Understanding mesa-optimization using toy models
post by tilmanr (tilman-ra), rusheb, Guillaume Corlouer (Tancrede), Dan Valentine (dan-molloy), afspies, mivanitskiy (mivanit), Can (Can Rager) · 2023-05-07T17:00:52.620Z · LW · GW · 2 commentsContents
Overview Introduction Connections to mesa-optimization Training setup Dataset construction Hypotheses on Search Mechanistic Hypotheses Behavioral Analysis Experiments Behavioral experiments Evaluating performance Obeying constraints Evaluating generalization Interpretability experiments Possible outcomes Model memorizes every maze Model uses some heuristics but doesn't search Model has learned to perform search Project None 2 comments
Overview
- Solving the problem of mesa-optimization would probably be easier if we understood how models do search internally [LW · GW]
- We are training GPT-type models on the toy task of solving mazes and studying them in both a mechanistic interpretability and behavioral context.
- This post lays out our model training setup, hypotheses we have, and the experiments we are performing and plan to perform. Experimental results will be forthcoming in our next post.
- We invite members of the LW community to challenge our hypotheses and the potential relevance of this line of work. We will follow up soon with some early results[1]. Our main source code is open source, and we are open to collaborations.
Introduction
Some [? · GW] threat models [LW · GW] of misalignment presuppose the existence of an agent which has learned to perform a search over actions to effectively achieve goals. Such a search process might involve exploring different sequences of actions in parallel and evaluating the best sequence of actions to achieve some goal.[2]
To deepen our understanding of what it looks like when models are actually performing search, we chose to train simple GPT-2 like models to find the shortest paths through mazes. Maze-solving models provide a tractable and interesting object of study, as the structure of both the problem and solutions is extensively studied. This relative simplicity makes identifying and understanding search through the lens of mechanistic and behavioral experiments much more concrete than working with pre-trained LLMs and more feasible in the context of limited computational resources.
Connections to mesa-optimization
Mesa-optimizers are learned optimizers for an objective that can be distinct from the base-objective. Inner misalignment can occur when the AI system develops an internal optimization process that inadvertently leads to the pursuit of an unintended goal. Models capable of perfoming search are relevant for understanding mesa-optimization as search requires iterative reasoning with subgoal evaluation. In the context of solving mazes, we may hope to understand how mesa-optimization arises and can become "misaligned"; either through the formation of non-general reasoning steps (reliance on heuristics or overfitted goals) or failure to retarget.[3]
Existing [LW · GW] literature [AF · GW] on search [LW · GW] has highlighted the potential for unintended consequences of search in ML systems. One lens of viewing the problem of mesa-optimization is that the behavior of a system changes in an undesirable way upon a distributional shift, and we believe that mazes provide a number of mechanisms to create such distributional shifts.
Training setup
We first aim to train a transformer model to predict the shortest path between a given start and end position in a maze.
- The maze exists as a 2D grid, with each position on the grid encoded as a single token. For example, a 5x5 maze has 25 coordinates that have corresponding tokens in the vocabulary.
- To the transformer, the maze is described as:
- An adjacency list containing all connections between pairs of positions: for example, (0,0) <--> (0,1).
- A "wall" in the maze is merely a missing connection between positions in the maze, but otherwise not explicitly stated.
- The start and end positions are coordinates on the maze grid, such as (3,3) and (4,0), respectively.
- An adjacency list containing all connections between pairs of positions: for example, (0,0) <--> (0,1).
- A training example contains a maze (as an adjacency list), start and end coordinates, and a path consisting of position tokens
We use an autoregressive decoder-only transformer model (implemented using TransformerLens), which (at inference) makes predictions one token at a time based on previously generated tokens. Our transformer models incorporate layer normalization and MLP layers by default.
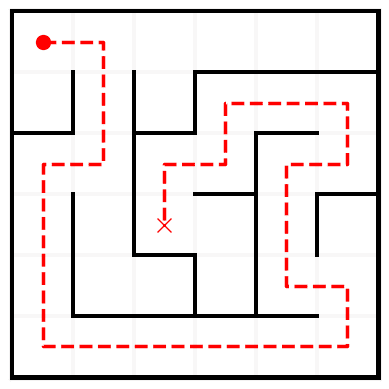
One training sample consists of a maze, as well as a unique path connecting randomly selected origin and target coordinates (circle and cross). The solved maze shown above is prompted to the model as shown below:
<ADJLIST_START> (4,4) <--> (3,4) ; (5,2) <--> (5,1) ; (0,2) <--> (0,1) ; (0,2) <--> (1,2) ; (2,1) <--> (1,1) ; (0,3) <--> (0,4) ; (3,0) <--> (2,0) ; (0,0) <--> (1,0) ; (0,5) <--> (0,4) ; (1,5) <--> (2,5) ; (4,3) <--> (3,3) ; (0,1) <--> (0,0) ; (3,1) <--> (2,1) ; (1,1) <--> (0,1) ; (3,0) <--> (4,0) ; (3,5) <--> (4,5) ; (4,1) <--> (3,1) ; (5,0) <--> (5,1) ; (3,4) <--> (2,4) ; (4,0) <--> (5,0) ; (2,4) <--> (2,5) ; (3,3) <--> (3,2) ; (5,5) <--> (5,4) ; (1,4) <--> (1,3) ; (5,3) <--> (5,4) ; (5,5) <--> (4,5) ; (2,2) <--> (3,2) ; (4,2) <--> (4,1) ; (0,2) <--> (0,3) ; (2,2) <--> (2,3) ; (4,5) <--> (4,4) ; (1,5) <--> (1,4) ; (5,2) <--> (5,3) ; (2,0) <--> (2,1) ; (2,3) <--> (1,3) ; <ADJLIST_END> <ORIGIN_START> (0,0) <ORIGIN_END> <TARGET_START> (3,2) <TARGET_END> <PATH_START> (0,0) (0,1) (1,1) (2,1) (2,0) (3,0) (4,0) (5,0) (5,1) (5,2) (5,3) (5,4) (5,5) (4,5) (4,4) (3,4) (2,4) (2,5) (1,5) (1,4) (1,3) (2,3) (2,2) (3,2) <PATH_END>Note that we implement a custom tokenizer -- each space-delimited substring of the above is a token. This greatly simplifies the analysis of our model through explicit control of the representation, compared to using a standard LLM tokenizer.
Dataset construction
To start with, we have primarily trained on mazes generated with randomized depth-first search, which produces acyclic mazes with unique paths between any two points. The target paths present in the dataset are the shortest paths (these paths do not backtrack owing to acyclicity).
Hypotheses on Search
Our hypotheses cover a broad spectrum of what our models might learn, ranging from high-level concepts of how the maze transformer internally represents graphs to specific, measurable mechanisms that can be tested.
We distinguish between search and heuristics in our hypotheses while recognizing that some of them fall along a continuum between these two. Heuristics refer to shortcuts that a model learns during training to solve a given task. For instance, when solving a maze, a model might memorize the solutions to some patterns which reoccur across mazes[4]. Search, however, explicitly considers potential future steps in the maze while deciding on the immediate next step. In the context of human reasoning, playing Chess960 may be useful as an example of what is a learned heuristic and what is search.
Testing the hypothesis of a learned internal search can be challenging. [LW · GW] This is because it may be difficult to distinguish between sophisticated internal search algorithms and crude heuristics sufficient to solve mazes. Additionally, it may be beyond the capability of small GPT-type models to learn internal search algorithms.
Mechanistic Hypotheses
- Lattice-Adjacency heads: There may exist in a trained model an attention head which, for some position
(x,y), places weight on the tokens of adjacent (Manhattan distance of 1 ignoring the graph structure) positions in the maze. This hypothesis is based on the assumption that the maze transformer model will learn to represent spatial relationships between different positions in the maze and will use this information to guide an iterative search process. As each coordinate is represented directly with a learned embedding vector, the model must learn to infer structure from input sequences rather than being able to directly deduce this from position embeddings (which would work for rasterized mazes). - Adjacency circuit: We expect the "Lattice-Adjacency Heads" to be able to pass on information about which nodes are adjacent but not to incorporate information about the graph structure. We that incorporating the graph structure requires at least 2 attention layers, similar to induction heads. We expect that this circuit would:
- given a token
(i,j), find instances of(i,j)in the adjacency list - look for tokens of nodes connected to
(i,j)via a connector token:(i,j+1) <--> (i,j) ;
- given a token
- Bottlenecks: John Wentworth talks about how one way of solving a maze is to find "bottlenecks" in it. Tokens (or positions) that serve as "bottlenecks" may receive more weight than other tokens in a model.
- Targets: The transformer may internally represent targets in some layers explicitly. This hypothesis builds on top of Alex's findings on retargeting agents [AF · GW].
- Discarding dead-ends: Training an RCNN on rasterized mazes produces a model which seems to solve acyclic mazes via "back-filling." During each recurrent step, nodes that have only one non-discarded neighbor are discarded, except for the starting and goal positions. In the early layers of the transformer, dead ends may also be discarded, which we hope to observe via LogitLens [LW · GW].
- Exploring parallel paths: Models that learn to solve mazes algorithmically have the ability to construct multiple possible paths in parallel. The transformer, for instance, constructs possible paths by using learned spatial primitives or adjacent cells. The algorithm employed in this process involves the model learning to follow valid paths and doing so for multiple paths in parallel. The output generated by the algorithm would be the shortest path that the model had found, although there may be a step of discarding paths on the fly.
- Precognition about future paths: At any fork in the maze, if the model is to eventually produce the shortest path, it must take into account the future consequences of the current fork. In particular, in an acyclic maze, taking any incorrect fork prevents the model from ever reaching the target (without backtracking). So, we expect that the model will have some representation of future states in the residual stream.
Behavioral Analysis
- Heuristics: To solve a maze with N steps, a model with fewer than N layers must consider multiple steps simultaneously. One way to accomplish this is by considering all steps between two forks as a single step and attaching distance information based on the number of adjacency list tokens that connect the two forks.
However, heuristics may not efficiently capture this approach, and a multi-layer circuit might be necessary. The model should encode spatial proximity/adjacency in its embedding space - seen through examples of models jumping over walls.
Furthermore, the model may learn to store long corridors as spatial primitives, but it is unclear how it would choose between this representation and the previous one. Overall, it is crucial for the model to be able to consider multiple steps simultaneously and encode spatial proximity in its embedding space to effectively solve a maze. - Choosing paths: The process of choosing paths in models involves exploring multiple paths simultaneously and selecting the optimal path at the end. It is unlikely for every layer to have a "stop once found" head. Instead, the model might keep track of path lengths and trajectories. In the last one or two layers, the model would read off the shortest path.
Experiments
Behavioral experiments
Evaluating performance
To evaluate the model's ability to solve the maze, we conduct behavioral tests and measure its performance using different metrics. Some of the metrics we use include the fraction of mazes of a given size that the model can solve perfectly, the fraction of nodes overlapping between the prediction and the solution, and the fraction of correct decisions at forking points (where the model must choose between different directions).
Obeying constraints
In our setup, we do not actually prevent the model from producing tokens that do not obey the constraints of the maze -- a model very early in training produces a path that jumps around the maze in an impossible way. It is only the distribution of the training dataset that enforces the constraints of not jumping around, not backtracking, and reaching the target. In some ways, this parallels how we train language models: we do not enforce any grammatical structure, and we do not enforce any adherence to human values -- we only show examples of desired behavior. It is probably a valuable thing to have a better idea of what sorts of distributional shifts can cause a model to ignore constraints that it seems to follow during training.
Evaluating generalization
If the model has learned how to search, it is expected to be more robust to distributional shift than if it has learned to rely on heuristics such as memorization. We can test the generalization of the model's performance by conducting several experiments.
- Size: Consider a model trained exclusively on mazes of size . Can the model generalize to mazes, where ? There is some complexity here in the tokenization required for this to even be plausible, which we will detail in our next post.
- Complexity: Currently, we only train on fully connected acyclic mazes generated by randomized depth-first search (RDFS). We can measure the effective complexity of a maze by evaluating the performance of a "Baseline Solver," which obeys adjacency and no-backtracking constraints and, at forks, chooses randomly among the valid paths. By evaluating the behavior on mazes generated via other methods, we hope to glean some information about whether the algorithm implemented by the model is specific to the structure of RDFS or applicable to mazes in general.
- Number of valid paths from origin to target: Consider a model which is exclusively trained on mazes with a single solution (acyclic mazes). We assess the model's capability to identify the shortest path in cyclic mazes (with multiple solution paths of varying length) and an open field (maze environment without walls).
- Exploring other tokenization schemes: Given an maze, the model has to learn pairwise relationships between tokens. By simplifying the tokenization scheme to have a coordinate
(i,j)be represented as a pair of tokens rather than a single token, we drastically reduce this number. Additionally, it may be interesting to investigate whether there are significant differences in a model trained on the dual problem: instead of providing the adjacency list, provide a list of walls in the maze that obstruct movement. - Generalization between maze types: RDFS generates acyclic fully-connected mazes, but there are many other ways of generating valid mazes; for some of these, our metrics would actually be counterintuitive. Consider, for example, an "open field" with a single object obstructing part of the path. To a human (or probably RCNN), this is an easier task. However, to our baseline solver, this would be significantly more difficult. How would the transformer model perform?
Interpretability experiments
- Direct logit attribution and activation patching: Using direct logit attribution and activation patching, we hope to better understand the computations relevant to valid "path following." Ideally, this will result in a circuits-level understanding of the processes involved in "path following" and target token representation. Outside of direct logit attribution and activation patching, we expect to apply attention visualization techniques and, at some point, path-patching.
- Geometric structure of the embedding space: We will examine the weight matrices (OV, QK, MLP) projected onto the embedding space for any interpretable structure. To achieve this, we will use singular value decomposition (SVD) on OV, QK, and MLP matrices and measure the similarity of singular vectors with embedded tokens. Previous work by conjecture [LW · GW] serves as the foundation for this approach. Additionally, looking at distances between sets of tokens, as well as the geometry of probes, might help us to understand the learned world model.
- Clustering of tokens: We will use t-SNE to check for clustering of tokens at different layers of the residual stream. For example, we want to explore if tokens representing coordinates along the predicted path are clustered together at some point.
- Probing for future states: Given our expectation of the necessity of representing future states for making correct choices at forking points, we want to test for the presence of these representations. One option is to train for each token
(i,j)a linear probe of "token(i,j)is in the future path". If this linear probe is effective, it might also give us a way to visualize how the model selects among possible future paths. - Goal retargeting: In the long run, one particularly exciting experiment would be to be able to do causal interventions on the model's goal representation (if it exists) to facilitate goal retargeting.
Possible outcomes
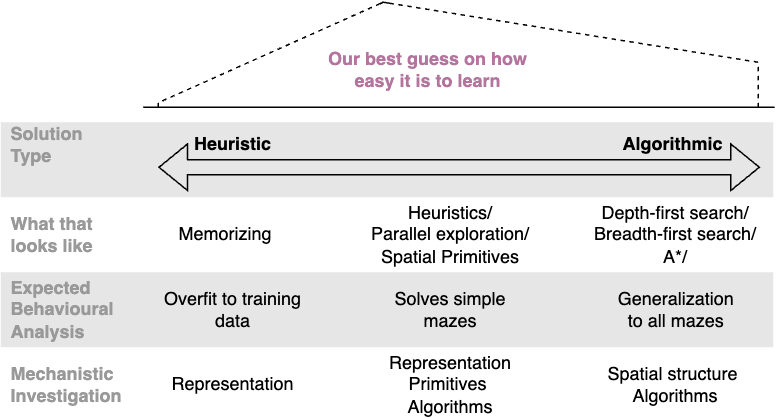
Model memorizes every maze
The most conservative hypothesis is that the model memorizes every maze, leading to poor generalization. This is relatively uninteresting from the perspective of alignment but also simply not true of LLMs. As such, we expect to be able to induce more interesting behavior through hyperparameter tuning if we find that the model is only memorizing.
Model uses some heuristics but doesn't search
Assuming that the model has learned some heuristics but not implemented search, there are still intriguing hypotheses to explore from the lens of mechanistic interpretability. For instance, it may have acquired an emergent world model that can be tested through specific hypotheses related to its representation of the maze, such as the presence of adjacency heads. Alternatively, in the best-case scenario, the model may have learned heuristics but still be performing an approximate search.
If this ends up being the case, we still think this sheds light on the ambiguities of what is meant by search brought up in the original Searching for Search [LW · GW] post.
Model has learned to perform search
The most interesting outcome, research-wise, is that the model has not only learned heuristics but also acquired the ability to perform search. If we can both demonstrate and mechanistically explain this effect, it would have implications for how the behavior of LLMs can be controlled in more powerful systems.
Finally, understanding the retargetability and misgeneralization of the model's search capabilities is crucial for evaluating its performance and practical applicability. By measuring these aspects, we can better understand the model's limitations and identify areas for further improvement, thereby refining the Maze-Transformer's ability to tackle not only maze-solving tasks but also other search-based challenges in various domains.
Project
This project was cultivated in AISC8. Our team is made up of: Michael Ivanitskiy (Project Lead), Alex Spies, Dan Valentine, Rusheb Shah, Can Rager, Lucia Quirke, Chris Mathwin, Guillaume Corlouer, and Tilman Räuker. Our source repo for datset generation, model training, and model evaluation is public. For access to our slack or our (for now) private experiments repo, please email miv@knc.ai!
We would also like to extend our thanks to janus [LW · GW] for spearheading the idea of "searching for search".
- ^
We encourage readers to predict what we might find as an exercise in training your intuitions (inspired by Alex Turner's post [? · GW])
- ^
It's worth noting that this search could occur within a compressed or restricted space. For instance, instead of executing a conventional search algorithm such as BFS or DFS at the granularity of input features, a model may plan and evaluate with compressed representations (see related discussion [LW · GW])
- ^
We rephrased this paragraph for clarity. Thanks to Alex Turner for pointing this out.
- ^
Heuristics that leverage repeated substructure are to be expected, but it is not clear at what point a heuristic should be considered a "bad" result of overfitting; clearly, memorizing entire training examples is "bad" as that behavior doesn't generalize at all, but this is ultimately still a heuristic.
2 comments
Comments sorted by top scores.
comment by TurnTrout · 2023-05-10T01:07:38.451Z · LW(p) · GW(p)
I think language like this is unclear:
In the context of search, the propensity for mesa-optimization may be increased as the system explores various future states, potentially identifying alternative objectives that appear at least as rewarding or efficient in achieving the desired outcome.
A system identifies "objectives" which are "rewarding"? Can you clarify what that means? Is the system the network, or SGD, or the training process? Are the objectives internally represented?
And what about "desired"? Desired by whom -- the designers? "Desired" by SGD? Something else?
Replies from: Can Rager↑ comment by Can (Can Rager) · 2023-05-13T12:39:23.902Z · LW(p) · GW(p)
Thanks for pointing this out – indeed, our phrasing is quite unclear. The original paragraph was trying to say that our "system" (a transformer trained to find shortest paths via SGD) may learn "alternative objectives" which don't generalize (aren't "desirable" from our perspective), but which achieve the same loss (are "rewarding").
To be clear, the point we want to make here is that models capable of perfoming search are relevant for understanding mesa-optimization [AF · GW] as search requires iterative reasoning with subgoal evaluation.
In the context of solving mazes, we may hope to understand how mesa-optimization arises and can become "misaligned"; either through the formation of non-general reasoning steps (reliance on heuristics or overfitted goals) or failure to retarget.
Concretely, we can imagine the network learning to reach the <END_TOKEN> at train time, but failing to generalise at test time as it has instead learnt a goal that was an artefact of our training process. For example, it may have learnt to go to the top right corner (where the <END_TOKEN> happened to be during training).