The Perceptron Controversy
post by Yuxi_Liu · 2024-01-10T23:07:23.341Z · LW · GW · 18 commentsThis is a link post for https://yuxi-liu-wired.github.io/essays/posts/perceptron-controversy/
Contents
18 comments
Connectionism died in the 60s from technical limits to scaling, then resurrected in the 80s after backprop allowed scaling. The Minsky–Papert anti-scaling hypothesis explained, psychoanalyzed, and buried.
I wrote it as if it's a companion post to Gwern's The Scaling Hypothesis.
18 comments
Comments sorted by top scores.
comment by [deleted] · 2024-01-11T23:01:09.513Z · LW(p) · GW(p)
I wanted to make a comment here on alternate histories from a computer architecture perspective.
I'm a computer engineer and I've written many small control systems that interact with other systems - exactly the kind of 'society of the mind' that Builder the Robot used. I also have built robots that can pick up blocks as well as mimic human gestures, basic exercises 45 years later.
So the core of modern computers - that Ted Hoff et all developed into the 4004 in 1971 - is the ALU. I've built one in VHDL. The 4004 had only 2300 transistors, and is Turing complete.
Structure wise, you have bytecode with <opcode, data> and you keep as much of the program and data as possible on magnetic storage. (tape or hard drives). The ALU is a small reused chunk of silicon that can execute any program in theory. (in practice address space limited the practical size)
This is the problem with an alternate history of neural networks working 20 years early. Silicon consumption. With very slow clock speeds, and parallel architectures where you need many unnecessary connections (something we're still stuck with right now, because irregular sparsity is not supported in current hardware), you need probably unaffordable amounts of silicon area. The early computers, and actually the later computers, up until the slowdown for Moore's law, pretty much all work by minimizing the usage of the expensive resource, refined/patterned silicon.
You absolutely could build "special hardware boards" that implemented perceptrons and back prop, but they would also be unavoidably expensive*. Minsky's small programs consume much less memory, and are the backbone of 1970s-present control systems. (everything except things like autonomous car perception stacks and similar)
Another way to view it is, with the microprocessor + small serial program design, you repeatedly access the same cached instructions and data kernel, and operate across a larger amount of data.
With a neural network design, you end up accessing every weight in the network to generate every output**. This is extremely cache unfriendly, and it means current hardware is often limited by memory bandwidth, which you need extreme quantities of.
In a related topic to everyone's favorite AI risk topic, the above choice for computer architecture is the culprit for many of the cybersecurity vulnerabilities we are still stuck with. (the structure of the early 80s language C is responsible for many vulnerabilities as well)
*they were. Various early 2000s AI experiments used FPGAs for this purpose
**unless MoE or other bleeding edge techniques are in use
Replies from: Yuxi_Liu↑ comment by Yuxi_Liu · 2024-01-12T06:07:18.018Z · LW(p) · GW(p)
Concretely speaking, are you to suggest that a 2-layered fully connected network trained by backpropagation, with ~100 neurons in each layer (thus ~20000 weights), would have been uneconomical even in the 1960s, even if they had backprop?
I am asking this because the great successes in 1990s connectionism, including LeNet digit recognition, NETtalk, and the TD-gammon, all were on that order of magnitude. They seem within reach for the 1960s.
Concretely speaking, TD-gammon cost about 2e13 FLOPs to train, and in 1970, 1 million FLOP/sec cost 1 USD, so with 10000 USD of hardware, it would take about 1 day to train.
And interesting that you mentioned magnetic cores. The MINOS II machine built in 1962 by the Stanford Research Institute group had precisely a grid of magnetic core memory. Can't they have scaled it up and built some extra circuitry to allow backpropagation?
Corroborating the calculation, according to some 1960s literature, magnetic core logic could go up to 10 kHz. So if we have ~1e4 weights updated 1e4 times a second, that would be 1e8 FLOP/sec right there. TD-gammon would take ~1e5 seconds ~ 1 day, the same OOM as the previous calculation.
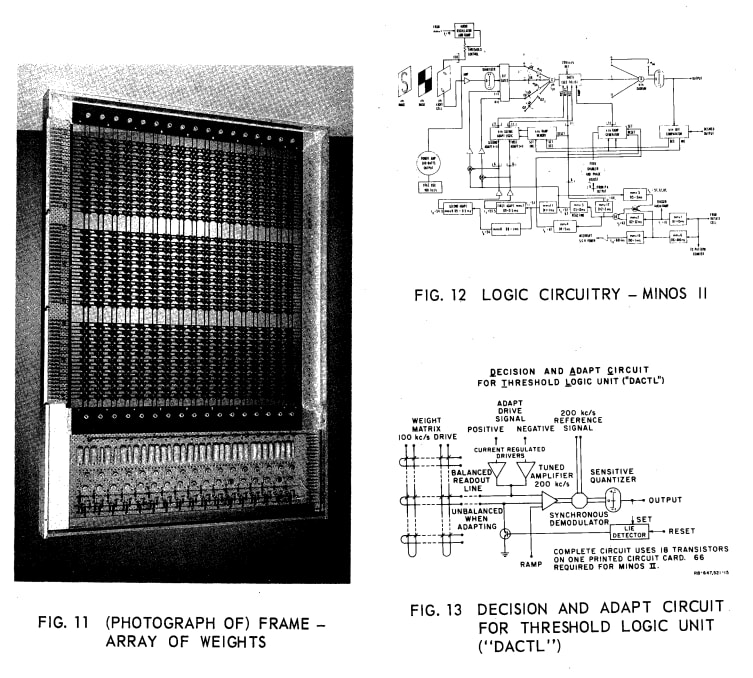
↑ comment by [deleted] · 2024-01-13T20:44:08.982Z · LW(p) · GW(p)
magnetic cores. The MINOS II machine built in 1962 by the Stanford Research Institute group had precisely a grid of magnetic core memory
By magnetic memory I was referring to :

The core idea is that you can bulk store a reasonably large amount of data - 5 mb a module for the picture above, up to hundreds of mb in the 1970s - that get accessed infrequently.
For example, suppose you wanted to calculate a paycheck for an hourly worker, an early application for this type of computer. Every time they use a time card reader (a punchcard with their employee ID), you save to a data structure on a hard drive the recorded time.
Then, once every 2 weeks, for each n employees, you retrieve the data for all the clock in/clock out times, retrieve a record with their rate of pay and other meta rules (are they eligible for overtime etc), and then in a relatively simply program you can calculate the payroll record, print it to text, print their paycheck, save the record to a tape drive, and then zero out the record for the next payroll cycle.
So you have relative large dataset : n employee records with m times for each, plus bits for meta rules, and a relatively tiny program. You will only check each record 1 time.
Neural networks have the issue that any practical one is pretty large, and all weights must be accessed every inference.
great successes in 1990s connectionism, including LeNet digit recognition, NETtalk, and the TD-gammon
These are not useful applications. The closest is digit recognition.
From the 1970s to somewhere in the 2000s, OCR was done with computer vision. You collect features from each letter, such as the lines with hough transforms, harris corner detectors, and you map these features to a relative coordinate space. Then you use some type of classifier, SVMs or similar, to detect the letter.
I'm not quite sure of the flop requirements for a CV solution, since calculating these transforms is some matrix operations, but I can say that the kernels to do it are much smaller than a neural network.
You can only detect printed characters reliably this way - so an earlier LeNet would have saved a little bit of money for the post office.
And just to reiterate, as bad as Builder the Robot was at navigation, Minsky was right. Avionics, factory control systems, motor control, automotive throttle by wire - I have worked on a variety of these systems, and they all work as a "society of the mind" of small specialized programs. They don't scale to large, complex robots, but it doesn't matter, startups today driving big robots have immensely more compute and memory to do it. RT-X is getting closer to a useful capability level, and it's 50B weights.
The main limitation is without neural networks, you need really clean perception. For example resolvers for joint position, or GPS or older systems for avionics. The machine needs the exact coordinates or rotational angle, it can't use a camera.
comment by the gears to ascension (lahwran) · 2024-01-11T05:57:46.243Z · LW(p) · GW(p)
wow, that's really long. satisfying writing, though.
Replies from: Yuxi_Liu↑ comment by Yuxi_Liu · 2024-01-11T18:37:32.859Z · LW(p) · GW(p)
I was thinking of porting it full-scale here. It is in R-markdown format. But all the citations would be quite difficult to port. They look like [@something2000].
Does LessWrong allow convenient citations?
Replies from: Alex_Altair, habryka4, lahwran↑ comment by Alex_Altair · 2024-01-11T21:30:37.813Z · LW(p) · GW(p)
I'd recommend porting it over as a sequence instead of one big post (or maybe just port the first chunk as an intro post?). LW doesn't have a citation format, but you can use footnotes for it (and you can use the same footnote number in multiple places).
↑ comment by habryka (habryka4) · 2024-01-12T00:30:14.942Z · LW(p) · GW(p)
Porting it full-scale seems nice. Our markdown dialect does indeed not currently support that citation format, but a simple regex would probably be good enough to just replace all the citations with footnotes.
↑ comment by the gears to ascension (lahwran) · 2024-01-11T22:04:53.137Z · LW(p) · GW(p)
Does LessWrong allow convenient citations?
don't think so, I've bugged them about it before so maybe it got implemented while I wasn't looking but idk where to find out. what do you use to process the citations into the form on the webpage? I doubt they'll implement it now but sending the code for it could make it happen someday
Replies from: Yuxi_Liu↑ comment by Yuxi_Liu · 2024-01-16T06:47:43.493Z · LW(p) · GW(p)
I use a fairly basic Quarto template for website. The code for the entire site is on github.
The source code is actually right there in the post. Click the button Code, then click View Source.
https://yuxi-liu-wired.github.io/blog/posts/perceptron-controversy/
comment by Ilio · 2024-01-11T14:11:19.375Z · LW(p) · GW(p)
The story went that “Perceptrons proved that the XOR problem is unsolvable by a single perceptron, a result that caused researchers to abandon neural networks”. (…) When I first heard the story, I immediately saw why XOR was unsolvable by one perceptron, then took a few minutes to design a two-layered perceptron network that solved the XOR problem. I then noted that the NAND problem is solvable by a single perceptron, after which I immediately knew that perceptron networks are universal since the NAND gate is.
Exactly the same experience and thoughts in my own freshyears (nineties), including the « but wasn’t that already known? » moment.
Rosenblatt’s solution was mainly just randomization because he mistakenly believed that the retina was randomly wired to the visual cortex, and he believed in emulating nature. Rosenblatt was working with the standard knowledge of neuroscience in his time. He could not have known that neural connections were anything but random – the first of the Hubel and Wiesel papers was published only in 1959.
Push back against this. Wiring is actually largely random before the critical periods that prunes most synapses, after which what remains is selected to fit the visual properties of the training environment. One way to mimicking that is to pick the delta weights at random and update iff the error diminishes (annealing).
But that’s one nitpick within many food for thought, thanks for the good reading!
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-01-11T16:45:44.035Z · LW(p) · GW(p)
[edit: I am referring to the brain here, not Artificial Neural Nets.] Hmmm, I disagree with the randomness. A lot of projections in the brain are ordered before pruning. Indeed, given the degree of order, and the percentage of neurons pruned, it would be impossible to establish that much order with pruning alone.
https://www.cell.com/fulltext/S0092-8674(00)80565-6
Replies from: gwern, Ilio↑ comment by gwern · 2024-01-11T22:13:54.057Z · LW(p) · GW(p)
it would be impossible to establish that much order with pruning alone.
That seems straightforwardly falsified by ANNs like lottery tickets or weight agnostic NNs, where the weights are randomized and all the learning is done by adding/pruning away connections (you can think of it as searching in fully-connected net space). Most on point here would be Ramanujan et al 2019 which proves that as random NNs get bigger, you expect there to be a sub-network which computes whatever you need (which makes sense, really, why wouldn't there be? NNs express such rich classes of functions, that if you can pick and choose from within a very large NN, it'd make sense you could sculpt whatever you need).
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-01-12T19:30:02.687Z · LW(p) · GW(p)
To clarify, I meant, within a human brain. Not within an artificial neural net. The human brain is highly ordered before birth by genetically determined chemotaxis signals guiding axon growth. Synapses are formed within relatively small regions of where the guided axons have ended up. This results in a large capacity for 'fine' adjustments, while having a preset large scale structure which is very similar between individuals. The amount of this large-scale order seen in the human brain, as evidenced by the broad similarity of Brodmann regions between individuals, is the thing I'm claiming couldn't be established by pruning neurons.
For more info: https://www.lesswrong.com/posts/Wr7N9ji36EvvvrqJK/response-to-quintin-pope-s-evolution-provides-no-evidence?commentId=r72N4LxupbmTtgN3i [LW(p) · GW(p)]
↑ comment by Ilio · 2024-01-11T17:18:50.372Z · LW(p) · GW(p)
Hmmm, I disagree with the randomness.
I don’t think you do. Let me rephrase: the weights are picked at random, under a distribution biased by molecular cues, then pruned through activity dependent mechanisms.
In other words, our disagreement seems to count as an instance of Bertrand’s paradox.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-01-14T20:57:09.079Z · LW(p) · GW(p)
"Wiring is actually largely random before the critical periods that prunes most synapses, after which what remains is selected to fit the visual properties of the training environment"
Yes, I think I technically agree with you. I just think that describing the cortex's connections as "largely random" gives a misleading sense of the pattern. Randomness actually plays a relatively small and constrained role in brain wiring even before learning occurs.
The analogy I've come up with is: Original growth and connection For an analogy of the scale involved, I describe this as a neuron being like a house in America. That house grows a neuron guided by chemotaxis to a particular block of buildings on the other coast. Once there, the neuron forms a synapse according to a chemical compatibility rule. In this analogy, let's say that the neuron in our example must connect to an address ending in 3.
Refinement Picking a different member of the closest ten allowed options (respecting the rule of ending in 3 and respecting the neighborhood boundary) according to the Hebbian rule. The Hebbian rule is "Neurons that fire together, wire together." The highest temporally synchronous candidate from among the set will be chosen for a new connection. Existing connections with poor temporal synchronicity will get gradually weaker. Synchronicity changes over time, and thus the set of connections fluctuates.
Pruning Of the candidates matched with following refinement, those which are consistently poorly synchronized will be considered 'bad'. The poor quality connections will weaken until below threshold, then be pruned (removed). A neuron with no connections above threshold for a lengthy period of time will be killed (also called pruning). Connections can break and later be reformed, but neurons which are killed are not replaced.
Replies from: Ilio↑ comment by Ilio · 2024-01-15T16:26:38.308Z · LW(p) · GW(p)
Not bad! But I stand by « random before (..) » as a better picture in the following sense: neurons don’t connect once to an address ending in 3. It connects several thousands of times to an address ending in 3. Some connexion are on the door, some on windows, some on the roof, one has been seen trying to connect to the dog, etc. Then it’s pruned, and the result looks not that far from a crystal. Or a convnet.
(there’s also long lasting silent synapses and a bit of neurogenesis, but that’s details for another time)
Replies from: nathan-helm-burger, nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-03-21T02:51:57.854Z · LW(p) · GW(p)
For those interested in more details, I recommend this video:
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-01-15T17:18:28.146Z · LW(p) · GW(p)
Yes, that's fair. I think we've now described the situation well enough that I don't think future readers of this thread will end up with a wrong impression. To expand on Ilio's point: the connection point on the "building" (recipient neuron's dendrites) matters a lot because the location of of the synapse on the dendrites sets a floor and ceiling on the strength of the connection which cannot be exceeded by weight modifications due to temporal synchronicity. Also, yes, there is neurogenesis ongoing throughout the lifespan. Never long range (e.g. cross country in our metaphor), only short range (within same metropolitan area). The long range connections are thus special in that they are irreplaceable.