Dealing with infinite entropy
post by Alex_Altair · 2023-03-01T15:01:40.400Z · LW · GW · 9 commentsContents
The problem The analogy with probability distributions Differential entropy Looking at the naive limits Conclusion None 9 comments
A major concession of the introduction post [LW · GW] was limiting our treatment to finite sets of states. These are easier to reason about, and the math is usually cleaner, so it's a good place to start when trying to define and understand a concept.
But infinities can be important. It seems quite plausible that our universe has infinitely many states, and it is frequently most convenient for even the simplest models to have continuous parameters. So if the concept of entropy as the number of bits you need to uniquely distinguish a state is going to be useful, we'd better figure out how to apply it to continuous state spaces.[1]
For simplicity, we'll just consider the case where the state space is a single real-valued parameter in some interval. Because is real-valued, its set of possible values (the "states") is infinite. Extending the results to more complex sets of states is the domain of other fields of mathematics.
The problem
If you were to play the Guess Who? game [LW · GW] with an increasing number of cards, you would need an increasing number of questions to nail down each card, regardless of what strategy you were using. The number of questions doesn't go up very fast; after all, each new question lets you double the number of cards you can distinguish, and exponents grow very fast. But, in the limit of infinite cards, you would still need infinitely many questions. So that means that if we use the yes/no questions method to assign binary string labels to the cards, we would end up with each card being represented by infinitely long strings, and therefore having infinite entropy. It ends up being equivalent to playing "guess my number" instead, where your friend could have chosen any real number between, say, 0 and 1.
This doesn't seem very useful. But it still feels like we should somehow be able to use the concept of entropy (that is, the concept of using bits to distinguish states). If your friend tends to choose numbers on the left way more often than the cards on the right, then it still seems like it should take fewer questions to "narrow in" on the chosen number, even if we can never guess it exactly.
One way we could still make use of it is to use finitely many bits to distinguish among sets of states (dropping the requirement to uniquely distinguish individual states). After all, in the real world, any measurement of a continuous parameter will return a number with only finite precision, meaning that we can only ever know that our state is within a set compatible with that measurement. That set will have infinitely many individual states, but in practice we only care about some finite measurement precision. This path of investigation will take us somewhere interesting.
A second way to handle the infinities would be to maintain unique binary strings for each state, and just see what happens to the equations as we increase the number of states to infinity. When the probability distribution is not uniform, is there a useful sense in which some of the infinities are "bigger" than others? The history of mathematics has a long tradition of making sense out of comparing infinities, and we can apply the tools that people have previously developed.
That said, really nailing these ideas down has considerable mathematical detail (and therefore considerable subtlety in exactly what they mean and what statements are true). This level of detail tends to make the conceptual content substantially less clear, so I've saved it for a future post. For now, I'd like to give you a conceptual grasp that is just formally grounded enough to be satisfying.
The analogy with probability distributions
To understand the first strategy, I think it's very useful to remember exactly how continuous probability distributions work, and then extend that mechanism to entropy.
When you first learn about probability, you typically start with discrete events. The coin flip lands on heads or tails. The die comes up on some integer between 1 and 6. There are simply finite sets of outcomes, each with a finite probability, and all the math is nice and clear. But pretty soon, you need to start being able to handle probabilities of events that are distributed smoothly over intervals. You're flipping a coin repeatedly, and trying to use the heads/tails ratio to figure out how fair it is. You throw a dart at a board and want to know the chance that you'll get within the bullseye.
But if you model the dart board the normal way, as a circle with a certain diameter, then it contains infinitely many points inside it, each of which has a 0% chance of being hit with the dart. But the dart will hit the board somewhere; what gives?
Mathematicians dealt with this by well-defining infinitesimal probabilities. They come up with a continuous function over the range of all possible outcomes, and they say that , which is to say, the probability that the outcome is between and is the area under the curve (the "probability mass") between and . These objects must obey certain axioms, et cetera. If you'd like, you can consider to be the limit of a sequence of discrete probability distributions .[2]
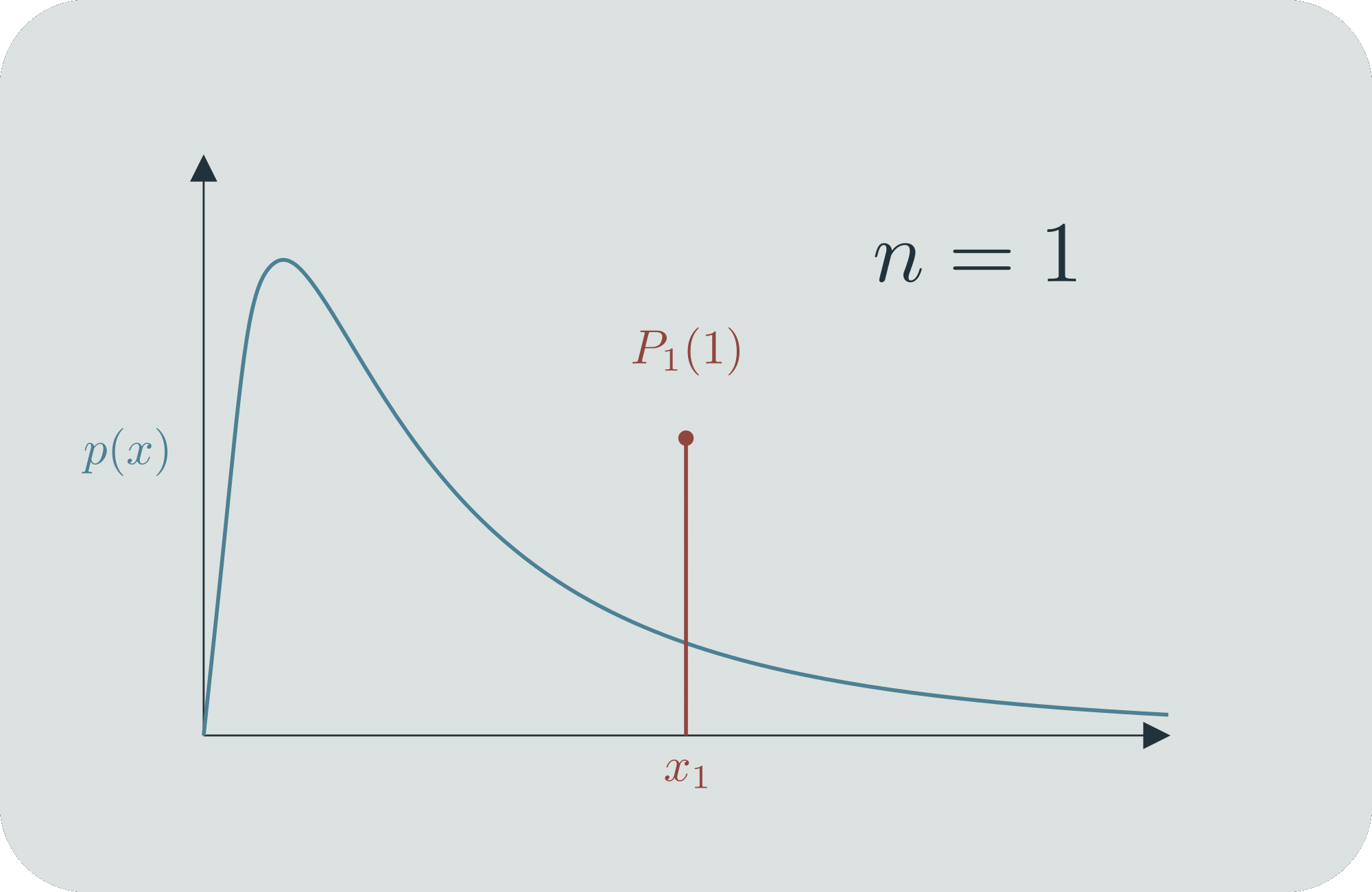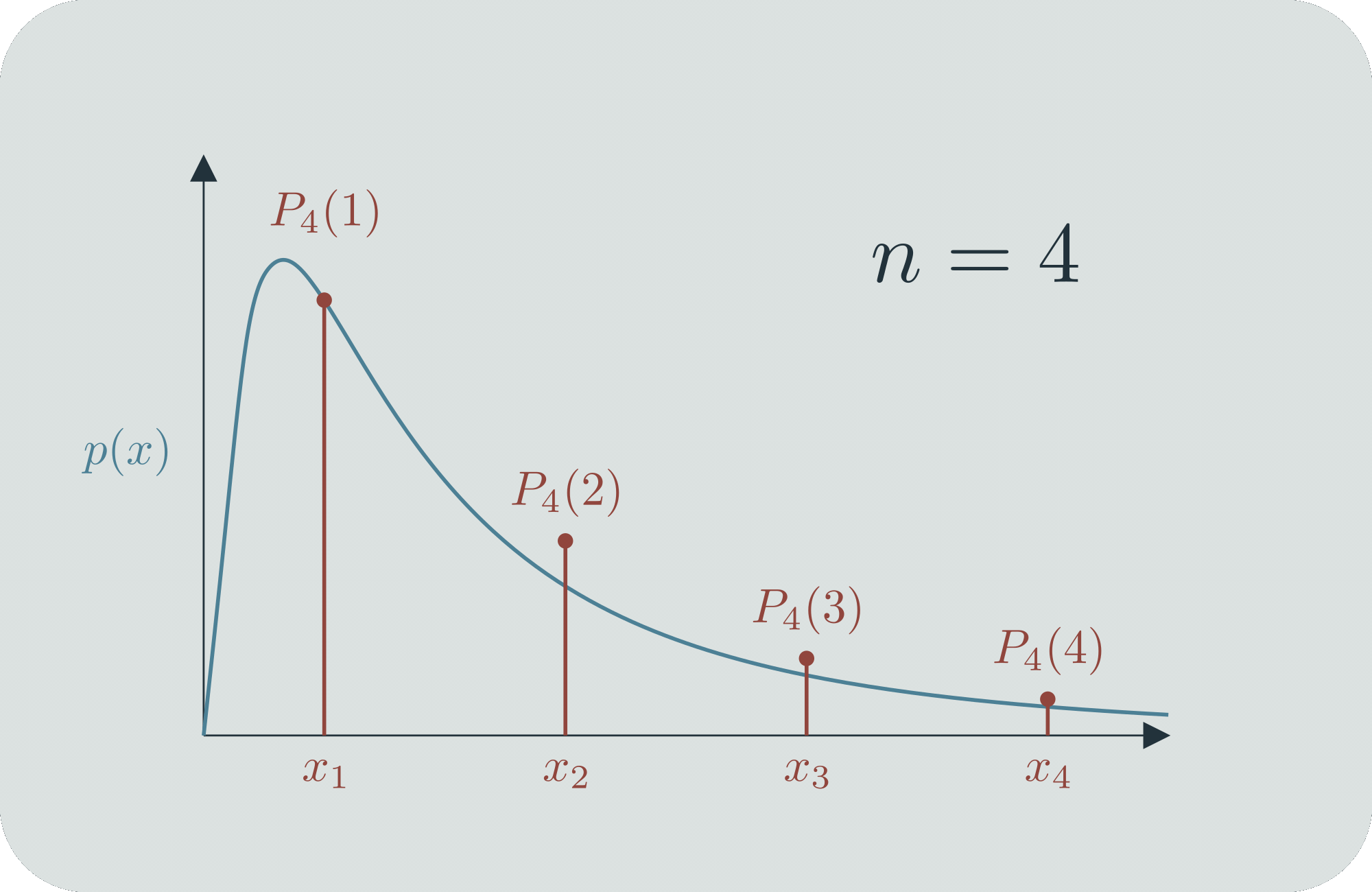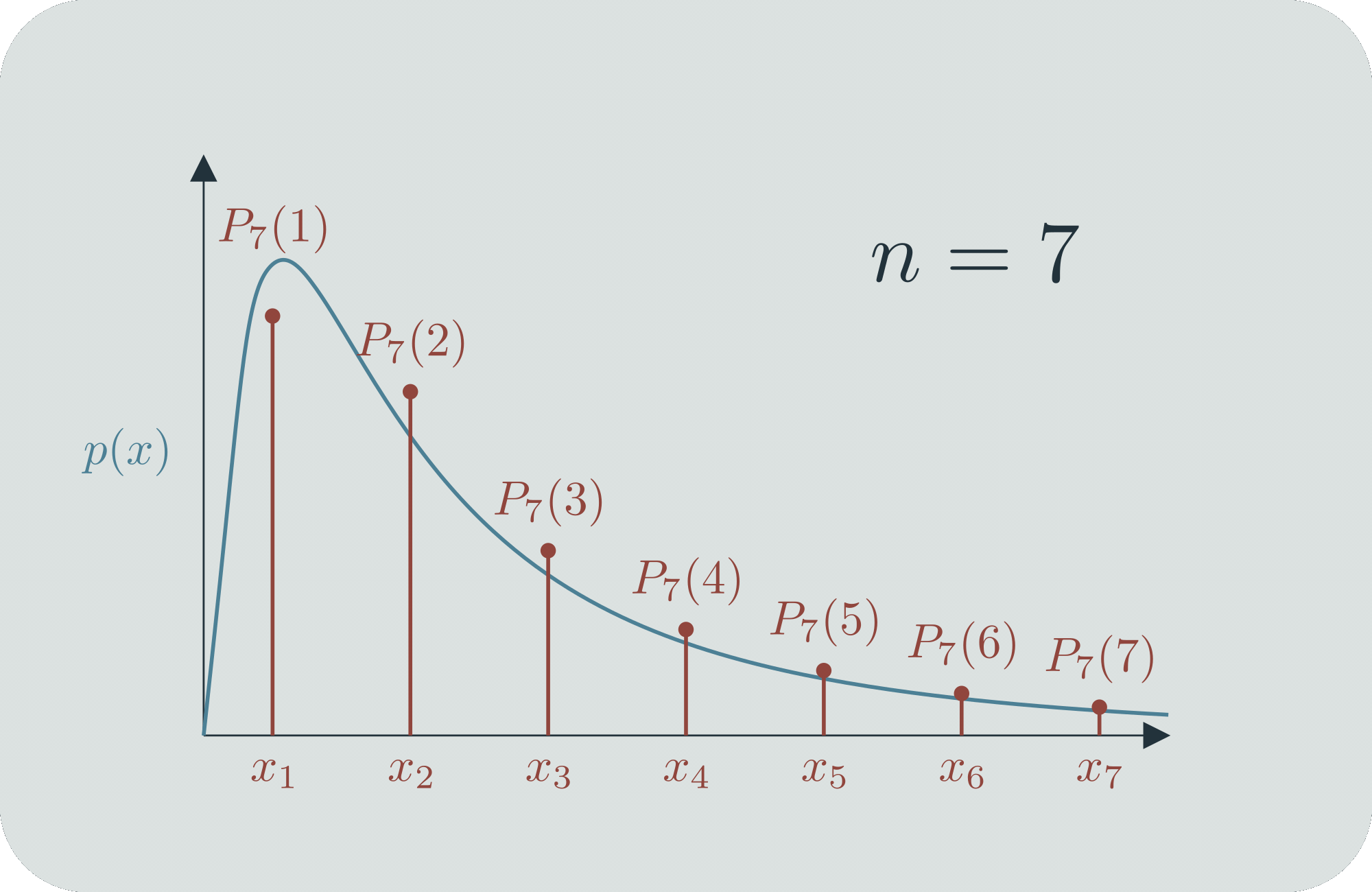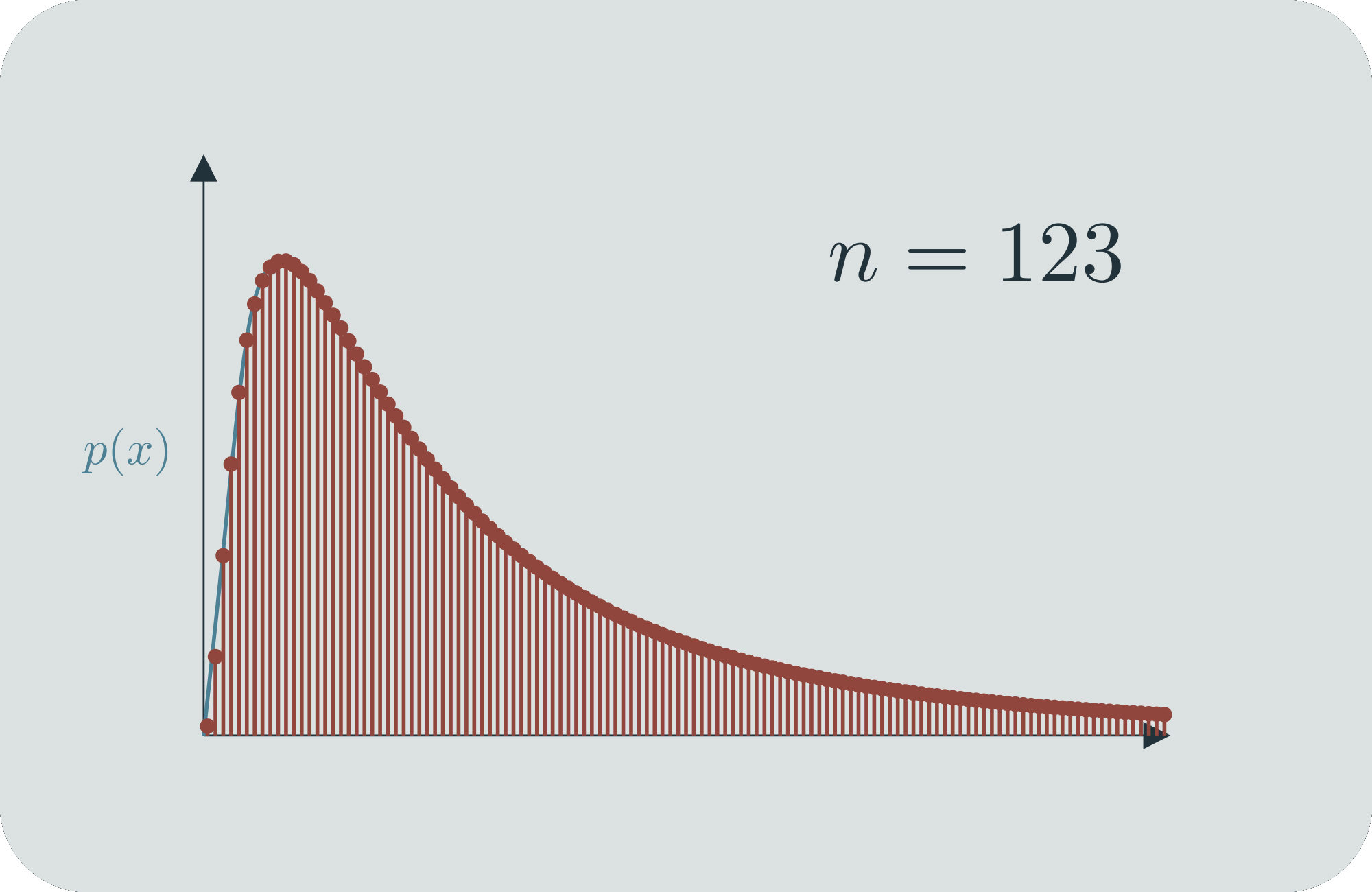
If you work with continuous probability distributions a lot, then they feel totally normal. But the whole idea behind them is quite a brilliant innovation! The fact that every specific value has infinitesimal probability can sometimes bother people when they're first learning about it, but ultimately people are content that it's well-defined via ranges. (Largely because, in practice, we can only take measurements with a certain range of precision.) You can also use it for comparisons; even though and , it's still meaningful to say that ,[3] and since is always nice and finite, that ratio will also be a nice finite number. You can use to tell, for example, when is twice as likely as .
Differential entropy
In a similar way, we can construct "continuous entropy distributions", that is, a continuous function that tells you something about how you can compare the entropy at individual values. Let's say that our states, represented by values on the -axis, occur according to the (continuous) probability distribution . We will assign binary strings to them in the following way.[4] Say that we want to figure out the binary string that belongs to a specific value . First, we find the value on the -axis that cuts the probability mass of in half; we'll call this value . If , that is, if is to the left of , then the first bit of is 0. If , then its first bit is a 1. Then we iterate. For whichever side is on, we find the next value, , which cuts that probability mass in half again (now partitioning it into areas of 1/4). We do the same bit assignment based on whether is less or more than . We can iterate this process for as long as we want, and continue getting more bits to assign to . This is our scheme for using finitely many bits to distinguish among sets of states.
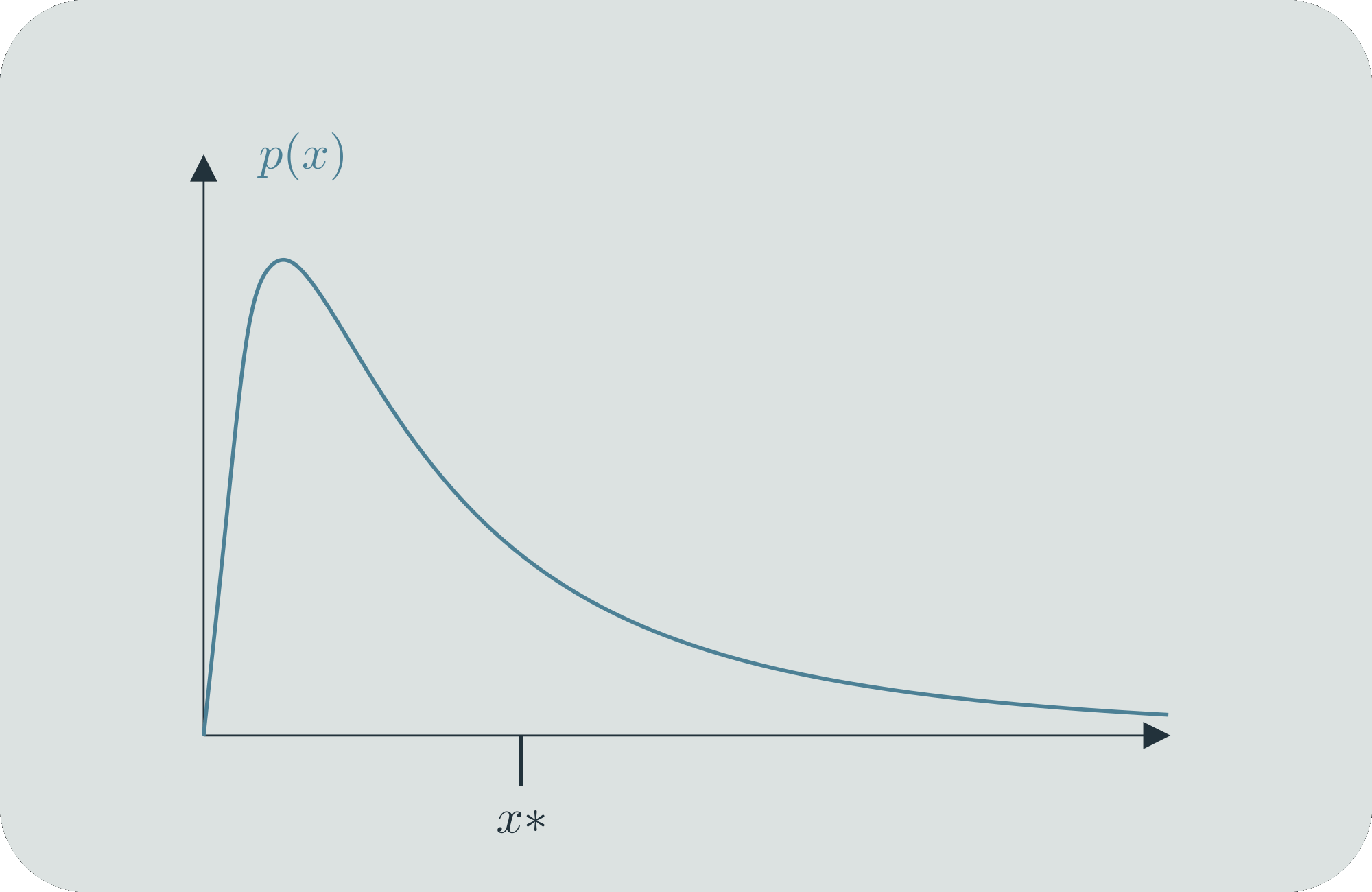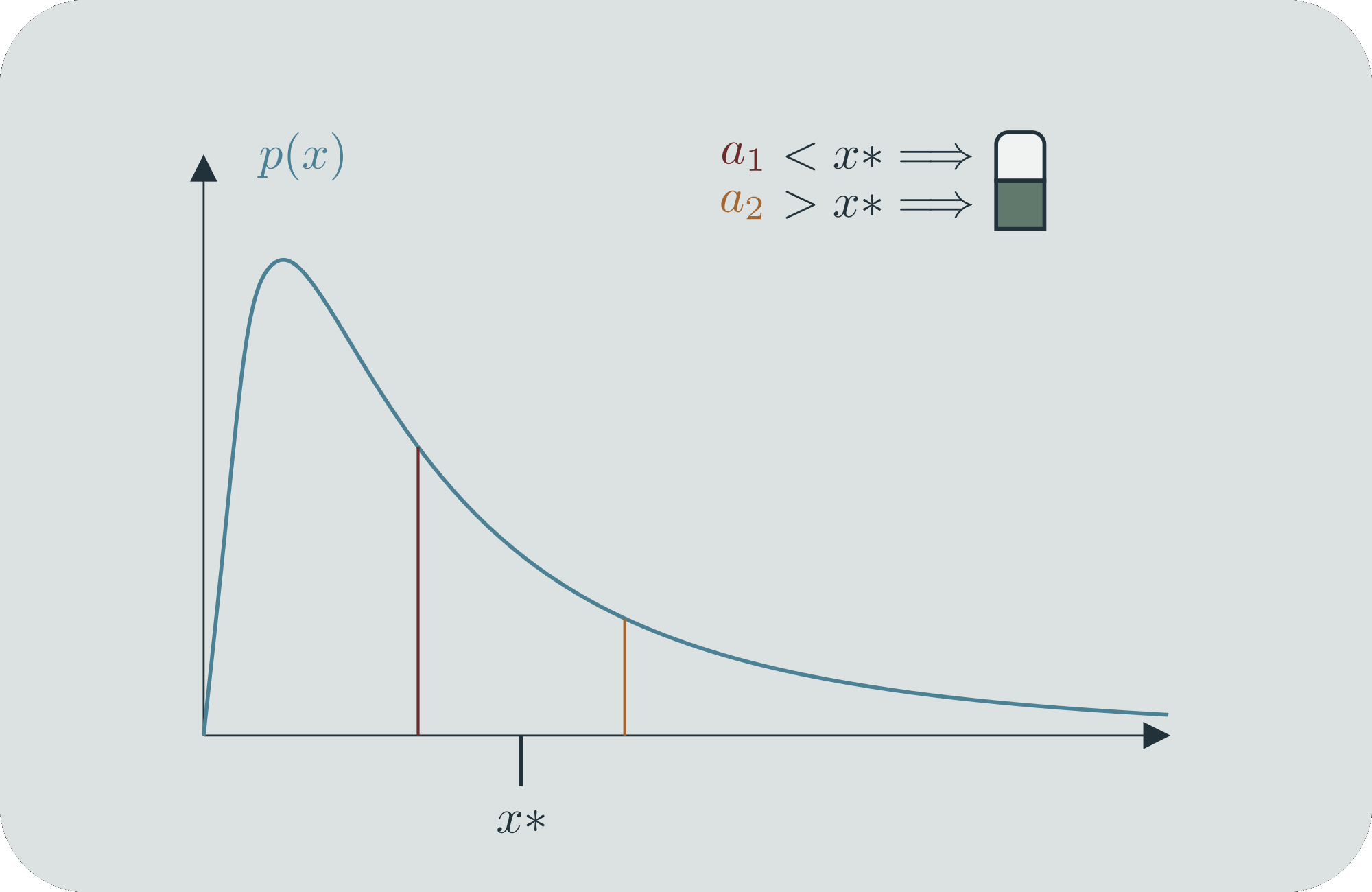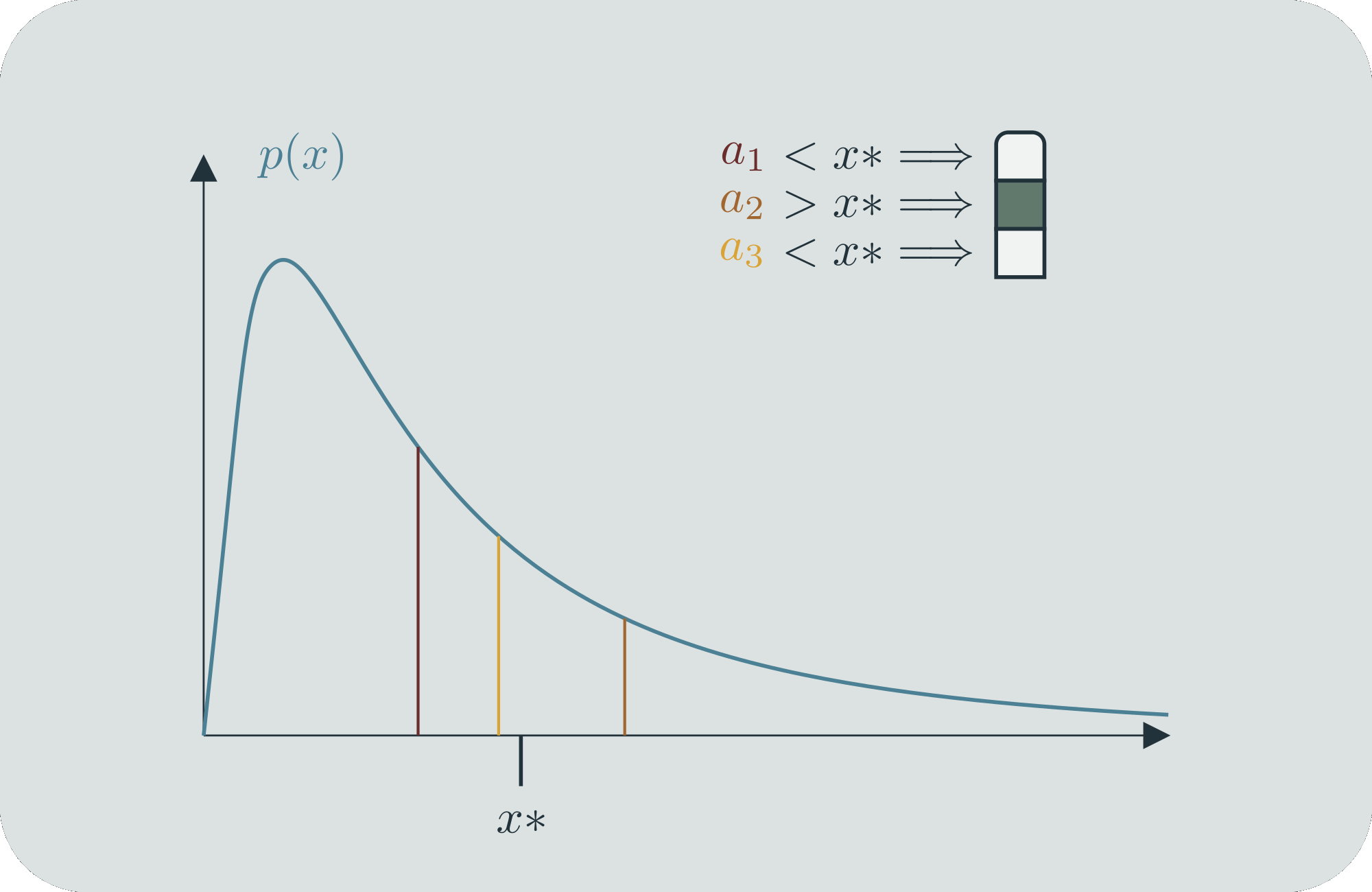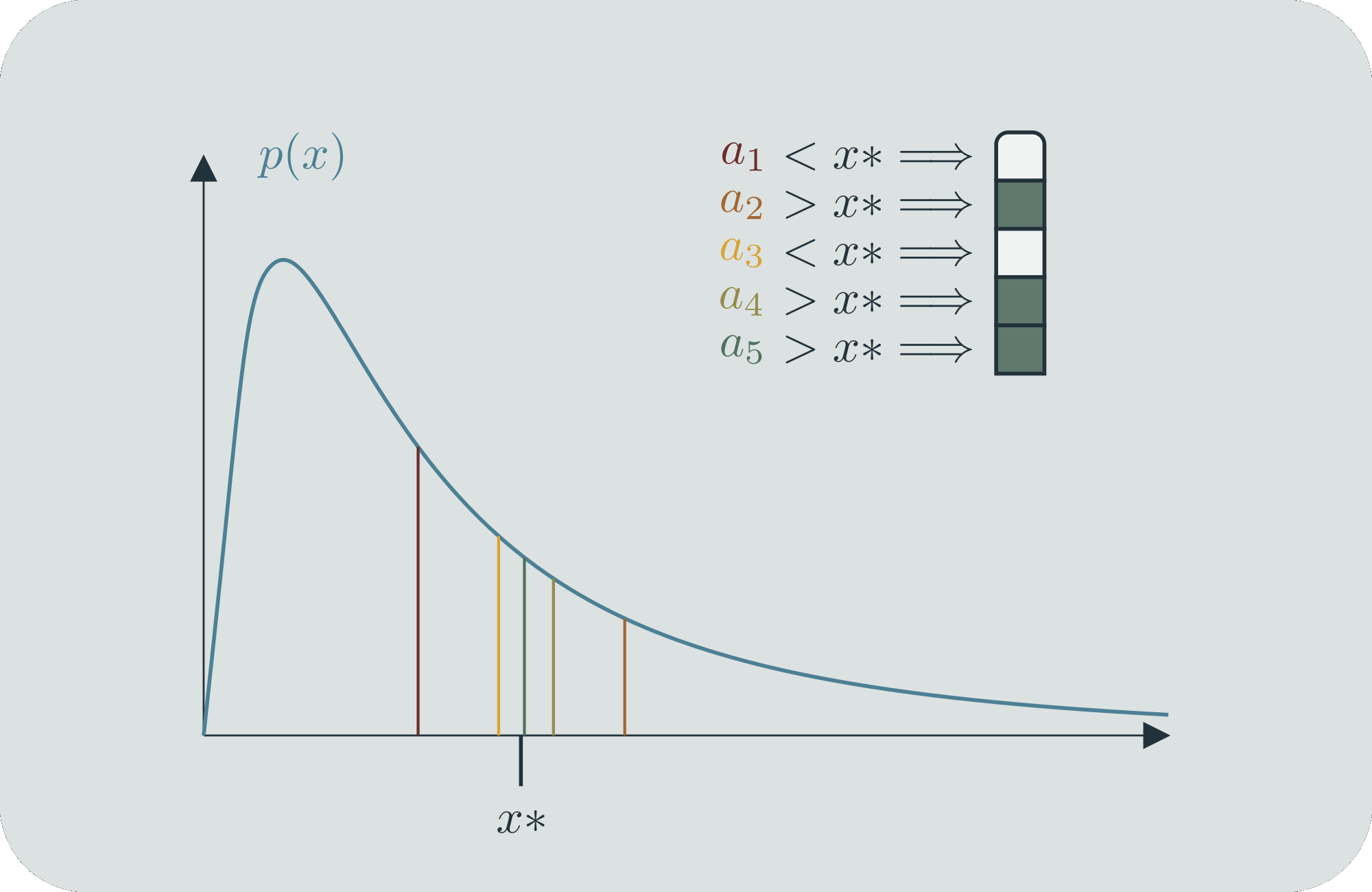
For any two different specific values of , they will eventually be on different sides of some , and thus will eventually have different binary representations. And because the probability mass is smoothly distributed over the real line, every specific will require an infinitely long binary string to locate it perfectly. But to get within a small distance of , we only need a finite number of bits. And furthermore, given a fixed , the number of bits we need is different for different s. If is large, then it will have a lot of probability mass in its immediate vicinity, and we will require less bits (=mass halvings) to get within , and inversely if is small, we will require more. Can we use this to get a finite comparative measure?
Of course, we can't really just pick a specific like 0.0001 and then use the resulting number of bits for our comparison, because for any we might pick, there exist perfectly well-behaved functions that happen to still have large fluctuations within of . It wouldn't be fair to "credit" with those probability mass fluctuations. Instead, we want to get a measure that only relies on the value exactly at .
Let's continue using the analogy with probability distributions. If, for some specific distribution , we have that , then what does that mean? Well, one thing you could say that it means is the thing about ranges and limits that I described in the above section. But another, equivalent thing you could say is that it means that events in the region of are as unlikely as any event in a uniform distribution that is equal to everywhere. Since the total area still must be 1, we can conclude that the domain of must be units wide. This kind of comparison might give you an intuition for how unlikely the event is, even if is some complicated function overall; it's like picking a random real number between 0 and 4.

Similarly, if , what does that say about how many bits we need to pinpoint within a range of ?
Well, in the limit of going to zero, it's the same number as if the distribution was . Since that means that the probability mass would be spread over an interval 4 units long, we'd need to halve it twice to get to 1 unit around . If we had , then the interval would be 2 units long, and we'd need to halve it once to get within 1. At , it would be 1 unit long, and we'd need to halve it 0 times. At , it would be half a unit long, and we'd need to halve it times.
The generalization of those is times. And since is uniform, it's okay that we only narrow it down to a range of length 1; there are no fluctuations inside that range. It's the same as the limiting behavior of , but now we can safely pick a fixed , and we might as well pick .
Because it only pinpoints to within a range, this isn't the entropy of (in the same way that is not the probability of ). So let's call it the "differential" entropy, and give it a lowercase letter[5] (like how we sometimes use instead of );
And then the expected value is just
which could be considered the differential entropy of all of , rather than just of .
In this sense then, the differential entropy of a continuous-valued is the number of bits you need to specify a range of size 1 containing . To complete the analogy with probability distributions:
- , but
- , but .
This quantity seems quite useful to me. It's conveniently not a function of anything other than the value of at . As a consequence though, it might not be quite the right comparison in some occasions. Let's say you have two distributions, defined on and defined on . Perhaps is uniform, but is non-uniform in a way that gives it exactly the same as . The value of is sort of mushing together these two factors, and cancelling them out in a certain way. Perhaps we'd like to better understand their individual contributions.
Looking at the naive limits
Now let's consider a second strategy for dealing with the entropy of infinite sets. What does happen if we just plow ahead and take the limit as the set size goes to infinity? The detailed post contains the derivations; here I'll just give you the setup and the conclusions.
What we want is to extend the notion of entropy to a continuous probability distribution defined over an infinite set of s. So, as mentioned above, we'll say that is defined as the limit of discrete probability distributions , where the s pack into the same range that the s run over. Since our entropy is already defined for discrete distributions, we can simply consider the limit of the entropy of those distributions.
The notation here will be dissatisfying. These derivations have a ton of moving parts, and devoting notation for each part leads to a panoply of symbols. So consider all these equations to be glosses.
For the entropy of a single state, the limit looks like this;
We've switched to a capital because this is a proper entropy, and not a differential entropy. is the th discrete distribution, so it changes at each step in the limit. There's a lot of machinery required to specify how the limit works, but conceptually, what matters is that converges to as discussed above. That means that the number of states that assigns a chunk of probability mass to must increase, and that said states must eventually "fill in" the part of the -axis that is defined over. For any given , we don't need it to put one of its mass chunks exactly on our specific , so the is intending to connote that we're talking about whatever chunk is nearest to our specific .
Because it's discrete, each value of is finite. But since the total probability mass is getting divvied up between more and more states, each value gets smaller, and eventually goes to zero. Then our limit is effectively , which tells us what we knew in the beginning; the number of bits needed to pinpoint one state is infinite. The expected value also diverges;
(Although that's less clear from just looking at it: derivation in the longer post).
However, once you pick a specific sequence of s and a specific strategy for placing the s, then the limit can always be naturally manipulated into this form:
Each of these terms has a semantic interpretation;
- is the differential entropy we discussed above, and so we've already given it a meaning! Also, it's only a function of , and it's finite.[6]
- is a term that depends on how exactly you take the limit (but not on [6]) and is also finite.
- and is exactly what it looks like; a diverging limit that depends only on .
I find this decomposition to be particularly elegant and satisfying!
Here's what really fascinates me about it; since and are both finite, all of the divergence is contained in the last term, which is independent of both and the details of our limit-taking!
This makes it really easy to compare the entropy of two continuous distributions; you can just look at and !
Simply evaluating [7] will tell you how many more bits it will take to uniquely distinguish a value from the first distribution compared to the second distribution, even though it still takes infinite bits to represent each individual .
And if you take the limit in the same way, then the s cancel out as well. Looking back at our definition of , if you're concerned with individual values of , then
And if you're looking at expected values, then – well, then you encounter an interesting subtlety, which I will save for the detailed post (or perhaps as an exercise for the reader).
Conclusion
Now that we've reached the end, it's worth reflecting on what this all means. So we've found a way to finitely compare states with infinite entropies; does that really make it a valid model of the real world?
Here's how I see it. Imagine a world where all the people live in the tops of skyscrapers. They've never seen the ground. They don't know that there's no ground, that the skyscrapers have "infinite" height. But as many stories as anyone has ever gone down, they still look out the window and see the walls receding below them.
So it at least seems plausible that the skyscrapers are all infinitely tall. Despite that, they still clearly have their top floors at different heights! If you're on the roof of one skyscraper, you can see that some others' roofs are lower, and some are higher. Even though they don't know where the bottom is, it's still valid to ask how much taller one building is than another, or how many stories you have to climb to get to another floor. The people can agree to define a particular height as the zeroth story, and number all the other stories with respect to that one.
In our world, we can tell that physical properties can differ across extremely small distances. We can measure down to a certain precision, but who could ever say when we hit the "bottom"? And yet, we can still ask whether two states differ within a given precision, or how many bits it would take to describe a state to within a given precision. We can agree to define a given distance as the unit meter, and measure things with respect to that.
Their skyscraper stories are the exponent of our meters. Their stories are our bits of information.

- ^
There is a way in which you can have an infinite set of states, each of which has finite entropy; after all, there are infinitely many binary strings of finite length. This, however, is a countable infinity. In this post we will be talking about intervals of the real numbers,[8] which means we're talking about uncountably infinitely many states. There are uncountably many binary strings of (countably) infinite length, which is why this works at all. (Technically, given an uncountable set, you could go ahead and assign all the finite strings to a countable subset, which would mean that some of the states would get finite entropy; but that's not very useful, and would violate some of our other premises.)
- ^
This animation represents one possible way to define a set of which converge to , where the point masses are equally spaced with different mass. Another option would be to have them equally massed at , but denser where is greater. Intermediates are also possible.
- ^
This works out because, for sufficiently well-behaved , we could say that
By the definition of how is constructed, this is equal to
And because of how integrals work, in the limit this simplifies to
- ^
This is, of course, only one possible way to use bits to distinguish states. But it's a way that I think is easier to follow, and, assuming that the "true" distribution of is , this will also be the bit assignment that minimizes the entropy.
- ^
The letter or is commonly used for entropy in information theory, whereas is more common in physics.
- ^
A couple caveats; if you're using the expected value of , then and are of course also a function of . And there do exist pathological s where is infinite.
- ^
In a similar fashion as footnote 3, what we're actually doing here is an outside limit. Instead of this,
we mean this;
This latter expression is what can be formally manipulated into . This is essentially saying that as long as we take the limit in the same way for both probability distributions, then the infinities cancel out.
- ^
I can't resist adding another mathematical disclaimer here. The purpose of this post is to allow us to apply entropy to realistic models of the physical world. Typically, people use the real numbers for this. But another option could be to use sets that are simply dense, meaning that all points have other points arbitrarily close to them. This set could be countable (like the rationals), which means we could use only finite binary strings for them. However, if you try to stuff all the finite binary strings into a dense interval like this, then you lose continuity; if some is given a string of length 6, zooming in closer to the -neighborhood around will reveal states with arbitrarily long strings, rather than strings whose length gets closer to 6. (This is similar to how, the closer you zoom into , the larger the denominators of nearby rationals will be.) Realistic models of the world will assume continuity, ruling out this whole scheme.
9 comments
Comments sorted by top scores.
comment by Martín Soto (martinsq) · 2023-03-02T00:11:37.955Z · LW(p) · GW(p)
Great post!
, but
Isn't this 2e? Or maybe you just wanted to ignore the constant.
comment by Dagon · 2023-03-01T16:16:09.691Z · LW(p) · GW(p)
What's your reason to claim/believe that the state space is literally infinite, rather than "just" insanely large? How do we know that parameters are truly real-valued, rather than quantized at some level of granularity?
Replies from: interstice, Gurkenglas, sharmake-farah↑ comment by interstice · 2023-03-01T19:19:17.825Z · LW(p) · GW(p)
Continuity/infinity could still be useful as modelling tools for creatures living in an ultimately discrete universe.
↑ comment by Gurkenglas · 2023-03-01T18:51:47.743Z · LW(p) · GW(p)
If it's possible, our math should model it.
Replies from: Dagon↑ comment by Dagon · 2023-03-01T19:07:10.597Z · LW(p) · GW(p)
Hmm. I'm not sure I understand what you mean by "possible" or "should" enough to know how to apply it here. If it's not the case that entropy is literally infinite in possible quantities, is it still possible just because we don't know it's not the case? We know from Godel that math is either incomplete or inconsistent, so what form of "should" is contained in "can't"? I'm not sure even what "model" means here - math doesn't model anything, it stands on it's own axioms. Models tie math to reality (or at least predictions of observations), imperfectly.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2023-03-01T20:43:34.996Z · LW(p) · GW(p)
I suspect "no math handles all worlds" is fully addressed by a size parameter, letting the remainder of the math stay constant.
What we set it to comes down to Bayes. Let's not assign probability 0 to a live hypothesis.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-01T19:30:12.222Z · LW(p) · GW(p)
Basically, because of geometry and the fact that our best theories for how quantum gravity works rely on space being continuous rather than discretely quantized.
There are 3 geometries of the universe, and 2 of them are infinite: flat and hyperbolic. The spherical geometry is finite. Most cosmological evidence suggests we live in the flat universe, which is infinite.
Finally, one of the theories which asserts that space is quantized, loop quantum gravity, has a dealbreaker in that it's difficult to reproduce general relativity at the areas it's known to work.
That's why I believe the universe is infinite, rather than truly large.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2023-03-01T21:19:36.065Z · LW(p) · GW(p)
That physical constants support life suggests that, elsewhere, they don't. On which Tegmark level would you expect this elsewhere to be?
comment by Richard_Kennaway · 2023-03-02T08:28:34.283Z · LW(p) · GW(p)
I think one can justify using continuous methods without depending on whether the universe itself is made of continuous structures. If everything is imagined to be discrete, but you don't know the scale of the discreteness other than it being much smaller than anything we can observe, then smooth manifolds are the way to formalise that. Even where we can observe the discreteness, such as fluids being made of atoms, the continuous model still works for most practical purposes, especially when augmented with perturbation methods when the mean free path is of a small but macroscopic size. No ontological commitment to continuity is needed. Continuity is instead the way to think about indefinitely fine division.