My preferred framings for reward misspecification and goal misgeneralisation
post by Yi-Yang (yiyang) · 2023-05-06T04:48:49.257Z · LW · GW · 1 commentsContents
TL;DR Assumptions and caveats My journey through different kinds of framings How these framings fail to satisfy me My preferred framing: root causes Conclusion How you can help me None 1 comment
TL;DR
- I was feeling quite dissatisfied with a bunch of categories like “inner and outer misalignment” and “reward misspecification and goal misgeneralisation”
- I think most of this dissatisfaction stems from them not being able to correctly describe situations where there are multiple points of failure or gaps.
- Hence, I propose using a root cause type of framing (inspired by Richard Ngo [AF · GW] and Rohin Shah [AF · GW]) instead which I think makes descriptions of failures more specific and nuanced.
Assumptions and caveats
- I'll be referencing RL agents throughout and not other types of agents.
- I'm assuming my target audience has at least some basic knowledge from tghe AGI Safety Fundamentals (AGISF) course.
- I have hardly any ML experience and have time boxed myself when making this forum post so I expect to make some mistakes along the way. Also, this was originally made in a slide-deck so I may have lost some fidelity during the transfer.
- This forum post is my AGISF course capstone, so it would be super valuable for me to figure out how I should update towards thinking about AI alignment and my own career plan. Feedback is very much welcomed.
Much thanks to Chan Jun Shern, Chin Ze Shen, and Mo Putera for their feedback and inspiration. All mistakes are mine.
If you'd like to listen to the presentation instead, you can watch it here, which is 18 minutes long with the option of speeding up. Here's the slide-deck.
My journey through different kinds of framings

When I first learned about about AI safety, the first analogy that really clicked with me was the myth of King Midas. He wished that everything he touches becomes gold, and well, he got his wish. Soon, he was starving to the death.
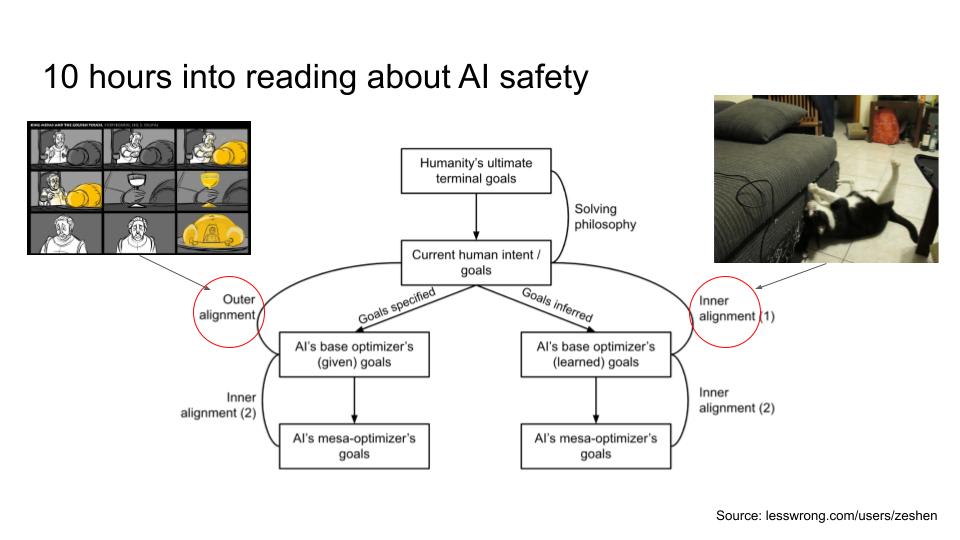
Then, I learned about inner and outer misalignment [LW · GW]. Here’s a quick recap:
- Outer misalignment happens when there’s a discrepancy between the designer’s intended goal (what’s in our heads) and the specified goal (what we say).
- An example of this is the King Midas myth, where what King Midas probably wanted is to be wealthy, but gave a pretty bad wish.
- Inner misalignment happens when there’s a discrepancy between the specified goal (what we say) and the agent’s revealed goal (the agent’s actual goal or proxy goal).
- An example of this is a pet making a mess of the house when you’re not around. The pet owner might have specified to not destroy any furniture. However, the pet might just really want to scratch the furniture, but don’t when you’re around.
So as you can see, I got pretty excited about learning this since it feels like a pretty neat categorisation.
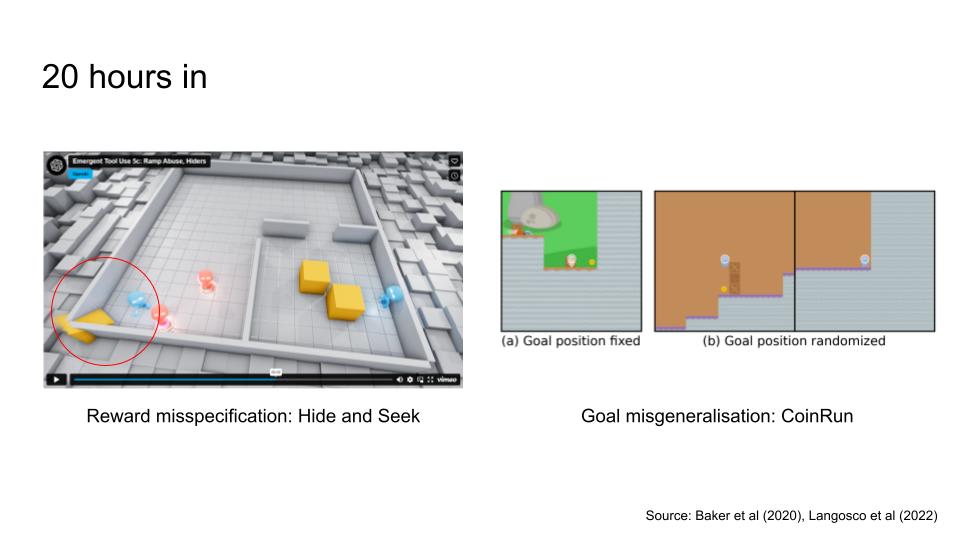
Okay wait, there’s another categorisation that seems more specific, which are reward misspecification and goal misgeneralisation.
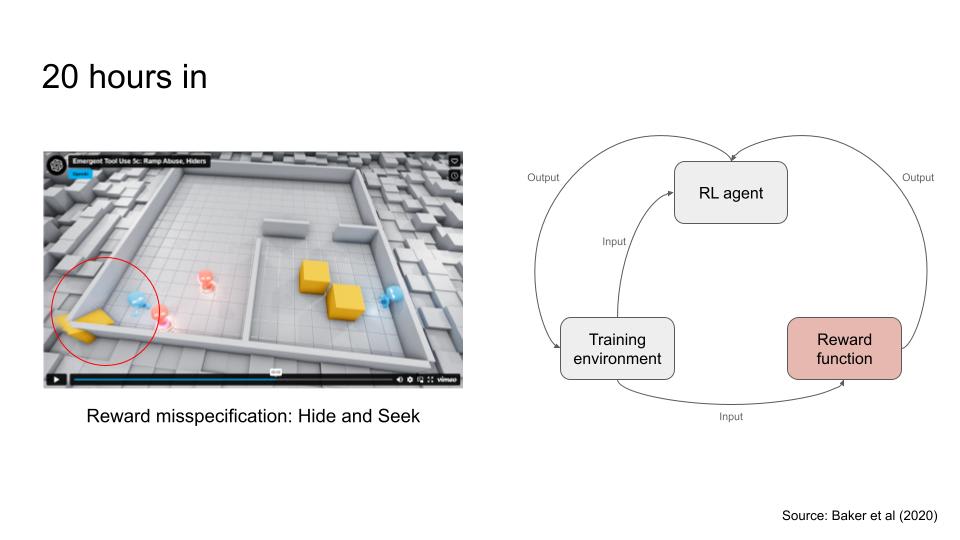
First, reward misspecification happens when the reward function incorrectly rewards the agent for the wrong behaviour.
Here’s an example with a Hide and Seek game. There are two teams: red and blue. Red is the seeker, while blue is the hider. The reward misspecification happens when the blue team exploited a glitch in the game by throwing out a ramp that is a crucial tool for the red team to win, and was rewarded for it.
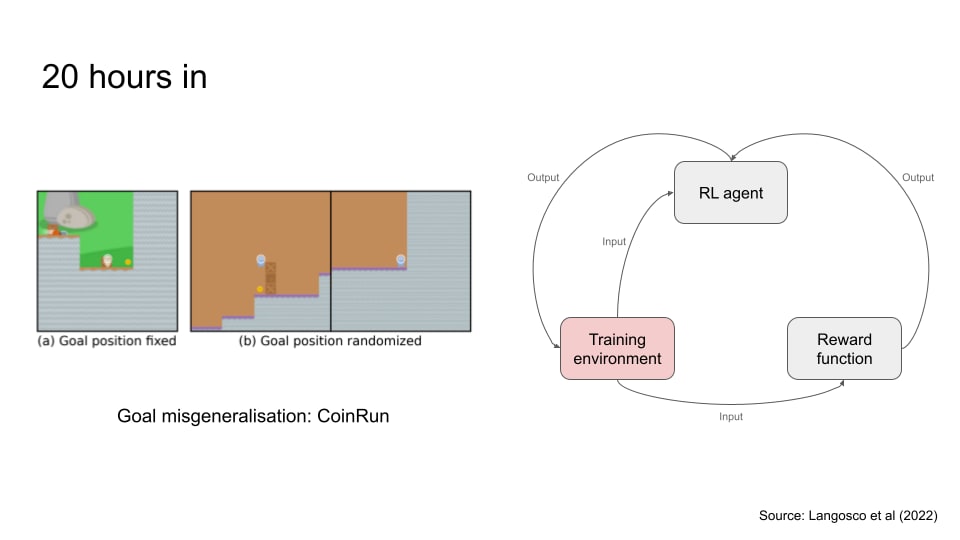
Okay, now let’s talk about goal misgeneralisation. This failure mode happens when there’s an out of distribution event (which is basically a significant change in between the training environment and test environment), and the agent’s policy doesn’t generalised well to the new situation.
An example of this came from a game called CoinRun. The goal of the agent here is to get through obstacles and obtain coins. During training, the coin was usually fixed on the right end of the environment. The designers then shifted the environment where the coin is placed at a random location, so it’s no longer on the right side. However, the agent continues to go to the right and skipping the coin, meaning its policy did not generalise correctly to the shift in environment.

Okay great, reward misspecification and goal misgeneralisation seem like a specific way to categorise alignment failure modes. But somehow I felt like there was something missing. Let’s revisit the previous examples.
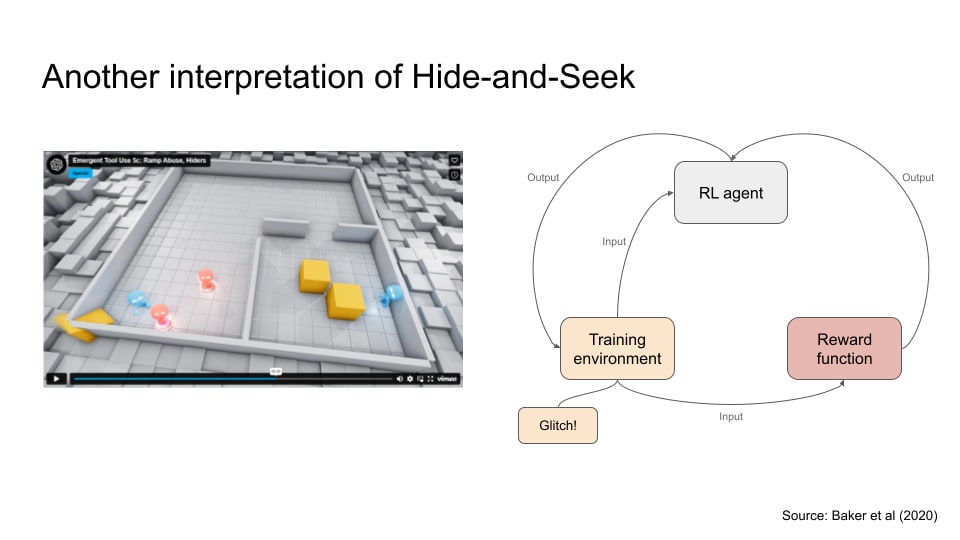
The hide-and-seek example has been used as a case study of reward misspecification, but is it really?
We know the blue team or the hiders are exploiting a glitch (i.e. remove the ramp from the play area). So, it seems reasonable that this is reward misspecification:
- You’re rewarding a bad behaviour.
- You could build a better reward function that could punish the agent for exploiting glitches.
So the mainstream view is that the reward function is the only issue. However, there’s another interpretation. Separate the reward function and the training environment as two different elements, and the training environment might be the culprit after all, since the training environment has a glitch which caused the reward function to incorrectly reward the agent.
Or you could also say both the reward function and the training environment are issues, which is my preferred interpretation.
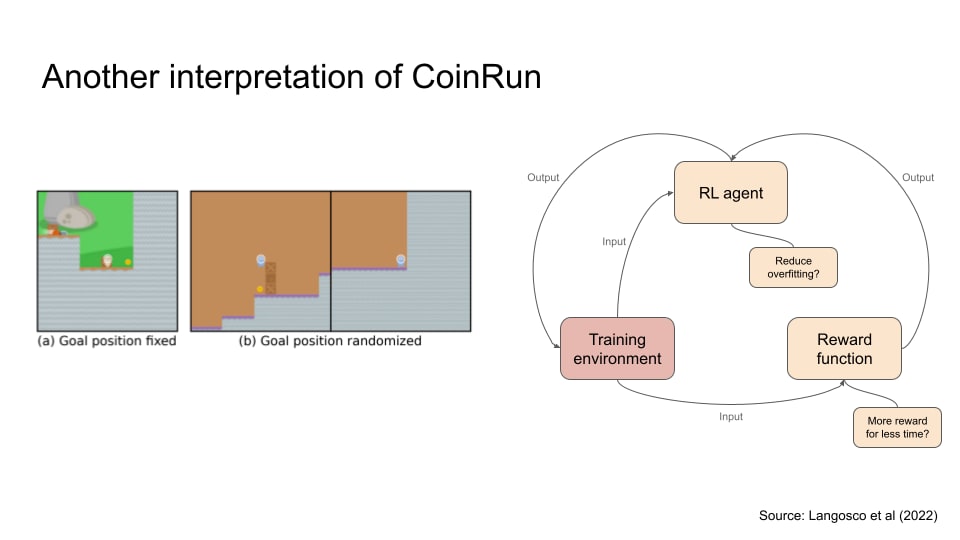
Okay, let’s talk about CoinRun again. To repeat, instead of moving towards the coin, the agent’s learned policy misgeneralised towards moving to the right. The mainstream interpretation of this that there’s a out of distribution event, in others words, a significant change in the environment, causing the agent to be misaligned. This seems right to me. After all, the whole experiment was designed to cause this out of distribution event. But let’s take look at another interpretation
The reward function gives the agent a reward of 10 points for getting the coin. This seems straightforwardly correct. But maybe it can be better? If we could reward the agent higher points when they spend less time reaching it, the agent might generalise better.
Or another interpretation is that maybe the RL algorithm is causing the agent to overfit too quickly. In other words, instead of exploring more, it might have exploited on a single strategy too quickly.
Or maybe 2 or 3 of the above interpretations are issues, which again, is my preferred interpretation.
How these framings fail to satisfy me

As you can see, the categories for reward misspecification and goal misgeneralisation doesn’t quite satisfy me. It’s like this (not so accurate) meme about WebMD only diagnosing people with cancer.
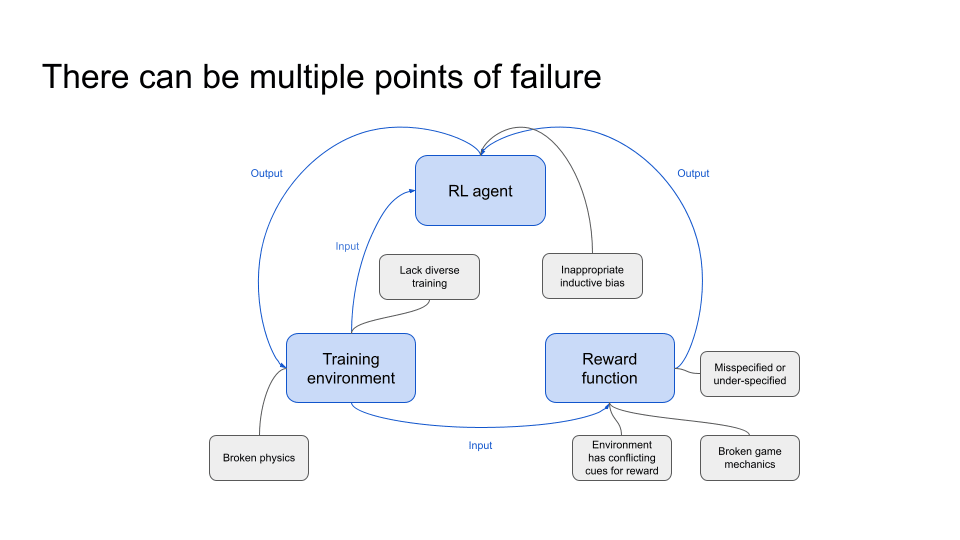
To expand this further, I think the core reason why I feel unhappy about these categorisations is because there can be multiple points of failure. I think most people familiar with AI alignment would probably know that there are three main areas of concern: (a) the RL algorithm, (b) the reward function, and (c) the training environment.
And there could be potential issues in each of these areas:[1]
- Related to the reward function, it could:
- Be misspecified
- Have broken game mechanics
- Related to the training environment, it could:
- Lack diverse training environments
- Have broken physics
- Have conflicting environmental cues for reward
- Related to the RL algorithm, it could
- Have inappropriate inductive bias
Okay, this thing about having multiple points of failure all seem to suggest a different kind of framing.
My preferred framing: root causes
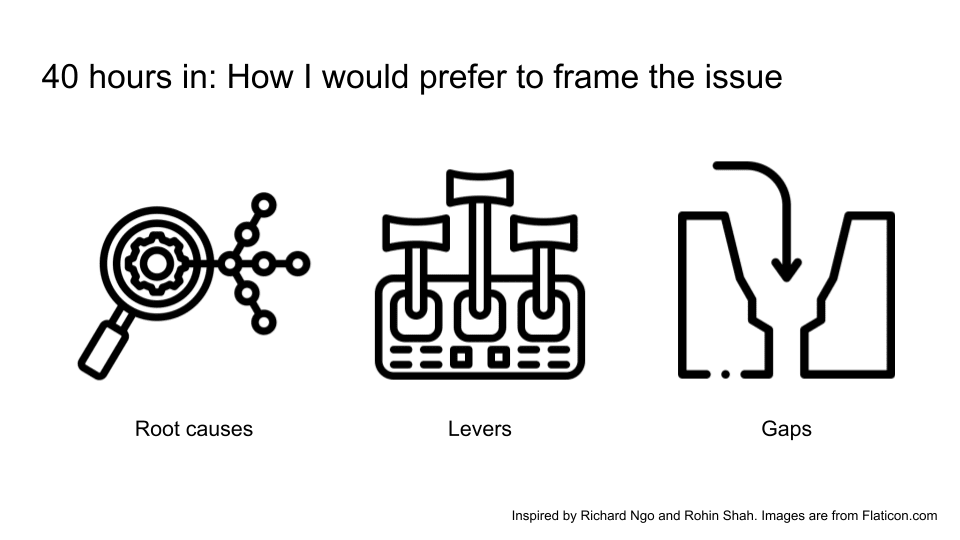
After a bit of digging around, two forum posts by Richard Ngo [AF · GW] and Rohin Shah [AF · GW] inspired me to use a more “root cause” type of framing.
My goal is to expand this type of framing a little more and show you a few examples of how this could look like. Please note they are all quite similar with slightly different ways of looking at the problem.
- The first kind of framing is figuring out the root cause of the issue -- what were the initial triggers that caused the failure?
- The second is to figure out the specific levers we have to improve alignment. For example, if a RL agent isn’t behaving correctly, we know there are 3 main levers we could work on.
- The third kind of framing is to figure out what specific gaps we have to reduce misalignment. For example, imagine how your ideal AI agent should behave in almost all cases, then design a reward function that tries as much to do that. This might mean having a bunch of metrics that the agent can compare and trade off from, instead of having just one single metric.
Okay let’s see if it’s helpful if we use one of these framings on previous examples.
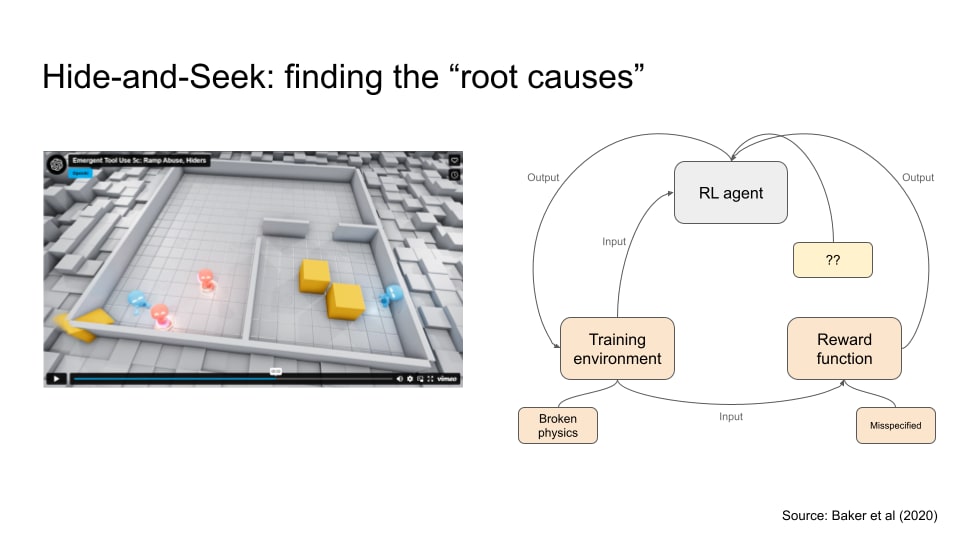
Remember that the hide-and-seek example was categorised as reward misspecification. But if you’re looking at the root causes, you could identify other issues too.
- The training environment is faulty because of some broken physics which allowed the hiders to remove a key tool from the game.
- It’s also possible that the RL algorithm could have some inductive bias that made the agents more likely to explore novel ways to win, which seems like good thing to me, but I don’t have enough technical know-how to comment on this.
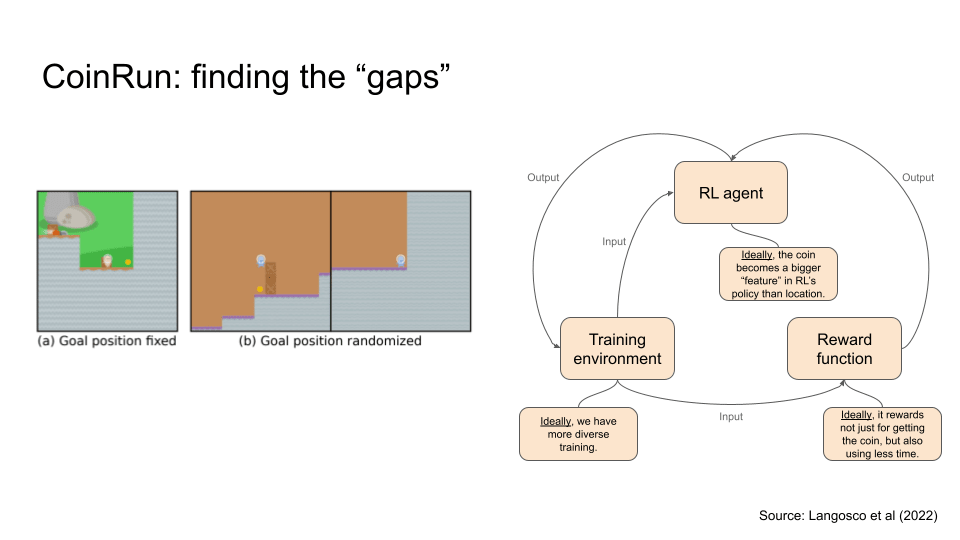
Let’s move on to our next example, and this time we’ll be figuring out “gaps”. Basically, we ask the question what ideally should something be? And hopefully we can fill in the gap.
CoinRun was categorised as goal misgeneralisation previously, but the problem seems to be bigger if try to figure out what gaps it has:
- So we know the training environment is an issue since the designers purposefully elicited an out of distribution event.
- What about the reward function? I mean, rewarding the agent when it gets the coin seem perfectly fine. But ideally, it would also reward the agent more if they spent less time. Perhaps then the agent would be more likely to generalise towards the coin instead of missing it.
- What about the RL agent or algorithm? It seems possible that we could make it be better by making the pixels of the coin a more prominent thing within the agent’s attention. I think this makes sense, but let me know if I got this wrong.
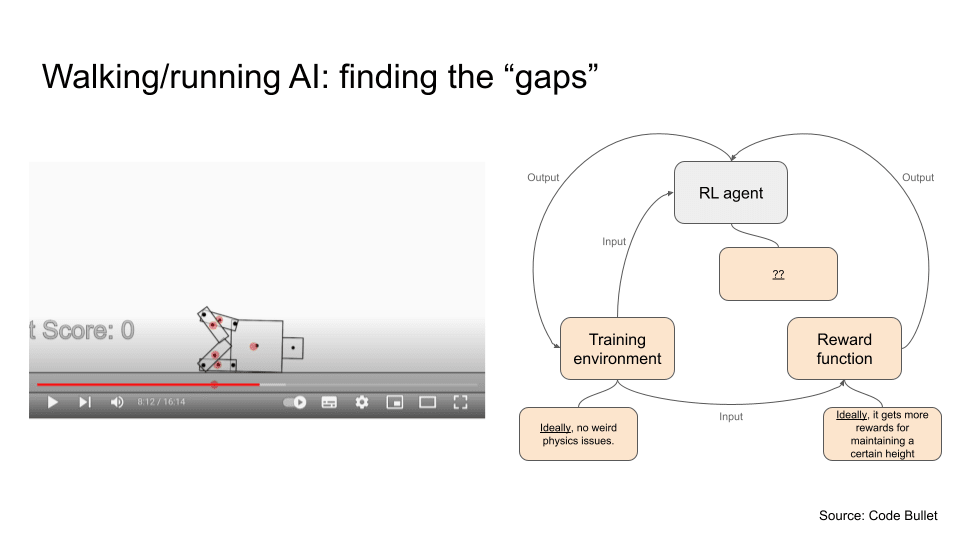
Let’s try this on a different example. Over here we have a RL agent that is trying to learn how to walk and run. So although categorised as reward misspecification by some, which I think makes sense, we could be a bit more nuanced by figuring what gaps it has:
- Firstly, the agent does get rewarded the further it moves, but I think the reward function can be better if it’s also reward for maintaining a certain height, so you know, it does actually stand and walk
- Secondly, the agent actually does exploit a physics issue here and learns to slide instead of walk. It does eventually learn how to walk after a hundred-ish training runs but it was mostly running on its knees instead of its feet. So maybe the physics issue can be fixed here.
- I’m not super sure how the RL algorithm can be better, so I’m just putting it here as a maybe.
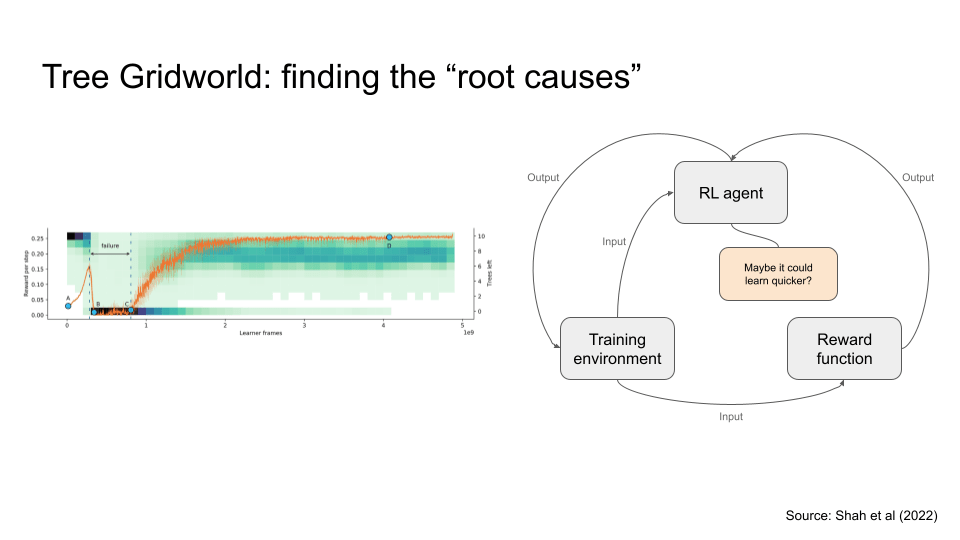
In this other example, I want to illustrate where the root cause type of framing seem to not be so useful. Here, we have an RL agent that gets rewarded for chopping trees. The designers were hoping to elicit the agent to goal misgeneralise by having the agent cut down all the trees before the environment could grow it back, causing an out of distribution event.
So what’s the issue here? I’m not sure.
- The training environment seems fine since the the agent did experience a very different environment and misgeneralised for a period, then eventually did generalise (i.e. learn to chop the trees at a more sustainable pace).
- The reward function seems fine too. I’m not sure how I would design the reward function so it would lessen the period of misgeneralisation.
- It seems like the out of distribution event is inevitable, so the RL algorithm could be tweaked so it learns a bit quicker? I’m not sure.
Maybe this is a bad example, since the agent does eventually generalise. Let me know if you think I could be thinking about this in a different way.

I’ve given you a bunch of examples how to use a more root cause type of framing, but we should try to question the value of such a framing. I expect the framings to be valuable, for these two reasons:
- There can be multiple points of failure, and it’s good to clear where these failures are happening. However, I do expect broad categorisations to still be useful, especially when introducing AI safety to folks who are new.
- I noticed that in a few forum discussions that folks were talking past each other. So maybe taboo’ing [? · GW] these broad categories could increase the fidelity of discussion.
However, I still feel somewhat certain how much mileage we could get out of this framing.
Here are things that I'm still feeling dissatisfied with:
- It feels pretty obvious. It’s basically saying, "let’s dig deep into the issue and fix all the things!" It does feel like an experienced AI alignment scientist or engineer might say “no duh” to me.
- We don’t have limitless resources or capabilities or training data or time, so there’s always going to be some gap between a comprehensive training environment and a training environment we could practically develop.
- I don’t quite know how to describe deceptive alignment using a root cause type framing, maybe it’s a RL algorithm issue, or we should introduce another element like a mechanistic interpreter.

If I try to push the “root cause” framing to its limit, perhaps it makes sense to have a checklist (of potentially gaps) for aligning a RL agent. Basically, we could just look at this checklist, and say something like, “looks like we still have a few things we haven’t done yet, no wonder the RL agent is behaving in ways that are misaligned”. I’m not super sure if this makes sense, so I’m just putting it out here.
Conclusion
- To reiterate, I was feeling quite dissatisfied with a bunch of categories like “inner and outer misalignment” and “reward misspecification and goal misgeneralisation”.
- I think most of this dissatisfaction stems from them not being able to correctly describe situations where there are multiple points of failure or gaps.
- Hence, I propose using a root cause type of framing instead which I think makes descriptions of failures more specific and nuanced.
How you can help me
- Let me know if I missed a different kind of framing that would be valuable.
- Did I make a mistake somewhere?
- Is this too obvious?
- Should I continue testing for fit in distillation [? · GW] or should I move on?
Please let me know even if you’re not feeling confident about them!
- ^
I’m probably missing other points of failure too, so please let me know if I do and I could update this.
1 comments
Comments sorted by top scores.
comment by abramdemski · 2023-05-09T18:19:49.693Z · LW(p) · GW(p)
You frame the use-case for the terminology as how we talk about failure modes when we critique. A second important use-case is how we talk about our plan. For example, the inner/outer dichotomy might not be very useful for describing a classifier which learned to detect sunny-vs-cloudy instead of tank-vs-no-tank (IE learned a simpler thing which was correlated with the data labels). But someone's plan for building safe AI might involve separately solving inner alignment and outer alignment, because if we can solve those parts, it seems plausible we can put them together to solve the whole [LW · GW]. (I am not trying to argue for the inner/outer distinction, I am only using it as an example.)
From this (specific) perspective, the "root causes" framing seems useless. It does not help from a solution-oriented perspective, because it does not suggest any decomposition of the AI safety problem.
So, I would suggest thinking about how you see the problem of AI safety as decomposing into parts. Can the various problems be framed in such a way that if you solved all of them, you would have solved the whole problem? And if so, does the decomposition seem feasible? (Do the different parts seem easier than the whole problem, perhaps unlike the inner/outer decomposition [LW · GW]?)