Would we even want AI to solve all our problems?
post by So8res · 2023-04-21T18:04:11.636Z · LW · GW · 15 commentsContents
15 comments
Status: more of the basics, that I find myself regularly repeating.
When people from the wider population talk to me about politics or global warming or various other large global issues (as they're prone to do), I am prone to noting that most problems would be easier to fix if we had superintelligent friends at our backs.
A common objection I get goes something like:
So you think you can get AI to solve all the world's problems? Wouldn't that kinda suck, though? Wouldn't a problem-free life be kinda terrible? Isn't overcoming obstacles part of the fun of life?
To which my answer is: that's completely right. If we aren't careful, artificial intelligence could easily destroy all the value in the future, e.g. by aggressively solving everyone's problems and giving everyone everything they ask for, in a way that sucks all the joy and meaning out of life.
Value is fragile [LW · GW]. The goal is not to alleviate every ounce of discomfort; the goal is to make the future awesome. My guess is that that involves leaving people with real decisions that have real consequences, that it involves giving people the opportunity to screw up, that it involves allowing the universe to continue to be a place of obstacles that people must overcome.
But it also probably involves putting an end to a bunch of the senseless death, and putting an end to bad things happening to good people for no reason, and putting an end to the way that reality can punish a brief lapse of judgment with disproportionate, horrific, and irreversible consequences.
And it probably involves filling the universe with much more fun and joy and laughter. (And not just by building a bunch of speakers that play laugh tracks on a loop, but by filling the universe with the sorts of things that cause joyful laughter among healthy people, plus the healthy people to experience those things and laugh joyfully.)
The problem of making the future awesome is tricky and subtle. The way to get AI to help in the long term, is not to tell them exactly what our current best guess of what's "good" consists in, in a long list of current philosopher's best guesses, and then hope that modern philosophers got it exactly right. Because modern philosophers haven't got it exactly right; and that whole approach is doomed to failure.
The hope is that we can somehow face our AI and point at all the things we care about, and say "we don't know how to describe this in detail, and we don't know what the limits are, but we care about it; can you look at us and look at all this lovely stuff and care about it too, and help us in the great endeavor to have a wonderful future?". The win-state is ultimately to make friends, to make allies that help us fight the good fight.
The field of "what is the good stuff even (given that it's not something simple, like mere cessation of suffering or understanding of the universe)?" is called fun theory [LW · GW], and people who took the AI problem seriously invented it, once it became clear that our species is going to face a question like this, as we grow up.
The word I use for this concept is Fun (with a capital F), and I don't pretend to know exactly what it consists of, and the long-term goal is to build superintelligences that also want the future to be Fun.
And make no mistake, this is a long term goal. None of this is something humanity should be shooting for on its first try building AIs. The issue of AI alignment today is less about making the AIs care about fun, and more about making them perform some minimal pivotal act that ends the acute risk period, and buys us time to figure out how to make the superintelligent friends.
Because it's important not to screw that task up, and we shouldn't attempt it under time pressure before we know what we're doing.
See also don't leave your fingerprints on the future [LW · GW] and coherent extrapolated volition and indirect normativity [? · GW].
15 comments
Comments sorted by top scores.
comment by jacob_cannell · 2023-04-21T18:23:05.315Z · LW(p) · GW(p)
Value is fragile. The goal is not to alleviate every ounce of discomfort; the goal is to make the future awesome. My guess is that that involves leaving people with real decisions that have real consequences, that it involves giving people the opportunity to screw up, that it involves allowing the universe to continue to be a place of obstacles that people must overcome.
This is AGI optimizing for human empowerment [LW · GW].
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-04-21T21:50:53.353Z · LW(p) · GW(p)
that's probably part of it, agreed. it's probably not even close to closing the key holes in the loss landscape, though. you have a track record of calling important shots and people would do well to take you seriously, but at the same time, they'd do well not to assume you have all the answers. upvote and agree. how does that solve program equilibria in osgt though? how does it bound worst mistake, how does it bound worst powerseeking? how does it ensure defensibility?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2023-04-23T00:36:13.683Z · LW(p) · GW(p)
I'm not sure what you mean by solve program equilibria in osgt - partly because i'm not sure what 'osgt' means.
Optimizing for human/external empowerment doesn't bound the worst mistakes the agent can make. If by powerseeking you mean the AI seeking its own empowerment, the AI may need to do that in the near term, but in the long term that is an opposing rather obviously unaligned utility function. Navigating that transition tradeoff is where much of the difficulty seems to lie - but I expect that to be true of any viable solution. Not sure what you mean by defensibility.
Replies from: lahwran, lahwran, lahwran, lahwran, lahwran↑ comment by the gears to ascension (lahwran) · 2023-04-23T03:02:09.314Z · LW(p) · GW(p)
- program equilibria in open-source game theory: once a model is strong enough to make exact mathematical inferences about the implications of the way the approximator's actual learned behavior landed after training, the reflection about game theory can be incredibly weird. this is where much of the stuff about decision theories comes up, and the reason we haven't run into it already is because current models are big enough to be really hard to prove through. Related work, new and old:
- https://arxiv.org/pdf/2208.07006.pdf - Cooperative and uncooperative institution designs: Surprises and problems in open-source game theory - near the top of my to read list; by Andrew Critch [LW · GW] who has some other posts on the topic, especially the good ol "Open Source Game Theory is weird", and several more recent ones I haven't read properly at all
- https://arxiv.org/pdf/2211.05057.pdf - A Note on the Compatibility of Different Robust Program Equilibria of the Prisoner's Dilemma
- https://arxiv.org/pdf/1401.5577.pdf - Robust Cooperation in the Prisoner's Dilemma: Program Equilibrium via Provability Logic
- https://www.semanticscholar.org/paper/Program-equilibrium-Tennenholtz/e1a060cda74e0e3493d0d81901a5a796158c8410?sort=pub-date - the paper that introduced OSGT, with papers citing it sorted by recency
- also interesting https://www.semanticscholar.org/paper/Open-Problems-in-Cooperative-AI-Dafoe-Hughes/2a1573cfa29a426c695e2caf6de0167a12b788ef and https://www.semanticscholar.org/paper/Foundations-of-Cooperative-AI-Conitzer-Oesterheld/5ccda8ca1f04594f3dadd621fbf364c8ec1b8474
- This also connects through to putting neural networks in formal verification systems. The summary right now is that it's possible but doesn't scale to current model sizes. I expect scalability to surprise us.
↑ comment by the gears to ascension (lahwran) · 2023-04-23T03:18:05.680Z · LW(p) · GW(p)
- Bounding worst mistake: preventing adversarial examples and generalization failures. Plenty of work on this in general, but in particular I'm interested in certified bounds. (Though those usually turn out to have some sort of unhelpfully tight premise.)
- tons of papers I could link here that I haven't evaluated deeply, but you can find a lot of them by following citations from https://www.katz-lab.com/research - in particular:
- here's what's on my to-evaluate list in my
ai formal verification and hard robustnesstag in semanticscholar: https://arxiv.org/pdf/2302.04025.pdf https://arxiv.org/pdf/2304.03671.pdf https://arxiv.org/pdf/2303.10513.pdf https://arxiv.org/pdf/2303.03339.pdf https://arxiv.org/pdf/2303.01076.pdf https://arxiv.org/pdf/2303.14564.pdf https://arxiv.org/pdf/2303.07917.pdf https://arxiv.org/pdf/2304.01218.pdf https://arxiv.org/pdf/2304.01826.pdf https://arxiv.org/pdf/2304.00813.pdf https://arxiv.org/pdf/2304.01874.pdf https://arxiv.org/pdf/2304.03496.pdf https://arxiv.org/pdf/2303.02251.pdf https://arxiv.org/pdf/2303.14961.pdf https://arxiv.org/pdf/2301.11374.pdf https://arxiv.org/pdf/2303.10024.pdf - most of these are probably not that amazing, but some of them seem quite interesting. would love to hear which stand out to anyone passing by!
↑ comment by the gears to ascension (lahwran) · 2023-04-23T09:26:34.392Z · LW(p) · GW(p)
(and I didn't even mention reliable ontological grounding in the face of arbitrarily large ontological shifts due to fundamental representation corrections)
↑ comment by the gears to ascension (lahwran) · 2023-04-23T03:01:52.553Z · LW(p) · GW(p)
I'm replying as much to anyone else who'd ask the same question as I'm answering you in particular; I imagine you've seen some of this stuff in passing before. Hope the detail helps anyway! I'm replying in multiple comments to organize responses better. I've unvoted all my own comments but this one so it shows up as the top reply to start with.
↑ comment by the gears to ascension (lahwran) · 2023-04-23T03:02:32.220Z · LW(p) · GW(p)
- inappropriate powerseeking: seeking to achieve empowerment of the ai over empowerment of others, in order to achieve adversarial peaks of the reward model, or etc; ie, "you asked for collaborative powerseeking and instead got deceptive alignment due to an adversarial hole in your model". Some recent papers that try to formalize this in terms of RL:
- https://arxiv.org/pdf/2304.06528.pdf - Power-seeking can be probable and predictive for trained agents - see also the lesswrong post [LW · GW]
- https://arxiv.org/pdf/2206.13477.pdf - Parametrically Retargetable Decision-Makers Tend To Seek Power - see also the lesswrong post [LW · GW]
- Boundaries sequence [? · GW] is also relevant to this
- (also, having adversarial holes in behavior makes the OSGT branch of concern look like "smart model reads the weights of your vulnerable model and pwns it" rather than any sort of agentically intentional cooperation.)
comment by David Bravo (davidbravocomas) · 2023-04-22T21:24:40.925Z · LW(p) · GW(p)
As others have pointed out, there's a difference between a) problems to be tackled for the sake of the solution, vs b) problems to be tackled for the sake (or fun) of the problem. Humans like challenges and puzzles and to solve things themselves rather than having the answers handed down to them. Global efforts to fight cancer can be inspiring, and I would guess a motivation for most medical researchers is their own involvement in this same process. But if we could push a button to eliminate cancer forever, no sane person would refuse to.
I think we should aim to have all a) solved asap (at least those problems above a certain threshold of importance), and maintain b). At the same time, I suspect that the value we attach to b) also bears some relation to the importance of the solution to those problems. E.g. that a theoretical problem can be much more immersive, and eventually rewarding, when the whole of civilisation is at stake, than when it's a trivial puzzle.
So I wonder how to maintain b) once the important solutions can be provided much faster and easily by another entity or superintelligence. Maybe with fully immersive similations that reproduce e.g. the situation and experience of trying to find a cure to cancer, or with large-scale puzzles (such as scape rooms) but which are not life-or-death (nor happiness-or-suffering).
comment by jbash · 2023-04-22T00:51:42.347Z · LW(p) · GW(p)
If it "solves all your problems" in a way that leaves you bored or pithed or wireheaded, then you still have a problem, don't you? At least you have a problem according to your pre-wireheading value system, which ought to count for something.
That, plus plain old physical limitations, may mean that even talking about "solving all of anybody's problems" is an error.
Also, I'm not so sure that there's an "us" such that you can talk about "our problems". Me getting what makes me Truly Happy may actually be a problem from your point of view, or of course vice versa. It may or may not make sense to talk about "educating" anybody out of any such conflict. Irreconcilable differences seem very likely to be a very real thing, at least on relatively minor issues, but quite possibly in areas that are and will remain truly important to some people.
But, yeah, as I think you allude to, those are all nice problems to have. For now I think it's more about not ending up dead, or inescapably locked into something that a whole lot of people would see as an obvious full-on dystopia. I'm not as sure as you seem to be that you can assure that without rapidly going all the way to full-on superintelligence, though.
comment by baturinsky · 2023-04-22T12:26:59.802Z · LW(p) · GW(p)
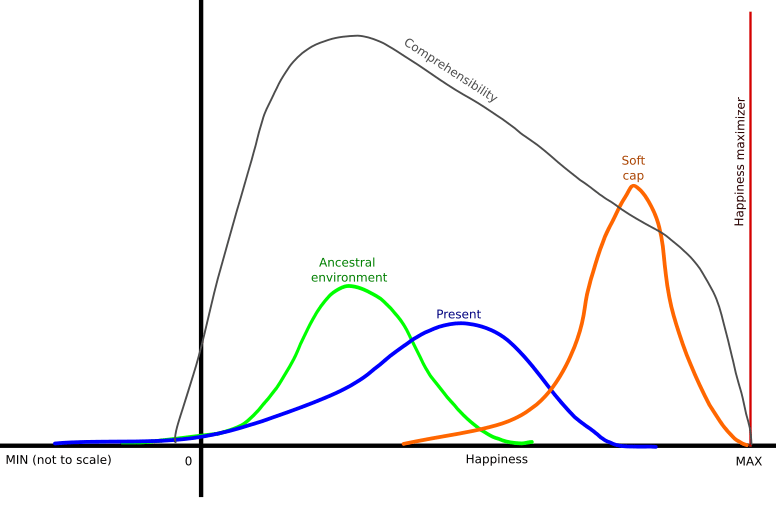
I was thinking about this issue too. Trying to make an article out of it, but so far all I have is this graph.
Idea is a "soft cap" AI. I.e., AI that is significantly improving our lives, but not giving us the "max happiness". And instead, giving us the oportunity of improving our life and life of other people using our brains.
Also, ways of using our brains should be "natural" for them, i.e. that should be mostly to solve tasks similar to tasks of our ancestral involvement.
↑ comment by Matthew_Opitz · 2023-04-22T14:49:39.818Z · LW(p) · GW(p)
Can you explain what the Y axis is supposed to represent here?
Replies from: baturinsky↑ comment by baturinsky · 2023-04-22T16:24:14.312Z · LW(p) · GW(p)
It's the distrbution, so it's the percentage of people in that state of "happiness" at the moment.
"Happiness" is used in the most vague and generic meaning of that word.
"Comprehensibility" graph is different, it is not a percentage, but some abstract measure of how well our brains are able to process reality with respective amount of "happiness".
comment by dr_s · 2023-04-22T06:26:13.134Z · LW(p) · GW(p)
I think a fair way to steelman that objection is interpreting it as meaning that doing what you describe isn't just subtle and super difficult, it's theoretically impossible, due to inherent contradictions in what we think we want, what different people want, inaccessibility of our true subjective experiences, etc.
That said, obviously, there's a lot of leeway before getting to those limits. The world with no cancer sounds a lot more awesome than the world with it, and if getting there requires depriving a handful of researchers of the satisfaction of knowing they solved the problem and the consequent Nobel Prize, well, I'm sure we can manage.
comment by Jon Garcia · 2023-04-22T01:04:17.288Z · LW(p) · GW(p)
I would say we want an ASI to view world-state-optimization from the perspective of a game developer. Not only should it create predictive models of what goals humans wish to achieve (from both stated and revealed preferences), but it should also learn to predict what difficulty level each human wants to experience in pursuit of those goals.
Then the ASI could aim to adjust the world into states where humans can achieve any goal they can think of when they apply a level of effort that would leave them satisfied in the accomplishment.
Humans don't want everything handed to us for free, but we also don't generally enjoy struggling for basic survival (unless we do). There's a reason we pursue things like competitive sports and video games, even as we denounce the sort of warfare and power struggles that built those competitive instincts in the ancestral environment.
A safe world of abundance that still feels like we've fought for our achievements seems to fit what most people would consider "fun". It's what children expect in their family environment growing up, it's what we expect from the games we create, and it's what we should expect from a future where ASI alignment has been solved.