Why square errors?
post by Aprillion · 2022-11-26T13:40:37.318Z · LW · GW · 11 commentsContents
11 comments
Mean squared error (MSE) is a common metric to compare performance of models in linear regression or machine learning. But optimization based on the L2 norm metrics can exaggerate bias in our models in the name of lowering variance. So why do we square errors so often instead of using absolute value?
Follow my journey of deconfusion about the popularity of MSE.
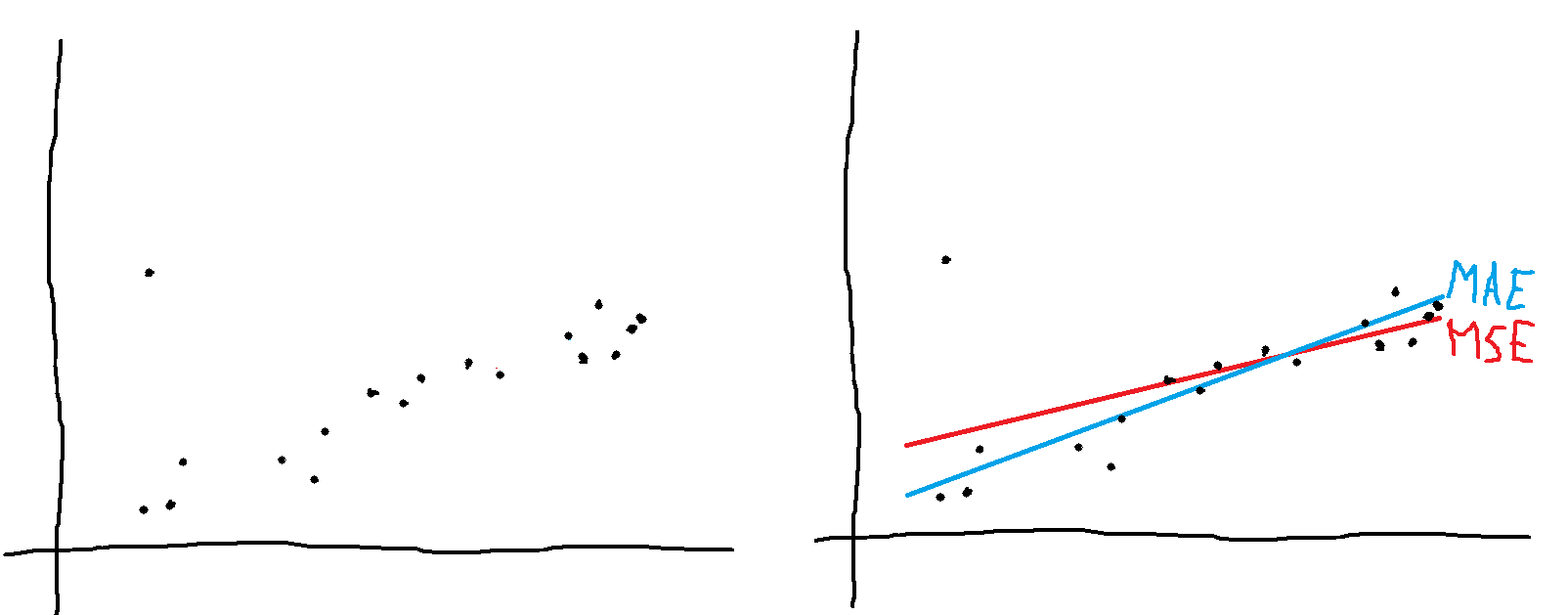
My original intuition was that optimizing mean absolute error (MAE) ought to always create "better" models that are closer to the underlying reality, capture the "true meaning" of the data, be more robust to outliers. If that intuition were true, would it mean that I think most researchers are lazy and use an obviously incorrect metric purely for convenience?
MSE is differentiable, while MAE needs some obscure linear programming to find the (not necessarily unique) solutions. But in practice, we would just call a different method in our programming language. So the Levenberg–Marquardt algorithm shouldn't look like a mere convenience, there should be fundamental reasons why smart people want to use it.
Another explanation could be that MSE is easier to teach and to explain what's happening "inside", and thus more STEM students are more familiar with the benefits of MSE / L2. In toy examples, if you want to fit one line through an ambiguous set of points, minimizing MSE will give you that one intuitive line in the middle, while MAE will tell you that there are infinite number of equally good solutions to your linear regression problem:
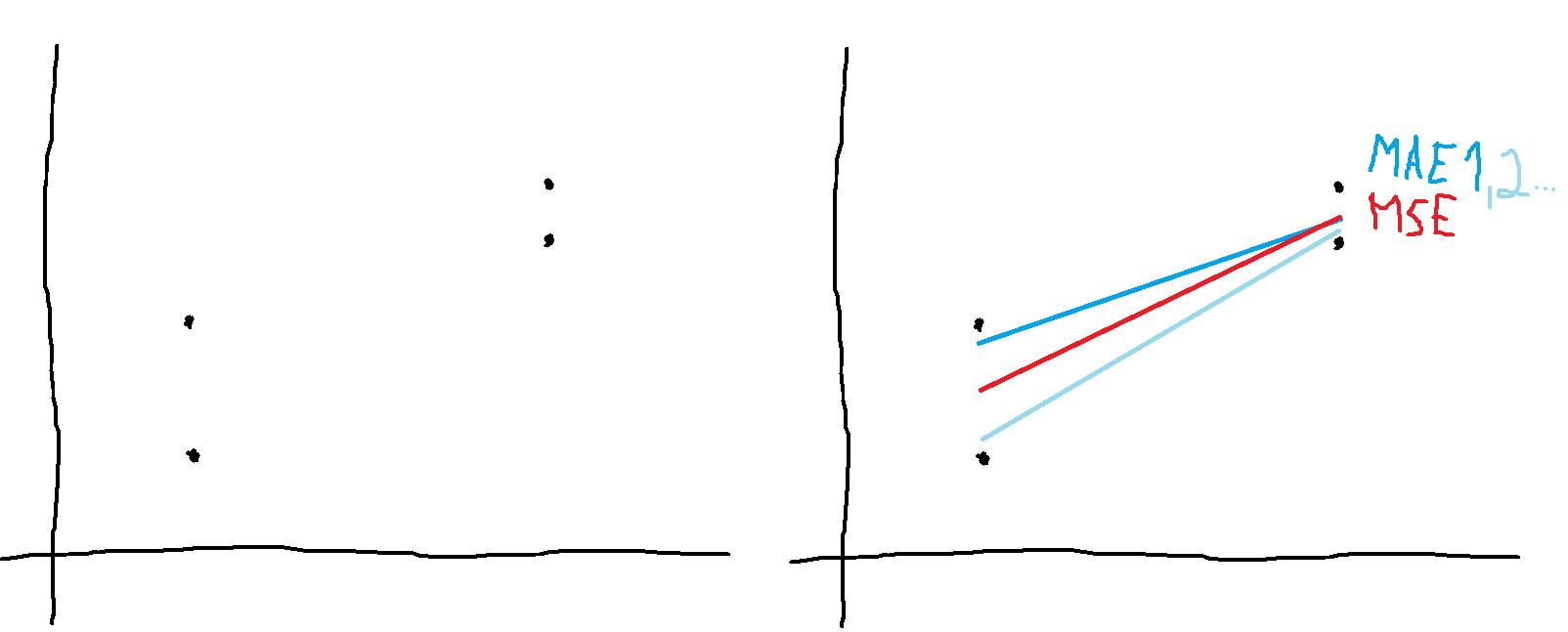
I see this as an advantage of MAE or L1, that it reflects the ambiguousness of reality ("don't use point estimates pf linear regression parameters when multiple lines would fit the data equally well, use those damned error bars and/or collect more data"). But I also see that other people might understand this as an advantage of MSE or L2 ("I want to gain insights and some reasonable prediction, an over-simplified fast model is enough, without unnecessary complications").
Previously, I also blamed Stein's Paradox on L2, but that does not seem true, so other people probably formed their intuitions about L1 and L2 without imaginary evidence against one of them. If both norms are equally good starting points for simplifying reality into models, then computational performance will be a bigger factor in the consideration that L2 is "better".
However, Root mean square error (RMSE) or mean absolute error (MAE)? by Chai and Draxler (2014) captures the biggest gap in my previous understanding - we have to make an assumption (or measurement) about the error distribution and choose our metric(s) accordingly:
Condensing a set of error values into a single number, either the RMSE or the MAE, removes a lot of information. The best statistics metrics should provide not only a performance measure but also a representation of the error distribution. The MAE is suitable to describe uniformly distributed errors. Because model errors are likely to have a normal distribution rather than a uniform distribution, the RMSE is a better metric to present than the MAE for such a type of data.
And for many problems, small errors are more likely than large errors, without an inherent bias in the direction of the error (or we can control for bias), so normal distribution is a reasonable assumption.
When we are not sure (which we never are), we can also use more than one metric to guide our understanding, evaluating our models by one over-simplified number shouldn't be enough.
11 comments
Comments sorted by top scores.
comment by Razied · 2022-11-27T03:53:23.936Z · LW(p) · GW(p)
As usual, being a bayesian makes everything extraordinarily clear. The mean-squared-error loss is just the negative logarithm of your data likelihood under the assumption of gaussian-distributed data, so "minimizing the mean-squared-loss" is completely equivalent to a MLE with gaussian errors . Any other loss you might want to compute directly implies an assumption about the data distribution, and vice-versa. If you have reason to believe that your data might not be normally distributed around an x-dependent mean... then don't use a mean-squared loss
Replies from: Oliver Sourbut, Aprillion↑ comment by Oliver Sourbut · 2022-11-28T10:49:17.966Z · LW(p) · GW(p)
This approach also makes lots of regularisation techniques transparent. Typically regularisation corresponds to applying some prior (over the weights/parameters of the model you're fitting). e.g. L2 norm aka ridge aka weight decay regularisation corresponds exactly to taking a Gaussian prior on the weights and finding the Maximum A Priori estimate (rather than the Maximum Likelihood).
↑ comment by Aprillion · 2022-11-27T09:19:37.799Z · LW(p) · GW(p)
see your β there? you assume that people remember to "control for bias" before they apply tools that assume Gaussian error
that is indeed what I should have remembered about the implications of "we can often assume approximately normal distribution" from my statistics course ~15 years ago, but then I saw people complaining about sensitivity to outliers in 1 direction and I failed to make a connection until I dug deeper into my reasoning
comment by P. · 2022-11-26T14:34:31.096Z · LW(p) · GW(p)
Doesn’t minimizing the L1 norm correspond to performing MLE with laplacian errors?
Replies from: gjm, donald-hobson, Aprillion↑ comment by gjm · 2022-11-26T19:29:58.650Z · LW(p) · GW(p)
Yes. I'm not sure where the thing about "uniformly distributed errors" comes from in Chai & Draxler; they don't explain it. I think it's just an error (it looks as if they are atmospheric scientists of some sort rather than mathematicians or statisticians).
If your model of errors is, say, uniform between -1 and +1, then a good regression line is one that gets within a vertical distance of 1 unit of all your points, and any such is equally good. If you think your errors are uniformly distributed but don't know the spread, then (without thinking about it much; I could be all wrong) I think the best regression line is the one that minimizes the worst error among all your data points; i.e., L-infinity regression. L1/MAE is right for Laplacian errors, L2/MSE is right for normally distributed errors.
[EDITED to add:] Each of these models also corresponds to a notion of "average": you want to pick a single true value and maximize the likelihood of your data. Normal errors => arithmetic mean. Laplacian errors => median. Uniform errors with unknown spread => (with the same caveat in the previous paragraph) half-way between min and max. Uniform errors between -a and +a => any point that's >= max-a and <= min+a, all such points (if there are any; if not, you've outright refuted your model of the errors) equally good.
↑ comment by Donald Hobson (donald-hobson) · 2022-11-27T19:32:51.412Z · LW(p) · GW(p)
Yep.
comment by dmav · 2022-11-27T03:21:37.417Z · LW(p) · GW(p)
Here's a good/accessible blog post that does a pretty good job discussing this topic. https://ericneyman.wordpress.com/2019/09/17/least-squares-regression-isnt-arbitrary/
comment by cohenmacaulay · 2022-11-28T23:30:16.285Z · LW(p) · GW(p)
Here is an additional perspective, if it's helpful. Suppose you live in some measure space X, perhaps for concreteness. For any can make sense of a space of functions for which the integral is defined (this technicality can be ignored at a first pass), and we use the norm . Of course, and are options, and when X is a finite set, these norms give the sum of absolute values as the norm, and the square root of the sum of squares of absolute values, respectively.
Fun exercise: If X is two points, then is just with the norm . Plot the unit circle in this norm (i.e, the set of all points at a distance of from the origin). If , you get a square (rotated 45 degrees). If you get the usual circle. If you get a square. As varies, the "circle" gradually interpolates between these things. You could imagine trying to develop a whole theory of geometry --- circumferences, areas, etc., in each of these norms (for example, is taxicab geometry). What the other comments are saying (correctly) is that you really need to know about your distribution of errors. If you expect error vectors to form a circular shape (for the usual notion of circle), you should use . If you know that they form a diamond-ish shape, please use . If they form a box (uniform distribution across both axes, i.e., the two are genuinely uncorrelated) use .
To have a larger and more useful example, let be a 1000 x 1000 grid, and regard as the set of possible colors between absolute black at and absolute white at (or use any other scheme you wish). Then a function is just a 1000 x 1000 pixel black-and-white image. The space of all such functions has dimension as a real vector space, and the concern about whether integrals exist goes away ( is a finite set). If and are two such images, the whole discussion about concerns precisely the issue of how we measure the distance .
Suppose I have a distinguished subspace of my vector space. Maybe I took ten thousand pictures of human faces perfectly centered in the frame, with their faces scaled to exactly fit the 1000 x 1000 grid from top to bottom. The K can be the span of those photos, which is roughly the "space of human face images" or at least the "space of images that look vaguely face-like" (principal component analysis tells us that we actually want to look for a much smaller-dimensional subspace of that contains the most of the real "human face" essence, but's let's ignore that).
I have a random image . I want to know if this image is a human face. The question is "how far away if from the distinguished subspace ?" I might have some cutoff distance where images below the cutoff are classified as faces, and images away from the cutoff as non-faces.
Speaking in very rough terms, a Banach space is a vector space that comes with a notion of size and a notion of limits. A Hilbert space is a vector space that comes with a notion of size, a notion of angles, and a notion of limits. The nice thing about Hilbert spaces is that the question "how far away if from the distinguished subspace ?" has a canonical best answer: the orthogonal projection. It is exactly analogous to the picture in the plane where you take , draw the unique line from to that makes a right angle, and take the point of intersection. That point is the unique closest point, and the projection onto the closet point is a linear operator.
In a Banach space, as you have observed in this post, there need not exist a unique closest point. The set of closest points may not even be a subspace of , it could be an unpleasant nonlinear object. There are no projection operators, and the distance between a point and a subspace is not very well-behaved.
It is a theorem that is a Hilbert space if and only if . That is, only the norm admits a compatible notion of angles (hence perpendicularity/orthogonality, hence orthogonal projection). You can talk about the "angle between" two images in the norm, and subtract off the component of one image "along" another image. I can find which directions in are the "face-iest" by finding the vector that my data points have the strongest components around, then project away from that direction, find a vector orthogonal to my "face-iest" vector along which the component of everything is strongest, project that away, etc., and identify a lower-dimensional subspace of that captures the essential directions (principal components) of that capture the property of "face-iness." There are all kinds of fun things you can do with projection to analyze structure in a data set. You can project faces onto face-subspaces, e.g., project a face onto the space of female faces, or male faces, and find the "best female approximation" or "best male approximation" of a face, you could try to classify faces by age, try to recognize whether a face belongs to one specific person (but shot independently across many different photos) by projecting onto their personal subspace, etc.
In the infinite-dimensional function spaces, these projections let you reconstruct the best approximation of a function by polynomials (the Taylor approximations) or by sinusoids (the Fourier approximations) or by whatever you want (e.g. wavelet approximations). You could project onto eigenspaces of some operator, where the projection might correspond to various energy levels of some Hamiltonian.
The reason we prefer in quantum mechanics is because, while eigenvectors and eigenvalues only make sense, projection operators onto eigenspaces are very much a special thing. Thus, things like spectral decomposition, and projection onto eigenstates of observable operators, all require you to live inside of .
None of this works in for precisely because "orthogonal" projection does not make sense. That is not to say that these spaces are useless. If you are in a function space, you might sometimes do weird things that take you outside of (i.e., they make the integral in question undefined) and you end up inside of some other , and that may not necessarily be the end of the world. Something as innocent as multiplication point-by-point can take you outside of the space you started in, and put you into a different one (i.e., the integral of might fail to exist, but the integral of for some may converge). That is to say, these spaces are Banach spaces but are not Banach algebras --- they do not have a nice multiplication law. The flexibility of moving to different 's can help get around this difficulty. Another example is taking dual spaces, which generally requires a different unless, funnily enough, (the only space that is self-dual).
tl;dr if you want geometry with angles, you are required to use . If you don't feel like you need angles (hence, no orthogonality, no projections, no spectral decompositions, no "component of x along y", no PCA, etc.) then you are free to use . Sometimes the latter is forced upon you, but usually only if you're in the infinite-dimensional function space setting.
comment by notfnofn · 2024-02-08T12:25:55.302Z · LW(p) · GW(p)
In case it hasn't crossed your mind, I personally think it's helpful to start in the setting of estimating the true mean of a data stream. A very natural choice estimator for is the sample mean of the which I'll denote . This can equivalently be formulated as the minimizer of .
Others have mentioned the normal distribution, but this feels secondary to me. Here's why - let's say , where is a known continuous probability distribution with mean 0 and variance 1, and are unknown. So the distribution of each has mean and variance (and assume independence).
What must be for the sample mean to be the maximum likelihood estimator of ? Gauss proved that it must be , and intuitively it's not hard to see why it would have to be of the form .
So from this perspective, MSE is a generalization of taking the sample mean, and asking the linear model to have gaussian errors is necessary to formally justify MSE through MLE.
Replace sample mean with sample median and you get the mean absolute error.
comment by DaemonicSigil · 2022-11-26T22:48:32.464Z · LW(p) · GW(p)
I think what it boils down to is that in 1 dimension, the mean / expected value is a really useful quantity, and you get it by minimizing squared error, whereas the absolute error gives the median, which is still useful, but much less so than the mean. (The mean is one of the moments of the distribution, (the first moment), while the median isn't. Rational agents maximize expected utility, not median utility, etc. Even the M in MAE still stands for "mean".) Plus, although algorithmic considerations aren't too important for small problems; in large problems the fact that least squares just boils down to solving a linear system is really useful, and I'd guess that in almost any large problem, the least squares solution is much faster to obtain than the least absolute error solution.