart enough!
My view on ethics has shifted; maybe smart selfish egoism really is a decent ethics to live by. However, also evidenced by Risk, most people aren't smart enough to work with, and most that are took awhile to get there. I think utilitaranism/deontology works better because people don't need to think as hard to take good actions. Even if they aren't necessarily the best, they're far better than most people would come up with!
I wrote up my explanation as its own post here: https://www.lesswrong.com/posts/LpcEstrPpPkygzkqd/fractals-to-quasiparticles
I think you're looking for the irreducible representations of (edit: for 1D, ). I'll come back and explain this later, but it's going to take awhile to write up.
Utilitarianism is usually introduced as summing "equally" between people, but we all know some arrangements of atoms are more equal than others.
How do you choose to sum the utility when playing a Prisoner's Dilemma against a rock?
Is there a difference between utilitarianism and selfish egoism?
For utilitarianism, you need to choose a utility function. This is entirely based on your preferences: what you value, and who you value get weighed and summed to create your utility function. I don't see how this differs from selfish egoism: you decide what and who you value, and take actions that maximize these values.
Each doctrine comes with a little brainwashing. Utilitarianism is usually introduced as summing "equally" between people, but we all know some arrangements of atoms are more equal than others. However, introducing it this way naturally leads people to look for cooperation and value others more, both of which increase their chance of surviving.
Ayn Rand was rather reactionary against religion and its associated sacrificial behavior, so selfish egoism is often introduced as a reaction:
- When you die, everything is over for you. Therefore, your survival is paramount.
- You get nothing out of sacrificing your values. Therefore, you should only do things that benefit you.
Kant claimed people are good only by their strength of will. Wanting to help someone is a selfish action, and therefore not good. Rand takes the more individually rational approach: wanting to help someone makes you good, while helping someone against your interests is self-destructive. To be fair to Kant, when most agents are highly irrational your society will do better with universal laws than moral anarchy. This is also probably why selfish egoism gets a bad rapport: even if you are a selfish egoist, you want to influence your society to be more Kantian. Or, at the very least, like those utilitarians. They at least claim to value others.
However, I think rational utilitarians really are the same as rational selfish egoists. A rational selfish egoist would choose to look for cooperation. When they have fundamental disagreements with cooperative others, they would modify their values to care more about their counterpart so they both win. In the utilitarian bias, it's more difficult to realize when to change your utility function, while it's a little easier with selfish egoism. After all, the most important thing is survival, not utility.
I think both philosophies are slightly wrong. You shouldn't care about survival per se, but expected discounted future entropy (i.e. how well you proliferate). This will obviously drop to zero if you die, but having a fulfilling fifty years of experiences is probably more important than seventy years in a 2x2 box. Utility is merely a weight on your chances of survival, and thus future entropy. ClosedAI is close with their soft actor-critic, though they say it's entropy-regularized reinforcement learning. In reality, all reinforcement learning is maximizing energy-regularized entropy.