Clarifying mesa-optimization
post by Marius Hobbhahn (marius-hobbhahn), Pierre Peigné (pierre-peigne) · 2023-03-21T15:53:33.955Z · LW · GW · 6 commentsContents
What is an accurate definition of mesa-optimization? What is a definition of mesa-optimization we care about? How do real-world models do mesa-optimization? Falsifiable predictions General implications None 6 comments
Produced as part of the SERI ML Alignment Theory Scholars Program - Winter 2022 Cohort.
Thanks to Jérémy Scheurer, Nicholas Dupuis and Evan Hubinger for feedback and discussion
When people talk about mesa-optimization, they sometimes say things like “we’re searching for the optimizer module” or “we’re doing interpretability to find out whether the network can do internal search”. An uncharitable interpretation of these claims is that the researchers expect the network to have something like an “optimization module” or “internal search algorithm” that is clearly different and distinguishable from the rest of the network (to be clear, we think it is fine to start with probably wrong mechanistic models [LW · GW]).
In this post, we want to argue why we should not expect mesa-optimization to be modular [? · GW] or clearly different from the rest of the network (at least in transformers and CNNs) and that current architectures can already do mesa-optimization in a meaningful way. We think this implies that
- Mesa-optimization improves gradually where more powerful models likely develop more powerful mesa optimizers.
- Mesa-optimization should not be treated as a phenomenon of the future. Current models likely already do it, just in a very messy and distributed fashion.
- When we look for mesa optimization, we probably have to look for a messy stack of heuristics combined with search-like abilities rather than clean Monte Carlo Tree Search (MCTS)-like structures.
We think most of our core points can be conveyed in a simple analogy. Imagine a human chess grandmaster that has to choose their moves in 1 second. In this second, they are probably not running a sophisticated tree search in their head, they rely on heuristics. These heuristics were shaped by years of playing the game and are often the result of doing explicit tree searches with more time. The resulting decision-making process is a heuristic that approximates or was at least shaped by optimization but is not an optimizer itself. This is approximately what we think mesa-optimization might look like in current neural networks, i.e. the model uses heuristics that have aspects of or approximate parts of optimization, but are not “clean”[1] in the way e.g. MCTS is.
What is an accurate definition of mesa-optimization?
In risks from learned optimization [LW · GW] mesa-optimization is characterized as
[...] it is also possible for a neural network to itself run an optimization algorithm. For example, a neural network could run a planning algorithm that predicts the outcomes of potential plans and searches for those it predicts will result in some desired outcome. Such a neural network would itself be an optimizer because it would be searching through the space of possible plans according to some objective function. If such a neural network were produced in training, there would be two optimizers: the learning algorithm that produced the neural network—which we will call the base optimizer—and the neural network itself—which we will call the mesa-optimizer.
In this definition, the question of whether a network performs mesa-optimization or not boils down to whether whatever it does can be categorized as optimization, planning or search with an objective function.
We think this question is very hard to answer for most networks and ML applications in general, e.g. one could argue that sparse linear regression performs search according to some objective function and that the attention layer of a transformer implements search since it scans over many inputs and reweighs them. We think this is an unhelpful way to think about transformers but it might technically fulfill the criterion.
On the other hand, transformers very likely can’t perform variable length optimization like tree search or a recursive optimization procedure. Thus, they are not able to perform many forms of optimization.
However, we think the question of whether transformers “truly” do mesa-optimization is not meaningful. We are mostly interested in whether they can do the kind of mesa-optimization we care about, i.e. the one that could lead to harmful consequences.
What is a definition of mesa-optimization we care about?
We mostly care about mesa-optimization in contexts where it can lead to bad, potentially catastrophic consequences. Intuitively, these capabilities lie on a spectrum.
On the lower end of that spectrum, we would put powerful LLMs with very long context lengths. If prompted or fine-tuned to “think step by step”, this could allow the model to do fairly complicated reasoning by repeated token generation. We think it is hard for a model to plan a take-over like that but it doesn’t seem impossible.
In the middle of the spectrum would be something like an LLM with powerful memory and chain-of-thought capabilities. This would allow the model to plan by writing on a scratchpad, database, or other form of memory and then use this knowledge for future actions.
On the upper end, we could imagine an AI that simulates large parts of the world, e.g. with a very powerful physics engine, and then searches over different simulations according to some objective function. This AI could, for example, simulate the reaction of a large number of people to a political event and then choose actions that yield the best outcome according to its objective. It could also simulate chemistry and biology to a level of sophistication that is currently unknown to humans and thus accurately predict how specific medicine would interact with a human body, etc. The compute budget to make all of these simulations would obviously not be infinite and it can’t simulate the universe until the end of time but it can simulate it much further than all humans combined. Such an AI could then search through these simulations according to its objective function and enact the plan that scores the highest. In a world where the inner objective is not aligned, this plan could lead to catastrophic consequences.
There are multiple properties that seem relevant to successfully plot and execute an AI takeover like situational awareness, deception, different goals than humans, and so forth. However, in the context of mesa-optimization, it seems like the ability to do long-term planning is the component that increases the probability of bad results the most. If your model does mesa-optimization but can’t plan over longer trajectories, it probably won’t be able to pull a successful takeover.
Thus, we are not just looking for whether the model can do any kind of mesa-optimization but if it can do the kind of mesa-optimization that allows it to develop long-term plans which when executed would lead to catastrophic consequences.
How do real-world models do mesa-optimization?
Originally, we intuitively thought that mesa-optimization means that the model has an internal search procedure like Monte Carlo tree search or a version of internal SGD or some other mathematically clean idea.
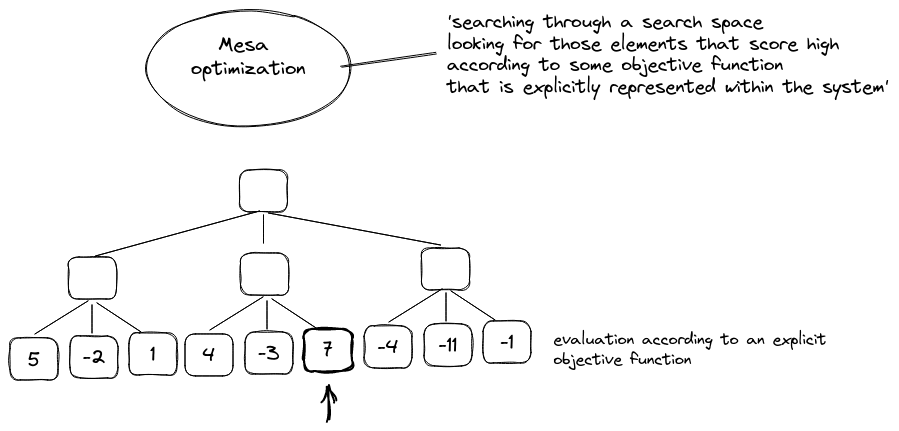
In Searching for Search [LW(p) · GW(p)], Nick argued that searching for search will be difficult because the search space representation is compressed to make the problem more tractable.
In particular, adding constraint to the search problem (e.g. focussing only on board configuration mitigating a specific threat to your queen), and using higher-level representations (e.g. thinking in terms of patterns among the pieces instead of considering each piece independently) are very good dimensionality techniques used by humans when performing search.
However, such a compression scheme makes the search process much less interpretable from an outsider's perspective.
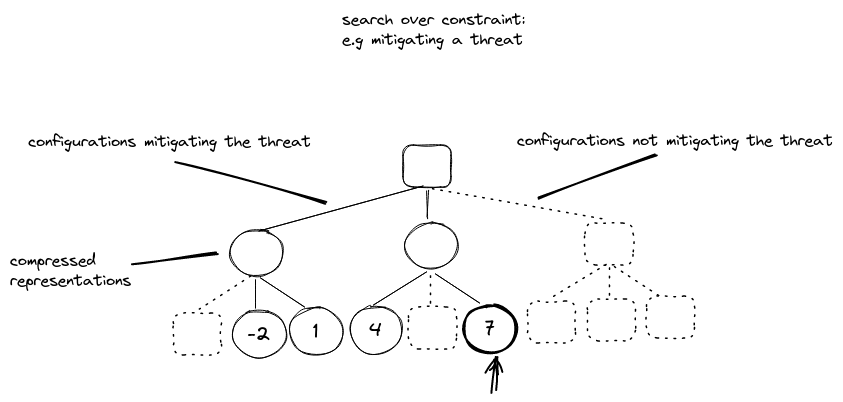
Our contribution discusses another dimension of the problem: the messy nature of the exploration process itself. In addition to the compression of the representation and the constraint to the search, the heuristics used as shortcuts during the search processes push them away from clean MCTS-like search.
We think it’s possible that AI systems will use some of these procedures as one possible tool in their toolbox, e.g. they could use a calculator or a physics engine as one possible action in their forward pass. However, we think it is not the most likely scenario, that they will develop a calculator or unbounded “clean” optimizer in their weights.
Rather, we think that mesa-optimizers will primarily use a complicated stack of heuristics that takes elements from different clean optimization procedures. In the future, these internal heuristics might be combined with external optimization procedures like calculators or physics engines. This is similar to how humans that play chess don't actually run a tree-search of depth n with alpha-beta pruning in their heads. The heuristics human chess players use can often look like approximate versions of optimization procedures but they are not literally running the algorithm. For example, chess players might run a couple of steps of explicit tree search in their head before making a decision but, importantly, they already implicitly prune parts of the tree in a heuristic fashion or skip a bunch of steps here and there. The better these players become the better their pruning heuristics become and the more steps they skip in their internal search tree. For example, for specific board positions, they might know what the optimal play for the next 5 rounds looks like and can thus skip all of the computation in the explicit tree.
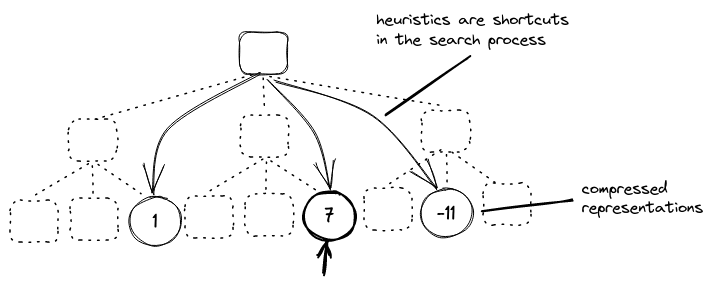
Our primary argument is that most architectures are not very well-designed for clean optimization algorithms like MCTS, because they require repeatedly doing the same action over and over again. And unless the model has a special module that recursively runs such a procedure it is unlikely that this is the most effective use of space in a feed-forward model.
Here is the reasoning for this intuition in more detail:
- For most tasks, there is no reason to re-discover MCTS or other human-designed search algorithms. Open-ended optimization is probably not necessary for the vast majority of tasks and even if it was, complicated heuristics likely approximate bounded optimization sufficiently well.
- There is limited space in a forward pass, i.e. any finite-length model can only do a finite number of computational steps. If an n-layer model could only do n steps of MCTS it would probably perform worse than when using heuristics.
- Superposition allows the model to do a lot of things at once. Thus, if the model wants to use its space efficiently, it performs multiple steps at once or uses highly compressed heuristics even if they don’t cover all corner cases. Especially in feed-forward models, the model can’t repeatedly apply the same module. Thus, implementing a “clean” algorithm would require implementing a similar algorithm in multiple layers which seems very space inefficient.
- Everything with a residual stream (e.g. transformers and ResNets used in AlphaZero) can already have aspects of a limited-depth search algorithm that uses different heuristics at different layers. Attention has important aspects of search, i.e. it reduces a large space of options to a much smaller space of options according to some objective function and MLP layers can perform computations on this narrowed space. The residual stream allows us to keep track of a consistent state, so the network could repeatedly simulate different actions and then evaluate them in a later layer.
- Empirically AlphaZero is pretty good without MCTS. AlphaGo Zero without MCTS still performs very well. Its ELO ranking is evaluated at 3055 which is higher than the best human players. This is not evidence for the fact that it does mesa-optimization but it could mean that it either actively simulates moves or that its heuristics approximate explicit optimization.
Thus, our current expectation of how mesa-optimization will look like is less like a neural network that re-implements SGD or MCTS within its weights and more like a human that uses a complicated stack of heuristics that picks and chooses between aspects of optimization procedures like a grandmaster playing chess.
In the future, the network might even use an externalized version of optimizers such as calculators or a physics engine. Eventually, it might even internalize these modules. However, we think it is unlikely that it will re-implement them in its weights if current architectures continue due to all of the reasons above (e.g. it is an inefficient use of space to re-implement clean optimization procedures). If NN architectures fundamentally change (e.g. with more recurrence), all of the above arguments have to be rethought.
This has a couple of important consequences in our opinion. First and foremost, we think there will not be clear red flags for “the model is doing optimization”. With our framing of mesa-optimization, current transformers already do mesa-optimization, it’s just not good enough to do meaningful long-term planning. But there won’t be a binary cut-off point at which models go from zero mesa-optimization to full mesa-optimization, it’s just a gradual increase in the ability to run internal search heuristics and different aspects of optimization procedures.
Second, we think it will be much harder to learn something about search in a toy model and transfer that to a larger model because the kind of mesa-optimization is much more messy and diverse than this hypothesis assumes. We think it’s possible that “we investigate how toy networks play chess to understand how future models plan takeover” could be as fruitful as something like “we investigate how babies plan their hand movement to understand how adults plan to take over the world”.
In some way, it might not be meaningful to think of mesa-optimization in these binary terms in such a heuristic-based setting in the first place. For example, if a human plays chess, are they doing mesa-optimization? Probably they engage in a little bit of planning, so they optimize. Now what if the human is given only one second to decide on the next move, are they still doing mesa-optimization? They probably don’t simulate many moves in that second but the heuristics that shape their decisions might be approximations of steps that they have previously considered when thinking longer. Thus, their actions are a consequence of and an approximation to an optimization procedure but at that very moment, they are not optimizing. This is roughly how we think about mesa-optimization in feed-forward models. The network’s actions can approximate the results of cleaner optimization procedures but they are probably not running the clean optimization procedure during a forward pass.
Falsifiable predictions
To test if our theory is plausible, we make a couple of falsifiable predictions.
Firstly, we expect that even models that solve problems that are usually solved with optimizers do not use the kind of optimization humans use, i.e. an iterative application of the same procedure. For example
- When models are trained to solve small optimization tasks like Knapsack, they will not rediscover either the recursive or the dynamic programming solution to the problem. Instead, we predict that they will use heuristics that have aspects of the optimization procedure but are otherwise different.
- We expect the same for maze-solving models or NNs trained to play chess.
Second, we expect that when general-purpose models like GPT-3 are playing chess, they do not call an internal optimizer. Instead, they might apply heuristics that either have small components of optimization procedures or are approximations of aspects of explicit optimization. We expect that most of the decisions will come from highly refined heuristics learned from the training data.
A corollary of this prediction is that a model will use different internal circuits for games that could be solved with the same clean optimization algorithm. For example, when you ask GPT-3 to suggest the next Go move, we predict that the model uses a different circuit than when it is asked to suggest the next chess move even if both could in theory be solved with MCTS.
To test how context-dependent different circuits are, we can run them on symmetrical settings and see if/where they diverge.
General implications
We think these considerations have a couple of important implications if they are true.
- Mesa-optimization is more continuous than we (at least the authors) thought, i.e. GPT-2 does a bit of mesa-optimization, GPT-3 a bit more, GPT-4 even more, etc. This also implies that there wouldn’t be a hard step-function from “model doesn’t do mesa-optimization” to “model does mesa-optimization”. This might allow us to study mesa-optimization for longer and e.g. derive scaling laws for it and thus reduce the ability of a sudden surprise. However, there can still be sharp jumps in behavior related to mesa-optimization just like other phenomena emerge with scale.
- Mesa-optimization is more fuzzy, distributed and context-sensitive than we previously expected. Rather than the model building an internal general tool for MCTS or SGD, it uses a lot of heuristics that sometimes do and sometimes don’t translate between contexts. This would imply that “searching for search”, i.e. looking for general patterns that hold between different networks and architectures might be misguided since the patterns that look like search in one setting might be different from the search in another setting.
Importantly, many of these considerations rely on future architectures being similar to current architectures in some core ways, e.g. a distinction between forward and backward pass. If the architectures change, so do many of the implications in this post.
On a more personal note, thinking about this post made us more hopeful that mesa-optimization increases gradually and we thus get a bit of time to study it before it is too powerful but it made us more pessimistic about finding general tools that can tell us whether the model is currently doing mesa-optimization.
- ^
By ‘clean’ we mean something like "could easily be implemented in a Python program" or “applies the same simple step over and over again” as opposed to an ‘unclean’ heuristic that is hard to put into a formal framework.
6 comments
Comments sorted by top scores.
comment by wesg (wes-gurnee) · 2023-03-21T22:30:28.236Z · LW(p) · GW(p)
There has been some work on understanding in-context learning which suggests that models are doing literal gradient descent:
- Transformers learn in-context by gradient descent
- What learning algorithm is in-context learning? investigations with linear models
- Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
Superposition allows the model to do a lot of things at once. Thus, if the model wants to use its space efficiently, it performs multiple steps at once or uses highly compressed heuristics even if they don’t cover all corner cases. Especially in feed-forward models, the model can’t repeatedly apply the same module. Thus, implementing a “clean” algorithm would require implementing a similar algorithm in multiple layers which seems very space inefficient.
I think the first and last sentence are inconsistent. Since superposition lets you do so much at once, you can get away with having this redundancy in every layer, especially if this capacity is dedicated to a general search process that would reduce loss across a wide variety of tasks.
When models are trained to solve small optimization tasks like Knapsack, they will not rediscover either the recursive or the dynamic programming solution
I think it depends on the problem size. If the number of layers is greater than the max weight, then I would expect the model to implement the DP algorithm (and if less, I wouldn't be surprised if it still implemented an approximate DP algorithm).
In general though, I agree that the bounded depth is what makes it hard for a transformer to implement general optimization procedures.
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2023-03-22T08:40:48.967Z · LW(p) · GW(p)
How confident are you that the model is literally doing gradient descent from these papers? My understanding was that the evidence in these papers is not very conclusive and I treated it more as an initial hypothesis than an actual finding.
Even if you have the redundancy at every layer, you are still running copies of the same layer, right? Intuitively I would say this is not likely to be more space-efficient than not copying a layer and doing something else but I'm very uncertain about this argument.
I intend to look into the Knapsack + DP algorithm problem at some point. If I were to find that the model implements the DP algorithm, it would change my view on mesa optimization quite a bit.
↑ comment by abhayesian · 2023-03-22T16:56:00.782Z · LW(p) · GW(p)
I think that these papers do provide sufficient behavioral evidence that transformers are implementing something close to gradient descent in their weights. Garg et al. 2022 examine the performance of 12-layer GPT-style transformers trained to do few-shot learning and show that they can in-context learn 2-layer MLPs. The performance of their model closely matches an MLP with GD for 5000 steps on those same few-shot examples, and it cannot be explained by heuristics like averaging the K-nearest neighbors from the few-shot examples. Since the inputs are fairly high-dimensional, I don't think they can be performing this well by only memorizing the weights they've seen during training. The model is also fairly robust to distribution shifts in the inputs at test time, so the heuristic they must be learning should be pretty similar to a general-purpose learning algorithm.
I think that there also is some amount of mechanistic evidence that transformers implement some sort of iterative optimization algorithm over some quantity stored in the residual stream. In one of the papers mentioned above (Akyurek et al. 2022), the authors trained a probe to extract the ground-truth weights of the linear model from the residual stream and it appears to somewhat work. The diagrams seem to show that it gets better when trained on activations from later layers, so it seems likely that the transformer is iteratively refining its prediction of the weights.
comment by TurnTrout · 2023-03-31T20:20:38.572Z · LW(p) · GW(p)
Overall, strong upvote, I like this post a lot, these seem like good updates you've made.
we think that mesa-optimizers will primarily use a complicated stack of heuristics that takes elements from different clean optimization procedures. In the future, these internal heuristics might be combined with external optimization procedures like calculators or physics engines. This is similar to how humans that play chess don't actually run a tree-search of depth n with alpha-beta pruning in their heads.
I agree. Heuristic-free search seems very inefficient and inappropriate for real-world intelligence [LW(p) · GW(p)].
we think it will be much harder to learn something about search in a toy model and transfer that to a larger model because the kind of mesa-optimization is much more messy and diverse than this hypothesis assumes.
I agree. However, I agree with this as an argument against direct insight transfer from toy->real-world models. If you don't know how to do anything with anything for how e.g. an adult would plan real-world takeover, start simple IMO.
Second, we expect that when general-purpose models like GPT-3 are playing chess, they do not call an internal optimizer. Instead, they might apply heuristics that either have small components of optimization procedures or are approximations of aspects of explicit optimization. We expect that most of the decisions will come from highly refined heuristics learned from the training data.
First, thanks for making falsifiable predictions. Strong upvote for that. Second, I agree with this point. See also my made-up account of what might happen in a kid's brain when he decides to wander away from his distracting friends [LW · GW]. (It isn't explicit search.)
However, I expect there to be something like... generally useful predictive- and behavior-modifying circuits (aliased to "general-purpose problem-solving module", perhaps), such that they get subroutine-called by many different value shards. Even though I think those subroutines are not going to be MCTS.
On a more personal note, thinking about this post made us more hopeful that mesa-optimization increases gradually and we thus get a bit of time to study it before it is too powerful but it made us more pessimistic about finding general tools that can tell us whether the model is currently doing mesa-optimization.
I feel only somewhat interested in "how much mesaoptimization is happening?", and more interested in "what kinds of cognitive work is being done, and how, and towards what ends?" (IE what are the agent's values, and how well are they being worked towards?)
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2023-03-31T20:51:03.492Z · LW(p) · GW(p)
Thank you!
I also agree that toy models are better than nothing and we should start with them but I moved away from "if we understand how toy models do optimization, we understand much more about how GPT-4 does optimization".
I have a bunch of project ideas on how small models do optimization. I even trained the networks already. I just haven't found the time to interpret them yet. I'm happy for someone to take over the project if they want to. I'm mainly looking for evidence against the outlined hypothesis, i.e. maybe small toy models actually do fairly general optimization. Would def. update my beliefs.
I'd be super interested in falsifiable predictions about what these general-purpose modules look like. Or maybe even just more concrete intuitions, e.g. what kind of general-purpose modules you would expect GPT-3 to have. I'm currently very uncertain about this.
I agree with your final framing.
comment by baturinsky · 2023-03-21T16:27:39.646Z · LW(p) · GW(p)
Can we instill heuristics into AI to lock down some dangerous routes of thinking? For example, can we make it assume that "thinking about microbiology or nanotech do not lead to anything interesting" or "if I make a copy of me it will be hostile to me"?