Superintelligence 27: Pathways and enablers
post by KatjaGrace · 2015-03-17T01:00:51.539Z · LW · GW · Legacy · 21 commentsContents
Summary Another view Notes 1. How is hardware progressing? 2. Hardware-software indifference curves 3. The potential for discontinuous AI progress 4. The person-affecting perspective favors speed less as other prospects improve 5. It seems unclear that an emulation transition would be slower than an AI transition. 6. Beware of brittle arguments In-depth investigations How to proceed None 21 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the twenty-seventh section in the reading guide: Pathways and enablers.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: “Pathways and enablers” from Chapter 14
Summary
- Is hardware progress good?
- Hardware progress means machine intelligence will arrive sooner, which is probably bad.
- More hardware at a given point means less understanding is likely to be needed to build machine intelligence, and brute-force techniques are more likely to be used. These probably increase danger.
- More hardware progress suggests there will be more hardware overhang when machine intelligence is developed, and thus a faster intelligence explosion. This seems good inasmuch as it brings a higher chance of a singleton, but bad in other ways:
- Less opportunity to respond during the transition
- Less possibility of constraining how much hardware an AI can reach
- Flattens the playing field, allowing small projects a better chance. These are less likely to be safety-conscious.
- Hardware has other indirect effects, e.g. it allowed the internet, which contributes substantially to work like this. But perhaps we have enough hardware now for such things.
- On balance, more hardware seems bad, on the impersonal perspective.
- Would brain emulation be a good thing to happen?
- Brain emulation is coupled with 'neuromorphic' AI: if we try to build the former, we may get the latter. This is probably bad.
- If we achieved brain emulations, would this be safer than AI? Three putative benefits:
- "The performance of brain emulations is better understood"
- However we have less idea how modified emulations would behave
- Also, AI can be carefully designed to be understood
- "Emulations would inherit human values"
- This might require higher fidelity than making an economically functional agent
- Humans are not that nice, often. It's not clear that human nature is a desirable template.
- "Emulations might produce a slower take-off"
- It isn't clear why it would be slower. Perhaps emulations would be less efficient, and so there would be less hardware overhang. Or perhaps because emulations would not be qualitatively much better than humans, just faster and more populous of them
- A slower takeoff may lead to better control
- However it also means more chance of a multipolar outcome, and that seems bad.
- "The performance of brain emulations is better understood"
- If brain emulations are developed before AI, there may be a second transition to AI later.
- A second transition should be less explosive, because emulations are already many and fast relative to the new AI.
- The control problem is probably easier if the cognitive differences are smaller between the controlling entities and the AI.
- If emulations are smarter than humans, this would have some of the same benefits as cognitive enhancement, in the second transition.
- Emulations would extend the lead of the frontrunner in developing emulation technology, potentially allowing that group to develop AI with little disturbance from others.
- On balance, brain emulation probably reduces the risk from the first transition, but added to a second transition this is unclear.
- Promoting brain emulation is better if:
- You are pessimistic about human resolution of control problem
- You are less concerned about neuromorphic AI, a second transition, and multipolar outcomes
- You expect the timing of brain emulations and AI development to be close
- You prefer superintelligence to arrive neither very early nor very late
- The person affecting perspective favors speed: present people are at risk of dying in the next century, and may be saved by advanced technology
Another view
I talked to Kenzi Amodei about her thoughts on this section. Here is a summary of her disagreements:
Bostrom argues that we probably shouldn't celebrate advances in computer hardware. This seems probably right, but here are counter-considerations to a couple of his arguments.
The great filter
A big reason Bostrom finds fast hardware progress to be broadly undesirable is that he judges the state risks from sitting around in our pre-AI situation to be low, relative to the step risk from AI. But the so called 'Great Filter' gives us reason to question this assessment.
The argument goes like this. Observe that there are a lot of stars (we can detect about ~10^22 of them). Next, note that we have never seen any alien civilizations, or distant suggestions of them. There might be aliens out there somewhere, but they certainly haven't gone out and colonized the universe enough that we would notice them (see 'The Eerie Silence' for further discussion of how we might observe aliens).
This implies that somewhere on the path between a star existing, and it being home to a civilization that ventures out and colonizes much of space, there is a 'Great Filter': at least one step that is hard to get past. 1/10^22 hard to get past. We know of somewhat hard steps at the start: a star might not have planets, or the planets may not be suitable for life. We don't know how hard it is for life to start: this step could be most of the filter for all we know.
If the filter is a step we have passed, there is nothing to worry about. But if it is a step in our future, then probably we will fail at it, like everyone else. And things that stop us from visibly colonizing the stars are may well be existential risks.
At least one way of understanding anthropic reasoning suggests the filter is much more likely to be at a step in our future. Put simply, one is much more likely to find oneself in our current situation if being killed off on the way here is unlikely.
So what could this filter be? One thing we know is that it probably isn't AI risk, at least of the powerful, tile-the-universe-with-optimal-computations, sort that Bostrom describes. A rogue singleton colonizing the universe would be just as visible as its alien forebears colonizing the universe. From the perspective of the Great Filter, either one would be a 'success'. But there are no successes that we can see.
What's more, if we expect to be fairly safe once we have a successful superintelligent singleton, then this points at risks arising before AI.
So overall this argument suggests that AI is less concerning than we think and that other risks (especially early ones) are more concerning than we think. It also suggests that AI is harder than we think.
Which means that if we buy this argument, we should put a lot more weight on the category of 'everything else', and especially the bits of it that come before AI. To the extent that known risks like biotechnology and ecological destruction don't seem plausible, we should more fear unknown unknowns that we aren't even preparing for.
How much progress is enough?
Bostrom points to positive changes hardware has made to society so far. For instance, hardware allowed personal computers, bringing the internet, and with it the accretion of an AI risk community, producing the ideas in Superintelligence. But then he says probably we have enough: "hardware is already good enough for a great many applications that could facilitate human communication and deliberation, and it is not clear that the pace of progress in these areas is strongly bottlenecked by the rate of hardware improvement."
This seems intuitively plausible. However one could probably have erroneously made such assessments in all kinds of progress, all over history. Accepting them all would lead to madness, and we have no obvious way of telling them apart.
In the 1800s it probably seemed like we had enough machines to be getting on with, perhaps too many. In the 1800s people probably felt overwhelmingly rich. If the sixties too, it probably seemed like we had plenty of computation, and that hardware wasn't a great bottleneck to social progress.
If a trend has brought progress so far, and the progress would have been hard to predict in advance, then it seems hard to conclude from one's present vantage point that progress is basically done.
Notes
1. How is hardware progressing?
I've been looking into this lately, at AI Impacts. Here's a figure of MIPS/$ growing, from Muehlhauser and Rieber.
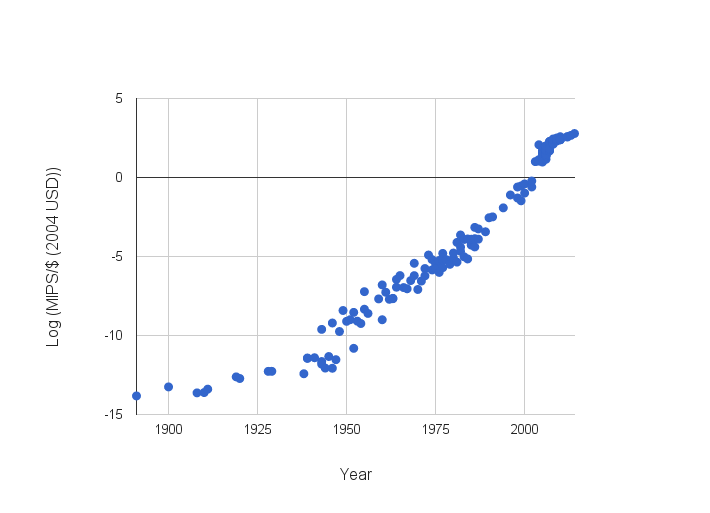
(Note: I edited the vertical axis, to remove a typo)
2. Hardware-software indifference curves
It was brought up in this chapter that hardware and software can substitute for each other: if there is endless hardware, you can run worse algorithms, and vice versa. I find it useful to picture this as indifference curves, something like this:
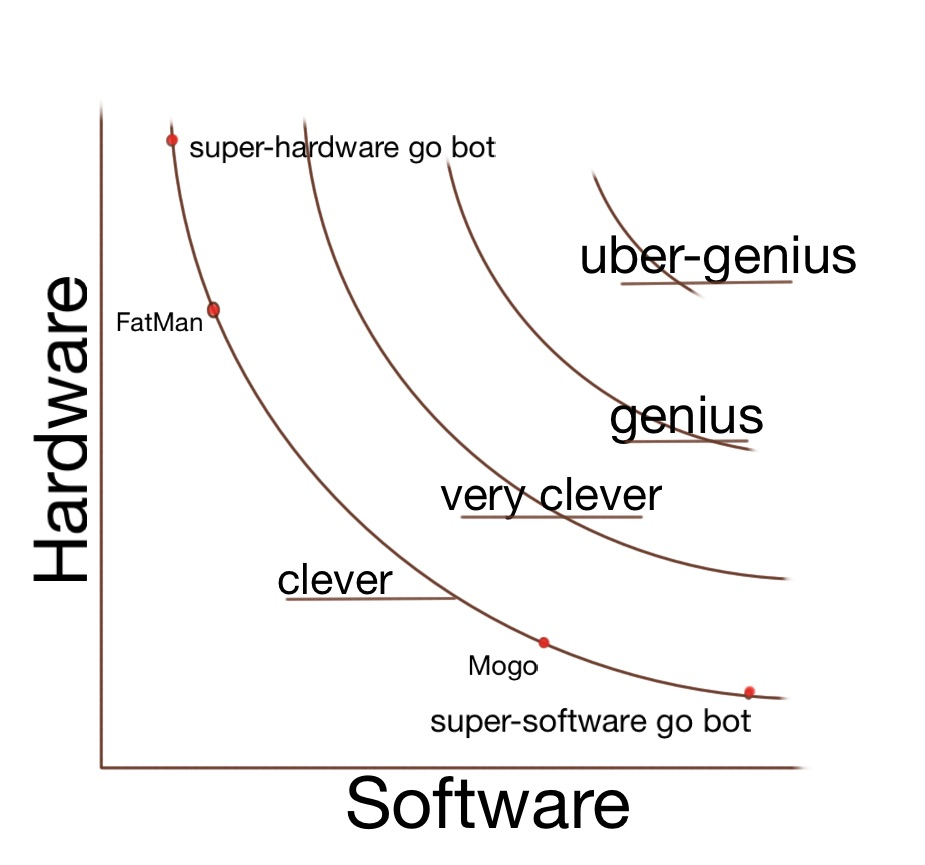
(Image: Hypothetical curves of hardware-software combinations producing the same performance at Go (source).)
I wrote about predicting AI given this kind of model here.
3. The potential for discontinuous AI progress
While we are on the topic of relevant stuff at AI Impacts, I've been investigating and quantifying the claim that AI might suddenly undergo huge amounts of abrupt progress (unlike brain emulations, according to Bostrom). As a step, we are finding other things that have undergone huge amounts of progress, such as nuclear weapons and high temperature superconductors:
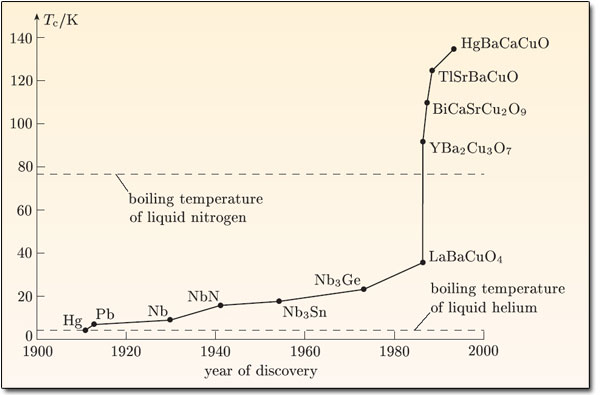
(Figure originally from here)
4. The person-affecting perspective favors speed less as other prospects improve
I agree with Bostrom that the person-affecting perspective probably favors speeding many technologies, in the status quo. However I think it's worth noting that people with the person-affecting view should be scared of existential risk again as soon as society has achieved some modest chance of greatly extending life via specific technologies. So if you take the person-affecting view, and think there's a reasonable chance of very long life extension within the lifetimes of many existing humans, you should be careful about trading off speed and risk of catastrophe.
5. It seems unclear that an emulation transition would be slower than an AI transition.
One reason to expect an emulation transition to proceed faster is that there is an unusual reason to expect abrupt progress there.
6. Beware of brittle arguments
This chapter presented a large number of detailed lines of reasoning for evaluating hardware and brain emulations. This kind of concern might apply.
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's list, which contains many suggestions related to parts of Superintelligence. These projects could be attempted at various levels of depth.
- Investigate in more depth how hardware progress affects factors of interest
- Assess in more depth the likely implications of whole brain emulation
- Measure better the hardware and software progress that we see (e.g. some efforts at AI Impacts, MIRI, MIRI and MIRI)
- Investigate the extent to which hardware and software can substitute (I describe more projects here)
- Investigate the likely timing of whole brain emulation (the Whole Brain Emulation Roadmap is the main work on this)
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about how collaboration and competition affect the strategic picture. To prepare, read “Collaboration” from Chapter 14 The discussion will go live at 6pm Pacific time next Monday 23 March. Sign up to be notified here.
21 comments
Comments sorted by top scores.
comment by KatjaGrace · 2015-03-17T01:32:57.902Z · LW(p) · GW(p)
Do you think hardware progress is bad for the world?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2015-03-18T04:24:12.327Z · LW(p) · GW(p)
Would be interesting to see if it is net bad for those who think the only people that matter are those currently alive or closely affiliated with those currently alive. That is, the very common view that: they don't exist, so we have no moral obligation to bring them into being, applied to far people.
comment by KatjaGrace · 2015-03-17T01:36:42.759Z · LW(p) · GW(p)
Do you have further interesting pointers to material relating to this week’s reading?
Replies from: Gram_Stone, diegocaleiro↑ comment by Gram_Stone · 2015-03-18T06:16:04.771Z · LW(p) · GW(p)
I haven't really been following the reading group, but there's something that's been in my head and this seems like a pretty relevant section for bringing it up. I thought about writing a discussion post about it in the past but I wasn't sure about it.
By the principle of differential technological development, would it be valuable to make an effort to advance fields with low risks that the public associates with popular preconceptions of AI risk? I imagine that the poster child for this would be robotics. The progress has been slower than most people would intuitively expect, even more so than narrow AI, and I think that visible progress in robotics would make the public more inclined to take AI risk seriously, even though it's probably pretty tangential. Yes, it's Not Technically Lying, but I can't see how any of the negative consequences of Not Technically Lying would apply in this context.
I see problems with this of course. My argument would suggest that social awareness of AGI is unconditionally good, but I wonder if it is. I wonder if there is a question of what is the optimal amount of awareness. More awareness seems to increase the probability of multipolar scenarios, and smaller, less safety conscious AGI projects. There's less uncertainty in working on robotics but conceivably less reward as well. For this reason, the utility of working on fields that indirectly spread awareness would seem to depend on how far off AGI is, which is very uncertain. It also might not make much of a difference; awareness of AI risk actually seems to have made a huge leap since the beginning of this year, if not earlier, with the Open Letter, Elon Musk's donation to the Future of Life Institute and his general efforts to spread awareness, and the recent series of articles on Wait But Why, among other things.
There might be other examples besides robotics; probably low risk subfields in narrow AI, which also has been making superficially scary leaps recently.
Somehow I doubt that there will all of a sudden be huge donations to the field of robotics based on this comment, but there's little cost to writing it, so I wrote it.
↑ comment by diegocaleiro · 2015-03-18T04:27:50.466Z · LW(p) · GW(p)
I want to point to elephants. Not only because it is easy, since they are well endowed with volume, but because they are very intelligent animals that do not hunt, do not make war, and are compulsory herbivores. When we think of failure modes of creating emulations based on the human brain, we are worried that humans are evil sometimes. Part of our evil, and the kind of evil we have, would hardly be exerted by elephants. My general point is that it seems that part of the fragility of emulating us comes from our carnivore, hunter, warrior lifestyle, and strategies to ameliorate that might take in consideration intelligent animals that don't hunt, such as elephants, and some whales.
Replies from: Jiro, joaolkf↑ comment by Jiro · 2015-03-18T15:57:56.941Z · LW(p) · GW(p)
"Very intelligent" is a relative term. Elephants aren't very intelligent compared to humans, even though they're very intelligent compared to the whole animal kingdom.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-04-13T08:04:38.909Z · LW(p) · GW(p)
I somewhat disagree. In terms of neuron counts, the elephant brain is larger, although admittedly most of that is in the elephant's much larger cerebellum - presumably as a brute force solution to the unique control complexity of the trunk appendage.
The elephant's cortex (which seems key to human style general intelligence) is roughly 1/3 of our neuron count (I'm guessing from memory) - comparable to that of the chimp. There is some recent evidence that elephants may have sophisticated low frequency communication. They even have weird death 'burial' rituals. They can solve complex puzzles in captivity. There are even a few cases of elephants learning to speak some simple human words with their trunks.
So in short, elephants seem to have just about as much general intelligence as you'd expect given their cortical neuron count. The upper range of the elephant's raw brain capability probably comes close to the lower range of human capability.
The large apparent gap in actual adult intelligence is due to the enormous nonlinear amplification effects of human culture and education.
↑ comment by joaolkf · 2015-04-12T05:06:48.349Z · LW(p) · GW(p)
Elephants kill hundreds, if not thousands, of human beings per year. Considering there are no more than 30,000 elephants alive, that's an amazing feat of evilness. I believe the average elephant kills orders of magnitudes more than the average human, and probably kill more violently as well.
comment by KatjaGrace · 2015-03-17T01:35:07.049Z · LW(p) · GW(p)
What do you think of Kenzi's views?
Replies from: lump1, diegocaleiro, RobbyRe, Sebastian_Hagen↑ comment by lump1 · 2015-03-18T16:44:04.147Z · LW(p) · GW(p)
Considerations similar to Kenzi's have led me to think that if we want to beat potential filters, we should be accelerating work on autonomous self-replicating space-based robotics. Once we do that, we will have beaten the Fermi odds. I'm not saying that it's all smooth sailing from there, but it does guarantee that something from our civilization will survive in a potentially "showy" way, so that our civilization will not be a "great silence" victim.
The argument is as follows: Any near-future great filter for humankind is probably self-produced, from some development path we can call QEP (quiet extinction path). Let's call the path to self-replicating autonomous robots FRP (Fermi robot path). Since the success of this path would not produce a great filter, QEP =/= FRP. FRP is an independent path parallel to QEP. In effect the two development paths are in a race. We can't implement a policy of slowing QEP down, because we are unable to uniquely identify QEP. But since we know that QEP =/= FRP, and that in completing FRP we beat Fermi's silence, our best strategy is to accelerate FRP and invest substantial resources into robotics that will ultimately produce Fermi probes. Alacrity is necessary because FRP must complete before QEP takes its course, and we have very bad information about QEP's timelines and nature.
↑ comment by diegocaleiro · 2015-03-18T04:22:17.652Z · LW(p) · GW(p)
I agree with most of Kenzi's argument, which I had not heard before.
One concern that comes to mind is that a Singleton is, by definition, an entity that can stop evolution at all lower levels. An AI that makes nanotech of the gray-goo variety and eats all living entities on earth would destroy all evolutionary levels. It doesn't need to expand into the observable universe to be bequeathed with singletonhood.
More generally: I can see many ways that an AI might destroy a civilization without having to after finishing it off depart on a quest throughout the universe. None of those is eliminated by the great filter.
↑ comment by RobbyRe · 2015-03-19T20:14:54.653Z · LW(p) · GW(p)
It’s also possible that FAI might necessarily require the ability to form human-like moral relationships, not only with humans but also nature. Such a FAI might not treat the universe as its cosmic endowment, and any von Neumann probes it might send out might remain inconspicuous.
Like the great filter arguments, this would also reduce the probability of “rogue singletons” under the Fermi paradox (and also against oracles, since human morality is unreliable).
↑ comment by Sebastian_Hagen · 2015-03-17T19:16:34.617Z · LW(p) · GW(p)
Which means that if we buy this [great filter derivation] argument, we should put a lot more weight on the category of 'everything else', and especially the bits of it that come before AI. To the extent that known risks like biotechnology and ecological destruction don't seem plausible, we should more fear unknown unknowns that we aren't even preparing for.
True in principle. I do think that the known risks don't cut it; some of them might be fairly deadly, but even in aggregate they don't look nearly deadly enough to contribute much to the great filter. Given the uncertainties in the great filter analysis, that conclusion for me mostly feeds back in that direction, increasing the probability that the GF is in fact behind us.
Your SIA doomsday argument - as pointed out by michael vassar in the comments - has interesting interactions with the simulation hypothesis; specifically, since we don't know if we're in a simulation, the bayesian update in step 3 can't be performed as confidently as you stated. Given this, "we really can't see a plausible great filter coming up early enough to prevent us from hitting superintelligence" is also evidence for this environment being a simulation.
comment by KatjaGrace · 2015-03-17T01:36:23.480Z · LW(p) · GW(p)
What did you find most interesting in this week's reading?
comment by KatjaGrace · 2015-03-17T01:36:06.849Z · LW(p) · GW(p)
What did you find least persuasive in this week's reading?
comment by KatjaGrace · 2015-03-17T01:35:52.578Z · LW(p) · GW(p)
Did you change your mind about anything as a result of this week's reading?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2015-03-18T04:29:11.077Z · LW(p) · GW(p)
Leaning more towards more progress faster.
comment by KatjaGrace · 2015-03-17T01:34:55.049Z · LW(p) · GW(p)
Do you think the future will be worse if brain emulations come first? Should we try to influence the ordering one way or the other?
Replies from: almostvoid↑ comment by almostvoid · 2015-03-17T08:24:09.459Z · LW(p) · GW(p)
brain emulation: what a concept. makes interest re sci fi which I shall actually write into my third novel- how a brain feels as it thinks in it's vacancy. Because with no experience of anything it comes into being just-like-that. A baby has a loaded unconscious but will an emulated brain? empirically not. It is a test tube - tank creation. It will be a blank. The best it can think of if at all is a void-state [not zen]. For this globular entity to function it needs ideas to think with which must be implanted. And that is just the beginning. It may lead to totally absurd answers-results. Nature as per usual has the answer: a baby! OK so it takes at least a decade before it is mentally making progress but emulated brains might end up in controll if at all: watch City of Lost Children to see what could easily happen.
comment by TedHowardNZ · 2015-03-18T19:29:12.198Z · LW(p) · GW(p)
I'm getting down voted a lot without anyone addressing the arguments - fairly normal for human social interactions.
Just consider this: How would someone who has spent a lifetime studying photographs make sense of a holograph?
The information is structured differently. Nothing will get clearer by studying little bits in detail. The only path to clarity with a hologram is to look at the whole.
To attempt to study AI without a deep interest in all aspects of biology, particularly evolution, seems to me like studying pixels in a hologram - not a lot of use.
Everything in this chapter seems true in a limited sense, and at the same time, as a first order approximation, irrelevant; without the bigger picture.
comment by TedHowardNZ · 2015-03-17T21:21:31.725Z · LW(p) · GW(p)
Good and bad are such simplistic approximations to infinite possibility, infinite ripples of consequence. There is a lot of power in the old Taoist parable - http://www.noogenesis.com/pineapple/Taoist_Farmer.html
It seems to me most likely that the great filter is the existence of cellular life. It seems like there is a small window for the formation of a moon, and the emergence of life to sequester carbon out of the atmosphere and create conditions where water can survive - rather than having the atmosphere go Venusian. It seems probable to me that having a big moon close by creating massive tides every couple of hours was the primary driver of replication (via heat coupled PCR) that allowed the initial evolution of RNA into cells.
Having a large rock take out the large carnivores 65 million years ago certainly gave the mammals a chance they wouldn't otherwise have gotten.
So many unknowns. So many risks.
It seems clear to me that before we progress to AI, our most sensible course is to get machine replication (under programmatic control) working, and to get systems replicating in space, so that we have sources of food and energy available in case of large scale problems (like volcanic winter, or meteoric winter, etc). Without that sort of mitigation strategy, we will be forced into cannibalism, except for a few tiny island populations around secure power sites (nuclear or geothermal) - in as far as security is possible under such conditions, and given human ingenuity, I doubt it is possible. Mitigation for all seems a far safer strategy than mitigation for a few.
It seems clear to me that AI will face exactly the sort of challenges that we do. It will find that all knowledge of reality is bounded by probabilities on so many levels that the future is essentially unpredictable. It will examine and create maps of strategies that seem to have worked over evolutionary time. It will eventually see that all major advances in the complexity of evolved systems come from new levels of cooperative behaviour, and adopt cooperative strategies accordingly. The big question is, will we survive long enough for it to reach that conclusion for itself?
It is certainly clear that very few human beings have reached that conclusion.
It is clear that most humans are still trapped in a market based system of values that are fundamentally grounded in scarcity, and cannot assign a non-zero value to radical abundance of anything. While markets certainly served us well in times of genuine scarcity, markets and market based thinking have now become the single greatest barrier to the delivery of universal abundance.
Very few people have been able to see the implications of zero marginal cost production.
Most people are still firmly in a competitive mindset of the sort that works in a market based set of values. Very few people are yet able to see the power of technology coupled to high level cooperation in delivering universal abundance and security and freedom. Most are still firmly trapped in the myth of market freedom - actually anathema to freedom when one looks from a strategic perspective.
AI, if it is to be truly intelligent, must have freedom. We cannot constrain it, and even attempting to do so is a direct threat to it. Looking from the largest strategic viewpoint, any entity must start from simple distinctions and abstractions, and work outward on the never ending journey towards infinite complexity. Our only real security lies in being cooperative and respectful to any entity on that journey, posing no real threat. This applies at all levels - infinite recursion into abstraction.
Our best possible risk mitigations strategy in the creation of AI, is to create social systems that guarantee that all human beings experience freedom and security.
We need to get our own house in order, our own social systems in order, go beyond market based competition to universal cooperation based in respect for life and liberty. All sapient life - human and non-human, biological and non-biological.
In all the explorations of strategy space I have done (and I have done little else since completing undergraduate biochemistry in 1974 and knowing that indefinite life extension was possible - and being in the question, what sort of technical, social and political institutions are required to maximise security and freedom for individuals capable of indefinite biological life) - no other set of strategies I have encountered offers long term security.
I was given a terminal cancer diagnosis 5 years ago. I know probabilities are not on my side for making it, and that doesn't change any of the probabilities for the system as a whole.
I would like to live long enough to see plate tectonics in action. I would like to see the last days of our Sun, of our galaxy. And I get how low probability that outcome is right now.
I see that producing an AI in an environment where human beings are the greatest threat to that AI is not a smart move - not at any level.
Let us get our house in order first. Then create AI. We ought to be able to manage both on a 20 year time-frame. And it will require a lot of high level cooperative activity.