Introduction to abstract entropy
post by Alex_Altair · 2022-10-20T21:03:02.486Z · LW · GW · 78 commentsContents
Introduction & motivation Abstract definition The entropy of a state is the number of bits you need to use to uniquely distinguish it. Macrostates Two basic strategies for distinguishing states Binary string labels Yes/no questions How they compare Exactly what is a bit? Probabilities over states Negentropy What's next None 78 comments
This post, and much of the following sequence, was greatly aided by feedback from the following people (among others): Lawrence Chan [LW · GW], Joanna Morningstar [LW · GW], John Wentworth [LW · GW], Samira Nedungadi [LW · GW], Aysja Johnson [LW · GW], Cody Wild [LW · GW], Jeremy Gillen [LW · GW], Ryan Kidd [LW · GW], Justis Mills [LW · GW] and Jonathan Mustin [LW · GW].
Introduction & motivation
In the course of researching optimization, I decided that I had to really understand what entropy is.[1] But there are a lot of other reasons why the concept is worth studying:
- Information theory:
- Entropy tells you about the amount of information in something.
- It tells us how to design optimal communication protocols.
- It helps us understand strategies for (and limits on) file compression.
- Statistical mechanics:
- Entropy tells us how macroscopic physical systems act in practice.
- It gives us the heat equation.
- We can use it to improve engine efficiency.
- It tells us how hot things glow, which led to the discovery of quantum mechanics.
- Epistemics (an important application to me and many others on LessWrong):
- The concept of entropy yields the maximum entropy principle, which is extremely helpful for doing general Bayesian reasoning.
- Entropy tells us how "unlikely" something is and how much we would have to fight against nature to get that outcome (i.e. optimize).
- It can be used to explain the arrow of time.
- It is relevant to the fate of the universe.
- And it's also a fun puzzle to figure out!
I didn't intend to write a post about entropy when I started trying to understand it. But I found the existing resources (textbooks, Wikipedia, science explainers) so poor that it actually seems important to have a better one as a prerequisite for understanding optimization! One failure mode I was running into was that other resources tended only to be concerned about the application of the concept in their particular sub-domain. Here, I try to take on the task of synthesizing the abstract concept of entropy, to show what's so deep and fundamental about it. In future posts, I'll talk about things like:
- How abstract entropy can be made meaningful on continuous spaces [LW · GW]
- Exactly where the "second law of thermodynamics"[2] comes from, and exactly when it holds (which turns out to be much broader than thermodynamics)
- How several domain-specific types of entropy relate to this abstract version
Many people reading this will have some previous facts about entropy stored in their minds, and this can sometimes be disorienting when it's not yet clear how those facts are consistent with what I'm describing. You're welcome to skip ahead to the relevant parts and see if they're re-orienting; otherwise, if you can get through the whole explanation, I hope that it will eventually be addressed!
But also, please keep in mind that I'm not an expert in any of the relevant sub-fields. I've gotten feedback on this post from people who know more math & physics than I do, but at the end of the day, I'm just a rationalist trying to understand the world.
Abstract definition
Entropy is so fundamental because it applies far beyond our own specific universe, the one where something close to the standard model of physics and general relativity are true. It applies in any system with different states. If the system has dynamical laws, that is, rules for moving between the different states, then some version of the second law of thermodynamics is also relevant. But for now we're sticking with statics; the concept of entropy can be coherently defined for sets of states even in the absence of any "laws of physics" that cause the system to evolve between states. The example I keep in my head for this is a Rubik's Cube, which I'll elaborate on in a bit.
The entropy of a state is the number of bits you need to use to uniquely distinguish it.
Some useful things to note right away:
- Entropy is a concrete, positive number of bits,[3] like 4, 73.89, or .
- Its definition does not rely on concepts like heat or energy, or a universe with spatial dimensions, or even anything to do with random variables.
- You're distinguishing the state from all the other states in a given set. Nothing about the structure or contents of this set matters for the definition to be applicable; just the number of things in the set matters.
- Entropy depends on an agreed-upon strategy for describing things, and is "subjective" in this sense.
But after you agree on a strategy for uniquely distinguishing states, the entropy of said states becomes fixed relative to that strategy (and there are often clearly most-sensible strategies) and thus, in that sense, objective. And further, there are limits on how low entropy can go while still describing things in a way that actually distinguishes them; the subjectivity only goes so far.
Macrostates
I just defined entropy as a property of specific states, but in many contexts you don't care at all about specific states. There are a lot of reasons not to. Perhaps:
- They're intractable to ever learn, like the velocity of every particle in a box.
- You're not even holding a specific state, but are instead designing something to deal with a "type" of state, like writing a compression algorithm for astronomical images.
- There are uncountably many states [LW · GW].
- Every state is just as good to you; you don't care to assign any states lower entropy than others.
In cases like these, we only care about how many possible states there are to distinguish among.
Historically, the individual states are called microstates, and collections of microstates are called macrostates. Usually the macrostates are connotively characterized by a generalized property of the state, like "the average speed of the particles" (temperature). In theory, a macrostate could be any subset, but usually we will care about a particular subset for some reason, and that reason will be some macroscopically observable property.
Two basic strategies for distinguishing states
I would say that any method used to distinguish states forms a valid sub-type of entropy. But there are a couple really fundamental ones that are worth describing in detail. The first one I'll talk about is using finite binary strings to label each individual state. The second one is using yes/no questions to partition sets until you've identified your state. (Note that both these methods are defined in terms of sets of discrete states, so later I'll talk [LW · GW] about what happens in continuous spaces. A lot of real-world states have real-valued parameters, and that requires special treatment.)
Binary string labels
In order to be able to say which of the possible states a system is in, there has to be some pre-existing way of referring to each individual state. That is, the states must have some kind of "labels". In order to have a label, you'll need some set of symbols, which you put in sequence. And it turns out that anything of interest to us here that could be done with a finite alphabet of symbols can also be done with an alphabet of only two symbols,[4] so we will spend the whole rest of this sequence speaking in terms of binary.[5]
It would be parsimonious to use the shortest descriptions first. Fewer symbols to process means faster processing, less space required to store the labels, et cetera. So we'll label our states starting from the shortest binary strings and working our way up.
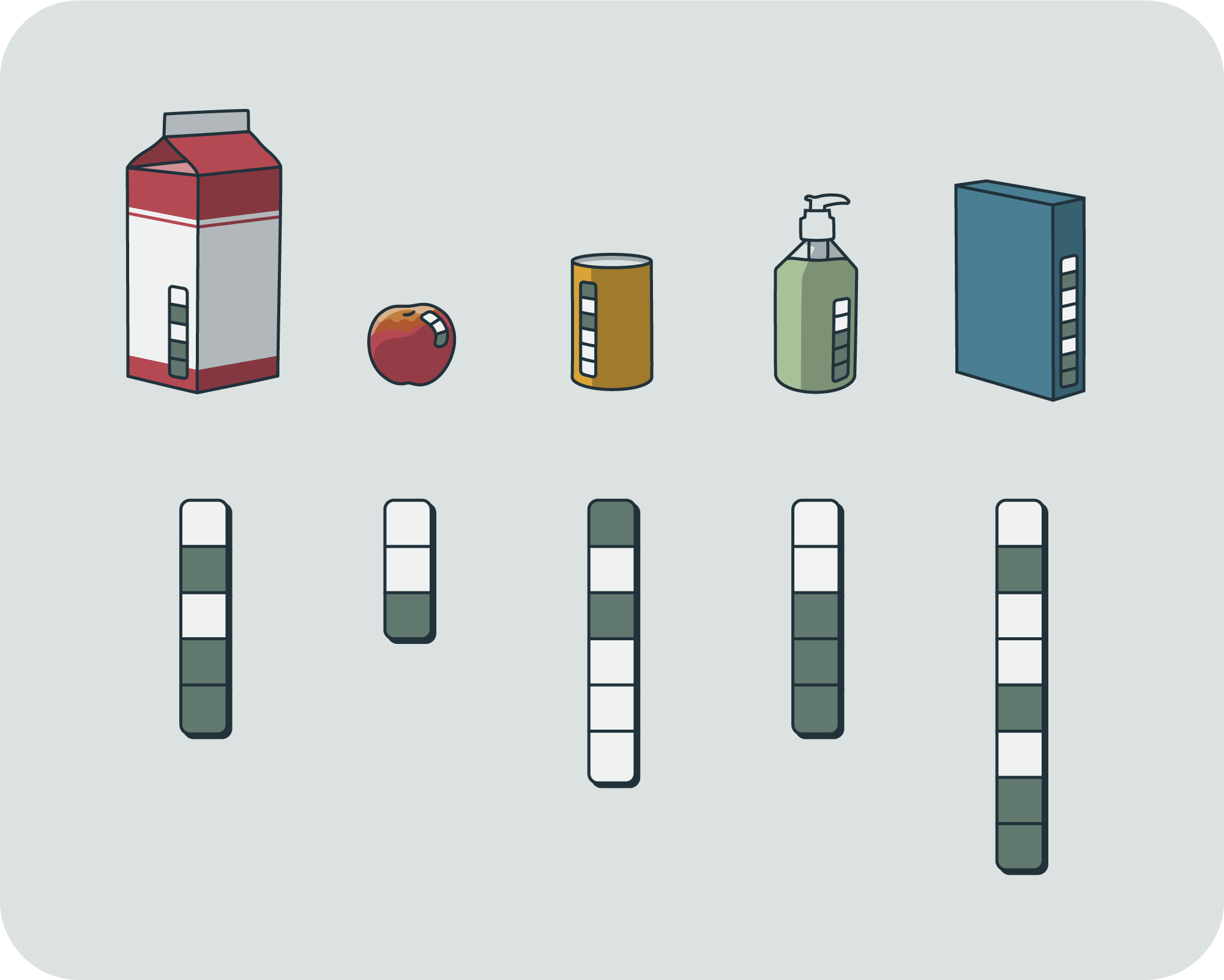
Here's where we can see one way in which entropy is subjective. For any given set of states, there are many ways to give labels to the individual elements – you can always just swap the labels around. In contexts where quantities of entropy are treated as objective, that's because the context includes (explicitly or implicitly) chosen rules about how we're allowed to describe the states. On top of that, while you can swap labels, there are limits to how few bits we can use overall. You could always choose a state-labeling scheme that uses more bits, but there is a minimum average number of bits we can use to describe a certain number of states (i.e. the number we get by using the shortest strings first). Often, when talking about entropy, it's an implicit assumption that we're using a maximally efficient labeling.
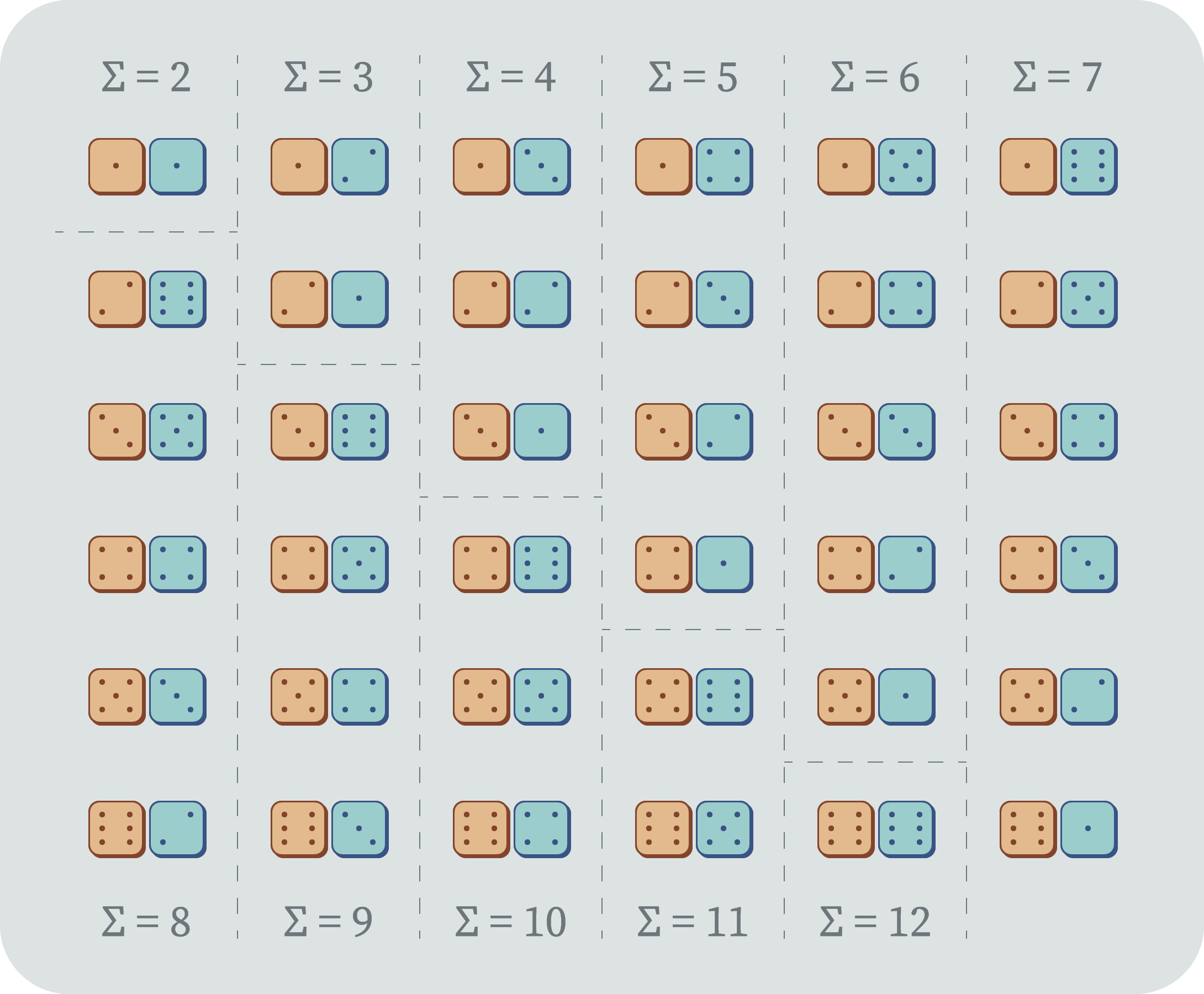
Let's get a tiny bit more concrete by actually looking at the first several binary strings. The first string is the "empty" string, with no characters, which therefore has length 0. Next, there are only two strings which have a length of 1: the string 0 and the string 1. This means that, no matter what my system is, and no matter how many states it has, at most two states could be said to have an entropy of 1. There are twice as many strings with length 2: 00, 01, 10, and 11. Thus, there are (at most) four states that could be said to have entropy 2. For every +1 increase in entropy, there are twice as many states that could be assigned that entropy, because there are twice as many binary strings with that length.[6]
I think it's easy for people to get the impression that the rarity of low-entropy states comes from something more complex or metaphysical, or is tied to the nature of our universe. But it turns out to be from this simple math thing. Low-entropy states are rare because short binary strings are rare.
To be more concrete, consider the Rubik's Cube. As you turn the faces of a Rubik's Cube, you change the position and orientation of the little sub-cubes. In this way, the whole cube could be considered to have different states. There's no law that dictates how the cube moves from one state to the next; you can turn the faces however you want, or not at all. So it's not a system with a time-evolution rule. Nonetheless, we can use the concept of entropy by assigning labels to the states.
Intuitively, one might say that the "solved" state of a Rubik's Cube is the most special one (to humans). Turning one side once yields a state that is slightly less special, but still pretty special. If you turn the sides randomly twenty times, then you almost certainly end up in a state that is random-looking, which is to say, not special at all. There are about possible Rubik's Cube states, and the log of that number is about 65.2[7]. Thus, a random Rubik's Cube state takes about 65 bits to specify.[8]



According to our above string-labeling, the solved state would have zero entropy. Similarly intuitively, almost-solved states would have almost-zero entropy. So if you turned one side a quarter turn, then maybe that state gets labeled with one bit of entropy. Perhaps we could carry on with this scheme, and label the states according to how many moves you need to restore the cube from that state to the solved state.[9] There's nothing normative here; this just seems like a useful thing to do if you care about discussing how to solve a Rubik's Cube. You could always randomly assign binary strings to states. But we rarely want that; humans care a lot about patterns and regularities. And this is how entropy comes to be associated with the concept of "order". The only reason order is associated with low entropy is because ordered states are rare. The set of ordered states is just one particular set of states that is much smaller than the whole set. And because it's a smaller set, we can assign the (intrinsically rare) smallest strings to the states in that set, and thus they get assigned lower entropy.
You might object that ordered states are a very special set! I would agree, but the way in which they are special has nothing to do with this abstract entropy (nor with the second law). The way in which they are special is simply the reason why we care about them in the first place. These reasons, and the exact nature of what "order" even is, constitute a whole separate subtle field of math. I'll talk about this in a future post; I think that "order" is synonymous with Kolmogorov complexity. It's somewhat unfortunate how often entropy and order are conflated, because the concept of order can be really confusing, and that confusion bleeds into confusion about entropy. But it's also worth noting that any reasonable definition of order (for example, particles in a smaller box being more ordered than particles in a bigger box, or particles in a crystal being more ordered than particles in a gas) would be a consistent definition of entropy. You'd just be deciding to assign the shorter labels to those states, and states that are "ordered" in some other way (e.g. corresponding to the digits of ) wouldn't get shorter labels. But this is fine as long as you remain consistent with that labeling.
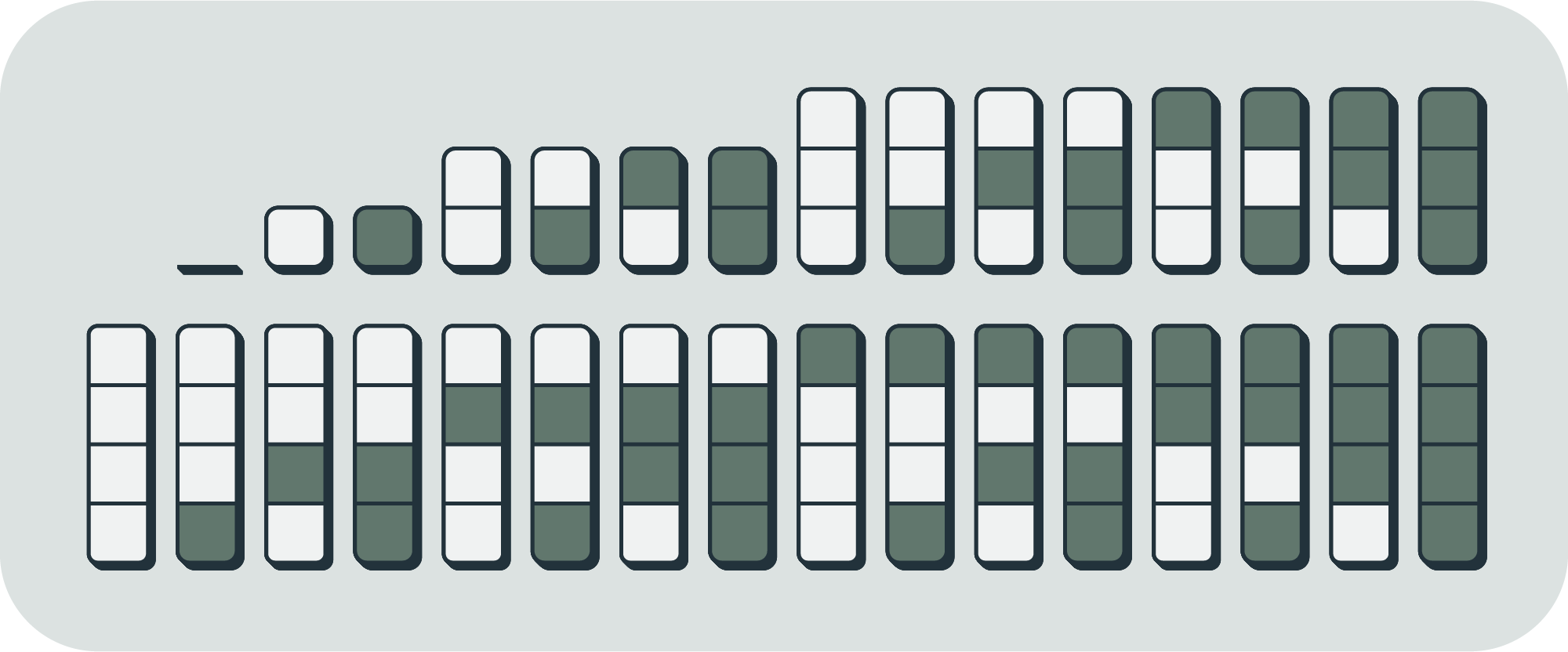
The binary string labeling scheme constitutes a form of absolute lower bound on average (or total) entropy. We can calculate that bound by summing the lengths of the first binary strings and dividing by .[10] Let be the entropy of a set of states, and let be the length of the th binary string. Then the average is by definition
By looking at the above image of the first 31 binary strings, we can see that for ,
which is to say that you can sum all the lengths by breaking it up into terms of each length times the number of strings of that length (). Next, it can be shown by induction that that sum has a closed form;
Substituting back in , dividing by , and doing algebraic manipulation, we get that
This is a very tight inequality. It's exact when , and is monotonic, and grows very slowly.
The three terms are ordered by their big-O behavior. In the limit of large numbers of states, we really don't care about the smaller terms, and we use . Thus, the average entropy grows as the length of the longest strings in the set.
Yes/no questions
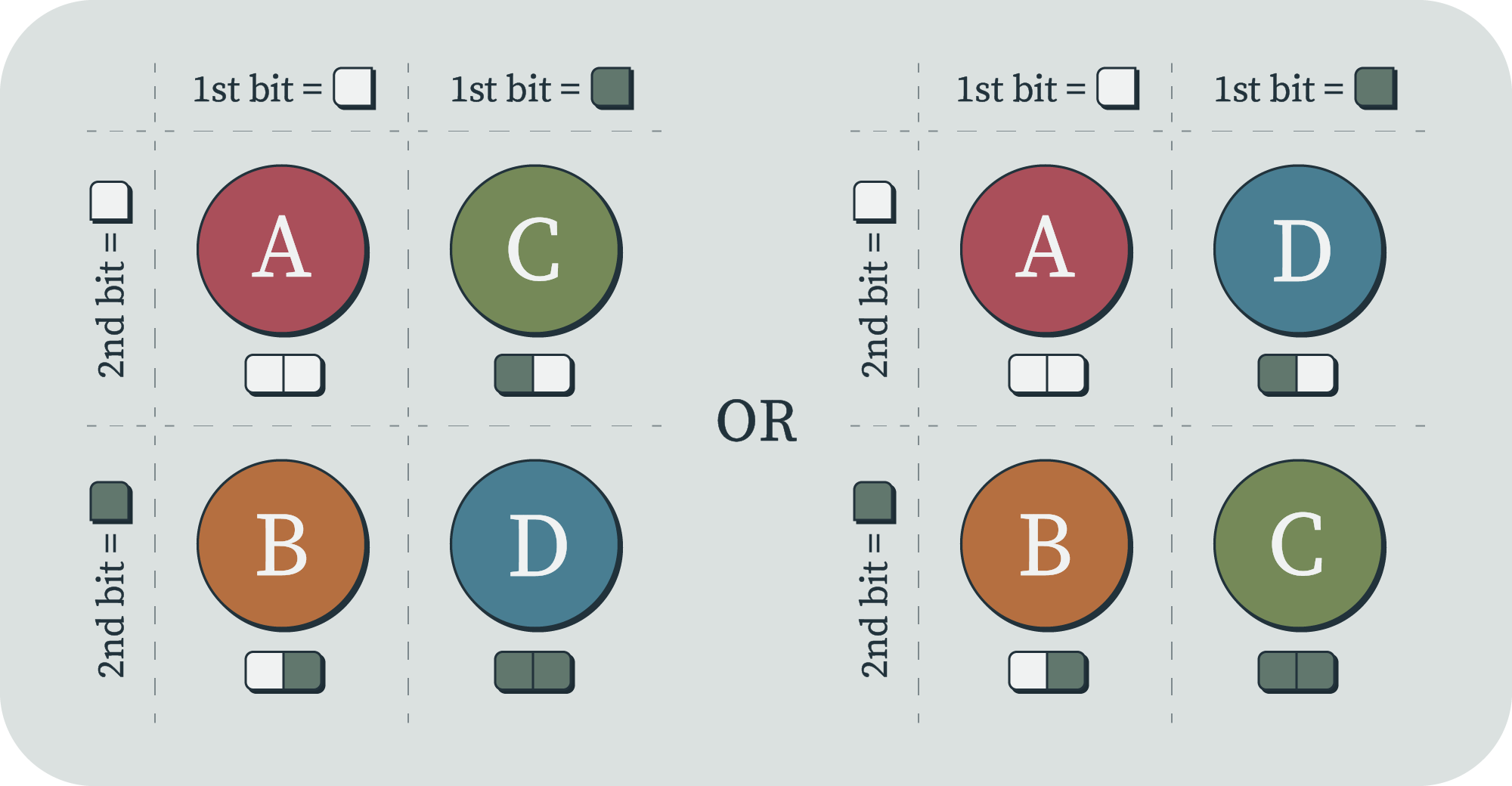
There's another very natural way we could use bits to distinguish one state from a set of states (especially when all the states are the same to us). This method is identical to the kids' game Guess Who?. In this game, you and your opponent each pick a person card from a fixed set of possible person cards. Then you try to guess which card your opponent has picked by asking yes-or-no questions about the person, like, "Do they have blonde hair?". You each have a board in front of you with copies of all the cards, so you can flip down the ones you've eliminated (which is highly satisfying). The way to minimize the expected number of questions you'll need to guess the person[11] is to ask questions that eliminate half[12] the remaining possible cards. If you start with cards, then this will require questions, and therefore you'll use bits of information to pinpoint a state, making your entropy equal to . This is your entropy for every specific card; you never assign a card zero entropy.

This way of measuring entropy is usually more useful for macrostates, because typically we have a huge number of microstates in a macrostate, and we don't care about any of the individual ones, just how many there are. So to assign entropy to a microstate in this case, we just look at which macrostate it's in (e.g. check its temperature), calculate the number of possible microstates that are consistent with that macrostate, and take the log.
If a Rubik's Cube is in the macrostate of being one move away from solved, then (since there are 12 such (micro)states) according to the yes/no questions method of assigning entropy, that macrostate has an entropy of bits. The number of microstates in the macrostate "one face is solved" is much, much higher, and so that macrostate has a much higher entropy. As we'll talk about in a later post, increased temperature means an increased number of possible microstates, so a higher-temperature object has higher entropy.
How they compare
You may notice that while the binary string model gives us entropy, the yes/no question model gives us exactly [13]. This reveals an underlying subtlety about our models. The label-assignment form of entropy is somewhat less than the binary questions form of entropy. Both are formalizations of the number of bits you need to describe something. But the question-answering thing seems like a pretty solidly optimal strategy; how could you possibly do it in fewer bits?
Imagine that the questions are fixed. For every state (e.g. Guess Who? card), the answers to the series of questions are just a list of yeses and nos, which is the same as a binary string. So each state could be said to be labeled with a binary string which is bits long. This is now just like our previous binary string strategy, except that setup uses the strings of all lengths up to , and this one uses only strings of exactly length .
The difference is that, if you had the states labeled with the shorter strings, and you were playing the game by asking a series of questions (equivalent to "Is the card's label's first bit 0?"), then you would sometimes reach the end of a binary string before you'd asked all questions. If the state happened to be the one labeled with just a 0, and your first question was, "Is the first bit a 0?" then the answer would be "yes" – but also, there would be further information, which is that there were no more bits left in the string. So in this formulation, that's equivalent to there being three pieces of information: "yes", "no" and "all done". If you were expecting only two possible answers, this could be considered a type of cheating, smuggling in extra information. It's as if all the finite binary strings need to have a special terminating character at the end.
So, the minimum average number of bits you need to distinguish a state depends on whether you're handed a whole label all at once (and know that's the whole label), or whether you need to query for the label one bit at a time (and figure out for yourself when you've received the whole label).
Exactly what is a bit?
In the opening definition of entropy, I used the word "bit", but didn't define it. Now that we've talked about cutting sets of states in half, it's a good time to pause and point out that that is what a bit is. It's often very natural and useful to think of bits as thing-like, i.e. of bits as existing, of there being a certain number of bits "in" something, or of them moving around through space. This is true in some cases, especially in computer storage, but it can be confusing because that's not really how it works in general.[14] It's often not the case that the bits are somewhere specific, even though it feels like they're "in there", and that can contribute to them (and entropy) feeling elusive and mysterious.
For a state to "have" a bit "in" it just means that there was another way for that state to be (which it is not). If a state has a degree of freedom in it that has two possible values, then you can coherently think of the bit as being "in" that degree of freedom. But note that this relies on counterfactual alternatives; it is not inherently inside the specific state.
Concretely, a state could have a simple switch in it (or a particle with up or down spin, or an object which could be in either of two boxes). If half of the entire set of possible states has the switch on, and the other half has the switch off, then I think it's fair to say that the bit is in the switch, or that the switch is one bit of entropy (or information). However, if 99% of states have the switch on and 1% have it off, then it contains significantly less than one bit, and if all states have the switch on, then it is zero bits.
As a simple example of a bit not being clearly located, consider a system that is just a bunch of balls in a box, where the set of possible states is just different numbers of balls. One way to divide up the state space is between states with an even number of balls versus states with an odd number of balls. This divides the state space in half, and that constitutes a bit of information that does not reside somewhere specific; it can be "flipped" by removing any single ball.
Thus, you can also see that just because you've defined a bit somewhere, it doesn't mean that feature must represent a bit. Though the quantity "the number of times you can cut the state space in half" is an objective property of a state space, the exact ways that you cut the space in half are arbitrary. So just because your state contains a switch that could be flipped does not mean that the switch must represent a bit.
Probabilities over states
In all of the above discussion of average entropies, we implicitly treated the states as equally likely. This is not always true, and it's also a problematic premise if there are infinitely many states [LW · GW]. If you want to get the average entropy when some states are more likely than others, then you can just take a standard expected value:
Here, is our entropy, is the set of possible states , and is the probability of each state. If is uniform and the size of is , then the minimum average entropy is the thing we already calculated above. If is not uniform, then the best thing we could do is give the most likely states the shortest strings, which could give us an average entropy that is arbitrarily small (depending on how non-uniform is).
That's what we could do in the binary string labels model. But what about in the yes/no questions model? What if, for example, we know that our friend likes picking the "Susan" card more often? If the cards aren't equally likely, then we shouldn't just be picking questions that cut the remaining number of cards in half; instead we should be picking questions that cut the remaining probability mass in half. So, if we know our friend picks Susan half the time, then a very reasonable first question would be, "Is your card Susan?".
But now our labels are not the same lengths. This feels like it's bringing us back to the binary string model; if they're not the same length, how do we know when we've asked enough questions? Don't we need an "end of string" character again? But a subtle difference remains. In the binary string model, the string 0 and the string 1 both refer to specific states. But in our game of Guess Who?, the first bit of all the strings refers to the answer to the question, "Is your card Susan?". If the answer is yes, then that state (the Susan card) just gets the string 1. If the answer is no, then the first bit of all the remaining states (i.e. the non-Susan cards) is 0 – but there's a second question for all of them, and therefore a second bit. No card has the string that is just 0.
The generalization here is that, in the yes/no questions model, no binary string label of a state can be a prefix of another state's binary string label. If 1 is a state's whole label, then no other label can even start with a 1. (In the version of the game where all states are equally likely, we just use equally-sized strings for all of them, and it is the case that no string can be a prefix of a different string of the same size.)
This is how you can use different-sized labels without having an additional "all done" symbol. If the bits known so far match a whole label, then they are not a prefix of any other label. Therefore they could not match any other label, and so you know the bits must refer to the label they already match so far. And using different-sized labels in your "prefix code" lets you reduce your expected entropy in cases where the states are not equally likely.
There are infinitely many prefix codes that one could make (each of which could have finitely or infinitely many finite binary strings).[15] It turns out that for a given probability distribution over states, the encoding that minimizes average entropy uses strings that have one bit for every halving that it takes to get to (e.g. if , that's two halvings, so use two bits to encode the state ). In other words we can use labels such that
and therefore,
which is minimal. (This is also how we can assign an entropy to a macrostate of unequally-likely microstates; we still want it to represent the number of yes/no questions we'd have to ask to get to a specific microstate, only now it has to be an expected value, and not an exact number.)
This definition, formally equivalent to Shannon entropy and Gibbs entropy, is often considered canonical, so it's worth taking a step back and reminding ourselves how it compares to what else we've talked about. In the beginning, we had a set of equally-likely states, and we gave the ones we "liked" shorter binary string labels so they required fewer bits to refer to. Next, we had sets of equally likely states that we didn't care to distinguish among, and we gave them all equally long labels, and just cared about how many bits were needed to narrow down to one state. Here, we have unequally-likely states, and we're assigning them prefix-codes in relation to their probability, so that we can minimize the expected number of bits we need to describe a state from the distribution.
All of these are ways of using bits to uniquely distinguish states, and thus they are all types of entropy.
Negentropy
Negentropy is the "potential" for the state (micro or macro) to be higher entropy – literally the maximum entropy minus the state's entropy:[16]
Note that while the entropy of a state is something you can determine from (a labeling of) just that state, the negentropy is a function of the maximum possible entropy state, and so it's determined by the entire collection of states in the system. If you have two systems, A and B, where the only difference is that B has twice as many states as A, then any state in both systems will have one more bit of negentropy in system B (even though they have the same entropy in both systems).
When we have a finite number of states, then is just some specific binary string length. But for systems with an infinite number of states [LW · GW] (and thus no bound on how long their labels are), is infinite, and since is finite for every state , every specific state just does actually have infinite negentropy.
If we're using entropy as the number of yes/no questions, and all the states are equally likely, then they all have equal entropy, and therefore zero negentropy. If they have different probabilities and we've assigned them labels with a prefix code, then we're back to having a different maximum length to subtract from.
If we're considering the entropy of a macrostate, then what is the maximum "possible" entropy? I'd say that the maximum entropy macrostate is the whole set of states.[17] Therefore the negentropy of a macrostate is how many halvings it takes to get from the whole set of states to .
If the system has an infinite number of microstates, then a macrostate could have finite or infinite negentropy; a macrostate made of a finite number of microstates would have infinite negentropy, but a macrostate that was, say, one-quarter of the total (infinite) set of states would have a negentropy of 2. As above, if the states are not equally likely, then the generalization of macrostate negentropy is not in terms of number of microstates but instead their probability mass. Then, the negentropy of a macrostate is
One concrete example of negentropy would be a partially-scrambled Rubik's Cube. Using the distance-from-solved entropy discussed above, a cube that is merely 10 moves from solved is far from the maximum entropy of 26 moves from solved, and thus has large negentropy.
Another example shows that negentropy could be considered the potential bits of information you could store in the state than you currently are. If your file is 3 KB in size, but can be losslessly compressed to 1 KB, then your file has about 1 KB of entropy and 2 KB of negentropy (because the highest-entropy file you can store in that space is an incompressible 3 KB).
What's next
At the risk of over-emphasizing, all the above is (if my understanding is correct) the definition of entropy, the very source of its meaningfulness. Any other things that use the term "entropy", or are associated with it, do so because they come from the above ideas. In a future post I try to trace out very explicitly how that works for several named types of entropy. In addition, we will show [LW · GW] how these ideas can meaningfully carry over to systems with continuous state spaces, and also consider moving between states over time, which will allow us to work out other implications following directly from the abstract definition.
- ^
The quickest gloss is that optimization is a decrease in entropy. So it's a pretty tight connection! But those six words are hiding innumerable subtleties.
- ^
Something like "the entropy of a closed system tends to increase over time"; there are many formulations.
- ^
Some contexts will use "nats" or "dits" or whatever. This comes from using logarithms with different bases, and is just a change of units, like meters versus feet.
- ^
I've justified the use of binary before [LW · GW]. There's a lot of interesting detail to go into about what changes when you use three symbols or more, but all of the heavy-lifting conclusions are the same. Turing machines that use three symbols can compute exactly the set of things that Turing machines with two symbols can; the length of a number is whether it's represented in binary or trinary; et cetera.
- ^
Binary strings are usually written out with 0s and 1s, and I'll do that in the text. But I personally always visualize them as strings of little white and black squares, which is what I'll use in the illustrations. This is probably because I first learned about them in the context of Turing machines with tapes.
- ^
Note that the entropy of a state is the length of its label, and not the label itself; the specific layout of 0s and 1s just serves to distinguish that label from other labels of the same length.
- ^
Justification for merely taking the log comes from the derivation at the end of this section, though you may have been able to intuit it already!
- ^
Again, this is assuming you're using a binary string labeling scheme that uses all the smaller strings before using bigger strings. You could always decide to label every state with binary strings of length 100.
- ^
The typical minimal notation for describing Rubik's Cube algorithms has one letter for each of the six faces (F, B, L, R, U, D), and then an apostrophe for denoting counter-clockwise (and a number of other symbols for more compact representations). This means that six of the one-move states have a label of length one, and six others have length two. This all comes out in the big-O wash, and the label lengths will end up differing by a constant factor, because e.g. .
- ^
I'll have bits of math throughout this sequence. This is a pretty math-heavy concept, but I still don't think that most of the actual equations are essential for gaining a useful understanding of entropy (though it is essential to understand how logarithms work). So if you feel disinclined to follow the derivations, I'd still encourage you to continue reading the prose.
None of the derivations in this sequence are here for the purpose of rigorously proving anything, and I've tried to include them when the structure of the equations actually helped me understand the concepts more clearly.
- ^
Wikipedia informs me that this is not technically the optimal strategy for winning the game, because if you are behind and your opponent plays optimally, then you're better off guessing specific people and hoping to get lucky.
- ^
Or as close to half as you can get.
- ^
Again, only exact when is a power of 2, but in any case, the binary string one is strictly less than the yes/no questions one, which is what we want to resolve here.
- ^
For this reason I've been careful not to use the phrase "bit string", instead sticking with "binary string". For our purposes, a binary string is a bit string if each of those symbols could have been the flipped value (for some relevant definition of "could").
- ^
Examples of finite prefix codes: {0, 1}, {0, 10, 11}, {00, 01, 10, 110, 1110, 1111}
Example of an infinite prefix code: {0, 10, 110, 1110, 11110, ... }
- ^
Note that for many systems, most states have maximum or near-maximum entropy, such that the negentropy is virtually the same as the average entropy minus the state's entropy; this would also mean that most states have virtually zero negentropy.
- ^
You could argue that the maximum entropy macrostate is just the macrostate that contains only the highest entropy state(s). I think the spirit of macrostates is that you don't consider individual states, and thus it would be "cheating" to pick out specific states to form your macrostate. In the spirit of , the way to maximize is to maximize , that is, include all states into .
78 comments
Comments sorted by top scores.
comment by So8res · 2022-10-21T16:05:39.193Z · LW(p) · GW(p)
This piece reads to me like the output of someone who worked hard to comprehend a topic in full, without accepting the rest of society's cloudy bullshit / papered-over-confusion / historical baggage in place of answers. And in a particularly thorny case, no less. And with significant effort made to articulate the comprehension clearly and intuitively to others.
For instance: saying "if we're going to call all of these disparate concepts 'entropy', then let's call the length of the name of a microstate 'entropy' also; this will tie the whole conceptual framework together and make what follows more intuitive" is a bold move, and looks like the product of swallowing the whole topic and then digesting it down into something organized and comprehensible. It strikes me as a unit of conceptual labor.
Respect.
I'm excited to see where this goes.
Replies from: adam-scherlis, Alex_Altair↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-22T18:16:14.083Z · LW(p) · GW(p)
I almost agree, but I really do stand by my claim that Alex has nicely identified the correct abstract thing and then named the wrong part of it entropy.
[EDIT: I now think the abstract thing I describe below -- statistical entropy -- is not the full thing Alex is going for. A more precise claim is: Alex is describing some general thing, and calling part of it "entropy". When I map that thing onto domains like statmech or information theory, his "entropy" doesn't map onto the thing called "entropy" in those domains, even though the things called "entropy" in those domains do map onto each other. This might be because he wants it to map onto "algorithmic entropy" in the K-complexity setting, but I think this doesn't justify the mismatch.]
The abstract thing [EDIT: "statistical entropy"] is shaped something like: there are many things (call 'em microstates).
Each thing has a "weight", p. (Let's not call it "probability" because that has too much baggage.)
We care a lot about the negative log of p. However, in none of the manifestations of this abstract concept is that called "entropy".
We also care about the average of -log(p) over every possible microstate, weighted by p. That's called "entropy" in every manifestation of this pattern (if the word is used at all), never "average entropy".
I don't see why it helps intuition to give these things the same name, and especially not why you would want to replace the various specific "entropy"s with an abstract "average entropy".
Replies from: So8res, Alex_Altair↑ comment by So8res · 2022-10-23T00:50:47.954Z · LW(p) · GW(p)
I'm also unsure whether I would have made Alex's naming choice. (I think he suggested that this naming fits with something he wants to do with K complexity, but I haven't understood that yet, and will wait and see before weighing in myself.)
Also, to state the obvious, noticing that the concept wants a short name (if we are to tie a bunch of other things together and organize them properly) feels to me like a unit of conceptual progress regardless of whether I personally like the proposed pun.
On a completely different note, one of my personal spicy takes is that when we're working in this domain, we should be working in log base 1/2 (or 1/e or suchlike, namely with a base 0 < b < 1). Which is very natural, because we're counting the number of halvings (of probability / in statespace) that it takes to single out a (cluster of) state(s). This convention dispells a bunch of annoying negative signs.
(I also humbly propose the notation ə, pronounced "schwa", for 1/e.)
((In my personal notation I use lug, pronounced /ləg/, for log base ə, and lug2 and etc., but I'm not yet confident that this is a good convention.))
↑ comment by Alex_Altair · 2022-10-23T19:01:14.409Z · LW(p) · GW(p)
I think he suggested that this naming fits with something he wants to do with K complexity
I didn't mean something I'm doing, I meant that the field of K-complexity just straight-forwardly uses the word "entropy" to refer to it. Let me see if I can dig up some references.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T21:18:52.302Z · LW(p) · GW(p)
K-complexity is apparently sometimes called "algorithmic entropy" (but not just "entropy", I don't think?)
Wiktionary quotes Niels Henrik Gregersen:
Algorithmic entropy is closely related to statistically defined entropy, the statistical entropy of an ensemble being, for any concisely describable ensemble, very nearly equal to the ensemble average of the algorithmic entropy of its members
I think this might be the crux!
Note the weird type mismatch: "the statistical entropy of an ensemble [...] the ensemble average of the algorithmic entropy of its members".
So my story would be something like the following:
- Many fields (thermodynamics, statistical mechanics, information theory, probability) use "entropy" to mean something equivalent to "the expectation of -log(p) for a distribution p". Let's call this "statistical entropy", but in practice people call it "entropy".
- Algorithmic information theorists have an interestingly related but distinct concept, which they sometimes call "algorithmic entropy".
Whoops, hang on a sec. Did you want your "abstract entropy" to encompass both of these?
If so, I didn't realize that until now! That changes a lot, and I apologize sincerely if waiting for the K-complexity stuff would've dissipated a lot of the confusion.
Things I think contributed to my confusion:
(1) Your introduction only directly mentions / links to domain-specific types of entropy that are firmly under (type 1) "statistical entropy"
(2) This intro post doesn't yet touch on (type 2) algorithmic entropy, and is instead a mix of type-1 and your abstract thing where description length and probability distribution are decoupled.
(3) I suspect you were misled by the unpedagogical phrase "entropy of a macrostate" from statmech, and didn't realize that (as used in that field) the distribution involved is determined by the macrostate in a prescribed way (or is the macrostate).
I would add a big fat disclaimer that this series is NOT just limited to type-1 entropy, and (unless you disagree with my taxonomy here) emphasize heavily that you're including type-2 entropy.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-10-23T23:02:52.606Z · LW(p) · GW(p)
Did you want your "abstract entropy" to encompass both of these?
Indeed I definitely do.
I would add a big fat disclaimer
There are a bunch of places where I think I flagged relevant things, and I'm curious if these seem like enough to you;
- The whole post is called "abstract entropy", which should tell you that it's at least a little different from any "standard" form of entropy
- The third example, "It helps us understand strategies for (and limits on) file compression", is implicitly about K-complexity
- This whole paragraph: "Many people reading this will have some previous facts about entropy stored in their minds, and this can sometimes be disorienting when it's not yet clear how those facts are consistent with what I'm describing. You're welcome to skip ahead to the relevant parts and see if they're re-orienting; otherwise, if you can get through the whole explanation, I hope that it will eventually be addressed!"
- Me being clear that I'm not a domain expert
- Footnote [4], which talks about Turing machines and links to my post on Solomonoff induction
- Me going on and on about binary strings and how we're associating these with individual state -- I dunno, to me this just screams K-complexity to anyone who's heard of it
- "I just defined entropy as a property of specific states, but in many contexts you don't care at all about specific states..."
- ... "I'll talk about this in a future post; I think that "order" is synonymous with Kolmogorov complexity." ...
I struggled with writing the intro section of this post because it felt like there were half a dozen disclaimer-type things that I wanted to get out of the way first. But each one is only relevant to a subset of people, and eventually I need to get to the content. I'm not even expecting most readers to be holding any such type-1/type-2 distinction in their mind to start, so I'd have to go out of my way to explain it before giving the disclaimer.
All that aside, I am very open to the idea that we should be calling the single-state thing something different. The "minimum average" form is the great majority of use cases.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T23:29:36.670Z · LW(p) · GW(p)
I initially interpreted "abstract entropy" as meaning statistical entropy as opposed to thermodynamic or stat-mech or information-theoretic entropy. I think very few people encounter the phrase "algorithmic entropy" enough for it to be salient to them, so most confusion about entropy in different domains is about statistical entropy in physics and info theory. (Maybe this is different for LW readers!)
This was reinforced by the introduction because I took the mentions of file compression and assigning binary strings to states to be about (Shannon-style) coding theory, which uses statistical entropy heavily to talk about these same things and is a much bigger part of most CS textbooks/courses. (It uses phrases like "length of a codeword", "expected length of a code [under some distribution]", etc. and then has lots of theorems about statistical entropy being related to expected length of an optimal code.)
After getting that pattern going, I had enough momentum to see "Solomonoff", think "sure, it's a probability distribution, presumably he's going to do something statistical-entropy-like with it", and completely missed the statements that you were going to be interpreting K complexity itself as a kind of entropy. I also missed the statement about random variables not being necessary.
I suspect this would also happen to many other people who have encountered stat mech and/or information theory, and maybe even K complexity but not the phrase "algorithmic entropy", but I could be wrong.
A disclaimer is probably not actually necessary, though, on reflection; I care a lot more about the "minimum average" qualifiers both being included in statistical-entropy contexts. I don't know exactly how to unify this with "algorithmic entropy" but I'll wait and see what you do :)
↑ comment by MikkW (mikkel-wilson) · 2022-10-23T14:26:50.053Z · LW(p) · GW(p)
I like the schwa and lug proposals. Trying to anticipate problems, I do suspect newcomers will see 'lug', and find themselves confused, if it has never been explained to them. It even seems possible they may not connect it to logarithms sans explanation
↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T18:33:48.407Z · LW(p) · GW(p)
Also, to state the obvious, noticing that the concept wants a short name (if we are to tie a bunch of other things together and organize them properly) feels to me like a unit of conceptual progress regardless of whether I personally like the proposed pun
Agreed!
schwa and lug
Yeah, shorthand for this seems handy. I like these a lot, especially schwa, although I'm a little worried about ambiguous handwriting. My contest entry is nl (for "negative logarithm" or "ln but flipped").
↑ comment by Alex_Altair · 2022-10-23T19:18:10.462Z · LW(p) · GW(p)
one of my personal spicy takes...
Omfg, I love hearing your spicy takes. (I think I remember you advocating hard tabs, and trinary logic.)
ə, pronounced "schwa", for 1/e
lug, pronounced /ləg/, for log base ə
nlfor "negative logarithm"
XD XD guys I literally can't
↑ comment by Alex_Altair · 2022-10-23T18:58:00.610Z · LW(p) · GW(p)
(Let's not call it "probability" because that has too much baggage.)
This aside raises concerns for me, like it makes me worry that maybe we're more deeply not on the same page. It seems to me like the weighing is just straight-forward probability, and that it's important to call it that.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T19:47:08.381Z · LW(p) · GW(p)
I think I was overzealous with this aside and regret it.
I worry that the word "probability" has connotations that are too strong or are misleading for some use cases of abstract entropy.
But this is definitely probability in the mathematical sense, yes.
Maybe I wish mathematical "probability" had a name with weaker connotations.
↑ comment by Alex_Altair · 2022-10-23T19:14:45.485Z · LW(p) · GW(p)
Extremely pleased with this reception! I indeed feel pretty seen by it.
comment by Alex_Altair · 2023-12-16T00:06:15.686Z · LW(p) · GW(p)
[This is a self-review because I see that no one has left a review to move it into the next phase. So8res's comment [LW(p) · GW(p)] would also make a great review.]
I'm pretty proud of this post for the level of craftsmanship I was able to put into it. I think it embodies multiple rationalist virtues. It's a kind of "timeless" content, and is a central example of the kind of content people want to see on LW that isn't stuff about AI.
It would also look great printed in a book. :)
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-12-16T00:08:03.603Z · LW(p) · GW(p)
For this part of the review you only need positive or negative votes, not reviews!
comment by Adam Scherlis (adam-scherlis) · 2022-10-20T23:12:30.514Z · LW(p) · GW(p)
I haven't read all of this yet. I like it so far. One nitpick: I would really try to avoid referring to individual microstates as having "entropy" assigned to them. I would call (or things playing a similar role) something else like "surprisal" or "information", and reserve entropy (rather than "average entropy") for things that look like or .
Of course, for macrostates/distributions with uniform probability, this works out to be equal to for every state in the macrostate, but I think the conceptual distinction is important.
(I'm as guilty as anyone of calling simple microstates "low-entropy", but I think it's healthier to reserve that for macrostates or distributions.)
Replies from: Alex_Altair, Alex_Altair, habryka4, adam-scherlis↑ comment by Alex_Altair · 2022-10-20T23:21:23.172Z · LW(p) · GW(p)
That's a reasonable stance, but one of the main messages of the sequence is that we can start with the concept of individual states having entropy assigned to them, and derive everything else from there! This is especially relevant to the idea of using Kolmogorov complexity as entropy. Calling it "surprisal" or "information" has an information-theoretic connotation to it that I think doesn't apply in all contexts.
Replies from: adam-scherlis, Alex_Altair↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-20T23:28:31.965Z · LW(p) · GW(p)
I'm fine with choosing some other name, but I think all of the different "entropies" (in stat mech, information theory, etc) refer to weighted averages over a set of states, whose probability-or-whatever adds up to 1. To me that suggests that this should also be true of the abstract version.
So I stand by the claim that the negative logarithm of probability-or-whatever should have some different name, so that people don't get confused by the ([other thing], entropy) → (entropy, average entropy) terminology switch.
I think "average entropy" is also (slightly) misleading because it suggests that the -log(p)'s of individual states are independent of the choice of which microstates are in your macrostate, which I think is maybe the root problem I have with footnote 17. (See new comment in that subthread)
Replies from: Alex_Altair, Alex_Altair, Alex_Altair, Alex_Altair↑ comment by Alex_Altair · 2022-10-23T18:59:31.752Z · LW(p) · GW(p)
Part of what confuses me about your objection is that it seems like averages of things can usually be treated the same as the individual things. E.g. an average number of apples is a number of apples, and average height is a height ("Bob is taller than Alice" is treated the same as "men are taller than women"). The sky is blue, by which we mean that the average photon frequency is in the range defined as blue; we also just say "a blue photon".
A possible counter-example I can think of is temperature. Temperature is the average [something like] kinetic energy of the molecules, and we don't tend to think of it as kinetic energy. It seems to be somehow transmuted in nature through its averaging.
But entropy doesn't feel like this to me. I feel comfortable saying "the entropy of a binomial distribution", and throughout the sequence I'm clear about the "average entropy" thing just to remind the reader where it comes from.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T19:52:32.716Z · LW(p) · GW(p)
I think it's different because entropy is an expectation of a thing which depends on the probability distribution that you're using to weight things.
Like, other things are maybe... A is the number of apples, sum of p×A is the expected number of apples under distribution p, sum of q×A is the expected number of apples under distribution q.
But entropy is... -log(p) is a thing, and sum of p × -log(p) is the entropy.
And the sum of q × -log(p) is... not entropy! (It's "cross-entropy")
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-10-23T20:30:37.392Z · LW(p) · GW(p)
That makes sense. In my post I'm saying that entropy is whatever binary string assignment you want, which does not depend on the probability distribution you're using to weight things. And then if you want the minimum average string length, it becomes in terms of the probability distribution.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T21:14:00.559Z · LW(p) · GW(p)
Ah, I missed this on a first skim and only got it recently, so some of my comments are probably missing this context in important ways. Sorry, that's on me.
↑ comment by Alex_Altair · 2022-10-23T18:57:04.413Z · LW(p) · GW(p)
One thing I'm not very confident about is how working scientists use the concept of "macrostate". If I had good resources for that I might change some of how the sequence is written, because I don't want to create any confusion for people who use this sequence to learn and then go on to work in a related field. (...That said, it's not like people aren't already confused. I kind of expect most working scientists to be confused about entropy outside their exact domain's use.)
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T19:56:59.616Z · LW(p) · GW(p)
I think it might be a bit of a mess, tbh.
In probability theory, you have outcomes (individual possibilities), events (sets of possibilities), and distributions (assignments of probabilities to all possible outcomes).
"microstate": outcome.
"macrostate": sorta ambiguous between event and distribution.
"entropy of an outcome": not a thing working scientists or mathematicians say, ever, as far as I know.
"entropy of an event": not a thing either.
"entropy of a distribution": that's a thing!
"entropy of a macrostate": people say this, so they must mean a distribution when they are saying this phrase.
I think you're within your rights to use "macrostate" in any reasonable way that you like. My beef is entirely about the type signature of "entropy" with regard to distributions and events/outcomes.
↑ comment by Alex_Altair · 2022-10-23T18:56:22.675Z · LW(p) · GW(p)
Here's another thing that might be adding to our confusion. It just so happens that in the particular system that is this universe, all states with the same total energy are equally likely. That's not true for most systems (which don't even have a concept of energy), and so it doesn't seem like a part of abstract entropy to me. So e.g. macrostates don't necessarily contain microstates of equal probability (which I think you've implied a couple times).
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T19:42:47.606Z · LW(p) · GW(p)
Honestly, I'm confused about this now.
I thought I recalled that "macrostate" was only used for the "microcanonical ensemble" (fancy phrase for a uniform-over-all-microstates-with-same-(E,N,V) probability distribution), but in fact it's a little ambiguous.
Wikipedia says
Treatments on statistical mechanics[2][3] define a macrostate as follows: a particular set of values of energy, the number of particles, and the volume of an isolated thermodynamic system is said to specify a particular macrostate of it.
which implies microcanonical ensemble (the other are parametrized by things other than (E, N, V) triples), but then later it talks about both the canonical and microcanonical ensemble.
I think a lot of our confusion comes from way physicists equivocate between macrostates as a set of microstates (with the probability distribution) unspecified) and as a probability distribution. Wiki's "definition" is ambiguous: a particular (E, N, V) triple specifies both a set of microstates (with those values) and a distribution (uniform over that set).
In contrast, the canonical ensemble is a probability distribution defined by a triple (T,N,V), with each microstate having probability proportional to exp(- E / kT) if it has particle number N and volume V, otherwise probability zero. I'm not sure what "a macrostate specified by (T,N,V)" should mean here: either the set of microstates with (N, V) (and any E), or the non-uniform distribution I just described.
(By the way: note that when T is being used here, it doesn't mean the average energy, kinetic or otherwise. kT isn't the actual energy of anything, it's just the slope of the exponential decay of probability with respect to energy. A consequence of this definition is that the expected kinetic energy in some contexts is proportional to temperature, but this expectation is for a probability distribution over many microstates that may have more or less kinetic energy than that. Another consequence is that for large systems, the average kinetic energy of particles in the actual true microstate is very likely to be very close to (some multiple of) kT, but this is because of the law of large numbers and is not true for small systems. Note that there's two different senses of "average" here.)
I agree that equal probabilities / uniform distributions are not a fundamental part of anything here and are just a useful special case to consider.
↑ comment by Alex_Altair · 2022-10-23T18:55:24.916Z · LW(p) · GW(p)
I'm not quite sure what the cruxes of our disagreement are yet. So I'm going to write up some more of how I'm thinking about things, which I think might be relevant.
When we decide to model a system and assign its states entropy, there's a question of what set of states we're including. Often, we're modelling part of the real universe. The real universe is in only one state at any given time. But we're ignorant of a bunch of parts of it (and we're also ignorant about exactly what states it will evolve into over time). So to do some analysis, we decide on some stuff we do know about its state, and then we decide to include all states compatible with that information. But this is all just epistemic. There's no one true set that encompasses all possible states; there's just states that we're considering possible.
And then there's the concept of a macrostate. Maybe we use the word macrostate to refer to the set of all states that we've decided are possible. But then maybe we decide to make an observation about the system, one that will reduce the number of possible states consistent with all our observations. Before we make the observation, I think it's reasonable to say that for every possible outcome of the observation, there's a macrostate consistent with that outcome. The probability that we will find the system to be in that macrostate is the sum of the probability of its microstates. Thus the macrostate has p<1 before the observation, and p=1 after the observation. This feels pretty normal to me.
We can do this for any property that we can observe, and that's why I defined a macrostate as, "collections of microstates ... connotively characterized by a generalized property of the state".
I also don't see why it couldn't be a set containing a singe state; a set of one thing is still a set. Whether that one thing has probability 1 or not depends on what you're deciding to do with your uncertainty model.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T20:53:19.279Z · LW(p) · GW(p)
I think the crux of our disagreement [edit: one of our disagreements] is whether the macrostate we're discussing can be chosen independently of the "uncertainty model" at all.
When physicists talk about "the entropy of a macrostate", they always mean something of the form:
- There are a bunch of p's that add up to 1. We want the sum of p × (-log p) over all p's. [EXPECTATION of -log p aka ENTROPY of the distribution]
They never mean something of the form:
- There are a bunch of p's that add up to 1. We want the sum of p × (-log p) over just some of the p's. [???]
Or:
- There are a bunch of p's that add up to 1. We want the sum of p × (-log p) over just some of the p's, divided by the sum of p over the same p's. [CONDITIONAL EXPECTATION of -log p given some event]
Or:
- There are a bunch of p's that add up to 1. We want the sum of (-log p) over just some of the p's, divided by the number of p's we included. [ARITHMETIC MEAN of -log p over some event]
This also applies to information theorists talking about Shannon entropy.
I think that's the basic crux here.
This is perhaps confusing because "macrostate" is often claimed to have something to do with a subset of the microstates. So you might be forgiven for thinking "entropy of a macrostate" in statmech means:
- For some arbitrary distribution p, consider a separately-chosen "macrostate" A (a set of outcomes). Compute the sum of p × (-log p) over every p whose corresponding outcome is in A, maybe divided by the total probability of A or something.
But in fact this is not what is meant!
Instead, "entropy of a macrostate" means the following:
- For some "macrostate", whatever the hell that means, we construct a probability distribution p. Maybe that's the macrostate itself, maybe it's a distribution corresponding to the macrostate, usage varies. But the macrostate determines the distribution, either way. Compute the sum of p × (-log p) over every p.
EDIT: all of this applies even more to negentropy. The "S_max" in that formula is always the entropy of the highest-entropy possible distribution, not anything to do with a single microstate.
↑ comment by Alex_Altair · 2022-10-20T23:25:00.305Z · LW(p) · GW(p)
I think it's also important for my definition of optimization (coming later), because individual microstates do deserve to be assigned a specific level of optimization.
↑ comment by Alex_Altair · 2022-10-23T20:37:32.671Z · LW(p) · GW(p)
Just mulling over other names, I think "description length" is the one I like best so far. Then "entropy" would be defined as minimum average description length.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T21:33:33.227Z · LW(p) · GW(p)
I like "description length".
One wrinkle is that entropy isn't quite minimum average description length -- in general it's a lower bound on average description length.
If you have a probability distribution that's (2/3, 1/3) over two things, but you assign fixed binary strings to each of the two, then you can't do better than 1 bit of average description length, but the entropy of the distribution is 0.92 bits.
Or if your distribution is roughly (.1135, .1135, .7729) over three things, then you can't do better than 1.23 bits, but the entropy is 1 bit.
You can only hit the entropy exactly when the probabilities are all powers of 2.
(You can fix this a bit in the channel-coding context, where you're encoding sequences of things and don't have to assign fixed descriptions to individual things. In particular, you can assign descriptions to blocks of N things, which lets you get arbitrarily close as N -> infinity.)
Replies from: So8res↑ comment by So8res · 2022-10-23T22:06:55.120Z · LW(p) · GW(p)
I think you can bring the two notions into harmony by allowing multiple codes per state (with the entropy/description-length of a state being the lug/nl of the fraction of the codespace that codes for that state).
For instance, you can think of a prefix-free code as a particularly well-behaved many-to-one assignment of infinite bitstrings to states, with (e.g.) the prefix-free code "0" corresponding to every infinite bitstring that starts with 0 (which is half of all infinite bitstrings, under the uniform measure).
If we consider all many-to-one assignments of infinite bitstrings to states (rather than just the special case of prefix-free codes) then there'll always be an encoding that matches the entropy, without needing to say stuff like "well our description-length can get closer to the theoretical lower-bound as we imagine sending more and more blocks of independent data and taking the average per-block length".
(If you want to keep the codespace finite, we can also see the entropy as the limit of how well we can do as we allow the codespace to increase in size.)
(I suspect that I can also often (always?) match the entropy if you let me design custom codespaces, where I can say stuff like "first we have a bit, and then depending on whether it's 0 or 1, we follow it up by either a trit or a quadit".)
(epistemic status: running off of a cache that doesn't apply cleanly, but it smells right \shrug)
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-24T02:30:26.321Z · LW(p) · GW(p)
Sure, from one perspective what's going on here is that we're being given a distribution p and asked to come up with a distribution q such that
CrossEntropy(p, q) = E_p[-log q]
is as small as possible. And then a bit of calculus shows that q=p is optimal, with a minimal value of
Entropy(p) = CrossEntropy(p, p)
If we're happy to call -log q "description length" right off the bat, we can let q be a distribution over the set of infinite bit strings, or the set of finite simple graphs, or over any (infinite) set we like.
But some settings are special, such as "q has to be the coin-flip distribution over a prefix-free code", because in those settings our quantity -log q is forced to equal the length of something in the normal sense of "length of something".
So the gap I'm interested in closing is between things that have actual lengths and things that are exactly equal to entropy, and the block encoding thing is the simplest way I know to do that.
I think using the coin-flip distribution over infinite strings is nice because it hits entropy exactly and has a clear relationship with the prefix-free-code case, but the block code motivates "length" better in isolation.
Replies from: So8res↑ comment by So8res · 2022-10-24T13:18:30.133Z · LW(p) · GW(p)
What's your take on using "description length" for the length of a single description of a state, and "entropy" for the log-sum-exp of the description-lengths of all names for the state? (Or, well, ləg-sum-əxp, if you wanna avoid a buncha negations.)
I like it in part because the ləg-sum-əxp of all description-lengths seems to me like a better concept than K-complexity anyway. (They'll often be similar, b/c ləg-sum-əxp is kinda softminish and the gap between description-lengths is often long, but when they differ it's the ləg-sum-əxp'd thing that you usually want.)
For example, Solomonoff induction does not have the highest share of probability-mass on the lowest K-complexity hypothesis among those consistent with the data. It has the highest share of probability-mass on the hypothesis with lowest ləg-sum-əxp of all description-lengths among those consistent with the data.
This can matter sometimes. For instance, in physics we can't always fix the gauge. Which means that any particular full description of physics needs to choose a full-fledged gauge, which spends an enormous amount of description-length. But this doesn't count against physics, b/c for every possible gauge we could describe, there's (same-length) ways of filling out the rest of the program such that it gives the right predictions. In the version of Solomonoff induction where hypotheses are deterministic programs, physics does not correspond to a short program, it corresponsd to an enormous number of long programs. With the number so enormous that the ləg-sum-əxp of all those big lengths is small.
More generally, this is related to the way that symmetry makes things simpler. If your code has a symmetry in it, that doesn't make your program any shorter, but it does make the function/hypothesis your program represents simpler, not in terms of K-complexity but in terms of "entropy" (b/c, if S is the symmetry group, then there's |S|-many programs of the ~same length that represent it, which decreases the ləg-sum-əxp by ~log(S)).
(Ofc, if we start thinking of hypotheses as being probabilistic programs instead, then we can unify all the symmetry-partners into a single probabilistic program that samples a gauge / element of the symmetry group. So K-complexity is often pretty close to the right concept, if you pick the right formalism. But even then I still think that the ləg-sum-əxp of all description-lengths is even more precisely what you want, e.g. when there's multiple similar-length probabilistic programs that do the same thing.)
I'm not up to speed on the theorems that approximately relate "algorithmic entropy" to normal entropy, but I suspect that the conditions of those theorems are doing some hand-waving of the form "as the gap between description-lengths gets longer" (perhaps by iterating something that artificially inflates the gap and taking averages). If so, then I expect the ləg-sum-əxp of all description lengths to satisfy these theorems immediately and without the the handwaving.
I have now personally updated towards thinking that calling the K-complexity the "algorithmic entropy" is simply wrong. Close, but wrong. The thing deserving that name is the ləg-sum-əxp of all the description-lengths.
(Indeed, the whole concept of K-complexity seems close-but-wrong to me, and I've personally been using the ləg-sum-əxp concept in its place for a while now. I've been calling it just "complexity" in my own head, though, and hadn't noticed that it might be worthy of the name "entropy".)
epistemic status: spittballing; still working like 50% from cache
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-24T15:30:18.021Z · LW(p) · GW(p)
I still don't like that, because this whole subthread is kind of orthogonal to my concerns about the word "entropy".
This subthread is mostly about resolving the differences between a code (assignment of one or more codewords to one or more states) and a probability distribution. I think we've made progress on that and your latest comment is useful on that front.
But my concerns about "entropy" are of the form: "I notice that there's a whole field of coding theory where 'entropy' means a particular function of a probability distribution, rather than a function of an individual state. This is also consistent with how physicists and other kinds of computer scientists use the word, except for the phrase 'algorithmic entropy'. I think we should not break compatibility with this usage."
Ignoring the differences between distributions and codes, I'd be fine with assigning "entropy" to various things shaped like either "sum of p(state) lug(p(state)) across all states" for a distribution or "sum of (2^-len(state)) len(state) across all states" for a code.
I am also fine with assigning it to "sum of p(state) len(state)" for a (distribution, code) pair that are matched in an appropriate sense -- the distribution is the coinflip distribution for the code, or the code is optimal for the distribution, or something else roughly equivalent.
Elsewhere Alex and I have been referring to this as a pair of qualifiers "average" (i.e. it's a sum over all states weighted by p or 2^-len) and "minimal" (i.e. the two factors in the sum are for matching or identical codes/distributions).
"Average" distinguishes entropy from the things information theorists call "length" or "self-information" or "surprisal" or just "[negative] log-prob", and "minimal" distinguishes entropy from "expected length [of an arbitrary code]" or "cross-entropy".
Replies from: So8res↑ comment by So8res · 2022-10-24T16:10:14.750Z · LW(p) · GW(p)
Cool thanks. I'm hearing you as saying "I want to reserve 'entropy' for the case where we're weighting the length-like thingies by probability-like thingies", which seems reasonable to me.
I'm not sure I follow the part about matched (distribution, code) pairs. To check my understanding: for a sufficiently forgiving notion of "matching", this is basically going to yield the cross-entropy, right? Where, IIUC, we've lifted the code to a distribution in some natural way (essentially using a uniform distribution, though there might be a translation step like translating prefix-free codes to sets of infinite bitstrings), and then once we have two distributions we take the cross-entropy.
(One of my hypotheses for what you're saying is "when the distribution and the code are both clear from context, we can shorten 'cross-entropy' to 'entropy'. Which, ftr, seems reasonable to me.)
My own proclivities would say: if I specify only a state and a code, then the state lifts to a distribution by Kronecker's delta and the code lifts to a distribution uniformly, and I arbitrarily declare these to 'match', and so when we speak of the (cross-)entropy of a state given a code we mean the length of the code(s) for that particular state (combined by ləg-sum-əxp if there's multiple).
This seems like the natural way to 'match' a state and a code, to my eye. But I acknowledge that what counts as 'matching' is a matter of intuition and convention, and that others' may differ from mine.
At this point, though, the outcome I'm most invested in is emerging with a short name for "the ləg-sum-əxp of the lengths of all the descriptions". I'm fine with naming it some variation on 'complexity', though. (Komolgorov kindly left a K in K-complexity, so there's ample room to pick another letter if we have to.)
(Though to be very explicit about my personal preferences, I'd use "entropy". It seems to me that once we've conceded that we can talk about the entropy of a (distribution, code) pair then we might as well extend the notation to include (state, code) pairs; they're sibling shorthands. Or, to say it more trollishly: the Nate!complexity of a function is a length-like thingy weighted by a probability-like thingy, where the probability-like thingy is 1 :-p.)
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-24T17:03:39.901Z · LW(p) · GW(p)
(One of my hypotheses for what you're saying is "when the distribution and the code are both clear from context, we can shorten 'cross-entropy' to 'entropy'. Which, ftr, seems reasonable to me.)
I want something much more demanding -- I want the distribution and code to be "the same" (related by p = 2^-len), or something "as close as possible" to that.
I was leaving a little bit of wiggle room to possibly include "a code matches a distribution if it is the optimal code of its type for compression under that source distribution", but this is only supposed to allow rounding errors; it seems sort of okay to say that the expected length of (0, 10, 11) under the distribution (0.4, 0.3, 0.3) is some (not quite standard) sort of entropy for that distribution, but not okay to say that the expected length of (0, 10, 11) under (0., 0., 1.) is an entropy.
But I'm on the fence about even giving that much wiggle room.
That's the only reason I exclude single states. I agree that the length of a state is a kind of cross-entropy, because you can choose a delta distribution, but I draw a firm line between cross-entropy and entropy.
(Obviously there's a special case, where a code that has a single empty codeword for a single state matches a delta distribution. But not if the codeword isn't the empty string.)
Replies from: adam-scherlis, So8res↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-24T17:28:04.539Z · LW(p) · GW(p)
I wonder if it would be reasonable to use "xentropy" for the broad sense of "entropy" in OP, with the understanding that xentropy is always a two-argument function.
"The length of a codeword is the xentropy between [the delta distribution located at] the state and [the coinflip distribution implied by] the code"
↑ comment by So8res · 2022-10-24T17:34:20.488Z · LW(p) · GW(p)
Cool cool. I can personally see the appeal of reserving 'entropy' for the case where the distribution and the (natural lifting of) the code (to a distribution) are identical, i.e. your proposal without the wiggle-room.
I don't yet personally see a boundary between the wiggle-room you're considering and full-on "we can say 'entropy' as a shorthand for 'cross-entropy' when the second distribution is clear from context" proposal.
In particular, I currently suspect that there's enough wiggle-room in "optimal code of its type for compression under the source distribution" to drive a truck through. Like, if we start out with a uniform code C and a state s, why not say that the "type of codes" for the source distribution δ(s) is the powerset of {c ∈ C | c codes for s}? In which case the "optimal code for compression" is the set of all such c, and the 'entropy' is the Nate!complexity?
I'm not yet sure whether our different aesthetics here are due to:
- me failing to see a natural boundary that you're pointing to
- you not having yet seen how slippery the slope is
- you having a higher tolerance for saying "humans sometimes just wanna put fences halfway down the slippery slope, dude".
Insofar as you think I'm making the mistake of (1), I'm interested to hear arguments. My argument above is ofc tuned to case (2), and it's plausible to me that it pushes you off the fence towards "no wiggle room".
Another place we might asethetically differ is that I'm much happier blurring the line between entropy and cross-entropy.
One handwavy argument for blurring the line (which has the epistemic status: regurgitating from a related cache that doesn't cleanly apply) is that if the statespace is uncountably infinite then we need a measure in order to talk about entropy (and make everything work out nicely under change-of-variables). And so in the general case, entropy is already a two-place predicate function involving a distribution and some sort of measure. (...Although my cache is unclear on whether this generalization yields the KL divergence or the cross-entropy. Probably KL. But, like, if we're holding the correct distribution fixed, then they differ only by a constant. Hopefully. This is as far as I can go w/out warming up that cache, and I don't wanna warm it up right now \shrug.)
↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-24T18:11:21.017Z · LW(p) · GW(p)
My argument above is ofc tuned to case (2), and it's plausible to me that it pushes you off the fence towards "no wiggle room".
Yup, I think I am happy to abandon the wiggle room at this point, for this reason.
if the statespace is uncountably infinite then we need a measure in order to talk about entropy (and make everything work out nicely under change-of-variables). And so in the general case, entropy is already a two-place predicate involving a distribution and some sort of measure.
I think my preferred approach to this is that the density p(x) is not really the fundamental object, and should be thought of as dP/dmu(x), with the measure in the denominator. We multiply by dmu(x) in the integral for entropy in order to remove this dependence on mu that we accidentally introduced. EDIT: this is flagrantly wrong because log(p) depends on the measure also. You're right that this is really a function of the distribution and the measure; I'm not sure offhand if it's crossentropy, either, but I'm going to think about this more. (This is an embarrassing mistake because I already knew differential entropy was cursed with dependence on a measure -- quantum mechanics famously provides the measure on phase-space that classical statistical mechanics took as axiomatic.)
For what it's worth, I've heard the take "entropy and differential entropy are different sorts of things" several times; I might be coming around to that, now that I see another slippery slope on the horizon.
Replies from: Alex_Altair, So8res↑ comment by Alex_Altair · 2022-10-24T19:33:00.750Z · LW(p) · GW(p)
quantum mechanics famously provides the measure on phase-space that classical statistical mechanics took as axiomatic
I'd be interested in a citation of what you're referring to here!
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-25T21:29:58.782Z · LW(p) · GW(p)
The state-space (for particles) in statmech is the space of possible positions and momenta for all particles.
The measure that's used is uniform over each coordinate of position and momentum, for each particle.
This is pretty obvious and natural, but not forced on us, and:
- You get different, incorrect predictions about thermodynamics (!) if you use a different measure.
- The level of coarse graining is unknown, so every quantity of entropy has an extra "+ log(# microstates per unit measure)" which is an unknown additive constant. (I think this is separate from the relationship between bits and J/K, which is a multiplicative constant for entropy -- k_B -- and doesn't rely on QM afaik.)
On the other hand, Liouville's theorem gives some pretty strong justification for using this measure, alleviating (1) somewhat:
https://en.wikipedia.org/wiki/Liouville%27s_theorem_(Hamiltonian)
In quantum mechanics, you have discrete energy eigenstates (...in a bound system, there are technicalities here...) and you can define a microstate to be an energy eigenstate, which lets you just count things and not worry about measure. This solves both problems:
- Counting microstates and taking the classical limit gives the "dx dp" (aka "dq dp") measure, ruling out any other measure.
- It tells you how big your microstates are in phase space (the answer is related to Planck's constant, which you'll note has units of position * momentum).
This section mostly talks about the question of coarse-graining, but you can see that "dx dp" is sort of put in by hand in the classical version: https://en.wikipedia.org/wiki/Entropy_(statistical_thermodynamics)#Counting_of_microstates
I wish I had a better citation but I'm not sure I do.
In general it seems like (2) is talked about more in the literature, even though I think (1) is more interesting. This could be because Liouville's theorem provides enough justification for most people's tastes.
Finally, knowing "how big your microstates are" is what tells you where quantum effects kick in. (Or vice versa -- Planck estimated the value of the Planck constant by adjusting the spacing of his quantized energy levels until his predictions for blackbody radiation matched the data.)
↑ comment by So8res · 2022-10-24T19:33:11.231Z · LW(p) · GW(p)
:D
(strong upvote for shifting position in realtime, even if by small degrees and towards the opposite side of the fence from me :-p)
(I'm not actually familiar enough w/ statmech to know what measure we use on phase-space, and I'm interested in links that explain what it is, and how it falls out of QM, if you have any handy :D)
I don't currently have much sympathy for "entropy and differential entropy are different" view, b/c I occasionally have use for non-uniform measures even in the finite case.
Like, maybe I'm working with distributions over 10 states, and I have certain constraints I'm trying to hit, and subject to those constraints I wanna maximize entropy wrt the Binomial distribution as the measure. And you might be like "Well, stop doing that, and start working with distributions on 2^10 states, and convert all your constraints to refer to the bitcount of the new state (instead of the value of the old state). Now you can meet your constraints while maximizing entropy wrt the uniform measure like a normal person." To which I'd reply (somewhat trollishly) "that rejoinder doesn't work in the limit, so it must get weaker and weaker as I work with more and more states, and at numbers as large as 10 this rejoinder is so weak as to not compel me."
From my perspective, the obvious rejoinder to "entropy is already two-place" is "insofar as entropy is two-place, cross-entropy is three-place!". Which, ftr, I might find compelling. It depends whether differential cross-entropy needs all three parameters (P, Q, μ), or whether we can combine two of them (like by using (P, μP/Q) or something). Or, at least, that's what my intuition says off-the-cuff; I'm running on guesswork and a stale cache here :-p.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-25T04:14:33.006Z · LW(p) · GW(p)
From my perspective, the obvious rejoinder to "entropy is already two-place" is "insofar as entropy is two-place, cross-entropy is three-place!".
I think this is roughly where I'm at now.
After thinking a bit and peeking at Wikipedia, the situation seems to be:
The differential entropy of a probability density p is usually defined as
This is unfortunate, because it isn't invariant under coordinate transformations on x. A more principled (e.g. invariant) thing to write down, courtesy of Jaynes, is
where is a density function for some measure . We can also write this as
(Jaynes' continuous entropy of P with respect to )
in terms of a probability measure P with , which is a bit more clearly invariant.
Now we can define a cross-entropy-like thing as
(continuous cross-entropy of Q under P with respect to )
...and a small surprise is coming up. Jumping back to the discrete case, the KL divergence or "relative entropy" is
What happens when we try to write something analogous with our new continuous entropy and crossentropy? We get
which looks like the right generalization of discrete KL divergence, but also happens to be the continuous entropy of P with respect to Q! (The dependence on drops out.) This is weird but I think it might be a red herring.
We can recover the usual definitions in the discrete (finite or infinite) case by taking to be a uniform measure that assigns 1 to each state (note that this is NOT a probability measure -- I never said was a probability measure, and I don't know how to handle the countably infinite case if it is.)
So maybe the nicest single thing to define, for the sake of making everything else a concisely-specified special case, is
("H" chosen because it is used for both entropy and cross-entropy, afaik unlike "S").
We could take KL divergence as a two-argument atomic thing, or work with for a scalar function f and a distribution P, but I think these both make it cumbersome to talk about the things everyone wants to talk about all the time. I'm open to those possibilities, though.
The weird observation about KL divergence above is a consequence of the identity
but I think this is a slightly strange fact because R is a probability measure and is a general measure. Hmm.
We also have
in the case that is a probability measure, but not otherwise.
And I can rattle off some claims about special cases in different contexts:
- A (the?) fundamental theorem of entropy-like stuff is , or "crossentropy >= entropy".
- In the discrete case, practitioners of information theory and statistical physics tend to assume is uniform with measure 1 on each state, and (almost?) never discuss it directly. I'll call this measure U.
- They reserve the phrase "entropy of P" (in the discrete case) for H(P, P; U), and this turns out to be an extremely useful quantity.
- They use "cross-entropy of Q relative to P" to mean H(P, Q; U)
- They use "KL divergence from Q to P" (or "relative entropy ...") to mean H(P, Q; P) = -H(P, P; Q) = H(P, Q; U) - H(P, P; U)
- For a state s, let's define delta_s to be the distribution that puts measure 1 on s and 0 everywhere else.
- For a code C, let's define f_C to be the "coin flip" distribution that puts probability 2^-len(C(s)) on state s (or the sum of this over all codewords for s, if there are several). (Problem: what if C doesn't assign all its available strings, so that this isn't a probability distribution? idk.)
- (see also https://en.wikipedia.org/wiki/Cross_entropy#Motivation)
- If a state s has only one codeword C(s), the length of that codeword is len(C(s)) = H(delta_s, f_C; U)
- Note that this is not H(delta_s, delta_s; U), the entropy of delta_s, which is always zero. This is a lot of why I don't like taking "entropy of s" to mean H(delta_s, f_C; U).
- Information theorists use "surprisal of s under P" (or "self-information ...") to mean H(delta_s, P; U)
- The expected length of a code C, for a source distribution P, is H(P, f_C; U)
- Consequence from fundamental thm: a code is optimal iff f_C = P; the minimal expected length of the code is the entropy of P
- If you use the code C when you should've used D, your expected length is H(f_D, f_C; U) and you have foolishly wasted H(f_D, f_C; f_D) bits in expectation.
- Physicists use "entropy of a macrostate" to mean things like H(p_A, p_A; U) where p_A is a uniform probability measure over a subset A of the state space, and possibly also for other things of the form H(P, P; U) where P is some probability measure that corresponds to your beliefs if you only know macroscopic things.
- Kolmogorov complexity ("algorithmic entropy") of a state s is, as you argue, maybe best seen as an approximation of H(delta_s, p_Solomonoff; U). I don't see a good way of justifying the name by analogy to any "entropy" in any other context, but maybe I'm missing something.
- This makes that one quote from Wiktionary into something of the form: "H(P, p_Solomonoff; U) ~= H(P, P, U) whenever P is computed by a short program". This makes sense for some sense of "~=" that I haven't thought through.
- When working in continuous spaces like R, people typically define "[differential] entropy of P" as H(P, P; L) where L is the Lebesgue measure (including the uniform measure on R). If they are working with coordinate transformations from R to R, they implicitly treat one variable as the "true" one which the measure should be uniform on, often without saying so.
- They define cross-entropy as H(P, Q; L)....
- ...and KL divergence as H(P, Q; L) - H(P, P; L) = H(P, Q; P) (same as discrete case!)
- But sometimes people use Jaynes' definitions, which replace L with an arbitrary (and explicitly-specified) measure, like we're doing here. In that case, "entropy" is H(P, P; mu) for an arbitrary mu.
- The properness of the logarithmic scoring rule also follows from the fundamental theorem. Your (subjective) expected score is H(your_beliefs, your_stated_beliefs; U) and this is minimized for your_stated_beliefs = your_beliefs.
↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-25T04:17:43.915Z · LW(p) · GW(p)
I wanted to let that comment be about the interesting question of how we unify these various things.
But on the ongoing topic of "why not call all this entropy, if it's all clearly part of the same pattern?":
When the definition of some F(x) refers to x twice, it's often useful to replace one of them with y and call that G(x, y). But it's usually not good for communication to choose a name for G(x, y) that (almost) everyone else uses exclusively for F(x), especially if you aren't going to mention both x and y every time you use it, and doubly especially if G is already popular enough to have lots of names of its own (you might hate those names, but get your own[1]).
e.g.: x*y is not "the square of x and y" much less "the square of x [and y is implied from context]", and the dot product v.w is not "the norm-squared of v and w" etc.
[1] might I suggest "xentropy"?
Replies from: So8res↑ comment by So8res · 2022-10-25T15:05:28.429Z · LW(p) · GW(p)
:D
(strong upvote for delicious technical content)
(also fyi, the markdown syntax for footnotes is like blah blah blah[^1] and then somewhere else in the file, on a newline, [^1]: content of the footnote)
This updates me a fair bit towards the view that we should keep entropy and cross-entropy separate.
The remaining crux for me is whether the info theory folks are already using "entropy" to mean "the minimum expected surprise you can achieve by choosing a code from this here space of preferred codes" (as per your "wiggle room" above), in which case my inclination is to instead cackle madly while racing my truck through their wiggle-room, b/c that's clearly a cross-entropy.
At a glance through wikipedia, it doesn't look like they're doing that, though, so I retreat.
But, hmm, I'm not sure I retreat all the way to having separate words.
I'm persuaded that "the square of x" should absolutely not mean "x * y [where y is implied from context]", and I no longer think that "entropy" should mean the cross-entropy with Q implied from context. (Thanks for the distillation of why it's mad!)
But, like, if geometrists instead invented a two-place operation rect, with a general form rect(x, y) := x * y, and declared that rect(x) was shorthand for rect(x, x), then I would not protest; this seems like a reasonable an unambiguous way to reduce the number of names floating around.[1]
And this seems to me like exactly what the information theorists (by contrast to the physicists) are doing with (by contrast to )!
Like, the notations and are just begging for us to pronounce the same way in each case; we're not tempted to pronounce the former as "eych" and the latter as "cross-eych". And no ambiguity arises, so long as we use the rule that if Q is left out then we mean P.
Thus, I propose the following aggressive nomenclature:
- the "P-entropy of Q (wrt μ)" aka is the general form
- the "entropy of P (wrt μ)" aka is a shorthand for "the P-entropy of P (wrt μ)"
- μ may be omitted when the canonical uniform measure is clear from context
With the following bold extension:
- the "Q-complexity of P (wrt μ)" aka is another name for
- the "complexity of P (wrt μ)" aka is used when Q can be inferred from context
- we cast codes/UTMs/points/sets to distributions in natural ways
Thus, when we have a canonical universal Turing machine U on hand, "the complexity of f" aka means "the Solomonoff(U)-complexity of δ(f)" aka "the δ(f)-entropy of Solomonoff(U)".
(I'm not wedded to the word "complexity" or the symbol "" there. What I want is terms and symbols that let me quickly say something that means the ləg-sum-əxp of the code-lengths of all codes for in the implicit coding scheme.)
(One reason I like the pronunciation "P-entropy of Q" is that saying "P-entropy" feels intuitively like we're obvously weighting by P (perhaps b/c of the analogy to "P-expectation"), and so I expect it to help me remember which distribution is which in H(P, Q).)
As a fallback, I think 'xentropy' is decent, but my guess is that 'crossent' is better. It has fewer syllables, it's already common, and it's more obvious what it means.
(If I was using 'crossent' a lot I might start using 'selfent' to mean the entropy, b/c of the symmetry and the saved syllable. Three syllables for 'entropy' is kinda a lot!)
That said, I currently personally prefer using the same word for both in this case, and note that it's very heavily precedented by info theory's .
Musing aloud for my own sake: it's not in general bad to say "the general form is , but when we say that means to infer from context". We do that even here, with the in entropy! The thing that's bad is when is a very common case. In particular, the rule " means " and the rule " means " are in conflict, and you can only have one of those active at a time. And in the case of entropy, the rule has a much, much stronger claim to the throne. So we concede that means and not , but without conceding that you can't invent other notation that says should be inferred from context. ↩︎
↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-25T18:02:35.472Z · LW(p) · GW(p)
I agree with all the claims in this comment and I rather like your naming suggestions! Especially the "P-entropy of Q = Q-complexity of P" trick which seems to handle many use cases nicely.
(So the word "entropy" wasn't really my crux? Maybe not!)
Replies from: So8res↑ comment by So8res · 2022-10-25T18:58:08.636Z · LW(p) · GW(p)
Convergence! 🎉🎉. Thanks for the discussion; I think we wound up somewhere cooler than I would have gotten to on my own.
Now we just need to convince Alex :-p. Alex, are you still reading? I'm curious for your takes on our glorious proposal.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-10-25T19:56:55.967Z · LW(p) · GW(p)
Heh, I'm still skimming enough to catch this, but definitely not evaluating arguments.
I'm definitely still open to both changing my mind about the best use of terms and also updating the terminology in the sequence (although I suspect that will be quite a non-trivial amount of modified prose). And I think it's best if I don't actually think about it until after I publish another post.
I'd also be much more inclined to think harder about this discussion if there were more than two people involved.
My main goal here has always been "clearly explain the existing content so that people can understand it", which is very different from "propose a unification of the whole field" (it's just that "unification" is my native method of understanding).
Replies from: So8res↑ comment by So8res · 2022-10-25T20:52:39.092Z · LW(p) · GW(p)
Cool cool. A summary of the claims that feel most important to me (for your convenience, and b/c I'm having fun):
- K-complexity / "algorithmic entropy" is a bad concept that doesn't cleanly relate to physics!entropy or info!entropy.
- In particular, the K-complexity of a state is just the length of the shortest code for , and this is bad because when has multiple codes it should count as "simpler". (A state with five 3-bit codes is simpler than a state with one 2-bit code.) (Which is why symmetry makes a concept simpler despite not making its code shorter.)
- If we correct our notion of "complexity" to take multiple codes into account, then we find that complexity of a state (with respect to a coding scheme ) is just the info!cross-entropy . Yay!
Separately, some gripes:
- the algorithmic information theory concept is knuckleheaded, and only approximates info!entropy if you squint really hard, and I'm annoyed about it
- I suspect that a bunch of the annoying theorems in algorithmic information theory are annoying precisely because of all the squinting you have to do to pretend that K-complexity was a good idea
And some pedagogical notes:
- I'm all for descriptive accounts of who uses "entropy" for what, but it's kinda a subtle situation because:
- info!entropy is a very general concept,
- physics!entropy is an interesting special case of that concept (in the case where the state is a particular breed of physical macrostate),
- algo!entropy is a derpy mistake that's sniffing glue in the corner,
- algo!entropy is sitting right next to a heretofore unnamed concept that is another interesting special case of info!(cross-)entropy (in the case where the code is universal).
(oh and there's a bonus subtlety that if you port algo!entropy to a situation where the coding schema has at most one code per state--which is emphatically not the case in algorithmic information theory--then in that limited case it agrees with info!cross-entropy. Which means that the derpiness of algo!entropy is just barely not relevant to this particular post.)
So, uh, good luck.
And separately, the key points about notation (while I'm summarizing, acknowledging that the notation might not to change in your coming posts):
- The corrected notion of the "complexity" of a state given a coding scheme is
- It's confusing to call this the "entropy" of , because that sounds like , which by long-established convenient convention means .
- An elegant solution is to just call this the "(-)complexity" of instead.
- This highlights a cool reciprocal relationship between (cross-)entropy and complexity, where the -entropy of is the same as the -complexity of . This can perhaps be mined for intuition.
↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-26T01:18:40.035Z · LW(p) · GW(p)
Endorsed.
↑ comment by habryka (habryka4) · 2022-10-23T01:31:20.641Z · LW(p) · GW(p)
Note: I added LaTeX to your comment to make it easier to read. Hopefully you don't mind. Pretty sure I translated it correctly. Feel free to revert of course.
↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-20T23:18:34.483Z · LW(p) · GW(p)
Footnote 17 sounds confusing and probably wrong to me, but I haven't thought it through. Macrostates should have some constraint that makes their total probability 1; you can't have a macrostate containing a single very unlikely microstate.
(Edit: "wrong" seems a bit harsh on reflection but I dislike the vagueness about "cheating" a lot. The single-improbable-thing macrostate should just not typecheck instead of somehow being against the spirit of things.)
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-20T23:36:56.903Z · LW(p) · GW(p)
I would maybe say that your "average entropy" (what I'd call entropy) is always the average over every state, every single time, and (uniform) macrostates are just a handy conceptual shorthand for saying "I want all of these states to have equal p (equal -log p) and all of these to have zero p (infinite -log p)" without getting bogged down in why 0 log 0 is 0. A state is "in" a macrostate if it's one of the states with nonzero p for that macrostate, but the sum is always over everything.
comment by Ruby · 2022-10-30T19:32:13.265Z · LW(p) · GW(p)
Curated. Came here to curate this and I think So8res's [LW · GW] comment serves as good a curation notice as I might write myself:
This piece reads to me like the output of someone who worked hard to comprehend a topic in full, without accepting the rest of society's cloudy bullshit / papered-over-confusion / historical baggage in place of answers. And in a particularly thorny case, no less. And with significant effort made to articulate the comprehension clearly and intuitively to others.
For instance: saying "if we're going to call all of these disparate concepts 'entropy', then let's call the length of the name of a microstate 'entropy' also; this will tie the whole conceptual framework together and make what follows more intuitive" is a bold move, and looks like the product of swallowing the whole topic and then digesting it down into something organized and comprehensible. It strikes me as a unit of conceptual labor.
Respect.
I'm excited to see where this goes.
I, too, am excited to see where this goes.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-10-31T04:36:00.442Z · LW(p) · GW(p)
I'm psyched to have a podcast version! The narrator did a great job. I was wondering how they were going to handle several aspects of the post, and I liked how they did all of them.
comment by mukashi (adrian-arellano-davin) · 2022-10-21T01:23:30.847Z · LW(p) · GW(p)
Thank you very much for writing this.
I have struggled with entropy since I first studied it in high school. I was taught that entropy measures "disorder" or the "chaos" in a system. I was totally disconcerted by the units (Joules/Kelvin), because I couldn't grasp it intuitively, the same way I could reason, for instance, about speed. I searched for a long time for an answer. Everything became much clearer (I remember this as a revelation) once I read "A farewell to Entropy", by Arieh Ben-Naim. According to the author, the only reason entropy is measured in J/K (in thermodynamics) is historical: we have different units for temperature and energy because the temperature was defined at a time when we did not understand very well the kinetic theory (Temperature should be in fact, measured in Joules) By using Joules for temperature, the entropy of a thermodynamic system would become in fact unitless, and the later connection with the entropy from information theory would have been much easier to draw (apparently people have discussed much that they are different things). In fact, it seems that the reason why we use the term entropy in Information Theory is that Von Neumann suggested Shannon use the term since a similar concept had been applied in statistical mechanics "but nobody understood it really well".
I don't know if the above statements are controversial and some physicists would strongly disagree with what I wrote, but in any case, "A Farewell to Entropy" does a great job at explaining what entropy means with very simple math.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-10-21T01:28:11.935Z · LW(p) · GW(p)
The historical baggage is something that tripped me up, too. In an upcoming post I have a section about classical thermodynamic entropy, including an explanation of the weird units!
Replies from: adrian-arellano-davin↑ comment by mukashi (adrian-arellano-davin) · 2022-10-21T01:31:11.828Z · LW(p) · GW(p)
That's great, I subscribed and looking forward to it!
comment by Yoav Ravid · 2023-12-16T06:49:48.939Z · LW(p) · GW(p)
You're not even holding a specific state, but are instead designing something to deal with a "type" of state, like writing a compression algorithm for astronomical images.
This reminds me of K-complexity is silly; use cross-entropy instead [LW · GW], though I'm not quite sure how/whether they're actually related.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2023-12-16T19:33:23.859Z · LW(p) · GW(p)
Yeah, So8res wrote that post after reading this one and having a lot of discussion in the comments. That said, my memory was that people eventually convinced him that the title idea in his post was wrong.
Replies from: Yoav Ravid↑ comment by Yoav Ravid · 2023-12-16T19:45:17.675Z · LW(p) · GW(p)
I think they later agreed he was actually right, and the initial criticism was based on a misunderstanding.
comment by Vitor · 2022-11-06T03:03:55.985Z · LW(p) · GW(p)
While I think this post overall gives good intuition for the subject, it also creates some needless confusion.
Your concept of "abstract entropy" is just Shannon entropy applied to uniform distributions. Introducing Shannon entropy directly, while slightly harder, gives you a bunch of the ideas in this post more or less "for free":
-
Macrostates are just events and microstates are atomic outcomes (as defined in probability theory). Any rules how the two relate to each other follow directly from the foundations of probability.
-
The fact that E[-log x] is the only reasonable function that can serve as a measure of information. You haven't actually mentioned this (yet?), but having an axiomatic characterization of entropy hammers home that all of this stuff must be the way it is because of how probability works. For example, your "pseudo-entropy" of Rubik's cube states (distance from the solved state) might be intuitive, but it is wrong!
-
derived concepts, such as conditional entropy and mutual information, fall out naturally from the probabilistic view.
-
the fact that an optimal bit/guess must divide the probability mass in half, not the probability space.
I hope I don't come across as overly harsh. I know that entropy is often introduced in confusing ways in various sciences, specially physics, where its hopelessly intertwined with the concrete subject matter. But that's definitely not the case in computer science (more correctly called informatics), which should be the field you're looking at if you want to deeply understand the concept.
comment by Lakin (ChrisLakin) · 2023-02-20T00:27:57.882Z · LW(p) · GW(p)
Registering that I think "[entropy] can be used to explain the arrow of time" is bunk (I've linked 4:50, but see particularly the animation at 5:49): entropy works to explain the arrow of time only if we assume a low-entropy initial state (eg the big bang) in the past
Edit: Oh hm maybe the description isn't "time moves forward" but "time moves away from the big bang"
comment by Lakin (ChrisLakin) · 2023-02-20T00:21:27.111Z · LW(p) · GW(p)
I REALLY liked this. A few years ago I scoured the internet trying to find a good conceptual explanation of entropy, and I couldn't find any. This is by far the best that I've seen. I'm glad you made it!
comment by awenonian · 2023-02-07T03:31:49.157Z · LW(p) · GW(p)
Is it important that negentropy be the result of subtracting from the maximum entropy? It seemed a sensible choice, up until it introduces infinities, and made every state's negentropy infinite. (And also that, if you subtract from 0, then two identical states should have the same negentropy, even in different systems. Unsure if that's useful, or harmful).
Though perhaps that's important for the noting that reducing an infinite system to a finite macrostate is an infinite reduction? I'm not sure if I understand how (or perhaps when?) that's more useful than having it be defined as subtracted from 0, such that finite macrostates have finite negentropy, and infinite macrostates have -infinite negentropy (showing that you really haven't reduced it at all, which, as far as I understand with infinities, you haven't, by definition).
comment by Caerulean · 2022-11-03T12:36:31.244Z · LW(p) · GW(p)
Reading this piece about entropy as an abstract concept reminded me of a beautiful story touching on the topic: Exhalation by Ted Chiang (wikipedia page with spoilers).
comment by andrew sauer (andrew-sauer) · 2022-11-03T02:40:23.875Z · LW(p) · GW(p)
Do you think it would be easier to solve the Diamond maximizer - Arbital problem if you were trying to maximize entropy instead of diamonds, due to entropy being more abstract and less dependent on specific ontology?
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-11-03T03:08:35.318Z · LW(p) · GW(p)
Hm, it seems pretty dependent on ontology to me – that's pretty much what the set of all states is, an ontology for how the world could be.
comment by cubefox · 2022-10-23T02:01:46.811Z · LW(p) · GW(p)
This is a very thought provoking post. As far as I understand, it is an attempt of finding a unified theory of entropy.
I admit I am still somewhat confused about this topic. This is partly because of my insufficient grasp of the material in this post, but, I think, also partly because you didn't yet went quite far enough with your unification.
One point is the thinking in terms of "states". A macrostate is said to be a set of microstates. As far as I understand, the important thing here is that all microstates are presumed to be mutually exclusive, such that for any two microstates and the probability of their conjunction is zero, i.e. . But that seems to be not a necessary restriction in general in order to speak about the entropy of something. So it seems better to use as the bearers of probability a Boolean algebra of propositions (or "events", as they are called in Boolean algebras of sets), just as in probability theory. Propositions are logical combinations of other propositions, e.g. disjunctions, conjunctions, and negations. A macrostates is then just a disjunction of microstates, where the microstates are mutually exclusive. But the distinction between micro- and macrostates is no longer necessary, since with a Boolean algebra we are not confined to mutually exclusive disjunctions.
Moreover, a microstate may be considered a macrostate itself, if it can itself be represented as a disjunction of other microstates. For example, the macrostate "The die comes up even" consists of a disjunction of the microstates "The die comes up 2", "The die comes up 4", "The die comes up 6". But "The die comes up 2" consists of a disjunction of many different orientations the die may land on the table. So the distinction between macrostates and microstates apparently cannot be upheld in an absolute way anyway, only in a relative way, which again means we have to treat the entropy of all propositions in a unified manner.
[We may perhaps think of fundamental "microstates" as (descriptions of) "possible worlds", or complete, maximally specific possible ways the world may be. Since all possible worlds are mutually exclusive (just exactly one possible world is the actual world), every proposition can be seen as a disjunction of such possible worlds: the worlds in which the proposition is true. But arguably this is not necessarily what have in mind with "microstates".]
So what should a theory of entropy do with a Boolean algebra of propositions? Plausibly it should define which mathematical properties the entropy function over a Boolean algebra has to satisfy -- just like the three axioms of probability theory define what mathematical properties a probability function (a "probability distribution") has to satisfy. More precisely, entropy uses itself a probability function, so entropy theory has to be an extension of probability theory. We need to add axioms -- or definitions, if we treat entropy as reducible to probability.
One way to begin is to add an axiom for mutually exclusive disjunction, i.e. for where , for two propositions and . You did already suggest something related to this: A formula for the expected entropy of such a disjunction. The expected value of a proposition is simply its value multiplied by its probability. And the expected value of a mutually exclusive disjunction is the sum of the expected values of the disjuncts. So: This is equivalent to In order to get the entropy (instead of the expected entropy) we just have to divide by : Which, because of mutual exclusivity, is equivalent to A quantity of this form is called a weighted average. So expected value and weighted average are not generally the same. They are only the same when , which need not be the case. For example, not all "macrostates" have probability one. All we can in general say about "macrostates" and "microstates" is that the entropy of a macrostate is the weighted average of the entropies of its microstates, while the expected entropy of a macrostate is the sum of the expected entropies of its microstates.
Another way to write the weighted average is in terms of conditional probability instead of as a fraction:
There is an interesting correspondence to utility theory here: The entropy of a proposition being the weighted average entropy of its mutually exclusive disjuncts is analogous to the utility of a proposition being the weighted average utility of its mutually exclusive disjuncts. In Richard Jeffrey's utility theory the weighted average formula is called "desirability axiom". Another analogy is apparently the role of tautologies: As in utility theory, it makes sense to add an axiom stating that the entropy of a tautology is zero, i.e. In fact, those two axioms (together with the axioms of probability theory) are sufficient for utility theory. But they allow for negative values. Negative utilities make sense in utility theory, but entropy is strictly non-negative. We could add an axiom for that, corresponding to the non-negativity axiom in probability theory: But I'm still not sure this would fully characterize entropy. After all, you also propose that entropy of a microstate is equivalent to its information content / self-information / surprisal, which is defined purely in terms of probability. But since it seems we have to give up the microstate/macrostate distinction in favor of a Boolean algebra of propositions, this would have to apply to all propositions. I.e. This would require that I'm not sure under which conditions this would be true, but it seems to be a pretty restrictive assumption. You said that information content is minimal (expected?) entropy. It is not clear why we should assume that entropy is always minimal.
It seems to me we are not yet quite there with our unified entropy theory...
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-23T18:58:08.287Z · LW(p) · GW(p)
I think macrostates are really a restricted kind of probability distribution, not a kind of proposition. But they're the kind of distribution p_A that's uniform over a particular disjunction A of microstates (and zero elsewhere), and I think people often equivocate between the disjunction A and the distribution p_A.
[EDIT: "macrostate" is a confusing term, my goal here is really to distinguish between A and p_A, whatever you want to call them]
In general, though, I think macrostates aren't fundamental and you should just think about distributions if you're comfortable with them.
I think microstates should indeed be considered completely-specified possible worlds, from this perspective.
"Average entropy" / "entropy of a macrostate" in OP ("entropy" in standard usage) is a function from probability distributions to reals. Shannon came up with an elegant set of axioms for this function, which I don't remember offhand, but which uniquely pins down the expectation of -log(p(microstate)) as the entropy function (up to a constant factor).
"Entropy of a microstate" in OP ("surprisal" in information theory, no standard name otherwise AFAIK) is a function from probability distributions to random variables, which is equal to -log(p(microstate)).
So I guess I'm not sure propositions play that much of a role in the usual definition of entropy.
On the other hand, if we do extend entropy to arbitrary propositions A, it probably does make sense to define it as the conditional expectation S(A) = E[-log p | A], as you did.
Then "average entropy"/"entropy" of a macrostate p_A is S(True) under the distribution p_A, and "entropy"/"surprisal" of a microstate B (in the macrostate p_A) is S(B) under the distribution p_A.
By a slight coincidence, S(True) = S(A) under p_A, but S(True) is the thing that generalizes to give entropy of an arbitrary distribution.
I've never seen an exploration of what happens if you apply this S() to anything other than individual microstates or True, so I'm pretty curious to see what you come up with if you keep thinking about this!
This is more complicated if there's a continuous space of "microstates", of course. In that case the sigma algebra isn't built up from disjunctions of individual events/microstates, and you need to define entropy relative to some density function as the expectation of -log(density). It's possible there's a nice way to think about that in terms of propositions.
Replies from: cubefox↑ comment by cubefox · 2022-10-23T23:00:24.030Z · LW(p) · GW(p)
Could you clarify this part?
On the other hand, if we do extend entropy to arbitrary propositions A, it probably does make sense to define it as the conditional expectation S(A) = E[-log p | A], as you did.
Then "average entropy"/"entropy" of a macrostate p_A is S(True) under the distribution p_A, and "entropy"/"surprisal" of a microstate B (in the macrostate p_A) is S(B) under the distribution p_A.
By a slight coincidence, S(True) = S(A) under p_A, but S(True) is the thing that generalizes to give entropy of an arbitrary distribution.
I think I don't understand your notation here.
Replies from: adam-scherlis↑ comment by Adam Scherlis (adam-scherlis) · 2022-10-25T20:45:40.587Z · LW(p) · GW(p)
I think I was a little confused about your comment and leapt to one possible definition of S() which doesn't satisfy all the desiderata you had. Also, I don't like my definition anymore, anyway.
Disclaimer: This is probably not a good enough definition to be worth spending much time worrying about.
First things first:
We may perhaps think of fundamental "microstates" as (descriptions of) "possible worlds", or complete, maximally specific possible ways the world may be. Since all possible worlds are mutually exclusive (just exactly one possible world is the actual world), every proposition can be seen as a disjunction of such possible worlds: the worlds in which the proposition is true.
I think this is indeed how we should think of "microstates". (I don't want to use the word "macrostate" at all, at this point.)
I was thinking of something like: given a probability distribution p and a proposition A, define
"S(A) under p" =
where the sums are over all microstates x in A. Note that the denominator is equal to p(A).
I also wrote this as S(A) = expectation of (-log p(x)) conditional on A, or , but I think "log p" was not clearly "log p(x) for a microstate x" in my previous comment.
I also defined a notation p_A to represent the probability distribution that assigns probability 1/|A| to each x in A and 0 to each x not in A.
I used T to mean a tautology (in this context: the full set of microstates).
Then I pointed out a couple consequences:
- Typically, when people talk about the "entropy of a macrostate A", they mean something equal to . Conceptually, this is based on the calculation , which is the same as either "S(A) under p_A" (in my goofy notation) or "S(T) under p_A", but I was claiming that you should think of it as the latter.
- The (Shannon/Gibbs) entropy of p, for a distribution p, is equal to "S(T) under p" in this notation.
- Finally, for a microstate x in any distribution p, we get that "S({x}) under p" is equal to -log p(x).
All of this satisfied my goals of including the most prominent concepts in Alex's post:
- log |A| for a macrostate A
- Shannon/Gibbs entropy of a distribution p
- -log p(x) for a microstate x
And a couple other goals:
- Generalizing the Shannon/Gibbs entropy, which is , in a natural way to incorporate a proposition A (by making the expectation into a conditional expectation)
- Not doing too much violence to the usual meaning of "entropy of macrostate A" or "the entropy of p" in the process
But it did so at the cost of:
- making "the entropy of macrostate A" and "S(A) under p" two different things
- contradicting standard terminology and notation anyway
- reinforcing the dependence on microstates and the probabilities of microstates, contrary to what you wanted to do
So I would probably just ignore it and do your own thing.
Replies from: cubefox↑ comment by cubefox · 2022-10-28T01:57:05.097Z · LW(p) · GW(p)
Okay, I understand. The problem with fundamental microstates is that they only really make sense if they are possible worlds, and possible worlds bring their own problems.
One is: we can gesture at them, but we can't grasp them. They are too big, they each describe a whole world. We can grasp the proposition that snow is white, but not the equivalent disjunction of all the possible worlds where snow is white. So we can't use then for anything psychological like subjective Bayesianism. But maybe that's not your goal anyway.
A more general problem is that there are infinitely many possible worlds. There are even infinitely many where snow is white. This means it is unclear how we should define a uniform probability distribution over them. Naively, if is 0, their probabilities do not sum to 1, and if it is larger than 0, they sum to infinity. Either option would violate the probability axioms.
Warning: long and possibly unhelpful tangent ahead
Wittgenstein's solution for this and other problems (in the Tractatus) was to ignore possible worlds and instead regard "atomic propositions" as basic. Each proposition is assumed to be equivalent to a finite logical combination of such atomic propositions, where logical combination means propositional logic (i.e. with connectives like not, and, or, but without quantifiers). Then the a priori probability of a proposition is defined as the rows in its truth table where the proposition is true divided by the total number of rows. For example, for and atomic, the proposition has probability 3/4, while has probability 1/4: The disjunction has three out of four possible truth-makers - (true, true), (true, false), (false, true), while the conjunction has only one - (true, true).
This definition in terms of the ratio of true rows in the "atomicized" truth-table is equivalent to the assumption that all atomic propositions have probability 1/2 and that they are all probabilistically independent.
Wittgenstein did not do it, but we can then also definite a measure of information content (or surprisal, or entropy, or whatever we want to call it) of propositions, in the following way:
- Each atomic proposition has information content 1.
- The information content of the conjunction of two atomic propositions is additive.
- The information content of a tautology is 0.
So for a conjunction of atomic propositions with length the information content of that conjunction is (), while its probability is (). Generalizing this to arbitrary (i.e. possibly non-atomic) propositions , the relation between probability and information content is or, equivalently, Now that formula sure looks familiar!
The advantage of Wittgenstein's approach is that we can assign an a priori probability distribution to propositions without having to assume a uniform probability distribution over possible worlds. It is assumed that each proposition is only a finite logical combination of atomic propositions, which would avoid problems with infinity. The same thing holds for information content (or "entropy" if you will).
Problem is ... it is unclear what atomic propositions are. Wittgenstein did believe in them, and so did Bertrand Russell, but Wittgenstein eventually gave up the idea. To be clear, propositions expressed by sentences like "Snow is white" are not atomic in Wittgenstein's sense. "Snow is white" is not probabilistically independent of "Snow is green", and it doesn't necessarily seem to have a priori probability 1/2. Moreover, the restriction to propositional logic is problematic. If we assume quantifiers, Wittgenstein suggested that we interpret the universal quantifier "all" as a possibly infinite conjunction of atomic propositions, and the existential quantifier "some" as a possibly infinite disjunction of atomic propositions. But that leads again to problems with infinity. It would always give the former probability 0 and the latter probability 1.
So logical atomism may be just as dead an end as possible worlds, perhaps worse. But it is somewhat interesting to note that approaches like algorithmic complexity have similar issues. We may want to assign a string of bits a probability or a complexity (an entropy? an information content?), but we may also want to say that some such string corresponds to a proposition, e.g. a hypothesis we are interested in. There is some superficial way of associating a binary string with propositional formulas, by interpreting e.g. as a conjunction . But there likewise seems to be no room for quantifiers in this interpretation.
I guess a question is what you want to do with your entropy theory. Personally I would like to find some formalization of Ockham's razor which is applicable to Bayesianism. Here the problems mentioned above appear fatal. Maybe for your purposes the issues aren't as bad though?
comment by Jon Garcia · 2022-10-21T00:12:11.726Z · LW(p) · GW(p)
Excellent introduction. Your examples were all very intuitive.
For those who are reading, one way to get an intuition for the difference between binary strings and bits is to look at data compression. To begin with, it's easy to create a code like ASCII, where every character is represented by a binary string of length 8 (usually referred to as 8 "bits" or one byte), allowing up to unique characters. This type of code will allow you to represent a text document in English that's 1024 characters in length with exactly 1 kB of information.
Except that's not quite right. The 1 kB is only how much storage space it takes up in computer memory, not how much information the document actually contains.
In fact, each English character has closer to something like 1.1 bits per character in terms of actual information content, so an optimal compression algorithm could theoretically get that document down to around 141 bits. This is because not all characters occur with equal frequencies in all contexts. In fact, which character goes next in a sequence turns out to be quite predictable. Every time a predictive model reaches a point where its confusion about the next token/state is distributed 50-50, it needs to be given one additional bit of information to resolve this confusion. When things are more predictable, it will need fewer bits, and when things are less predictable, it will need more. As you said:
It turns out that for a given probability distribution over states, the encoding that minimizes average entropy uses strings that have one bit for every halving that it takes to get to
What you wrote as is typically referred to as the "surprise" associated with state , proportional to how many bits are necessary to resolve the confusion of a predictive model.
One example, getting back to data compression, is Huffman coding. Using just character frequency as the predictive model , the surprise for each character will be equal to . Huffman coding approximates this by giving shorter bit strings to more frequent characters and ensuring that no character's bit string is a prefix of any other character's bit string. As you described (without mentioning Huffman coding):
This is how you can use different-sized labels without having an additional "all done" symbol. If the bits known so far match a whole label, then they are not a prefix of any other label. Therefore they could not match any other label, and so you know the bits must refer to the label they already match so far. And using different-sized labels in your "prefix code" lets you reduce your expected entropy in cases where the states are not equally likely.
Using this method, you could compress the English document above down to something like 681 bits, assuming an average of 5.32 bits per character. This is not quite as much compression as is possible for English, since next-character predictions can be made more certain by looking at the context (kind of like what GPT is trained to do), but it's easier to think about.
Replies from: Jon Garcia↑ comment by Jon Garcia · 2022-10-21T00:19:05.630Z · LW(p) · GW(p)
Also, just a couple minor errors:
- In your "The first 31 binary strings in lexical order" figure, you're missing a white square at the top of the fourth 3-bit string.
- "diving by " should be "dividing by ". I know spell check would miss that one.
I didn't notice any other errors. Again, great article.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2022-10-21T00:26:41.093Z · LW(p) · GW(p)
Nice catches. I love that somebody double-checked all the binary strings. :)