An Introduction to SAEs and their Variants for Mech Interp
post by Adam Newgas (BorisTheBrave) · 2025-04-19T14:09:31.198Z · LW · GW · 0 commentsContents
Sparse Autoencoders What is the Point of SAEs Circuits SAE Issues Shrinkage Feature Splitting And Absorption Faithfulness SAE Variants ReLU Gated JumpReLU TopK BatchTopK Switch Tokenized End to End Meta Matryoshka Archetypal P-Annealing MDL Transcoders and Crosscoders Other Related Things Other Sparse Decompositions Autointerp Patchscope Stage-Wise Model Diffing Useful References None No comments
I aim to cover a lot of ground, but only briefly. Click through the links for more detailed explanations.
Several of the techniques here see general use outside of interpretability. My definitions/references lean towards how they specifically apply to Mechanistic Interpretability
Sparse Dictionary Learning describes any ML technique that aims to find a set of “atoms” that can be sparsely combined to represent a dataset. These techniques have become popular in Mechanistic Interpretability as a way of analysing the space of activations in a LLM. Most commonly this has been achieved using a particular kind of dictionary learning called Sparse Autoencoders.
Sparse Autoencoders
Sparse Autoencoders (SAEs) focus on reconstructing the activations of a single layer of the model. As the name suggests, SAEs are autoencoders models. They are trained by feeding in the activations from the original model, and optimising their ability to reconstruct the full activations from their latents. The training process also aims for sparsity of the SAE latent activations.
The motivation for SAEs is based on the observation that LLMs often seem to store sparse features in “superposition”, i.e. there are many linear directions in the activation space that correspond to important features, but they overlap considerably. SAEs try to reconstruct those original features and structure.
SAEs were introduced for metchanistic interpretability in Sparse Autoencoders Find Highly Interpretable Features in Language Models and used a 2 layer encoder/decoder model:
Here x is the activations of the original model layer, the SAE latents, and the reconstruction of by the SAE. is much higher dimension than , but is forced to be sparse, so it still acts as a bottleneck. The SAE[1] is trained with a reconstruction loss and a sparsity loss .
Each entry in the SAE latent corresponds to a vector direction from rows of the decoder matrix . These directions are analgous to the feature directions of superposition. For this reason, the latents of the SAE are often called “SAE Features”.
What is the Point of SAEs
SAEs, in principle, are an unsupervised way to find linear directions in the activation space of a model that stand for distinct "concepts".
Being unsupervised means they can be trained once on a dataset, then you get a full set of learnt SAE features to be reused for many different purposes. This has led to projects like Neuronpedia that let you browse for interesting features.
The feature directions can be used for steering (like any other set of activation vectors). They can serve as linear probes and are useful for debugging.
Circuits
In the early days, it was hoped that neurons were monosemantic, and we could find circuits by tracing which neurons fed into which other ones. We know that's not plausible now, but SAEs recapture some of that dream.
Because SAEs map activations to themselves, you can splice a trained SAE into a model without significantly changing its behaviour[2]. We can treat the SAE latent activations as the objects of interest and skip the original neurons. SAE latent activations are sparse and (assumedly) monosemantic, so they are amenable to circuit techniques like ablation and activation patching.
For example, ARENA describes finding the gradients between SAE features for two different layers.
Note: Recent research in circuit detection tends to favour transcoders and crosscoders over SAEs.
SAE Issues
SAEs have seen a bit of a boom and bust cycle. There's a number of shortcomings that have become apparent has people have tried to do applied interpretability with SAEs. Many of the SAE variants were created to address these issues.
Shrinkage
Recall the basic SAE definition:
has much higher dimension than , so the goal is to train the model so that only a few entries of are active (non-zero) at any given time. The number of non-zeros is often called the norm of , i.e. .
To get a sparse , SAEs are trained with an extra loss term, a sparsity loss of . The use of norm on causes the optimizer to drive many of these values to 0, and the sparsity coefficient controls the strength of this drive.
But is an imperfect proxy for . In particular, a larger magnitude vector will have a larger loss, which means that our choice of loss will cause training to prefer smaller vectors, even if they result in a worse reconstruction. This problem is called shrinkage or feature supression [LW · GW].
Feature Splitting And Absorption
I previously described SAE features as an attempt to recreate an underlying set of features that the model might be using. But there are cases, easily reproducible in toy models, where the features found by the SAE systematically differ from the natural features, reducing their interpretability.
Feature splitting is a problem where if you increase the size of the SAE latent dimension, some of the features the smaller SAE found will be replaced with a cluster of more specific ones, losing the broad concepts in the process.
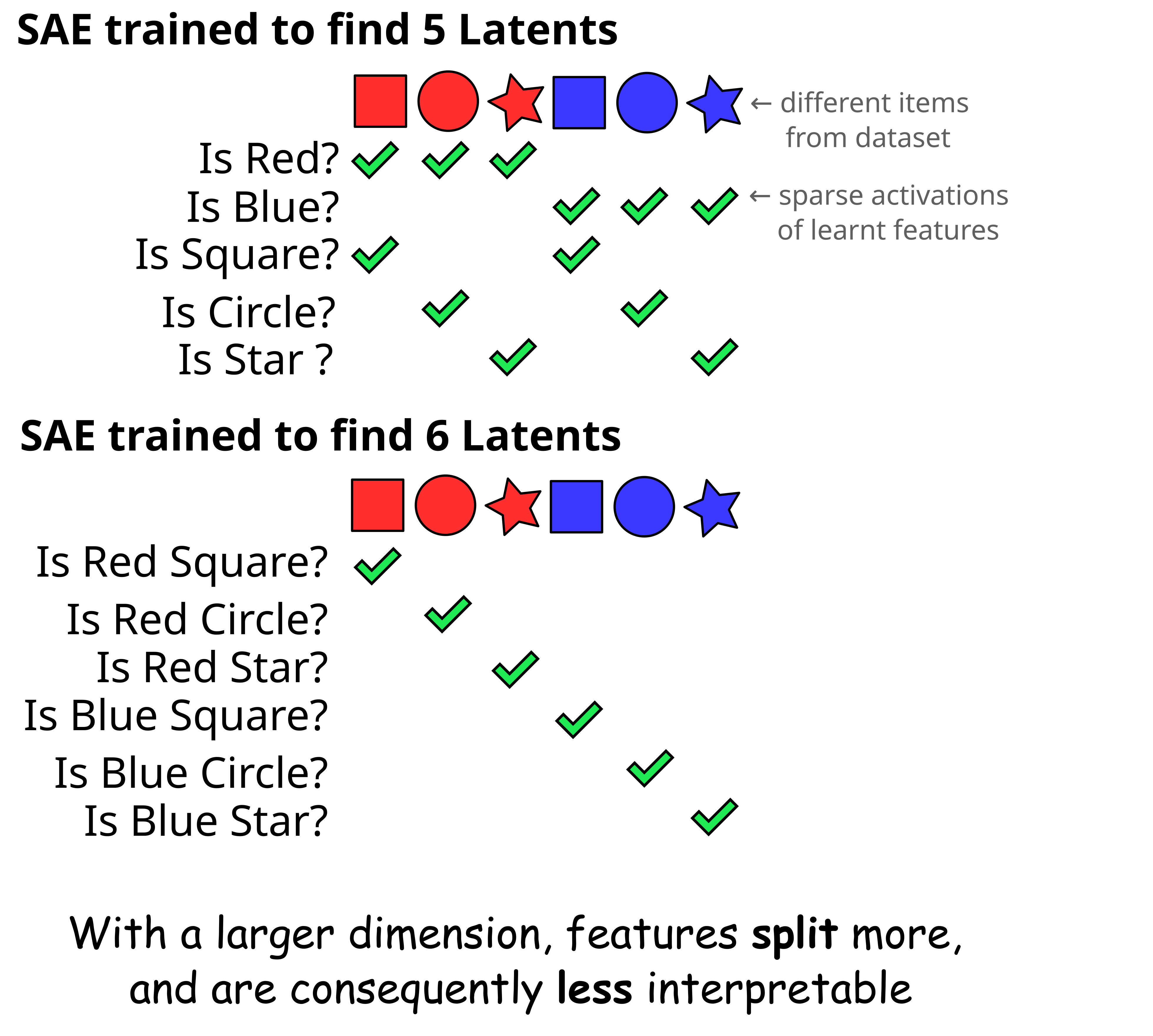
Feature Absorption [LW · GW] is a similar phenomenon. We'd consider "elephant" and "words starting with E" to be natural concepts. But "elephant" itself starts with E, so it always co-occurs, which is bad for feature sparsity. The optimization process therefore prefers to use features that correspond to "elephant" and "words starting with E except elephant", as this activates more sparsely, while still having everything representable. This can lead to a balkanization of broad features.
More broadly, SAEs can be criticized as treating latents as a bag of features, with no structure between them, of which splitting and absorption are two consequences.
Faithfulness
The empirical evidence for SAEs is somewhat mixed. While the features found definitely have some useful qualities, it's not at all clear that what they report corresponds to something intrinsic to the original model.
Some articles on this I can't concisely summarize:
- Do sparse autoencoders find "true features"? [LW · GW]
- SAE feature geometry is outside the superposition hypothesis [AF · GW]
- Standard SAEs Might Be Incoherent A Choosing Problem & A "Concise" Solution [LW · GW]
- Sparse Autoencoders Do Not Find Canonical Units of Analysis
Some futher evidence: SAEs tend to be unstable - the features found can vary between training runs, and are sensitive to the specific training dataset [LW · GW].
Ultimately, many practitioners have found that for many tasks, SAEs underperform alternative approaches. Recently, Google DeepMind announced they were deprioritizing SAE research [AF · GW] in light of this.
Despite this, there are quite a few SAE variants that improve quality, so it’s hard to conclusively rule them out. And their unsupervised nature makes them appropriate in some places where other techniques cannot be used. But overall, the community is starting to look beyond SAEs to Transcoders and Crosscoders.
SAE Variants
SAEs find features, but they have some issues. It's not that clear that the structure being found is either faithful to the model internals or practically useful. A number of variants have been proposed to fix things.
| Variant | Makes changes to | Aims to improve | ||||
| Encoder | Decoder | Reconstr-uction Loss | Sparsity Loss | Training | ||
| Gated | ✔️ | ✔️ | on gate | Shrinkage | ||
| JumpReLU | ✔️ | ✔️ | Shrinkage | |||
| TopK | ✔️ | None | Shrinkage | |||
| BatchTopK | ✔️ | None | Shrinkage | |||
| Switch | ✔️ | Performance | ||||
| Tokenized | ✔️ | Feature Quality | ||||
| End to End | ✔️ | ✔️ | Feature Quality | |||
| Meta | N/A | |||||
| Matryoshka | ✔️ | Feature Quality | ||||
| Archetypal | ✔️ | Feature Quality | ||||
| P-Annealing | ✔️ | Shrinkage | ||||
| MDL | ✔️ | Feature Quality | ||||
ReLU
ReLU SAEs are the first form of SAEs used for mech interp.
They have a simple 1-layer encoder/decoder with an ReLU nonlinearity.
This model is trained with a reconstruction loss and a sparsity loss .
Variants below are described in terms of their key differences from this baseline.
First introduced in 2023 with Sparse Autoencoders Find Highly Interpretable Features in Language Models.
Gated
Gated SAEs add an additional encoder term which switches off a given neuron entirely.
where is the pointwise Heavisde step function and is elementwise multiplication.
sparsity loss is only applied to the term, which avoids it causing shrinkage to the magnitude of .
There is also some value in allowing binary activation of the latents, as this matches our intuitions for features better.
ARENA Tutorial. Introduced in April 2024 Improving Dictionary Learning with Gated
Sparse Autoencoders.
JumpReLU
JumpReLU's swap out the normal ReLU activation for a function with a binary step.
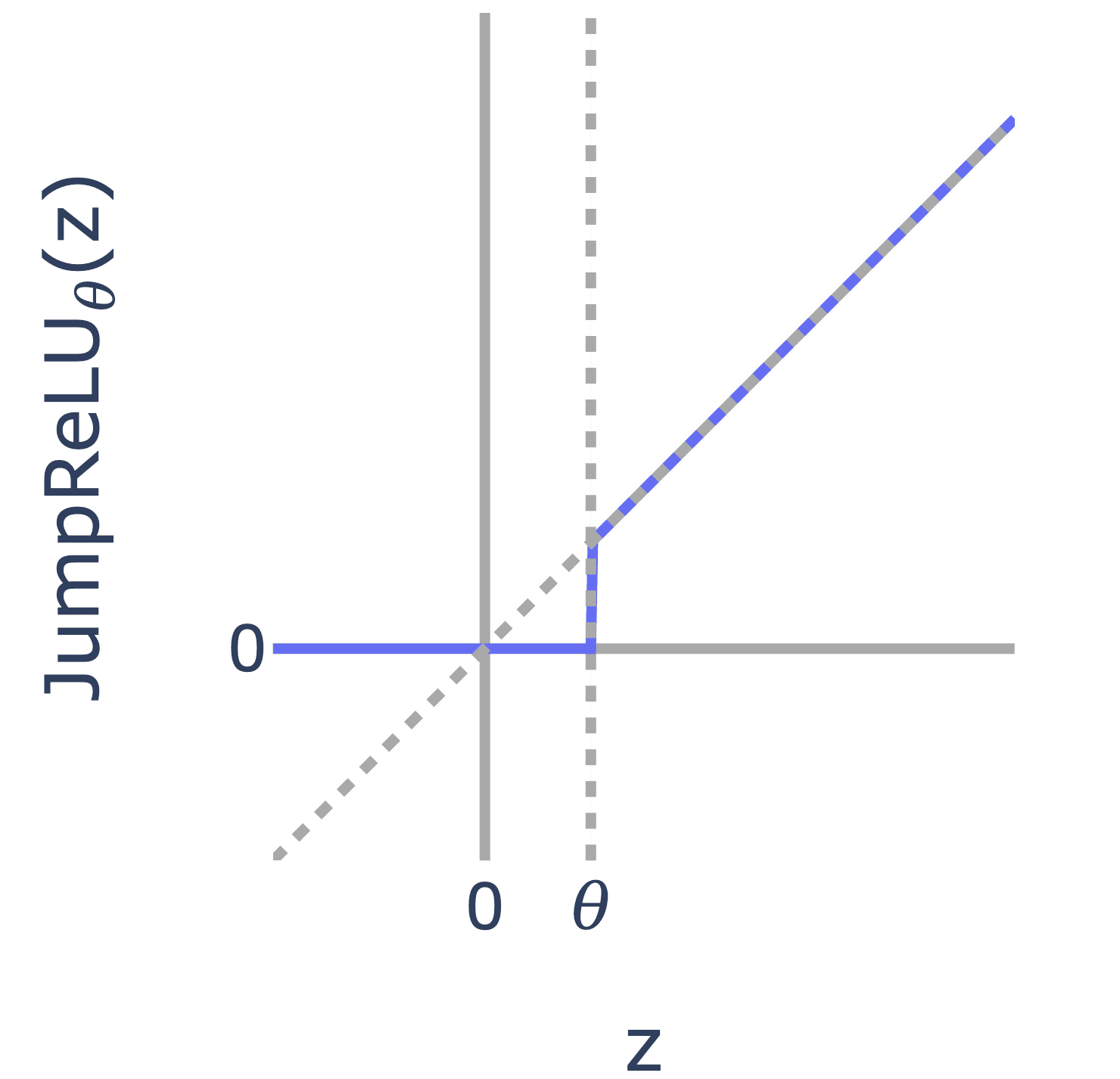
They also define sparsity loss in terms of norm (i.e. the count of non-zero elements)[3].
Like Gated SAEs, the intuition is to reduce sparsity (by not using norms) and allow a binary activation response.
Both the loss and activation function are non-differentiable, so a technique called straight-through-estimators is used during backpropagation.
ARENA Tutorial. Introduced in Aug 2024 with Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders.
TopK
Replaces with the function, which finds the largest elements of the encoded vector and zeros out the rest. This means no sparsity penalty is needed, avoiding shrinkage. It's also handy that the exact sparsity of the SAE latents can be set, rather than tuning the loss. Most later SAE variants tend to build on TopK.
Introduced in Jun 2024 Scaling and evaluating sparse autoencoders
BatchTopK
Similar to TopK, this zeros out all but a few elements of . But elements are evaluated across the entire batch, allowing some samples to have fewer than non-zeros, and others having more. This gives a bit more flexibility on exactly how many features are active during training. Training also collects the average minimum activation value in the batch. During inference, this value is used as a JumpReLU style threshold.
Introduced in July 2024 BatchTopK Sparse Autoencoders
Switch
Similar to Mixture of Experts and Switch Transformers, a Switch SAE subdivides the encoder into smaller experts, plus a routing network to decide which expert to use for a given input.
This gives performance improvements which are particularly valuable as the encoder, being dense, is usually the bottleneck for training SAEs
Introduced in Oct 2024 Efficient Dictionary Learning with Switch Sparse Autoencoders
Tokenized
Tokenized SAEs add an additional term to the decoder based on the current token.
This is motivated by the observation that trained SAEs tend to devote much of their limited latent space to learning activations that are highly related to the current token. This simple task is a waste of SAE's power, and it's better to handle that separately so the SAE can focus on more complex representation.
Introduced in Aug 2024 Tokenized SAEs: Infusing per-token biases. [LW · GW]
End to End
End to End SAE training involves running the full original model, with SAE architecture is inserted to replace the original activation with the reconstructed activation. Loss is given by KL divergence between the original logits and the newly computed logits.
This is slower but means the SAE is optimized to reconstruct in a way that prioritizes what actually matters to the rest of the model.
Introduced in May 2024, Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning [LW · GW]
Meta
Meta SAEs train a second SAE using rows sampled from the an underlying SAE's decoder matrix. The meta SAE is trained for a smaller dictionary size than the underlying.
The idea is to uncover the structure relating different SAE latents. That can help combat Feature Splitting and generally removes the limitation that SAEs tend to treat latents as an bag of unrelated features.
Introduced in Aug 2024, Showing SAE Latents Are Not Atomic Using Meta-SAEs [LW · GW].
Matryoshka
Matryoshka SAEs are inspired by Matryoshka Representation Learning. The idea is that you can slice the encoder/decoder matrices of an SAE to get a smaller SAE that shares a subset of the SAE features. A nested group of these SAEs are simultaneously trained, which in effect privileges the innermost features. This means the inner features are shielded from feature splitting, but the outer featuers still exist to pick up the slack.
An equivalent formulation is to consider a single SAE, but where the reconstruction loss penalizes some features more than others.
Introduced in Dec 2024, Learning Multi-Level Features with Matryoshka SAEs [LW · GW] and simultaneously Matryoshka Sparse Autoencoders [LW · GW]
Archetypal
Archetypal SAE constrains the SAE features to the convex hull of input activations. This improves stability - the similarity of found sae features between independently trained runs.
To make this performant, the input dataset is reduced by k-means to get the points of the hull, and a relaxation term is added to compensate for the size reduction.
Introduced in Feb 2025, Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
P-Annealing
P-Annealing replaces the sparsity loss with , where is slowly varied over the course of training from 1 to approaching 0. This gives the model a chance to train at high (where the gradient landscape is easier to train on), then closes in on which is the measure we actually care about, but not trainable.
Introduced in Aug 2024, Evaluating Sparse Autoencoders with Board Game Models [LW · GW]
MDL
Minimal Description Length SAEs (MDL-SAEs) proposes that rather than mimimizing the sparsity of the latents, the number of bits required to encode the latents should be used. This gives a more holistic view of choice of hyperparameters such as sparsity, dimension size and quantization. The paper performs a sweep over hyperparameters looking for the lowest description length SAE that is within an error tolerance.
Introduced in Aug 2024, Interpretability as Compression: Reconsidering SAE Explanations of Neural Activations with MDL-SAEs
Transcoders and Crosscoders
So far, we've looked at SAEs that take the activations for a single layer, and try and reconstruct them. The variants mess around with the internal details, but the target reconstruction has always been the same.
But the same broad structure works with other forms of input and output. There's been an explosion of these sorts of variants recently, which I hope to cover in more detail in a later article, but there are two fundamental changes that are the thrust of the area.
In short, transcoders are models encode activations from one layer, but decode to reconstruct activations from a later layer. This enables the transcoder to model not just activation space, but the functional behaviour of a layer, naturally leading to interpretable circuits. Strictly speaking transcoders cannot be described as "auto" encoders, but they are usually lumped in as they are technically so similar.
On the other hand, crosscoders pull multiple activations together into the input/output. For example, you could concatenate the activations from several levels. By learning encoder/decoders for multiple layers while minimizing their mutual sparsity, the crosscoder is able to form a 1:1 correspondence between different feature spaces.
This has many uses:
- It lets you view consecutive MLP layers as if they were one broad layer, which seems to be true for many cases
- It lets you easily identify features that persist in the residual stream, even though layers tend to rotate them for some reason.
- You can run crosscoders that get activations from multiple models, giving a way to translate activations or identify commonalities.
Other Related Things
Other Sparse Decompositions
SAEs are appealing because they are trained with the same ML techniques that models themselves use. But there are plenty of other techniques that have a similar goal in mind including Non-negative Matrix Factorization, Sparse-PCA.
Autointerp
Autointerp is a technique for using an LLM to analyse a SAE feature and give a short human readable text attempting to explain its usage in samples that strongly activate the feature. It's very handy for labelling and searching for specific SAE features.
Patchscope
Patchscope techniques involve getting an instruction-tuned LLM to explain itself, with a activations patched in from elsewhere.
For SAEs, patchscoping is an alternative to autointerp. You'd generate a completion of a text like "What is the meaning of ? The meaning of is", and then find the tokens for , and replace the activations at that token with the SAE feature you want to explain. For some features, this can give a directly generated explanation.
Self-explaining SAE features [LW · GW]
Stage-Wise Model Diffing
Stage-Wise Model Diffing (SWMD) is a tool for finding SAE features that are particularly relevant to a finetuning procedure.
If two models are very close, like a base model and a fine tune) then the SAE features are likely very close. SWMD exploits this by creating a a SAE for a fine-tuned model by starting with an SAE for a base model, and then finetune it it for the new model / new data.
Like crosscoders, this yields SAE features that can be directly translated across models, but with much simpler training. Typically, most SAE features are unchanged, and a few show much larger changes, which allows you to isolate SAE features relevant to the fine tuning.
SWMD then enhances the specificity of this technique by doing the procedure twice, with a slightly different finetune procedure. Any feature that changes in both finetunes is even more likely to to be relevant.
Useful References
Tutorials:
Useful libraries:
- SAELens - this library builds SAEs on Tranformerlens models. It has decent example tutorials, so it's particularly convenient for inspecting and hooking. It supports a relatively small set of architectures, but has a good number of SAEs pretrained for different models.
- dictionary_learning - this library builds SAEs on nnsight models. It supports a bit wider feature set, but isn't as ergonomic to use. It has limited support for reading SAEs trained by SAELens.
- sparsify - this library builds SAEs on huggingface transformers. It's minimally featured, but aims to support very large models efficiently.
- crosscode - built on Tranformerlens models, aims to support a wide variety of SAEs, crosscoders, transcoders and training techniques, and lets you mix and match features quite a bit. Like sparsify, activations can be computed on the fly
Neuronpedia maintains a large collection of pretrained SAEs, and has a nice dashboard for exploring specific SAE Features.
- ^
Sometimes tied weights are used, . The community seems to have settled that this is a bad idea: Two latents that have very similar decoded directions might still want to have quite different encoders, so they can be well disambiguated and not always be active together.
- ^
Or you can add "error nodes" that represent the difference of reconstruction from the original activation, and then the splice is fully compatible with the original model.
- ^
Anthropic's implementation uses a tanh loss instead.
0 comments
Comments sorted by top scores.