Taste & Shaping
post by CFAR!Duncan (CFAR 2017) · 2022-07-10T05:50:14.416Z · LW · GW · 1 commentsContents
The power of hyperbole Case study: the paycheck and the parking ticket Parking Ticket Paycheck Resolving model conflicts Taste: an Inner Simulator output Taste & Shaping—Further Resources None 1 comment
Author's note: while it does not belong in the handbook proper, Duncan Sabien's essay Goodhart's Imperius [LW · GW] is very close to (and partially derived from) the content in this chapter, and is a good extension or follow-up.
Epistemic status: Mixed
Many of the concepts presented in Taste & Shaping (such as operant conditioning, hyperbolic discounting, and theories of intrinsic vs. extrinsic motivation) are all well-known and well-researched. Similarly, the problem the unit seeks to address (of experiencing an emotional disconnect between actions and goals) is widely known and discussed. There is some academic support for the efficacy of priming and narrative reframings, and strong anecdotal support (but no formal research) for the overall conceptual framework.

English uses the word “want” to mean both the declarative, persistent desire to achieve a long-term goal, and also the immediate, visceral desire to satisfy an in-the-moment urge. That’s how we end up saying sentences like “I want to exercise, but I don’t want to exercise...know what I mean?”
Part of the reason that we don’t want to exercise, in the moment (or that we don’t want to work on page 37 of our dissertation, or that we don’t want to call up our parents even though it’s been a while, or that we don’t want to look at our work email backlog, or any number of other things) has to do with emotional valence.
Objects, actions, and experiences often carry with them a sort of aggregated positive-negative or approach-avoid rating, which we at CFAR casually refer to as a “yuck” or a “yum.” Consider, for instance:
- The sound that a laptop makes when it falls on a hard, concrete floor
- The feelings evoked by the “pinwheel of death” on an Apple computer
- Your emotional reaction to the sound you typically use as your alarm
- The sight of flashing lights in your rear view mirror
For many people, the sound of a falling laptop is actually painful in some hard-to-define way—it’s as though the sound is somehow intrinsically bad, just as the pinwheel of death is fundamentally frustrating. On an empirical, logical level, it’s clear that these associations were picked up after the fact— many people grow to hate their alarm clock sound over time; few people choose an unpleasant sound to begin with.
But on an emotional level, the yucks and yums can feel inherent and essential. We want to exercise, because exercise (and health and attractiveness and capability) are all very yummy—they’re all attractive qualities that create desire and motivation.
Exhaustion, though? And sweat? And aching joints and burning muscles and gasping for breath and feeling smelly and sticky and uncomfortable? For many people, the component pieces of this very yummy concept are icky, ugh-y, and more or less repulsive. Yuck.

This is problematic, because motivation often speaks the more immediate and emotional language of System 1. When we want to do something in the eat-a-bunch-of-cake sense, we don’t usually feel like we’re spending willpower or using up motivation or “making” ourselves follow through. Following our immediate sense of “yum” is like being in freefall—the default state is forward movement, and it takes some sort of active effort to put on the brakes.
In contrast, many of our more ambitious goals (like earning a postgraduate degree) require a large number of more-or-less difficult, more-or-less arbitrary, and more-or-less thankless steps, few of which are intrinsically desirable on their own. We want the end goal, but we have to consciously marshal our resources in order to take steps toward it, fighting against “yuck” factors much of the way.
People often power through these yuck factors through methods like watching inspiring videos, soliciting support from peers, and setting up incentive/reward/reinforcement structures to get themselves over the rough patches. A much better system, though (we posit) is one in which our emotional valences are aligned—in which every individual step has the same sort of feel or flavor as the end goal, and thus we want, in the moment, to do the things that will actually help us get what we want, in the long term.
The internal double crux technique, which is something of a sequel to this section,[1] is a concrete algorithm for achieving exactly that, while maintaining a focus on having true beliefs. In this section, though, we’re going to focus on the nuts and bolts of the machine that makes IDC work—as with TAPs, it helps to understand what’s already going on, before attempting to tinker.
The power of hyperbole
Generally speaking, things that seem yummy or attractive seem so because they align with some goal. We like foods we find delicious, and people whose presence we enjoy, and things that grant us greater power and flexibility (like stacks of money). Conversely, if you feel that a particular thing is “intrinsically” unpleasant, it’s potentially useful to interpret that feeling—tentatively—as a sign that you have a model in your head somewhere that that thing is harming one of your goals.
This is fairly obvious in cases like the dropped laptop or the flashing lights in the rearview mirror, where goals like “avoid breaking valuable tools” and “avoid breaking the law and getting tickets” are fairly clear-cut. It’s somewhat fuzzier in cases like exercise, where we often discount or ignore goals like “conserve energy” and “avoid discomfort.”
(You may find this part obvious, but for many people, it's hard to notice that there might be some valid or worthwhile goal underlying the hesitation. People often identify with one goal (such as working out and eating right) while "othering" or otherwise disavowing other goals (such as not-being-tired or eating all the Oreos). In part, this is because personal and cultural narratives tend to paint some goals as virtuous and worthy, and others as shameful or signs-of-weakness or simply "not a good look.")
But by following the “yuck” to its root, we can often clarify implicit goals that were in conflict with our larger aims, and make better plans as a result. For instance, if you notice that you’re tending to avoid a particular coworker, that might be the trigger that causes you to realize that they tend to subtly put you down, or always add difficult tasks to your to-do list, or simply cause you to burn more social energy than you have to spare.
It’s important to look for the causal structure, because by generating the yuck or the yum, our brains are not simply tagging various objects and actions in our environment—they’re actually influencing our behavior, through a kind of feedback reinforcement loop. Where our causal models are good, this kind of loop serves us well. But where they’re inaccurate or inappropriate, it can condition us into unhelpful habits.
Most people are familiar with the idea that conditioning shapes behavior—that by rewarding or punishing various actions (or removing rewards or punishments), we can make those actions more or less likely.
Imagine that you’d like to train a dog to step on a particular tile on the floor. You’re unlikely to get good results by waiting for the dog to randomly happen upon the correct spot; instead, you’ll probably want to use the process of shaping.
First, you’ll give the dog a treat for being in the same quadrant as the tile. Then, once it reliably stays within that quadrant, you’ll stop rewarding it, except when it’s in the “tic-tac-toe board” of the nine closest tiles. Once it reliably stays there, you’ll change the game again, this time only rewarding actually stepping on the chosen target, and soon enough, the dog will know to go straight to that spot any time it’s let into the room.
Shaping is extremely powerful—for instance, B.F. Skinner once successfully used it to train pigeons to play specific tunes on a toy piano, first reinforcing proximity to the piano, then touching it, then playing any note, then a note near the first note, then only the first note, etc.
But in order for it to work, there are a few preconditions that must be met. The reinforcement must be clear (whether it’s constant or intermittent, it must be for a specific thing, not a handful of different or variable things), and it must arrive close to the behavior.
Imagine automating the dog-training process by putting pressure sensors in the floor—whenever the dog steps on a tile we’d like to reward it for, it triggers a mechanism that delivers a treat. Would you expect better results if the delivery took ten hours, ten minutes, ten seconds, or a tenth of a second?
Research has shown that the length of the delay between a behavior and its reward has a disproportionately large effect—if you double the size or intensity of the reward, but also make the delay twice as long, the overall impact that it has on behavior drops. Similarly, if you cut the delay in half, and deliver the reward twice as quickly, then the training effect will be greater even if the treat is only half as big.
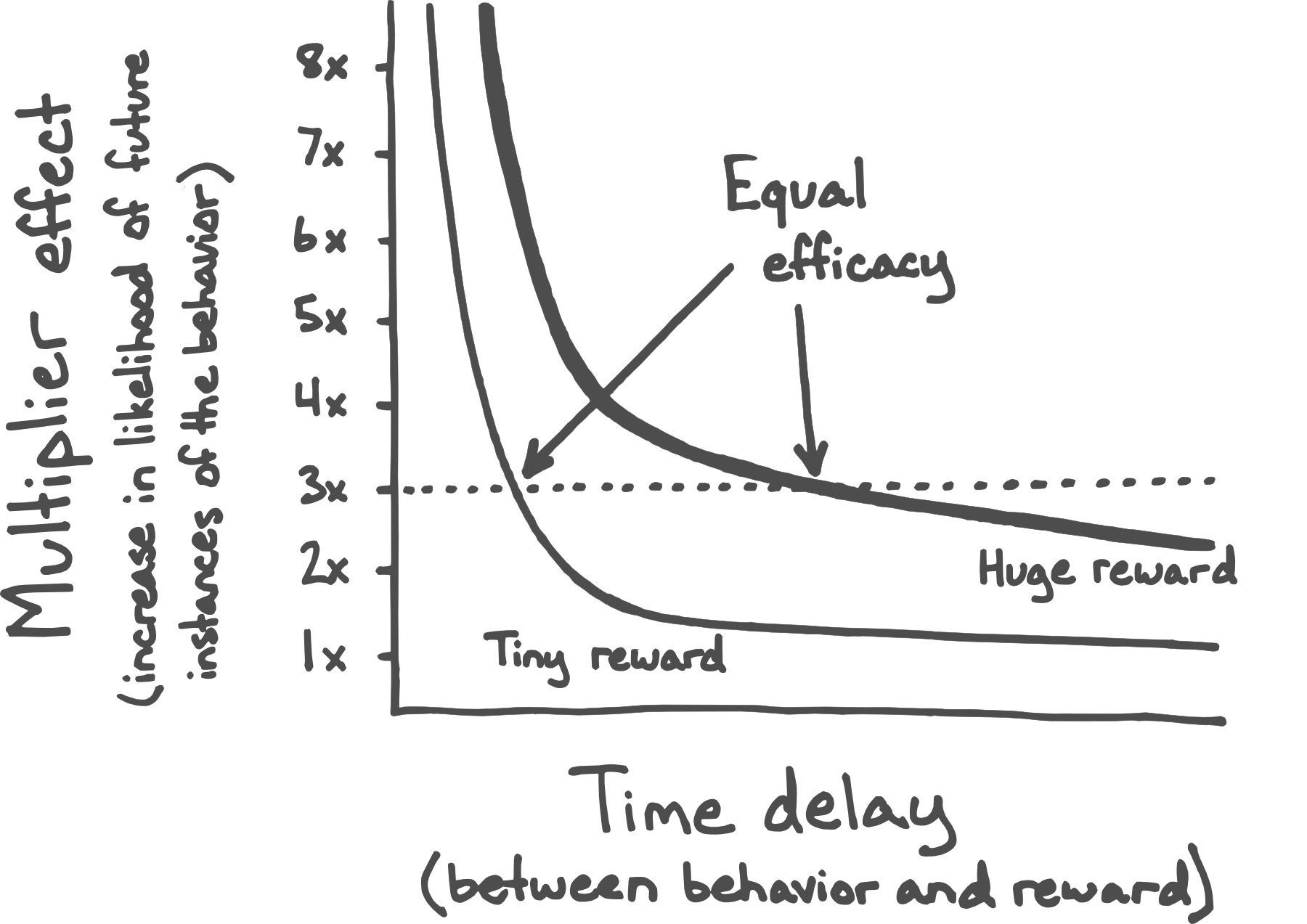
This effect is called temporal or hyperbolic discounting, and it’s a critical part of how conditioning works. For instance, it’s a partial explanation for why we eat foods that are delicious-but-unhealthy (such as chips or candy or cheeseburgers) even when we feel physically worse afterward. The reward of a delicious taste sensation is immediate, and so the behavior is reinforced despite the much larger distress that may follow after a delay.
A partial explanation for this effect can be found in thinking about the computational difficulty of linking together a cause and its effect, absent some kind of explicit model. Picture a dog's behaviors as a series of tick marks along a timeline, as below:
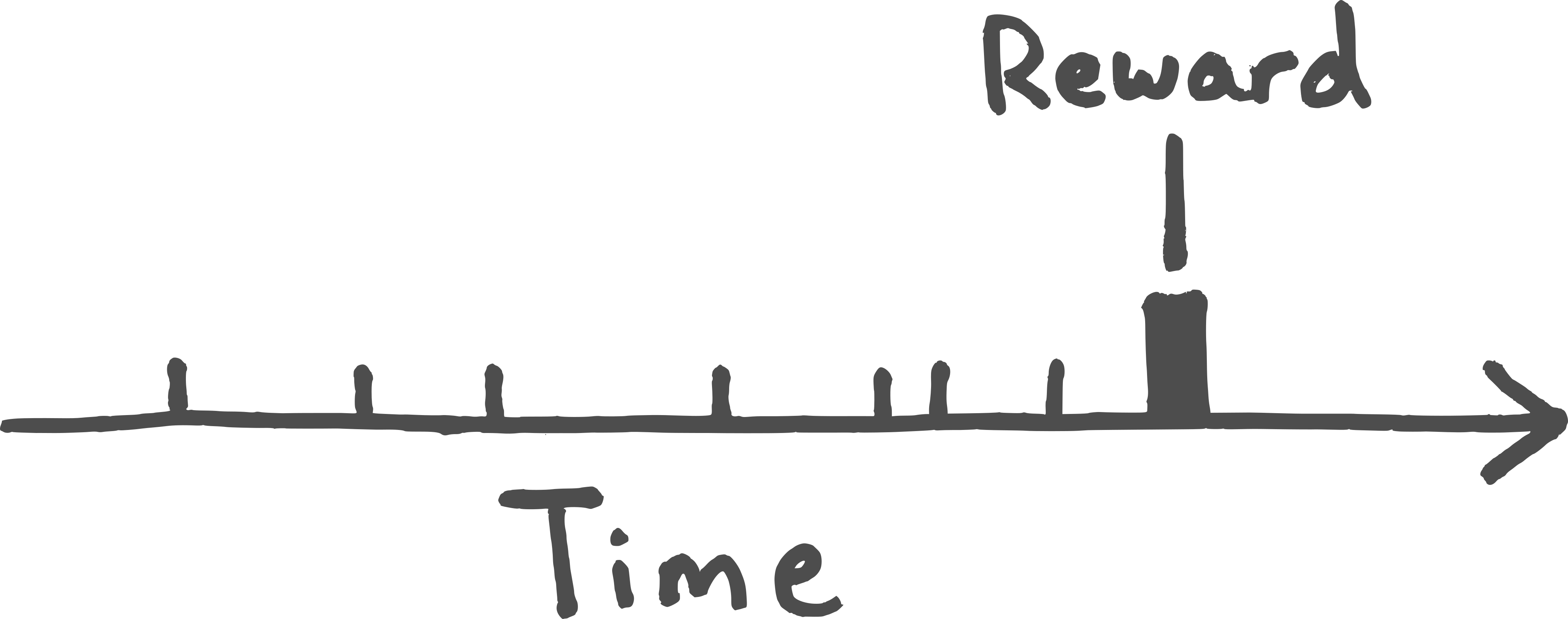
When the reward appears, the dog's brain immediately sets out to try to recreate whatever preconditions led to that reward, starting with the most recent actions under its direct control.
Did it happen because I did this? asks the dog's brain, implicitly. Or maybe because I did that?

It doesn't take long at all before the range of possible factors becomes too large for the dog's brain to manage, and so it (essentially) gives up.
Humans can do a little bit better than dogs, since humans do have explicit models, and can consider factors that are distant in time and action space. But System 2 is just a thin layer on top of our core System 1 operating system, and many of the System 1 rules apply to humans nearly as strongly as they do to dogs.
Hyperbolic discounting has powerful implications for how we should approach deliberate attempts to train behavior, whether in ourselves or in others.
First, it implies that there is almost always significant value to be gained from shortening the delay between the action and its consequence. This is why dog trainers often first associate a clicking sound with reward, and then use the click-plus-treat as a training tool, rather than tossing treats by themselves—the difference between the tenth-of-a-second delay for a click and the half-of-a-second delay for a treat has a large impact on the efficiency and efficacy of the reinforcement.
Second, it implies that—given a short enough delay—even extremely small consequences can have outsized effects on the shape of our behavior. This is important, because it means that even something as fleeting or ephemeral as a momentary yuck or yum can play a pivotal role in changing the way you view and interact with the world.
Case study: the paycheck and the parking ticket
Consider the following two scenarios:
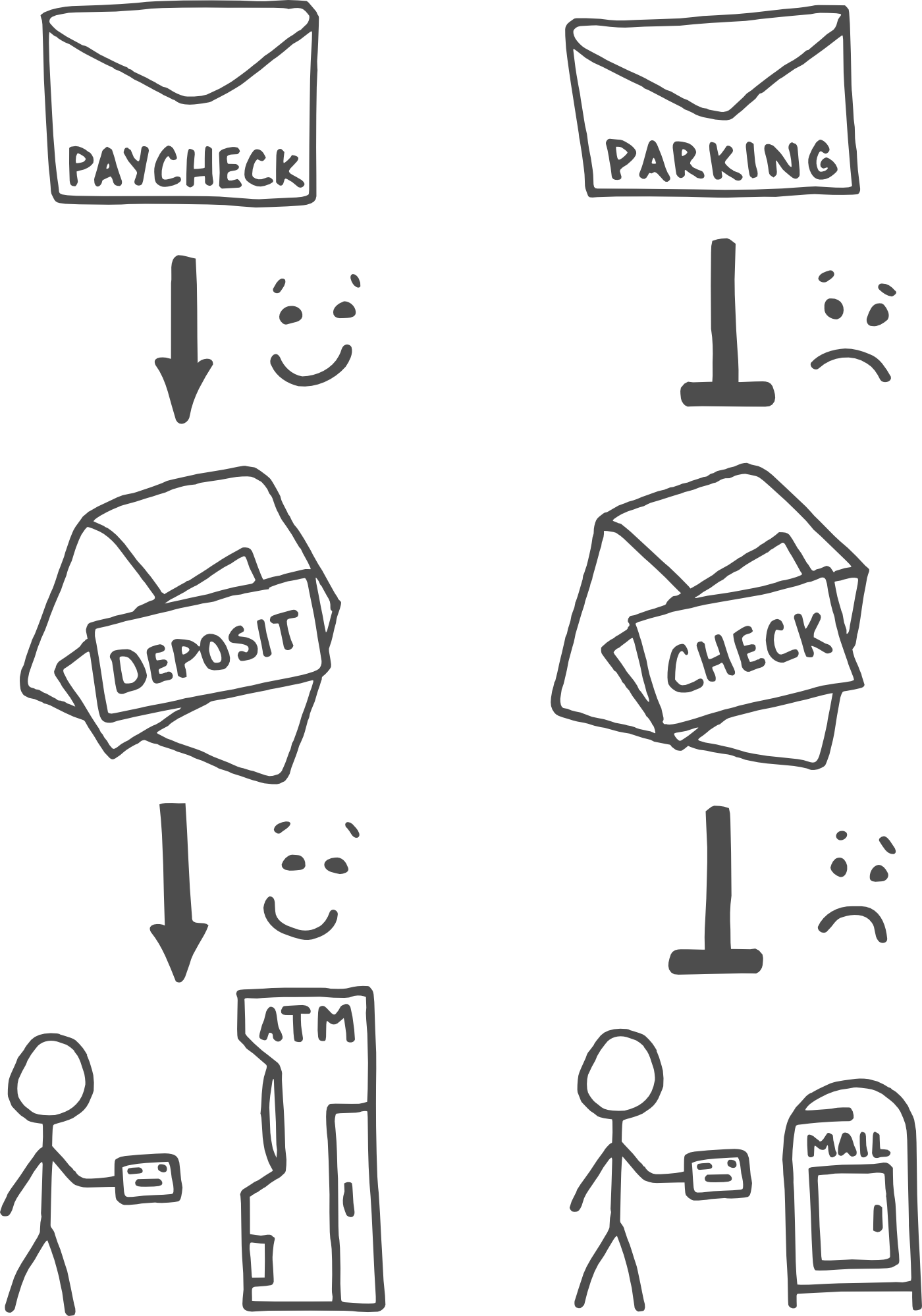
- You’re leaving your fourth errand on your way to your fifth errand, and you notice a parking ticket tucked under your windshield wiper. The ticket is for $40, with an additional $110 penalty that will come into effect if the fine isn't paid within sixty days. You slide the ticket into its envelope, go on about your day, and, upon returning home, drop it onto the “to-do” pile on your desk.
- You’re coming home from work, and you check the mailbox. There are four junk magazines—you throw those away—and an envelope containing a paycheck for $110, from a company you did some contract work for last week. The paycheck expires in sixty days, so you drop the envelope onto the “to-do” pile on your desk and head for the kitchen.
For some people, the next few scenes of these two situations play out identically. But for many of us, a quick inner simulator check reveals two very different sets of expectations:
Parking Ticket Notice the envelope on the desk; feel a sort of yucky “ow!” sensation Feel an urge to avoid the envelope; set it to the side and reach for the next item on the stack Notice the envelope again a little later and feel a second “ow!” sensation; set it in a different pile where you won’t forget it but also won’t have to keep looking at it Realize weeks later that you’ve been procrastinating and feel yet another “ow!” sensation; make yourself get out your checkbook so that you won’t have to pay the extra fee, despite feeling the whole time that you’ve failed at your goal of “money in the bank” | Paycheck Notice the envelope on the desk; feel a yummy “ka-ching!” sensation Feel an urge to open the envelope; tear it open and get a second “ka-ching!” as you see the check inside Feel an urge to open your checkbook and fill out a deposit slip; get yet another “ka-ching!” as you put the check and the slip into your pocket Notice the ATM for your bank on your way to work the next day; feel an urge to pull over and deposit the check; get one final “ka-ching!” sensation, coupled with a feeling that you’ve fulfilled your goal of “money in the bank” |
In a certain light, these two stories make no sense together. After all, from a denotative, System 2 standpoint, the two situations are practically identical—they’re both envelopes containing slips of paper which, when combined with a slip of paper from your checkbook and a small addition to your list of errands, will result in you having an extra $110 in your bank account, that you otherwise will not have.
But the envelopes also carry implicit, System 1 connotations. Parking tickets are bad/painful/yucky, and paychecks are good/pleasant/yummy, regardless of whether or not they have similar effects on your overall bank balance. If you imagine having a sort of inner emotional dashboard filled with progress meters, motivation gauges, and like-dislike indicators, then the former would be represented by redlines, falling needles, and flashing lights, while the latter would be the equivalent of a full tank and no problems.
The fact that our brains work this way is super helpful in the paycheck case, where the positive emotional valence associated with the piece of paper provides us with lots of “free” motivation to take steps toward [money in the bank]. We look at the envelope and consider opening it, and our implicit model says that’s progress toward your goal! and provides us with a spike of dopamine to reward the thought and encourage us to act on it.
But in the case of the ticket, it’s an active hindrance—the ticket is “lose money” flavored, and feels like anti-progress, and as a result, our implicit model sends us lurching away. At best, we don’t feel particularly motivated to take the next step, and at worst, we find ourselves actively averse.
The problem is that our implicit models can be inaccurate—for instance, they may not account for the fact that looking at, thinking about, and dealing with this painful envelope full of anti-utility is, in fact, helpful to our goals in the long run. If those implicit models can be updated—if they can be taught to understand and take into account the broader picture (say, by mentally reframing the situation as one in which you’ve already lost $150 to the parking fine, but have an envelope containing a $110 rebate) then they’ll stop making us feel conflicted and averse, and instead make us feel eager and motivated.
Resolving model conflicts
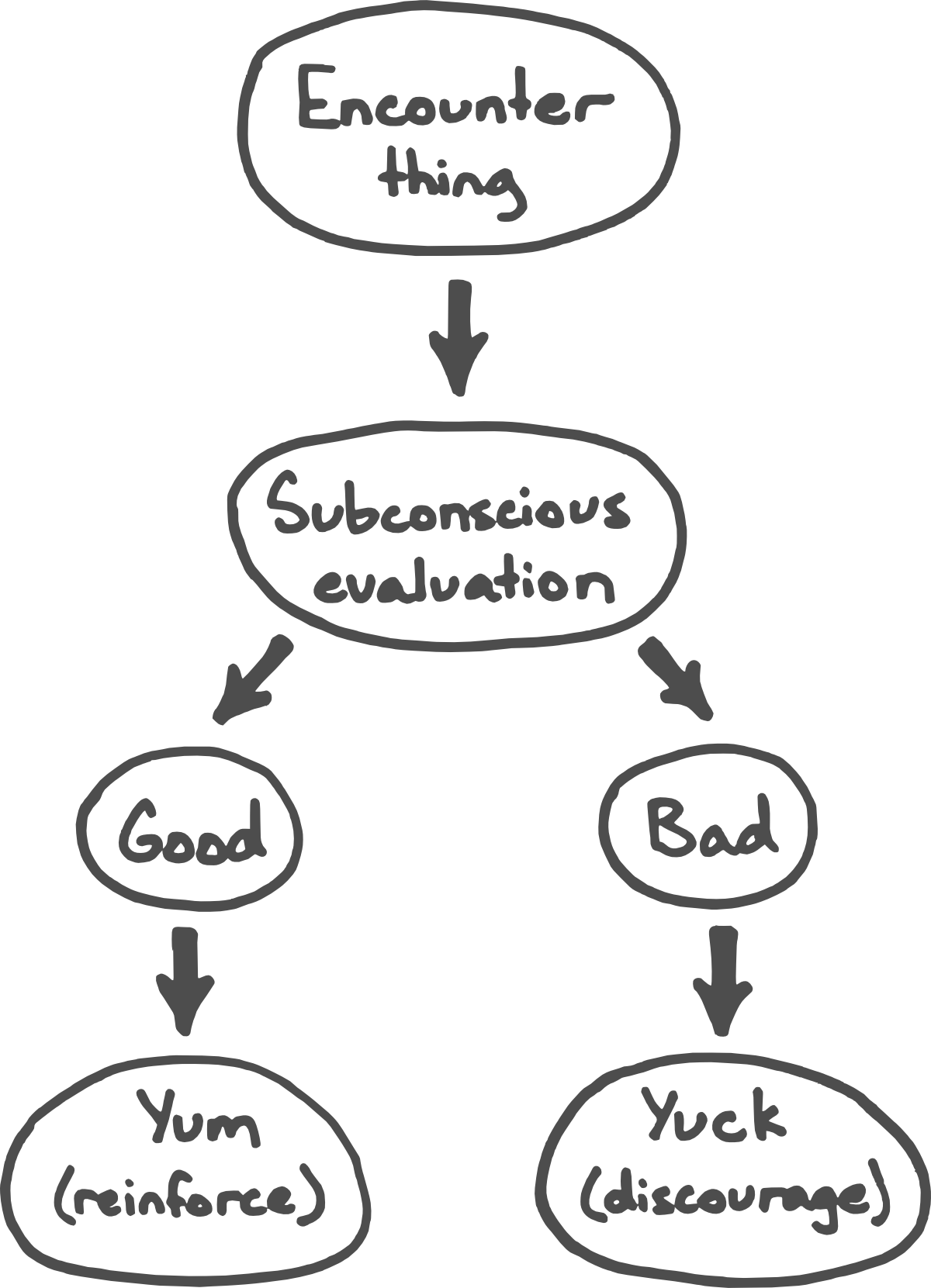
With these two pieces—the “karma scores” provided by your System 1, and an understanding of the power of hyperbolic discounting, we’re most of the way toward an understanding of how our brains train themselves. The process, at its core, is simple:
Consider what this model has to say about the following situations:
- A mother feels like her grown child doesn’t call often enough, and so when her child finally does call, she starts the conversation with “I haven’t heard from you in weeks! Why don’t you call more often!?”
- A junior executive is stressed about his ability to handle his workload, and so every time he realizes he’s made a mistake, he thinks Stupid! and berates himself for carelessness.
- A student is trying to be more diligent about her schoolwork, so she places a jellybean at the end of every paragraph on the pages she needs to read, as encouragement to keep up the pace.
The next time the person in the first example thinks about calling their mother (in this case, the “thing” being encountered is the thought “I should call Mom”), their brain will check their implicit models and come up with “bad!” because of the unpleasant negative reinforcement at the start of the previous conversation—they’ve learned that calling Mom doesn’t generate progress toward the goal of feeling good. The next time the junior executive finds himself in a position to look for or recognize a mistake, his brain may shy away, too, for similar reasons.
(This is upstream of the common advice to reward yourself for noticing your mistakes, rather than leaping straight to self-recrimination. If punishment teaches the brain to avoid doing whatever you just did, then the lesson the brain will actually learn is "don't raise awareness of mistakes to conscious attention," not "don't make that mistake again." The punishment has a much stronger conditioning effect on the more recent behavior!)

The student in the third example experienced reward, not punishment, so she’s going to do more of what she was doing before, but she’s made a relevance error à la turbocharging—she’s associated “good” with getting to the end of a paragraph instead of with understanding the content, and so her urges are going to be aligned with the goal of [feeling diligent], but not necessarily with the goal of [doing better at school].
None of these incidents are going to be very powerful on their own, of course—the junior executive is not going to suddenly become incapable of noticing his mistakes. But the combination of feedback loops and shaping can gradually lead each of these people further and further away from the behaviors they want-to-want, especially if the reinforcement is as immediate and consistent as a trigger-action pattern that goes notice mistake → punish self with negative thoughts.
Imagine, for instance, a student who’s always struggled with procrastination, and who, intending to spend four hours on their term paper, instead only spent one. Should this be viewed as a victory, or a defeat? According to the shaping model, this is real progress—one hour is closer to the desired behavior than zero, and should receive some positive reinforcement. But if the student is too busy berating himself for falling short, then he’s never going to start the feedback loop that will lead to a robust new habit. Instead, he’ll just make the thought of trying even more intolerable, next time. If he wants to make it stick, he should focus on the direction of his behavioral change, not the absolute value of how much progress he has or hasn’t made.
The key lesson is that these reinforcement patterns actually matter—a 20% or 5% or even 1% change in one’s motivation to take action or willingness to think a certain kind of thought makes a huge difference when compounded over months and years.
To avoid the trap, we need to resolve the model conflict—to improve our System 1’s causal model of the universe, so that when a part of our brain asks the question “is this bringing me closer to my goals?” the answer that comes back is accurate. There’s nothing inherently rewarding about a click, to a dog, but if that dog’s reward centers have developed an implicit causal model that clicks precede treats, then those reward centers will fire upon hearing the click without needing to wait for the actual treat.[2] The brain is translating the click into a pleasure signal that reinforces the proximate behavior, because it recognizes, on some level, that behavior X caused a click, and clicks cause treats, and therefore behavior X causes treats and we should do it again!
The internal double crux unit will explain more about how to do this while maintaining a focus on true beliefs—the last thing you want to do is set up a reinforcement loop that incentivizes miscalibrated action.[3] The aim is to patch the gaps in your own causal models—to train yourself away from parking tickets are bad and painful and we shouldn’t look at them or think about them, and toward something like avoiding an extra fee by paying my parking ticket on time is just like depositing a check! Your brain is already checking the progress meter and dispatching the corresponding urges and aversions—what you want to do is calibrate this process so that you feel motivated to take all of the actions that further your goals.
Taste: an Inner Simulator output
This last section is more speculative.
Consider a mathematics professor who has spent multiple decades in cutting edge mathematical research, and multiple decades working with promising graduate students on their own investigations.
CFAR posits that this professor is likely to have something like "taste" when it comes to evaluating potential lines of investigation on thorny problems. They have seen hundreds or thousands of attempts-at-proofs, and their inner simulator has been quietly collecting experiential data on what-sorts-of-attempts-pan-out, versus what-sorts-do-not.
They will often immediately be able to tell, merely from glancing at a student's paper, whether that student is on a promising or unpromising path. They may not be able to legibly justify this sense, but it will be present nonetheless.
Some people might be loath to put any stock in this knee-jerk implicit sense, and some others might trust it wholeheartedly.
CFAR's take, which is unlikely to surprise you, is that you should instead evaluate your taste. Consider the training data—is it rich, representative, and robust? Consider the domain at hand—is it one in which the training data is relevant?
The rapid and reflexive yucks and yums of a domain expert can be extremely useful, where they are well calibrated. They are a tool that is worth cultivating, and worth using frequently.
That being said, beware the failure modes of self-confirming feedback loops! If one develops and begins to rely upon one's taste too soon, or trusts it too unreflectively, one might easily condition oneself away from all sorts of promising lines of inquiry and never even know what one has missed.
Taste, in other words, is a double-edged sword, all the moreso if one does not even realize how much it can shape one's behavior. Think about, for instance, the reflexive flinch you might feel around a face that vaguely resembles the face of someone who was mean to you years ago—facial structure is probably not a particularly good predictor of how well you will get along with this entirely new person, and yet that flinch might color (or even prevent!) your first interaction.
It's neither correct to ignore one's taste reactions, nor to reject them, nor to let them drag you around. Instead, we encourage you to notice that they are a part of your operating system, and do your best to debug and iterate.
Taste & Shaping—Further Resources
Operant conditioning is the process by which people come to associate behaviors with the pleasures or pains that they produce, and to engage in behavioral patterns that lead to more pleasant consequences (while avoiding those that result in pain). Associations are formed most strongly when the pleasure or pain immediately follows the behavior.
http://en.wikipedia.org/wiki/Operant_conditioning
Complex behaviors can be learned through operant conditioning through a gradual step-by-step process known as “shaping.” Pleasant results are structured to provide positive reinforcement for behaviors which represent a small step in the direction of the desired behavior, beginning with behaviors that already occur, so that the individual is led towards the desired behavior by a hill-climbing algorithm.
http://en.wikipedia.org/wiki/Shaping_(psychology)
An engaging take on how the techniques of operant conditioning which are used to train animals can also be applied to people:
Pryor, Karen (1999). Don’t Shoot the Dog.
Psychologists Carver and Scheier (2002) use the theory of control systems to model goal pursuit, where feedback about one’s progress towards a goal is translated into pleasant or unpleasant feelings. These feelings then motivate the person to continue an effective approach or change an ineffective approach. In order for the system to function smoothly, it is necessary for the relevant part of the system to recognize the connection between the goal and one’s current behavior.
Carver, C. S., & Scheier, M. F. (2002). Control processes and self-organization as complementary principles underlying behavior. Personality and Social Psychology Review, 6, 304-315. http://goo.gl/U5WJY
Hollerman and Schultz (1998) review research on conditioning which investigated how monkeys’ dopamine systems respond when they receive a juice reward. Their dopamine response was based on the information that they received about whether they were getting juice, rather than the juice itself. Thus, an unexpected juice reward produced a dopamine spike, and a cue which indicated that they were about to receive juice also produced a spike.
However, expected juice did not produce a dopamine spike, and if a monkey that expected to receive juice did not receive juice then there was a decrease in dopamine.
Hollerman, J. R., & Schultz, W. (1998). Dopamine neurons report an error in the temporal prediction of reward during learning. Nature Neuroscience, 1, 304-309. http://goo.gl/3NKDhY
Sebastian Marshall’s stream-of-consciousness description of how the image of a barbarian warlord shaped both his motivation and behavior:
http://sebastianmarshall.com/barbarian-warlord
Stanford psychologist BJ Fogg has developed a simplified, systematic approach to behavior change. His free tutorial (which you can sign up to receive by email at his website) provides extremely useful practice at developing a new habit, as well as a clear explanation of the process. He emphasizes making the new behavior extremely simple and quick to do, having a clear trigger for the behavior, and celebrating each time that you complete the behavior in order to reinforce the new habit.
Adam Grant and Jihae Shin of the University of Pennsylvania offer an overview of contemporary research on work motivation, or the psychological processes that direct, energize, and maintain action toward a job, task, role, or project. They describe in depth five core theories that purport to explain work motivation, and explore controversies and unanswered questions for each before discussing new and promising areas of study.
Grant, A. M., & Shin, J. (2011) Work motivation: Directing, energizing, and maintaining effort (and research). Oxford handbook of motivation. Oxford University Press. https://goo.gl/Pi7tiR
- ^
In earlier versions of the CFAR curriculum, this class was titled Propagating Urges 1 and the thing which eventually became internal double crux was titled Propagating Urges 2.
- ^
Indeed, experiments with monkeys who received juice as a reward for scoring points in a video game showed that the dopamine spike associated with the juice eventually shifted to occur several seconds earlier, when the victory sign appeared on screen.
- ^
CFAR instructor Andrew Critch once infamously used hyperbolic discounting to train himself into an affinity for pain, while trying to recover from an injury. Fortunately, he noticed his mistake, and used that same knowledge to reverse the process.
1 comments
Comments sorted by top scores.
comment by Leon Lang (leon-lang) · 2023-01-23T20:03:33.007Z · LW(p) · GW(p)
Summary
- “I want to exercise but I don’t want to exercise”
- Wants reflect both for long-term goals and immediate desires
- Emotional valence makes both not always agree
- Yum and yuck: the things that are yucky at the moment often contain a yummy quality for the long-term
- Goal: Yum-feeling is aligned with the in-the-moment actions toward our long-term wants
- This can be achieved with internal double-crux (IDC)
- This article is more for understanding what’s going on, and IDC is for tinkering with it.
- Our motivations are shaped by hyperbolic discounting:
- If something feels intrinsically unpleasant then a model in us claims this is bad for one of our goals.
- E.g., in the exercise case: Goals like “conserve energy” and “avoid discomfort” are hurt
- It’s worthwhile to search for the causal structure of this.
- If that’s not clarified, the feelings can condition us into unhelpful behavior
- Parking ticket example:
- Paying the parking ticket and getting a paycheck may both gain us 110$ (in avoided fees vs. salary)
- However, the first feels like counter to the goal of making money whereas the second feels like serving that goal.
- It’s worthwhile to try to align the immediate emotional response with the actual effect of our actions
- Temporal or hyperbolic discounting: quick rewards work way better for conditioning than longer-term rewards
- E.g., the immediate reward of crisps vs. feeling bad afterward
- This is because our system 2 modeling ability is pretty weak compared to system 1 sensemaking
- Even very small yucks/yums can have an outsized effect
- If something feels intrinsically unpleasant then a model in us claims this is bad for one of our goals.
- Resolving model conflicts
- It seems worth it to track what our yums and yucks reinforce.
- Reward shaping can help with that: as in dog training, manage to produce a “click” after positive actions that align with the long-term goal (a “treat”) that will be achieved way later.
- IDC will focus on how to do this while keeping true beliefs.
- Taste: an Inner Simulator output
- Mathematics professors have a taste for what yields success, formed by hundreds of seen proof attempts.
- CFAR’s take: neither believe nor disbelieve your taste; evaluate it.
- Problem with taste: if you simply believe it, then it may become a self-fulfilling prophecy.