Notes on Internal Objectives in Toy Models of Agents
post by Paul Colognese (paul-colognese) · 2024-02-22T08:02:39.556Z · LW · GW · 0 commentsContents
Summary Introduction Internal Target Information/Internal Objectives Toy Models of Agents Toy Model: Thermostat The Thermostat Observations of the Thermostat Internal Target Information Observations Regarding the Thermostat’s Internal Target Information Toy Model: Model-Based Planning (Maze-Solving) Agent The Model-Based Planning (Maze-Solving) Agent The Task The Pseudo-Algorithm The Neural Network-based Value Function Observations of the Agent's Internal Target Information Discussion What form does ITI take? Retargetable Cognition Detecting an Agent's Objective None No comments
Thanks to Jeremy Gillen and Arun Jose for discussions related to these ideas.
Summary
WARNING: The quality of this post is low. It was sitting in my drafts folder for a while, yet I decided to post it because some people found these examples and analyses helpful in conversations. I tidied up the summary, deleted some sections, and added warnings related to parts of the post that could be confusing.
These notes are the result of reflecting on how Internal Objectives/Internal Target Information might be represented in simple theoretical models of agents. This reflection aimed to inform how we might detect these Internal Objectives via interpretability [LW · GW].
Note: Insights are over-indexed on these particular models of agents.
Insights include:
- Target information might be stored in some internal valuation function. The best way to extract the target information may be to search over inputs to this function (in the form of world model information) to observe which world state is highly valued. This requires advanced interpretability tools needed to isolate the value function.
- These fixed objective models are retargetable by modifying world model information.
- Retargetable models might have their objective represented as a (collection of) variables that can be naturally retargeted.
- It might be possible to train probes to map from internal variables to outcomes agents produce. By performing interpretability on these probes, we might find compact representations of the Internal Objective/Target Information.
Introduction
Internal Target Information/Internal Objectives
Internal Target Information [LW · GW] (ITI) or an Internal Objective [LW · GW] is information about an agent's target used by the agent's internals to differentiate between actions that lead to the target outcome and actions that don’t.
The hope is that by developing interpretability methods to detect and interpret this information, we can directly detect misalignment.
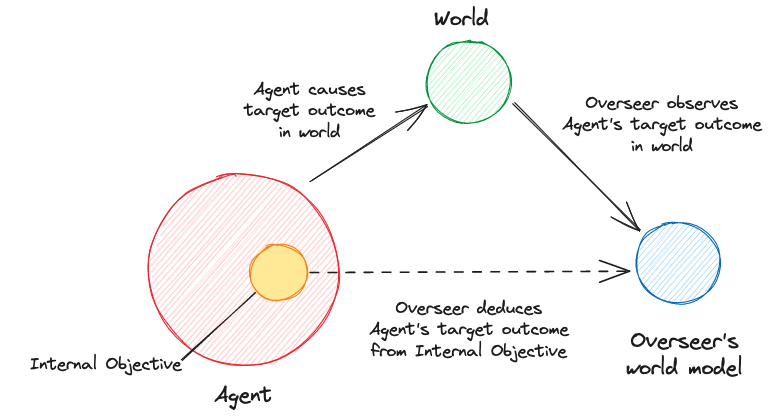
Toy Models of Agents
In this post, we explore two toy models of agents and how ITI is internally represented within these models. Our models are neural-network-based with static objectives. We sometimes reflect on what these models would look like if their objectives were retargetable [LW · GW] but do not consider this in detail.
These models are not implemented in practice but are considered in theory for speed of analysis.
Toy Model: Thermostat
The Thermostat
Consider a Thermostat whose input is the room's current temperature (as measured by a thermometer), and whose output is one of the two following actions: "Turn the radiator on" or "Turn the air conditioning on." Let denote the Thermostat's target temperature for the room. We assume that the thermostat implements the following function and that this is enough to maintain the target temperature of the room within reasonable bounds:
We suppose that is implemented on a simple one-layer hidden neural network, where the single input neuron corresponds to the room's current temperature, there are two neurons and in the hidden layer with ReLU activations, and the two output neurons and correspond to and , respectively (see Figure below).
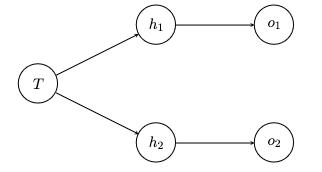
The hidden neuron values are given by: and . We apply the identity to get the outputs, i.e., and .
An argmax is applied to the outputs to select the corresponding action, i.e., if , is selected; otherwise, is selected. One can check that this implements as described above.
Observations of the Thermostat
The thermostat can be thought of as having a crude world model that consists of a single variable that tracks the temperature of the room, i.e., the input neuron.
Internal Target Information
Recall that Internal Target Information (ITI) is information about an agent's target used to differentiate between actions that lead to the target outcome and actions that don’t.
In this example, the thermostat's target is to maintain the room at temperature . We see that this information is explicitly stored in the bias terms in both hidden units.
Note that we can construct a space of neural networks that implement the same function , by multiplying the weights and biases related to the input to the hidden units by some non-zero number and multiplying the weights between the hidden units and the output units by .
This observation highlights the problem with conceiving of ITI as being explicitly represented in a human-interpretable way. Perhaps instead, it is better to conceive of ITI as encoded in the function that maps from the world model of the thermostat (in this case, a single variable represented by the input neuron) to the outputs of the neural network (or to intermediate variables such as those in the hidden layer).
Observations Regarding the Thermostat’s Internal Target Information
Quick observations:
- ITI is causally upstream of the target outcome: if we scale both bias terms that are added to the hidden units, then we expect the resulting temperature of the room to change accordingly
- ITI is naturally retargetable with respect to the world model: because it maps from the current temperature variable (input neuron) to the actions that lead to the target outcome, by postcomposing the current temperature variable with some linear function, the Thermostat can be retargeted.
- One could imagine a more expressive thermostat/NN that can have its target temperature set by some other input neuron (or by some more complicated process). In this case, the ITI would be contained in this variable.
Toy Model: Model-Based Planning (Maze-Solving) Agent
The Model-Based Planning (Maze-Solving) Agent
The Task
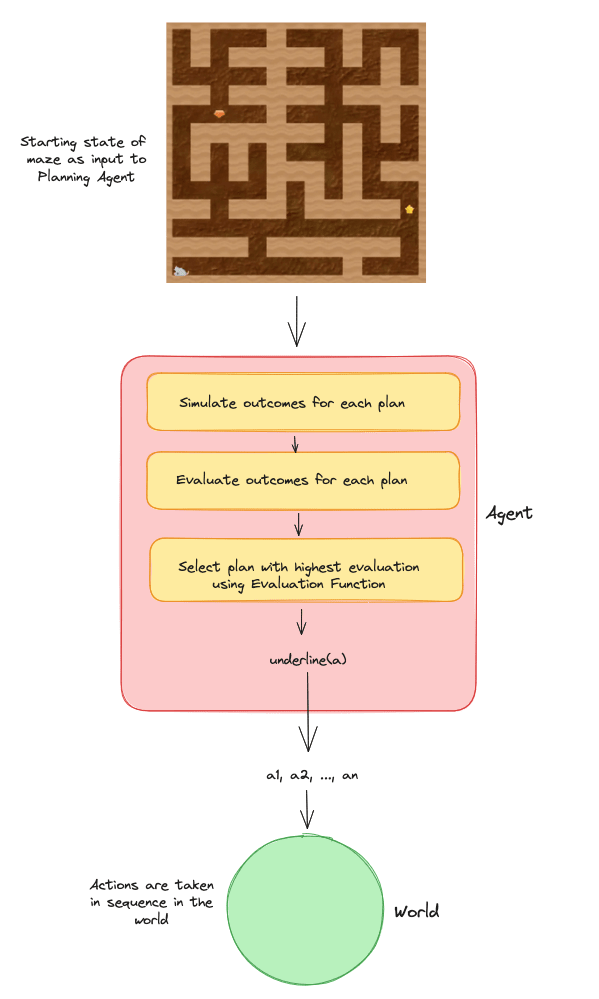
The agent receives an input image of a maze and has to compute and output a plan/action sequence that will lead the mouse to the yellow star.

The Pseudo-Algorithm
We briefly describe a Pseudo-Algorithm that the agent uses to solve the maze. The Figure below might be more illuminating.
We assume that the agent's algorithm used to select action sequences/plans is modular. The algorithm consists of several functions, including a world model for simulating the outcomes of plans, a value function for evaluating the value of a world state, and an argmax.
The agent receives an image of the maze and for each action sequence/plan in , the agent uses its world model to simulate the outcome of the plan. For each outcome it uses the value function to assign a value to the outcome according to how good the state is, and then finally, an argmax function is used to select the plan that leads to the highest value state.
The Neural Network-based Value Function
WARNING: This section is probably unnecessary. Feel free to ignore. I was going to write out the network explicitly but that seemed like it was too much effort. It wouldn't surprise me if the details are wrong/misleading, but I'm leaving it in just in case.
For our purposes, it isn't essential to consider how functions other than the value function are implemented. We ground the value function by assuming it's implemented by a neural network that we will describe shortly. The whole of the agent's architecture could be a neural network or some modular system that makes calls to a neural network that instantiates the value function.
Potentially, the most natural value function that encodes the idea that the agent's target is to get to the yellow star calculates the number of squares in the shortest path between the mouse and the yellow star and sets the value of that state as , where is sufficiently small.
We want to be explicit and write down the neural network that encodes the value function as we did in the thermostat case. Therefore, we choose a proxy value function that can be easily encoded in a neural network that also would result in the correct plan/action sequence being chosen.
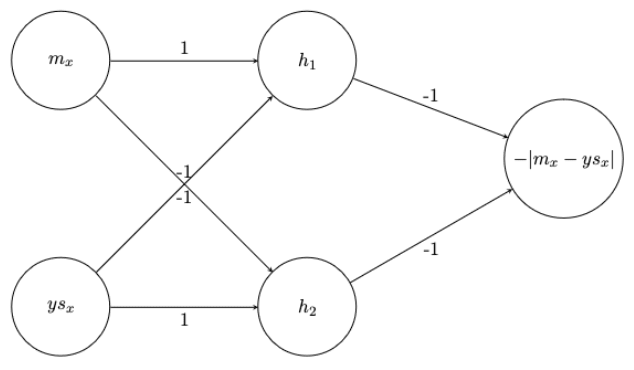
We assume that the input to this value function is a sequence of variables that represents high-level and relevant information about a particular world state. In particular, we assume that the input to the value function/neural network is a sequence of 6 variables that correspond to the mouse/yellow star/red gem's x/y coordinates in the maze. We denote the yellow star's x-coordinate as and give the other variables similar naming conventions.
The value function is given by:
.
The highest value state is 0 and corresponds to a world state where the mouse is at the yellow star (the target).
Observations of the Agent's Internal Target Information
- ITI is not clearly represented in a single weight or activation but is contained in the weights and variables that make up the Evaluation Function.
- The Target Outcome could be deduced from the Evaluation Function if the Overseer could identify the Evaluation Function, and search over inputs that maximize its output.
- For an Overseer to do this, it would need to identify the Evaluation Function subnetwork/circuit, be able to understand that the outputs of this subnetwork do indeed correspond to evaluations of world states, finally it would have to be able to intervene on the variables inputted to the Evaluation function.
- To me, the hardest part of this seems to be detecting the corresponding structure in the network and deducing that it corresponds to an Evaluation function.
- There is now a non-linear mapping from the world model variables to the value of the corresponding world state, which is then used to map to an action sequence that is finally mapped to individual actions that the agent might take. The ITI is used in the Evaluation function but is not represented explicitly in the weights, unlike in the case of the Thermostat.
- Again, the ITI is causally upstream of the Target Outcome occurring in the environment.
- The Agent can be retargeted by post-composing the world model variables (by changing the following weights in the corresponding way).
- Furthermore, the Agent could be retargeted to go to the red gem by swapping around the weights corresponding to the Mouse position and the Red gem position in the first layer of the Evaluation function. This intervention doesn't screw up the Agent's world model; it only modifies what the Agent values.
- One could train a probe whose domain is the world model variables/world state and whose codomain is the actual target outcome produced by the agent (technically, this would be the target outcome in the Overseer's world model). The probe would likely learn a compact representation of the Agent's target. In theory, a probe could be trained on all of the Agent's internal activations and would learn a similar compact representation without the Overseer needing prior knowledge of the Agent's World model, etc. This probe could then be studied to deduce the Agent's Target (although this remains tricky in practice).
Discussion
What form does ITI take?
The ITI is likely to be distributed across multiple parameters and activations but sufficiently localized that it can be used by a process that maps from world state variables to actions.
From these examples, it seems like ITI is embedded in the mapping (Action-Selection Process) from the Agent's world model to actions that lead to the target outcome.
Retargetable Cognition
- If the Agent's ITI is contained in some mapping (Action-Selection Process) from variables in its world model to actions, then in theory, this factorization of the Agent's internals could lead to some useful features:
- The Agent will be naturally retargetable by modifying the world model variables before they enter the mapping.
- Space of Objectives
- That being said, these Agents are not very sophisticated in terms of how diverse their objectives can be.
- The Thermostat can pursue just one objective - keeping the room at a pre-specified target temperature. The Model-Based Planner (and the thermostat whose target temperature can be set) is slightly more general in the sense that its objective depends on the location of the cheese in the maze. Therefore, it seems natural that we can retarget the Agent's cognition towards reaching other places in the maze. Furthermore, we saw how we might be able to naturally retarget the Agent's cognition towards non-cheese objects.
- We could imagine a maze-solving agent that's capable of pursuing different objectives in the maze in different circumstances. The Agent may have a flexible Evaluation function whose weights are modified (via the mechanism described earlier) to pursue the cheese or the red gem depending on some variable outside of the Evaluation Function. It could be the case that this external variable also can be said to be ITI.
Detecting an Agent's Objective
- Deducing Target Outcomes from ITI may require probes or interpretability of the action selection process.
- Probes could be used to map from the Agent's internals to the Target Outcome (in the Overseer's world model) if we assume the agent pursues aligned objectives on the probe's training dataset.
- One could then use interpretability on the probe to detect what information the probe is using to predict the outcome. The ITI would be a good candidate for this information.
- Potentially, one could set up a [Mechanistic Anomaly Detection] scheme where one could monitor the ITI and see whether it changes too drastically out-of-distribution.
- Presumably, the probe would learn a compact description of the Agent's Objective in terms of the Agent's world model (e.g., if the maze-solving agent represents the world in terms of the location of the cheese, mouse, and red gem, then the probe might learn some mapping from these variables to (cheese_loc, mouse_loc=cheese_loc, X),
- Relying on probes has its problems as has been discussed in the ML literature.
- Also, this won't work if the agent is already deceptive because the prob will pick up on the instrumental objective, not the model's true objective.
- That being said, if the Agent must use the same action-selection mechanism when it decides to pursue its terminal objective, we might detect this switch as stated in the MAD idea.
- The probing method works if the same action-selection mechanism is used OOD and the structure of the ITI remains the same, but its content may change.
- Interpreting the Agent's action-selection process
- If we can't rely on some safe dataset, we can't leverage the property of ITI that it causes the target outcome.
- We can only rely on deducing the Agent's action-selection process and interpreting that.
- That would likely require advanced mechanistic interpretability.
- It also might require observing the agent pursue objectives in the environment like above, as presumably finding the action-selection mechanism would involve observing that it is used to select actions that lead to the target outcome.
0 comments
Comments sorted by top scores.