Bits of Optimization Can Only Be Lost Over A Distance
post by johnswentworth · 2022-05-23T18:55:17.396Z · LW · GW · 18 commentsContents
18 comments
When we think of “optimization” as compressing some part of the universe into a relatively small number of possible states [LW · GW], it’s very natural to quantify that compression in terms of “bits of optimization” [LW · GW]. Example: we have a marble which could be in any of 16 different slots in a box (assume/approximate uniform probability on each). We turn the box on its side, shake it, and set it down so the marble will end up in one of the 4 slots on the downward side (again, assume/approximate uniform probability on each). Then we’ve compressed the marble-state from 16 possibilities to 4, cut the state-space in half twice, and therefore performed two bits of optimization.
In the language of information theory, this quantity is the KL-divergence between the initial and final distributions.
In this post, we’ll prove our first simple theorem about optimization at a distance [LW · GW]: the number of bits of optimization applied can only decrease over a distance. In particular, in our optimization at a distance picture:
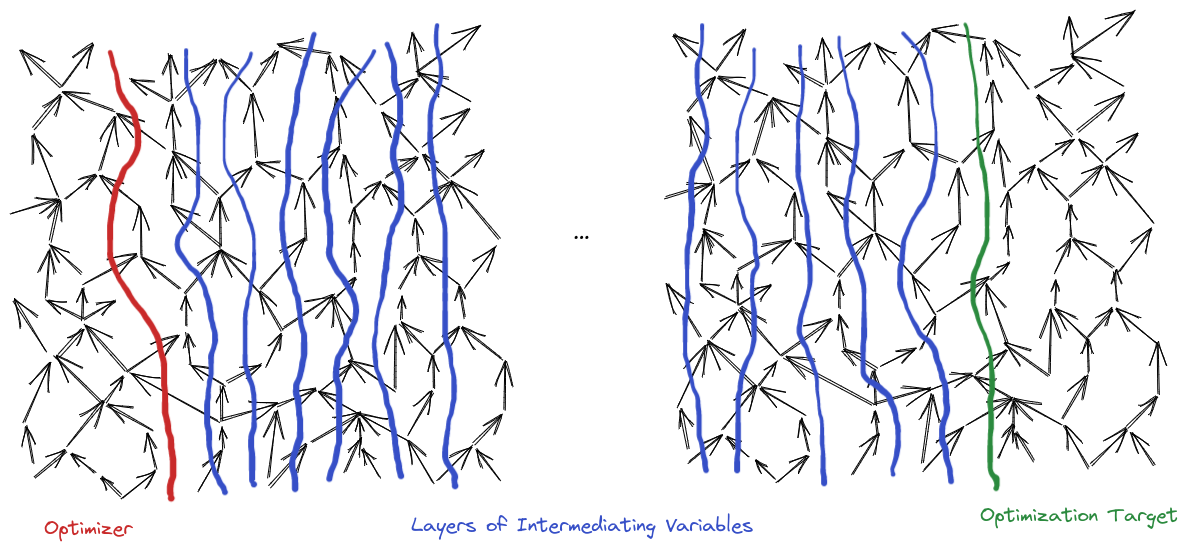
… the number of bits of optimization applied to the far-away optimization target cannot be any larger than the number of bits of optimization applied to the optimizer’s direct outputs.
The setup: first, we’ll need two distributions to compare over the optimizer’s direct outputs. You might compare the actual output-distribution to uniform randomness, or independent outputs. If the optimizer is e.g. a trained neural net, you might compare its output-distribution to the output-distribution of a randomly initialized net. If the optimizer has some sort of explicit optimization loop (like e.g. gradient descent), then you might compare its outputs to the initial outputs tested in that loop. These all have different interpretations and applications; the math here will apply to all of them.
Let’s name some variables in this setup:
- Optimizer’s direct outputs: (for “actions”)
- ’th intermediating layer: (with )
- Reference distribution over everything:
- Actual distribution over everything:
By assumption, only the optimizer differs between the reference and actual distributions; the rest of the Bayes net is the same. Mathematically, that means (and of course both distributions factor over the same underlying graph).
Once we have two distributions over the optimizer’s direct outputs, they induce two distributions over each subsequent layer of intermediating variables, simply by propagating through each layer:
At each layer, we can compute the number of bits of optimization applied to that layer, i.e. how much that layer’s state-space is compressed by the actual distribution relative to the reference distribution. That’s the KL-divergence between the distributions: .
To prove our theorem, we just need to show that . To do that, we’ll use the chain rule of KL divergence to expand in two different ways. First:
Recall that and are the same, so , and our first expression simplifies to . Second:
KL-divergence is always nonnegative, so we can drop the second term above and get an inequality:
Now we just combine these two expressions for and find
… which is what we wanted to prove.
So: if we measure the number of bits of optimization applied to the optimizer’s direct output, or to any particular layer, that provides an upper bound on the number of bits of optimization applied further away.
18 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-24T00:46:39.888Z · LW(p) · GW(p)
To check my noob understanding:
Suppose you are playing a MMO video game which accepts about 10,000 binary inputs per second, in the form of various keyboard buttons being pressed or not. You want to cause something crazy and meme-worthy to happen in the game, like everyone in the game falling over dead simultaneously. You have an hour or so of playtime total. What's the craziest thing you can make happen?
Answer: Well, whatever it is, it has to be at least 1/2^(10,000x3600) likely to happen already. If it was less likely than that, you wouldn't be able to make it likely even if you played perfectly.
Replies from: johnswentworth, tgbrooks↑ comment by johnswentworth · 2022-05-24T04:57:18.377Z · LW(p) · GW(p)
That's a correct intuitive understanding.
↑ comment by tgbrooks · 2022-05-24T01:45:31.171Z · LW(p) · GW(p)
I think this assumes implicitly that P(A|ref) is uniformly distributed over all the 10,000 options. In a video game I‘d think more that the ”reference” is always to output 0s since the player isn’t interacting. Then The KL divergence could be arbitrarily large. But it’s not really clear in general how to interpret the reference distribution, perhaps someone can clarify?
Replies from: kave↑ comment by kave · 2022-05-24T02:18:43.489Z · LW(p) · GW(p)
I agree on the "reference" distribution in Daniel's example. I think it generally means "the distribution over the random variables that would obtain without the optimiser". What exactly that distribution is / where it comes from I think is out-of-scope for John's (current) work, and I think is kind of the same question as where the probabilities come from in statistical mechanics.
Replies from: johnswentworth, tgbrooks↑ comment by johnswentworth · 2022-05-24T04:58:01.920Z · LW(p) · GW(p)
What exactly that distribution is / where it comes from I think is out-of-scope for John's (current) work, and I think is kind of the same question as where the probabilities come from in statistical mechanics.
Yup.
↑ comment by tgbrooks · 2022-05-24T11:00:32.050Z · LW(p) · GW(p)
My problem is that A is defined as the output of the optimizer, M0 is defined as A, so P(A|ref) is central to the entire inequality. However, what is the output of an optimizer if we are without the optimizer? The given examples (Daniel's and John's) both gloss over the question of P(A|ref) and implicitly treat it as uniform over the possible choices the optimizer could have made. In the box-with-slots examples, what happens if there is no optimizer? I don't know.
In the MMO example, what is the output without a player-optimizer? I don't think it's a randomly chosen string of 10,000 bit inputs. No MMO I've ever played chooses random actions if you walk away from it. Yet Daniel's interpretation assumes that that's the distribution. Anything else, the player choosing the least likely reference outcome can beat the bounds in Daniel's answer. I.e. his example makes it clear that bits-of-optimization applied by the player does not correspond to bits-of-input, unless the reference is a randomly chosen string of inputs. And in that case, the bound feels trivial and uninsightful. If every possible action I can choose has a p chance of happening without me, then the output that I choose will have had a chance of p by definition. And the distribution of outcomes I selected will then always have had at least a p chance of having been selected without me (plus some chance that it happened through other possible output choices). No math needed to make me believe that!
None of this applies to the equation itself. It works for any choice of P(A|ref). But I think that changes the interpretations given (such as Daniels) and without it I'm not sure I that this builds intuition for anything in the way that I think it's trying to do. Is "uniformly choose an output" really a useful reference? I don't think it is useful for intuition. And in the useful references I choose (constant output), the bound becomes trivial (infinite KL divergence). So what is a useful choice?
↑ comment by kave · 2022-05-24T15:50:24.401Z · LW(p) · GW(p)
Good point!
It seems like it would be nice in Daniel's example for P(A|ref) to be the action distribution of an "instinctual" or "non-optimising" player. I don't know how to recover that. You could imagine something like an n-gram model of player inputs across the MMO.
comment by Donald Hobson (donald-hobson) · 2022-05-24T12:23:22.326Z · LW(p) · GW(p)
Suppose I send a few lines of code to a remote server. Those lines are enough to bootstrap a superintelligence which goes on to strongly optimize every aspect of the world. This counts as a fairly small amount of optimization power, as the chance of me landing on those lines of code by pure chance isn't that small.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-05-24T16:05:52.376Z · LW(p) · GW(p)
Correct, though note that this doesn't let you pick a specific optimization target for that AGI. You'd need more bits in order to specify an optimization target. In other words, there's still a meaningful sense in which you can't "steer" the world into a specific target other than one it was likely to hit anyway, at least not without more bits.
comment by ACrackedPot · 2022-05-23T19:14:10.350Z · LW(p) · GW(p)
Is this assuming all optimization happens at "the optimizer" (and thus implicitly assuming that no optimization can take place in any intermediate step?)
Replies from: johnswentworth↑ comment by johnswentworth · 2022-05-23T19:21:20.605Z · LW(p) · GW(p)
That wording is somewhat ambiguous, but the answer to the question which I think you're trying to ask is "yes". We're assuming that any differences between "optimized" and "not optimized" states/distributions are driven by differences in the optimizer, in the sense that the causal structure of the world outside the optimizer remains the same.
Intuitively, this corresponds to the idea that the optimizer is "optimizing" some far-away chunk of the world, and we're quantifying the optimization "performed by the optimizer", not whatever optimization might be done by whatever else is in the environment.
Replies from: ACrackedPot↑ comment by ACrackedPot · 2022-05-23T19:44:07.720Z · LW(p) · GW(p)
Stepping into a real-world example, consider a text file, and three cases, illustrating different things:
First case: Entirely ineffective ZIP compression, (some processes), effective ZIP compression. If we treat the ineffective ZIP compression as "the optimizer", then it is clear that some compression happens later in the sequence of processes; the number of bits of optimization increased. However, the existence or non-existence of the first ineffective ZIP compression has no effect on the number of bits of optimization, so maybe this isn't quite appropriate as a way of thinking about this.
Second case: Anti-effective ZIP compression, (some processes), effective ZIP compression. The anti-effective ZIP compression, instead of compressing the file, maybe just copies the file twenty times. Then the effective ZIP compression takes that, and possibly compresses it nearly as effectively as the first case. The existence or non-existence of the anti-effective ZIP compression does matter in this case - in particular, if we compare the state of its output compared to the final state, the anti-effective ZIP compression creates a wider optimization discrepancy; it would appear to "optimize at a distance."
Third case: Garbage data cleanup, (some processes), effective ZIP compression. Here we enter an interesting case, because, if we treat the garbage data cleanup as our optimizer, it both optimizes the immediate output, and, in the event that the garbage is significantly higher entropy than the rest of the data, might make the effective ZIP compression more effective.
I think the third case really matters here, but in general, once you introduce a second optimizer, you can create emergent optimizations which don't strictly belong to either optimizer. Additionally, once we submit the existence of emergent optimizations, it may entirely be possible for an optimizer to optimize "at a distance", even without a specific second optimization taking place. Consider any given optimization as a sequence of operations each of which is necessary; if we treat the first operation as "the optimizer", then the optimization as a whole happens "at a distance", given that without the first operation, the optimization fails, and it is only optimized at the final step in the process (given that each step is necessary).
Replies from: tgbrooks↑ comment by tgbrooks · 2022-05-24T13:26:12.082Z · LW(p) · GW(p)
I'm intrigued by these examples but I'm not sure it translates. It sounds like you are interpreting "difference of size of file in bits between reference and optimized versions" as the thing the KL divergence is measuring, but I don't think that's true. I'm assuming here that the reference is where the first step does nothing and outputs the input file unchanged (effectively just case 1). Let's explicitly assume that the input file is a randomly chosen English word.
Suppose a fourth case where our "optimizer" outputs the file "0" regardless of input. The end result is a tiny zip file. Under the "reference" condition, the original file is zipped and is still a few bytes, so we have reduced the file size by a few bytes at most. However, the KL divergence is infinite! After all "0" is not an English word and so it's zip never appears in the output distribution of the reference but occurs with probability 1 under our optimizer. So the KL divergence is not at all equal to the number of bits of filesize reduced. Obviously this example is rather contrived, but it suffices to show that we can't directly translate intuition about filesizes to intuition about bits-of-optimization as measured by KL divergence.
Were you going for a different intuition with these examples?
↑ comment by ACrackedPot · 2022-05-24T17:39:16.050Z · LW(p) · GW(p)
It isn't the thing that the KL divergence is measuring, it is an analogy for it. The KL divergence is measuring the amount of informational entropy; strictly speaking, zipping a file has no effect in those terms.
However, we can take those examples more or less intact and place them in informational-entropy terms; the third gets a little weird in the doing, however.
So, having an intuition for what the ZIP file does, the equivalent "examples":
Example 1: KLE(Reference optimizer output stage, ineffective optimizer output) is 0; KLE(Reference final stage, ineffective optimizer final stage) is also 0. Not appropriate as a way of thinking about this, but helpful to frame the next two examples.
Example 2: KLE(Reference optimizer output stage, antieffective optimizer output) is -N; KLE(Reference final stage, antieffective optimizer final stage) is 0. Supposing an antieffective optimizer and an optimizer can both exist such that a future optimizer optimizes away the inefficiency introduced by the antieffective optimizer, we may observe a violation of the conclusion that, for N steps, adding an optimizer cannot result in a situation such that the KL distance of N+1 must be less than or equal to the KL distance of N, relative to their reference cases.
Example 3: The central conceit to this example is harder to translate; the basic idea is that one optimization can make a future optimization more efficient. Critically for this, the future optimization can vary in effectiveness depending on the input parameters. Suppose, for a moment, a state-reduction algorithm on a set of states n, using something like the opening example:
For n < 64, each state mapping n maps to the state {ceiling (n / 4)} [2 bits of optimization]
For n > 64, each state mapping n maps to the state {ceiling (n / 2)} [1 bit of optimization]
Then, for a probability distribution such that the number of states is greater than 64 but less than 128, a precursor optimization which halves the number of states (1 bit of optimization) will create an additional bit of optimization at this second optimizer.
Or, for a very contrived example, the first "optimizer" does minimal optimization, and mostly just encodes a control sequence into the output which enables the second optimizer to actually optimize.
There's something here about process-entropy versus data-entropy which I think merits examination, however.
[Also, an observation: Arithmetic is an optimizer. Consider the number of input states and the number of output states of addition.]
comment by Leon Lang (leon-lang) · 2023-01-13T23:50:28.805Z · LW(p) · GW(p)
Summary:
In this article, John reproves, without mentioning it, an information-theoretic version of the second law of thermodynamics, and then tries to apply it to talk about the loss of bits of optimization over a distance. I will first explain the classical result and then explain his attempted generalization. I say “attempted” since (a) I think he misses at least one assumption and (b) it is a bit unclear how to make sense of the result in the physical world.
In the classical setting of the result, one has a Markov chain M0 → M1 → … → Mn of random variables with fixed conditional distributions P(Mi | Mi-1) but unspecified initial distribution P(M0). Let’s call the two initial distributions P(M0 | opt) and P(M0 | ref) like John does in the article. One can then look at the KL divergence of the two distributions at each stage and prove that they get smaller and smaller. Why is this a second law of thermodynamics? The reason is that you can assume the initial reference distribution to be uniform, put more assumptions on the situation to show that all intermediate reference distributions will be uniform as well, and use the KL-inequality to show that the entropy of the optimized distribution will get larger and larger along the Markov chain. All of that is explained in chapter 4.4 of the classic information theory book by Thomas and Cover, and from that point of view, the article isn’t new. One nice interpretation in John’s context is that if the goal of the optimizer is just to produce order (= low entropy), then one should expect this effect to disappear over time: rooms don’t remain tidy.
Now, John would like to apply this to the case of Bayesian networks as generalizations of Markov chains, but isn’t very careful in stating the right assumptions. I don’t know what the right assumptions are either, but here is a caveat: in the picture drawn in the article, some of the later intermediate layers causally influence earlier intermediate layers by arrows going to the left. This means that the ordering of the layers is not strictly reflected in the partial ordering in the Bayes net. As an extreme example of where this goes wrong, consider the setting of a Markov chain M0 → M2 → M1 in which M2 has an arrow “back” to M1. John’s formulas state that P(M2 | M1, ref) = P(M2 | M1, opt), but is this true? Let’s use Bayes rule to figure it out:
P(M2 | M1, ref) = P(M1 | M2, ref) * P(M2 | ref) / (sum_M2’ P(M1 | M2’, ref) * P(M2’ | ref))
= P(M1 | M2, opt) * P(M2 | ref) / (sum_M2’ P(M1 | M2’, opt) * P(M2’ | ref))
!= P(M1 | M2, opt) * P(M2 | opt) / (sum_M2’ P(M1 | M2’, opt) * P(M2’ | opt))
= P(M2 | M1, opt)
One of the steps is not an equality since P(M2 | ref) and P(M2 | opt) are not the same. (Admittedly, I didn’t write down a full example of the non-equality being true, but playing around with numbers, you should be able to find one)
So, the visualization in the article seems to be wrong, insofar as it is supposed to apply to the result. I think the following assumption is likely sufficient, and probably one could relax this further:
- all variables in Mi+1 come after all variables in Mi in the partial ordering implied by the graph.
So much about the assumptions. Let’s assume we have settled these and the theorem is true. Then the article makes the following interpretation:
- M0 are the actions of an agent.
- KL divergence equals bits of optimization
Then the result states that you can’t cause more bits of optimization at a distance than at your vicinity.
My Opinion
There are some things I’m confused about here:
- Why measure bits of optimization as a KL divergence between distributions? What is the reference distribution here? Arguably, if one just “shifts a normal distribution far away”, then this doesn’t seem like optimization to me since the number of configurations doesn’t really get smaller in any way; the KL divergence might still be large.
- Maybe John just wants to be general in the same way in which the second law of thermodynamics can initially be formulated in terms of KL divergence. Under that interpretation, we might always want to assume the reference distribution to be uniform. The bits of optimization would then be the difference between the entropies of the uniform and the optimized distribution, which is larger for narrower optimized distributions. This seems closer to what I consider to be “optimization”.
- Is it valid to think of the universe as consisting of just one “large causal graph”?
- At the lowest level, this doesn’t seem correct since there doesn’t seem to be causality in fundamental physics (at least, physicists often say this… I’m not one of them)
- If we “bundle together” variables, then the assumption of a causal graph seems more true, but then it’s also less clear to me whether this causal graph can be modeled to be independent of changes in an optimizer’s actions. What if, for example, we assign a variable to a bacterium, but then it splits into two or not, depending on our actions? Or what if I perform actions that change the inner workings of another agent, resulting in changes in the conditional distributions of arrows going into the agent compared to the counterfactual world? These seem fundamentally very difficult questions that give me the impression that this article only scratches the surface.
- A final confusion is that KL divergence is not symmetric, meaning that if you switch between optimized and reference distributions back and forth, the bits of optimization will differ. This problem disappears if we just agree to always use the uniform distribution as the reference, but insofar as John also wants to apply it in the general case, I’m unsure how to interpret this asymmetry.
↑ comment by johnswentworth · 2023-01-15T20:41:55.838Z · LW(p) · GW(p)
Y'know, I figured someone must have already shown this and used it before, but I wasn't sure where. Didn't expect it'd already be on my bookshelf. Thanks for making that connection!
This means that the ordering of the layers is not strictly reflected in the partial ordering in the Bayes net. As an extreme example of where this goes wrong, consider the setting of a Markov chain M0 → M2 → M1 in which M2 has an arrow “back” to M1.
I think this part should not matter, so long as we're not using a do() operator anywhere? For chains specifically, we can reverse all the arrows and still get an equivalent factorization. Not sure off the top of my head how that plays with mixed-direction arrows, but at the very least we should be able to factor the sequence of nested markov blankets as an undirected chain (since each blanket mediates interactions between "earlier" and "later" blankets), and from there show that it factors as a directed chain.
Replies from: tailcalled↑ comment by tailcalled · 2023-01-15T22:58:32.668Z · LW(p) · GW(p)
Not sure off the top of my head how that plays with mixed-direction arrows,
If you have arrows M0 <- M1 -> M2, then it is also equivalent to an ordinary chain.
If you have arrows M0 -> M1 <- M2, then it becomes inequivalent, due to collider bias. Basically, if you condition on M1, then you introduce dependencies between M0 and M2 (and also everything upstream of M0 and M2).
(I actually suspect collider bias ends up mattering for certain types of abstractions, and I don't think it has been investigated how in detail.)