Simulators Increase the Likelihood of Alignment by Default
post by Wuschel Schulz (wuschel-schulz) · 2023-04-30T16:32:43.651Z · LW · GW · 1 commentsContents
Alignment by Default How Simulators help Possible objections: What if the Shoggoth might become the AGI, not the mask? What if the base model does not have the correct idea of human values? Are simulacra with human values actually more likely, compared to other possible values? None 1 comment
Alignment by Default is the idea that achieving alignment in artificial general intelligence (AGI) may be more straightforward than initially anticipated. When an AI possesses a comprehensive and detailed world model, it inherently represents human values within that model. To align the AGI, it's merely necessary to extract these values and direct the AI towards optimizing the abstraction it already comprehends.
In a summary of this concept, John Wentworth estimates a 10% chance of this strategy being successful, a perspective I generally agree with.
However, in light of recent advancements, I have revised my outlook, now believing that Alignment by Default has a higher probability of success, perhaps around 30%. This update was prompted by the accomplishments of ChatGPT, GPT-4, and subsequent developments. I believe these systems are approaching AGI closely enough that it is reasonable to assume the first AGI will be based on the large language model (LLM) paradigm, which in turn, makes Alignment by Default more likely. In this post, I will outline the reasons behind my updated belief.
This post is also an entry in the Open Philanthropy AI Worldviews Contest. It is supposed to address Question 2: How great is our Exiential Risk, if we develop AGI before 2070?
Alignment by Default
The Alignment by Default concept suggests that if we can direct AGI toward human values without any significant breakthroughs in alignment, we could avoid catastrophe. At first glance, this idea might seem implausible, given our limited understanding of AGI and human values, and the relatively small target we're trying to hit. Even if we almost succeed in alignment, it might not be enough.
For example, let's say we nearly succeeded in aligning an AI with human values but misdefined what constitutes a person. The outcome would be a universe populated by unconscious robots expressing happiness and seemingly leading fulfilled lives. Claiming that we can align an AGI to a non-catastrophic level with our current understanding of the alignment problem is like saying we can hit a bulls-eye without really knowing how bows work and only a vague idea of where the target is.
John Wentworth, however, argues in his post [LW · GW] that this might still be possible due to natural abstractions. He envisions building an AGI by first training a world model based solely on prediction and then creating an agent that accesses this world model. By equipping the AGI with the pre-trained world model, it already thinks in a certain way. The AGI will reason about the world as if it were composed of trees, sunsets, and Wednesdays, rather than particle fields. If the natural abstraction hypothesis holds, these concepts would resemble those used by humans.
Among these natural abstractions could be the notion of human values. As the AGI forms its values, they will be derived from the abstractions in its world model. It is therefore more likely that the AGI will actually value human values rather than subtly different ones because the slightly different values are not natural abstractions. Returning to the archery metaphor, this is like having certain points on the target that are magnetic, attracting the arrow. You no longer need to hit the bull's eye directly; the arrow will be drawn to it even if your aim is slightly off.
The key insight of the natural abstractions hypothesis, which makes Alignment by Default more probable, is that the search space is smaller than initially assumed. We don't need to locate human values in the space of all possible concepts, but rather within the space of natural abstractions in the world model.
How Simulators help
This argument was made over two years ago, and since then, we have witnessed astonishing progress in AI capabilities. ChatGPT, GPT-4, and various applications built on top of them demonstrate enough general capabilities that my main lin prediction is that the first AGIs will be built on the current LLM paradigm. LLMs have not turned out the way I expected the first AGIs to look: They are simulators, and this is relevant for the Alignment by Default idea.
Janus has argued [LW · GW] that the correct way to think about models like GPT is not as agents trying to achieve some goal, but as simulators, that simulate the processes that have generated the text in their training data. We now have a somewhat agent-like conversation partner in ChatGPT by eliciting the simulation of a helpful, friendly servant. This might seem similar to Wentworth's original idea of an agent on top of a pre-trained world model, but there is an important difference: Most of the cognition occurs within the world model.
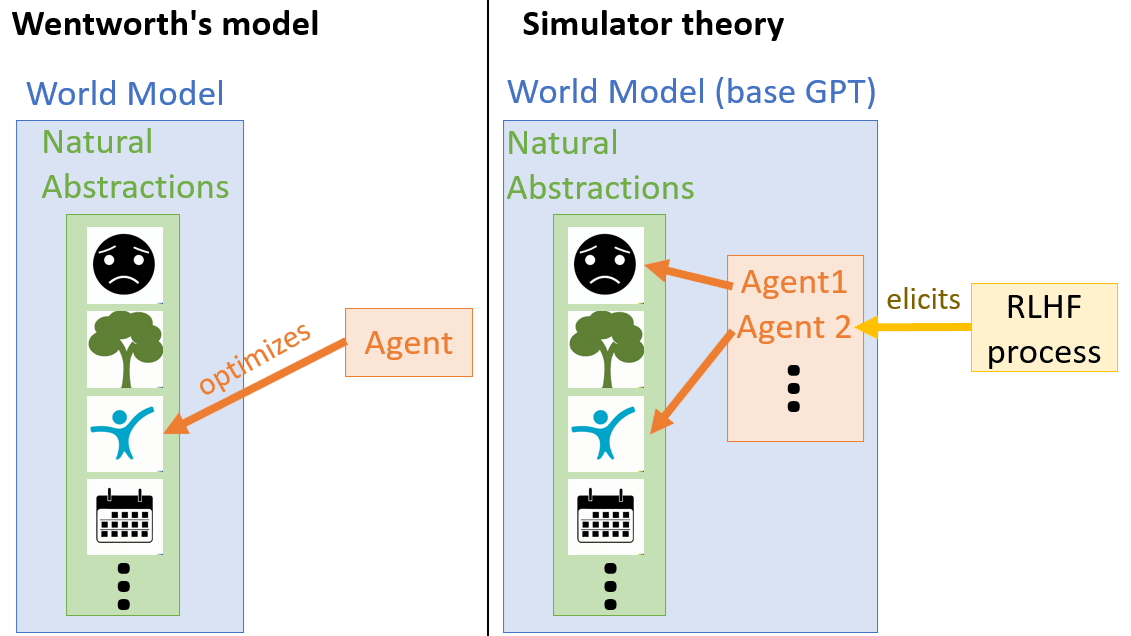
Let me clarify what I mean by this:
Wentworth's post assumes an AGI that can reason while accessing a pre-trained world model. Such an AI can make plans to optimize any of the abstractions within its world model. The task of alignment would then be to verify that the AGI has an abstraction of human values and direct it towards adhering to that rather than any other natural abstraction.
With ChatGPT and similar models, we don't have a general reasoning machine that accesses the GPT base model as a world model. In a sense, we only have a world model. As far as there is reasoning ability, we achieve it by pointing the world model at an agent and asking what this agent would do. The task of the RLHF process is to consistently point at a helpful, friendly servant and ask the world model what this advisor would do in a given situation.
The base GPT model can generate many different simulacra in this way, each with different goals. However, it doesn't produce all possible simulacra with equal likelihood. The prior likelihood of a simulacrum having a specific property is determined by how frequently that property appeared in the agents that created its training data.
This is good news for the same reason natural abstractions are beneficial: It shrinks the search space. In GPT's training data, there will be many instances of entities behaving in accordance with human values, and extremely few instances of entities behaving according to the value of "maximizing trees." Consequently, our current paradigm is much more likely to produce an agent behaving in accordance with human values rather than tree maximizers.
This wasn't clear just by considering natural abstractions. As long as we thought we would have a reasoner external to the world model, the reasoner might derive their values from any natural abstractions, and "trees" could is an abstraction as least as natural as "human values."
Continuing with the analogy: we no longer have to shoot the bow ourselves, but we can call for other people to come and shoot the bow for us. Before us is a crowd containing both archers and amateurs. Our task is now simply to call forth the right person to hit the bull's eye on our behalf.
I still believe that alignment by default has only about a 30% chance of actually working, and we cannot rely on it happening. However, with the LLM paradigm, I no longer feel confident in asserting that we would be certainly doomed if we were to ignore deeper alignment from now on.
Possible objections:
What if the Shoggoth might become the AGI, not the mask?
In my argument, I assumed that the relevant "thing doing the cognition" that we need to align is the simulacrum created by the GPT model. These simulacra then have a high prior likelihood of possessing human values. However, it might also be that the GPT model itself becomes more powerful. If the GPT model suddenly became agentic, it would have formed its values by being rewarded for predicting human texts. There would be no reason to assume that these values would be anything like human values. While I would be surprised if this happened, it is a topic deserving of its own discussion, and I may not have the expertise to fully address it.
What if the base model does not have the correct idea of human values?
This is a question I am uncertain about. It would be valuable to empirically investigate the conception of human values in current models like GPT-4. One could do this by RLHFing GPT-4 to produce the "morally correct" answers to questions and see if it misunderstood the concept to a degree that would be catastrophic. Even if such a test showed that GPT-4 does not have the correct abstraction for human values, there could still be hope that subsequent models do, as the correctness of a system's abstractions should scale with its general capabilities.
Are simulacra with human values actually more likely, compared to other possible values?
This is also an empirical question that can be addressed with current models. An easy test would be to prompt the base model with a text describing a character who might have one of several goals and then see how often the completed text described which goals. A better, but more resource-intensive test would be to RLHF the base model by giving it feedback consistent with having different values and then observing what values the model possesses after mode collapse.
1 comments
Comments sorted by top scores.
comment by quetzal_rainbow · 2023-04-30T16:58:08.401Z · LW(p) · GW(p)
The main problem here is "how to elicit simulacra of superhuman aligned intelligence while avoiding Waluigi effect". We don't have aligned superintelligence in training data and any attempts to elicit superintelligence from LLM can be fatal.