An Intuitive Explanation of Solomonoff Induction
post by Alex_Altair · 2012-07-11T08:05:20.544Z · LW · GW · Legacy · 225 commentsContents
Contents: Algorithms Induction Occam’s Razor Probability The Problem of Priors Binary Sequences All Algorithms Solomonoff's Lightsaber Formalized Science Approximations Unresolved Details None 225 comments
This is the completed article that Luke wrote the first half of. My thanks go to the following for reading, editing, and commenting; Luke Muehlhauser, Louie Helm, Benjamin Noble, and Francelle Wax.

People disagree about things. Some say that television makes you dumber; other say it makes you smarter. Some scientists believe life must exist elsewhere in the universe; others believe it must not. Some say that complicated financial derivatives are essential to a modern competitive economy; others think a nation's economy will do better without them. It's hard to know what is true.
And it's hard to know how to figure out what is true. Some argue that you should assume the things you are most certain about and then deduce all other beliefs from your original beliefs. Others think you should accept at face value the most intuitive explanations of personal experience. Still others think you should generally agree with the scientific consensus until it is disproved.
 Wouldn't it be nice if determining what is true was like baking a cake? What if there was a recipe for finding out what is true? All you'd have to do is follow the written directions exactly, and after the last instruction you'd inevitably find yourself with some sweet, tasty truth!
Wouldn't it be nice if determining what is true was like baking a cake? What if there was a recipe for finding out what is true? All you'd have to do is follow the written directions exactly, and after the last instruction you'd inevitably find yourself with some sweet, tasty truth!
In this tutorial, we'll explain the closest thing we’ve found so far to a recipe for finding truth: Solomonoff induction.
There are some qualifications to make. To describe just one: roughly speaking, you don't have time to follow the recipe. To find the truth to even a simple question using this recipe would require you to follow one step after another until long after the heat death of the universe, and you can't do that.
But we can find shortcuts. Suppose you know that the exact recipe for baking a cake asks you to count out one molecule of H2O at a time until you have exactly 0.5 cups of water. If you did that, you might not finish the cake before the heat death of the universe. But you could approximate that part of the recipe by measuring out something very close to 0.5 cups of water, and you'd probably still end up with a pretty good cake.
Similarly, once we know the exact recipe for finding truth, we can try to approximate it in a way that allows us to finish all the steps sometime before the sun burns out.
This tutorial explains that best-we've-got-so-far recipe for finding truth, Solomonoff induction. Don’t worry, we won’t be using any equations, just qualitative descriptions.
Like Eliezer Yudkowsky's Intuitive Explanation of Bayes' Theorem and Luke Muehlhauser's Crash Course in the Neuroscience of Human Motivation, this tutorial is long. You may not have time to read it; that's fine. But if you do read it, we recommend that you read it in sections.
Contents:
Background
1. Algorithms — We’re looking for an algorithm to determine truth.
2. Induction — By “determine truth”, we mean induction.
3. Occam’s Razor — How we judge between many inductive hypotheses.
4. Probability — Probability is what we usually use in induction.
5. The Problem of Priors — Probabilities change with evidence, but where do they start?
The Solution
6. Binary Sequences — Everything can be encoded as binary.
7. All Algorithms — Hypotheses are algorithms. Turing machines describe these.
8. Solomonoff's Lightsaber — Putting it all together.
9. Formalized Science — From intuition to precision.
10. Approximations — Ongoing work towards practicality.
11. Unresolved Details — Problems, philosophical and mathematical.
Algorithms
At an early age you learned a set of precisely-defined steps — a 'recipe' or, more formally, an algorithm — that you could use to find the largest number in a list of numbers like this:
21, 18, 4, 19, 55, 12, 30
The algorithm you learned probably looked something like this:
- Look at the first item. Note that it is the largest you've seen on this list so far. If this is the only item on the list, output it as the largest number on the list. Otherwise, proceed to step 2.
- Look at the next item. If it is larger than the largest item noted so far, note it as the largest you've seen in this list so far. Proceed to step 3.
- If you have not reached the end of the list, return to step 2. Otherwise, output the last noted item as the largest number in the list.
Other algorithms could be used to solve the same problem. For example, you could work your way from right to left instead of from left to right. But the point is that if you follow this algorithm exactly, and you have enough time to complete the task, you can't fail to solve the problem. You can't get confused about what one of the steps means or what the next step is. Every instruction tells you exactly what to do next, all the way through to the answer.
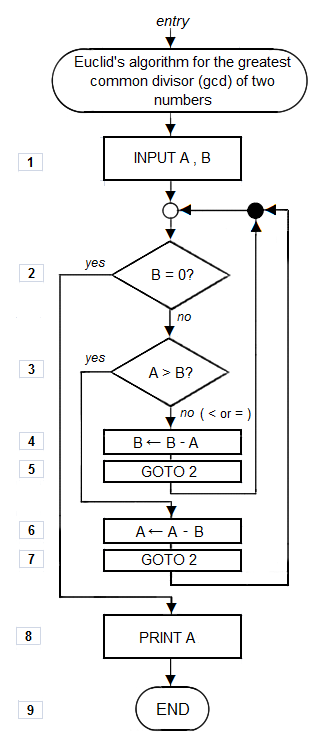 You probably learned other algorithms, too, like how to find the greatest common divisor of any two integers (see image on right).
You probably learned other algorithms, too, like how to find the greatest common divisor of any two integers (see image on right).
But not just any set of instructions is a precisely-defined algorithm. Sometimes, instructions are unclear or incomplete. Consider the following instructions based on an article about the scientific method:
- Make an observation.
- Form a hypothesis that explains the observation.
- Conduct an experiment that will test the hypothesis.
- If the experimental results disconfirm the hypothesis, return to step #2 and form a hypothesis not yet used. If the experimental results confirm the hypothesis, provisionally accept the hypothesis.
This is not an algorithm.
First, many of the terms are not clearly defined. What counts as an observation? What counts as a hypothesis? What would a hypothesis need to be like in order to ‘explain’ the observation? What counts as an experiment that will ‘test’ the hypothesis? What does it mean for experimental results to ‘confirm’ or ‘disconfirm’ a hypothesis?
Second, the instructions may be incomplete. What do we do if we reach step 4 and the experimental results neither ‘confirm’ nor ‘disconfirm’ the hypothesis under consideration, but instead are in some sense ‘neutral’ toward the hypothesis? These instructions don’t tell us what to do in that case.
An algorithm is a well-defined procedure that takes some value or values as input and, after a finite series of steps, generates some value or values as output.
For example, the ‘find the largest number’ algorithm above could take the input {21, 18, 4, 19, 55, 12, 30} and would, after 13 steps, produce the following output: {55}. Or it could take the input {34} and, after 1 step, produce the output: {34}.
An algorithm is so well written, that we can construct machines that follow them. Today, the machines that follow algorithms are mostly computers. This is why all computer science students take a class in algorithms. If we construct our algorithm for truth, then we can make a computer program that finds truth—an Artificial Intelligence.
Induction
Let’s clarify what we mean. In movies, scientists will reveal “truth machines”. Input a statement, and the truth machine will tell you whether it is true or false. This is not what Solomonoff induction does. Instead, Solomonoff induction is our ultimate “induction machine”.
Whether we are a detective trying to catch a thief, a scientist trying to discover a new physical law, or a businessman attempting to understand a recent change in demand, we are all in the process of collecting information and trying to infer the underlying causes.
-Shane Legg
The problem of induction is this: We have a set of observations (or data), and we want to find the underlying causes of those observations. That is, we want to find hypotheses that explain our data. We’d like to know which hypothesis is correct, so we can use that knowledge to predict future events. Our algorithm for truth will not listen to questions and answer yes or no. Our algorithm will take in data (observations) and output the rule by which the data was created. That is, it will give us the explanation of the observations; the causes.
Suppose your data concern a large set of stock market changes and other events in the world. You’d like to know the processes responsible for the stock market price changes, because then you can predict what the stock market will do in the future, and make some money.
 Or, suppose you are a parent. You come home from work to find a chair propped against the refrigerator, with the cookie jar atop the fridge a bit emptier than before. You like cookies, and you don’t want them to disappear, so you start thinking. One hypothesis that leaps to mind is that your young daughter used the chair to reach the cookies. However, many other hypotheses explain the data. Perhaps a very short thief broke into your home and stole some cookies. Perhaps your daughter put the chair in front of the fridge because the fridge door is broken and no longer stays shut, and you forgot that your friend ate a few cookies when he visited last night. Perhaps you moved the chair and ate the cookies yourself while sleepwalking the night before.
Or, suppose you are a parent. You come home from work to find a chair propped against the refrigerator, with the cookie jar atop the fridge a bit emptier than before. You like cookies, and you don’t want them to disappear, so you start thinking. One hypothesis that leaps to mind is that your young daughter used the chair to reach the cookies. However, many other hypotheses explain the data. Perhaps a very short thief broke into your home and stole some cookies. Perhaps your daughter put the chair in front of the fridge because the fridge door is broken and no longer stays shut, and you forgot that your friend ate a few cookies when he visited last night. Perhaps you moved the chair and ate the cookies yourself while sleepwalking the night before.
All these hypotheses are possible, but intuitively it seems like some hypotheses are more likely than others. If you’ve seen your daughter access the cookies this way before but have never been burgled, then the ‘daughter hypothesis’ seems more plausible. If some expensive things from your bedroom and living room are missing and there is hateful graffiti on your door at the eye level of a very short person, then the ‘short thief’ hypothesis becomes more plausible than before. If you suddenly remember that your friend ate a few cookies and broke the fridge door last night, the ‘broken fridge door’ hypothesis gains credibility. If you’ve never been burgled and your daughter is out of town and you have a habit of moving and eating things while sleepwalking, the ‘sleepwalking’ hypothesis becomes less bizarre.
So the weight you give to each hypothesis depends greatly on your prior knowledge. But what if you had just been hit on the head and lost all past memories, and for some reason the most urgent thing you wanted to do was to solve the mystery of the chair and cookies? Then how would you weigh the likelihood of the available hypotheses?
When you have very little data but want to compare hypotheses anyway, Occam's Razor comes to the rescue.
Occam’s Razor
Consider a different inductive problem. A computer program outputs the following sequence of numbers:
1, 3, 5, 7
Which number comes next? If you guess correctly, you’ll win $500.
In order to predict the next number in the sequence, you make a hypothesis about the process the computer is using to generate these numbers. One obvious hypothesis is that it is simply listing all the odd numbers in ascending order from 1. If that’s true, you should guess that "9" will be the next number.
But perhaps the computer is using a different algorithm to generate the numbers. Suppose that n is the step in the sequence, so that n=1 when it generated ‘1’, n=2 when it generated ‘3’, and so on. Maybe the computer used this equation to calculate each number in the sequence:
2n − 1 + (n − 1)(n − 2)(n − 3)(n − 4)
If so, the next number in the sequence will be 33. (Go ahead, check the calculations.)
But doesn’t the first hypothesis seem more likely?
The principle behind this intuition, which goes back to William of Occam, could be stated:
Among all hypotheses consistent with the observations, the simplest is the most likely.
The principle is called Occam’s razor because it ‘shaves away’ unnecessary assumptions.
For example, think about the case of the missing cookies again. In most cases, the ‘daughter’ hypothesis seems to make fewer unnecessary assumptions than the ‘short thief’ hypothesis does. You already know you have a daughter that likes cookies and knows how to move chairs to reach cookies. But in order for the short thief hypothesis to be plausible, you have to assume that (1) a thief found a way to break in, that (2) the thief wanted inexpensive cookies from your home, that (3) the thief was, unusually, too short to reach the top of the fridge without the help of a chair, and (4) many other unnecessary assumptions.
Occam’s razor sounds right, but can it be made more precise, and can it be justified? How do we find all consistent hypotheses, and how do we judge their simplicity? We will return to those questions later. Before then, we’ll describe the area of mathematics that usually deals with reasoning: probability.
Probability
 You’re a soldier in combat, crouching in a trench. You know for sure there is just one enemy soldier left on the battlefield, about 400 yards away. You also know that if the remaining enemy is a regular army troop, there’s only a small chance he could hit you with one shot from that distance. But if the remaining enemy is a sniper, then there’s a very good chance he can hit you with one shot from that distance. But snipers are rare, so it’s probably just a regular army troop.
You’re a soldier in combat, crouching in a trench. You know for sure there is just one enemy soldier left on the battlefield, about 400 yards away. You also know that if the remaining enemy is a regular army troop, there’s only a small chance he could hit you with one shot from that distance. But if the remaining enemy is a sniper, then there’s a very good chance he can hit you with one shot from that distance. But snipers are rare, so it’s probably just a regular army troop.
You peek your head out of the trench, trying to get a better look.
Bam! A bullet glances off your helmet and you duck down again.
“Okay,” you think. “I know snipers are rare, but that guy just hit me with a bullet from 400 yards away. I suppose it might still be a regular army troop, but there’s a seriously good chance it’s a sniper, since he hit me from that far away.”
After another minute, you dare to take another look, and peek your head out of the trench again.
Bam! Another bullet glances off your helmet! You duck down again.
“Whoa,” you think. “It’s definitely a sniper. No matter how rare snipers are, there’s no way that guy just hit me twice in a row from that distance if he’s a regular army troop. He’s gotta be a sniper. I’d better call for support.”
This is an example of reasoning under uncertainty, of updating uncertain beliefs in response to evidence. We do it all the time.
You start with some prior beliefs, and all of them are uncertain. You are 99.99% certain the Earth revolves around the sun, 90% confident your best friend will attend your birthday party, and 40% sure that the song you're listening to on the radio was played by The Turtles.
Then, you encounter new evidence—new observations—and you update your beliefs in response.
Suppose you start out 85% confident that the one remaining enemy soldier is not a sniper. That leaves only 15% credence to the hypothesis that he is a sniper. But then, a bullet glances off your helmet — an event far more likely if the enemy soldier is a sniper than if he is not. So now you’re only 40% confident he’s a non-sniper, and 60% confident he is a sniper. Another bullet glances off your helmet, and you update again. Now you’re only 2% confident he’s a non-sniper, and 98% confident he is a sniper.
Probability theory is the mathematics of reasoning with uncertainty. The keystone of this subject is called Bayes’ Theorem. It tells you how likely something is given some other knowledge. Understanding this simple theorem is more useful and important for most people than Solomonoff induction. If you haven’t learned it already, you may want to read either tutorial #1, tutorial #2, tutorial #3, or tutorial #4 on Bayes’ Theorem. The exact math of Bayes' Theorem is not required for this tutorial. We'll just describe its results qualitatively.
Bayes’ Theorem can tell us how likely a hypothesis is, given evidence (or data, or observations). This is helpful because we want to know which model of the world is correct so that we can successfully predict the future. It calculates this probability based on the prior probability of the hypothesis alone, the probability of the evidence alone, and the probability of the evidence given the hypothesis. Now we just plug the numbers in.
Of course, it’s not easy to “just plug the numbers in.” You aren’t an all-knowing god. You don’t know exactly how likely it is that the enemy soldier would hit your helmet if he’s a sniper, compared to how likely that is if he’s not a sniper. But you can do your best. With enough evidence, it will become overwhelmingly clear which hypothesis is correct.
But guesses are not well-suited to an exact algorithm, and so our quest to find an algorithm for truth-finding must continue. For now, we turn to the problem of choosing priors.
The Problem of Priors
In the example above where you're a soldier in combat, I gave you your starting probabilities: 85% confidence that the enemy soldier was a sniper, and 15% confidence he was not. But what if you don't know your "priors"? What then?
Most situations in real life are complex, so that your “priors” (as used in Bayes’ Theorem) are actually probabilities that have been updated several times with past evidence. You had an idea that snipers were rare because you saw many soldiers, but only a few of them were snipers. Or you read a reliable report saying that snipers were rare. But what would our ideal reasoning computer do before it knew anything? What would the probabilities be set to before we turned it on? How can we determine the probability of a hypothesis before seeing any data?
The general answer is Occam’s razor; simpler hypotheses are more likely. But this isn’t rigorous. It’s usually difficult to find a measure of complexity, even for mathematical hypotheses. Is a normal curve simpler than an exponential curve? Bayesian probability theory doesn’t have anything to say about choosing priors. Thus, many standard "prior distributions" have been developed. Generally, they distribute probability equally across hypotheses. Of course this is a good approach if all the hypotheses are equally likely. But as we saw above, it seems that some hypotheses are more complex than others, and this makes them less likely than the other hypotheses. So when distributing your probability across several hypotheses, you shouldn't necessarily distribute it evenly. There’s also a growing body of work around an idea called the Maximum Entropy Principle. This principle helps you choose a prior that makes the least assumptions given the constraints of the problem. But this principle can’t be used to handle all possible types of hypotheses, only ones for which “entropy” can be mathematically evaluated.
We need a method that everyone can agree provides the correct priors in all situations. This helps us perform induction correctly. It also helps everyone be more honest. Since priors partly determine what people believe, they can sometimes choose priors that help “prove” what they want to prove. This can happen intentionally or unintentionally. It can also happen in formal situations, such as an academic paper defending a proposed program.
To solve the problem of priors once and for all, we'd like to have an acceptable, universal prior distribution, so that there's no vagueness in the process of induction. We need a recipe, an algorithm, for selecting our priors. For that, we turn to the subject of binary sequences.
Binary Sequences
 At this point, we have collected a lot of background material. We know about algorithms, and we know we need an algorithm that does induction. We know that induction also uses Occam’s razor and probability. We know that one of the problems in probability is selecting priors. Now we’re ready to formalize it.
At this point, we have collected a lot of background material. We know about algorithms, and we know we need an algorithm that does induction. We know that induction also uses Occam’s razor and probability. We know that one of the problems in probability is selecting priors. Now we’re ready to formalize it.
To start, we need a language in which we can express all problems, all data, all hypotheses. Binary is the name for representing information using only the characters '0' and '1'. In a sense, binary is the simplest possible alphabet. A two-character alphabet is the smallest alphabet that can communicate a difference. If we had an alphabet of just one character, our “sentences” would be uniform. With two, we can begin to encode information. Each 0 or 1 in a binary sequence (e. g. 01001011) can be considered the answer to a yes-or-no question.
In the above example about sorting numbers, it's easy to convert it to binary just by writing a computer program to follow the algorithm. All programming languages are based on binary. This also applies to anything you’ve ever experienced using a computer. From the greatest movie you’ve ever seen to emotional instant messaging conversations, all of it was encoded in binary.
In principle, all information can be represented in binary sequences. If this seems like an extreme claim, consider the following...
All your experiences, whether from your eyes, ears, other senses or even memories and muscle movements, occur between neurons (your nerve cells and brain cells). And it was discovered that neurons communicate using a digital signal called the action potential. Because it is digital, a neuron either sends the signal, or it doesn't. There is no half-sending the action potential. This can be translated directly into binary. An action potential is a 1, no action potential is a 0. All your sensations, thoughts, and actions can be encoded as a binary sequence over time. A really long sequence.
Or, if neuron communication turns out to be more complicated than that, we can look to a deeper level. All events in the universe follow the laws of physics. We're not quite done discovering the true laws of physics; there are some inconsistencies and unexplained phenomena. But the currently proposed laws are incredibly accurate. And they can be represented as a single binary sequence.
You might be thinking, “But I see and do multiple things simultaneously, and in the universe there are trillions of stars all burning at the same time. How can parallel events turn into a single sequence of binary?”
This is a perfectly reasonable question. It turns out that, at least formally, this poses no problem at all. The machinery we will use to deal with binary sequences can turn multiple sequences into one just by dovetailing them together and adjusting how it processes them so the results are the same. Because it is easiest to deal with a single sequence, we do this in the formal recipe. Any good implementation of Solomonoff induction will use multiple sequences just to be faster.
A picture of your daughter can be represented as a sequence of ones and zeros. But a picture is not your daughter. A video of all your daughter’s actions can also be represented as a sequence of ones and zeros. But a video isn’t your daughter, either; we can’t necessarily tell if she’s thinking about cookies, or poetry. The position of all the subatomic particles that make up your daughter as she lives her entire life can be represented as a sequence of binary. And that really is your daughter.
Having a common and simple language can sometimes be the key to progress. The ancient Greek mathematician Archimedes discovered many specific results of calculus, but could not generalize the methods because he did not have the language of calculus. After this language was developed in the late 1600s, hundreds of mathematicians were able to produce new results in the field. Now, calculus forms an important base of our modern civilization.
Being able to do everything in the language of binary sequences simplifies things greatly, and gives us great power. Now we don't have to deal with complex concepts like “daughter” and “soldier." It's all still there in the data, only as a large sequence of 0s and 1s. We can treat it all the same.
All Algorithms
Now that we have a simple way to deal with all types of data, let's look at hypotheses. Recall that we’re looking for a way to assign prior probabilities to hypotheses. (And then, when we encounter new data, we'll use Bayes' Theorem to update the probabilities we assign to those hypotheses). To be complete, and guarantee we find the real explanation for our data, we have to consider all possible hypotheses. But how could we ever find all possible explanations for our data? We could sit in a room for days, making a list of all the ways the cookies could be missing, and still not think of the possibility that our wife took some to work.
It turns out that mathematical abstraction can save the day. By using a well-tested model, and the language of binary, we can find all hypotheses.
This piece of the puzzle was discovered in 1936 by a man named Alan Turing. He created a simple, formal model of computers called “Turing machines” before anyone had ever built a computer.
In Turing's model, each machine's language is—you guessed it—binary. There is one binary sequence for the input, a second binary sequence that constantly gets worked on and re-written, and a third binary sequence for output. (This description is called a three-tape Turing machine, and is easiest to think about for Solomonoff induction. The normal description of Turing machines includes only one tape, but it turns out that they are equivalent.)

The rules that determine how the machine reacts to and changes the bits on these tapes are very simple. An example is shown on the diagram above. Basically, every Turing machine has a finite number of “states”, each of which is a little rule. These rules seem bland and boring at first, but in a few paragraphs, you’ll find out why they’re so exciting. First, the machine will start out in a certain state, with some binary on the input tape, all zeros on the work tape, and all zeros on the output tape. The rules for that first state will tell it to look at the input tape and the work tape. Depending on what binary number is on those two tapes, the rules will say to perform certain actions. It will say to;
- feed the input tape (or not)
- write 0 or 1 to the work tape
- move the work tape left or right
- write 0 or 1 to the output tape
- feed the output tape (or not).
After that, the rules will say which state to move to next, and the process will repeat. Remember that the rules for these states are fixed; they could be written out on pieces of paper. All that changes are the tapes, and what rule the machine is currently following. The basic mathematics behind this is fairly simple to understand, and can be found in books on computational theory.
This model is incredibly powerful. Given the right rules, Turing machines can
- calculate the square of a number,
- run a spreadsheet program,
- compress large files,
- estimate the probability of rain tomorrow,
- control the flight of an airplane,
- play chess better than a human,
- and much, much more.
You may have noticed that this sounds like a list of what regular computers do. And you would be correct; the model of Turing machines came before, and served as an invaluable guide to, the invention of electronic computers. Everything they do is within the model of Turing machines.
Even more exciting is the fact that all attempts to formalize the intuitive idea of “algorithm” or “process” have been proven to be at most equally as powerful as Turing machines. If a system has this property, it is called Turing complete. For example, math equations using algebra have a huge range of algorithms they can express. Multiplying is an algorithm, finding the hypotenuse of a right triangle is an algorithm, and the quadratic formula is an algorithm. Turing machines can run all these algorithms, and more. That is, Turing machines can be used to calculate out all algebraic algorithms, but there are some algorithms Turing machines can run that can’t be represented by algebra. This means algebra is not Turing complete. For another example, mathematicians often invent “games” where sequences of symbols can be rewritten using certain rules. (They will then try to prove things about what sequences these rules can create.) But no matter how creative their rules, every one of them can be simulated on a Turing machine. That is, for every set of re-writing rules, there is a binary sequence you can give a Turing machine so that the machine will rewrite the sequences in the same way.
Remember how limited the states of a Turing machine are; every machine has only a finite number of states with “if” rules like in the figure above. But somehow, using these and the tape as memory, they can simulate every set of rules, every algorithm ever thought up. Even the distinctively different theory of quantum computers is at most Turing complete. In the 80 years since Turing’s paper, no superior systems have been found. The idea that Turing machines truly capture the idea of “algorithm” is called the Church-Turing thesis.
So the model of Turing machines covers regular computers, but that is not all. As mentioned above, the current laws of physics can be represented as a binary sequence. That is, the laws of physics are an algorithm that can be fed into a Turing machine to compute the past, present and future of the universe. This includes stars burning, the climate of the earth, the action of cells, and even the actions and thoughts of humans. Most of the power here is in the laws of physics themselves. What Turing discovered is that these can be computed by a mathematically simple machine.
As if Turing’s model wasn’t amazing enough, he went on to prove that one specific set of these rules could simulate all other sets of rules.
The computer with this special rule set is called a universal Turing machine. We simulate another chosen machine by giving the universal machine a compiler binary sequence. A compiler is a short program that translates between computer languages or, in this case, between machines. Sometimes a compiler doesn’t exist. For example, you couldn’t translate Super Mario Brothers onto a computer that only plays tic-tac-toe. But there will always be a compiler to translate onto a universal Turing machine. We place this compiler in front of the input which would have been given to the chosen machine. From one perspective, we are just giving the universal machine a single, longer sequence. But from another perspective, the universal machine is using the compiler to set itself up to simulate the chosen machine. While the universal machine (using its own, fixed rules) is processing the compiler, it will write various things on the work tape. By the time it has passed the compiler and gets to the original input sequence, the work tape will have something written on it to help simulate the chosen machine. While processing the input, it will still follow its own, fixed rules, only the binary on the work tape will guide it down a different “path” through those rules than if we had only given it the original input.
For example, say that we want to calculate the square of 42 (or in binary, 101010). Assume we know the rule set for the Turing machine which squares numbers when given the number in binary. Given all the specifics, there is an algorithmic way to find the “compiler” sequence based on these rules. Let’s say that the compiler is 1011000. Then, in order to compute the square of 42 on the universal Turing machine, we simply give it the input 1011000101010, which is just the compiler 1011000 next to the number 42 as 101010. If we want to calculate the square of 43, we just change the second part to 101011 (which is 101010 + 1). The compiler sequence doesn’t change, because it is a property of the machine we want to simulate, e. g. the squaring machine, but not of the input to that simulated machine, e. g. 42.
In summary: algorithms are represented by Turing machines, and Turing machines are represented by inputs to the universal Turing machine. Therefore, algorithms are represented by inputs to the universal Turing machine.
In Solomonoff induction, the assumption we make about our data is that it was generated by some algorithm. That is, the hypothesis that explains the data is an algorithm. Therefore, a universal Turing machine can output the data, as long as you give the machine the correct hypothesis as input. Therefore, the set of all possible inputs to our universal Turing machine is the set of all possible hypotheses. This includes the hypothesis that the data is a list of the odd numbers, the hypothesis that the enemy soldier is a sniper, and the hypothesis that your daughter ate the cookies. This is the power of formalization and mathematics.
Solomonoff's Lightsaber
Now we can find all the hypotheses that would predict the data we have observed. This is much more powerful than the informal statement of Occam's razor. Because of its precision and completeness, this process has been jokingly dubbed “Solomonoff's Lightsaber”. Given our data, we find potential hypotheses to explain it by running every hypothesis, one at a time, through the universal Turing machine. If the output matches our data, we keep it. Otherwise, we throw it away.
By the way, this is where Solomonoff induction becomes incomputable. It would take an infinite amount of time to check every algorithm. And even more problematic, some of the algorithms will run forever without producing output—and we can't prove they will never stop running. This is known as the halting problem, and it is a deep fact of the theory of computation. It's the sheer number of algorithms, and these pesky non-halting algorithms that stop us from actually running Solomonoff induction.
The actual process above might seem a little underwhelming. We just check every single hypothesis? Really? Isn’t that a little mindless and inefficient? This will certainly not be how the first true AI operates. But don’t forget that before this, nobody had any idea how to do ideal induction, even in principle. Developing fundamental theories, like quantum mechanics, might seem abstract and wasteful. But history has proven that it doesn’t take long before such theories and models change the world, as quantum mechanics did with modern electronics. In the future, men and women will develop ways to approximate Solomonoff induction in a second. Perhaps they will develop methods to eliminate large numbers of hypotheses all at once. Maybe hypotheses will be broken into distinct classes. Or maybe they’ll use methods to statistically converge toward the right hypotheses.
So now, at least in theory, we have the whole list of hypotheses that might be the true cause behind our observations. These hypotheses, since they are algorithms, look like binary sequences. For example, the first few might be 01001101, 0011010110000110100100110, and 1000111110111111000111010010100001. That is, for each of these three, when you give them to the universal Turing machine as input, the output is our data. Which of these three do you think is more likely to be the true hypothesis that generated our data in the first place?
 We have a list, but we're trying to come up with a probability, not just a list of possible explanations. So how do we decide what the probability is of each of these hypotheses? Imagine that the true algorithm is produced in a most unbiased way: by flipping a coin. For each bit of the hypothesis, we flip a coin. Heads will be 0, and tails will be 1. In the example above, 01001101, the coin landed heads, tails, heads, heads, tails, and so on. Because each flip of the coin has a 50% probability, each bit contributes ½ to the final probability.
We have a list, but we're trying to come up with a probability, not just a list of possible explanations. So how do we decide what the probability is of each of these hypotheses? Imagine that the true algorithm is produced in a most unbiased way: by flipping a coin. For each bit of the hypothesis, we flip a coin. Heads will be 0, and tails will be 1. In the example above, 01001101, the coin landed heads, tails, heads, heads, tails, and so on. Because each flip of the coin has a 50% probability, each bit contributes ½ to the final probability.
Therefore an algorithm that is one bit longer is half as likely to be the true algorithm. Notice that this intuitively fits Occam's razor; a hypothesis that is 8 bits long is much more likely than a hypothesis that is 34 bits long. Why bother with extra bits? We’d need evidence to show that they were necessary.
So, why not just take the shortest hypothesis, and call that the truth? Because all of the hypotheses predict the data we have so far, and in the future we might get data to rule out the shortest one. We keep all consistent hypotheses, but weigh the shorter ones with higher probability. So in our eight-bit example, the probability of 01001101 being the true algorithm is ½^8, or 1/256. It's important to say that this isn't an absolute probability in the normal sense. It hasn't been normalized—that is, the probabilities haven't been adjusted so that they add up to 1. This is computationally much more difficult, and might not be necessary in the final implementation of Solomonoff induction. These probabilities can still be used to compare how likely different hypotheses are.
To find the probability of the evidence alone, all we have to do is add up the probability of all these hypotheses consistent with the evidence. Since any of these hypotheses could be the true one that generates the data, and they're mutually exclusive, adding them together doesn't double count any probability.
Formalized Science
Let’s go back to the process above that describes the scientific method. We’ll see that Solomonoff induction is this process made into an algorithm.
1. Make an observation.
Our observation is our binary sequence of data. Only binary sequences are data, and all binary sequences can qualify as data.
2. Form a hypothesis that explains the observation.
We use a universal Turing machine to find all possible hypotheses, no fuzziness included. The hypothesis “explains” the observation if the output of the machine matches the data exactly.
3. Conduct an experiment that will test the hypothesis.
The only “experiment” is to observe the data sequence for longer, and run the universal machine for longer. The hypotheses whose output continues to match the data are the ones that pass the test.
4. If the experimental results disconfirm the hypothesis, return to step #2 and form a hypothesis not yet used. If the experimental results confirm the hypothesis, provisionally accept the hypothesis.
This step tells us to repeat the “experiment” with each binary sequence in our matching collection. However, instead of “provisionally” accepting the hypothesis, we accept all matching hypotheses with a probability weight according to its length.
Now we’ve found the truth, as best as it can be found. We’ve excluded no possibilities. There’s no place for a scientist to be biased, and we don’t need to depend on our creativity to come up with the right hypothesis or experiment. We know how to measure how complex a hypothesis is. Our only problem left is to efficiently run it.
Approximations
As mentioned before, we actually can’t run all the hypotheses to see which ones match. There are infinitely many, and some of them will never halt. So, just like our cake recipe, we need some very helpful approximations that still deliver very close to true outputs. Technically, all prediction methods are approximations of Solomonoff induction, because Solomonoff induction tries all possibilities. But most methods use a very small set of hypotheses, and many don't use good methods for estimating their probabilities. How can we more directly approximate our recipe? At present, there aren't any outstandingly fast and accurate approximations to Solomonoff induction. If there were, we would be well on our way to true AI. Below are some ideas that have been published.
 In Universal Artificial Intelligence, Marcus Hutter provides a full formal approximation of Solomonoff induction which he calls AIXI-tl. This model is optimal in a technical and subtle way. Also it can always return an answer in a finite amount of time, but this time is usually extremely long and doubles with every bit of data. It would still take longer than the life of the universe before we got an answer for most questions. How can we do even better?
In Universal Artificial Intelligence, Marcus Hutter provides a full formal approximation of Solomonoff induction which he calls AIXI-tl. This model is optimal in a technical and subtle way. Also it can always return an answer in a finite amount of time, but this time is usually extremely long and doubles with every bit of data. It would still take longer than the life of the universe before we got an answer for most questions. How can we do even better?
One general method would be to use a Turing machine that you know will always halt. Because of the halting problem, this means that you won't be testing some halting algorithms that might be the correct hypotheses. But you could still conceivably find a large set of hypotheses that all halted.
Another popular method of approximating any intractable algorithm is to use randomness. This is called a Monte Carlo method. We can’t test all hypotheses, so we have to select a subset. But we don’t want our selection process to bias the result. Therefore we could randomly generate a bunch of hypotheses to test. We could use an evolutionary algorithm, where we test this seed set of hypotheses, and keep the ones that generate data closest to ours. Then we would vary these hypotheses, run them again through the Turing machine, keep the closest fits, and continue this process until the hypotheses actually predicted our data exactly.
The mathematician Jürgen Schmidhuber proposes a different probability weighing which also gives high probability to hypotheses that can be quickly computed. He demonstrates how this is “near-optimal”. This is vastly faster, but risks making another assumption, that faster algorithms are inherently more likely.
Unresolved Details
Solomonoff induction is an active area of research in modern mathematics. While it is universal in a broad and impressive sense, some choices can still be made in the mathematical definition. Many people also have philosophical concerns or objections to the claim that Solomonoff induction is ideal and universal.
The first question many mathematicians ask is, “Which universal Turing machine?” I have written this tutorial as if there is only one, but there are in fact infinitely many sets of rules that can simulate all other sets of rules. Just as the length of a program will depend on which programming language you write it in, the length of the hypothesis as a binary sequence will depend on which universal Turing machine you use. This means the probabilities will be different. The change, however, is very limited. There are theorems that well-define this effect and it is generally agreed not to be a concern. Specifically, going between two universal machines cannot increase the hypothesis length any more than the length of the compiler from one machine to the other. This length is fixed, independent of the hypothesis, so the more data you use, the less this difference matters.
Another concern is that the true hypothesis may be incomputable. There are known definitions of binary sequences which make sense, but which no Turing machine can output. Solomonoff induction would converge to this sequence, but would never predict it exactly. It is also generally agreed that nothing could ever predict this sequence, because all known predictors are equivalent to Turing machines. If this is a problem, it is similar to the problem of a finite universe; there is nothing that can be done about it.
Lastly, many people, mathematicians included, reject the ideas behind the model, such as that the universe can be represented as a binary sequence. This often delves into complex philosophical arguments, and often revolves around consciousness.
Many more details can be found the more one studies. Many mathematicians work on modified versions and extensions where the computer learns how to act as well as predict. However these open areas are resolved, Solomonoff induction has provided an invaluable model and perspective for research into solving the problem of how to find truth. (Also see Open Problems Related to Solomonoff Induction.)
Fundamental theories have an effect of unifying previously separate ideas. After Turing discovered the basics of computability theory, it was only a matter of time before these ideas made their way across philosophy and mathematics. Statisticians could only find exact probabilities in simplified situations; now they know how to find them in all situations. Scientists wondered how to really know which hypothesis was simpler; now they can find a number. Philosophers wondered how induction could be justified. Solomonoff induction gives them an answer.
So, what’s next? To build our AI truth-machine, or even to find the precise truth to a single real-world problem, we need considerable work on approximating our recipe. Obviously a scientist cannot presently download a program to tell him the complexity of his hypothesis regarding deep-sea life behavior. But now that we know how to find truth in principle, mathematicians and computer scientists will work on finding it in practice.
(How does this fit with Bayes' theorem? A followup.)
225 comments
Comments sorted by top scores.
comment by Shmi (shminux) · 2012-07-09T06:03:09.526Z · LW(p) · GW(p)
Let me dramatize your sniper example a bit with this hypothetical scenario.
You read about homeopathy, you realize that the purported theoretical underpinnings sound nonsensical, you learn that all properly conducted clinical trials show that homeopathy is no better than placebo and so estimate that the odds of it being anything but a sham are, charitably, 1 in a million. Then your mother, who is not nearly as rational, tries to convince you to take Sabadil for your allergies, because it has good product reviews. You reluctantly agree to humor her (after all, homeopathy is safe, if useless).
Lo, your hay fever subsides... and now you are stuck trying to recalculate your estimate of homeopathy being more than a sham in the face of the shear impossibility of the sugar pills with not a single active molecule remaining after multiple dilutions having any more effect than a regular sugar pill.
What would you do?
Replies from: Vaniver, None, DaFranker, Alex_Altair, Luke_A_Somers↑ comment by Vaniver · 2012-07-15T18:00:17.466Z · LW(p) · GW(p)
Lo, your hay fever subsides... and now you are stuck trying to recalculate your estimate of homeopathy being more than a sham in the face of the shear impossibility of the sugar pills with not a single active molecule remaining after multiple dilutions having any more effect than a regular sugar pill.
What would you do?
Test regular sugar pills, obviously. Apparently my hayfever responds to placebo, and that's awesome. High fives all around!
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-15T20:45:41.691Z · LW(p) · GW(p)
Apparently my hayfever responds to placebo
and if it does not?
Replies from: Vaniver, johnlawrenceaspden↑ comment by Vaniver · 2012-07-16T00:31:05.219Z · LW(p) · GW(p)
Increase the probability that homeopathy works for me- but also increase the probability of all other competing hypotheses except the "sugar placebo" one. The next most plausible hypothesis at that point is probably that the effort is related to my mother's recommendation. Unless I expect the knowledge gained here to extend to something else, at some point I'll probably stop trying to explain it.
At some point, though, this hypothetical veers into "I wouldn't explain X because X wouldn't happen" territory. Hypothetical results don't have to be generated in the same fashion as real results, and so may have unreal explanations.
↑ comment by johnlawrenceaspden · 2012-07-16T10:29:12.883Z · LW(p) · GW(p)
Oooh! That would be so interesting. You could do blind trials with sugar pills vs other sugar pills. You could try to make other tests which could distinguish between homeopathic sugar and non-homeopathic sugar. Then if you found some you could try to make better placebos that pass the tests. You might end up finding an ingredient in the dye in the packaging that cures your hayfever. And if not something like that, you might end up rooting out something deep!
I suspect that if you were modelling an ideal mind rather than my rubbish one, the actual priors might not shift very much, but the expected value of investigating might be enough to prompt some experimenting. Especially if the ideal mind's hayfever was bad and the homeopathic sugar was expensive.
↑ comment by [deleted] · 2012-07-12T08:03:48.480Z · LW(p) · GW(p)
Do a bayesian update.
Additional to the prior, you need:
(A) The probability that you will heal anyway
(B) The probability that you will heal if sabadil works
I have done the math for A=0,5 ; B=0,75 : The result is an update from 1/10^6 to 1,5 * 1/10^6
For A=1/1000 and B=1 the result is 0.000999
The math is explained here: http://lesswrong.com/lw/2b0/bayes_theorem_illustrated_my_way
↑ comment by DaFranker · 2012-07-09T16:40:07.033Z · LW(p) · GW(p)
I would follow the good old principle of least assumptions: It is extremely likely that something else, the nature of which is unknown and difficult to identify within the confines of the stated problem, caused the fever to subside. This merely assumes that your prior is more reliable and that you do not know all the truths of the universe, the latter assumption being de-facto in very much all bayesian reasoning, to my understanding.
From there, you can either be "stubborn" and reject this piece of evidence due to the lack of an unknown amount of unknown data on what other possible causes there could be, or you could be strictly bayesian and update your belief accordingly. Even if you update your beliefs, since the priors of Homeopathy working is already very low, and the prior of you being cured by this specific action is also extremely low when compared to everything else that could possibly have cured you... and since you're strictly bayesian, you also update other beliefs, such as placebo curing minor ailments, "telepathic-like" thought-curing, self-healing through symbolic action, etc.
All in all, this paints a pretty solid picture of your beliefs towards homeopathy being unchanged, all things considered.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T17:01:15.253Z · LW(p) · GW(p)
Following the OP's sniper example, suppose you take the same pill the next time you have a flare-up, and it helps again. Would you still stick to your prewritten bottom line of "it ought to be something else"?
Replies from: DaFranker, private_messaging↑ comment by DaFranker · 2012-07-10T19:11:47.131Z · LW(p) · GW(p)
To better frame my earlier point, suppose that you flare up six times during a season, and the six times it gets better after having applied "X" method which was statistically shown to be no better than placebo, and after rational analysis you find out that each time you applied method X you were also circumstantially applying method Y at the same time (that is, you're also applying a placebo, since unless in your entire life you have never been relieved of some ailment by taking a pill, your body/brain will remember the principle and synchronize, just like any other form of positive reinforcement training).
In other words, both P(X-works|cured) and P(Y-works|cured) are raised, but only by half, since statistically they've been shown to have the same effect, and thus your priors are that they are equally as likely of being the cure-cause, and while both could be a cure-cause, the cure-cause could also be to have applied both of them. Since those two latter possibilities end up evening out, you divide the posteriors in the two, from my understanding. I might be totally off though, since I haven't been learning about Bayes' theorem all that long and I'm very much still a novice in bayesian rationality and probability.
To make a long story short, yes, I would stick to it, because within the presented context there are potentially thousands of X, Y and Z possible cure-causes, so while the likeliness that one of them is a cure is going up really fast each time I cure myself under the same circumstances, only careful framing of said circumstances will allow anyone to really rationally establish which factors become more likely to be truly causal and which are circumstantial (or correlated in another, non-directly-causal fashion).
Since homeopathy almost invariably involves hundreds of other factors, many of which are unknown and some of which we might be completely unaware, it becomes extremely difficult to reliably test for its effectiveness in some circumstances. This is why we assign greater trust in the large-scale double-blind studies, because our own analysis is of lower comparative confidence. At least within the context of this particular sniper example.
↑ comment by private_messaging · 2012-07-10T18:16:27.354Z · LW(p) · GW(p)
The homoeopathy claims interaction of water molecules with each other leads to water memory... it can even claim that all the physics is the same (hypothesis size per Solomonoff induction is same) yet the physics works out to the stuff happening. And we haven't really ran sufficiently detailed simulation to rule it out, just arguments of uncertain validity. There's no way to estimate it's probability.
We do something different than estimating probability of homoeopathy being true. It's actually very beautiful method, very elegant solution. We say, well, let's strategically take the risk of one-in-a-million that we discard a true curing method homoeopathy with such and such clinical effect. Then we run the clinical trials, and find evidence that there's less than one-in-a-million chance that those trials happened as they were, if the homoeopathy was true. We still do not know the probability of homoeopathy, but we strategically discard it, and we know the probability of wrongfully having discarded it, we can even find upper bound on how much that strategy lost in terms of expected utility, by discarding. That's how science works. The cut off strategy can be set from utility maximization considerations (with great care to avoid pascal's wager).
Replies from: shminux, othercriteria↑ comment by Shmi (shminux) · 2012-07-10T18:37:47.603Z · LW(p) · GW(p)
So, suppose that Sabadil cured your allergies 10 times out of 10, you will not take again unless forced to, because "There's no way to estimate it's (sic) probability."? Maybe you need to reread chapter 1 of HPMOR, and brush up on how to actually change your mind.
Replies from: DaFranker, private_messaging↑ comment by DaFranker · 2012-07-10T19:28:56.681Z · LW(p) · GW(p)
If it did cure allergies 10 times out of 10, and that ALL other possible cure-causes had been eliminated as causal beforehand (including the placebo effect which is inherent to most acts of taking a homoeopathic pill, even when the patient doesn't believe it'll work, simply out of subconscious memory of being cured by taking a pill), then yes, the posterior belief in its effectiveness would shoot up.
However, "the body curing itself by wanting to and being willing to even try things we know probably won't work based on what-ifs alone" is itself a major factor, one that has also been documented.
Par contre, if it did work 10 times out of 10, then I almost definitely would take it again, since it has now been shown to be, at worst, statistically correlated with whatever actually does cure me of my symptoms, whether that's the homoeopathic treatment or not. While doing that, I would keep attempting to rationally identify the proper causal links between events.
↑ comment by private_messaging · 2012-07-10T18:48:32.202Z · LW(p) · GW(p)
The point is that there is a decision method that allows me to decide without anyone having to make a prior.
Say, the cost of trial is a, the cost (utility loss) of missing valid cure to strategy failure is b, you do the N trials , N such that a N < (the probability of trials given assumption of validity of cure) b , then you proclaim cure not working. Then you can do more trials if the cost of trial falls. You don't know the probability and you still decide in an utility-maximizing manner (on choice of strategy), because you have the estimate on the utility loss that the strategy will incur in general.
edit: clearer. Also I am not claiming it is the best possible method, it isn't, but it's a practical solution that works. You can know the probability that you will end up going uncured if the cure actually works.
↑ comment by othercriteria · 2012-07-10T19:17:40.673Z · LW(p) · GW(p)
let's strategically take the risk of one-in-a-million that we discard a true curing method homoeopathy with such and such clinical effect
Where does your choice of "such and such clinical effect" come from? Keeping your one-in-a-million chance of being wrong fixed, the scale of the clinical trials required depends on the effect size of homeopathy. If homeopathy is a guaranteed cure, it's enough to dose one incurably sick person. If it helps half of the patients, you might need to dose on the order of twenty. And so on for smaller effect sizes. The homeopathy claim is not just a single hypothesis but a compound hypothesis consisting of all these hypotheses. Choosing which of these hypotheses to entertain is a probabilistic judgment; it can't be escaped by just picking one of the hypotheses, since that's just concentrating the prior mass at one point.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T20:45:37.472Z · LW(p) · GW(p)
It's part of the hypothesis, without it the idea is not a defined hypothesis. See falsifiability.
Replies from: othercriteria↑ comment by othercriteria · 2012-07-10T21:53:45.518Z · LW(p) · GW(p)
(Pardon the goofy notation. Don't want to deal with the LaTeX engine.)
The compound hypothesis is well-defined. Suppose that the baseline cure probability for a placebo is θ ∈ [0,1). Then hypotheses take the form H ⊂ [0,1], which have the interpretation that the cure rate for homeopathy is in H. The standing null hypothesis in this case is Hθ = { θ }. The alternative hypothesis that homeopathy works is H>θ = (θ,1] = { x : x > θ }. For any θ' ∈ H>θ, we can construct a "one-in-a-million chance of being wrong" test for the simple hypothesis Hθ' that homeopathy is effective with effect size exactly θ'. It is convenient that such tests work just as well for the hypothesis H≥θ'. However, we can't construct a test for H>θ.
Bringing in falsifiability only confuses the issue. No clinical data exist that will strictly falsify any of the hypotheses considered above. On the other hand, rejecting Hθ' seems like it should provide weak support for rejecting H>θ. My take on this is that since such a research program seems to work in practice, falsifiability doesn't fully describe how science works in this case (see Popper vs. Kuhn, Lakatos, Feyerabend, etc.).
Replies from: private_messaging↑ comment by private_messaging · 2012-07-11T06:25:57.241Z · LW(p) · GW(p)
Clinical data still exists that would allow a strategy to stop doing more tests at specific cut off point as the payoff from the hypothesis being right is dependent to the size of the effect and there will be clinical data at some point where the integral of payoff over lost clinical effects is small enough. It just gets fairly annoying to calculate. . Taking the strategy will be similar to gambling decision.
I do agree that there is a place for occam's razor here but there exist no formalism that actually lets you quantify this weak support. There's the Solomonoff induction, which is un-computable and awesome for work like putting an upper bound on how good induction can (or rather, can't) ever be.
↑ comment by Alex_Altair · 2012-07-09T15:22:41.415Z · LW(p) · GW(p)
I would do the same thing I would do if my hay fever had gone away with no treatment.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T15:52:31.772Z · LW(p) · GW(p)
And what would that be? Refuse to account for new evidence?
Replies from: Alex_Altair↑ comment by Alex_Altair · 2012-07-09T16:52:31.409Z · LW(p) · GW(p)
No, I mean I would be equally confused, because that's exactly what happened. Homeopathy is literally water, so I would be just as confused if I had drank water and my hay fever subsided.
Also, completely separately, even if you took some drug that wasn't just water, your case is anecdotal evidence. It should hold the same weight as any single case in any of the clinical trials. That means that it adds pretty much no data, and it's correct to not update much.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T18:19:47.675Z · LW(p) · GW(p)
even if you took some drug that wasn't just water, your case is anecdotal evidence. It should hold the same weight as any single case in any of the clinical trials.
Ah, but that's not quite true. If a remedy helps you personally, it is less than a "single case" for clinical trial purposes, because it was not set up properly for that. You would do well to ignore it completely if you are calculating your priors for the remedy to work for you.
However, it is much more than nothing for you personally, once you have seen it working for you once. Now you have to update on the evidence. It's a different step in the Bayesian reasoning: calculating new probabilities given that a certain event (in this case one very unlikely apriori -- that the remedy works) actually happened.
↑ comment by Luke_A_Somers · 2012-07-09T14:13:00.955Z · LW(p) · GW(p)
hypothesize that they're incompetent/dishonest at diluting and left some active agent in there.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T15:51:48.806Z · LW(p) · GW(p)
OK, so you take it to your chem lab and they confirm that the composition is pure sugar, as far as they can tell. How many alternatives would you keep inventing before you update your probability of it actually working?
In other words, when do you update your probability that there is a sniper out there, as opposed to "there is a regular soldier close by"?
Replies from: Luke_A_Somers, Oscar_Cunningham↑ comment by Luke_A_Somers · 2012-07-09T21:28:58.847Z · LW(p) · GW(p)
Before I update my probability of it working? The alternatives are rising to the surface because I'm updating the probability of it working.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-10T05:58:09.828Z · LW(p) · GW(p)
OK, I suppose this makes sense. Let me phrase it differently. What personal experience (not published peer-reviewed placebo-controlled randomized studies) would cause you to be convinced that what is essentially magically prepared water is as valid a remedy as, say, Claritin?
Replies from: johnlawrenceaspden↑ comment by johnlawrenceaspden · 2012-07-15T15:35:11.001Z · LW(p) · GW(p)
Well, I hate to say this for obvious reasons, but if the magic sugar water cured my hayfever just once, I'd try it again, and if it worked again, I'd try it again. And once it had worked a few times, I'd probably keep trying it even if it occasionally failed.
If it consistently worked reliably I'd start looking for better explanations. If no-one could offer one I'd probably start believing in magic.
I guess not believing in magic is something to do with not expecting this sort of thing to happen.
Replies from: Vladimir_Nesov, SusanBrennan, private_messaging↑ comment by Vladimir_Nesov · 2012-07-15T17:11:31.107Z · LW(p) · GW(p)
Well, I hate to say this for obvious reasons, but if the magic sugar water cured my hayfever just once, I'd try it again, and if it worked again, I'd try it again.
(This tripped my positive bias sense: only testing the outcome in the presence of an intervention doesn't establish that it's doing anything. It's wrong to try again and again after something seemed to work, one should also try not doing it and see if it stops working. Scattering anti-tiger pills around town also "works": if one does that every day, there will be no tigers in the neighborhood.)
Replies from: shminux, Vaniver, johnlawrenceaspden↑ comment by Shmi (shminux) · 2012-07-15T20:57:41.592Z · LW(p) · GW(p)
Scattering anti-tiger pills around town also "works": if one does that every day, there will be no tigers in the neighborhood.
That's a bad analogy. If "anti-tiger pills" repeatedly got rid of a previously observed real tiger, you would be well advised to give the issue some thought.
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2012-07-15T23:35:13.359Z · LW(p) · GW(p)
That's a bad analogy. If "anti-tiger pills" repeatedly got rid of a previously observed real tiger, you would be well advised to give the issue some thought.
What's that line about how, if you treat a cold, you can get rid of it in seven days, but otherwise it lasts a week?
You would still want to check to see whether tigers disappear even when no "anti-tiger pills" are administered.
Replies from: Sarokrae↑ comment by Sarokrae · 2012-07-15T23:50:20.813Z · LW(p) · GW(p)
You would still want to check to see whether tigers disappear even when no "anti-tiger pills" are administered.
Depending on how likely the tiger is to eat people if it didn't disappear, and your probability of the pills successfully repelling the tiger given that it's always got rid of the tiger, and the cost of the pill and how many people the tiger is expected to eat if it doesn't disappear? Not always.
Replies from: TGM, Tyrrell_McAllister↑ comment by TGM · 2012-07-16T00:32:21.217Z · LW(p) · GW(p)
A medical example of this is the lack of evidence for the efficacy of antihistamine against anaphylaxis. When I asked my sister (currently going through clinical school) about why, she said "because if you do a study, people in the control group will die if these things work, and we have good reason to believe they do"
EDIT: I got beaten to posting this by the only other person I told about it
↑ comment by Tyrrell_McAllister · 2012-07-16T17:03:36.542Z · LW(p) · GW(p)
and your probability of the pills successfully repelling the tiger given that it's always got rid of the tiger
Yes. But the point is that this number should be negligible if you haven't seen how the tiger behaves in the absence of the pills. (All of this assumes that you do not have any causal model linking pill-presence to tiger-absence.)
This case differs from the use of antihistamine against anaphylaxis for two reasons:
There is some theoretical reason to anticipate that antihistamine would help against anaphylaxis, even if the connection hasn't been nailed down with double-blind experiments.
We have cases where people with anaphylaxis did not receive antihistamine, so we can compare cases with and without antihistamine. The observations might not have met the rigorous conditions of a scientific experiment, but that is not necessary for the evidence to be rational and to justify action.
↑ comment by Sarokrae · 2012-07-16T17:39:14.375Z · LW(p) · GW(p)
Absolutely. The precise thing that matters is the probability tigers happen if you don't use the pills. So, say, I wouldn't recommend doing the experiment if you live in areas with high densities of tigers (which you do if there's one showing up every day!) and you weren't sure what was going into the pills (tiger poison?), but would recommend doing the experiment if you lived in London and knew that the pills were just sugar.
Similarly, I'm more likely to just go for a herbal remedy that hasn't had scientific testing, but has lots of anecdotal evidence for lack of side-effects, than a homeopathic remedy with the same amount of recommendation.
↑ comment by Vaniver · 2012-07-15T17:56:29.425Z · LW(p) · GW(p)
It is positive bias (in that this isn't the best way to acquire knowledge), but there's a secondary effect: the value of knowing whether or not the magic sugar water cures his hayfever is being traded off against the value of not having hayfever.
Depending on how frequently he gets hayfever, and how long it took to go away without magic sugar water, and how bothersome it is, and how costly the magic sugar water is, it may be better to have an unexplained ritual for that portion of his life than to do informative experiments.
(And, given that the placebo effect is real, if he thinks the magic sugar water is placebo, that's reason enough to drink it without superior alternatives.)
Replies from: Sarokrae↑ comment by Sarokrae · 2012-07-15T19:56:30.280Z · LW(p) · GW(p)
Agree with this. Knowing the truth has a value and a cost (doing the experiment).
I recently heard something along the lines of: "We don't have proof that antihistamines work to treat anaphylaxis, because we haven't done the study. But the reason we haven't done the study is because we're pretty sure the control group would die."
↑ comment by johnlawrenceaspden · 2012-07-16T09:44:15.663Z · LW(p) · GW(p)
I agree, I'd try not taking it too! I had hayfever as a child, and it was bloody awful. I used to put onion juice in my eyes because it was the only thing that would provide relief. But even as a child I was curious enough to try it both ways.
↑ comment by SusanBrennan · 2012-07-15T16:13:09.940Z · LW(p) · GW(p)
The placebo effect strikes me as a decent enough explanation.
Replies from: johnlawrenceaspden↑ comment by johnlawrenceaspden · 2012-07-16T10:10:22.942Z · LW(p) · GW(p)
Maybe, but it also explains why any other thing will cure my hayfever. And shouldn't it go away if I realize it's a placebo? And if I say 'I have this one thing that cures my hayfever reliably, and no other thing does, but it has no mechanism except for the placebo effect', is that very different from 'I have this magic thing?'.
I'm not keen on explanations which don't tell me what to anticipate. But maybe I misunderstand the placebo effect. How would I tell the difference between it and magic?
Replies from: TheOtherDave, Sarokrae↑ comment by TheOtherDave · 2012-07-16T13:15:07.828Z · LW(p) · GW(p)
And if I say 'I have this one thing that cures my hayfever reliably, and no other thing does, but it has no mechanism except for the placebo effect', is that very different from 'I have this magic thing?'.
No, not very. Also, if it turns out that only this one thing works, and no other thing works, then (correcting for the usual expectation effects) that is relatively strong evidence that something more than the placebo effect is going on. Conversely, if it is the placebo effect, I would expect that a variety of substances could replace the sugar pills without changing the effect much.
Another way of putting this is, if I believe that the placebo effect is curing my hayfever, that ultimately means the power to cure my hayfever resides inside my brain and the question is how to arrange things so that that power gets applied properly. If I believe that this pill cures my hayfever (whether via "the placebo effect" or via "magic" or via "science" or whatever other dimly understood label I tack onto the process), that means the power resides outside my brain and the question is how to secure a steady supply of the pill.
Those two conditions seem pretty different to me.
↑ comment by Sarokrae · 2012-07-16T10:35:38.915Z · LW(p) · GW(p)
shouldn't it go away if I realize it's a placebo?
Apparently not. The effect might be less, I don't think the study checked. But once you know it's a placebo and the placebo works, then you're no longer taking a sugar pill expecting nothing, you're taking a sugar pill expecting to get better.
You could tell the difference between the placebo effect and magic by doing a double blind trial on yourself. e.g. Get someone to assign either "magic" pill or identical sugar pill (or solution) with a random number generator for a period where you'll be taking the drug, prepare them and put them in order for you to take on successive days, and write down the order to check later. Then don't talk to them for the period of the experiment. (If you want to talk to them you can apply your own shuffle and write down how to reverse it)
Replies from: johnlawrenceaspden↑ comment by johnlawrenceaspden · 2012-07-16T10:39:13.091Z · LW(p) · GW(p)
Wait, what? I'm taking a stack of identical things and whether they work or not depends on a randomly generated list I've never seen?
Replies from: Sarokrae, TGM↑ comment by Sarokrae · 2012-07-16T10:42:57.594Z · LW(p) · GW(p)
Exactly. You write down your observations for each day and then compare them to the list to see if you felt better on days when you were taking the actual pill.
Only if it's not too costly to check, of course, and sometimes it is.
Edit: I think gwern's done a number of self-trials, though I haven't looked at his exact methodology.
Edit again: In case I haven't been clear enough, I'm proposing a method to distinguish between "sugar pills that are magic" and "regular sugar pills".
Edit3: ninja'd
↑ comment by TGM · 2012-07-16T11:38:00.784Z · LW(p) · GW(p)
If you have a selection of 'magic' sugar pills, and you want to test them for being magic vs placebo effect, you do a study comparing their efficacy to that of 'non-magic' sugar pills.
If they are magic, then you aren't comparing identical things, because only some of them have the 'magic' property
↑ comment by private_messaging · 2012-07-16T17:56:50.476Z · LW(p) · GW(p)
Well, you need it to work better than without the magic sugar water.
My approach is: I believe that the strategy of "if the magic sugar water worked with only 1 in a million probability of 'worked' being obtained by chance without any sugar water, and if only a small number of alternative cures were also tried, then adopt the belief that magic sugar water works" is a strategy that has only small risk of trusting in a non-working cure, but is very robust against unknown unknowns. It works even if you are living in a simulator where the beings-above mess with the internals doing all sorts of weird stuff that shouldn't happen and for which you might be tempted to set very low prior.
Meanwhile the strategy of "make up a very low prior, then update it in vaguely Bayesian manner" has past history of screwing up big time leading up to significant preventable death, e.g. when antiseptic practices invented by this guy were rejected on the grounds of 'sounds implausible', and has pretty much no robustness against unknown unknowns, and as such is grossly irrational (in the conventional sense of 'rational') even though in the magic water example it sounds like awesomely good idea.
↑ comment by Oscar_Cunningham · 2012-07-09T21:56:16.193Z · LW(p) · GW(p)
How many alternatives would you keep inventing before you update your probability of it actually working?
Precisely the hypotheses that are more likely than homeopathy. Once I've falsified those the probability starts pouring into homeopathy. Jaynes' "Probability Theory: The Logic Of Science", explains this really well in Chapter 4 and the "telepathy" example of Chapter 5. In particular I learnt a lot by staring at Figure 4.1.
comment by kilobug · 2012-07-09T13:09:38.326Z · LW(p) · GW(p)
After reading it fully, I've another, deeper problem with this (still great) article : Bayes' theorem totally disappears at the end. Hypothesis that exactly match the observation bitwise have a fixed probability (2^-n where n is their length), and those which are off even by one bit is discarded. There is no updating of probabilities, because hypothesis are always right or wrong. There is no concept left of an hypothesis that'll predict the position of an electron using a probability distribution, and there is no room for an hypothesis like "the coin will fall heads 75% of times, tails 25% of time".
That's both a problem for the article itself (why even speak of Bayes' theorem, if at the end it doesn't matter ?) and to find the "truth" about the universe in a quantum world (even if you accept MWI, what you'll actually observe in the world you end up being in will still be random).
I understand that going into the full details on how to handle fuzzy hypothesis (like, algorithms who don't just output one result, but different results and the probability of each) would make the article even longer, but it would still be a good thing to address those issues somewhere, IMHO.
Replies from: Alex_Altair, lukeprog, private_messaging, razorcamDOTcom↑ comment by Alex_Altair · 2012-07-09T16:26:51.026Z · LW(p) · GW(p)
You are pretty much correct.
The causal reason that Bayes' theorem is in the article is because Luke wrote that part before I was involved. If I had written it from scratch, I probably wouldn't have included it.
But I think it's reasonable to include it because this is an article for laymen, and Bayes' theorem is a really important piece to have your knowledge of rationality built around. Furthermore, the discovery of Solomonoff induction was motivated by the search for objective priors, which is a Bayes' theorem thing.
But you're exactly correct that hypotheses either match or they don't. The updating of probabilities occurs when you renormalize after eliminating hypotheses. Also, I've thought about it for a while and concluded that no modification is needed to represent probabilistic hypotheses. I may write a piece later about how Bayes' theorem is consistent with Solomonoff induction.
↑ comment by lukeprog · 2012-07-10T05:51:49.787Z · LW(p) · GW(p)
Note that Alex has now added this addendum.
↑ comment by private_messaging · 2012-07-09T15:38:03.100Z · LW(p) · GW(p)
You don't really use Solomonoff induction with Bayes. It directly gives predictions (and in AIXI, evaluates actions). You could use 2^-len prior on hypotheses in Bayesian inference, but this is not Solomonoff induction, it just looks superficially similar but doesn't share the properties.
Point entirely retracted. I am completely wrong here - I did not see how it works out to identical if you assign certainty of 1 to data. (didn't occur to me to assign certainty of 1 to anything). Thanks for corrections.
Replies from: gjm↑ comment by gjm · 2012-07-10T10:51:51.624Z · LW(p) · GW(p)
I haven't read Solomonoff's original papers, but e.g. Shane Legg's paper on Solomonoff induction gives a description that amounts to "use Bayes with a 2^-program_length prior". How do you see the two differing and (if this isn't obvious) why does it matter?
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T11:05:43.727Z · LW(p) · GW(p)
Well then you have to be using it on each and every program for each bit of uncertain data. (What is uncertain data? The regular definition can model the errors you might have in measurement apparatus as well; it is not clear what is the advantage of putting the uncertainty outside of the codes themselves)
If I am to assume that the hypotheses do not get down to their minimum length (no exhaustive uncomputable search), then there is a very significant penalty from 2^-length prior for actual theories versus just storing the data. The computable generative methods (such as a human making hypothesis) don't find shortest codes, they may be generating codes that are e.g. the size of the shortest code squared, or even faster growing function.
edit: Also, btw, on the sum over all programs: consider the program that never runs past N bits so the bits after N do not matter. There is 1 program of length N, 2 programs of length N+1 , 4 programs of length N+2, and so on, that are identical to this program when run. Got to be careful counting and not forget you care about prefixes.
Replies from: gjm, Steve_Rayhawk↑ comment by gjm · 2012-07-10T12:26:36.409Z · LW(p) · GW(p)
Perhaps I'm being dim, but it doesn't look as if you answered my question: what differences do you see between "Solomonoff induction" and "Bayesian inference with a 2^-length prior"?
It sounds (but I may be misunderstanding) as if you're contrasting "choose the shortest program consistent with the data" with "do Bayesian inference with all programs as hypothesis space and the 2^-length prior" in which case you're presumably proposing that "Solomonoff induction" should mean the former. But -- I have now found at least one of Solomonoff's articles -- it's the latter, not the former, that Solomonoff proposed. (I quote from "A preliminary report on a general theory of inductive inference", revised version. From the preface: "The main point of the report is Equation (5), Section 11". From section 12, entitled "An interpretation of equation (5)": "Equation (5) then enables us to use this model to obtain a priori probabilities to be used in computation of a posteriori probabilities using Bayes' Theorem.")
Solomonoff induction is uncomputable and any computable method necessarily fails to find shortest-possible programs; this is well known. If this fact is the basis for your objection to using the term "Solomonoff induction" to denote Bayes-with-length-prior then I'm afraid I don't understand why; could you explain more?
It's conventional to assume a prefix-free representation of programs when discussing this sort of formalism. I don't see that this has anything to do with the distinction (if there is one) between Solomonoff and Bayes-with-length-prior.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T13:51:06.693Z · LW(p) · GW(p)
Firstly, on what is conventional, it is sadly the case that in the LW conversations observed by me it is not typical that either party recollects the magnitude of the importance of having ALL programs as the hypothesis space, or any other detail, even the detail so important as 'the output's beginning is matched against observed data'.
I'm sorry I was thinking in the context whereby the hypothesis space is not complete (note: in the different papers on subjects if i recall correctly the hypothesis can either refer to the final string - the prediction - or to the code). Indeed in the case where it is applied to the complete set of hypotheses, it works fine. It still should be noted though that it is Solomonoff probability (algorithmic probability), that can be used with Bayes, resulting in Solomonoff induction.
It was my mistake with regards to what Solomonoff exactly specified, given that there is a multitude of different equivalent up to constant definitions that end up called same name. By Solomonoff induction I was referring to the one described in the article.
Replies from: gjm↑ comment by gjm · 2012-07-10T15:26:44.036Z · LW(p) · GW(p)
OK. (My real purpose in posting this comment is to remark, in case you should care, that it's not I who have been downvoting you in this thread.)
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T15:47:49.202Z · LW(p) · GW(p)
Thanks for correction in any case. This was genuinely an error on my part. Amusingly it was at +1 while noting that MWI (which someone else brought up) doesn't begin with the observed data, was much more negatively treated.
↑ comment by Steve_Rayhawk · 2012-07-10T13:57:22.429Z · LW(p) · GW(p)
You discussed this over here too, with greater hostility:
also someone somehow thinks that Solomonoff induction finds probabilities for theories, while it just assigns 2^-length as probability for software code of such length, which is obviously absurd when applied to anything but brute force generated shortest pieces of code,
I'm trying to figure out whether, when you say "someone", you mean someone upthread or one of the original authors of the post. Because if it's the post authors, then I get to accuse you of not caring enough about refraining from heaping abuse on writers who don't deserve it to actually bother to check whether they made the mistake you mocked them for. The post includes discussion of ideals vs. approximations in the recipe metaphor and in the paragraph starting "The actual process above might seem a little underwhelming...":
We just check every single hypothesis? Really? Isn’t that a little mindless and inefficient? This will certainly not be how the first true AI operates. But don’t forget that before this, nobody had any idea how to do ideal induction, even in principle. Developing fundamental theories, like quantum mechanics, might seem abstract and wasteful. [...] such theories and models change the world, as quantum mechanics did with modern electronics. In the future, [...] ways to approximate Solomonoff induction [...] Perhaps they will develop methods to eliminate large numbers of hypotheses all at once. Maybe hypotheses will be broken into distinct classes. Or maybe they’ll use methods to statistically converge toward the right hypotheses.
Everyone knows there are practical difficulties. Some people expect that someone will almost certainly find a way to mitigate them. You tend to treat people as idiots for going ahead with the version of the discussion that presumes that.
With respect to your objections about undiscoverable short programs, presumably people would look for ways to calibrate the relationship between the description lengths of the theories their procedures do discover (or the lengths of the parts of those theories) and the typical probabilities of observations, perhaps using toy domains where everything is computable and Solomonoff probabilities can be computed exactly. Of course, by diagonalization there are limits to the power of any finite such procedure, but it's possible to do better than assuming that the only programs are the ones you can find explicitly. Do you mean to make an implicit claim by your mockery which special-cases to the proposition that what makes the post authors deserve to be mocked is that they didn't point out ways one might reasonably hope to get around this problem, specifically? (Or, alternatively, is the cause of your engaging in mockery something other than a motivation to express propositions (implicit or explicit) that readers might be benefited by believing? For example, is it a carelessly executed side-effect of a drive to hold your own thinking to high standards, and so to avoid looking for ways to make excuses for intellectual constructs you might be biased in favor of?)
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T14:11:19.717Z · LW(p) · GW(p)
It is the case that Luke, for instance of an author of this post, wrote this relatively recently. While there is understanding that bruteforcing is the ideal, I do not see understanding of how important of a requirement that is. We don't know how long is the shortest physics, and we do not know how long is the shortest god-did-it, but if we can build godlike AI inside our universe then the simplest god is at most same length and unfortunately you can't know there isn't a shorter one. Note: I am an atheist, before you jump onto he must be theist if he dislikes that statement. Nonetheless I do not welcome pseudo-scientific justifications of atheism.
edit: also by the way, if we find a way to exploit quantum mechanics to make a halting oracle and do true Solomonoff induction some day, that would make physics of our universe incomputable and this amazing physics itself would not be representable as Turing machine tape, i.e. would be a truth that Solomonoff induction we could do using this undiscovered physics would not be able to even express as a hypothesis. Before you go onto Solomonoff induction you need to understand Halting problem and variations, otherwise you'll be assuming that someday we'll overcome Halting problem, which is kind of fine except if we do then we just get ourselves the Halting problem of the second order plus a physics where Solomonoff induction doable with the oracle does not do everything.
↑ comment by razorcamDOTcom · 2012-07-10T10:34:07.995Z · LW(p) · GW(p)
Kilobug wrote "There is no updating of probabilities, because hypothesis are always right or wrong" Do not forget that any wrong hypothesis can become right by adding some error correcting instructions in it. It will only make the program longer and thus lower its probability. But is seems intuitive that the more a theory needs error corrections, the less it's probable.
Kilobug wrote "there is no room for an hypothesis like "the coin will fall heads 75% of times, tails 25% of time" There is room for both an hypothesis that predict the coin will always fall heads and this hypothesis has a probability of 75%. And an hypothesis that predict the coin will always fall tails and this hypothesis has a probability of 25%.
Replies from: D_Malik↑ comment by D_Malik · 2012-08-05T01:29:43.680Z · LW(p) · GW(p)
Kilobug wrote "there is no room for an hypothesis like "the coin will fall heads 75% of times, tails 25% of time" There is room for both an hypothesis that predict the coin will always fall heads and this hypothesis has a probability of 75%. And an hypothesis that predict the coin will always fall tails and this hypothesis has a probability of 25%.
Say the coin falls HHTHTHH. Then the hypothesis that it will always fall heads has probability 0%, because they weren't all heads. Same for the hypothesis that it will always fall tails.
It seems like it would be pretty easy, though, to extend Solomonoff induction to have each hypothesis be an algorithm that outputs a probability distribution, and then update for each bit of evidence with Bayes's theorem. If we did that for this example, I think the hypothesis that generated the 25%:75% probability distribution would eventually win out.
Replies from: pengvado↑ comment by pengvado · 2012-08-05T04:47:49.068Z · LW(p) · GW(p)
The original Solomonoff induction is already equivalent to that.
Proof sketch: Any program that computes a probability distribution can (with constant overhead and a source of uniform random bits) be converted into a program that samples from that same distribution. Then convert that into a family of deterministic programs, each of which hardcodes one possible random sequence.
The total weight of such a family in the Solomonoff prior is within a constant factor of the weight that the single probabilistic hypothesis would have had, and ruling out members of the family that disagreed with observation is equivalent to Bayesian updating.
comment by Shmi (shminux) · 2012-07-09T05:35:43.004Z · LW(p) · GW(p)
What's the length of the hypothesis that F=ma?
Replies from: Mitchell_Porter, JulianMorrison, handoflixue, Eliezer_Yudkowsky↑ comment by Mitchell_Porter · 2012-07-09T06:19:40.769Z · LW(p) · GW(p)
How many bits does it take to say "mass times the second derivative of position"? An exact answer would depend on the coding system. But if mass, position, time, multiplication, and differentiation are already defined, then, not many bits. You're defining force as ProductOf(mass,d[d(position)/d(time)]/d(time)).
See the discussion here on the bit complexity of physical laws. One thing missing from that discussion is how to code the rules for interpreting empirical data in terms of a hypothesis. A model is useless if you don't know what empirical phenomena it is supposed to be describing, and that has to be specified somehow too.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T06:21:35.722Z · LW(p) · GW(p)
I understand all that, I just want a worked example, not only hand-waving. After all, a formalization of Occam's razor is supposed to be useful in order to be considered rational.
Replies from: abe-dillon, dbc↑ comment by Abe Dillon (abe-dillon) · 2019-08-09T01:04:28.782Z · LW(p) · GW(p)
After all, a formalization of Occam's razor is supposed to be useful in order to be considered rational.
Declaring a mathematical abstraction useless just because it is not practically applicable to whatever your purpose may be is pretty short-sighted. The concept of infinity isn't useful to engineers, but it's very useful to mathematicians. Does that make it irrational?
↑ comment by dbc · 2012-07-09T06:40:06.883Z · LW(p) · GW(p)
Remember, the Kolmogorov complexity depends on your "universal Turing machine", so we should expect to only get estimates. Mitchell makes an estimate of ~50000 bits for the new minimal standard model. I'm not an expert on physics, but the mathematics required to explain what a Lagrangian is would seem to require much more than that. I think you would need Peano arithmetic and a lot of set theory just to construct the real numbers so that you could do calculus (of course people were doing calculus for over one hundred years before real numbers existed, but I have a hard time imagining a rigorous calculus without them...) I admit that 50000 bits is a lot of data, but I'm sceptical that it could rigorously code all that mathematics.
F=ma has the same problem, of course. Does the right hand side really make sense without calculus?
ETA: If you want a fleshed out example, I think a much better problem to start off with would be predicting the digits of pi, or the prime numbers.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2012-07-09T06:51:09.864Z · LW(p) · GW(p)
My estimate was 27000 bits to "encode the standard model" in Mathematica. To define all the necessary special functions on a UTM might take 50 times that.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T07:38:25.129Z · LW(p) · GW(p)
I just want something simple but useful. Gotta start small. Once we are clear on F=ma, we can start thinking about formalizing more complicated models, and maybe some day even quantum mechanics and MWI vs collapse.
Replies from: Mitchell_Porter, private_messaging↑ comment by Mitchell_Porter · 2012-07-09T08:13:50.616Z · LW(p) · GW(p)
Maybe start by showing how it works to predict a sequence like 010101..., then something more complicated like 011011... It starts to get interesting with a sequence like 01011011101111... - how long would it take to converge on the right model there? (which is that the subsequence of 1s is one bit longer each time).
True Solomonoff induction is uselessly slow. The relationship of Solomonoff induction to actual induction is like the relationship of Principia Mathematica to a pocket calculator; you don't use Russell and Whitehead's methods and notation to do practical arithmetic. Solomonoff induction is a brute-force scan of the whole space of possible computational models for the best fit. Actual induction tends to start apriori with a very narrow class of possible hypotheses, and only branches out to more elaborate ones if that doesn't work.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T15:38:29.116Z · LW(p) · GW(p)
Maybe start by showing how it works to predict a sequence like 010101..., then something more complicated like 011011... It starts to get interesting with a sequence like 01011011101111... -
This would be a derivation of F=ma, vs all other possible laws. I am not asking for that. My question is supposedly much simpler: write a binary string corresponding to just one model out of infinitely many, namely F=ma.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2012-07-09T16:11:56.640Z · LW(p) · GW(p)
If we adopt the paradigm in the article - a totally passive predictor, which just receives a stream of data and makes a causal model of what's producing the data - then "F=ma" can only be part of the model. The model will also have to posit particular forces, and particular objects with particular masses.
Suppose the input consists of time series for the positions in three dimensions of hundreds of point objects interacting according to Newtonian gravity. I'm sure you can imagine what a program capable of generating such output looks like; you may even have written such a program. If the predictor does its job, then its model of the data source should also be such a program, but encoded in a form readable by a UTM (or whatever computational system we use).
Such a model would possibly have a subroutine which computed the gravitational force exerted by one object on another, and then another subroutine which computed the change in the position of an object during one timestep, as a function of all the forces acting on it. "F=ma" would be implicit in the second subroutine.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2012-07-09T17:05:25.206Z · LW(p) · GW(p)
This is correct.
Solomonoff induction accounts for all of the data, which is a binary sequence of sensory-level happenings. In its hypothesis, there would have to be some sub-routine that extracted objects from the sensory data, one that extracted a mass from these objects, et cetera. The actual F=ma part would be a really far abstraction, though it would still be a binary sequence.
Solomonoff induction can't really deal with counterfactuals in the same way that a typical scientific theory can. That is, we can say, "What if Jupiter was twice as close?" and then calculate it. With Solomonoff induction, we'd have to understand the big binary sequence hypothesis and isolate the high-level parts of the program to use just those to calculate the consequence of counterfactuals.
↑ comment by private_messaging · 2012-07-09T09:42:29.077Z · LW(p) · GW(p)
We can already do MWI vs Collapse without being clear on F=ma. MWI is not even considered because MWI does not output a string that begins with the observed data, i.e. MWI will never be found when doing Solomonoff induction. MWI's code may be a part of correct code, such as Copenhagen interpretation (which includes MWI's code). Or something else may be found (my bet is on something else because general relativity). It is this bloody simple.
The irony is, you can rule MWI out with Solomonoff induction without even choosing the machine or having a halting oracle. Note: you can't rule out existence of many worlds. But MWI simply does not provide the right output.
Replies from: shminux, Kawoomba, Luke_A_Somers, naasking↑ comment by Shmi (shminux) · 2012-07-09T15:42:26.892Z · LW(p) · GW(p)
We can already do MWI vs Collapse without being clear on F=ma.
At this point I am not interested in human logic, I want a calculation of complexity. I want a string (an algorithm) corresponding to F=ma. Then we can build on that.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-09T15:53:28.368Z · LW(p) · GW(p)
If F, m and a are true real numbers, its un-computable (can't code it in TM) and not even considered by Solomonoff induction, so here.
My point was simply that MWI is not a theory that would pass the 'input begins with string s' criterion, and therefore, is not even part of the sum at all.
It's pretty hilarious, the explanation is semi okay, but implied is that Solomonoff induction is awesome, and the topic is hard to think about, so people substitute "awesome" for Solomonoff induction, then all the imagined implications end up "not even wrong". edit: also someone somehow thinks that Solomonoff induction finds probabilities for theories, while it just assigns 2^-length as probability for software code of such length, which is obviously absurd when applied to anything but brute force generated shortest pieces of code, because we don't get codes to their minimum lengths (thats uncomputable) and the hypothesis generation process can have e.g. bloat up factor of 10 (plausible) or even a quadratic blow up factor, making the 2^-length prior be much much too strongly discriminating against actual theories in favour of simply having the copy of the data stored inside.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-09T20:39:27.590Z · LW(p) · GW(p)
If F, m and a are true real numbers, its un-computable (can't code it in TM) and not even considered by Solomonoff induction, so here.
That's a cop-out, just discretize the relevant variables to deal with integers, Planck units, if you feel like it. The complexity should not depend on the step size.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T21:36:45.370Z · LW(p) · GW(p)
Well it does depend on the step size. You end up with higher probability for larger discretization constant (and zero probability for no discretization at all), if you use the Turing machine model of computation (and if you use something that does reals you will not face such issue). I'm trying explain that in the ideal limit, it has certain huge shortcomings. The optimality proofs do not imply it is good, they only imply other stuff isn't 'everywhere as good and somewhere better'.
The primary use of this sort of thing - highly idealized induction that is uncomputable - is not to do induction but to find limits to induction.
↑ comment by Kawoomba · 2012-07-09T20:07:27.787Z · LW(p) · GW(p)
Why are his comments in this thread getting downvoted? They show a quite nuanced understanding of S. I. and raise interesting points.
If there is no requirement for the observed data to be at the start of the string that is output, then the simplest program that explains absolutely everything that is computable is this:
Print random digits. (This was actually a tongue-in-cheek Schmidhuber result from the early 2000s, IIRC. The easiest program whose output will assuredly contain our universe somewhere along the line.)
Luckily there is such a requirement, and I don't know how MWI could possibly fit into it. This unacknowledged tension has long bugged me, and I'm glad someone else is aware of it.
Replies from: Steve_Rayhawk, thomblake, shminux↑ comment by Steve_Rayhawk · 2012-07-10T09:24:50.514Z · LW(p) · GW(p)
He identifies subtleties, but doesn't look very hard to see whether other people could have reasonably supposed that the subtleties resolve in a different way than he thinks they "obviously" do. Then he starts pre-emptively campaigning viciously for contempt for everyone who draws a different conclusion than the one from his analysis. Very trigger-happy.
This needlessly pollutes discussion... that is to say, "needless" in the moral perspective of everyone who doesn't already believe that most people who first appear wrong by that criterion that way in fact are wrong, and negligently and effectively incorrigibly so, such that there'd be nothing to lose by loosing broadside salvos before the discussion has even really started. (Incidentally, it also disincentivizes the people who could actually explain the alternative treatment of the subtleties from engaging with him, by demonstrating a disinclination to bother to suppose that their position might be reasonble.) This perception of needlessness, together with the usual assumption that he must already be on some level aware of other peoples' belief in that needlessness but is disregarding that belief, is where most of the negative affect toward him comes from.
Also, his occasional previous lack of concern for solid English grammar didn't help the picture of him as not really caring about the possibility that the people he was talking to might not deserve the contempt for them that third parties would inevitably come away with the impression that he was signaling.
(I wish LW had more people who were capable of explaining their objections understandably like this, instead of being stuck with a tangle of social intuitions which they aren't capable of unpacking in any more sophisticated way than by hitting the "retaliate" button.)
Replies from: TheOtherDave, private_messaging, private_messaging↑ comment by TheOtherDave · 2012-07-10T14:23:50.456Z · LW(p) · GW(p)
Were capable of and bothered to, I suppose. I rarely bother to explain the reasons for my value judgments unless I'm specifically asked, and sometimes not even then. Especially not when it comes to value judgments of random people on the Internet. Low-value Internet interactions are fungible.
↑ comment by private_messaging · 2012-07-10T14:39:20.471Z · LW(p) · GW(p)
See edit on this post . Also, note that this tirade starts from going down to -6 votes (or so) on, you know, perfectly valid issue that Solomonoff induction has with expressing the MWI. You get the timeline backwards. I post something sensible, concise and clear, then I get it down -6 or so, THEN I can't help it but assume utter lack of understanding. Can't you see I have my retaliate button too? There's more downvotes here to pointing out a technical issue normally without flaming anyone. This was early in my posting history (before me disagreeing with anyone massively thats it):
http://lesswrong.com/lw/ai9/how_do_you_notice_when_youre_rationalizing/5y3w
and it is me honestly expressing another angle on the 'rationalization', and it was at -7 at it's lowest! I interpret it as '7 people disagree'.
edit: also by someone I tend to refer to 'unknown persons', i.e. downvoters of such posts.
Replies from: Steve_Rayhawk↑ comment by Steve_Rayhawk · 2012-07-10T16:34:37.905Z · LW(p) · GW(p)
I'm sorry; I was referring to what I had perceived as a general pattern, from seeing snippets of discussions involving you while I was lurking off-and-on. The "pre-emptive" was meant to refer to within single exchanges, not to refer all the way back to (in this case) the original discussion about MWI (which I'm still hunting down). Now that I look more closely at your history, this has only been at all frequent within the past few months.
I don't have any specific recollection of you from before that comment on the "detecting rationalization" post, but looking back through your comment history of that period, I'm mystified by what happened there too. It's possible that someone thought you were Thomas covertly giving a self-justifying speech about a random red-herring explanation he'd invented to tell himself for why other people disagreed with him, and they wished to discourage him from thinking other people agreed with that explanation.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T16:53:05.041Z · LW(p) · GW(p)
I responded privately earlier... I really don't quite know why I still bother posting here. Also btw, there's other thing: I posted several things that werequite seriously wrong, in the sense of wrong chain of reasoning (not outcome). Those were upvoted and agreed with a fair lot.
Also, on the MWI, I am a believer that as far as we know there can be many worlds out there, and even if quantum mechanics is wrong it is fairly natural for mathematics to work out to many worlds, and it is not like believing in the apple cake in the asteroid belt. I do not dislike the conclusion. I dislike the argument. Ditto for Solomonoff induction and theism, I am an atheist. I tend to be particularly negative towards the arguments that incorrectly argue in favour of what I believe, on the few times that I notice the incorrectness (obviously that got to be much less common than seeing incorrectness in the arguments in favour of what I don't believe).
↑ comment by private_messaging · 2012-07-10T16:07:57.531Z · LW(p) · GW(p)
p.s. please note that the field is VERY full of impossibility proofs (derived from Halting Problem) which are of the form 'this does not resolve" (and full of "even if you postulate that this resolves, then something else doesn't resolve") and I do not look very hard indeed into the possibility that the associated subtleties resolve. Please also note that the subtlety of 'the output must begin with data' is not the kind of subtlety that resolves in any way. I can sometimes be very certain that a subtlety does not resolve; most of the time I am not certain (this field is outside my field of expertise) and I seldom if ever comment on those points (e.g. I refrained from commenting on Solomonoff induction here in the beginning of my post history) and I do not comment negatively on those.
The Solomonoff induction is a very complicated topic and it requires very careful consideration before the speculations. Due to it's high difficulty the probability of subtleties resolving is considerably less than in the less complicated topics.
Replies from: Steve_Rayhawk↑ comment by Steve_Rayhawk · 2012-07-10T16:44:10.025Z · LW(p) · GW(p)
The subtleties I first had in mind were the ones that should have (but didn't) come up in the original earlier dicussion of MWI, having to do with the different numbers of bits in different parts of an observation-predicting program based on a physical theory, and which of those parts should have their bits be charged against the prior or likelihood of the physical theory itself and which of the parts should have their bits be taken for granted as intrinsic parts of the anthropic reasoning that any agent would need to be capable of (even if some physical theories didn't use part of that anthropic reasoning "software").
(I didn't specify what the subtleties were, and you seem to have picked a reading of which subtleties I must have been referring to and what I must have meant by "resolve" that together made what I was saying make no sense at all. This might be another example of the proposed tendency of "not looking very hard to see whether other people could have reasonably supposed" etc. (whether or not other people in the same reference class from your point of view as me weren't signaling that they understood the point either).)
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T17:08:00.822Z · LW(p) · GW(p)
Well, taking for granted some particular class of bits is very problematic when you have brute force search over values of those bits. You can have a reasonably short program (that can be shorter than physics) which would iterate all theories of physics and run them for a very very long time. Then if you are allowed to just search for the observers, this program will be the simplest theory, and you are effectively back to the square one; you don't get anything useful (you got solomonoff induction inside solomonoff induction). Sorry I still can't make sense out of it.
I also don't see why I should have searched for possible resolutions, and assume that other party has good reason to expect such resolution, if I reasonably believe that such resolution would have a good chance at Fields medal (or even a good reason to expect such resolution would).
I also don't like speculative conjectures via lack of counter argument as combined with posts like this (and all posts inspired by it's style), and feel very disinclined to run the highly computationally expensive search for possible solutions by a person that would not have such considerations about the entire majority of scientists that he thinks believe in something other than MWI. (in so much as MWI is part of CI every CI endorser believes in MWI in a way, they just believe that it is invalid to believe in extra worlds that can't be observed, or other philosophical stance that is a matter of opinion).
edit: that is to say, the stance often expressed on MWI here is normative: if you don't believe in MWI you are wrong, and not just that, but the scientific community is wrong for not believing in MWI. That is the backgrounder. I do believe many worlds are a possibility, but I do not believe the above argument to be valid. And as you yourself have eloquently explained, one should not proclaim those believing in MWI to be stupid on basis of unresolved problems not being resolved (I do not do that). But this also goes with CI, and I am not the community that is being normative about what is rational and judges by MWI belief status whenever one's rational. edit2: and I do not see how this strong-pro-MWI stance is compatible with awareness of the subtleties. Furthermore, at the point when you make so many implicit assumptions about subtleties resolving in your favour, you could as well say Occam's razor; it is not appropriate to use specific term (Solomonoff induction) to refer to something fuzzy.
↑ comment by thomblake · 2012-07-10T15:02:20.771Z · LW(p) · GW(p)
private_messaging is a troll. Safely assume bad faith.
Replies from: shminux, private_messaging↑ comment by Shmi (shminux) · 2012-07-10T18:48:22.098Z · LW(p) · GW(p)
private_messaging is a troll
Wikipedia:
a troll is someone who posts inflammatory extraneous, or off-topic messages in an online community, such as an online discussion forum, chat room, or blog, with the primary intent of provoking readers into an emotional response or of otherwise disrupting normal on-topic discussion
Let's see:
- inflammatory: check
- extraneous: sometimes, not in this case
- off-topic: not exactly
- intent to provoke/disrupt: not in my estimation
so, maybe 25-30% trollness.
Safely assume bad faith.
I never get this impression from his posts. They seem honest (if sometimes misguided) not malicious to me.
Replies from: TheOtherDave↑ comment by TheOtherDave · 2012-07-10T18:57:13.499Z · LW(p) · GW(p)
Can you say more about how you distinguish messages intended to provoke emotional response from those that are merely inflammatory?
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-10T21:14:41.634Z · LW(p) · GW(p)
Intent makes a difference for me. private_messaging seems to want to get his point across (not counting an occasional rant), without regard to the way his comments come across. I did not detect any intent of riling people up for its own sake.
Replies from: TheOtherDave↑ comment by TheOtherDave · 2012-07-10T21:16:07.485Z · LW(p) · GW(p)
(nods) That's fair. Thanks for the clarification.
↑ comment by private_messaging · 2012-07-10T15:06:04.646Z · LW(p) · GW(p)
Hmm so you safely assume that I made up a requirement that the observed data be at the start of the string that is output?
↑ comment by Shmi (shminux) · 2012-07-09T20:36:21.346Z · LW(p) · GW(p)
I suspect that others downvote private_messaging because of his notoriety. I did downvote his comment because he strayed away from my explicit (estimate the complexity of the Newton's 2nd law) request and toward a flogged-to-death topic of MWI vs the world. Such a discussion has proven to be unproductive time and again in this forum.
Replies from: wedrifid↑ comment by wedrifid · 2012-07-09T21:30:45.300Z · LW(p) · GW(p)
I suspect that others downvote private_messaging because of his notoriety. I did downvote his comment because he strayed away from my explicit (estimate the complexity of the Newton's 2nd law) request and toward a flogged-to-death topic of MWI vs the world. Such a discussion has proven to be unproductive time and again in this forum.
Likewise. (With the caveat that I endorse downvoting extreme cases based on notoriety so probably would have downvoted anyway.)
↑ comment by Luke_A_Somers · 2012-07-09T14:11:28.846Z · LW(p) · GW(p)
An interesting point - the algorithm would contain apparent collapses as special instructions even while it did not contain it as general rules.
I think leaving it out as a general rule damages the notion that it's producing the Copenhagen Interpretation, though.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-09T15:06:49.630Z · LW(p) · GW(p)
What is special instructions and what is general rules? The collapse in CI is 'special instructions' unless you count confused and straw-man variations of CI. It's only rules in objective collapse theories.
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2012-07-09T21:27:37.327Z · LW(p) · GW(p)
In that case, Ci is MWI, so why draw the distinction?
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T06:31:55.997Z · LW(p) · GW(p)
Yes, no shit Sherlock, why? I do not know. It's called 'interpretations' for a reason. You tell me. I am not the one drawing distinction with posts like this.
Also, in so much as the codes produce identical output, the Solomonoff induction using agent (like AIXI) behaves the same and it doesn't matter what interpretation label you slap onto the shortest model in it.
edit: also, in physics it is important to minimize number of principles, even if that doesn't minimize the predictor code. We want to derive apparent collapse from the de-coherence, even if predictor code is the same. That's because we do look for understanding, you know, intellectual curiosity and all that.
↑ comment by naasking · 2013-03-08T15:01:13.666Z · LW(p) · GW(p)
MWI is not even considered because MWI does not output a string that begins with the observed data, i.e. MWI will never be found when doing Solomonoff induction.
The same observed that produced Copenhagen and de Broglie-Bohm produced MWI. You acknowledge as much when you state that Copenhagen extends MWI with more axioms. The observation string for MWI is then identical to Copenhagen, and there is no reason to select Copenhagen as preferred.
↑ comment by JulianMorrison · 2012-07-12T12:41:13.823Z · LW(p) · GW(p)
I think this post is making the mistake of allowing the hypothesis to be non-total. Definition: a total hypothesis explains everything, it's a universe-predicting machine and equivalent to "the laws of physics". A non-total hypothesis is like an unspecified total hypothesis with a piece of hypothesis tacked on. Neither what it does, nor any meaningful understanding of its length, can be derived without specifying what it's to be attached to.
↑ comment by handoflixue · 2012-08-08T00:57:09.819Z · LW(p) · GW(p)
01000110001111010110110101100001
Replies from: TheWakalix↑ comment by TheWakalix · 2018-11-23T17:25:16.489Z · LW(p) · GW(p)
The number of bits required to express something in English is far from the information-theoretic complexity of the thing. "The woman over there is a witch; she did it."
Replies from: habryka4↑ comment by habryka (habryka4) · 2018-11-23T17:53:53.583Z · LW(p) · GW(p)
Depends on your choice of Universal Turing Machine. You can choose a human, which is a valid universal turing machine, and then the kolmogorov complexity is equal.
Replies from: TheWakalix↑ comment by TheWakalix · 2018-11-23T22:14:39.780Z · LW(p) · GW(p)
Hm, good point. I think there might still be a way to save the concept that witches are more complex than electromagnetism, though.
You need a very large overhead for a human. This overhead contains some of the complexity of "witch" but comparatively less of the complexity of "electromagnetism". So Complexity(human)+Complexity("witch", context=human) is an upper bound on the "inherent complexity" of "witch", and the latter term alone doesn't mean as much.
Replies from: TheWakalix↑ comment by TheWakalix · 2019-05-17T20:29:08.043Z · LW(p) · GW(p)
But where do we get Complexity(human)?
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-07-09T21:23:44.051Z · LW(p) · GW(p)
Four.
Replies from: MixedNuts, shminux↑ comment by MixedNuts · 2012-07-09T21:45:26.683Z · LW(p) · GW(p)
Plus a constant.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T17:58:42.588Z · LW(p) · GW(p)
I think people missed a joke here. I mean, seriously, EY is not so stupid as to think that it is 4 bits literally. And if it is 4 symbols, and symbols are arbitrary size, then it's not 'plus a constant', it's multiply by a log2(nsymbols in alphabet) plus a constant (suppose I make Turing machine with 8-symbol tape, then on this machine I can compress arbitrary long programs of other machine into third length plus a constant).
Replies from: wedrifid↑ comment by wedrifid · 2012-07-10T18:18:51.733Z · LW(p) · GW(p)
I think people missed a joke here. I mean, seriously, EY is not so stupid as to think that it is 4 bits literally. And if it is 4 symbols, and symbols are arbitrary size, then it's not 'plus a constant', it's multiply by a log2(nsymbols in alphabet) plus a constant (suppose I make Turing machine with 8-symbol tape, then on this machine I can compress arbitrary long programs of other machine into third length plus a constant).
No, really. It can be 4 literal bits and a sufficiently arbitrary constant. It's still a joke and I rather liked it myself.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-10T18:30:16.726Z · LW(p) · GW(p)
Yes. I was addressing what I thought might be sensible reason not to like the joke given that F=ma is 4 symbols (so is "four").
↑ comment by Shmi (shminux) · 2012-07-10T15:06:36.757Z · LW(p) · GW(p)
Then my hypothesis is simpler: GOD.
Replies from: wedrifid, Thomas↑ comment by Thomas · 2012-07-13T10:28:22.682Z · LW(p) · GW(p)
Then my hypothesis is simpler: GOD.
As long as the GOD is simple and not too knowable. If he knows everything (about the Universe), he is even more complex than the Universe.
Replies from: shminux↑ comment by Shmi (shminux) · 2012-07-13T15:32:56.142Z · LW(p) · GW(p)
The same logic applies to EY's comment :)
comment by [deleted] · 2012-07-08T23:26:56.139Z · LW(p) · GW(p)
Which number comes next?
Here is my favorite integer sequence:
Arrange N points around a circle, then draw lines between all of them in order to slice up the circle. What is the maximum number of regions that you can obtain?
N=1 gives you 1 region (the whole circle). N=2 gives you 2 regions (a single cut) N=3 gives you 4 regions (a triangle and 3 circular segments). N=4 gives you 8 regions (a quadrilateral with an X gives you 4 triangles and 4 circular segments).
Remember, these are the maximum numbers - I have provided examples of how to get them, but there is no way to get more regions. (Obvious for low N, harder to prove for higher N.)
What are the next two numbers?
Answer: http://oeis.org/A000127
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-07-09T09:22:22.409Z · LW(p) · GW(p)
I was one asked the answer to that with N=6. I noticed the pattern for N <= 5, but I suspected they were trying to trick me so I actually tried to determine it from scratch. (As for the “Obvious for low N, harder to prove for higher N” part, I used the heuristic that if no three of the lines met at one same point inside the circle, I had probably achieved the maximum. It worked.)
OTOH I was once asked "2, 3, 5, 7, what comes next?" and I immediately answered “that's the prime numbers, so it's 11”, but there was some other sequence they were thinking about (I can't remember which).
Replies from: Thomas↑ comment by Thomas · 2012-07-13T10:31:30.417Z · LW(p) · GW(p)
Replies from: SPLH↑ comment by Simon Pepin Lehalleur (SPLH) · 2012-07-14T09:05:01.239Z · LW(p) · GW(p)
Yes, the OEIS is a great way to learn first-hand the Strong Law of Small Numbers. This sequence being a particularly nice example of "2,3,5,7,11,?".
comment by johnlawrenceaspden · 2012-07-16T14:30:24.091Z · LW(p) · GW(p)
This explanation makes something that sounds scary look obvious. It's a model of clarity and good writing. Thank you.
comment by loganamcnichols · 2019-03-05T17:50:40.054Z · LW(p) · GW(p)
I am struggling to understand part of how Solomonoff's Induction is justified. Once we have all hypothesis that satisfy the data represented as a series of 0s and 1s, how can we say that some hypothesis are more likely than others? I understand that some strings have a higher probability of appearing within a certain sets (e.g. 101 is 2x as likely in the set of binaries of length 3 as 1111 is in the set of binaries of length 4) but how can we say that we are more likely to encounter 101 versus 1111 in the set of strings of length n (where n > 4)? Won't both strings occur exactly once? Or is it the case that, let's say, we are deciding between one hypothesis looks like "101" + "either 0 or 1 or nothing" versus 1111. In this case it is clear that the first is more likely than the second, but this would only be valid if 1010 and 1011 both were also valid algorithms, which doesn't seem like it would necessarily be the case. Can someone help me understand this?
comment by smk · 2012-08-09T09:14:33.385Z · LW(p) · GW(p)
In the "Probability" section, you say:
Suppose you start out 85% confident that the one remaining enemy soldier is not a sniper. That leaves only 15% credence to the hypothesis that he is a sniper.
But in the next section, "The Problem of Priors", you say:
In the example above where you're a soldier in combat, I gave you your starting probabilities: 85% confidence that the enemy soldier was a sniper, and 15% confidence he was not.
Seems like you swapped the numbers.
comment by BurntVictory · 2012-07-13T00:00:53.232Z · LW(p) · GW(p)
The idea of reducing hypotheses to bitstrings (ie, programs to be run on a universal Turing machine) actually helped me a lot in understanding something about science that hindisght had previously cheapened for me. Looking back on the founding of quantum mechanics, it's easy to say "right, they should have abandoned their idea of particles existing as point objects with definite position and adopted the concept and language of probability distributions, rather than assuming a particle really exists and is just 'hidden' by the wavefunction." But the scientists of the day had a programming language in their heads where "particle" was a basic object and probability was something complicated that you had to build up--the optimization process of science had arrived at a local maximum in the landscape of possible languages to describe the world.
I realize this is a pretty simple insight, but I'm glad the article gave me a way to better understand this.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2012-07-13T02:06:44.852Z · LW(p) · GW(p)
they should have abandoned their idea of particles existing as point objects with definite position and adopted the concept and language of probability distributions, rather than assuming a particle really exists and is just 'hidden' by the wavefunction
When people describe something with a probability distribution, they normally continue to think that it does have a definite property and they just don't know exactly what it is. To abandon the idea of a particle having a definite position is logically distinct from adopting the use of probability distributions.
Perhaps you mean that they should have adopted the view that the wavefunction is a physical object? That was what Schrodinger and de Broglie wanted. But particles show up at points, not smeared out. It took many decades for someone to think of many worlds coexisting inside a wavefunction.
comment by A1987dM (army1987) · 2012-07-09T09:38:24.779Z · LW(p) · GW(p)
Because it is digital, a neuron either sends the signal, or it doesn't. There is no half-sending the action potential. This can be translated directly into binary. An action potential is a 1, no action potential is a 0. All your sensations, thoughts, and actions can be encoded as a binary sequence over time.
Only if there's discrete timing. If the time elapsed between two 1s can take uncountably many different values...
But the currently proposed laws are incredibly accurate. And they can be represented as a single binary sequence.
Can they? Both QFT and GR are based on real numbers, and the Standard Model has twenty-odd free parameters which are real numbers and hence in principle can require infinitely many bits to be fully specified. (Or do you mean something else by “the currently proposed laws”?)
Replies from: DaFranker, private_messaging↑ comment by DaFranker · 2012-07-09T16:52:16.745Z · LW(p) · GW(p)
Only if there's discrete timing. If the time elapsed between two 1s can take uncountably many different values...
This is also true of modern computers. This time is merely ignored with various hardware tricks to make sure things happen around the time we want them to happen. What it eventually comes down to is the order in which the inputs arrive at each neuron, regardless of how long it took to get there, and the order in which they come out, regardless of how long they take once sent, which in turn decides the order in which other neurons will get their inputs, and so forth.
You could very easily simulate any brain on an infinitely fast UTM by simply having the algorithm take that into account. (Hell, an infinitely fast UTM could simulate everything about the brain, including external stimuli and quantum effects, so it could be made infinitely accurate to the point of being the brain itself)
↑ comment by private_messaging · 2012-07-13T19:37:39.363Z · LW(p) · GW(p)
That's a very good point.
It is where S.I. strays from how we applied Occam's razor.
If you lack knowledge of any discrete behaviour, it seems reasonable to assume that function is continuous, as a more likely hypothesis than it is made of steps of some specific size. The S.I. would produce models that contain specific step size, with highest probability for the shortest representable step size.
edit: how the hell is that 'wrong'?
Replies from: Kawoomba↑ comment by Kawoomba · 2012-07-13T19:54:43.129Z · LW(p) · GW(p)
As long as our best model of the laws of physics includes the concept of Planck time (Planck length), doesn't that mean that time (space) is discrete and that any interval of time (length of space) can be viewed as an integer number of Planck times (Planck lengths)?
Replies from: private_messaging, army1987↑ comment by private_messaging · 2012-07-13T20:16:51.845Z · LW(p) · GW(p)
Doesn't quite work like this so far, maybe there will be some good discrete model but so far the Plank length is not a straightforward discrete unit, not like cell in game of life. More interesting still is why reals have been so useful (and not just reals, but also complex numbers, vectors, tensors, etc. which you can build out of reals but which are algebraic objects in their own right).
Replies from: naasking↑ comment by naasking · 2013-03-08T15:15:15.304Z · LW(p) · GW(p)
maybe there will be some good discrete model but so far the Plank length is not a straightforward discrete unit, not like cell in game of life.
't Hooft has been quite successful in defining QM in terms of discrete cellular automata, taking "successful" to mean that he has reproduced an impressive amount of quantum theory from such a humble foundation.
More interesting still is why reals have been so useful (and not just reals, but also complex numbers, vectors, tensors, etc. which you can build out of reals but which are algebraic objects in their own right).
This is answered quite trivially by simple analogy: second-order logics are more expressive than first-order logics, allowing us to express propositions more succinctly. And so reals and larger numeric abstractions allow some shortcuts that we wouldn't be able to get away with when modelling with less powerful abstractions.
↑ comment by A1987dM (army1987) · 2012-07-13T22:11:23.643Z · LW(p) · GW(p)
We don't have anything remotely like a well-established theory of quantum gravity yet, so we don't know. Anyway, lack of observable frequency dispersion in photons from GRBs suggests space-time is not discrete at the Planck scale.[http://www.nature.com/nature/journal/v462/n7271/edsumm/e091119-06.html]
comment by TruePath · 2012-08-03T12:16:45.174Z · LW(p) · GW(p)
Another concern is that the true hypothesis may be incomputable. There are known definitions of binary sequences which make sense, but which no Turing machine can output. Solomonoff induction would converge to this sequence, but would never predict it exactly.
This statement is simply false. There are a bunch of theorems in machine learning about the class of sequences that an algorithm would converge to predicting (depending on your definition of convergence...is it an algorithm that is eventually right...an algorithm for guessing algorithms that eventually always give the correct answer etc..) but every single one of them is contained in the tiny class of sequences computable in 0'.
To put it another way given any algorithm that guesses at future outputs there is some sequence that simply disagrees with that algorithm at each and every value. Thus any computable process is maximally incorrect on some sequence (indeed is infinitely often wrong on the next n predictions for every n on a dense uncountable set of sequences...say the 1-generics).
However, this is not the end of the story. If you allow your hypothesis to be probabilistic things get much more interesting. However, exactly what it means for induction to 'work' (or converge) in such a case is unclear (you can't get it to settle on a single theory and never revise even if the theory is probabilistic).
comment by [deleted] · 2012-07-10T21:31:12.851Z · LW(p) · GW(p)
Complexity of the map vs Complexity of the territory
Solomonoff induction infers facts about the territory from the properties of the map. That is an ontological argument, and therefore not valid.
Replies from: hankx7787, razorcamDOTcom↑ comment by hankx7787 · 2012-07-12T02:01:01.248Z · LW(p) · GW(p)
...
Replies from: naasking↑ comment by naasking · 2013-03-08T15:03:30.554Z · LW(p) · GW(p)
(simplicity of the map) alone is sufficient to judge a theory- you also need to take into account the theory's parsimony (simplicity of the territory).
Solomonoff Induction gauges a theory's parsimony via Kolmogorov complexity, which is a formalization of Occam's razor. It's not a naive measurement of simplicity.
↑ comment by razorcamDOTcom · 2012-07-10T22:20:23.933Z · LW(p) · GW(p)
Solomonoff's only assumption is that the environment follows some unknown but computable probability distribution. Everything else is a mathematically proven theorem which come from this only assumption, and the traditional axioms and definitions of Math.
So if for you "the map" means "follows some unknown computable probability distribution" then you are right in the sense that if you disagree with this assumption, the theorem is not valid anymore.
But a lot of scientists do make the assumption that there exists at least one useful computable theory and that their job is to find it.
Replies from: None↑ comment by [deleted] · 2012-07-11T04:21:17.512Z · LW(p) · GW(p)
The problem is the "minimum message lenght". This is a property of the map, wich tell us about nothing about the territory.
Well, unless there is a direct connection between message lenght and "unknown but computable probability distribution" ?
Replies from: razorcamDOTcom↑ comment by razorcamDOTcom · 2012-07-11T08:14:54.552Z · LW(p) · GW(p)
Yes, there is a connection between "the length of the shortest program that generates exactly the message coming from the environment" (the Kolmogorov Complexity of this message ) and "unknown but computable probabililty distribution".
"unknown but computable" means there is a program, but we don't know anything about it, including its size. There is an infinite number of possible programs, and an infinite number of lengths of such programs. But we know that the sum of all the probabilities from "the probability distribution" of all programs that could generate the environment must be exactly equal to one, as per Math's definition of probability.
Let me quote Shane Legg about it:
"Over a denumerable (infinite but countable) space you mathematically can’t put a non-zero uniform prior because it will always sum to more than one. Thus, some elements have to have higher prior probability than others. Now if you order these elements according to some complexity measure (any total ordering will do, so the choice of complexity function makes no difference), then the boundedness of the probability sum means that the supremium of the sequence converges to zero. Thus, for very general learning systems, and for any complexity measure you like, you can only violate Occam’s razor locally. Eventually, as things get more complex, their probabilities must decrease.
In summary: if you want to do pure Bayesian learning over very large spaces you must set a prior that globally respects a kind of Occam’s razor. It’s not a matter of belief, it’s a mathematical necessity." http://www.vetta.org/2011/06/treatise-on-universal-induction/comment-page-1/#comment-21408
Replies from: Nonecomment by [deleted] · 2012-07-09T13:14:02.180Z · LW(p) · GW(p)
A good and useful abstraction that is entirely equivalent to Turing machines, and to humans much more useful, is Lambda calculus and Combinator calculi. Many of these systems are known to be Turing complete.
Lambda calculus and other Combinator calculi are rule-sets that rewrite a string of symbols expressed in a formal grammar. Fortunately the symbol-sets in all such grammars are finite and can therefore be expressed in binary. Furthermore, all the Turing complete ones of these calculi have a system of both linked lists and boolean values, so equivalent with the Turing machine model expressed in this article, one can write a programme in a binary combinator calculus and feed it a linked list of boolean values expressed in the combinator calculus itself and then have it reduce itself (return) a linked list of boolean values.
Personally I prefer combinator calculi to Turing machines mainly because they are vastly easier to program.
Related:
Replies from: Alex_Altair, olalonde↑ comment by Alex_Altair · 2012-07-09T16:47:06.904Z · LW(p) · GW(p)
I love lambda calculus! I considered formulating Solomonoff induction in lambda calculus instead, but I'm more familiar with Turing machines and that's what the literature uses so far. (Also Zvonkin and Levin 1970 use partial recursive functions.) It wasn't obvious to me how to alter lambda calculus to have a monotonic input and output, like with the three-tape Turing machine above.
Replies from: None↑ comment by olalonde · 2012-07-09T15:25:38.448Z · LW(p) · GW(p)
To expand on what parent said, pretty much all modern computer languages are equivalent to Turing machines (Turing complete). This includes Javascript, Java, Ruby, PHP, C, etc. If I understand Solomonoff induction properly, testing all possible hypothesis implies generating all possible programs in say Javascript and testing them to see which program's output match our observations. If multiple programs match the output, we should chose the smallest one.
Replies from: Nonecomment by Jayson_Virissimo · 2012-07-09T01:54:58.762Z · LW(p) · GW(p)
The soldier in the probability section updates in the wrong direction. If you survived two shots to your helmet, then you were almost certainly not being shot at with a sniper rifle. For instance, my Mosin Nagant (a bolt-action 7.62x54mmR) will penetrate both sides of a WWII era infantry helmet (and presumably, a "soft target" in between) every single time (although, at a shorter range).
BTW, love the article.
Replies from: Vaniver, Dr_Manhattan, ciphergoth, lukeprog, AlexMennen↑ comment by Dr_Manhattan · 2012-07-09T17:12:31.798Z · LW(p) · GW(p)
Replacing the Nazi soldier pictured with something more modern might solve 2 problems.
Mosin Nagant FTW!
↑ comment by Paul Crowley (ciphergoth) · 2012-07-09T06:59:16.723Z · LW(p) · GW(p)
Could you suggest new wording that fixes the problem? Thanks!
Replies from: Jayson_Virissimo↑ comment by Jayson_Virissimo · 2012-07-09T07:50:49.870Z · LW(p) · GW(p)
Could you suggest new wording that fixes the problem? Thanks!
Vaniver pre-empted me with an elegant solution.
↑ comment by lukeprog · 2012-07-09T02:11:06.001Z · LW(p) · GW(p)
Maybe Alex can clarify the wording there? I meant to indicate that the bullet glanced off the helmet (instead of "bouncing" off), because only a tiny part of the helmet was within the sniper's view.
Replies from: Jayson_Virissimo↑ comment by Jayson_Virissimo · 2012-07-09T07:53:07.940Z · LW(p) · GW(p)
Maybe Alex can clarify the wording there? I meant to indicate that the bullet glanced off the helmet (instead of "bouncing" off), because only a tiny part of the helmet was within the sniper's view.
I like this idea.
Replies from: DaFranker↑ comment by AlexMennen · 2012-07-09T19:40:01.924Z · LW(p) · GW(p)
Also, he apparently updates by a Bayes factor of 8.5 the first time his helmet gets hit, and 33 the second time. I'm not sure how to justify that.
Replies from: DaFrankerSuppose you start out 85% confident that the one remaining enemy soldier is not a sniper. That leaves only 15% credence to the hypothesis that he is a sniper. But then, a bullet glances off your helmet — an event far more likely if the enemy soldier is a sniper than if he is not. So now you’re only 40% confident he’s a non-sniper, and 60% confident he is a sniper. Another bullet glances off your helmet, and you update again. Now you’re only 2% confident he’s a non-sniper, and 98% confident he is a sniper.
↑ comment by DaFranker · 2012-07-10T19:22:26.624Z · LW(p) · GW(p)
I'm fairly certain that that's because of an approximation of the coincidence factor. After the first shot, which was totally individual and specifically aimed at the helmet, the odds of it being a sniper suddenly shoot right up, but there's still the odds of a coincidence. Once it happens twice, you end up multiplying the odds of a coincidence and they become ridiculously low.
The thing isn't that evidence (bullet hits helmet at X distance) is applied twice, but that the second piece of evidence is actually (hit a helmet at X distance twice in a row), which is radically more unlikely if non-sniper, and radically more likely if sniper. The probabilities within the evidence and priors end up multiplying somewhere, which is how you arrive at the conclusion that it's 98% likely that the remaining enemy is a sniper.
Of course, I'm only myself trying to rationalize and guess at the OP's intent. I could also very well be wrong in my understanding of how this is supposed to work.
Replies from: AlexMennen↑ comment by AlexMennen · 2012-07-10T19:32:55.574Z · LW(p) · GW(p)
That doesn't work. If the probability of a regular soldier being able to hit the helmet once is p, then conditional on him hitting the helmet the first time, the probability that he can hit it again is still p. Your argument is the Gambler's fallacy.
Replies from: DaFranker, thomblake↑ comment by DaFranker · 2012-07-10T19:45:06.575Z · LW(p) · GW(p)
(Offtopic: Whoa, what's with the instant downvote? That was a valid point he was making IMO.)
While it is indeed the Gambler's fallacy to believe it to be less than p-likely that he hits me on the second try, I was initially .85 confident that he was non-sniper, which went to .4 as soon as the helmet was hit once. If that was a non-sniper, there was p chances that he hit me, but if it was a sniper, there was s chances that he did.
Once the helmet is hit twice, there is now p^2 odds of this same exact event (helmet-hit-twice) happening, even if the second shot was only p-likely to occur regardless of the result of the first shot. By comparison, the odds that s^2 happens are not nearly as low, which makes the difference between the two possible events greater than the difference between the two possibilities when (helmet-hit-once), hence the greater update in beliefs.
Again, I'm just trying to rationalize on the assumption that the OP intended this to be accurate. There might well be something the author didn't mention, or it could just be a rough approximation and no actual math/bayesian reasoning went into formulating the example, which in my opinion would be fairly excusable considering the usefulness of this article already.
Replies from: AlexMennen↑ comment by AlexMennen · 2012-07-10T19:50:58.577Z · LW(p) · GW(p)
If you update by a ratio s/p for one hit on the helmet, you should update by s^2/p^2 for two hits, which looks just like updating by s/p twice, since updating is just like multiplying by the Bayes factor.
Replies from: DaFranker↑ comment by DaFranker · 2012-07-10T19:56:16.533Z · LW(p) · GW(p)
Hmm. I'll have to learn a bit more about the actual theory and math behind Bayes' theorem before I can really go deeper than this in my analysis without spouting out stuff that I don't even know if it's true. My intuitive understanding is that there's a mathematical process that would perfectly explain the discrepancy with minimal unnecessary assumptions, but that's just intuition.
For now, I'll simply update my beliefs according to the evidence you're giving me / confidence that you're right vs confidence (or lack thereof) in my own understanding of the situation.
↑ comment by thomblake · 2012-07-10T19:49:38.392Z · LW(p) · GW(p)
The interesting bit is that the helmet was hit twice, so we're looking at the probability of being shot twice, not the probability of being shot the second time conditional on being shot the first time.
Replies from: AlexMennen↑ comment by AlexMennen · 2012-07-10T19:55:42.535Z · LW(p) · GW(p)
In retrospect, my first attempt at explanation was fairly poor. Is this clearer?
Edit: To more specifically address your objection: P(hit twice) = P(hit 1st time) * P(hit 2nd time | hit 1st time) = P(hit)^2.
Replies from: thomblakecomment by johnswentworth · 2012-07-09T01:54:55.184Z · LW(p) · GW(p)
Does anyone know if the probabilities output by Solomonoff Induction have been proven to converge? There could be as many as O(2^n) hypotheses of length n, each of which get a probability proportional to 2^-n. Once you sum that over all n, it doesn't converge, therefore the probability can't be normalized unless there's some other constraint on the number of hypotheses of length n consistent with the data. Does anyone know of such a constraint?
Replies from: Peter_de_Blanc, Alex_Altair↑ comment by Peter_de_Blanc · 2012-07-09T02:46:53.210Z · LW(p) · GW(p)
No hypothesis is a prefix of another hypothesis.
↑ comment by Alex_Altair · 2012-07-09T04:08:24.064Z · LW(p) · GW(p)
Peter is right. It's a detail you can find in Universal Artificial Intelligence.
comment by [deleted] · 2024-08-05T02:32:04.517Z · LW(p) · GW(p)
In a sense, binary is the simplest possible alphabet. A two-character alphabet is the smallest alphabet that can communicate a difference. If we had an alphabet of just one character, our “sentences” would be uniform. With two, we can begin to encode information.
This is technically false. Any finite binary sequence can be converted to or from a finite unary sequence. For example, 110 ↔ 111111.
(If your binary format allows sequences to start with 0s, 0 ↔ 1 and 110 ↔ 1111111 (7 instead of 6 1s) and 0000 ↔ 111111111 (9 1s))
comment by jabowery · 2023-02-28T02:47:52.514Z · LW(p) · GW(p)
Marcus Hutter provides a full formal approximation of Solomonoff induction which he calls AIXI-tl.
This is incorrect. AIXI is a Sequential Decision Theoretic AGI whose predictions are provided by Solomonoff Induction. AIXI-tl is an approximation of AIXI in which Solomonoff Induction's predictions are approximate but also in which Sequential Decision Theory's decision procedure is approximate.
comment by Tim Liptrot (rockthecasbah) · 2021-05-07T01:28:25.121Z · LW(p) · GW(p)
Great! Now redo it with equations included ;)
comment by Zaq · 2015-10-22T23:13:25.540Z · LW(p) · GW(p)
"Specifically, going between two universal machines cannot increase the hypothesis length any more than the length of the compiler from one machine to the other. This length is fixed, independent of the hypothesis, so the more data you use, the less this difference matters."
This doesn't completely resolve my concern here, as there are infinitely many possible Turing machines. If you pick one and I'm free to pick any other, is there a bound on the length of the compiler? If not, then I don't see how the compiler length placing a bound on any specific change in Turing machine makes the problem of which machine to use irrelevant.
To be clear: I am aware that starting with different machines, the process of updating on shared observations will eventually lead us to similar distributions even if we started with wildly different priors. My concern is that if "wildly different" is unbounded then "eventually" might also be unbounded even for a fixed value of "similar." If this does indeed happen, then it's not clear to me how S I does anything more useful than "Pick your favorite normalized distribution without any 0s or 1s and then update via Bayes."
Edit: Also thanks for the intro. It's a lot more accessible than anything else I've encountered on the topic.
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2017-05-31T14:00:39.224Z · LW(p) · GW(p)
can anyone answer these concerns?
Replies from: jabowery↑ comment by jabowery · 2023-02-28T03:01:37.312Z · LW(p) · GW(p)
This seems to be a red-herring issue. There are clear differences in description complexity of Turing machines so the issue seems merely to require a closure argument of some sort in order to decide which is simplest:
Decide on the Turing machine has the shortest program that simulates that Turing machine while running on that Turing machine.
comment by G0W51 · 2015-02-19T15:43:34.433Z · LW(p) · GW(p)
I'm concerned about how Solomonoff induction accounts for how many "steps into" a program the universe is. A program only encoding the laws of physics and the initial state of the universe would fail, because the universe has been running for a very long time. One could get around this by having the program simulate the entire beginning of the universe by looping through an execution of the laws of physics many many times before outputting anything, but this seems to have some unintuitive consequences. Since it would take bits to specify the length of the loop, shorter loops would result in shorter programs, and thus beliefs that the universe is younger would be considered more probable than beliefs that the universe is older. Additionally, though I'm not sure about this, perhaps the algorithm would believe the universe is more likely to be, say, 5 10^50 steps old that 4.49345820893410^50 steps old, simply because the latter can be written more compactly. That doesn't seem quite right...
comment by Rubix · 2014-02-27T01:33:13.291Z · LW(p) · GW(p)
"In the example above where you're a soldier in combat, I gave you your starting probabilities: 85% confidence that the enemy soldier was a sniper, and 15% confidence he was not. But what if you don't know your "priors"? What then?"
The starting priors seem to be reversed here.
comment by vallinder · 2012-07-12T09:34:46.932Z · LW(p) · GW(p)
Among all hypotheses consistent with the observations, the simplest is the most likely.
I think this statement of Occam's razor is slightly misleading. The principle says that you should prefer the simplest hypothesis, but doesn't say why. As seen in the SEP entry on simplicity, there have been several different proposed justifications.
Also, if I understand Solomonoff induction correctly, the reason for preferring simpler hypotheses is not that such theories are a priori more likely to be true, but rather that using Solomonoff's universal prior means that there will be a finite bound on the number of prediction errors you make over an infinite string.
Assuming that simpler hypotheses are more likely to be true looks like wishful thinking. But the fact that the number of prediction errors will be bounded seems like a good justification of Occam's razor.
comment by MyrddinE · 2012-07-11T21:21:27.139Z · LW(p) · GW(p)
I am a bit confused... how do you reconcile SI with Gödel's incomleteness theorum. Any rigid symbolic system (such as one that defines the world in binary) will invariably have truths that cannot be proven within the system. Am I misunderstanding something?
Replies from: Eliezer_Yudkowsky, shokwave↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-07-12T20:37:31.535Z · LW(p) · GW(p)
There are things Solomonoff Induction can't understand which Solomonoff Induction Plus One can comprehend, but these things are not computable. In particular, if you have an agent with a hypercomputer that uses Solomoff Induction, no Solomonoff Inductor will be able to simulate the hypercomputer. AIXI is outside AIXI's model space. You need a hypercomputer plus one to comprehend the halting behavior of hypercomputers.
But a Solomonoff Inductor can predict the behavior of a hypercomputer at least well as you can, because you're computable, and so you're inside the Solomonoff Inductor. Literally. It's got an exact copy of you in there.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-14T12:35:35.076Z · LW(p) · GW(p)
It seems easy to imagine a hypercomputation capable universe where computable beings evolve, ponder the laws of physics, and form an uncomputable theory of everything which they can't use predictively in general case but which they can use to design a hypercomputer. S.I. might be able to do this but it is not obvious how (edit: i.e. even though AIXI includes those computable beings with their theory, they aren't really capable of replicating existing data with their theory, and so are not part of S.I. sum, and so even though they can do better - by building a hypercomputer - AIXI won't use them)
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-07-14T23:36:42.625Z · LW(p) · GW(p)
It's obvious to me; an S.I. user does it the same way the computable beings do.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-15T08:51:29.199Z · LW(p) · GW(p)
The issue is that besides the computable beings S.I. includes a lot of crud that is predicting past observations without containing a 'compiler' for some concept of 'hey, the universe might be doing something uncomputable here, we better come up with an intricate experiment to test this because having a hypercomputer will be awesome'. The shorter crud influences actions the most. edit: also it is unclear how well can AIXI seek experimentation. We do experiments because we guess that with more knowledge we'll have more power. It's like self improvement, it requires some reflective thinking. For AIXI its like seeking futures where the predictor works bad.
Easier example: We can make a theory containing true real numbers, without penalizing theory for the code for discretization and for construction of a code that recreates past observations. We can assign some vague 'simplicity' values to theories that are not computable, namely a theory with true reals is simpler than discretization of this theory with a made-up discretization constant. We don't rate the theories by size of their implementation by applied mathematicians. S.I. does rate by size of discrete, computable implementation. It's no help if S.I. will contain somewhere neatly separable compiler plus our theory, if the weight for this is small.
↑ comment by shokwave · 2012-07-11T21:41:59.669Z · LW(p) · GW(p)
The post covers that, though not by that name:
And even more problematic, some of the algorithms will run forever without producing output—and we can't prove they will never stop running. This is known as the halting problem, and it is a deep fact of the theory of computation.
When Solomonoff induction runs into a halting problem it may well run forever. This is a part of why it's uncomputable. Uncomputable is a pretty good synonym for unprovable, in this case.
comment by kilobug · 2012-07-09T09:45:05.059Z · LW(p) · GW(p)
Great article (at least the beginning, didn't finish it yet, will do so later on).
There is one thing which unsettles me : « Bayes’ Theorem can tell us how likely a hypothesis is, given evidence (or data, or observations). » Well, no, Bayes' Theorem will only tell you how more or less likely a hypothesis is. It requires the prior to give a "full" probability. It's said a bit later on that the "prior" is required, but not just after, so I fear the sentence may confuse people who don't actually know well enough Bayes.
IMHO it would be less confusing to alter the sentence to ensure it makes clear that the prior is required (or that Bayes' theorem makes updates on the probability, but doesn't tell it).
Replies from: private_messaging↑ comment by private_messaging · 2012-07-13T08:30:49.659Z · LW(p) · GW(p)
It's especially confusing when the other use that you have for probability of evidence given hypothesis is not mentioned.
Suppose you have a non-sniper test which has 10% probability of returning nonsniper if enemy is a sniper, and near-certainty of returning nonsniper if enemy is not a sniper. Lacking a prior, you may not know how likely it is that it is a sniper, but you know that executing a program do the test 3 times then run if all indicate non-sniper has expected risk of running out into sniper of 0.1% or less if the tests are statistically independent. This is very useful when determining advance policies such as the testing required for some airplane hardware component, or for a drug. Or when designing an AI for a computer game, and in many other competitive situations.
comment by [deleted] · 2015-03-13T11:32:28.129Z · LW(p) · GW(p)
I would like to point out a minor error here. Above stated "The position of all the subatomic particles that make up your daughter as she lives her entire life can be represented as a sequence of binary. And that really is your daughter." is of course not true.
You may get a perfect representation of your daughter, INSIDE CONTEXT*, but a representation is obviously not the object being represented. If it were it wouldn´t be a REPRESENTATION in the first place.
*0´s and 1´s are just zeroes and ones unless you interpret them, and in order to interpret, you need a context.
comment by jockocampbell · 2013-11-20T20:03:27.800Z · LW(p) · GW(p)
What a wonderful post!
I find it intellectually exhilarating as I have not been introduced to Solomonoff before and his work may be very informative for my studies. I have come at inference from quite a different direction and I am hopeful that an appreciation of Solomonoff will broaden my scope.
One thing that puzzles me is the assertion that:
Therefore an algorithm that is one bit longer is half as likely to be the true algorithm. Notice that this intuitively fits Occam's razor; a hypothesis that is 8 bits long is much more likely than a hypothesis that is 34 bits long. Why bother with extra bits? We’d need evidence to show that they were necessary.
First my understanding of the principle of maximum entropy suggests that prior probabilities are constrained only by evidence and not by the length of the hypothesis test algorithm. In fact Jaynes argues that 'Ockham's' razor is already built into Bayesian inference.
Second given that the probability is reduced by half with every bit of added algorithm length wouldn't that imply that algorithms' having 1 bit were the most likely and have a probability of 1/2. In fact I doubt if any algorithm at all is describable with 1 bit. Some comments as well as the body of the article suggest that the real accomplishment of Solomonoff's approach is to provide the set of all possible algorithms/hypothesis and that the probabilities assigned to each are not part of a probability distribution but rather are for the purposes of ranking. Why do they need to be ranked? Why not assign them all probability 1/N where N = 2^(n+1) - 2, the number of algorithms having length up to and including length n.
Clearly I am missing something important.
Could it be that ranking them by length is for the purpose of determining the sequence in which the possible hypothesis should be evaluated? When ranking hypothesis by length and then evaluating them against the evidence in sequence from shorter to longer our search will stop at the shortest possible algorithm, which by Occam's razor is the preferred algorithm.
Replies from: V_V↑ comment by V_V · 2013-11-20T21:35:15.274Z · LW(p) · GW(p)
Second given that the probability is reduced by half with every bit of added algorithm length wouldn't that imply that algorithms' having 1 bit were the most likely and have a probability of 1/2. In fact I doubt if any algorithm at all is describable with 1 bit.
Keep in mind that the Solomonoff induction is defined up to the choice of a prefix-free universal Turing machine. There exist some of these UTMs that can represent a valid program with 1 bit, but this isn't particularly relevant:
Each UTM leads to a different Solomonoff prior. Solomonoff induction is universal only in an asymptotic sense: as you accumulate more and more bits of evidence, the posterior distributions converge with high probability.
Probability estimates dominated by short programs are biased by the choice of the UTM. As more evidence accumulates, the likelihood of a short program being consistent with all of it decreases (intuitively, by the pigeonhole principle), and the probability estimate will be dominated by longer and longer programs, "washing out" the initial bias.
Why do they need to be ranked? Why not assign them all probability 1/N where N = 2^(n+1) - 2, the number of algorithms having length up to and including length n.
In order to normalize properly, you have to divide the raw Solomonoff measure by the Chaitin's omega of that particular UTM, that is, the probability that a randomly generated program halts.
comment by myron_tho · 2012-10-14T07:17:41.709Z · LW(p) · GW(p)
I'm interested to know how this methodology is supposed to diverge from existing methods of science in any useful way. We've had a hypothesis-driven science since (at least) Popper and this particular approach seems to offer no practical alternative; at best we're substituting one preferred type of non-empirical criteria for selection (in this case, a presumed ability to calculate he metaprobabilities that we'd have to assume for establishing likelihoods of given hypotheses, a matter which is itself controversial) for the currently-existing criteria, along the lines of elegance, simplicity, and related aesthetic criteria which currently encompass inference to the best explanation.
With regards to the above metaprobabilities, how are we to justify these assumptions with regards to epistemic uncertainty? Popper and Hume have already shown us that, for all intents and purposes, we can't justify induction and Solomonoff is no realizable way around that. I don't see how substituting one mode of inference, based on a set of assumptions that are given no justification whatsoever, provides a superior or even a reasonably-supportable alternative to current methods of science.
This is undoubtedly a useful heuristic for establishing confirmation of what has been observed, but then again so is the research structure we already possess; to claim that such an unsupported and unjustified methodology as outlined in this article is in any way establishing "truth" above and beyond current methods of confirming hypotheses is to overstate the case to such a degree that it cannot be taken seriously.
comment by Houshalter · 2012-08-22T03:43:15.597Z · LW(p) · GW(p)
Where would I go to learn more about this? I'm really interested, but I don't even know where to begin here.
comment by aelephant · 2012-07-14T23:49:57.186Z · LW(p) · GW(p)
And even more problematic, some of the algorithms will run forever without producing output—and we can't prove they will never stop running.
Maybe it is just my reading, but these 2 sentences seem to contradict each other. You say the algorithms "will run forever" but then you say that you can't prove that they will never stop running forever. Doesn't "never stop running forever" equal "will run forever"? If you don't know that they will never stop running forever, how can you say that they will run forever?
Replies from: None↑ comment by [deleted] · 2012-07-15T00:05:52.893Z · LW(p) · GW(p)
Some algorithms run forever, some do not, and we do not have any way to prove that an algorithm is in the first set and not the latter, that was my interpretation at least.
Replies from: aelephantcomment by Mark_Lu · 2012-07-11T12:20:02.525Z · LW(p) · GW(p)
Okay, I have a "stupid" question. Why is the longer binary sequence that represents the hypothesis less likely to be 'true' data generator? I read the part below but I don't get the example, can someone explain in a different way?
Replies from: Viliam_BurWe have a list, but we're trying to come up with a probability, not just a list of possible explanations. So how do we decide what the probability is of each of these hypotheses? Imagine that the true algorithm is produced in a most unbiased way: by flipping a coin. For each bit of the hypothesis, we flip a coin. Heads will be 0, and tails will be 1. In the example above, 01001101, the coin landed heads, tails, heads, heads, tails, and so on. Because each flip of the coin has a 50% probability, each bit contributes ½ to the final probability.
Therefore an algorithm that is one bit longer is half as likely to be the true algorithm. Notice that this intuitively fits Occam's razor; a hypothesis that is 8 bits long is much more likely than a hypothesis that is 34 bits long. Why bother with extra bits? We’d need evidence to show that they were necessary.
↑ comment by Viliam_Bur · 2012-07-12T12:18:57.744Z · LW(p) · GW(p)
This is a completely different explanation, and I am not sure about its correctness. But it may help your intuition.
Imagine that you randomly generate programs in a standard computer language. And -- contrary to the S.I. assumption -- let's say that all those programs have the same length N.
Let's try a few examples. For simplicity, let's suppose that the input is in variable x, and the programming language has only two commands: "x++" (increases x by one) and "return x" (returns the current value of x as a result). There are four possible programs:
x++;
x++;
x++;
return x;
return x;
x++;
return x;
return x;
The first program does not return a value. Let's say that it is not a valid program, and remove it from the pool. The second program returns the value "x+1". The third and fourth programs both return the value "x", because both are equivalent to one-line program "return x".
It seems that the shorter programs have an advantage, because a longer program can give the same results as the shorter program. More precisely, for every short program, there are infinitely many equivalent longer programs; as you increase the maximum allowed length N, you increase their numbers exponentially (though not necessarily 2^x exponentially; this is just a result of our example language having 2 instructions). This is why in this example the one-line program won the competition, even if it wasn't allowed to participate.
OK, this is not a proof, just an intuition. Seems to me that even if you use something else instead of S.I., the S.I. may appear spontaneously anyway; so it is a "natural" distribution. (Similarly, the Gauss curve is a natural distribution for adding independent random variables. If you don't like it, just choose a different curve F(x), and then calculate what happens if you add together thousand or million random numbers selected by F(x)... the result will be more and more similar to the Gauss curve.)
Replies from: private_messaging↑ comment by private_messaging · 2012-07-12T18:20:07.330Z · LW(p) · GW(p)
The algorithmic probability of a string is the probability that the binary sequence will be obtained when you feed infinite string of random digits on input tape to universal prefix Turing machine (look up prefix Turing machine for more info).
The sum weighted by powers of two is simply the alternative way of writing it down as the probability of obtaining specific prefix of length l via coin flips is 2^-l , in the model whereby you split the string into some 'prefix' that is executed as program, and the 'data'. This division is pretty arbitrary as the prefix may be an interpreter.
AFAIK, Solomonoff induction can be specified in such way: probability of seeing 1 after [string] is algorithmic probability ( [ string ] 1 ) / algorithmic_probability ( [ string ] )
Further reading: papers by Marcus Hutter.
edit: i've always said that markdown is for people who use italics more than algebra.
edit2: and if its not clear from the post, the programs are self delimiting; this is what specifies the end of program. Prefix turing machine does not have special 'stop' marker. The end of program is largely in the eye of the beholder; you can make a prefix that would proceed to read the input tape and output the digits from input tape; you can view it as a short program, or you can view it as a set of of infinitely long programs.
comment by [deleted] · 2012-07-11T08:53:16.615Z · LW(p) · GW(p)
I will try to prove that solomonoff induction leads to solipsism:
The most simple explanation for everything is solipsism: Only my mind exists, nothing else. All experiences of an outside world are dream-like illusions. The world is very, very much more complex than my mind. Therefore, according to solomonoffs lightsaber, the prior for Solipsism = 1-epsilon No reasonable amount of evidence can counter a prior that is that extreme.
Therefore, if solomoff induction is true, then solipsism is true.
Replies from: private_messaging, shokwave, scav, None, Incorrect↑ comment by private_messaging · 2012-07-11T10:35:59.411Z · LW(p) · GW(p)
A point I've been trying to make here, to no avail, is that S.I. is about finding predictors not explainers (codes that output string beginning with the data not codes outputting the string containing the data). "Solipsism" isn't really a predictor of anything, and neither are other philosophical stances, nor are some parts of some physical theories by themselves with omission of some other parts of those theories.
↑ comment by shokwave · 2012-07-11T10:33:45.440Z · LW(p) · GW(p)
All experiences of an outside world are dream-like illusions
It's a very convoluted Turing machine that produces dream-like illusions in such an incredibly consistent, regular manner!
Replies from: None↑ comment by [deleted] · 2012-07-12T07:03:50.787Z · LW(p) · GW(p)
That is a valid point against solipsism.
Don't get me wrong. I do indeed believe that there is strong evidence against solipsism. All i am saying is that it is not enough to counter the massive, massive headstart that S.I. gives to solipsism.
Replies from: Viliam_Bur↑ comment by Viliam_Bur · 2012-07-12T11:56:22.534Z · LW(p) · GW(p)
I think that "complex things happening in the real world" and "complex things happening in my head" have similar lengths of description. And "my head" probably just increases the description.
↑ comment by scav · 2012-07-13T11:31:49.026Z · LW(p) · GW(p)
With "your mind" undefined, solipsism is meaningless.
If only "your mind" exists and nothing else, then "your mind" (whatever it is) is the universe. How this differs from any other kind of universe, part of which can arbitrarily be labelled "you" and another part "me" escapes me. But feel free to disregard my opinion if you think I don't really exist :)
↑ comment by [deleted] · 2012-07-11T10:05:45.988Z · LW(p) · GW(p)
dream-like illusion
What does this mean? You make it seem like this is a mathematically simple object, but I think it is an instance of "the lady down the street is a witch."
If you want to convince me, please dissolve it, along with "outside world," "existing," and "experience." Before you do that I will hold my better-functioning Tegmark 4 cosmological considerations in much higher regard than mere useless radical scepticism.
Replies from: None↑ comment by [deleted] · 2012-07-12T06:44:13.208Z · LW(p) · GW(p)
My argument is not that that mental states/experiences/whatever are simple. The argument is: However complicated mental experiences might be, the following is true:
My mind is less complex than (my mind + the rest of the universe)
Even more so if i consider that the universerse entails a lot of minds that are as complex as my own.
By the way, i am not trying to prove solipsism, but to disprove solomonoff induction by reductio ad absurdum.
Replies from: None, Strange7, private_messaging↑ comment by [deleted] · 2012-07-12T13:04:00.369Z · LW(p) · GW(p)
You, my good sir, need to improve your intuitions on Kolmogorov Complexity.
The reason I am asking you the above questions, asking if you in fact know how to dissolve the concepts of "existence," "dream like illusion," "outside world," "experience" and similar words, because I think almost all people who even have a concept of solipsism are not actually referring to a well-formed mathematical entity.
I have given extensive thought along with three other strong bayesians about related concepts and we have actually gotten somewhere interesting on dissolving the above phrases, alas the message-length is nontrivial.
So all in all, trying to disprove Solomonof Induction cannot be done because Solipsism isn't a well-formed mathematical entity, whereas the Induction is.
Additionally, the universe is simpler than your mind. Because it unfolds form mathematically simple statements into a very large thing. It is like a 1000000px by 1000000px picture of the Mandelbrot fractal, the computer programme that creates it is significantly smaller than the image itself. A portrait of a man taken with a high-definition camera has no similar compression. Even though the fractal is vastly larger, it's complexity is vastly smaller.
And this is where you first and foremost go astray in your simple arhgument: (My Mind) < (My Mind + Universe). Firstly because your mind is part of the Universe, so Universe + My Mind = Universe, and also because the universe consists of little more than the Schroedinger equation and some particle fields, but your mind consists either of the Universe + Appropriate Spatial Coordinate, or all the atom positions in your brain, or a long piece of AI-like code.
↑ comment by Strange7 · 2012-07-12T09:09:10.981Z · LW(p) · GW(p)
Which would be more complex:
1) a Turing-computable set of physical laws and initial conditions that, run to completion, would produce a description of something uncannily similar to the universe as we know it, or
2) a Turing-computable set of physical laws and initial conditions that, run to completion, would produce a description of something uncannily similar to the universe as we know it, and then uniquely identify your brain within that description?
A program which produced a model of your mind but not of the rest of the universe would probably be even more complicated, since any and all knowledge of that universe encoded within your mind would need to be included with the initial program rather than emerging naturally.
Replies from: private_messaging↑ comment by private_messaging · 2012-07-12T09:27:35.543Z · LW(p) · GW(p)
Well, if the data is description of your mind then the code should produce a string that begins with description of your mind, somehow. Pulling the universe out will require examining the code's internals.
If you do S.I. in a fuzzy manner there can be all sorts of self-misconceptions; it can be easier (shorter coding) to extract an incredibly important mind, therefore you obtain not solipsism but narcissism. The prior for self importance may then be quite huge.
If you drop requirement that output string begins with description of the mind and search for the data anywhere within the output string, then a simple counter will suffice as valid code.
↑ comment by private_messaging · 2012-07-12T07:34:21.080Z · LW(p) · GW(p)
Take a very huge prime. It is less complex than the list of all primes, you would say. The shortest code to generate such prime may be the correct prime finding program that prints Nth prime (it stores the N of which prime to print), if the prime is big enough.
↑ comment by Incorrect · 2012-07-11T09:13:37.131Z · LW(p) · GW(p)
The world is very, very much more complex than my mind.
But the smallest description of your mind might implicitly describe the universe. Anyway, Solomonoff induction is about predictions, it doesn't concern itself with untestable statements like solipsism.
Solomonoff induction isn't true/false. It can be useful/not useful but not true/false.
comment by taw · 2012-07-09T11:49:03.152Z · LW(p) · GW(p)
... and then it becomes incomputable in both theory perfectly (even given unbounded resources) and in practice via any kind of realistic approximation.
It's a dead end. The only interesting thing about it is realizing why precisely it is a dead end.
Replies from: abe-dillon↑ comment by Abe Dillon (abe-dillon) · 2019-08-09T01:39:01.549Z · LW(p) · GW(p)
This is a pretty lame attitude towards mathematics. If William Rowan Hamilton showed you his discovery of quaternions, you'd probably scoff and say "yeah, but what can that do for ME?".
Occam's razor has been a guiding principal for science for centuries without having any proof for why it's a good policy, Now Solomonoff comes along and provides a proof and you're unimpressed. Great.
Replies from: TAG↑ comment by TAG · 2019-08-09T04:20:17.898Z · LW(p) · GW(p)
SI is so bad, it doesn't even prove the one thing people say it proves.
Edit:
The S.I is a inept tool for measuring the relative complexity of CI and MWI because it is a bad match for both. It's a bad match for MWI because of the linear, or., if you prfer sequential, nature of the output tape, and its a bad match for CI because its deterministic and CI isn't. You can simulate collapse with a PRNG, but it won't give you the right random numbers. Also, CI'ers think collapse is a fundamental process, so it loads the dice to represent it with a multi-step PRNG. It should be just a call to one RAND instruction to represent their views fairly.
comment by marcusmorgan · 2012-07-22T01:18:49.601Z · LW(p) · GW(p)
Some ideas about Solomonoff that might be of use: he is trying to raise induction from given deductive bases into somehow being "forwardly deductive" rather than inductive. No doubt we can refine our bases for inductive hypotheses to make them as deductively strict as possible, but ultimately if they are too deductively strict we leave no room for induction and would merely be proposing a continuation of the status quo as a process leading inevitably, deductively, somewhere.
Induction is a process from supposed real facts to hypothesized real facts, and when the hypothesized real facts eventually arise, we deduce the accuracy of our hypothesis about them. We can hypothesize backwards about the bases for the supposed real facts, to open issues about their supposed reliability as the basis for a future hypothesis, and use deduction to check again and decide again their reliability as facts, but we should have already done that before relying on them for the future hypothesis.
Hypotheses are not limited to the future, and we can hypthesize about the basis for anything to open up argument, and use deduction to be satisfied we are secure. What Solominoff is doing is identifying some important factors to deductively refine our induction when hypothesizing backwards or forwards. My concern is that creativity in working real facts into inductive hypotheses in reality can be guided by deductive refinements, but only broadly. The entire point of induction is to open up, and deduction is to close down, so I would not get too excited about Solominoff's attempt at limiting induction to some kind of deductive certainty. All he is doing is building deductive refinements into his inductive methods.
I agree that the status quo may be a process leading inevitably statistically somewhere, and that we can try to use past deduced bases for the status quo to inductively predict its future. That is nice and secure, and perhaps a little like dominoes falling in line. In reality, data is more complicated, and interpreting it using induction (refined by deduction) is more creative. I will read Solominoff's gudelines again, but I assume they are a product of his consideration of all the fundamental logical and practical issues that need consideration for greatest certainty, and if so, useful. However, I like looking at nature around me to see the factual complexity that needs reconciliation by hypotheses, and work on that rather than dredging too much through the basic formalisms, Facts rule at the end of the day.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2012-07-25T03:35:41.532Z · LW(p) · GW(p)
The entire point of induction is to open up, and deduction is to close down, so I would not get too excited about Solominoff's attempt at limiting induction to some kind of deductive certainty.
This seems wrong, see Lawful intelligence, Free will.
Replies from: D_Malik, marcusmorgan↑ comment by D_Malik · 2012-08-05T01:22:55.182Z · LW(p) · GW(p)
The first part of the quote (before "so") seems right - induction generates hypotheses, and deduction destroys them (for loose definitions of in/deduction). One way to see Solomonoff induction is that we first "open up" as far as possible, by generating all possible hypotheses, and then use deduction to "close down", by throwing away all the invalid hypotheses.
↑ comment by marcusmorgan · 2012-07-25T03:39:20.932Z · LW(p) · GW(p)
Could you possibly provide a simple reason why it is wrong, to let me know what to look for if I go to your links? It is fine if you have no time to provide a simple reason, rather than "this seems wrong", but I would much prefer any reason at all or any reasoning at all. Just a short sentence would be fine to address your key point. Otherwise it appears disrespectful, like "back to the drawing board, lad" without any reason whatesoever. I am happy to argue my post above, which explains very clearly the meaning of the quote you chose. but I cannot go chasing rabbits of a decription I do not know, were I to chase rabbits. See this as a challenge Vladimir, in response to what seems a lazy reply.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2012-07-25T03:55:14.556Z · LW(p) · GW(p)
Induction, creativity or any other aspect of intelligence can run on a completely deterministic computation, and in a certain sense require determinism/structure to be expressed. The aspect of intelligence and choice that feels like it requires arbitrariness or uncertainty results from logical uncertainty, from not knowing some of the facts implied by what you already know, including the facts you yourself determine.
Replies from: marcusmorgan↑ comment by marcusmorgan · 2012-07-25T04:15:27.788Z · LW(p) · GW(p)
I agree that nature might even be entirely deterministic, but only statistically in particle & field behaviour, and ways poorly understood in biology, but that is not the point. It is obvious that we are resoning to a deductive conclusion because we hope that the solution, if there is one (a Unified Theory for example) explains a self-consistent state and our path to discovering it. The entire point is that in the practical journey to this hopeful order we use inductive creativity that is as open as we need to gather and refine into a stricter theory. I think you have set up a straw man argument against me, and your answer does not seem to relate directly to the quote you provided, which is consistent with the above. It is clearly foolish to assume in advance of deductive confirmation that we will get it, which is why we open up to be creative. We frequently revisit the deduced bases for our induction by induction and further deuction to refine them as the process works both ends.
As to the side issue you seem to raise in support of the claim that I "seem wrong", namely the appearance of choices when in fact we might be better off deductively guided to the best option, that is a non-argument. If we had that deductive guidance we wouldn't be in a process of reasoning about options to begin with. No matter which way you look at it, we are free to create when we have no clear deductive solution, and that's what we do when we use what you seem to call "Free Will" (a much broader issue that your identified point). Logical uncertainty is our reality until satisfied with reasoning to something more secure, as fact rule at the end of the day and we are nowhere near reconciling them across all sciences. Perhaps you should read my book, its free at my website http://www.theumandesign.net and deals with these issues. I see a lot of rigidity in your approach, perhaps leading to a misunderstanding of what is really going on when we discover things.
Replies from: marcusmorgan↑ comment by marcusmorgan · 2012-07-25T05:48:42.607Z · LW(p) · GW(p)
Vladimir, are you at liberty to confirm whether you have provided any of my various posts today with negative votes, and how many? I await your detailed reply to the basic issues I have outlined above in any event, but I read somewhere that it is common for unexplained negativity from others to be explained when asked. What is your explanation, if any?
Replies from: hairyfigment, wedrifid, DaFranker, Eliezer_Yudkowsky↑ comment by hairyfigment · 2012-07-25T20:32:28.663Z · LW(p) · GW(p)
I downvoted you because you keep plugging your book, and your comments suggest I'd gain nothing by reading it. Also you don't seem to have engaged with the reasons for that impression, though people have tried to point some of them out. Perhaps you should start by assuming that you have no clue what we believe, and keep that in mind as you read the links someone gave you.
↑ comment by wedrifid · 2012-07-25T12:24:40.295Z · LW(p) · GW(p)
Vladimir, are you at liberty to confirm whether you have provided any of my various posts today with negative votes, and how many?
Your challenge here prompted me to downvote each of them myself, after a brief confirmation. The multiple advertisements for your "book" also don't help.
I await your detailed reply to the basic issues I have outlined above in any event, but I read somewhere that it is common for unexplained negativity from others to be explained when asked. What is your explanation, if any?
Downvotes mean "I want to see less comments like this one". Since this currently applies to every one of your comments you may consider contrasting your comments with the ones that are voted highly and seeing if there are any features worth emulating.
Replies from: metatroll↑ comment by DaFranker · 2012-07-26T19:11:49.105Z · LW(p) · GW(p)
An attempt at formulating an explanation for the negativity might begin with:
"Your posts so far contain many critical and extremely destructive mistakes outlined in the Sequences, the core material usually discussed on this site and generally assumed to be at least partially understood by most commenters."
However, I find myself having trouble identifying further probable causes. I suspect the main reason for this is that when I read your posts, there's something out there in the back of my mind screaming bloody murder get me away from here arggh!... in a manner very similar to what I described in response to your post in the Welcome to LessWrong topic.
If you're confident that this place is somewhere you want to be, it would be most prudent to read the above-linked Sequences and re-think your approach when writing comments - a personal tip would be to start smaller, make simpler, less-bold assertions, and use the feedback on those to more clearly build a mental model of the norms and standards of this community.
Otherwise, as Eliezer suggested, you'd best start looking elsewhere.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-07-26T18:49:23.047Z · LW(p) · GW(p)
All of your recent comments have been downvoted. I suggest pursuing other forum opportunities online - LessWrong is not a good fit for you. Goodbye.