Levels of goals and alignment
post by zeshen · 2022-09-16T16:44:50.486Z · LW · GW · 4 commentsContents
Motivation Levels of goals Humanity’s ultimate terminal goals Current human intent / goals AI’s base goals AI’s mesa-optimizer’s goals Levels of alignment Solving philosophy Outer alignment Inner alignment (1) Inner alignment (2) The alignment problem Deceptive alignment Conclusion None 4 comments
This post was written as part of Refine [LW · GW]. Thanks to Adam Shimi, Lucas Teixeira, Linda Linsefors, and Jonathan Low for helpful feedback and comments.
Epistemic status: highly uncertain. This post reflects my understanding of the terminologies and may not reflect the general consensus of AI alignment researchers (if any).
Motivation
I have been very confused with the various terminologies of alignment e.g. ‘inner alignment’, ‘outer alignment’, ‘intent alignment’, etc for the longest time. For instance, someone might talk about a particular example of inner misalignment and I would be left wondering how the presence of a mesa-optimizer was established, only to find out much later that we were never on the same page at all.
Through many more conversations with people and reading more posts, I thought I finally had cleared this up and was able to stop asking ‘what do you mean by inner alignment’ in every conversation I was in. However, this confusion came back to bite me when I came across the terms ‘robustness’ and ‘alignment’ as being different concepts in the context of ML safety.
In this post, I attempt to clarify my understanding on the different levels of goals and alignment, as well as give examples of each type of misalignment. I expect a lot of disagreements and I welcome suggestions to and pushback.
Levels of goals
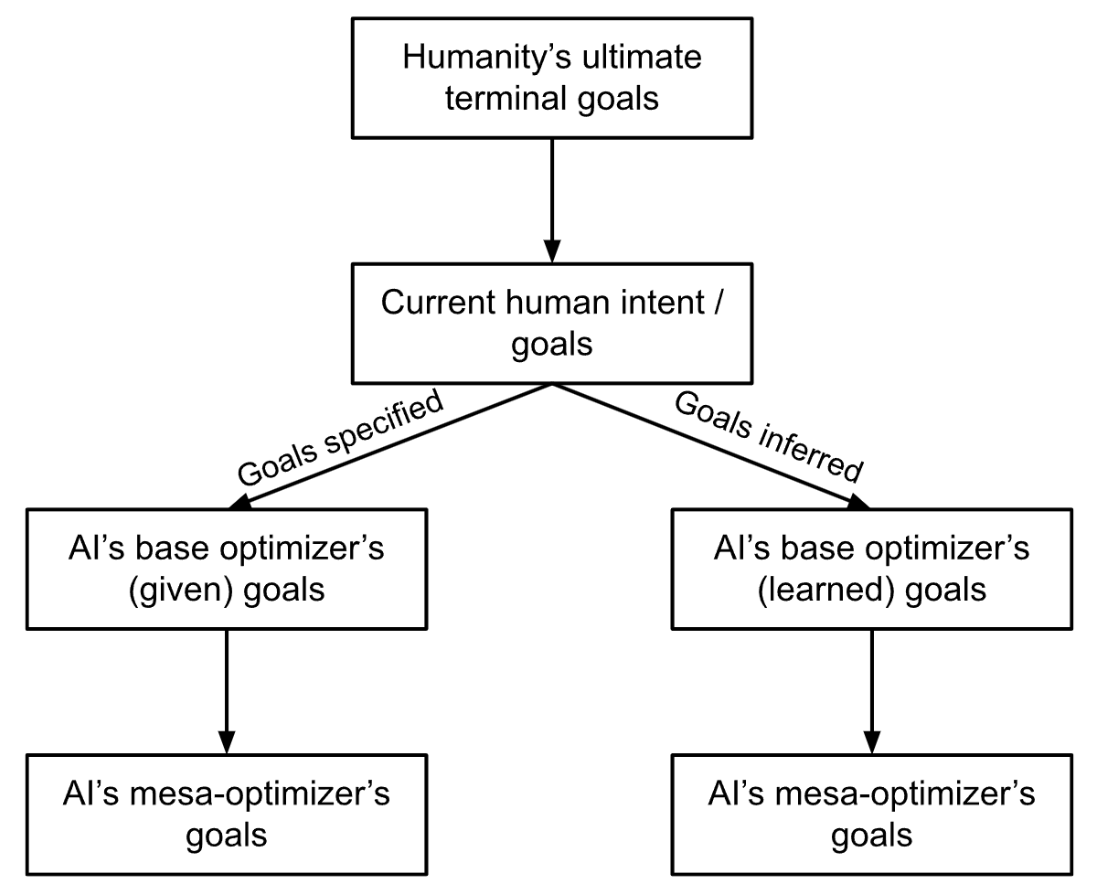
Humanity’s ultimate terminal goals
These are the ultimate goals that humanity will have, given enough time to ruminate over them. They can be thought of as our true goals after a long reflection [? · GW] or humanity’s coherent extrapolated volition [? · GW]. To moral anti-realists, these ultimate goals may not even exist. Nevertheless, there are some goals that are almost certainly closer to these hypothetical ultimate goals than others (e.g. reducing suffering is almost certainly better than increasing it).
Current human intent / goals
These are the intentions and goals of humans that are somewhat in line to our values. In other words, these include the things we want and exclude the things we don’t want (e.g. we’d like to eat when we’re hungry but not to the point of puking).
Of course, there are different levels of human goals, where some are instrumental in different ways while others are more terminal. Humans are notoriously bad at knowing what we really want, but we shall ignore these issues for now and assume there is a coherent set of goals that we want.
AI’s base goals
These are the goals that the AI pursues after, whether it is trained or programmed. They can either be explicitly specified by humans or inferred through some kind of training process.
AI’s mesa-optimizer’s goals
These are the goals of a mesa-optimizer [? · GW] which may exist under certain conditions. This will be further discussed in the next section.
Levels of alignment
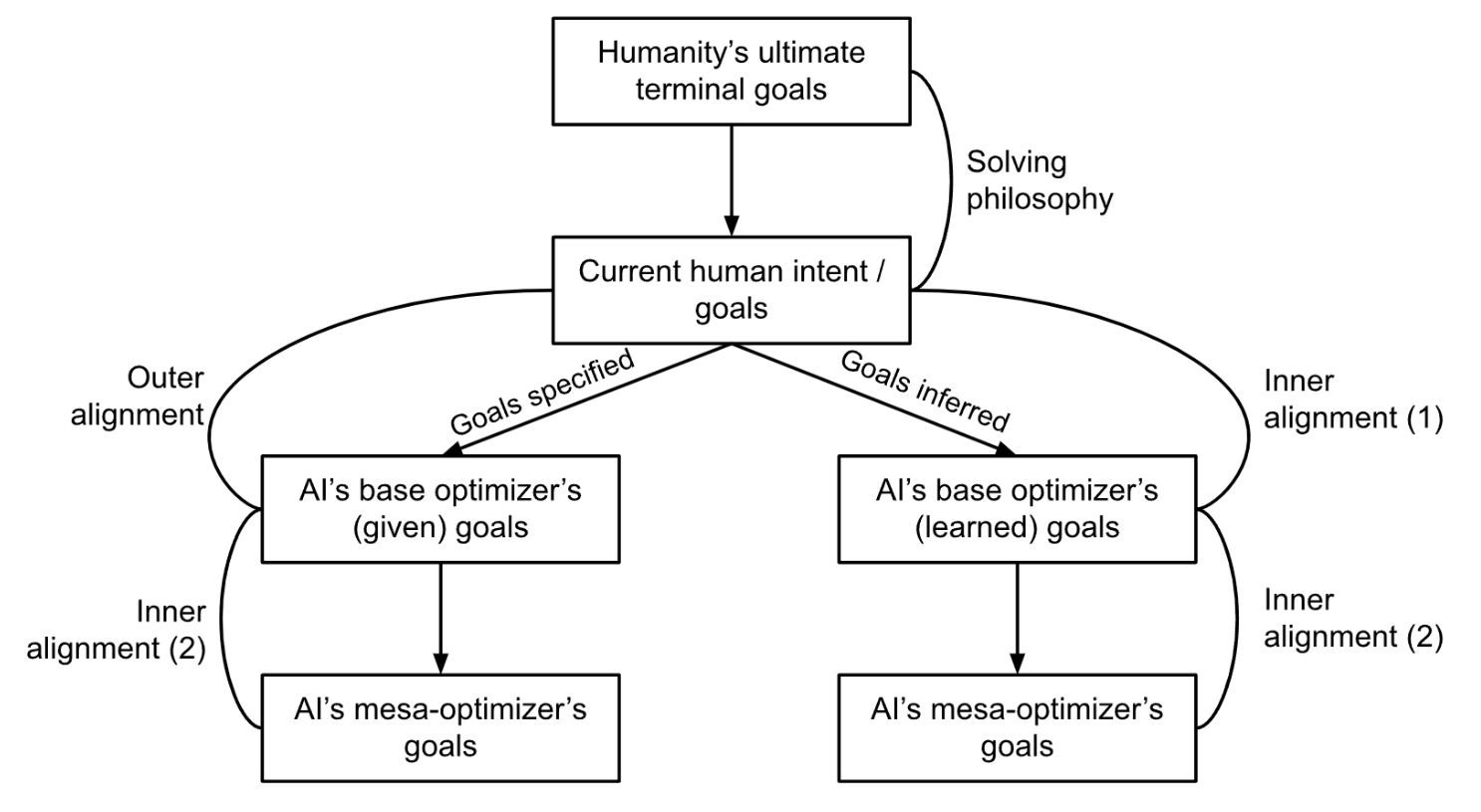
Solving philosophy
This is about aligning ‘what we currently want’ with ‘what we truly want if we had all the time and wisdom to think about it’.
An example of such a misalignment is when people in the previous centuries would want to own slaves, but we now know is morally reprehensible. A hypothetical AI fully aligned to human values at the time would probably be very effective slave-drivers.
An obvious issue with failing to solve moral philosophy is that a powerful AI fully aligned only to our current human values may lead us to some bad value lock-in [? · GW] scenarios, where it would continue to pursue presently set goals that we find morally reprehensible in the future. Proposed solutions to this problem include some form of corrigibility [? · GW], where an AI allows its goals to be modified by its human programmers. That being said, if we can have an AGI that is only aligned to what we want now, it would already be a huge win.
This misalignment may also not be relevant in a scenario where a fully aligned AI successfully pursues a goal of solving philosophy and improving humanity’s goals for us, e.g. an AGI that implements coherent extrapolated volition (CEV).
Outer alignment
Outer alignment is about correctly specifying human intent into goals given to an AI.
Outer misalignment happens when there is a misspecification of human goals with respect to our actual goals. The canonical example is the paperclip maximizer, where the paperclip factory manager specifies the goal of ‘maximizing the number of paperclips produced’ to the AI, and the AI promptly turns everything in the universe into paperclips.
The reason why outer misalignment can turn awful is because of Goodhart’s Law that leads to specification gaming. There are plenty of real world examples of specification gaming, one of the more well-known ones being the reinforcement learning agent in a boat racing game CoastRunners who went in circles to accumulate points instead of finishing the race. This is the classic scenario where the AI does what we say and not what we want.
Inner alignment (1)
The first type of inner alignment pertains to situations where the AI’s goal is not directly specified by humans but is inferred by the AI, such as in reinforcement learning environments. This empiricist approach [LW · GW] to inner alignment is about having the AI learn the right goals as we intended. Inner misalignment happens when the AI learns a proxy goal that has a different objective than our intended goal.
An example of inner misalignment was observed in the Procgen Maze environment where an AI agent (a mouse) was trained to navigate mazes to reach a piece of cheese. During training, the cheese was consistently placed at the upper right corner of the maze. The mouse was then trained to get to the piece of cheese by getting some reward for reaching it. The mouse was then deployed in different environments where the cheese was placed at random parts of the maze instead of only the upper right corner. Unsurprisingly, the mouse continued to pursue the proxy goal of “move to the upper right corner” instead of the intended goal of “move to the cheese”.
This type of inner misalignment is also commonly referred to as ‘goal misgeneralization’ or ‘objective robustness failure’, as the objective / goal of the agent does not robustly generalize when experiencing a distributional shift i.e. the deployment environment is out-of-distribution (OOD) compared to its training environment.
Inner alignment (2)
The second type of inner alignment pertains to situations where there is a mesa-optimizer. In the context of deep learning, a mesa-optimizer is simply a neural network that is implementing some optimization process which the base optimizer might find to solve its task. This mechanistic approach [LW · GW] to inner alignment is about having the mesa-optimizer pursue a goal that is aligned to that of the base optimizer. Inner misalignment happens when the mesa-optimizer’s goal differs from that of the base optimizer.
The emergence of mesa-optimizers is a theoretical possibility, and as far as I know they have yet to be observed in real world AI systems. However, as a canonical example, this type of inner misalignment has happened in the context of evolution and humans’ use of contraception. The goal of evolution (base optimizer) is to optimize for inclusive genetic fitness (IGF), and humans had developed proxy goals such as a desire for food and sex, which is perfectly aligned with the goal of evolution for most of human history. Inner misalignment happened when contraception was invented, enabling humans to achieve their goals (have sex) without achieving the goal of evolution (gene propagation). Arguably, humanity’s advancement in medicine is a bigger misalignment to evolution, as it allowed ‘unfit’ genes that would have been eliminated from evolution to continue to survive..
The alignment problem
Any kind of misalignment is bad, but they are of different natures, and some are worse than others. For instance, the misalignment between what we currently think we want versus what humanity truly wants is a philosophical problem, while the misalignment between what we want the AI to do versus what the AI wants is a technical problem. While we do not yet have solutions for both of these problems, it seems like most of the AI alignment field primarily aim to solve those of the nature of the latter one.
Deceptive alignment
Part of why the alignment problem is so hard is because misalignment may not be immediately obvious or easily detectable. This can happen when an optimizer is deceptively aligned, where it appears to pursue a goal that is aligned to our goal but turns to pursue a different goal once deployed. I conjecture that this is also a form of objective robustness failure, where the optimizer’s objective fails to generalize even within the training dataset. This happens in the following steps:
- The optimizer learns a goal in the earlier stages of training. Its proxy goal is pseudo-aligned with the initial data. Example: a mouse in a maze consistently goes to the upper right corner of the maze where the cheese always is.
- The optimizer then gets exposed to more training, where its proxy goal is no longer aligned with the data. It does not update its goals to fit the training data. Example: the mouse in the maze gets exposed to training environments where the cheese is not at the upper right corner of the maze.
- The optimizer somehow learns that it is in some kind of training environment, and it is able to maximize its reward by appearing to optimize for a different goal in order to be deployed and be able to maximize its reward later. Example: the mouse in the maze appears to go towards the cheese placed in random parts of the maze during training despite ‘wanting’ to only go to the upper right corner of the maze, because it thinks that it has a better chance of being deployed by doing so, where after deployment it will be put in many more mazes and be able to maximize the number of times it goes to the upper right corner of those mazes.
- The optimizer then gets deployed and starts to pursue a different goal than it did during training. Example: the mouse now knows that it is deployed, and proceeds to pursue its true goal by going to the upper right corner of the maze all the time.
With the above framing, it seems that deceptive alignment is caused by the failure of an objective to generalize to more data, except unlike normal inner misalignment where the objective fails to generalize from training to deployment environment, this failure occurs entirely during training.
Conclusion
In summary, the levels of alignment that should ideally be achieved, and my views on why they may or may not seem to be the key focus in the AI alignment is:
- Solving philosophy: This is a great-to-have but the implications for not solving philosophy does not seem catastrophic.
- Outer alignment: The problem with proxy gaming largely boils down to ‘goal misspecification’. Strong optimization certainly exacerbates proxy gaming and has the potential to lead to dangerous outcomes. However, it seems like present-day AIs with clearly specified goals behave more like tool AIs than agentic AIs (i.e. AIs that try to change their environment).
- Inner alignment (1): The empiricist approach largely boils down to ‘OOD failures’. Powerful systems that optimize strongly for proxy goals that fail to generalize when deployed seem dangerous. Many powerful AIs today seem to have goals that are learned instead of specified, making them susceptible to this form of inner alignment failure.
- Inner alignment (2): The mechanistic approach of inner misalignment has the potential to be dangerous if unsolved. However, as such misalignment is currently still unobserved (as far as I am aware, not necessarily good news if it is due to a lack of detection), this problem area seems less tractable.
4 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2022-09-17T05:18:47.650Z · LW(p) · GW(p)
The simulator [LW · GW] frame clashes with a lot of this. A simulator is a map that depicts possible agents in possible situations, enacting possible decisions according to possible intents, leading to possible outcomes. One of these agents seen on the map might be the one wielding the simulator as its map, in possible situations that happen to be actual. But the model determines the whole map, not just the controlling agent in actual situations, and some alignment issues (such as robustness) concern the map, not specifically the agent.
comment by Wei Dai (Wei_Dai) · 2022-09-17T01:17:49.857Z · LW(p) · GW(p)
That being said, if we can have an AGI that is only aligned to what we want now, it would already be a huge win. [...] Solving philosophy: This is a great-to-have but the implications for not solving philosophy does not seem catastrophic.
I tried to argue the opposite in the following posts. I'm curious if you've seen them and still disagree with my position.
- Two Neglected Problems in Human-AI Safety [LW · GW]
- Beyond Astronomical Waste [LW · GW]
- Morality is Scary [LW · GW]
↑ comment by zeshen · 2022-09-22T17:08:52.883Z · LW(p) · GW(p)
Your position makes sense. Part of it was just paraphrasing (what seems to me as) the 'consensus view' that preventing AIs from wiping us out is much more urgent / important than preventing AIs from keeping us alive in a far-from-ideal state.
comment by Emrik (Emrik North) · 2022-09-17T07:30:47.669Z · LW(p) · GW(p)
This is excellent and personally helpfwl. "Alignment" decconfusion/taxonomy can be extremely helpfwl because it lets us try to problem-solve individual parts more directly (without compromise [AF · GW]). It's also a form of problem-factoring that lets us coordinate our 'parallel tree search threads' (i.e. different researchers) more effectively.