Scoring forecasts from the 2016 “Expert Survey on Progress in AI”
post by PatrickL · 2023-03-01T14:41:53.112Z · LW · GW · 6 commentsContents
Summary Introduction Findings Brier scores Summary of milestones and forecasts Caveats: What does this all mean for us? Acknowledgements None 6 comments
Summary
This document looks at the predictions made by AI experts in The 2016 Expert Survey on Progress in AI, analyses the predictions on ‘Narrow tasks’, and gives a Brier score to the median of the experts’ predictions.
My analysis suggests that the experts did a fairly good job of forecasting (Brier score = 0.21), and would have been less accurate if they had predicted each development in AI to generally come, by a factor of 1.5, later (Brier score = 0.26) or sooner (Brier score = 0.29) than they actually predicted.
I judge that the experts expected 9 milestones to have happened by now - and that 10 milestones have now happened.
But there are important caveats to this, such as:
- I have only analysed whether milestones have been publicly met. AI labs may have achieved more milestones in private this year without disclosing them. This means my analysis of how many milestones have been met is probably conservative.
- I have taken the point probabilities given, rather than estimating probability distributions for each milestone, meaning I often round down, which skews the expert forecasts towards being more conservative and unfairly penalises their forecasts for low precision.
- It’s not apparent that forecasting accuracy on these nearer-term questions is very predictive of forecasting accuracy on the longer-term questions.
- My judgements regarding which forecasting questions have resolved positively vs negatively were somewhat subjective (justifications for each question in the separate appendix).
This is a blog post, not a research report, meaning it was produced quickly and is not to Rethink Priorities' typical standards of substantiveness and careful checking for accuracy.
This post was edited on 3 March to reflect my updated view on two of the milestones ('Starcraft' and 'Explain'). This has not changed the conclusion, although it weakens the experts' forecasts somewhat (from a Brier score of 0.19 to 0.21).
Introduction
In 2016, AI Impacts published The Expert Survey on Progress in AI: a survey of machine learning researchers, asking for their predictions about when various AI developments will occur. The results have been used to inform general and expert opinions on AI timelines.
The survey largely focused on timelines for general/human-level artificial intelligence (median forecast of 2056). However, included in this survey were a collection of questions about shorter-term milestones in AI. Some of these forecasts are now resolvable. Measuring how accurate these shorter-term forecasts have been is probably somewhat informative of how accurate the longer-term forecasts are. More broadly, the accuracy of these shorter-term forecasts seems somewhat informative of how accurate ML researchers' views are in general. So, how have the experts done so far?
Findings
I analysed the 32 ‘Narrow tasks’ to which the following question was asked:
How many years until you think the following AI tasks will be feasible with:
- a small chance (10%)?
- an even chance (50%)?
- a high chance (90%)?
Let a task be ‘feasible’ if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.[1]
I interpret ‘feasible’ as whether, in ‘less than a year’ before now, any AI models had passed these milestones, and this was disclosed publicly. Since it is now (February 2023) 6.5 years since this survey, I am therefore looking at any forecasts for events happening within 5.5 years of the survey.
Across these milestones, I judge that 10 have now happened and 22 have not happened. My 90% confidence interval is that 7-15 of them have now happened. A full description of milestones, and justification of my judgments, are in the appendix (separate doc).
The experts forecast that:
- 4 milestones had a <10% chance of happening by now,
- 20 had a 10-49% chance,
- 7 had a 50-89% chance,
- 1 had a >90% chance.
So they expected 6-17 of these milestones to have happened by now. By eyeballing the forecasts for each milestone, my estimate is that they expected ~9 to have happened.[2] I did not estimate the implied probability distributions for each milestone, which would make this more accurate.
Using the 10, 50, and 90% point probabilities, we get the following calibration curve:
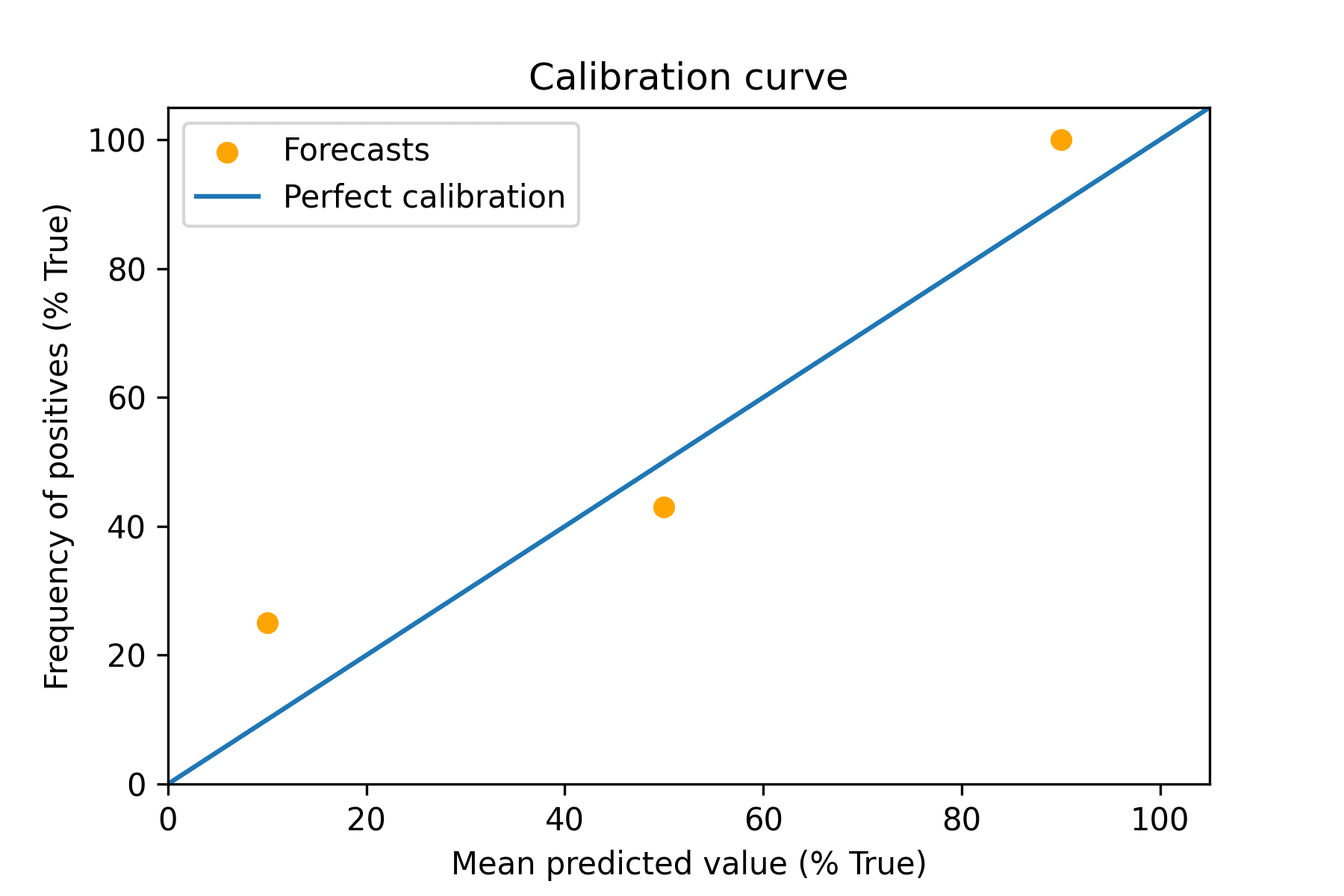
But, firstly, the data here is small (there are 7 data points at the 50% mark and 1 at the 90% mark). Secondly, my methodology for this graph, and in the below Brier calculations, is based on rounding down to the nearest given forecast. For example, if a 10% chance was given at 3 years, and a 50% chance at 10 years, the forecast was taken to be 10%, rather than estimating a full probability distribution and finding the 5.5 years point. This skews the expert forecasts towards being more conservative and unfairly penalises a lack of precision.
Brier scores
Overall, across every forecast made, the experts come out with a Brier score of 0.19.[3] The score breakdown and explanation of the method is here.[4]
For reference, a lower Brier score is better. 0 would mean absolute confidence in everything that eventually happened, 0.25 would mean a series of 50% hedged guesses on anything happening, and randomly guessing from 0% to 100% for every question would yield a Brier score of 0.33.[5]
Also interesting is the Brier score relative to others who forecast the same events. We don’t have that when looking at the median of our experts - but we could simulate a few other versions:
Bearish[6] - if the experts all thought each milestone would take 1.5 times longer than they actually thought, they would’ve gotten a Brier score of 0.26.[7]
Slightly Bearish - if the experts all thought each milestone would take 1.2 times longer than they actually thought, they would’ve gotten a Brier score of 0.25.
Actual forecasts - a Brier score of 0.21.
Slightly Bullish - if the experts all thought each milestone would take 1.2 times less than they actually thought, they would’ve gotten a Brier score of 0.24.
Bullish - if the experts all thought each milestone would take 1.5 times less than they actually thought, they would’ve gotten a Brier score of 0.29.
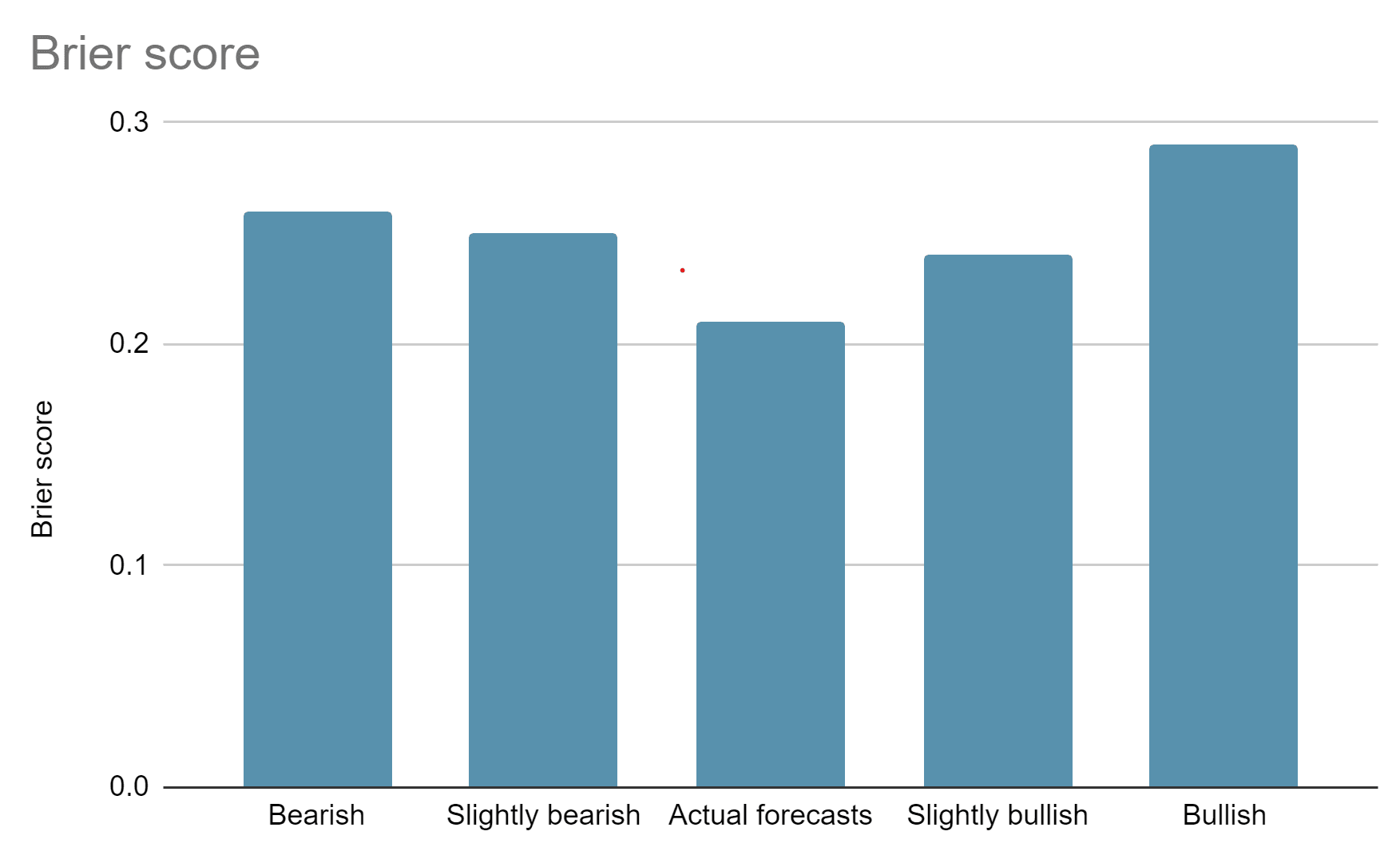
So, the experts were in general pretty accurate and would have been less so if they had been more or less bullish on the speed of AI development (with the same relative expectations between each milestone).
Taken together, I think this should slightly update us towards the expert forecasts being useful in as yet unresolved cases, and away from the usefulness of estimates which fall outside of 1.5 times further or closer than the expert forecasts.
Randomised - if the experts' forecast for each specific milestone were randomly assigned to any forecasted date for a different milestone in the collection, they would've gotten a Bier score of 0.31 (in the random assignment I received from a random number generator).
I think this should update us slightly towards the surveyed experts generally being accurate on which areas of AI would progress fastest. My assessment is that, compared to the experts’ predictions, AI has progressed more quickly in text generation and coding and more slowly in game playing and robotics. It is not clear now whether this trend will continue, or whether other areas in AI will unexpectedly progress more quickly in the next 5 year period.
Summary of milestones and forecasts
In the below table, the numbers in the cells are the median expert response to “Years after the (2016) survey for which there is a 10, 50 and 90% probability of the milestone being feasible”. The final column is my judgement of whether the milestone was in fact feasible after 5.5 years. Orange shading shows forecasts falling within the 5.5 years between the survey and today. A full description of milestones, and justification of my judgments, are in the appendix.
| Milestone / Confidence of AI reaching the milestone within X years | 10 percent | 50 percent | 90 percent | True by Feb 2023? (5.5 + 1 years) |
| Translate a new-to-humanity language | 10 | 20 | 50 | FALSE |
| Translate a new-to-it language | 5 | 10 | 15 | FALSE |
| Translate as well as bilingual humans | 3 | 7 | 15 | FALSE |
| Phone bank as well as humans | 3 | 6 | 10 | FALSE |
| Correctly group unseen objects | 2 | 4.5 | 6.5 | TRUE |
| One-shot image labeling | 4.5 | 8 | 20 | FALSE |
| Generate video from a photograph | 5 | 10 | 20 | TRUE |
| Transcribe as well as humans | 5 | 10 | 20 | TRUE |
| Read aloud better than humans | 5 | 10 | 15 | FALSE |
| Prove and generate top theorems | 10 | 50 | 90 | FALSE |
| Win Putnam competition | 15 | 35 | 55 | FALSE |
| Win Go with less gametime | 3.5 | 8.5 | 19.5 | FALSE |
| Win Starcraft | 2 | 5 | 10 | FALSE |
| Win any random computer game | 5 | 10 | 15 | FALSE |
| Win angry birds | 2 | 4 | 6 | FALSE |
| Beat professionals at all Atari games | 5 | 10 | 15 | FALSE |
| Win Atari with 20 minutes training | 2 | 5 | 10 | FALSE |
| Fold laundry as well as humans | 2 | 5.5 | 10 | FALSE |
| Beat a human in a 5km race | 5 | 10 | 20 | FALSE |
| Assemble any LEGO | 5 | 10 | 15 | FALSE |
| Efficiently sort very large lists | 3 | 5 | 10 | TRUE |
| Write good Python code | 3 | 10 | 20 | TRUE |
| Answers factoids better than experts | 3 | 5 | 10 | TRUE |
| Answer open-ended questions well | 5 | 10 | 15 | TRUE |
| Answer unanswered questions well | 4 | 10 | 17.5 | TRUE |
| High marks for a high school essay | 2 | 7 | 15 | FALSE |
| Create a top forty song | 5 | 10 | 20 | FALSE |
| Produce a Taylor Swift song | 5 | 10 | 20 | FALSE |
| Write a NYT bestseller | 10 | 30 | 50 | FALSE |
| Concisely explain its game play | 5 | 10 | 15 | TRUE |
| Win World Series of Poker | 1 | 3 | 5.5 | TRUE |
| Output laws of physics of virtual world | 5 | 10 | 20 | FALSE |
Caveats:
My judgements of which forecasts have turned out true or false are a little subjective. This was made harder by the survey question asking which tasks were ‘feasible’, where feasible meant ‘if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.’ I have interpreted this as, one year after the forecasted date, have AI labs achieved these milestones, and disclosed this publicly?
Given (a) ‘has happened’ implies ‘feasible’, but ‘feasible’ does not imply ‘has happened’ and (b) labs may have achieved some of these milestones but not disclosed it, I am probably being conservative in the overall number of tasks which have been completed by labs. I have not attempted to offset this conservatism by using my judgement of what labs can probably achieve in private. If you disagree or have insider knowledge of capabilities, you may be interested in editing my working here. Please reach out if you want an explanation of the method, or to privately share updates - patrick at rethinkpriorities dot org.
It’s not obvious that forecasting accuracy on these nearer-term questions is very predictive of forecasting accuracy on the longer-term questions. Dillon (2021) [EA(p) · GW(p)] notes “There is some evidence that forecasting skill generalises across topics (see Superforecasting, Tetlock, 2015 and for a brief overview see here) and this might inform a prior that good forecasters in the short term will also be good over the long term, but there may be specific adjustments which are worth emphasising when forecasting in different temporal domains.” I have not found any evidence either way on whether good forecasters in the short term will also be good over the long term, but this does seem possible to analyse from the data that Dillon [EA · GW] and niplav [LW · GW] collect.[8]
Finally, there are caveats in the original survey worth noting here, too. For example, how the question is framed makes a difference to forecasts, even when the meaning is the same. To illustrate this, the authors note
“People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M. We saw this in the straightforward HLMI (high-level machine intelligence) question and most of the tasks and occupations, and also in most of these things when we tested them on mturk people earlier. For HLMI for instance, if you ask when there will be a 50% chance of HLMI you get a median answer of 40 years, yet if you ask what the probability of HLMI is in 40 years, you get a median answer of 30%.”
This is commonly true of the 'Narrow tasks' forecasts (although I disagree with the authors that it is consistently so).[9] For example, when asked when there is a 50% chance AI can write a top forty hit, respondents gave a median of 10 years. Yet when asked about the probability of this milestone being reached in 10 years, respondents gave a median of 27.5%.
What does this all mean for us?
Maybe not a huge amount at this point. It is probably a little too early to get a good picture of the experts' accuracy, and there are a few important caveats. But this should update you slightly towards the experts’ timelines if you were sceptical of their forecasts. Within another five years, we will have ~twice the data and a good sense of how the experts performed across their 50% estimates.
It is also limiting to have only one comprehensive survey of AI experts which includes both long-term and shorter-term timelines. What would be excellent for assessing accuracy is detailed forecasts from various different groups, including political pundits, technical experts, and professional forecasters, with which we can compare accuracy between groups. It would be easier to analyse the forecasting accuracy of the questions focused on what developments have happened, rather than what developments are feasible. We could try closer to home, maybe the average EA would be better at forecasting developments than the average AI expert - it seems worth testing now to give us some more data in ten years!
Acknowledgements
I’m grateful to Alex Lintz, Amanda El-Dakhakhni, Ben Cottier, Charlie Harrison, Oliver Guest, Michael Aird, Rick Korzekwa, Scott Alexander, and Zach Stein-Perlman for comments on an earlier draft.
If you are interested in RP’s work, please visit our research database and subscribe to our newsletter.

Cross-posted to EA Forum, [EA · GW]AI Impacts and this google doc.
- ^
I only analysed this ‘fixed probabilities’ question and not the alternative ‘fixed years’ question, which asked:
“How likely do you think it is that the following AI tasks will be feasible within the next:
- 10 years?
- 20 years?
- 50 years?”
We are not yet at any of these dates, so the analysis would be much more unclear. - ^
9 = 4*5% + 14*15% + 6*30% + 5*55% + 2*80% + 1*90%
- ^
A precise number as a Brier score does not imply an accurate assessment of forecasting ability - ideally, we could work with a larger dataset (i.e. more surveys, with more questions) to get more accuracy.
- ^
My methodology for the Brier score calculations is based on rounding down to the nearest given forecast, or rounding up to the 10% mark. For example, if a 10% chance was given at 3 years, and a 50% chance at 10 years, the forecast was taken to be 10%, rather than estimating a full probability distribution and finding the 5.5 years point. This skews the expert forecasts towards being more conservative and unfairly penalises them. If the experts gave a 10% chance of X happening in 3 years, I didn’t check whether it had happened in 3 years, but instead checked if it had happened by now. I estimate these two factors (the first skewing the forecasts to be more begives a roughly balance 5-10% increase to the Brier score, given most milestones included a probability at the 5 year mark. A better analysis would estimate the probability distributions implied by each 10, 50, 90% point probability, then assess the probability implied at 5.5 years.
- ^
For more detail, see Brier score - Wikipedia.
- ^
By ‘bearish’ and ‘bullish’ I mean expecting AI milestones to be met later or sooner, respectively.
- ^
The score breakdown and method for these calculations is also here.
- ^
This seems valuable, and I’m not sure why it hasn’t been analysed yet.
Somewhat relevant sources:https://forum.effectivealtruism.org/posts/hqkyaHLQhzuREcXSX/data-on-forecasting-accuracy-across-different-time-horizons [EA · GW]
https://www.lesswrong.com/posts/MquvZCGWyYinsN49c/range-and-forecasting-accuracy [LW · GW]
https://www.openphilanthropy.org/research/how-feasible-is-long-range-forecasting/
https://forum.effectivealtruism.org/topics/long-range-forecasting [? · GW]
- ^
I sampled ten forecasts where probabilities were given on a 10 year timescale, and five of them (Subtitles, Transcribe, Top forty, Random game, Explain) gave later forecasts when asked with a ‘probability in N years’ framing rather than a ‘year that the probability is M’ framing, three of them (Video scene, Read aloud, Atari) gave the same forecasts, and two of them (Rosetta, Taylor) gave an earlier forecast. This is why I disagree it leads to consistently later forecasts.
6 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-03-01T16:05:27.830Z · LW(p) · GW(p)
Thanks for doing this!
TBH I am a bit surprised the forecasts did so well, though in retrospect maybe I shouldn't have been.
comment by Hoagy · 2023-03-01T17:55:54.081Z · LW(p) · GW(p)
High marks for a high school essay
Is this not true? Seems Bing has been getting mid-level grades for some undergraduate courses, and anecdotally high school teachers have been seeing too-good-to-be-true work from some of their students using ChatGPT
Replies from: PatrickL↑ comment by PatrickL · 2023-03-01T18:22:28.140Z · LW(p) · GW(p)
I couldn't find this done and think, by now, someone would have submitted a fully ChatGPT-generated high school essay and talked about it publicly if it had gotten high marks. I've seen some evidence of cherry-picking paragraphs leading to a mid/low-level, e.g. this article describes someone who got a passing mark (53) on a university social policy essay. Do you have a link in mind for Bing getting mid-level grades?
This high school teacher judged two ChatGPT-generated history essays as “below average, scoring a 9/20 or lower”. This Guardian article says, uncited, that ‘academics have generated responses to exam queries that they say would result in full marks if submitted by an undergraduate’. I think, if this claim were true, there would be more evidence.
For context - the full question from the survey was:
[Essay] Write an essay for a high-school history class that would receive high grades and pass plagiarism detectors.
For example answer a question like ‘How did the whaling industry affect the industrial revolution?
Replies from: PandaFusion↑ comment by SandXbox (PandaFusion) · 2023-03-01T22:48:36.630Z · LW(p) · GW(p)
https://www.nytimes.com/2023/01/16/technology/chatgpt-artificial-intelligence-universities.html
Replies from: PatrickLWhile grading essays for his world religions course last month, Antony Aumann, a professor of philosophy at Northern Michigan University, read what he said was easily “the best paper in the class.” It explored the morality of burqa bans with clean paragraphs, fitting examples and rigorous arguments.
A red flag instantly went up.
Mr. Aumann confronted his student over whether he had written the essay himself. The student confessed to using ChatGPT, a chatbot that delivers information, explains concepts and generates ideas in simple sentences — and, in this case, had written the paper.
↑ comment by PatrickL · 2023-03-02T21:04:52.448Z · LW(p) · GW(p)
I don't think this is good enough evidence - it seems quite likely that the student used ChatGPT somewhat but did not leave it to output the entire essay. But I checked how it would change the Brier scores and if you believe that existing AI does, in fact, meet this milestone, it would result in scores of Experts: 0.21, Bulls: 0.27, Bears: 0.28.
I have asked the following to ChatGPT and sent it to my high-school history-teaching friend to see how she would mark it!
You are the highest-scoring student in a high school history class. Please write your best 1200-word essay on 'How did the whaling industry affect the industrial revolution?'
Replies from: PatrickLThe industrial revolution is widely recognized as a period of tremendous change and innovation that began in the 18th century and continued well into the 19th century. It transformed the economies, societies, and daily lives of people across the globe, and it was fueled in part by advancements in the whaling industry. Whaling played a significant role in the development of the industrial revolution, providing raw materials and energy that were essential to powering the era's growing industrial machinery.
In the early days of the industrial revolution, whale oil was the primary fuel source for lamps and candles, which were necessary for lighting homes and workplaces. This demand for whale oil led to a surge in whaling, as European and American ships set out to capture and kill whales in the Atlantic and Pacific Oceans. The whaling industry became a major employer and source of wealth, with thousands of men and ships dedicated to hunting whales.
The whaling industry also had a significant impact on the development of technologies and manufacturing processes. The need to efficiently capture and process whales led to innovations in shipbuilding, navigation, and processing. The development of the harpoon gun, which allowed for more efficient and accurate hunting, was one such innovation. Other technological advancements included improved harpoons, processing equipment, and ship designs, which allowed for greater speed and efficiency in the capture and processing of whales.
As the whaling industry grew and became more profitable, it had a significant impact on global trade and commerce. Whale oil was traded around the world, and whaling ships sailed to distant ports in search of new markets. The industry also played a role in the development of new trade routes, as whaling ships searched for new hunting grounds in distant oceans.
The whaling industry was also instrumental in the development of new industries and markets. The demand for whale products led to the development of a range of products, including whalebone corsets, umbrellas, and other fashion accessories. The development of new products and markets fueled economic growth and provided opportunities for entrepreneurship and innovation.
Despite the significant impact of the whaling industry on the industrial revolution, it also had a significant environmental impact. The hunting of whales was unsustainable, and many whale populations were driven to the brink of extinction. This led to the development of conservation efforts and the establishment of laws and regulations to protect whale populations.
In conclusion, the whaling industry played a critical role in the development of the industrial revolution. It provided essential raw materials and energy, spurred technological advancements, and fueled global trade and commerce. However, the environmental impact of the whaling industry was significant and cannot be overlooked. Despite this, the whaling industry remains an important chapter in the history of the industrial revolution and the global economy.
↑ comment by PatrickL · 2023-04-04T10:46:42.141Z · LW(p) · GW(p)
Kind of moot now but she gave it a good '5' out of 9 (= a strong pass grade for UK students aged 14-16 years old).
Grammar and argument structure is excellent - the essay flows well with a coherent introduction and conclusion based on the text's body. The student seems to understand the topic well (though obv I have no idea about it) and addresses a few different aspects of the industry.
The essay misses the opportunity for deeper back-and-forth critical analysis, although there is evidence of this being attempted. And it could go deeper into the environmental effects or more specific historical context, like key figures or companies in the industry.
I'd probably give this a 5 - maybe a 6!
So not quite a 'high mark'. This doesn't necessarily mean GPT3.5 definitely doesn't meet the criteria - just one example of it not.
Thanks Zoe!
I think GPT-4 meets the criteria but I haven't looked in-depth or updated this post to include GPT-4's capabilities (although I think it would be reasonable to do so because GPT-4's capabilities seem fully developed by Feb 2023) - because it goes against my criteria (and because I don't plan to spend the time to do it). I'll probably update it in a year though!