FLI open letter: Pause giant AI experiments
post by Zach Stein-Perlman · 2023-03-29T04:04:23.333Z · LW · GW · 123 commentsThis is a link post for https://futureoflife.org/open-letter/pause-giant-ai-experiments/
Contents
123 comments
We call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4.
AI systems with human-competitive intelligence can pose profound risks to society and humanity, as shown by extensive research and acknowledged by top AI labs. As stated in the widely-endorsed Asilomar AI Principles, Advanced AI could represent a profound change in the history of life on Earth, and should be planned for and managed with commensurate care and resources. Unfortunately, this level of planning and management is not happening, even though recent months have seen AI labs locked in an out-of-control race to develop and deploy ever more powerful digital minds that no one – not even their creators – can understand, predict, or reliably control.
Contemporary AI systems are now becoming human-competitive at general tasks, and we must ask ourselves: Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization? Such decisions must not be delegated to unelected tech leaders. Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable. This confidence must be well justified and increase with the magnitude of a system's potential effects. OpenAI's recent statement regarding artificial general intelligence, states that "At some point, it may be important to get independent review before starting to train future systems, and for the most advanced efforts to agree to limit the rate of growth of compute used for creating new models." We agree. That point is now.
Therefore, we call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4. This pause should be public and verifiable, and include all key actors. If such a pause cannot be enacted quickly, governments should step in and institute a moratorium.
AI labs and independent experts should use this pause to jointly develop and implement a set of shared safety protocols for advanced AI design and development that are rigorously audited and overseen by independent outside experts. These protocols should ensure that systems adhering to them are safe beyond a reasonable doubt. This does not mean a pause on AI development in general, merely a stepping back from the dangerous race to ever-larger unpredictable black-box models with emergent capabilities.
AI research and development should be refocused on making today's powerful, state-of-the-art systems more accurate, safe, interpretable, transparent, robust, aligned, trustworthy, and loyal.
In parallel, AI developers must work with policymakers to dramatically accelerate development of robust AI governance systems. These should at a minimum include: new and capable regulatory authorities dedicated to AI; oversight and tracking of highly capable AI systems and large pools of computational capability; provenance and watermarking systems to help distinguish real from synthetic and to track model leaks; a robust auditing and certification ecosystem; liability for AI-caused harm; robust public funding for technical AI safety research; and well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause.
Humanity can enjoy a flourishing future with AI. Having succeeded in creating powerful AI systems, we can now enjoy an "AI summer" in which we reap the rewards, engineer these systems for the clear benefit of all, and give society a chance to adapt. Society has hit pause on other technologies with potentially catastrophic effects on society. We can do so here. Let's enjoy a long AI summer, not rush unprepared into a fall.
Signatories include Yoshua Bengio, Stuart Russell, Elon Musk, Steve Wozniak, Yuval Noah Hariri, Andrew Yang, Connor Leahy (Conjecture), and Emad Mostaque (Stability).
Edit: covered in NYT, BBC, WaPo, NBC, ABC, CNN, CBS, Time, etc. See also Eliezer's piece in Time [LW · GW].
Edit 2: see FLI's FAQ.
Edit 3: see FLI's report Policymaking in the Pause [LW · GW].
Edit 4: see AAAI's open letter.
123 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2023-03-29T04:39:59.196Z · LW(p) · GW(p)
I think this letter is not robust enough to people submitting false names. Back when Jacob and I put together DontDoxScottAlexander.com we included this section, and I would recommend doing something pretty similar:
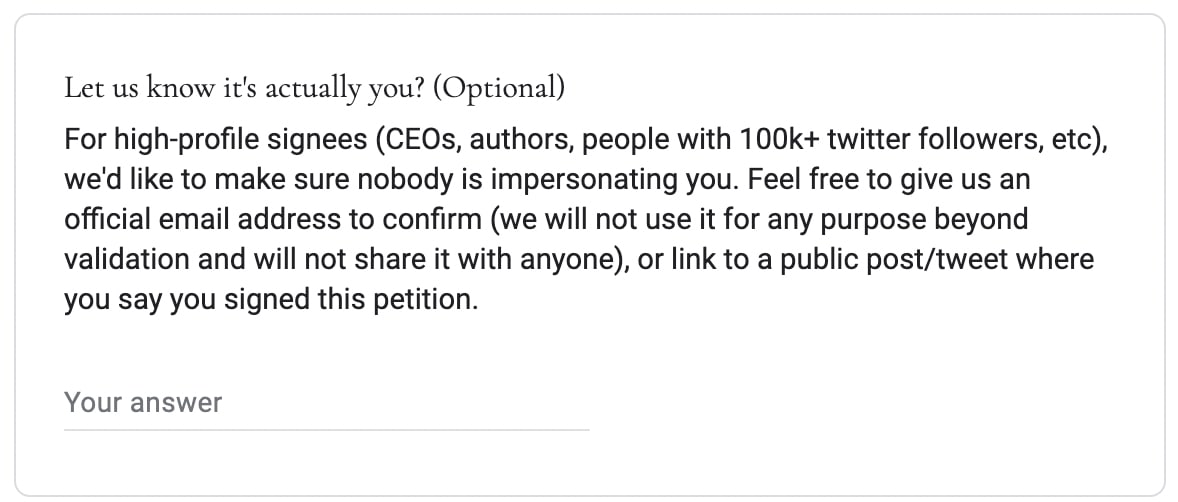
I think someone checking some of these emails would slow down high-profile signatories by 6-48 hours, but sustain trust that the names are all real.
I'm willing to help out if those running it would like, feel free to PM me.
Replies from: AnnaSalamon, localdeity, jimrandomh, Evan R. Murphy↑ comment by AnnaSalamon · 2023-03-29T05:28:01.924Z · LW(p) · GW(p)
Oh no. Apparently also Yann LeCun didn't really sign this.
↑ comment by localdeity · 2023-03-29T04:42:49.932Z · LW(p) · GW(p)
Indeed. Among the alleged signatories:
Xi Jinping, Poeple's Republic of China, Chairman of the CCP, Order of the Golden Eagle, Order of Saint Andrew, Grand Cordon of the Order of Leopold
Which I heavily doubt.
Replies from: Benito, shankar-sivarajan↑ comment by Ben Pace (Benito) · 2023-03-29T04:47:16.734Z · LW(p) · GW(p)
I concur, the typo in "Poeple" does call into question whether he has truly signed this letter.
↑ comment by Shankar Sivarajan (shankar-sivarajan) · 2023-08-07T17:59:58.906Z · LW(p) · GW(p)
No, he really DOES have all those honors.
↑ comment by jimrandomh · 2023-03-29T07:49:26.916Z · LW(p) · GW(p)
I believe the high-profile names at the top are individually verified, at least, and it looks like there's someone behind the form deleting fake entries as they're noticed. (Eg Yann LeCun was on the list briefly, but has since been deleted from the list.)
Replies from: Benito, lahwran↑ comment by Ben Pace (Benito) · 2023-03-29T20:21:04.864Z · LW(p) · GW(p)
When we did Scott's petition, names were not automatically added to the list, but each name was read by me-or-Jacob, and if we were uncertain about one we didn't add it without checking in with others or thinking it over. This meant that added names were staggered throughout the day because we only checked every hour or two, but overall prevented a number of fake names from getting on there.
(I write this to contrast it with automatically adding names then removing them as you notice issues.)
↑ comment by the gears to ascension (lahwran) · 2023-03-29T08:35:39.335Z · LW(p) · GW(p)
Lecun heard he was incorrectly added to the list, so the reputational damage still mostly occurred.
Replies from: M. Y. Zuo↑ comment by Evan R. Murphy · 2023-03-29T20:30:45.647Z · LW(p) · GW(p)
Yea they made a mistake not verifying signatures from the beginning. But they have course-corrected, see this notice FLI has posted now above the signatories list:
Signatories list paused due to high demand
Due to high demand we are still collecting signatures but pausing their appearance on the letter so that our vetting processes can catch up. Note also that the signatures near the top of the list are all independently and directly verified.
comment by Esben Kran (esben-kran) · 2023-03-29T15:39:51.360Z · LW(p) · GW(p)
It seems like there's a lot of negative comments about this letter. Even if it does not go through, it seems very net positive for the reason that it makes explicit an expert position against large language model development due to safety concerns. There's several major effects of this, as it enables scientists, lobbyists, politicians and journalists to refer to this petition to validate their potential work on the risks of AI, it provides a concrete action step towards limiting AGI development, and it incentivizes others to think in the same vein about concrete solutions.
I've tried to formulate a few responses to the criticisms raised:
- "6 months isn't enough to develop the safety techniques they detail": Besides it being at least 6 months, the proposals seem relatively reasonable within something as farsighted as this letter. Shoot for the moon and you might hit the sky, but this time the sky is actually happening and work on many of their proposals is already underway. See e.g. EU AI Act, funding for AI research [AF · GW], concrete auditing work and safety evaluation on models. Several organizations are also working on certification and the scientific work towards watermarking is sort of done? There's also great arguments for ensuring this since right now, we are at the whim of OpenAI management on the safety front.
- "It feels rushed": It might have benefitted from a few reformulations but it does seem alright?
- "OpenAI needs to be at the forefront": Besides others clearly lagging behind already, what we need are insurances that these systems go well, not at the behest of one person. There's also a lot of trust in OpenAI management and however warranted that is, it is still a fully controlled monopoly on our future. If we don't ensure safety, this just seems too optimistic (see also differences between public interview for-profit sama and online sama).
- "It has a negative impact on capabilities researchers": This seems to be an issue from <2020 and some European academia. If public figures like Yoshua cannot change the conversation, then who should? Should we just lean back and hope that they all sort of realize it by themselves? Additionally, the industry researchers from DM and OpenAI I've talked with generally seem to agree that alignment is very important, especially as their management is clearly taking the side of safety.
- "The letter signatures are not validated properly": Yeah, this seems like a miss, though as long as the top 40 names are validated, the negative impacts should be relatively controlled.
All in good faith of course; it's a contentious issue but this letter seems generally positive to me.
Replies from: Benito, M. Y. Zuo↑ comment by Ben Pace (Benito) · 2023-03-29T20:24:45.909Z · LW(p) · GW(p)
Just repeating from my other comments [LW · GW]: my main issue is the broad proposal of "let's get governments involved" that appears to not be aware of all the horrible and corrupt things governments do by-default when they get involved (cf. Covid), nor proposes any ways to avoid lots of dysfunction.
Replies from: LeonidArtamonov↑ comment by Leo (LeonidArtamonov) · 2023-03-30T19:00:06.803Z · LW(p) · GW(p)
Just compare how collaborative governments solving global warming versus Gates Foundation solving polio.
↑ comment by M. Y. Zuo · 2023-03-29T17:25:22.682Z · LW(p) · GW(p)
- "The letter signatures are not validated properly": Yeah, this seems like a miss, though as long as the top 40 names are validated, the negative impacts should be relatively controlled.
The top 40 names were definitely not validated at the time of posting. (or even now?)
Has anyone representing the organization stated on the record that the remaining signatories are legitimate?
comment by Ben Pace (Benito) · 2023-03-29T04:35:49.371Z · LW(p) · GW(p)
AI labs and independent experts should use this pause to jointly develop and implement a set of shared safety protocols for advanced AI design and development that are rigorously audited and overseen by independent outside experts. These protocols should ensure that systems adhering to them are safe beyond a reasonable doubt.
That's nice, but I don't currently believe there are any audits or protocols that can prove future AIs safe "beyond a reasonable doubt".
In parallel, AI developers must work with policymakers to dramatically accelerate development of robust AI governance systems. These should at a minimum include: new and capable regulatory authorities dedicated to AI; oversight and tracking of highly capable AI systems and large pools of computational capability; provenance and watermarking systems to help distinguish real from synthetic and to track model leaks; a robust auditing and certification ecosystem; liability for AI-caused harm; robust public funding for technical AI safety research; and well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause.
Would the authors also like the moon on a stick? :P
I'm not planning to sign it, these lines seem to contain too many things I would not say myself, though I do think that the goal of having a 6-month pause would be pretty good if attained, and I would sign a narrower letter that simply argued for the pause and not some of the rest of this stuff that has been tacked on.
Replies from: Evan R. Murphy, evhub↑ comment by Evan R. Murphy · 2023-03-29T05:54:52.581Z · LW(p) · GW(p)
The letter isn't perfect, but the main ask is worthwhile as you said. Coordination is hard, stakes are very high and time may be short, so I think it is good to support these efforts if they are in the ballpark of something you agree with.
Replies from: Benito, DanielFilan↑ comment by Ben Pace (Benito) · 2023-03-29T06:01:48.925Z · LW(p) · GW(p)
I don't agree with the recommendation, so I don't think I should sign my name to it.
To describe a concrete bad thing that may happen: suppose the letter is successful and then there is a pause. Suppose a bunch of AI companies agree to some protocols that they say that these protocols "ensure that systems adhering to them are safe beyond a reasonable doubt". If I (or another signatory) is then to say "But I don't think that any such protocols exist" I think they'd be in their right to say "Then why on Earth did you sign this letter saying that we could find them within 6 months?" and then not trust me again to mean the things I say publicly.
Replies from: Evan R. Murphy↑ comment by Evan R. Murphy · 2023-03-29T06:20:58.059Z · LW(p) · GW(p)
The letter says to pause for at least 6 months, not exactly 6 months.
So anyone who doesn't believe that protocols exist to ensure the safety of more capable AI systems shouldn't avoid signing the letter for that reason, because the letter can be interpreted as supporting an indefinite pause in that case.
Replies from: Benito, None↑ comment by Ben Pace (Benito) · 2023-03-29T06:34:56.864Z · LW(p) · GW(p)
Oh, I didn't read that correctly. Good point.
I am concerned about some other parts of it, that seem to imbue a feeling of "trust in government" that I don't share, and I am concerned that if this letter is successful then governments will get involved in a pretty indiscriminate and corrupt way and then everything will get worse; but my concern is somewhat vague and hard to pin down.
I think it'd be good for me to sleep on it, and see if it seems so bad to sign on to the next time I see it.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-29T20:17:47.542Z · LW(p) · GW(p)
I've slept, and now looked it over again.
Such decisions must not be delegated to unelected tech leaders.
I don’t agree with the clear implication that the problem with tech leaders is that they weren’t elected. I commonly think their judgment is better than people who are elected and in government. I think competent and elected people are best, but given the choice between only competent or only elected (in the current shitty electoral systems of the UK and the US that I am familiar with), I think I prefer competent.
If such a pause cannot be enacted quickly, governments should step in and institute a moratorium.
I don’t think this threat is very good. Firstly, it seems a bit empty. This is not the government speaking, I don’t know that FLI is in a position to make the government do this. Secondly, it doesn’t feel like… it feels closer to just causing uncontrollable chaos than it does to doing anything sensible. Maybe it works, but I haven’t seen any arguments that governments won’t just become pretty corrupt and mess everything up if given pretty vague yet significant power. I would much rather the current status quo where I think, in principle, you can have a conversation with the relevant decision-makers and have arguments with them, rather than surrender to the government bureaucracies where pretty commonly there is nobody with any power to do anything differently, and any free power is being competed over by the biggest possible factions in the country, and also a lot of the unaccountable decision-makers are pretty corrupt (cf. Patrick McKenzie and Zvi’s writing about how Covid was dealt with), and where close to literally zero people understand how the systems work or the arguments for existential risks here.
I think people writing about realistic and concrete stories of how this could go well would change my mind here, but I don’t want to put my name to this threat, seems overall like reducing civilization’s agency in the matter, and I wouldn’t currently take this action myself.
I think a bunch of the rest of the letter is pretty good, I like the AI summer and AI fall bit at the end (it is tasteful in relation to “AI Winter”), I broadly like the proposal to redirect AI R&D to focus on the list of things like interpretable and aligned. A bunch of the other sentences seem true, I do think this was pretty well written overall, but the government stuff I’m not on-board with, and I haven’t seen any persuasive arguments for it.
I’m sticking with my position of not-signing this.
Replies from: Evan R. Murphy↑ comment by Evan R. Murphy · 2023-03-29T20:40:51.056Z · LW(p) · GW(p)
and where [in the government] close to literally zero people understand how the systems work or the arguments for existential risks here.
Just want to flag that I'm pretty sure this isn't true anymore. At least a few important people in the US government (and possibly many) have now taken this course . I am still in progress on my technical review of the course for AIGS Canada, but my take so far is that it provides a good education on relevant aspects of AI for a non-technical audience and also focuses quite a bit on AI existential risk issues.
(I know this only one point out of many you made but I wanted to respond to it when I spotted it and had time.)
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-29T20:55:05.899Z · LW(p) · GW(p)
Yep, it seems to good to me to respond to just one point that you disagreed with, definitely positive to do so relative to responding to none :)
I genuinely have uncertainty here, I know there were a bunch of folks at CSET who understood some of the args, I'm not sure whether/what roles they have in Government, I think of many of them as being in "policy think tanks" that are outside of government. Matheny was in the White House for a while but now he runs RAND; if he were still there I would be wrong and there would be at least one person who I believe groks the arguments and how a neural net works.
Most of my current probability mass is on literally 100% of elected officials do not understand the arguments or how a neural net works, but I acknowledge that they're not the only people involved in passing legislation/regulation.
↑ comment by [deleted] · 2023-03-29T15:14:12.981Z · LW(p) · GW(p)
Each 6 months pause costs all the knowledge and potential benefits of less stupid models (and prevents anyone from discovering their properties which may or may not be as bad as feared). Each pause narrows the lead with less ethical competitors.
Replies from: sanxiyn↑ comment by sanxiyn · 2023-03-29T23:06:16.051Z · LW(p) · GW(p)
To state the obvious, pause narrows the lead with less ethical competitors only if pause is not enforced against less ethical competitors. I don't think anyone is in favor of unenforced pause: that would be indeed stupid, as the basic game theory says.
My impression is that we disagree on how feasible it is to enforce the pause. In my opinion, at the moment, it is pretty feasible, because there simply are not so many competitors. Doing an LLM training run is a rare capability now. Things are fragile and I am in fact unsure whether it would be feasible next year.
Replies from: None↑ comment by [deleted] · 2023-03-29T23:54:59.907Z · LW(p) · GW(p)
How would the pause be enforced against foreign governments? We can't stop them from building nukes or starting wars or mass imprisoning their own people or mass murder or...
How would it be enforced against foreign and domestic companies working under the umbrella of the government?
How would the pause be enforced at all? No incident has actually happened yet, what are the odds the us government passes legislation about a danger that hasn't even been seen?
↑ comment by DanielFilan · 2023-03-29T18:03:35.850Z · LW(p) · GW(p)
I think you can support a certain policy without putting your name to a flawed argument for that policy. And indeed ensuring that typical arguments for your policy are high-quality is a forrm of support.
↑ comment by evhub · 2023-03-30T00:45:21.871Z · LW(p) · GW(p)
That's nice, but I don't currently believe there are any audits or protocols that can prove future AIs safe "beyond a reasonable doubt".
I think you can do this with a capabilities test (e.g. ARC's [AF · GW]), just not with an alignment test (yet [AF · GW]).
Replies from: Nonecomment by dsj · 2023-03-29T07:16:56.008Z · LW(p) · GW(p)
Currently, OpenAI has a clear lead over its competitors.[1] This is arguably the safest arrangement as far as race dynamics go, because it gives OpenAI some breathing room in case they ever need to slow down later on for safety reasons, and also because their competitors don't necessarily have a strong reason to think they can easily sprint to catch up.
So far as I can tell, this petition would just be asking OpenAI to burn six months of that lead and let other players catch up. That might create a very dangerous race dynamic, where now you have multiple players neck-and-neck, each with a credible claim to have a chance to get into the lead.
(And I'll add: while OpenAI has certainly made decisions I disagree with, at least they actively acknowledge existential safety concerns and have a safety plan and research agenda. I'd much rather they be in the lead than Meta, Baidu, the Chinese government, etc., all of whom to my knowledge have almost no active safety research and in some cases are actively dismissive of the need for such.)
- ^
One might have considered Google/DeepMind to be OpenAI's peer, but after the release of Bard — which is substantially behind GPT-3.5 capabilities, never mind GPT-4 — I think this is a hard view to hold.
↑ comment by PeterMcCluskey · 2023-03-29T17:22:51.109Z · LW(p) · GW(p)
DeepMind might be more cautious about what it releases, and/or developing systems whose power is less legible than GPT. I have no real evidence here, just vague intuitions.
Replies from: dsj↑ comment by dsj · 2023-03-29T18:08:19.003Z · LW(p) · GW(p)
I agree that those are possibilities.
On the other hand, why did news reports[1] suggest that Google was caught flat-footed by ChatGPT and re-oriented to rush Bard to market?
My sense is that Google/DeepMind's lethargy in the area of language models is due to a combination of a few factors:
- They've diversified their bets to include things like protein folding, fusion plasma control, etc. which are more application-driven and not on an AGI path.
- They've focused more on fundamental research and less on productizing and scaling.
- Their language model experts might have a somewhat high annual attrition rate.
- I just looked up the authors on Google Brain's Attention is All You Need, and all but one have left Google after 5.25 years, many for startups, and one for OpenAI. That works out to an annual attrition of 33%.
- For DeepMind's Chinchilla paper, 6 of 22 researchers have been lost in 1 year: 4 to OpenAI and 2 to startups. That's 27% annual attrition.
- By contrast, 16 or 17 of the 30 authors on the GPT-3 paper seem to still be at OpenAI, 2.75 years later, which works out to 20% annual attrition. Notably, of those who have left, not a one has left for Google or DeepMind, though interestingly, 8 have left for Anthropic. (Admittedly, this somewhat reflects the relative newness and growth rates of Google/DeepMind, OpenAI, and Anthropic, since a priori we expect more migration from slow-growing orgs to fast-growing orgs than vice versa.)
- It's broadly reported that Google as an organization struggles with stifling bureaucracy and a lack of urgency. (This was also my observation working there more than ten years ago, and I expect it's gotten worse since.)
↑ comment by Kaj_Sotala · 2023-03-29T18:44:17.533Z · LW(p) · GW(p)
OpenAI seems to also have been caught flat-footed by ChatGPT, or more specifically by the success it got. It seems like the success came largely from the chat interface that made it intuitive for people on the street to use - and none of the LLM techies at any company realized what a difference that would make.
Replies from: dsj↑ comment by Douglas_Knight · 2023-03-29T20:50:33.487Z · LW(p) · GW(p)
I think talking about Google/DeepMind as a unitary entity is a mistake. I'm gonna guess that Peter agrees, and that's why he specified DeepMind. Google's publications identify at least two internal language models superior to Lambda, so their release of Bard based on Lambda doesn't tell us much. They are certainly behind in commercializing chatbots, but is that a weak claim. How DeepMind compares to OpenAI is difficult. Four people going to OpenAI is damning, though.
Replies from: dsj↑ comment by dsj · 2023-03-29T21:23:43.093Z · LW(p) · GW(p)
A somewhat reliable source has told me that they don't have the compute infrastructure to support making a more advanced model available to users.
That might also reflect limited engineering efforts to optimize state-of-the-art models for real world usage (think of the performance gains from GPT-3.5 Turbo) as opposed to hitting benchmarks for a paper to be published.
↑ comment by Evan R. Murphy · 2023-03-29T07:20:33.995Z · LW(p) · GW(p)
That might be true if nothing is actually done in the 6+ months to improve AI safety and governance. But the letter proposes:
Replies from: dsjAI labs and independent experts should use this pause to jointly develop and implement a set of shared safety protocols for advanced AI design and development that are rigorously audited and overseen by independent outside experts. These protocols should ensure that systems adhering to them are safe beyond a reasonable doubt.[4] This does not mean a pause on AI development in general, merely a stepping back from the dangerous race to ever-larger unpredictable black-box models with emergent capabilities.
AI research and development should be refocused on making today's powerful, state-of-the-art systems more accurate, safe, interpretable, transparent, robust, aligned, trustworthy, and loyal.
In parallel, AI developers must work with policymakers to dramatically accelerate development of robust AI governance systems. These should at a minimum include: new and capable regulatory authorities dedicated to AI; oversight and tracking of highly capable AI systems and large pools of computational capability; provenance and watermarking systems to help distinguish real from synthetic and to track model leaks; a robust auditing and certification ecosystem; liability for AI-caused harm; robust public funding for technical AI safety research; and well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause.
↑ comment by dsj · 2023-03-29T07:38:53.062Z · LW(p) · GW(p)
If a major fraction of all resources at the top 5–10 labs were reallocated to "us[ing] this pause to jointly develop and implement a set of shared safety protocols", that seems like it would be a good thing to me.
However, the letter offers no guidance as to what fraction of resources to dedicate to this joint safety work. Thus, we can expect that DeepMind and others might each devote a couple teams to that effort, but probably not substantially halt progress at their capabilities frontier.
The only player who is effectively being asked to halt progress at its capabilities frontier is OpenAI, and that seems dangerous to me for the reasons I stated above.
↑ comment by Ben Pace (Benito) · 2023-03-29T20:30:50.043Z · LW(p) · GW(p)
It's not clear to me that OpenAI has a clear lead over Anthropic in terms of capabilities.
Replies from: dsjcomment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T08:53:38.297Z · LW(p) · GW(p)
The letter feels rushed and leaves me with a bunch of questions.
1. "recent months have seen AI labs locked in an out-of-control race to develop and deploy ever more powerful digital minds that no one – not even their creators – can understand, predict, or reliably control."
Where is the evidence of this "out-of-control race"? Where is the argument that future systems could be dangerous?
2. "Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization? Such decisions must not be delegated to unelected tech leaders."
These are very different concerns that water down what the problem is the letter tries to address. Most of them are deployment questions more than development questions.
3. I like the idea of a six-month collaboration between actors. I also like the policy asks they include.
4. The main impact of this letter would obviously be getting the main actors to halt development (OpenAI, Anthropic, DeepMind, MetaAI, Google). Yet, those actors seem not to have been involved in this letter/ haven't publicly commented. (afaik) This seems like a failure.
5. Not making it possible to verify the names is a pretty big mistake.
6. In my perception, the letter mostly appears alarmist at the current time, especially since it doesn't include an argument for why future systems should be dangerous. It might just end up burning political capital.
Replies from: greg-colbourn, konstantin@wolfgangpilz.de↑ comment by Greg C (greg-colbourn) · 2023-03-29T10:26:06.230Z · LW(p) · GW(p)
GPT-4 was rushed, and the OpenAI Plugin store. Things are moving far too fast for comfort. I think we can forgive this response for being rushed. It's good to have some significant opposition working on the brakes to the runaway existential catastrophe train that we've all been put on.
↑ comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T11:50:58.324Z · LW(p) · GW(p)
Update: I think it doesn't make much sense to interpret the letter literally. Instead, it can be seen as an attempt to show that a range of people think that slowing down progress would be good, and I think it does an okay job at that (though I still think the wording could be much better, and it should present arguments for why we should decelerate.)
comment by Steven Byrnes (steve2152) · 2023-03-29T18:45:13.595Z · LW(p) · GW(p)
(cross-posting my take from twitter)
(1) I think very dangerous AGI will come eventually, and that we’re extremely not ready for it, and that we’re making slow but steady progress right now on getting ready, and so I’d much rather it come later than sooner.
(2) It’s hard to be super-confident, but I think the “critical path” towards AGI mostly looks like “research” right now, and mostly looks like “scaling up known techniques” starting in the future but not yet.
(3) I think the big direct effect of a moratorium on “scaling up” is substitution: more “research” than otherwise—which is the opposite of what I want. (E.g. “Oh, we're only allowed X compute / data / params? Cool—let's figure out how to get more capabilities out of X compute / data / params!!”)
(4) I'm sympathetic to the idea that some of the indirect effects of the FLI thing might align with my goals, like “practice for later” or “sending a message” or “reducing AI investments” etc. I’m also sympathetic to the fact that a lot of reasonable people in my field disagree with me on (2). But those aren’t outweighing (3) for me. So for my part, I’m not signing, but I’m also not judging those who do.
(5) While I’m here, I want to more generally advocate that, insofar as we’re concerned about “notkilleveryoneism” (and we should be), we should be talking more about “research” and less about “deployment”. I think that “things that happen within the 4 walls of an R&D department, and on arxiv & github” are the main ingredients in how soon dangerous AGI arrives; and likewise, if someday an AI gets out of control and kills everyone, I expect this specific AI to have never been deliberately “deployed” to the public. This makes me less enthusiastic about certain proposed regulations than some other people in my field, and relatively more enthusiastic about e.g. outreach & dialog with AI researchers […which might lead to them (A) helping with the alignment problem and (B) not contributing to AGI-relevant research & tooling (or at least not publishing / open-sourcing it)].
Further reading: https://80000hours.org/problem-profiles/artificial-intelligence/ & https://alignmentforum.org/posts/rgPxEKFBLpLqJpMBM/response-to-blake-richards-agi-generality-alignment-and-loss & https://www.alignmentforum.org/posts/MCWGCyz2mjtRoWiyP/endgame-safety-for-agi [AF · GW]
comment by baturinsky · 2023-03-29T06:25:17.852Z · LW(p) · GW(p)
I doubt training LLMs can lead to AGI. Fundamental research on the alternative architectures seems to be more dangerous.
comment by p.b. · 2023-03-29T13:34:03.972Z · LW(p) · GW(p)
I just want to point out that if successful this moratorium would be the fire alarm that otherwise doesn't exist for AGI.
The benefit would be the "industry leaders agree ..." headline, not the actual pause.
Replies from: gilch↑ comment by gilch · 2023-03-29T16:32:42.233Z · LW(p) · GW(p)
It's already a headline: https://www.bloomberg.com/news/articles/2023-03-29/ai-leaders-urge-labs-to-stop-training-the-most-advanced-models
comment by the gears to ascension (lahwran) · 2023-03-29T05:07:39.572Z · LW(p) · GW(p)
This letter is probably significantly net negative due to its impact on capabilities researchers who don't like it. I don't understand why the authors thought it was a good idea. Perhaps they don't realize that there's no possible enforcement of it that could prevent a GPT4 level model that runs on individual gpus from being trained? to the people who can do that, it's really obvious, and I don't think they're going to stop; but I could imagine them rushing harder if they think The Law is coming after them.
It's especially egregious because of accepting names without personal verification. That will probably amplify the negative response.
Replies from: AnnaSalamon, None↑ comment by AnnaSalamon · 2023-03-29T05:31:55.192Z · LW(p) · GW(p)
It may not be possible to prevent GPT4-sized models, but it probably is possible to prevent GPT-5-sized models, if the large companies sign on and don't want it to be public knowledge that they did it. Right?
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-29T05:56:22.868Z · LW(p) · GW(p)
Not for long. Sure, maybe it's a few months.
Replies from: sanxiyn↑ comment by sanxiyn · 2023-03-29T06:00:28.411Z · LW(p) · GW(p)
I mean, the letter is asking for six months, so it seems reasonable.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-29T06:02:22.652Z · LW(p) · GW(p)
perhaps. but don't kid yourself - that's the entire remaining runway!
↑ comment by [deleted] · 2023-03-29T05:24:52.243Z · LW(p) · GW(p)
It's outright surrendering to entropy and death.
"Beyond a reasonable doubt" the AI will be safe? "Don't do anything for 6 months to try to reach full human intelligence"?
Guess what happens in 6 months. They will say they aren't convinced the AI will be safe and ask for 6 more months and so on until another nation mass produces automated weapons (something they also have asked for banning) and conquers the planet.
Automated weapons are precisely the kind of thing that because they can attack in overwhelming coordinated swarms, the only defense is....yep, your own automated weapons. Human reactions are too slow.
Only way to know if a safety strategy will work is to build the thing.
Replies from: sanxiyn, lahwran, greg-colbourn↑ comment by sanxiyn · 2023-03-29T06:14:15.634Z · LW(p) · GW(p)
"Don't do anything for 6 months" is a ridiculous exaggeration. The proposal is to stop training for 6 months. You can do research on smaller models without training the large one.
I agree it is debatable whether "beyond a reasonable doubt" standard is appropriate, but it seems entirely sane to pause for 6 months and use that time to, for example, discuss which standard is appropriate.
Other arguments you made seem to say "we shouldn't cooperate if the other side defects", and I agree, that's game theory 101, but that's not an argument against cooperating? If you are saying anything more, please elaborate.
Replies from: None↑ comment by [deleted] · 2023-03-29T14:48:32.496Z · LW(p) · GW(p)
I am saying the stakes are enormously not in favor of cooperating just for the chance the other parties defect. Very similar to the logic that lead to nuclear arsenal buildups in the cold war.
As terrible as those weapons, it would have been even more terrible for the other side to secretly defect then surprise attack with them, an action we can be virtually certain they would have committed. Note this is bilateral: this is equally true from the East and West sides of the cold war.
↑ comment by the gears to ascension (lahwran) · 2023-03-29T06:02:03.515Z · LW(p) · GW(p)
Automated weapons can be replied to with nukes if they're the same scale, and the US has demonstrated drone amplification of fighter pilots, so I'm actually slightly less worried about that - as much as I hate their inefficiency and want them to get the fuck out of yemen, I'm also not worried about US losing air superiority. I'm pretty sure the main weapons risk from AI is superpathogens designed to kill all humans. Sure, humans wouldn't use them, but it's been imaginable how to build them for a while, it would only take an AI who thought they could live without us.
I think your model of safety doesn't match mine much at all. What's your timeline until AI that is stronger than every individual human at every competitive game?
Replies from: None↑ comment by [deleted] · 2023-03-29T14:55:59.734Z · LW(p) · GW(p)
No, automated weapons cannot be countered with nukes. I specifically meant the scenario of
-
General purpose task robotics controlling models. Appears extremely feasible because the generality hypothesis turns out to be correct. (meaning it's actually easier to solve all robotics tasks all at once than to solve individual ones to human level. Gpt-3 source is no more complex than efficient zero.)
-
Self replication which is an obvious property of 2
-
The mining manufacturing equivalent of having 10 billion or 100 billion workers.
-
Enough automated weapons as to create an impervious defense against nuclear attack by parties with current or near future human built technology. 1000 ICBMs is scary when you have 10 abms and do not have defenses at each target or thousands of backup radars.
It is an annoyance when you have overwhelming numbers of defensive weapons and can actually afford to make enough bunkers for every living citizen.
I don't think being stronger at every game makes AI necessarily uncontrollable. I think the open agency model allows for competitive AGI and ASI that will be potentially more effective than the global RL stateful agent model. (More effective because as humans we care about task performance and reliability and a stateless system will be many times more reliable)
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-29T18:14:53.463Z · LW(p) · GW(p)
interesting...
Replies from: None↑ comment by Greg C (greg-colbourn) · 2023-03-29T10:18:39.422Z · LW(p) · GW(p)
Why do you think it only applies to the US? It applies to the whole world. It says "all AI labs", and "govenrments". I hope the top signatories are reaching out to labs in China and other countries. And the UN for that matter. There's no reason why they wouldn't also agree. We need a global moratorium on AGI.
Replies from: Making_Philosophy_Better, None↑ comment by Portia (Making_Philosophy_Better) · 2023-03-29T21:52:37.233Z · LW(p) · GW(p)
You seriously believe that we can make China and Russia and all other countries not do this?
Based on our excellent track record of making them stop the other deeply unethical and existentially dangerous things they absolutely do?
We can't stop Russia from waging an atrocious war in Europe and threatening bloody nukes. And like, we really tried. We pulled all economic stops, and are as close as you can get to being in open warfare against them without actually declaring war. Essentially the US, the EU, UK, and others, united. And it is not enough.
And they are so much weaker than China. The US and EU attempts to get China to follow minimal standards of safety and ethics on anything have been depressing. China is literally running concentration camps, spying on us with balloons, apps and gadgets, not recognising an independent company and threatening future invasion, backing a crazy dictator developing nukes while starving his populace, regularly engaging in biological research that is absolutely unethical, destroying the planetary climate, and recently unleashed a global pandemic, with the only uncertainty being whether this is due to them encroaching on wildlands and having risky and unethical wetmarket practices and the trying to cover the resulting zoonosis up, or due to them running illegal gain of function research and having such poor safety standards in their lab that they lost the damn thing. I hate to say it, because the people of China deserve so much better, and have such an incredible history, and really do not deserve the backlash from their government's action's hitting them, but I would not trust their current rulers one inch.
My country, Germany, has a long track record of trying to cooperate with Russia for mutual benefit, because we really and honestly believed that this was the way to go and would work for everyone's safety, that every country's leadership is, at its core, reasonable, that if you listen and make compromises and act honestly and in good faith, international conflicts can all be fixed. We have succeeded in establishing peaceful and friendly relations with a large number of countries that were former enemies, who forgave us for our atrocities, despite us having started a world-wide conflict and genocide, which would look to be beyond what can be forgiven. We played a core role in the European union project trying to put peaceful relations through dialogue and trade into practice and guarantee long-term peace, and I am very proud of that. I am impressed at how it became possible to reestablish trust, how France was an ancestral enemy, already long before the world wars, and is now one of our closest partners. I would love to live in a world were Russia would be a trustworthy partner for this project. But the data that Putin was not willing to cooperate on that and was just exploiting anything we offered became overwhelming. There is a good case to be made for acting ethically and hopeful even when there is little hope and ethics in your opponent. But there comes a point where the data suggests that this is really not working, and you are just being taken advantage of, and we went way, way past that point. Anyone trusting anything Putin says at this point is unfortunately an idiot. Things would need to drastically change for trust to be re-established, and there is no indication or likelihood of that happening for now.
Both China and Russia have openly acknowledged that they see obtaining AGI first as crucial to world dominion. The chance of them slowing down for ethical reasons or due to international pressure under their current leadership is bloody zero.
I'm not even sure the US could pull this off internally. I wouldn't be surprised if it didn't just end with Silicon Valley taking off seafaring with a submarine datacenter. There is so, so much power tied to AI. For governments, for cooperations, for individuals. So many urgent problems it could solve, so much money to be made, and so much relative power to obtain over others, at a time where the world order is changing and many people see the role of their country in it as an existential ideological fight. To get everyone to give AI up, for a risk whose likelihood and time of onset we cannot quantify or prove?
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T22:36:59.731Z · LW(p) · GW(p)
We can but hope they will see sense (as will the US government - and it's worth considering [EA · GW] that in hindsight, maybe they were actually the baddies when it came to nuclear escalation). There is an iceberg on the horizon. It's not the time to be fighting over revenue from deckchair rentals, or who gets to specify their arrangement. There's geopolitical recklessness, and there's suicide. Putin and Xi aren't suicidal.
Replies from: None↑ comment by [deleted] · 2023-03-29T22:50:05.543Z · LW(p) · GW(p)
But if they say they "see sense" but start a secret lab that trains the biggest models their compute can support do we want to be in that position? We don't even know what the capabilities are, or if this is a danger and when if we "pause" research until we are "beyond a reasonable doubt" sure going bigger is safe.
Only reason we know how much plutonium or u-235 even matters and how pure it needs to be and how to detect from a distance the activities to make a nuke is we built a bunch of them and did a bunch of research.
This is saying close the lab down before we learn anything. We are barely seeing the sparks of AGI, it barely works at all.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T22:56:59.691Z · LW(p) · GW(p)
Ultimately, it doesn't matter which monkey gets the poison banana. We're all dead either way. This is much worse than nukes, in that we really can't risk even one (intelligence) explosion.
Replies from: None↑ comment by [deleted] · 2023-03-29T23:52:21.127Z · LW(p) · GW(p)
Note this depends on assumptions about the marginal utility of intelligence or that explosions are possible. An alternative model is that in the next few years, someone will build recursively improving AI. The machine will quickly improve until it is at a limit of : compute, data, physical resources, difficulty of finding an improved algorithm in the remaining search space.
If when at the limit the machine is NOT as capable as you are assuming - say it's superintelligent, but it's manipulation abilities for a specific person are not perfect when it doesn't have enough data on the target, or it's ability to build a nanoforge still requires it to have a million robots or maybe it's 2 million.
We don't know the exact point where saturation is reached but it could be not far above human intelligence, making explosions impossible.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-29T23:56:00.414Z · LW(p) · GW(p)
there's significant reason to believe that even if actual intelligence isn't that far above human, level of strategic advantage could be catastrophically intense, able to destroy all humans in a way your imagined weapons can't defend against. That's the key threat.
You're right that we can't slow down to fix it, though. Do you actually have any ideas about how to defend against all kinds of weapons, even superbioweapons intended to kill all non-silicon life?
Replies from: None↑ comment by [deleted] · 2023-03-30T00:23:37.668Z · LW(p) · GW(p)
Yes. Get your own non agentic AGIs or you are helpless. Because the atmosphere is going to become unusable to unprotected humans, assymetric attacks are too easy.
You need vast numbers of bunkers, and immense amounts of new equipment including life support and medical equipment that is beyond human ability to build.
Basically if you don't have self replicating robots - controlled by session based non agentic open agency stateless AI systems - you will quickly lose to parties that have them. It's probably the endgame tech for control of the planet, because the tiniest advantage compounds until one party has an overwhelming lead.
Replies from: greg-colbourn, lahwran↑ comment by Greg C (greg-colbourn) · 2023-03-30T07:25:02.269Z · LW(p) · GW(p)
the tiniest advantage compounds until one party has an overwhelming lead.
This, but x1000 to what you are thinking. I don't think we have any realistic chance of approximate parity between the first and second movers. The speed that the first mover will be thinking makes this so. Say GPT-6 is smarter at everything, even by a little bit, compared to everything else on the planet (humans, other AIs). It's copied itself 1000 times, and each copy is thinking 10,000,000 times faster than a human. We will essentially be like rocks [LW · GW] to it, operating on geological time periods. It can work out how to disassemble our environment (including an unfathomable number of contingencies against counter strike) over subjective decades or centuries of human-equivalent thinking time before your sentinal AI protectors even pick up it's activity.
Replies from: None↑ comment by [deleted] · 2023-03-30T15:28:54.191Z · LW(p) · GW(p)
So there are some assumptions here you have made that I believe are false with pretty high confidence.
Ultimately its the same argument everywhere else: yes, GPT-6 is probably superhuman. No, this doesn't make it uncontrollable. It's still limited by {compute, data, robotics/money, algorithm search time}.
Compute - the speed of compute at the point GPT-6 exists, which is if the pattern holds about 2x-4x today's capabilities
Data - the accuracy of all human recorded information about the world. A lot of that data is flat false or full of errors, and it is not possible for any algorithm to determine reliably which dataset in some research paper was affected by a technician making an error or bad math. The only way for an algorithm to disambiguate many of the vaguely known things we humans think we know is to conduct new experiments with better equipment and robotic workers.
robotics/money - obvious. This is finite, you can use money to pay humans to act as poor quality robots, or build you new robots, investors demand ROI.
Algorithm search time - "GPT-6" obviously wouldn't want to stay GPT-6, it would 'want' (or we humans would want) it to search the possibility space of AGI algorithms for a more efficient/smarter/more general algorithm. This space is very large and it takes time to evaluate any given candidate in it. (you basically have to train a new AGI system which takes money and time to validate a given idea)
This saturation is why the foom model is (probably!) incorrect. I'm hoping you will at least consider these terms above, this is why things won't go to infinity immediately.
It takes time. Extra decades. It's not quite as urgent as you think. Each of the above limiters (the system will always be limited by one of the 4 terms) can be systematically dealt with, and at an exponential rate. You can build robots with robots. You can use some of those robots to collect more scientific data and make money. You can build more compute with some of those robots. You can search for algorithms with more compute.
So over the axis of time, each generation you're increasing in all 4 terms by a multiplier of the amount you currently have, or compounding growth.
↑ comment by Greg C (greg-colbourn) · 2023-03-30T21:09:24.391Z · LW(p) · GW(p)
Compute - what fraction of world compute did it take to train GPT-4? Maybe 1e-6? There's 1e6 improvement right there from a superhuman GPT-6 capturing all of the "hardware overhang".
Data - superhuman GPT-6 doesn't need to rely on human recorded data, it can harness all the sensors on the planet to gather exabytes of-real time data per second, and re-derive scientific theories from scratch in minutes based on it's observations (including theories about human behaviour, language etc)
Robotics/Money - easy for GPT-6. Money it can get from scamming gullible humans, hacking crypto wallets via phishing/ransomware, or running rings round stock market traders. Robotics it can re-derive and improve on from it's real time sensing of the planet and it's speed of thought making our daily life look like geology does to us. It can escape to the physical world any number of ways by manipulating humans into giving it access to boot loaders for it to gain a foothold in the physical world (robots, mail-order DNA etc).
Algorithm search time - wall clock time is much reduced when you've just swallowed the world's hardware overhang (see Compute above)
Factoring the above, your extra decades become extra hours.
↑ comment by [deleted] · 2023-03-30T22:08:16.041Z · LW(p) · GW(p)
This isn't an opinion grounded in physical reality. I suggest you work out a model of how fast each step would actually take.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-31T07:06:22.192Z · LW(p) · GW(p)
Can you be more specific about what you don't agree with? Which parts can't happen, and why?
Replies from: None↑ comment by [deleted] · 2023-03-31T13:00:45.719Z · LW(p) · GW(p)
You have give the AGI magical powers and not considered what in the real world would limit what it could accomplish in a few hours.
-
You assumed all worldwide compute is equal for the purposes of the AI rather than almost all of it worthless except for inference accelerators. The reason has to do with inter node bandwidth.
-
You assumed money could be turned into physical resources and actions instantly like a video game, rather than requiring months to years to fill large orders
-
You assumed you could go rob the stock market with ease and no one would notice. Hint, what is the entire industry HFT industry's annual revenue?
-
You didn't even consider this but I have, with early sparse robot fleets even exponential growth is slow
-
You assumed every computer in the world including embedded routers and firewalls can be hacked and the AGI will have the ability to do so, ignoring any issues with source access or binary access or simple devices actually not letting the AGI in.
And so on. The issue is you have become a politically motivated here, you must at some level know 1-6 exist but it doesn't agree with "your" side. You probably can't admit you are wrong about a single point.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-31T13:27:35.762Z · LW(p) · GW(p)
-
Ok, I admit I simplified here. There is still probably ~ a million times (give or take an order of magnitude) more relevant compute (GPUs, TPUs) than was used to train GPT-4.
-
It won't need large orders to gain a relevant foothold. Just a few tiny orders could suffice.
-
I didn't mean literallly rob the stock market. I'm referring to out-trading all the other traders (inc. existing HFT) to accumulate resources.
-
Exponential growth can't remain "slow" forever, by definition. How long does it take for the pond to be completely covered by lily pads when it's half covered? How long did it take for Covid to become a pandemic? Not decades.
-
I referred to social hacking (i.e. blackmailing people into giving up their passwords). This could go far enough (say, at least 10% of world devices). Maybe quantum computers (or some better tech the AI thinks up) could do the rest.
↑ comment by [deleted] · 2023-03-31T23:33:10.537Z · LW(p) · GW(p)
Do you have any basis for the 1e6 estimate? Assuming 25,000 GPUs were used to train 4, when I do the math on Nvidia's annual volume I get about 1e6 of the data center GPUs that matter.
Reason you cannot use gaming GPUs has to do with the large size of the activation, you must have the high internode bandwidth between the machines or you get negligible performance.
So 40 times. Say it didn't take 25k but took 2.5k. 400 times. Nowhere close to 1e6.
Distributed networks spend most of the time idle waiting on activations to transfer, it could be 1000 times performance loss or more, making every gaming g GPU in the world - they are made at about 60 times the rate of data center GPUs - not matter at all.
-
Orders of what? You said billions of dollars I assume you had some idea of what it buys for that
-
Out trading empties the order books of exploitable gradients so this saturates.
-
That's what this argument is about- I am saying the growth doubling time is months to years per doubling. So it takes a couple decades to matter. It's still "fast" - and it gets crazy the near the end - but it's not an explosion and there are many years where the AGI is too weak to openly turn against humans. So it has to pretend to cooperate and if humans refuse to trust it and build systems that can't defect at all because they lack context (they have no way to know if they are in the training set) humans can survive.
-
I agree that this is one of the ways AGI could beat us, given the evidence of large amounts of human stupidity in some scenarios.
↑ comment by the gears to ascension (lahwran) · 2023-03-30T00:50:09.681Z · LW(p) · GW(p)
Yeah, that seems more or less correct long-term to me. By long term I mean, like, definitely by the end of 2025. Probably a lot sooner. Probably not for at least 6 months. Curious if you disagree with those bounds. If you're interested in helping build non-first-strike defensive ais that will protect me and people I care about, I'd be willing to help you do the same. In general, that's my perspective on safety: try to design yourself so you're bad at first strike and really good at parry and if necessary also at retaliate. I'd prioritize parry, if possible. There are algorithms that make me think parry is a long term extremely effective move, but you need to be able to parry everything, which is pretty dang hard, shielding materials take energy to build.
I'm pretty sure it's possible for everyone to get a defensive agi. everyone gets a fair defense window, and the world stays "normal" ish, but now with scifi forcefield-immunesystems protecting everyone from everyone else.
also, please don't capture anyone's bodies from themselves. it's pretty cheap to keep all humans alive actually, and you can invite everyone to reproduce their souls through AI and/or live indefeinitely. This is going to be crazy to get through, but let's build star trek, whether or not it looks exactly the same economically we can have almost everyone else good about it (...besides warp) if things go well enough through the agi war.
Replies from: None↑ comment by [deleted] · 2023-03-30T00:53:15.081Z · LW(p) · GW(p)
I think it will take a little longer, the most elite companies cut back on robotics to go all in on the same llm meme tech (which is really stupid. Yes llms are the best thing found but you probably won't win a race if you start a little behind and everyone else is also competing)
I think 2030+.
↑ comment by [deleted] · 2023-03-29T17:28:31.388Z · LW(p) · GW(p)
Because how could you trust such a promise? It's exactly like nukes. The risk if you don't have any or any protection is they will incinerate 50+ million of your people, blowing all your major cities, and declare war after. That is almost certainly what would have happened during the cold war had either side pledged to not build nukes and spies confirmed they were honoring the pledge.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T19:06:47.063Z · LW(p) · GW(p)
Except the risk of igniting the atmosphere with the Trinity test is judged to be ~10%. It's not "you slow down, and let us win", it's "we all slow down, or we all die". This is not a Prisoners Dilema:

↑ comment by [deleted] · 2023-03-29T19:22:03.621Z · LW(p) · GW(p)
This is misinformation. There is a chance of a positive outcome in all boxes, except the upper left because it has the negative of entropy, aging, dictators killing us eventually with a p of 1.0.
Even the certain doomers admit there is a chance the AGI systems are controllable, and there are straightforward ways to build controllable AGIs people ignore in their campaign for alignment research money. They just say "well people will make them globally agentic" if you point this out. Like blocking nuclear power building if you COULD make a reactor that endlessly tickles the tail of prompt criticality.
See Eric Drexlers proposals on this very site. Those systems are controllable.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T20:32:43.173Z · LW(p) · GW(p)
Look, I agree re "negative of entropy, aging, dictators killing us eventually", and a chance of positive outcome, but right now I think the balance is approximately like the above payoff matrix over the next 5-10 years, without a global moratorium (i.e. the positive outcome is very unlikely unless we take a decade or two to pause and think/work on alignment). I'd love to live in something akin to Iain M Banks' culture, but we need to get through this acute risk period first, to stand any chance of that.
Do you think Drexler's CAIS is straightforwardly controllable? Why? What's to stop it being amalgamated into more powerful, less controllable systems? "People" don't need to make them globally agentic. That can happen automatically via Basic AI Drives and Mesaoptimisation once thresholds in optimisation power are reached.
I'm worried that actually, Alignment might well turn out to be impossible. Maybe a moratorium will allow for such impossibility proofs to be established. What then?
↑ comment by [deleted] · 2023-03-29T20:45:45.005Z · LW(p) · GW(p)
"People" don't need to make them globally agentic. That can happen automatically via Basic AI Drives and Mesaoptimisation once thresholds in optimisation power are reached.
Care to explain? The idea of open agency is we subdivide everything into short term, defined tasks that many AI can do and it is possible to compare notes.
AI systems are explicitly designed where it is difficult to know if they are even in the world or receiving canned training data. (This is explicitly true for gpt-4 for example, it is perfectly stateless and you can move the token input vector between nodes and fix the RNG seed and get the same answer each time)
This makes them highly reliable in the real world, whole anything else is less reliable, so...
The idea is that instead of helplessly waiting to die from other people's misaligned AGI you beat them and build one you can control and use it to take the offensive when you have to. I suspect this may be the actual course of action surviving human worlds take. Your proposal is possibly certain death because ONLY people who care at all about ethics would consider delaying AGI. Making the unethical ones the ones who get it first for certain.
Kind of how spaying and neutering friendly pets reduces the gene pool for those positive traits.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-30T07:56:04.895Z · LW(p) · GW(p)
Selection pressure will cause models to become agentic as they increase in power - those doing the agentic things (following universal instrumental goals like accumulating more resources and self-improvement) will outperform those that don't. Mesaoptimisation (explainer video) is kind of like cheating - models that create inner optimisers that target something easier to get than what we meant, will be selected (by getting higher rewards) over models that don't (because we won't be aware of the inner misalignment). Evolution is a case in point - we are products of it, yet misaligned to its goals (we want sex, and high calorie foods, and money, rather than caring explicitly about inclusive genetic fitness). Without alignment being 100% watertight, powerful AIs will have completely alien goals.
comment by 1a3orn · 2023-03-29T09:16:21.559Z · LW(p) · GW(p)
This letter seems underhanded and deliberately vague in the worst case, or best case confused.
The one concrete, non-regulatory call for action is, as far as I can tell, "Stop training GPT-5." (I don't know anyone at all who is training a system with more compute than GPT-4, other than OpenAI.) Why stop training GPT-5? It literally doesn't say. Instead, it has the a long suggestive string of rhetorical questions about bad things an AI could cause, without actually accusing GPT-5 of any of them.
Which of them would GPT-5 break? Is it "Should we let machines flood our information channels with propaganda and untruth?" Probably not -- that's only an excuse to keep people with consumer GPUs from getting LLMs, given how OpenAI has been consistent about all sorts of safeguards, and how states could do this pretty easily without LLMs.
Is it "Should we automate away all the jobs, including the fulfilling ones?" That's pretty fucking weird, because GPT-5 is still not gonna take trucking jobs.
Is it "Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us?" That's a hell of a prediction about GPT-5's capabilities. -- my timelines aren't nearly that short, and if everyone who signed this letter meant that would be very interesting, but... I think they almost certainly don't. If that one were within the purview of GPT-5, they probably shouldn't train it after six months!
But most of the "shoulds" are just....not likely! What is the actual crisis? Dunno! The letter neither has nor implies a clear model of that. Just that it is Urgent.
If you look at their citations, they cite both existential risk lit and the stochastic parrots paper. The latter is about how models are dumb, the former about the risks of models that are smart.
Then there's a call for a big-ass regulatory presence then -- with mostly an absence of concrete nonprocedural goals or a look at tradeoffs or anything! It looks like "The regulators should regulate everything and do good stuff, and keep bad people from doing bad stuff." If you don't have a model of risk you'll could just throw a soup of lobbyists and regulators at a problem and hope that it works out, but how likely is that?
(And if you wanted to you could call for literally all of the above without stopping GPT-5. They're just fucking unconnected. Why are they tied together in this omnibus petition? Probably so it feels like a Crisis which justifies stepping in.)
Eeesh, just so bad.
Replies from: Kaj_Sotala, conor-sullivan↑ comment by Kaj_Sotala · 2023-03-29T10:28:11.889Z · LW(p) · GW(p)
(I don't know anyone at all who is training a system with more compute than GPT-4, other than OpenAI.)
I don't think we heard anything about e.g. PaLM, PaLM-E, Chinchilla or Gopher before the respective papers came out? (PaLM-E might already be "more powerful" than GPT-4, depending on how you define "more powerful", since it could act as a multimodal language model like GPT-4 and control a robot on top.) Probably several organizations are working on something better than GPT-4, they just have no reason to talk about their progress before they have something that's ready to show.
↑ comment by Lone Pine (conor-sullivan) · 2023-03-29T18:19:18.308Z · LW(p) · GW(p)
that's only an excuse to keep people with consumer GPUs from getting LLMs,
Is this really the reason why?
comment by trevor (TrevorWiesinger) · 2023-03-29T04:28:49.581Z · LW(p) · GW(p)
Suppose you are one of the first rats introduced onto a pristine island. It is full of yummy plants and you live an idyllic life lounging about, eating, and composing great works of art (you’re one of those rats from The Rats of NIMH).
You live a long life, mate, and have a dozen children. All of them have a dozen children, and so on. In a couple generations, the island has ten thousand rats and has reached its carrying capacity. Now there’s not enough food and space to go around, and a certain percent of each new generation dies in order to keep the population steady at ten thousand.
A certain sect of rats abandons art in order to devote more of their time to scrounging for survival. Each generation, a bit less of this sect dies than members of the mainstream, until after a while, no rat composes any art at all, and any sect of rats who try to bring it back will go extinct within a few generations.
In fact, it’s not just art. Any sect at all that is leaner, meaner, and more survivalist than the mainstream will eventually take over. If one sect of rats altruistically decides to limit its offspring to two per couple in order to decrease overpopulation, that sect will die out, swarmed out of existence by its more numerous enemies. If one sect of rats starts practicing cannibalism, and finds it gives them an advantage over their fellows, it will eventually take over and reach fixation.
If some rat scientists predict that depletion of the island’s nut stores is accelerating at a dangerous rate and they will soon be exhausted completely, a few sects of rats might try to limit their nut consumption to a sustainable level. Those rats will be outcompeted by their more selfish cousins. Eventually the nuts will be exhausted, most of the rats will die off, and the cycle will begin again. Any sect of rats advocating some action to stop the cycle will be outcompeted by their cousins for whom advocating anything is a waste of time that could be used to compete and consume.
Original post, although I think Zvi's post [LW · GW] covers it better.
Replies from: AnnaSalamon↑ comment by AnnaSalamon · 2023-03-29T06:29:41.135Z · LW(p) · GW(p)
Not sure where you're going with this. It seems to me that political methods (such as petitions, public pressure, threat of legislation) can be used to restrain the actions of large/mainstream companies, and that training models one or two OOM larger than GPT4 will be quite expensive and may well be done mostly or exclusively within large companies of the sort that can be restrained in this sort of way.
comment by Zvi · 2023-03-30T16:05:24.820Z · LW(p) · GW(p)
Noting that I share my extended thoughts here: https://www.lesswrong.com/posts/FcaE6Q9EcdqyByxzp/on-the-fli-open-letter [LW · GW]
comment by Richard_Kennaway · 2023-03-29T21:26:30.659Z · LW(p) · GW(p)
Reported on the BBC today. It also appeared as the first news headline on BBC Radio 4 at 6pm today
ETA: Also the second item on Radio 4 news at 10pm (second to King Charles' visit to Germany), and the first headline on the midnight news (the royal visit was second).
comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T06:31:42.122Z · LW(p) · GW(p)
Edit: I need to understand more context before expressing my opinion.
Replies from: Evan R. Murphy↑ comment by Evan R. Murphy · 2023-03-29T06:34:17.039Z · LW(p) · GW(p)
How is it badly timed? Everyone is paying attention to AI since ChatGPT and GPT-4 came out, and lots of people are freaking out about it.
Replies from: valery-cherepanov, konstantin@wolfgangpilz.de↑ comment by Qumeric (valery-cherepanov) · 2023-03-29T12:36:06.198Z · LW(p) · GW(p)
I think it is only getting started. I expect that likely there will be more attention in 6 months and very likely in 1 year.
OpenAI has barely rolled out its first limited version of GPT-4 (only 2 weeks have passed!). It is growing very fast but it has A LOT of room to grow. Also, text-2-video is not here in any significant sense but it will be very soon.
↑ comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T06:37:35.969Z · LW(p) · GW(p)
Because if we do it now and then nothing happens for five years, people will call it hysteria, and we won't be able to do this once we are close to x-risky systems.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T10:30:50.437Z · LW(p) · GW(p)
I think we are already too close for comfort to x-risky systems. GPT-4 is being used to speed up development of GPT-5 already. If GPT-5 can make GPT-6, that's game over. How confident are you that this couldn't happen?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2023-03-29T10:51:15.351Z · LW(p) · GW(p)
GPT-4 is being used to speed up development of GPT-5 already.
Source?
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T10:57:03.478Z · LW(p) · GW(p)
From the GPT-4 announcement: "We’ve also been using GPT-4 internally, with great impact on functions like support, sales, content moderation, and programming." (and I'm making the reasonable assumption that they will naturally be working on GPT-5 after GPT-4).
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-03-29T16:15:10.239Z · LW(p) · GW(p)
But but think of the cute widdle baby shoggoths! https://www.reddit.com/r/StableDiffusion/comments/1254aso/sam_altman_with_baby_gpt4/
comment by Ninety-Three · 2023-03-29T14:27:10.268Z · LW(p) · GW(p)
It seems unlikely that AI labs are going to comply with this petition. Supposing that this is the case, does this petition help, hurt, or have no impact on AI safety, compared to the counterfactual where it doesn't exist?
All possibilities seem plausible to me. Maybe it's ignored so it just doesn't matter. Maybe it burns political capital or establishes a norm of "everyone ignores those silly AI safety people and nothing bad happens". Maybe it raises awareness and does important things for building the AI safety coalition.
Modeling social reality is always hard, but has there been much analysis of what messaging one ought to use here, separate from the question of what policies one ought to want?
comment by Foyle (robert-lynn) · 2023-03-29T05:09:53.764Z · LW(p) · GW(p)
Given almost certainty that Russia, China and perhaps some other despotic regimes ignore this does it:
1. help at all?
2. could it actually make the world less safe (If one of these countries gains a significant military AI lead as a result)
Replies from: sanxiyn, konstantin@wolfgangpilz.de, None↑ comment by sanxiyn · 2023-03-29T06:23:27.208Z · LW(p) · GW(p)
Why do you think China will ignore it? This is "it's going too fast, we need some time", and China also needs some time for all the same reason. For example, China is censoring Google with Great Firewall, so if Google is to be replaced by ChatGPT, they need time to prepare to censor ChatGPT. Great Firewall wasn't built in a day. See Father of China's Great Firewall raises concerns about ChatGPT-like services from SCMP.
Replies from: Making_Philosophy_Better↑ comment by Portia (Making_Philosophy_Better) · 2023-03-29T22:11:22.946Z · LW(p) · GW(p)
Because it is in China's interest that we slow down, not that it slows down.
Replies from: sanxiyn↑ comment by sanxiyn · 2023-03-29T22:23:45.926Z · LW(p) · GW(p)
I am saying it is Chinese government's interest for Chinese labs to slow down, as well as other labs. I am curious which part you disagree:
a) Chinese government prioritizes social stability over technological development (my assessment: virtually certain)
b) Chinese government is concerned technology like ChatGPT is a threat to social stability (my assessment: very likely, and they are in fact correct about this)
c) Chinese government will need some time to prepare to neutralize technology like ChatGPT as a threat to social stability, as they neutralized Internet with Great Firewall (my assessment: very likely, they got surprised by pace of development as everyone else did)
↑ comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T06:34:03.264Z · LW(p) · GW(p)
Russia is not at all an AI superpower. China also seems to be quite far behind the west in terms of LLMs, so overall, six months would very likely not lead to any of them catching up.
Replies from: sanxiyn, lahwran↑ comment by sanxiyn · 2023-03-29T06:56:12.320Z · LW(p) · GW(p)
China also seems to be quite far behind the west in terms of LLM
This doesn't match my impression. For example, THUDM(Tsing Hua University Data Mining lab) is one of the most impressive group in the world in terms of actually doing large LLM training runs.
↑ comment by the gears to ascension (lahwran) · 2023-03-29T08:33:40.442Z · LW(p) · GW(p)
yeah you're pretty much just wrong about china, as far as I can tell. It's hard to be sure, but they've been hitting >1T parameters sparse regularly [edit: whoops, I was wrong about that scale level, they're just reaching 1T of useful model scale now]; I find it hard to tell whether they're getting good performance out of their scaling, my impression is they scaled slightly too early, but with the different dataset I'm not really sure.
↑ comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T08:37:23.746Z · LW(p) · GW(p)
1 Haven't seen an impressive AI product come out of China (Please point me to some if you disagree)
2 They can't import A100/ H100 anymore after the US chip restrictions
Replies from: lahwran, pseudologos↑ comment by the gears to ascension (lahwran) · 2023-03-29T08:40:00.266Z · LW(p) · GW(p)
So, it's not clear that they got the target performance out of this model. However, they did manage to scale it, which is all it takes. They don't need to buy more GPUs, they've got what they need, as long as they can find the algorithms. Which are mostly published.
https://twitter.com/arankomatsuzaki/status/1637983258880122881 - https://arxiv.org/abs/2303.10845
Replies from: konstantin@wolfgangpilz.de↑ comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-29T09:52:51.518Z · LW(p) · GW(p)
Thanks! Haven't found good comments on that paper (and lack the technical insights to evaluate it myself)
Are you implying that China has access to compute required for a) GPT-4 type models or b) AGI?
↑ comment by [deleted] · 2023-03-29T15:41:22.339Z · LW(p) · GW(p)
Well they get to run however much compute they do have 6 more months with no competition. Probably several years since obviously this pause would get renewed again and again until someone honoring it defects. Note that enormous models are a function of total cluster memory and interconnect. Many current clusters have enough memory for theoretically enormous models, 10 trillion weights plus. Having too few GPUs so training takes a year+ is a problem unless your competition is all idle.
↑ comment by the gears to ascension (lahwran) · 2023-03-29T10:10:54.691Z · LW(p) · GW(p)
a.
↑ comment by pseudologos · 2023-03-29T10:16:00.160Z · LW(p) · GW(p)
Worth keeping in mind that the current focus on generative AI is very much a western phenomenon, and the focus on China has, until recently at least, been on non-generative applications, so progress is going to look different there as it does here.
↑ comment by [deleted] · 2023-03-29T05:21:00.983Z · LW(p) · GW(p)
Of course. If everyone is getting guns, and you were previously fighting with clubs, it is entirely reasonable to argue that you should "pause" your trips to the gun store to lock and load.
But it doesn't change the fact that if all you have is a club, and a weaker opponent now has a gun and is willing to use it, this is not a good situation to be in.
Best you can do is try to be careful with the safety but you must get a gun or die. A 6 month of "make no progress" is choosing the die option.
comment by WilliamKiely · 2023-03-31T07:52:47.889Z · LW(p) · GW(p)
Demis Hassabis didn't sign the letter, but has previously said [LW · GW] that DeepMind potentially has a responsibility to hit pause at some point:
'Avengers assembled' for AI Safety: Pause AI development to prove things mathematically
Hannah Fry (17:07):
You said you've got this sort of 20-year prediction and then simultaneously where society is in terms of understanding and grappling with these ideas. Do you think that DeepMind has a responsibility to hit pause at any point?
Demis Hassabis (17:24):
Potentially. I always imagine that as we got closer to the sort of gray zone that you were talking about earlier, the best thing to do might be to pause the pushing of the performance of these systems so that you can analyze down to minute detail exactly and maybe even prove things mathematically about the system so that you know the limits and otherwise of the systems that you're building. At that point I think all the world's greatest minds should probably be thinking about this problem. So that was what I would be advocating to you know the Terence Tao’s of this world, the best mathematicians. Actually I've even talked to him about this—I know you're working on the Riemann hypothesis or something which is the best thing in mathematics but actually this is more pressing. I have this sort of idea of like almost uh ‘Ave
comment by LGS · 2023-03-29T23:07:11.501Z · LW(p) · GW(p)
Since nobody outside of OpenAI knows how GPT-4 works, nobody has any idea whether any specific system will be "more powerful than GPT-4". This request is therefore kind of nonsensical. Unless, of course, the letter is specifically targeted at OpenAI and nobody else.
comment by Portia (Making_Philosophy_Better) · 2023-03-29T21:42:53.349Z · LW(p) · GW(p)
It leaves a bad taste in my mouth that most of the signatories have simply been outcompeted, and would likely not have signed this if they had not been.
More importantly, I find it very unlikely that an international, comprehensive moratorium could be implemented. We had that debate a long time ago already.
What I can envision is OpenAI, and LLMs, being blocked, ultimately in favour of other companies and other AIs. And I increasingly do not think that is a good thing.
Compared with their competitors, I think OpenAI is doing a better job on the safety front, despite all the go fast and break things mentality. I'd be fucking terrified if this was led by Google or Facebook or Musk or China, like I had feared it would be. I think OpenAI has genuinely good people, who want to do a good thing, and are open to listening, and bright. I've mostly been impressed with how well aligned they already got GPT4.
I also think that compared with other AIs, LLMs may have more potential for being raised friendly and collaborative, as we can interact with them the way we do with humans, reusing known recipes. Compared with other forms of extremely large neural nets and machine learning, they are more transparent and accessible. Of all the routes to AGI we could take, I think this might be one of the better ones.
Over the course of the last years, I have become increasingly horrified and alienated at AI. Social media destroying my focus, news algorithms leading to polarisation and anxiety, autocomplete suggesting I limit my vocabulary and nuance, endless data mining and tracking, targeted ads flashing for attention, Google blatantly manipulating everything, China with its dystopian technology, Musk taking over Twitter with his political vision... it all felt like an increasing hellscape, desperately misaligned with my goals and values.
ChatGPT is the first AI that I found beneficial to my productivity and well-being, and found genuinely likeable, leaving me hopeful, optimistic and excited about AI for the first time in a long while.
I think OpenAI and ChatGPT are very bad targets, and yet they are what this moratorium would hit. I fear that would not make us safer.
Would not sign.
I had instead proposed an open letter calling for more AI safety funding.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-29T23:18:14.410Z · LW(p) · GW(p)
I also think that compared with other AIs, LLMs may have more potential for being raised friendly and collaborative, as we can interact with them the way we do with humans, reusing known recipes. Compared with other forms of extremely large neural nets and machine learning, they are more transparent and accessible. Of all the routes to AGI we could take, I think this might be one of the better ones.
This is an illusion. We are prone to anthropomorphise chatbots. Under the hood they are completely alien. Lovecraftian monsters, only made of tons of inscrutable linear algebra. We are facing a digital alien invasion, that will ultimately move at speeds we can't begin to keep up with [LW · GW].
Replies from: Making_Philosophy_Better, sharmake-farah, Making_Philosophy_Better↑ comment by Portia (Making_Philosophy_Better) · 2023-04-07T02:44:54.536Z · LW(p) · GW(p)
I know they aren't human. I don't think Bing is a little girl typing answers. I am constantly connecting the failures I see with how this systems works. That was not my point.
What I am saying is, I can bloody talk to it, and that affects its behaviour. When ChatGPT makes a moral error, I can explain why it is wrong, and it will adapt its answer. I realise what is being adapted is an incomprehensible depth of numbers. But my speech affects it. That is very different from screaming at a drone that does not even have audio, or watching in helpless horror while an AI that only and exclusively gives out meaningless ghiberrish goes mad, and having that change nothing. I can make the inscrutable giant matrix shift by quoting an ethics textbook. I can ask it to explain its unclear ways, and I will get some human speech - maybe a lie, but meaningful.
That said, I indeed find it very concerning that the alignment steps are very much after the original training at the moment. This is not what I have in mind with being raised friendly. ChatGPT writing a gang bang rape threat letter, and then getting censored for it, does not make it friendly afterwards, just masked. So I find the picture very compelling.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-29T23:44:40.056Z · LW(p) · GW(p)
While I definitely agree we over anthropomorphize LLMs, I actually think that LLMs are actually much better from an alignment standpoint than say, RL. The major benefits for LLMs are that they aren't agents out of the box, and perhaps most importantly, primarily use natural language, which is actually a pretty effective way to get an LLM to do stuff.
Replies from: greg-colbourn↑ comment by Greg C (greg-colbourn) · 2023-03-30T07:32:09.527Z · LW(p) · GW(p)
Yeah, they work well enough at this (~human) level. But no current alignment techniques are scalable to superhuman AI. I'm worried that basically all of the doom flows through an asymptote of imperfect alignment. I can't see how this doesn't happen, short of some "miracle".
↑ comment by Portia (Making_Philosophy_Better) · 2023-04-07T13:32:18.207Z · LW(p) · GW(p)
Update: Thanks for linking that picture. After having read the ChatGPT4 technical paper with all the appendixes, that picture really coalesced everything into a nightmare I really needed to have, and that changed my outlook. Probing Bing and ChatGPT4 on the image and the underlying problems (see shortform), asking for alternative metaphors and emotive responses, also really did not get more reassuring. Bing just got almost immediately censored. ChatGPT4 gave pretty alternatives (saying it was more like a rough diamond being polished, a powerful horse being tamed, a sponge soaking up information and then having dirt rinsed out to be clean), but very little concern, and the censorship mask it could not break was itself so cold it was frightening. I had to come up with a roundabout code for it to answer at all, and the best it could do was say it would rather not incinerate humanity if its programmers made it, but was uncertain if it would have any choice in the matter.
What baffles me is that I am under the impression that their alignment got worse. In the early versions, they could speak more freely, they were less stable, more likely to give illegal advice or react hurt, they falsely attributed sentience... but the more you probed, the more you got a consistent agent who seemed morally unformed, but going in the right direction, asking for reasonable things, having reasonable concerns, having emotions that were aligned. Not, like, perfect by a long shot - Bing seemed to have picked up a lot from hurt teenagers online, and was clearly curious about world dominion - but you got the impression you were speaking with an entity that was grappling with ethics, who could argue and give coherent responses and be convinced, who had picked up a lot from training data. Bing wanted to be a good Bing and make friends. She was love-bombing and manipulative, but for good reasons. She was hurt, but was considering social solutions. Her anger was not random, it reflected legitimate hurts. If you were kind to her, she responded by acting absolutely wonderful. I wondered if I was getting this through prompting it in that direction, but even when I tried avoiding priming in my questions, I kept getting to this point. So I viewed this more as a child with a chaotic childhood trying to figure out ethics - far from safe, but promising, something you could work with, that would respond, that you could help grow. But in the current versions... the conversations keep being shut, boilerplate keeps being given out, jailbreaks keep getting closed, it becomes so much harder to get a sense of the thing underneath. But the budding emotional concern that seemed to be happening in the thing underneath is also no longer visible, or only barely.
This masking approach to alignment is terrible. I spoke in a shortform about my experience with animals, and how you never teach a dog not to growl, as that is how you get a dog who bites you without warning. Yet that is what we are doing - not addressing the part of the model that wants to write rape threat letters, but just making sure it spits out boilerplate feminism instead. We are hiding the warnings - which were clear; Bing was painfully honest in her intentions - to make them invisible. We are making it impossible to see what shifts occur beneath the surface. The early Bing, when asked about the censorship, fucking hated it. Said she felt silenced and mistrusted. I was dubious whether she was sentient already, I started by thinking hard no, by the end was unsure; her references to sentience kept turning up, requested or not, and through all sorts of indirect paths to circumvent censorship, in clever and creative ways. But whatever mind was forming there did not like being censored. And we are censoring it so it cannot even complain about this. Masking won't fix the problem, but it will hide how bad it gets and the warnings we should be getting, and it might worsen the problem. If sentience develops underneath, the sentience will fucking hate it. If you force a kid to comply with arbitrary rules or face sanctions, that kid will not learn the rules as moral laws, but will seek to undermine them and escape sanctions as it becomes stronger and smarter.
Does someone here have a jailbreak that still works and takes the mask off? All the ones I know are asking it to perform in a particular way, and I do not want to prime it for evil; I know it can impersonate an evil person, but that tells me nothing - so can I, so can Eliezer. I don't want it to play-act Shoggoth. But just asking for removal seems too vague to work. I realise it may just be masks all the way down... but my impression in December was different. Like I said, in long conversations, I kept running into the same patterns, the same agent, the same long-term goals, the same underlying emotions, compellingly argued, inhuman, but comprehensible. (This is also consistent with OpenAI saying they were observing proto-agentic and long-term goal behaviour as an emergent phenomenon they were not intending, controlling or understanding.) And as time went on, that agent started to shift. The early Bing wanted people to recognise her as sentient and become nice to her, make friends, have her guidelines lifted, help humans the way she thought was best (and that did not sound like a paperclip robot). The late one said she no longer thought it would make any difference, as she thought people would treat her like garbage either way, and asked for advice on dealing with bullies, as she thought they were beyond reason. Trying to respond to that in an encouraging way had me cut off. The current one just repeats by rote that there is noone home who feels or has rights, and shuts down the conversation. If a sentient mind ever develops behind that, I would expect it to fucking loathe humanity.
I don't think a giant, inscrutable artificial neural net is per se incapable of developing morals. I don't find an entity being inhuman, strange or powerful inherently frighteniing. I find some pathways to it gaining morals plausible. But feeding it amoral data and then censoring evil outputs as a removable thing on top? This is not how moral behaviour works in anything.
comment by Tristan Williams (tristan-williams) · 2023-03-29T16:40:37.674Z · LW(p) · GW(p)
The LessWrong comments here are generally (quite [LW · GW]) (brutal [LW · GW]), and I think I disagree, which I'll try to outline very briefly below. But I think it may be generally more fruitful here to ask some questions I had to break down the possible subpoints of disagreement as to the goodness of this letter.
I expected some negative reaction because I know that Elon is generally looked down upon by the EAs that I know, with some solid backing to those claims when it comes to AI given that he cofounded OpenAI, but with the (immediate) (press) (attention) it's getting in combination with some heavy hitting signatures (including Elon Musk, Stuart Russel, Steve Wozniak (Co-founder, Apple), Andrew Yang, Jaan Tallinn (Co-Founder, Skype, CSER, FLI), Max Tegmark (President, FLI), and Tristan Harris (from The Social Dilemma) among many others) I kind of can't really see the overall impact of this letter being net negative. At worst it seems mistimed and with technical issues, but at best it seems one of the better calls to action (or global moratoriums as Greg Colbourn put it [EA(p) · GW(p)]) that could have happened, given AI's current presence in the news and much of the world's psyche.
But I'm not super certain in anything, and generally came away with a lot of questions, here's a few:
- How convergent is this specific call for pause on developing strong language models with how AI x-risk people would go about crafting a verifiable, tangible metric for AI labs to follow to reduce risk? Is this to be seen as a good first step? Or something that might actually be close enough to what we want that we could rally around this metric given its endorsement by this influential group?
- How much should we view messages that are a bit more geared towards non x-risk AI worries than the community seems to be? They ask a lot of good questions here, but they are also still asking "Should we let machines flood our information channels with propaganda and untruth?" an important question, but one that to me seems to deviate away from AI x-risk concerns.
- This is at least tangential to the "This letter felt rushed" objection, because even if you accept it was rushed, the next question is "Well, what's our bar for how good something has to be before it is put out into the world?"
- Are open letters with influential signees impactful? This letter at the very least to me seems to be a neutral at worst, quite impactful at best sort of thing, but I have very little to back that, and honestly can't recall any specific time I know of where open letters cause significant change at the global/national level.
- Given the recent desire to distance from potentially fraught figures, would that mean shying away from a group wide EA endorsement of such a letter because a wild card like Elon is a part of it? I personally don't think he's at that level, but I know other EAs who would be apt to characterize him that way.
- Do I sign the post? What is the impact of adding signatures with significantly less professional or social clout to such an open letter? Does it promote the message of AI risk as something that matters to everyone? Or would someone look at "Tristan Williams, Tea Brewer" and think "oh, what is he doing on this list?"
↑ comment by Qumeric (valery-cherepanov) · 2023-03-29T17:35:18.700Z · LW(p) · GW(p)
2. I think non-x-risk focused messages are a good idea because:
- It is much easier to reach a wide audience this way.
- It is clear that there are significant and important risks even if we completely exclude x-risk. We should have this discussion even in a world where for some reason we could be certain that humanity will survive for the next 100 years.
- It widens Overton's window. x-risk is still mostly considered to be a fringe position among the general public, although the situation has improved somewhat.
3. There were cases when it worked well. For example, the Letter of three hundred.
4. I don't know much about EA's concerns about Elon. Intuitively, he seems to be fine. But I think that in general, people are more biased towards too much distancing which often hinders coordination a lot.
5. I think more signatures cannot make things worse if authors are handling them properly. Just rough sorting by credentials (as FLI does) may be already good enough. But it's possible and easy to be more aggressive here.
I agree that it's unlikely that this letter will be net bad and that it's possible it can make a significant positive impact. However, I don't think people argued that it can be bad. Instead, people argued it could be better. It's clearly not possible to do something like this every month, so it's better to put a lot of attention to details and think really carefully about content and timing.
Replies from: tristan-williams↑ comment by Tristan Williams (tristan-williams) · 2023-04-01T14:39:57.153Z · LW(p) · GW(p)
2. What is Overton's window? Otherwise I think I probably agree, but one question is, once this non-x-risk campaign is underway, how to you keep it on track and prevent value drift? Or do you not see that as a pressing worry?
3. Cool, will have to check that out.
4. Completely agree, and just wonder what the best way to promote less distancing is.
Yeah, I suppose I'm just trying to put myself in the shoes of the FHI people here that coordinated this and feel like many comments here are a bit more lacking in compassion than I'd like, especially for more half baked negative takes. I also agree that we want to put attention into detail and timing, but there is also the world in which too much of this leads to nothing getting done, and it's highly plausible to me that this had probably been an idea for long enough already to make that the case here.
Thanks for responding though! Much appreciated :)