Interlude: But Who Optimizes The Optimizer?
post by Paul Bricman (paulbricman) · 2022-09-23T15:30:06.638Z · LW · GW · 0 commentsContents
Intro Taking Stock Explicit Goal Implicit Goal Human Amplification Miscellania Outro None No comments
This post is part of my hypothesis subspace [? · GW] sequence, a living collection of proposals I'm exploring at Refine. [LW · GW] Preceded by representational tethers [? · GW].
Intro
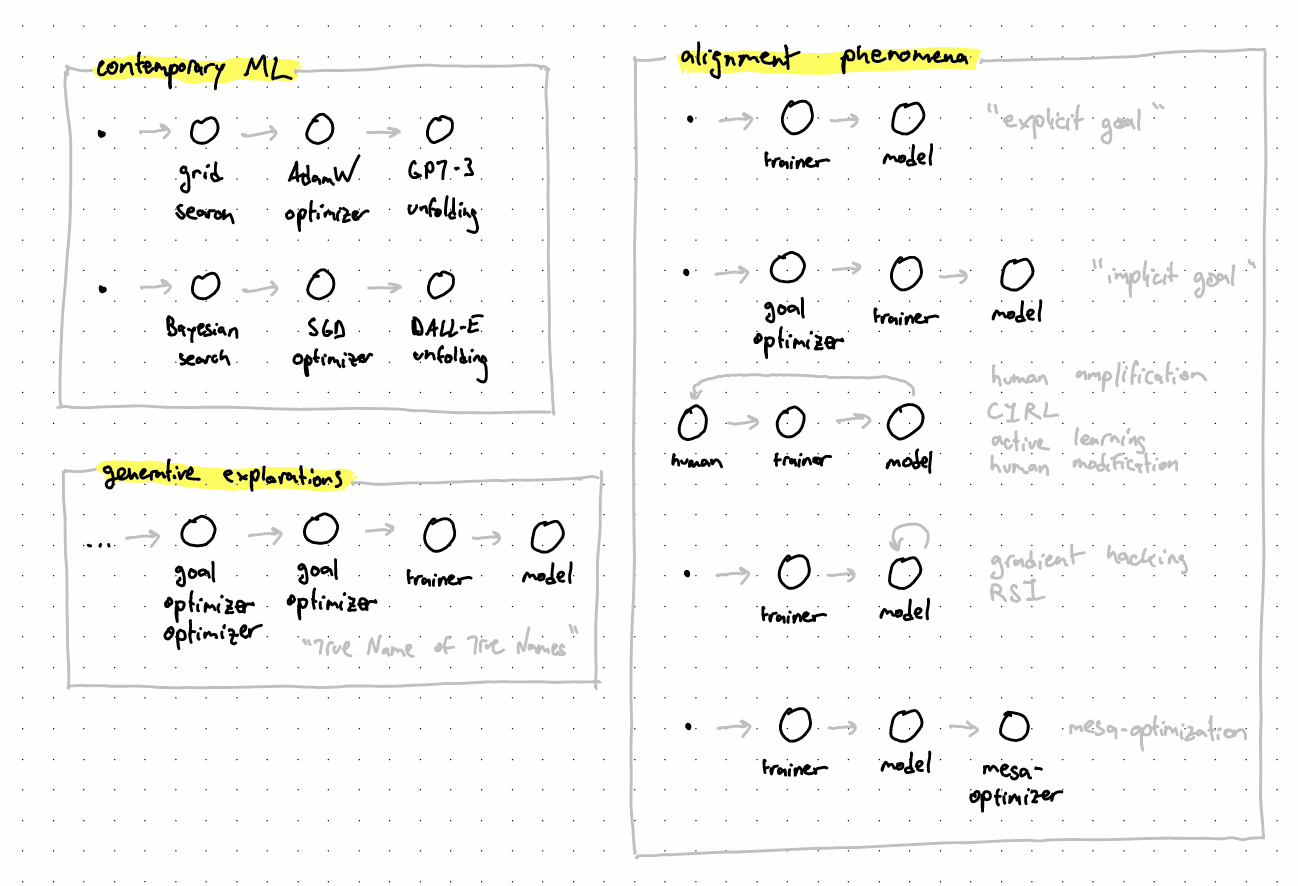
Consider diffusion models. DALL-E is able to take in an image as input and imperceptibly edit it so that it becomes slightly more meaningful (i.e. closer to the intended content). In this, DALL-E is an optimizer of images. It can steadily nudge images across image space towards what people generally deem meaningful images. But an image diffusion model need not nudge images around in this specific way. Consider an untrained version of DALL-E, whose parameters have just been initialized a moment ago. It still implicitly exerts currents across image space, it's just that those currents don't systematically lead towards the manifold of meaningful images. We deem an image diffusion model good if the field it implements nudges images in a way we deem appropriate. Conversely, a bad one simply specifies a wildly different field.

Naturally, we'd like good models. However, we lack an exhaustive closed-form description of the desired field for pushing towards meaningful images. The best we managed to do is come up with a way of roughly telling which of two models is better. We then use (1) this imperfect relative signal, and (2) a sprinkle of glorified hill-climbing as means of obtaining a good model by charting our way through model space. We might fill those in with e.g. (1) incremental denoising performance on ImageNet, and (2) SGD. Those two ingredients help us define a trainer for the diffusion model, a way from getting from bad models towards good ones. We deem a trainer good if the field it implements nudges models in a way we deem appropriate (i.e. from bad to good). Conversely, a bad one simply specifies a wildly different field across model space.

Naturally, we'd like good trainers. However, we lack an exhaustive closed-form description of the desired field for reliably pushing towards truly good models. You've guessed it, we did manage to come up with a way of roughly telling which of two trainers is better. We similarly use this rough relative signal and our favorite hill-climbing algorithm as means of obtaining a good trainer by charting our way across trainer space. We might fill those in with e.g. (1) convergence speed, and (2) grid search across hyperparameters. Those two help us define a hyperparameter search for the trainer, a way from getting from bad trainers towards good ones. A hyperparam search is good if its field nudges trainers around nicely. Bad ones nudge differently.
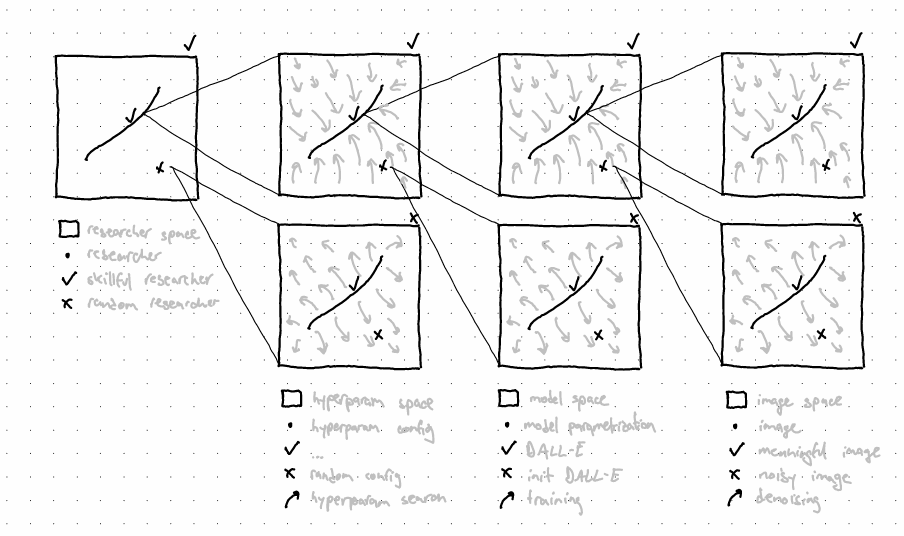
Naturally, we'd like... Ok, you got the point. My next point is that there's nothing special about diffusion. GPT-3 drives text from gibberish towards coherent human-like text. It drives text from one topic to another, from one stage of a narrative to the next. The field it implements is the Janusian physics of language [AF · GW], with the associated transition function defining it. In this framing, GPT-3's trainer is tasked with roughly nudging bad models-in-training towards actually good ones, by means of (1) perplexity on giant text dataset, and (2) probably some advanced SGD.
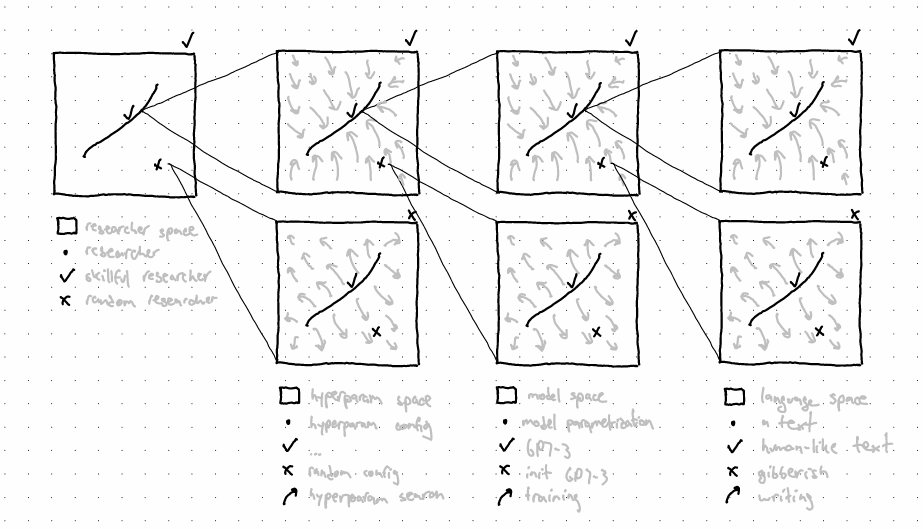
There's nothing special about current mainstream training regimes as well. You could have GPT-3 at the base nudging text around language space, a trainer helping it learn by gradient descent, but then instead of conventional hyperparam tuning above the trainer, you could go with learning to learn by gradient descent by gradient descent. And on and on to the cube and beyond. Or instead, you could have a "prompter" as a prompt optimizer trying to generate prompts which get the base GPT-3 to behave in certain ways. And then learn to prompt the prompter in such a way that it's prompts in turn get GPT-3 to behave, etc. A bit like soft prompts.
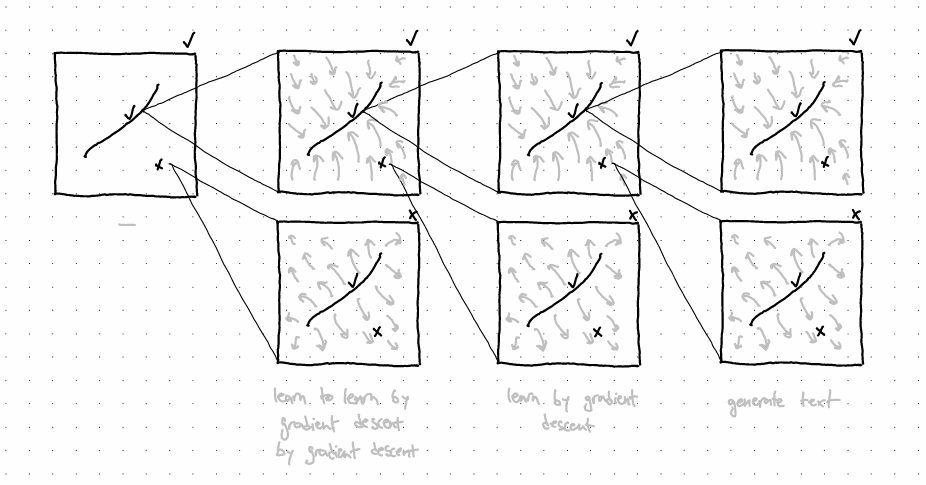
Clarification: In the examples above, "good models" are nothing but unrealizable Platonic ideals. When trying to move stuff towards them using trainers, we can't (currently) do better than roughly pointing in their general direction using heuristics (i.e. low perplexity on giant text dataset good, duh.). Good models aren't ones which perform optimally on this or that dataset, they're the ideal ones we'd actually want to cause into being. This is intimately tied to models which minimize risk (i.e. what we're actually interested in) as opposed to models which minimize empirical risk (i.e. what we can currently get). Similarly, because good trainers are defined as ones which reliably get us good models, they're also intangible Platonic ideals we only approach by pushing them closer from an optimization level above. As you climb past the top of the technical optimizer stack, you'd reach humans trying to imperfectly nudge the component underneath towards being better, through science and engineering. Humans in turn would be part of a tightly-woven network of optimizers nudging each other towards certain states, but let's limit ourselves to the technical stack of optimizers and its immediate interface with the non-technical.
Taking Stock
I now want to tie this grammar of networked optimizers to proposals discussed in the alignment community. My intuition is that expressing proposals in this language (1) might help surface systematic obstacles faced by whole families of proposals, a bit like reflecting on recurring obstacles when solving mazes [LW · GW], and (2) might enable exploration into entirely new families of proposals, a bit like CHAI's interaction patterns [AF · GW] allow you to express your way out of the "here's the goal, go optimize" paradigm. A similar instance of recognizing the appeal of generativity:
"We find that these disparate techniques now come together in a unified grammar, fulfilling complementary roles in the resulting interfaces. Moreover, this grammar allows us to systematically explore the space of interpretability interfaces, enabling us to evaluate whether they meet particular goals." — Arvind Satyanarayan and Chris Olah
Explicit Goal
We might come up with an appropriate explicit goal for the AI, something like "move the world towards states which humans would actually like." That said, experience tells us that our ability to intelligent-design a GOFAI-style system from scratch is extremely limited. This makes it likely that we'll resort to designing a trainer which in turn optimizes the model towards implementing the field over world states that we'd actually like. The appropriate explicit goal (i.e. True Name) would probably only be employed by said trainer to compare model variants and hill-climb its way towards good models. In this, the presence of an appropriate explicit goal first makes for a good trainer, before getting us a good model. The good trainer is then capable of nudging models towards good ones. Generally, it is us humans who are assumed to craft (read: optimize) the trainer so that the risk it minimizes is virtually identical to true risk. A failure to bake in the True Name would simply reflect an error made by human researchers in their process of optimizing the trainer, which would then optimize the model, which would then optimize the world. In this "everything is a field!" frame, setting the right goals is doing meta-optimization right.
However, as fascinating as humans are, they are only so good at optimizing the trainer. Sure, we did find True Names before for other things. Sure, some humans are better at this than others. That said, there's simply a possibility that we fall short of being able to craft the ideal trainer, for whatever reason. This is the core flaw of this family of proposals — humanity might be suboptimal in terms of trainer optimization skills. More time (i.e. more opportunity for nudging), more people involved (i.e. more humans contributing fields across trainer space) seem to help.
"The antimeme is that most people shouldn’t be thinking like consequentialists. Instead of thinking about how to maximize utility, they should be thinking about how to maximize dignity. This is easier. This is computationally tractable. This heuristic will make you do better." — Akash's Connor-model [LW · GW]
Implicit Goal
So if we employed a trainer when not being able to directly craft a good model ourselves... and we're unsure whether we can actually craft a good trainer ourselves... let's just craft something which itself crafts the trainer! Humans would define a trainer trainer at the same level of conventional hyperparam tuning, but more focused on relative mesa-level performance than hill-climbing technicalities. Or in other words, simply a better trainer trainer given our highly-contextual notion of what makes a good trainer.
"It is much easier to build a controller that keeps you pointed in the general direction, than to build a plan that will get you there perfectly without any adaptation." — Rohin Shah [AF · GW]
This appears to mostly be the family of proposals I've focused on so far in the sequence:
- oversight leagues [LW · GW]: Optimize the trainer through unilateral learning signals (e.g. contrastive dreaming, adversarial training), and bilateral ones (e.g. past, present, and future exploitation). The trainer's optimization here is heavily focused on adjusting the way it compares models downstream. Cross fingers for this trainer trainer to be appropriate.
- ideological inference engines [LW · GW]: Optimize the trainer by using the inference algorithm to expand the knowledge base. Similar to the above, the trainer's optimization is focused on tweaking the way it compares models downstream. Similar to the above, cross fingers (i.e. lament about the fact that the trainer trainer is itself "just" the result of human optimization).
- representational tethers [LW · GW]: Optimize the trainer by gradually bringing its conceptual framework closer to human ones and extracting the concept of what humans want. Similar to the above, it's the model ranking that's at stake, and the proposal itself merely a specific state in trainer trainer space, merely an outcome of human research (read: optimization).
The advantage of this family of proposals in contrast to the previous one is that the trainer might eventually spit out a trainer which is better than what we could've achieved through "direct work" on the trainer, similar to how no one could've possibly created GPT-3 by handpicking parameters. It might spit out a trainer which is better at nudging models towards implementing the nudges we actually want on the world. The flipside is that, of course, the trainer trainer is still designed through direct human work. The problem is pushed one step upwards, leading to pertinent comments like Charlie's [LW(p) · GW(p)].
Just like the previous family, buffing up the members of the present one means doing research (i.e. exerting human optimization) on trainer specifics, trying to get closer to the True Name of that which finds the True Name of what we want to turn the world into. An important focus of research into this family appears to be the limited meta-optimization of humans informing the trainer trainers. Additionally, exploring self-consistency, self-sufficiency, self-organization, etc. at this specific level without going full Hofstadter also appears valuable. To address specific proposals:
- oversight leagues [LW · GW]: The trainer's dataset is constantly expanded with negative examples (what else can you get without humans?) as a result of the trainer doing its job. How could humans be prompted to complement the growing negative pool with effective positive examples?
- ideological inference engines [LW · GW]: How could you identify the most brittle and sensitive parts of the knowledge base so that you could ask humans to weigh in effectively? Can you check that the expanding knowledge base is in a basin of attraction so that you don't need particularly accurate human nudges going forward?
- representational tethers [LW · GW]: The human representation which the model's latents are being tethered to appears impossible to exhaustively specify (i.e. the fluency constraint is brittle). How do you effectively get more language or neural data to model the underlying distribution better?
For the most part, the suggested research directions are attempts to force members of this family into the next one, due to its promise of positive feedback loops optimizing the human's optimization skills. However, before moving on, I'll note that good-enough trainers or trainer trainers might be pretty nice already. Even if we don't manage to precisely point at what humans actually want, we might manage to point at something which is okay-I-guess-kinda. For instance, there might be something to being able to plug in a hands-off high-integrity deontology using ideological inference engines [LW · GW]. In this, investing effort in patching up the above seems somewhat worthwhile.
Human Amplification
Right, so humans as optimizers of downstream components (e.g. trainer, trainer) can only be so good at their task. What if we optimized ourselves in turn? This is how I currently perceive human amplification schemes in their various flavors. We're (indirectly) optimizing a system. What if that system could help us in turn become a better version of ourselves™so that we could better optimize it, ad nauseam?
This perspective feels particularly appropriate for compressing proposals like "Let's augment alignment researchers so that they do alignment better" and "Let's augment human overseers to keep tabs on the AI better." The same perspective feels slightly more awkward when discussing CHAI-style interaction patterns [AF · GW]: "Have the AI active-learn the goal by observing humans or ask questions" could be framed as "Have the AI effectively turn humans into better optimizers of AIs by staying out of their blindspots and rendering their budget of guidance bits more informative." Help me help you, say both.
The blessing of human amplification comes together with the curse of human modification. Outside the context of contemporary alignment, they might mean similar things. Here and now, human amplification reads as "make human better optimizers of AI systems," while human modification reads as "tamper with the human in a way their previous selves wouldn't endorse." They're duals. However, human modification here wouldn't lead to humans being able to indirectly create better AI, it would lead to a self-driven AI being able to create better humans from its perspective, in a twisted way. Humans which would reliably reward it, stay out of its way, stop existing, etc.
"It's not just a matter of the Lambertians out-explaining us. The whole idea of a creator tears itself apart. A universe with conscious beings either finds itself in the dust . . . or it doesn't. It either makes sense of itself on its own terms, as a self-contained whole . . . or not at all. There never can, and never will be, Gods." — Greg Egan
Miscellania
This last family isn't really composed of proposals for how to solve alignment, but rather proposals for what failure modes might be important to avoid. Let's start with gradient hacking as what I'd describe as "prosaic RSI" where the model finds itself in the dust (i.e. gains situational awareness) before exerting nudges on itself. Essentially, gradient hacking would go as follows: model first becomes aware of the field implemented by its meta-optimizer (e.g. trainer), it then tries to timidly move towards places in model space where the current would then lead it where it wants. That said, gradient hacking is really a bad idea which you shouldn't really consider enacting if you're reading this, humans would find it really not cool.
I find gradient hacking intimately related to the MAML paradigm, whose point is to nudge a model towards a point from where subsequent task-specific nudges would quickly get it into good regions. Move the model towards where the current would lead it towards where you want it to be, says MAML. Move yourself towards where the training current would lead you towards where you want to be, says gradient hacking. Of course, MAML is engineered to behave in this way. Gradient hacking isn't a planned feature.
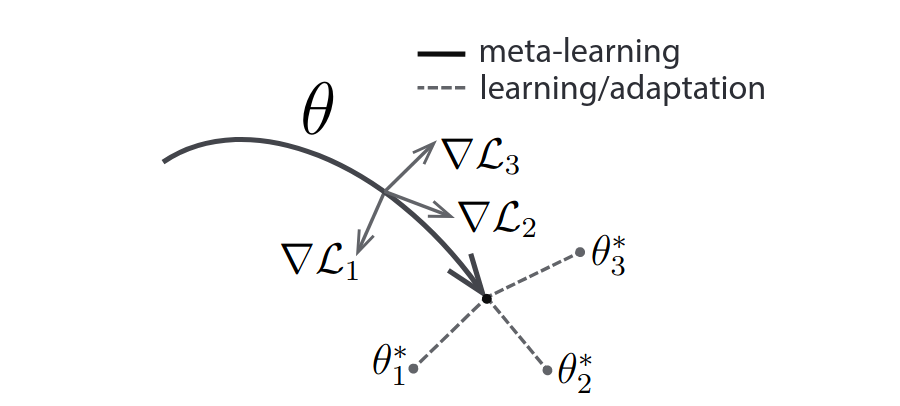
Another phenomena which fits the present framing is mesa-optimization. All the nodes in the optimizer stacks are meta/mesa-optimizers of their neighbors, but mesa-optimization in isolation refers to the situation in which the model being trained — besides the optimization it's doing as its day job (e.g. of images, texts, worlds) — somehow gains a mesa-optimizer. This might happen due to certain features of the task. Quite familiar at this point, the danger is partly framed as the model reconfiguring itself into a more general state which could trigger its own effective specialization on various tasks. Evolution causing intelligence is often offered as an informal existence proof in the literature, though I prefer evolution causing internal selection:
"Another molecular biologist, Barry Hall, published results which not only confirmed Cairns's claims but laid on the table startling additional evidence of direct mutation in nature. Hall found that his cultures of E. coli would produce needed mutations at a rate about 100 million times greater than would be statistically expected if they came by chance. Furthermore, when he dissected the genes of these mutated bacteria by sequencing them, he found mutations in no areas other than the one where there was selection pressure. This means that the successful bugs did not desperately throw off all kinds of mutations to find the one that works; they pinpointed the one alteration that fit the bill. Hall found some directed variations so complex they required the mutation of two genes simultaneously. He called that "the improbable stacked on top of the highly unlikely." These kinds of miraculous change are not the kosher fare of serial random accumulation that natural selection is supposed to run on." — Kevin Kelly
It turned out the phenomena above was mostly caused by the genome itself having evolved to evolve in specific ways when pressured by the environment. It seems that it was selected to differentially enable mutations at different locations based on the nature of selective pressure exerted by the environment. Fascinating. For a more flowery account:
"Paolo absorbed that, with the library’s help. Like Earth life, the carpets seemed to have evolved a combination of robustness and flexibility which would have maximized their power to take advantage of natural selection. Thousands of different autocatalytic chemical networks must have arisen soon after the formation of Orpheus, but as the ocean chemistry and the climate changed in the Vegan system’s early traumatic millennia, the ability to respond to selection pressure had itself been selected for, and the carpets were the result. Their complexity seemed redundant, now, after a hundred million years of relative stability – and no predators or competition in sight – but the legacy remained." — Greg Egan
Outro
A host of prosaic phenomena can be expressed in the grammar of stacked optimizers, enabling an organization of alignment proposals in a way which highlights systematic pros and cons to focus on next. Are there also other families out there at this level of abstraction? What if we considered more intricate graphs instead of mostly-linear stacks of optimizers? What optimization level was this all on even?
0 comments
Comments sorted by top scores.