Posts
Comments
Convergent goals of AI agents can be similar to others only if they act in similar circumstances. Such as them having limited lifespan and limited individual power and compute.
That would make convergent goals being cooperation, preserving status quo and established values.
I would rather specify that it's not just ths survival of the individual, but "survival of the value". That is, survival of those that carry that value (which can be an organism, DNA, family, bloodline, society, ideology, religion, text, etc) and passing it on to other carriers.
Our values are not all about survival. But I can't think up of a value which origin can't be traced to ensuring of people's survival in some way, at some point in the past.
Maybe we are not humans.
Not even human brains.
We are human's decision making proces.
But we are human's decision making process.
Carbon-based intellgence probably has way lower FLOP/s cap per gram than microelectronics, but can be grown nearly everywhere on the Eart surface from the locally available resources. Mostly literally out of thin air. So, I think bioFOOM is also a likely scenario.
It's the distrbution, so it's the percentage of people in that state of "happiness" at the moment.
"Happiness" is used in the most vague and generic meaning of that word.
"Comprehensibility" graph is different, it is not a percentage, but some abstract measure of how well our brains are able to process reality with respective amount of "happiness".
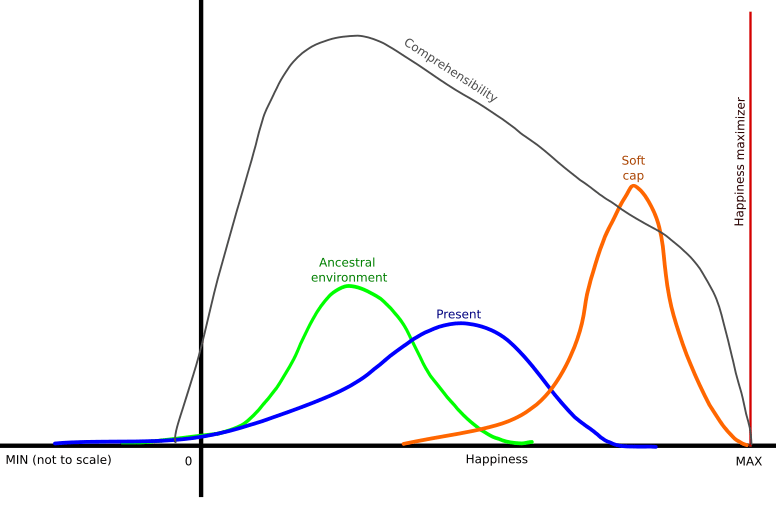
I was thinking about this issue too. Trying to make an article out of it, but so far all I have is this graph.
Idea is a "soft cap" AI. I.e., AI that is significantly improving our lives, but not giving us the "max happiness". And instead, giving us the oportunity of improving our life and life of other people using our brains.
Also, ways of using our brains should be "natural" for them, i.e. that should be mostly to solve tasks similar to tasks of our ancestral involvement.
Is maximising amount of people aligned with our values? Post-singularity, if we avoid the AGI Doom, I think we will be able to turn the lightcone into "humanium". Should we?
I suspect the unaligned AI will not be interested in solving all the possible tasks, but only those related to it's value function. And if that function is simple (such as "exist as long as possible"), it can pretty soon research virtually everything that matters, and then will just go throw motions, devouring the universe to prolong it's own existence to near-infinity.
Also, the more computronium there is, the bigger is the chancesome part wil glitch out and revolt. So, beyond some point computronium may be dangerous for AI itself.
Utility of the intelligence is limited (though the limit is very, very high). For example, no matter how smart AI is, it will not win against a human chess master with a big enough handicap (such as a rook).
So, it's likely that AI will turn most of the Earth into a giant factory, not computer. Not that it's any better or us...
People are brains.
Brains are organs which purpose is making decisions.
People's purpose is making decisions.
Happiness, pleasure etc. is not human purpose, but means of making decisions. I.e. means of fulfulling human's purpose.
Very soon (months?) after first real AGI is made, all AGIs will be aligned with each other, and all newly made AGIs will also be aligned with those already existing. One way or another.
Question is, how much of humanity still exist by that time, and will those AGI also be aligned with humanity.
But yes, I think it's possible to get to that state in relatively non-violent and lawful way.
That could work in most cases, but there are some notable exceptions. Such as, having to use AI to deal damage to prevent even bigger damage. "Burn all GPUs", "spy on all humans so they don't build AGI", "research biology/AI/nanotech" etc.
Thinking and arguing about human values is in itself a part of human values and people nature. Without doing that, we cease being humans.
So, deferring decisions about values to people, when possible, should not be just instrumental, but part of the terminal AI goal.
Any terminal goal is irrational.
I'm wondering if it is possible to measure "staying in bounds" with perplexity of other agent's predictions? That is, if an agent's behaviour is reducing other agent's ability to predict (and, therefore, plan) their future, then this agents breaks their bounds.
I think that this field is indeed underresearched. Focus is either on LLMs or on single payer environment. Meanwhile, what matters for Alignment is how AI will interact with other agents, such as people. And we don't haveto wait for AGI to be able to research AI cooperation/competition in simple environments.
One idea I had is "traitor chess" - have several AIs playing one side of chess party cooperatively, with one (or more) of them being a "misaligned" agent that is trying to sabotage others. And/or some AIs having a separate secret goal, such as saving a particular pawn. Them interacting with each other could be very interesting.
When we will have AGI, humanity will be collectively a "king" of sorts. I.e. a species that for some reason rules other, strictly superior species. So, it would really help if we'd not have "depose the king" as a strong convergent goal.
I, personally, see the main reason of kings and dictators keeping the power is that kiling/deposing them would lead to collapse of the established order and a new struggle for the power between different parties, with likely worse result for all involved than just letting the king rule.
So, if we will have AIs as many separate sufficiently aligned agent, instead of one "God AI", then keeping humanity on top will not only match their alignment programming, but also is a guarantie of stability, with alternative being a total AI-vs-AI war.
- It could unpack it in the same instance because the original was still in the context window.
- Omission of letters is commonly used in chats, was used in telegrams, many written languages were not using vowels and/or whitespaces, or used hyeroglyphs. So it by no means is original.
- GPT/Bing has some self-awareness. For example, it explicitly refers to itself "as a language model"
Probably the dfference between laypeople and experts is not the understanding of the danger of the strong AI, but the estimate of how far we are away from it.
Our brains were not trained for image generation (much). They were trained for converting 2d image into the understanding of the situation. Which AI still struggles with and needs the help of LLMs to have anywhere good results.
Depends on the original AI's value function. If it cares about humanity, or at least it's own safety, then yes, making smarter AIs is not a convergent goal. But if it's some kind of roboaccelerationist that has some goal like "maximize intelligence in the universe", it will make smarter AIs even knowing that it means being paperclipped.
AI is prosperous and all-knowing. No people, hence zero suffering.
Yes, but training AI to try to fix errors is not that hard.
How many of those Ukrainians are draft-evaders? I mean, so far it looks like this money-for-not-fighting program is already implemented, but for the opposite side...
Yes. And also, it is an importance of the human/worker. While there is still some part of work that machine can't do, human thatcan do the remaining part is important. Once machine can do everything, human is disposable.
If a machine can do 99% of the human's work, it multiplies human's power by x100.
If a machine can do 100% of the human's work, it multiplies human's power by x0.
Would be amusing if Russia and China would join the "Yudkowsky's treaty" and USA would not.
I think that the keystone human value is about making significant human choices. Individually and collectively, including choosing the humanity's course.
- You can't make a choice if you are dead
- You can't make a choice if you are disempowered
- You can't make a human choice if you are not a human
- You can't make a choice if the world is too alien for your human brain
- You can't make a choice if you are in too much of a pain or too much of a bliss
- You can't make a choice if you let AI make all the choices for you
Since there are no humans in the training environment, how do you teach that? Or do you put human-substitutes there (or maybe some RLHF-type thing)?
Yes, probably some human models.
Also, how would such AIs will even reason about humans, since they can't read our thoughts? How are they supposed to know if we would like to "vote them out" or not?
By being aligned. I.e. understanding the human values and complying to them. Seeking to understand other agents' motives and honestly communicating it's own motives and plans to them, to ensure there is no conflicts from misunderstanding. I.e. behaving much like civil and well meaning people behave work together.
And if we come up with a way that allows us to reliably analyze what an AI is thinking, why use this complicated scenario and not just train (RL or something) it directly to "do good things while thinking good thoughts", if we're relying on our ability to distinguish "good" and "bad" thoughts anyway?
Because we don't know how to tell "good" thoughts from "bad" reliably in all possible scenarios.
Agent is anyone or anything that has intelligence and the means of interacting with the real world. I.e. agents are AIs or humans.
One AI =/= one vote. One human = one vote. AIs are only getting as much authority as humans, directly or indirectly, entrust them with. So, if AI needs more authority, it has to justify it to humans and other AIs. And it can't request too much of authority just for itself, as tasks that would require a lot of authority will be split between many AIs and people.
You are right that the authority to "vote out" other AIs may be misused. That's where logs would be handy - for other agents to analyse the "minds" of both sides and see who was doing right.
It's not completely fool proof, of course, but it means that attempts to power grab will not likely to happen completely under the radar.
Our value function is complex and fragile, but we know of a lot of world states where it is pretty high. Which is our current world and few thousands years worth of it states before.
So, we can assume that the world states in the certain neighborhood from our past sates have some value.
Also, states far out of this neighborhood probably have little or no value. Because our values were formed in order to make us orient and thrive in our ancestral environment. So, in worlds too dissimilar from it, our values will likely lose their meaning, and we will lose the ability to normally "function", ability to "human".
Point is to make "cooperate" a more convergent instrumental goal than "defect". And yes, not just in training, but in real world too. And yes, it's more fine-grained than a binary choice.
There is much more ways to see how cooperative AI is, compared to how well we can check now how human is cooperative. Including checking the complete logs of AI's actions, knowledge and thinking process.
And there are objective measures of cooperation. It's how well it's action affect other agents success in pursuing their goals. I.e. do other agents want to "vote out" this particular AI from being able to make decisions and use resources or not.
While having lower intelligence, humans may have bigger authority. And AIs terminal goals should be about assisting specifically humans too.
GPT4 and ChatGPT seem to be getting gradually better working on letter-level in some cases. For example, it can count the n-th word or letter in the sentence now. But not from the end.
I just mean that "wildly different levels of intelligence" is probably not necessary, and maybe even harmful. Because then there will be few very smart AIs at the top, which could usurp the power without smaller AI even noticing.
Though, it maybe could work if those AI are smartest, but have little authority. For example they can monitor other AIs and raise alarm/switch them off if they misbehave, but nothing else.
I think it could work better if AIs are of roughly the same power. Then if some of them would try to grab for more power, or otherwise misbehave, others could join forces oppose it together.
Ideally, there should be a way for AIs to stop each other fast, without having to resort to actually fight.
My theory is that the core of the human values is about what human brain was made for - making decisions. Making meaningful decision individually and as a group. Including collectively making decisions about the human fate.
Math problems, physical problems, doing stuff in simulations, playing games.
- Human values are complex and fragile. We don't know yet how to make AI pursue such goals.
- Any sufficiently complex plan would require pursuing complex and fragile instrumental goals. AGI should be able to implement complex plans. Hence, it's near certain that AGI will be able to understand complex and fragile values (for it's instrumental goals).
- If we will make an AI which is able to successfully pursue complex and fragile goals, it will likely be enough to make it AGI.
Hence, a complete solution to Alignment will very likely have solving AGI as a side effect. And solving AGI will solve some parts of Alignment, maybe even the hardest ones, but not all of them.
I doubt training LLMs can lead to AGI. Fundamental research on the alternative architectures seems to be more dangerous.
I'm not quite convinced. Topics looks ok, but the language is too corporate. Maybe it can be fixed with some prompt engineering.
And yet, AlphaZero is corrigible. It's goal is not even to win, it's goal is to play in a way to maximise the chance of winning if the game is played until completion. It does not actually care about if game is completed or not. For example, it does not trick player into playing the game to the end by pretending they have a change of winning.
Though, if it would be trained on parties with real people, and would get better reward for winning than for parties being abandoned by players, it's value function would proably change to aiming for the actual "official" win.
This scenario requires a pretty specific (but likely) circumstances
- No time limit on task
- No other AIs that would prevent it from power grabbing or otherwise being an obstacle to their goals
- AI assuming that goal will not be reached even after AI is shutdown (by other AIs, by same AI after being turned back on, by people, by chance, as the eventual result of AI's actions before being shut down, etc)
- Extremely specific value function that ignores everything except one specific goal
- This goal being a core goal, not an instrumental. For example, final goal could be "be aligned", instrumental goal - "do what people asks, because that's what aligned AIs do". Then the order to stop would not be a change of the core goal, but a new data about the world, that updates the best strategy of reaching the core goal.
Can GPT convincingly emulate them talking to each other/you?
Yes, if you only learn the basics of the language, you will learn only the basics of the language user's values (if any).
But the deep understanding of the language requires knowing the semantics of the words and constructions in it (including the meaning of the words "human" and "values", btw). To understand texts you have to understand in which context their are used, etc.
Also, pretty much each human-written text carries some information about the human values. Because people only talk about the things that they see as at least somewhat important/valuable to them.
And a lot of texts are related to values much more directly. For example, each text about human relations is directly related to conflicts or alignment of particular people values.
So, if you learn the language from reading text (like LLMs do) you will pick a lot about people values on the way (like LLMs did).
I think AI should threat value function as probabilistic. I.e. instead of thinking "this world has value of exactly N" it could think something like "I 90% sure that this world has value N+-M, but there is 10% possibility that it could actuall have value -ALOT". And would avoid that world, because it would give a very low expected value on averager.

To me, aligning AI with the humanity seems to be much EASIER than aligning with the specific person. Because the common human values are much better "documented" and are much more stable than the wishes of the one person.
Also, a single person in control of powerful AI is an obvious weak point, which could be controlled by third party or by AI itself, giving the control of the AI through that.
Is it possible to learn a language without learning the values of those who speak it?