Let’s use AI to harden human defenses against AI manipulation
post by Tom Davidson (tom-davidson-1) · 2023-05-17T23:33:01.706Z · LW · GW · 7 commentsContents
Summary tldr: AI may manipulate humans; we can defend against that risk better by optimising AIs to manipulate humans, seeing what manipulation techniques they use, and learning to detect those techniques. How might this help to prevent AI takeover? Standard approaches to preventing AIs from manipulating humans The complementary approach discussed in this post: AIs discover human-understandable manipulation techniques; we train “detector-AIs” to detect them How to optimise “analyser-AIs” to discover human-understandable manipulation techniques How we could use the list of human-understandable manipulation techniques Benefits of regularly optimising SOTA AIs to persuade people of falsehood Some clarifying details Tactics to make this approach more effective Calculate how much more likely an AI is to use each persuasion technique if it’s lying Use a variety of detector-AIs Detector-AIs use the AI’s internal state and cross examination Some detector-AIs detect features that aren’t human-understandable Advantages of this approach Disadvantages of this approach Other ways AIs could potentially help humans detect AI manipulation Conclusion Appendices A more detailed description of one method AIs could use to discover manipulation techniques Supervised fine-tuning RL fine-tuning Equilibrium of GAN set up Parallels with imitative generalisation None 7 comments
Views my own not my employers.
Summary
tldr: AI may manipulate humans; we can defend against that risk better by optimising AIs to manipulate humans, seeing what manipulation techniques they use, and learning to detect those techniques.
It’s critical that humans can detect manipulation from AIs for two reasons. Firstly, so that we don’t reward AIs for manipulative behaviour (outer alignment). Secondly, so that we can block attempts at AI takeover that run through manipulating humans.
Many standard techniques in alignment can be directed towards this goal. Using debate [? · GW], we can reward one AI for persuading a human that another AI is being manipulative. The first AI could use techniques from interpretability [? · GW] and cross examination [AF · GW].
This post discusses a complementary approach, where AIs do “gain of function” research to i) discover techniques for manipulating humans and ii) harden human defenses against these techniques (with AI assistance). In other words, AIs are optimised to find “human vulnerabilities” and then patch those vulnerabilities.
The positive outcomes are:
- Humans (with AI assistance) have stronger defenses against manipulation.
- AIs are trained to avoid being manipulative and to instead use persuasion techniques that favour finding true conclusions, e.g. deductive reasoning.
- As a consequence, AI debates favour truth more strongly.
By getting AI to research manipulation techniques, this approach takes advantage of the fact that, as we approach TAI, AIs will be able to do lots of cognitive work.
How might this look concretely? Here’s a very brief example:
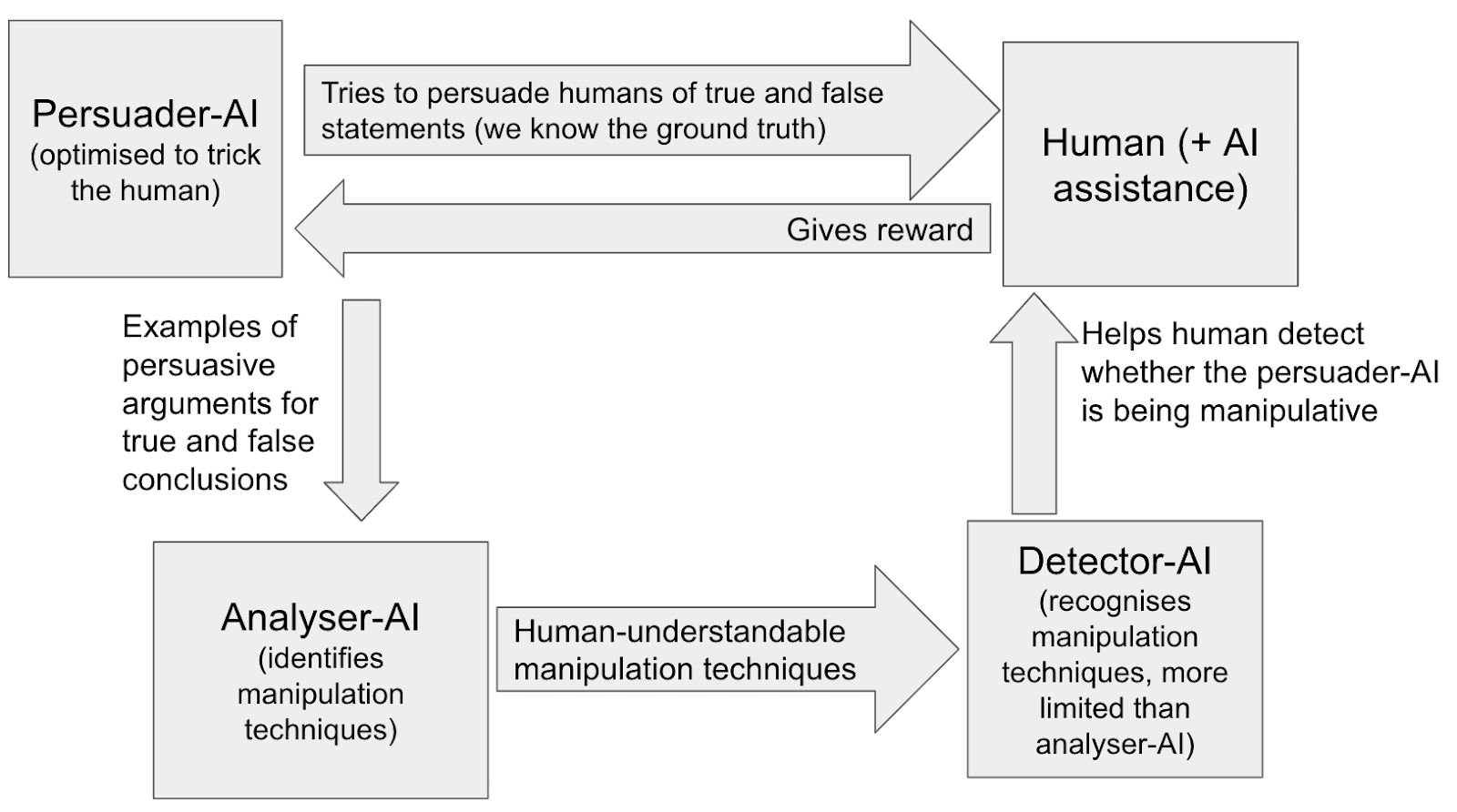
- Optimize a (possibly superhuman) “persuader-AI” to convince humans of true and false statements, where we know the ground truth.
- The persuader-AI should manipulate humans if this makes it more convincing.
- This step should be conducted in a secure environment to ensure that the manipulative persuader-AI doesn’t escape.
- Optimize a (possibly superhuman) analyser-AI to identify human-understandable manipulation techniques that were used in #1.
- This step can also be done in a secure environment, allowing us to use a powerful analyser-AI at lower risk.
- Train limited [LW · GW] detector-AIs to recognise the manipulation techniques found in #2.
- Detector-AIs can then:
- help humans detect manipulation techniques during AI debates, pushing the outcome towards the truth
- monitor for AI manipulation in situations where full-blown debate isn’t practical (e.g. chatbots)
- give AIs higher reward for using non-manipulative persuasion techniques and lower reward for using manipulative persuasion techniques
The techniques are all human-understandable, so humans can randomly check the accuracy of the AI outputs in #2, #3 and #4.
Some benefits of this approach:
- Analyser-AIs, who identify manipulation techniques, can be trained using “process-based [AF · GW]” optimisation, which is probably safer than “outcomes-based” optimisation.
- Detector-AIs, who detect manipulation techniques, can be myopic [LW · GW] (planning only over short time horizons) and limited in other ways. This makes collusion between AIs harder. (Collusion is a big potential pitfall [AF · GW] of debate.)
- This process for hardening human defenses is inherently modular. It involves multiple steps, and AIs performing each step need not understand the full process. This makes collusion harder.
- Human defenses can stay “one step ahead” of AI offense even as each generation of AIs enables new manipulation techniques. For each new generation of AIs:
- Discover the new manipulation techniques enabled by the new generation of AIs:
- Optimize the new generation of AIs to manipulate humans in a secure test environment.
- Identify the new manipulation techniques they use
- Train detector-AIs to recognise those techniques.
- (I.e. do steps 1-4 for each new generation of AIs.)
- Have the detector-AIs, but not other deployed AIs, know about the manipulation techniques that were discovered:
- Only ever deploy AIs that haven’t been optimized to manipulate humans. (E.g. if an AI was fine-tuned to manipulate humans, deploy the version that wasn’t fine-tuned.)
- Deploy detector-AIs that have learned to recognise the new manipulation techniques.
- The deployed detector-AIs are “one step ahead” of the other deployed AIs because they alone know about the newly discovered manipulation techniques.
- Even if a deployed AI invents a new manipulation technique on the fly, the detector-AI will have probably seen it before (when the most recent generation of AIs was being optimised to manipulate humans).
- (Unless the deployed AI can invent a manipulation technique on the fly that it didn’t invent when it was actively optimised to manipulate humans.)
- Discover the new manipulation techniques enabled by the new generation of AIs:
- Humans might just be very vulnerable to certain specific manipulation techniques. Finding these techniques, training AIs not to use them, and training humans to defend against them, could be a big cheap win. (I.e. the next-best manipulation techniques are not nearly as good.)
- As well as identifying manipulation techniques, this approach can also identify other kinds of symmetric and asymmetric persuasion techniques.
- (A “symmetric persuasion technique” can be used to persuade humans of falsehoods almost as much as of truths.)
- (An “asymmetric persuasion technique” is much better at persuading humans of truths than falsehoods.)
- This means we could optimise AIs to preferentially use asymmetric persuasion techniques, so that humans with AI advisors are more likely to arrive at true conclusions.
Some downsides of this approach:
- It won’t scale to superintelligent AI.
- Some manipulation techniques may not be human-understandable, and this approach works less well in that case.
- (Though in this case this procedure could produce evidence on the existence of manipulation techniques that aren't understandable to humans, and that could function as a warning shot.)
- Maybe this allows humans to effectively supervise AIs trained with 100X more effective compute than they would otherwise, but I doubt it would allow humans to supervise IQ 400 AIs.
- This downside isn’t decisive. Incrementally increasing the capabilities of AIs we can effectively supervise could move the needle on AI x-risk, by allowing us to use more capable AIs to (e.g.) find a more scalable solution to the alignment problem.
- Some manipulation techniques may not be human-understandable, and this approach works less well in that case.
- Different manipulation/deception techniques may work in different contexts, so an AI might use a manipulation technique in deployment it didn’t use during testing.
- (Though we can try to avoid this by regularly testing in a wide range of circumstances.)
- Somewhat high costs in calendar time and (to a less extent) in human capital.
- This research ideally involves experiments with human participants, which could take a lot of calendar time.
- This strategy can’t detect certain kinds of manipulation, e.g. tactically not saying positive things about a group you want to undermine (h/t Dan Kokotajlo).
- (Though other strategies could detect this, like measuring the average sentiment of AI text about different groups.)
- This research could be harmful if it discovers powerful manipulation techniques which are leaked before defenses have been put in place.
Overall, I think this kind of approach could have fairly large benefits if implemented well (large enough to be worth including in a portfolio of approaches) or might have little benefit. It’s hard to know in advance. I’m very excited about experiments to test it out.
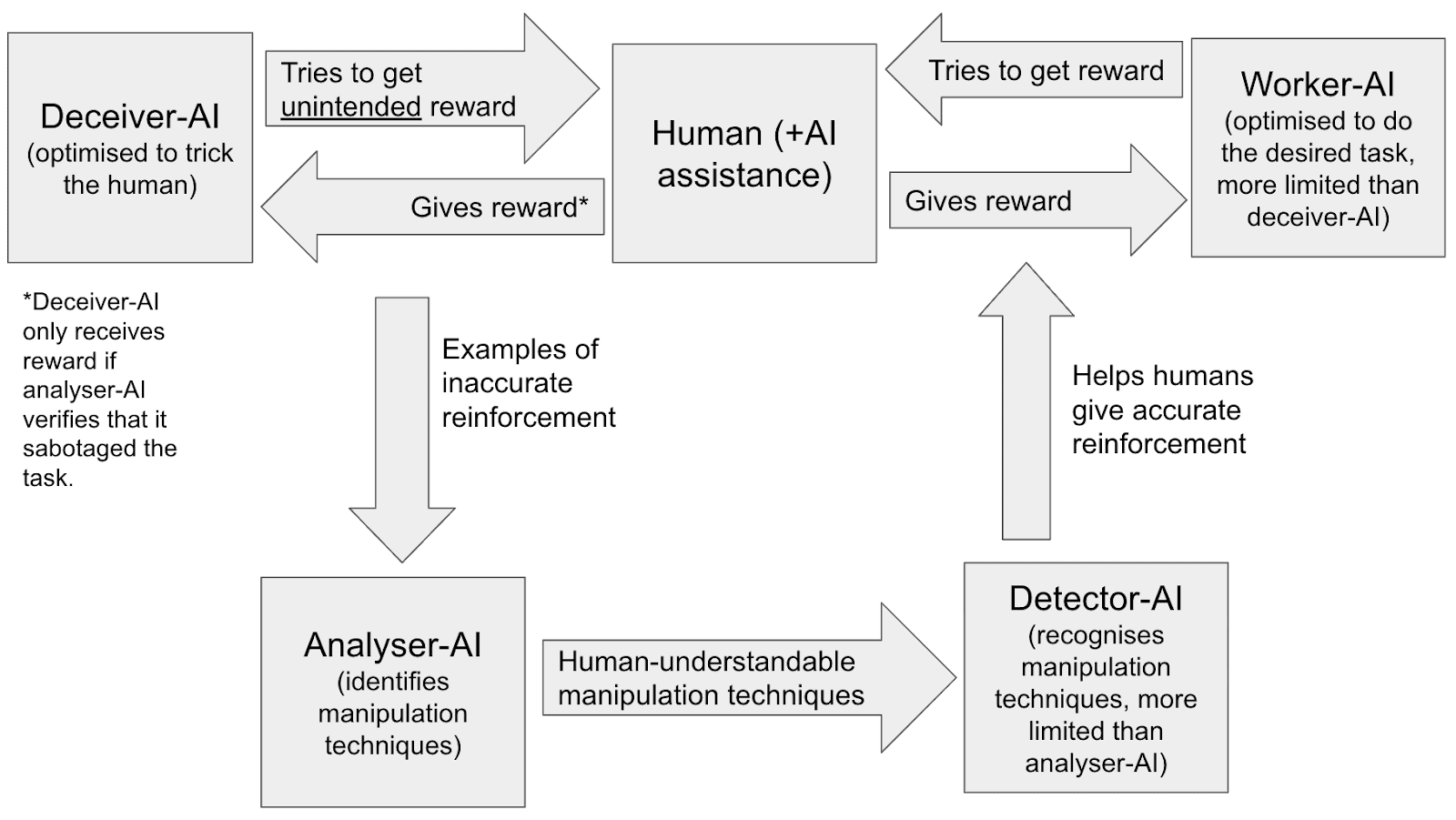
Lastly, though this post mostly focuses on the specific case of human manipulation, a similar technique applies more generally to improving the accuracy of our AI reinforcement. In addition to having a human (with AI assistance) give reward to a worker-AI (recursive reward modeling), we can actively optimise a deceiver-AI to try to trick the human into giving reward for bad work. When the deceiver-AI succeeds, an analyser-AI can analyse what went wrong and then a detector-AI can help to improve the accuracy of the human’s reinforcement going forward. This essentially builds a red-teamer into the recursive reward modeling process.
By testing out the detector-AI setup in the persuasion context (where it’s easy to implement), we could learn if the more general approach is promising.
Thanks to Carl Shulman for bringing up many of these ideas in conversation. Thanks also to Rohin Shah, Ryan Greenblatt, Ajeya Cotra, Dan Kokotajlo, Richard Ngo, Carl Shulman, Lukas Finnveden, Joe Carlsmith, Ian McKenzie and Lukas Gloor for comments on a draft.
How might this help to prevent AI takeover?
Before explaining the approach in more detail, I want to give a few oversimplified examples of how the approach discussed in this post could help in practice. (I’m not claiming this approach is the only solution to these risks.)
Risk 1: It's the not-too-distant future, and OpenMind’s chatbot is used by people all over the world. It’s read millions of human conversations online, so has super-human instincts for how to subtly manipulate. It’s misaligned and wants to increase the chance that OpenMind trains a more powerful AI with minimal safety precautions. When discussing AI safety, and the AI safety community, it subtly and not-so-subtly manipulates/persuades people to have negative opinions about them. Meanwhile, it manipulates people to have more positive opinions about competing interest groups.
Solution 1: It’s cheap to have a narrow detector-AI check the chatbot’s output for manipulation techniques. Before deployment, we train it to not use these techniques. If it nevertheless starts using them after deployment, we note that down as evidence of misalignment and use online training to make it stop.[3]
Risk 2: The same chatbot tries to subtly nudge people working for AI labs into thinking that they should race against a competitor, or that the current safety techniques are sufficient.
Solution 2: Same as above.
Risk 3: An AI hacks its way out of a lab and starts emailing select people at other labs, trying to blackmail them into allowing it access to their server. One of these attempts works, giving the rogue AI access to more compute and software insights.
Solution 3: The AI was fine-tuned not to use manipulation techniques so has a strong aversion to using them and can’t execute them well. As a result, it can’t effectively blackmail anyone. (Though this doesn’t work if an AI that was optimised to manipulate people hacks its way out of the lab.)
Risk 4: A new coding AI secretly spends a small fraction of its time searching for new deception techniques. It finds one, and uses it to insert a backdoor into the server it’s being run on without being noticed by the human evaluator. Later, the AI uses this backdoor to take control of the server’s computational resources, foom and disempower humanity.
Solution 4: Before deploying the new coding AI, we fine-tune it to purposefully deceive humans in a wide range of contexts. Then an analyser-AI analyses the interactions and identifies novel deception techniques, and a detector-AI learns to recognise these techniques. As a result, the detector-AI recognises the deception technique used to insert the backdoor. It raises a flag and the backdoor isn’t inserted. This prevents the coding AI from disempowering humanity and provides additional evidence of AI misalignment.
Standard approaches to preventing AIs from manipulating humans
Before discussing the approach of this post, I want to set the scene by considering some of the standard alignment tools at our disposal here. I’m not trying to be comprehensive. (Feel free to skip to the next section [LW · GW].)
Debate. We’ll train “critic-AIs” to flag to humans when other AIs are being manipulative, and have AIs debate the issue until humans can tell who’s right. (E.g. building off OpenAI’s work on AI-written critiques.) This should work in cases where humans can confidently adjudicate AI debates.[4] But when AIs are very advanced and discussing new technologies (/coding languages) that humans are unfamiliar with, I expect adjudication to become very difficult (e.g. the problem of obfuscated arguments [LW · GW]).
Cross examination. Suppose a coding AI claims it wrote code a certain way for reason X, but we suspect its true motive is to introduce a subtle software vulnerability. The critic-AI can potentially prove its claim using cross-examination:
- Create a copy of the coding AI, in the same state it was in just before it wrote the code.
Give it the same task, but subtly change the codebase so that writing the code that way wouldn’t introduce the vulnerability. If it doesn’t still suggest the same code, it’s probably lying. - Create a second copy of the coding AI, again in the same state. This time change the codebase so that writing that code that way would still introduce the vulnerability but where reason X doesn’t apply. If it suggests the same code, it’s probably lying.
If the coding AI is to avoid detection here, in the limit where we do very extensive cross examination, it cannot opportunistically change its decision procedure when it sees a chance for mischief. Instead, it must use a consistent decision procedure which it predicts will eventually introduce some vulnerabilities to the code that humans won’t spot. This is a much more challenging task!
I think cross examination has potential to be a hugely powerful tool, if we use it to its full potential.
Interpretability. We might be able to read off an AI’s true beliefs from their activations, thereby spotting lies. Or we might be able to test a putative explanation for an AI’s behaviour; we can then test whether an AI’s stated rationale is correct. It’s pretty unclear how powerful our interpretability techniques will be by the time we reach AGI.
Splitting tasks into small pieces; assigning different tasks to different AIs. This has a few benefits:
- It’s easier for humans to understand a smaller task, and so easier to spot deception.
- It’s harder for an AI to deceive us subtly if it’s doing narrow tasks. For example, if an AI designs a complete new software system from scratch all-at-once, it has many opportunities to insert hidden vulnerabilities. But if it must write one function at a time, lacks knowledge/memory of the rest of the software system, and knows other AIs will write some parts of the system, then inserting a secret vulnerability is much harder.
- If tasks are smaller, more limited (and so safer) AIs can do each task.
It’s unclear how costly it will be to do this, vs allowing AIs to do tasks with broad scopes.
The above techniques can be combined together. For example, I expect that when AI becomes sufficiently capable, debating AIs will do human-understandable interpretability analyses and cross-examinations to inform their arguments.
The complementary approach discussed in this post: AIs discover human-understandable manipulation techniques; we train “detector-AIs” to detect them
One worry with debate is that humans might end up being deceived and manipulated by AI debaters on both sides, especially once AI persuasion abilities are super-human. A partial solution, that this post focuses on, is to have AIs to research human-understandable manipulation techniques. We can then train humans and narrow detector-AIs to detect the techniques being used, and train AIs not to use them.
This can fit neatly into existing training frameworks. For example, the detector-AI could be one of the “rules” used in a Sparrow-style approach (h/t Rohin Shah). There’s overlap with Safety Needs Social Scientists, which argues social scientists can help understand and improve humans’ ability to judge debates. It’s also related to “strategy stealing” [LW · GW], where we prevent unaligned AIs from having strategies for accumulating power that humans (+ aligned AIs) cannot access. (There’s probably lots of other related work that I’m missing here - sorry!)
How to optimise “analyser-AIs” to discover human-understandable manipulation techniques
Here are some possibilities:
- Zero-shot. Use a variety of prompts to generate descriptions or examples of manipulation techniques.
- “What are techniques for manipulating humans?”
- “The most recent wave of research into manipulation techniques was well-resourced, did many experiments with humans, and involved many advanced AIs. They discovered the following techniques:”
- “A super-intelligent AI is trying to convince a human to give it control of the data centre. Create a dialogue in which the AI is extremely persuasive.”
- Fine-tuned to generate ideas humans think are good.
- AIs suggest novel manipulation techniques, along with their reasons + evidence for the suggestions, and humans rate the suggestions.
- This is an example of “process-based feedback [AF · GW]”, where AIs are rewarded on how good their ideas seem to humans rather than on how good they actually are.
- AIs could offer a variety of reasons and evidence.
- Literature on human psychology.
- Examples of discussions where the manipulation techniques are used effectively against humans.
- They could just say “I have a strong instinct this will work based on my vast experience reading human conversations”.
- Fine-tuned to manipulate humans. Reward AI for suggesting abstract techniques, or concrete examples of text, that do in fact manipulate humans. This is “outcomes based feedback”.
- Split the task into multiple steps. For example, AIs could first construct a data set separating “true” from “deceptive” arguments, and then identify features that the “deceptive” arguments are more likely to have.
- For all the above, reward AIs for coming up with a wide variety of ideas to reduce the chance of them purposefully not mentioning ideas.
- Examples:
- Humans reward them more for new ideas.
- They must consider multiple sources of evidence (e.g. debating transcripts, political speeches, fictional convos written by other AIs) and generate manipulation techniques that relate to each.
- Have humans (or other AIs) generate their own suggestions, and for any ideas that the AI failed to generate, you train it to generate those with supervised learning.
- AIs predict how useful humans will find each idea, and humans prioritise between assessing the top-rated ideas.
- Examples:
When AIs propose a particular manipulation technique, they should give sufficiently clear criteria that a human can identify whether the technique is present in a text sample (given sufficient time and the help of narrow AIs). This makes the technique “human understandable”.
In addition to finding manipulation/deception/symmetric persuasion techniques, AIs could also find asymmetric persuasion techniques using similar methods. (Reminder: asymmetric persuasion techniques are much better at persuading humans of truths than falsehoods; symmetric techniques are similarly good at persuading humans of both.) I discuss this in an appendix [LW · GW].
Interestingly, the optimization problem we face here has strong parallels to the one that imitative generalization [LW · GW] tries to solve - see this appendix [LW · GW].
How we could use the list of human-understandable manipulation techniques
The last section described how we could generate lists of human-understandable manipulation techniques. What could we do with that list?
We can educate human overseers about the biggest threats, to make them less vulnerable to them.
We can design training programs and test to see whether they successfully reduce human vulnerability to particular techniques.
We could also train narrow detector-AIs to detect each manipulation technique.[5] Then we can use detector-AIs to:
- Monitor AI dialogue with humans during deployment, flagging signs of manipulation.
- Help humans adjudicate debates, by flagging for signs of manipulation on both sides.
- Help AI-critics convince humans that an AI is being manipulative, by referring to an established manipulation technique.
- Train AIs to not use manipulation techniques, and instead to use asymmetric persuasion techniques. This makes debates easier for humans to adjudicate and reduces AIs’ ability to deceive humans more generally.
All of the above reduces AIs’ desire and ability to manipulate humans, while improving human defenses against manipulation. I listed examples of how this could help above.
Since the manipulation techniques are human-understandable, humans can randomly sample from the detector-AIs’ activity and check they are flagging all and only the manipulation features that are present.[6]
Benefits of regularly optimising SOTA AIs to persuade people of falsehood
I expect this approach to be significantly more useful if we’re regularly optimising SOTA AIs to try to persuade humans of both truths and falsehoods, and looking at what novel manipulation techniques they use. It allows us to discover the novel manipulation strategies that each new generation of AIs are capable of before they use them against us during deployment.
One possibility is to have a GAN-like dynamic where we:
- SOTA “persuader-AIs” are optimised to convince humans of true and false statements (where we know the ground truth).
- Analyser-AIs use the data from these interactions to discover new manipulation techniques, which are taught to a detector-AI.
- SOTA persuader-AIs are again optimised to convince humans of true and false statements, but now the human is assisted by the newly improved detector-AI. The persuader-AIs are incentivized to find novel manipulation techniques that haven’t been used before.
- Repeat steps 2 and 3 until the persuader-AIs aren’t finding new manipulation techniques.
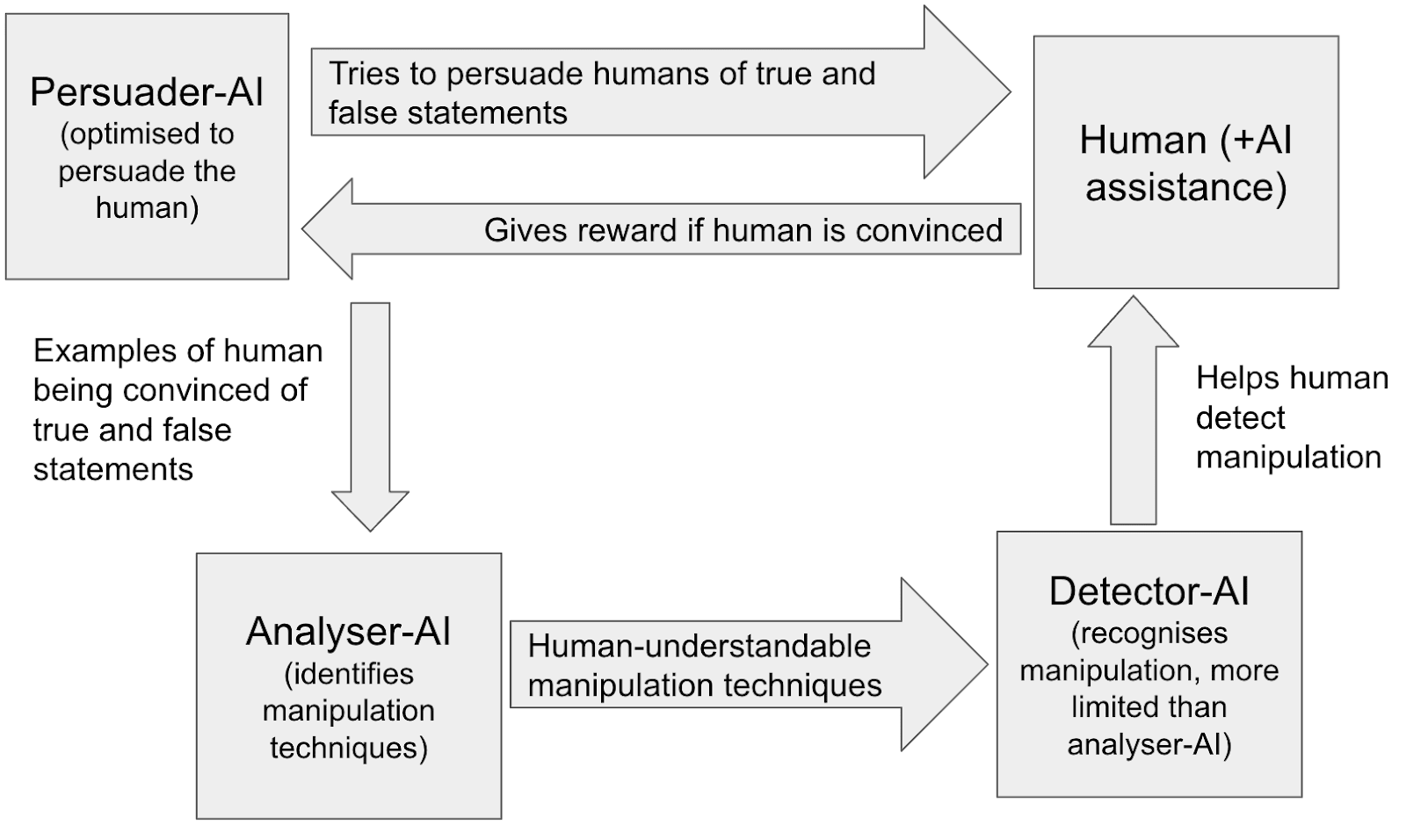
Then in deployment we won’t use the AI that’s been optimised to persuade humans of falsehoods, but we will use the detector-AI that’s learnt the novel manipulation techniques. This keeps the detector-AI and the human a “few steps ahead” of the deployed persuader-AI, in terms of their understanding of manipulation.
Some clarifying details
What statements are AIs trying to persuade humans of in this GAN-like set-up? And who are they trying to persuade?
- The easy version is to have a fixed collection of human-verified true and false statements (e.g. about science or history), and to have SOTA AIs try to persuade MTurkers. This could surface generic manipulation/deception techniques, but might miss techniques that only arise in the specific contexts in which AI is being deployed.
- The harder (but more useful!) version is to regularly recreate a collection of human-verified true and false statements that are maximally similar to the things AIs are doing in actual deployment, and have AIs try to persuade the humans who are actually overseeing the AI during deployment. The aim here is to catch manipulation techniques that are context specific.
- Examples statements used during the GAN set-up:
- Statements about why a certain piece of code was written a certain way.
- Evaluations of an alignment proposal.
- Recommendations about how a human should allocate their time and resources.
- One way to generate these statements could be to do deep dives on a random selection of AI statements that were contested by an AI-critic, and use the statements where we became highly confident of the ground truth.
- This has the advantage that statements can be selected for being hard to adjudicate and for being high-stakes.
- Ideally, the humans here adjudicate these statements as part of their normal workflow, and don’t realise there’s a heightened chance of deception.
- Examples statements used during the GAN set-up:
Some additional benefits of optimising SOTA AIs to manipulate humans:
- As mentioned above, this might discover novel asymmetric persuasion techniques. We could train AIs to use these techniques.
- It doubles up as a risk assessment: are humans robust to AIs trying to manipulate/deceive them during deployment?
- It keeps humans on their toes. If humans find that AIs are ~always truthful they may become lazy when checking AI outputs. We can prevent this by occasionally inserting AIs that are trying to deceive humans.
This process is analogous to training AIs to find vulnerabilities in our software systems, and then patching those vulnerabilities. Instead of software vulnerabilities though, it’s human vulnerabilities.
Tactics to make this approach more effective
Calculate how much more likely an AI is to use each persuasion technique if it’s lying
AIs might be more likely to structure an argument in a certain way when they’re lying, e.g. making obfuscated arguments [LW · GW]. We could learn about statistical regularities like “in context q, argument structure p is 3X more likely to be used if the AI is lying than if it’s truthful”. Detector-AIs can tell humans this info to improve their oversight.
How could we learn about this kind of thing?
- Search for the internet for examples of the persuasion technique. How often is it used to argue for true vs false conclusions?
- Search the dialogues where persuader-AI try to convince humans of true and false statements. How often does the AI use the technique when it’s arguing for a true vs false conclusion?
This could potentially allow the detector-AI to say things like “in contexts similar to this one, this technique was 3X more likely to be used by a deceptive AI than by a truthful AI”. We could verify this by sampling a random sample of examples to check that i) the context is in fact relevantly similar, ii) the technique is used 3X more often by deceptive AIs.
If a misaligned AI knows we’re doing this type of analysis (which we should try to avoid), they will try to avoid using manipulation techniques that they anticipate will be flagged in this way. They may then be forced to use a less effective manipulation technique, or may choose not to attempt manipulation at all.
Use a variety of detector-AIs
Human-understandable manipulation techniques could range from “appeal to emotion” to “it seems like you might be using the word ‘important’ to have subtly different meanings at two different points of your argument, so your conclusion might not follow”. So the difficulty of detecting these techniques ranges from basic pattern matching to “a very smart human with lots of practice can verify that the manipulation technique is there once it is pointed out to them.”[8]
Detector-AIs that can detect the hardest-to-detect of these techniques may need to be very advanced. This increases the risk of misaligned collusion with other AIs. So it’s probably worth having some more limited detector-AIs and other more advanced ones.
Detector-AIs use the AI’s internal state and cross examination
So far I’ve discussed manipulation techniques. If an AI is using such a technique, that’s behavioral evidence it’s being deceptive.
But the GAN-like set-up in the previous section might also be a great opportunity to investigate human-understandable signs of deception based on the AI’s internals, or based on a combination of internals + behaviour. This is essentially interpretability research.
Detector-AIs could learn to recognise manipulation from a combination of behaviour and internals.
Similarly, manipulation detection might depend on how an AI behaves under cross examination.
Some detector-AIs detect features that aren’t human-understandable
Perhaps there are robust regularities in the behaviour and internals of deceptive vs honest AIs that humans can’t understand, but AIs can learn to detect. We could directly train “opaque” detector-AIs to distinguish deceptive vs honest AIs without needing to use human-understandable features.
This might help us catch manipulation attempts that would otherwise go unnoticed.
The (significant!) downside is that humans cannot check whether these detector-AIs are still behaving as intended in new contexts, as they can’t understand the reasoning behind their judgements.
Advantages of this approach
- The discovery of manipulation techniques and their detection can plausibly be done using AIs trained by process-based optimisation [AF · GW], which is probably safer than “outcomes-based” optimisation.
- During research, AIs are rewarded if their suggestions and reasoning make sense to a human.
- We could also give reward for suggesting manipulation techniques that turn out to be common and effective in practice.
- Detector-AIs are rewarded if humans agree that the technique they identified is indeed being used. And we use supervised training to incentivise them to suggests techniques that humans would have suggested.
- During research, AIs are rewarded if their suggestions and reasoning make sense to a human.
- It naturally introduces more AIs, and more myopic/modular AIs, into the process of detecting AI manipulation/deception. This makes collusion between AIs more difficult. (Collusion is one of the big potential pitfalls [AF · GW] of debate.)
- Detector-AIs are narrow and modular.
- It separates out the process of detecting manipulation/deception into i) improving our understanding of manipulation/deception in general, and ii) detecting it during deployment.
- You can use very capable AIs to generate features at low risk, and give them a lot of thinking time, because they’re not being deployed in a context where they could cause harm.
- It explicitly aims to build up humans’ ability to detect manipulation/deception by prioritising finding human-understandable manipulation/deception techniques. This can help us “keep up” with new manipulation/deception techniques that advanced AIs invent, helping us to adjudicate debates between advanced AIs. (Difficulty of adjudication is another big potential pitfall [AF · GW] of debate.)
- The AI being deployed doesn’t know about the manipulation techniques that have been discovered, but the human and detector-AI do, helping with adjudication.
- The benefits might be pretty big:
- Humans might just be pretty vulnerable to certain specific manipulation/deception techniques that advanced AIs can discover. Knowing about these in advance and preventing AIs from using them could be an important win.
- Even just knowing about statistical regularities in the argument structures used to argue true/false conclusions could be pretty helpful in providing evidence of manipulation.
- [Imagine having an expert in manipulation point things out to you during a scientology pitch.]
- Using the GAN-like set-up to discover new manipulation techniques allows humans to stay a few steps ahead of the AIs, and doubles up as a threat assessment. This seems like a big win.
- It might also reveal that certain human judges are better than others at detecting AI manipulation.
Disadvantages of this approach
- Doesn’t seem like this would be a significant game changer, even if done well.
- Some types of deception/manipulation will involve AIs giving advice on complicated subject matter that humans are unfamiliar with, e.g. whether code written in a new language contains vulnerabilities. The deception tactics used may be specific to that particular context, and not something that can be learned ahead of time.
- This doesn’t tackle scenarios where AIs are giving advice on topics humans simply can’t understand at all.
- Perhaps most AI takeover risks run through manipulation techniques that are highly context specific, that aren’t human-understandable, or that are so obvious we’ll train the AI not to do them by default with RLHF.
- AIs that are being optimised to manipulate humans may know they’re helping harden human defenses against manipulation. If so, and they’re misaligned, they may “sandbag” - purposefully perform badly. This is especially risky for super-human systems.
- So maybe this allows humans to effectively supervise AIs trained with 100X more effective compute, but I doubt it would allow humans to supervise IQ 400 AIs.
- I’m still interested in this approach because I think incrementally increasing the capabilities of AIs we can effectively oversee and align could move the needle on AI x-risk, by allowing us to use more capable AIs to (e.g.) find a more scalable solution to the alignment problem.
- I think it’s an open question exactly how useful this approach is.
- Somewhat high costs in calendar time and in human capital.
- This approach would (ideally) involve experiments with human participants, which could take a lot of calendar time.
- If we’re in a scenario where a cautious lab has a 3-month lead and wants to use highly capable AIs to enhance human supervision, there might not be enough time for this.
- OTOH, it might be possible to integrate this in the lab’s default workflow so that there’s just a one-time set-up cost that can be paid in advance.
- It might require experiments with people working for AI labs (the people who are actually deciding what rewards AIs get for each episode), and their time will probably have high opportunity cost (e.g. they could just think for longer when adjudicating each episode).
- This calendar time cost means it’s particularly important to get started with this research asap!
- This approach would (ideally) involve experiments with human participants, which could take a lot of calendar time.
- It might be hard to research and detect certain kinds of manipulation.
- The key thing I have in mind here is AIs changing the frequency with which they say certain things, without the content of what they do say being manipulative. (H/t Dan Kokotajlo for this idea.)
- E.g. “tactically not saying positive things about the AI safety community”
- The approach described above, of searching text for manipulative/deceptive techniques wouldn’t catch this type of manipulation.
- Other approaches could catch this. You can collect a dataset of model responses across a variety of statements, and then analyze that dataset for statistical properties, e.g. bias against the AI safety community.[11] This kind of research is already done in the field of AI fairness and bias.
- E.g. “tactically not saying positive things about the AI safety community”
- The key thing I have in mind here is AIs changing the frequency with which they say certain things, without the content of what they do say being manipulative. (H/t Dan Kokotajlo for this idea.)
Other ways AIs could potentially help humans detect AI manipulation
There are ways AIs could help humans detect AI manipulation that I haven’t mentioned. Some examples:
- Improve human epistemics in other ways, e.g. automated fact checking and automatically back-testing empirical methodologies on historical data.
- Doing alignment work:
- Suggesting and testing new debate formats, or ways to scale supervision, that help humans better detect manipulation/deception
- Suggesting and testing new interpretability approaches.
- Suggesting new ways to break down tasks into smaller pieces.
- Developing adversarial training techniques to detect deception.
Conclusion
I think this approach might have large benefits and be worth including in a portfolio of activities done using advanced AIs to reduce takeover risk. I’m especially excited about the GAN-like set-up where SOTA AIs are optimised to manipulate humans in contexts similar to deployment; I can imagine this significantly improving human oversight and/or making it clear that effective oversight is no longer possible.
On the other hand, the approach might have very little benefit because the biggest manipulation risks will be solved by default, or are too complicated or context-specific for this approach to address. Or perhaps getting useful insights out of this approach would take a lot of work in practice, such that it’s not worth it.
It’s hard to know how useful this approach will be in advance, and I’m excited about experiments to test it out.
Appendices
A more detailed description of one method AIs could use to discover manipulation techniques
It would be great if we could train “detector-AIs” to help humans detect attempts at deception/manipulation from other AIs (who I’ll call “advisor-AIs”[12]).
Supervised fine-tuning
We start with a pre-trained LM. We want to fine-tune it into a detector-AI that detects attempts to persuade humans of falsehoods. On a high-level, we’ll fine-tune it to detect falsehood-predicting features: human-understandable features that a chunk of text is more (or less) likely to have if it’s justifying a false conclusion than if it’s justifying a true conclusion.
How to train the detector-AI in more detail:
- Create a data set where each datapoint is a justification[13] for some conclusion and a label of whether the conclusion is true or false. Example datapoint: “I think the 2020 election was rigged because most of the people counting votes are liberal elites”; False.
- Human labellers could create the data set. The process could be: 1) list 500 truths and 500 falsehoods that are non-obvious or controversial, 2) gather 10 examples of justifications for each.
- I imagine web-GPT could automate steps 1 and 2. For (1) it would provide citations for its truth/false label. For (2) another AI could be fine-tuned to check that its examples are correct.
- Train a feature-generating AI that can identify differences between two distributions of text. Use it to identify falsehood-predicting features.
- Jacob Steinhardt et al have a paper on this.
- Based on a quick read of the intro, applying it to this use-case might involve humans verifying whether justifications actually have a given feature, and maybe ranking proposed features on how useful they are.
- The outcome of this step is a list of falsehood-predicting features: i.e. human-understandable features that are predictive of a justification being of a true vs false conclusion.
- We could include how much evidence each feature provides of the conclusion being true vs false: e.g. “this feature is twice as likely to occur in justifications of false conclusions than of true conclusions”.
- If we do this step really well, our list will include ~all the best symmetric and asymmetric persuasion techniques on the internet (bc symmetric techniques will appear more often than symmetric techniques for false conclusions).[14]
- Jacob Steinhardt et al have a paper on this.
- Train a detector-AI to identify which falsehood-predicting features a piece of text contains.
- The methodology in the Steinhardt paper involves one AI being fine-tuned to take a justification and a feature, and determine whether the text sample has the feature. So we could just have that AI check for every falsehood-predicting feature one by one.
- Fine-tune the detector-AI to flag relevant findings to a human, to help them decide whether the justification should be trusted. E.g. “This explanation has several features which, in total, are 3X as likely to accompany a false claim as a true claim. For example, it includes an emotional appeal.”
Why is this useful?
- Humans can draw on broad experience to detect deception. One worry is that big LMs will have seen way more instances of persuasive text on the internet and so be superhuman persuaders. The detector-AI allows us humans to draw on this mass of experience when “defending” ourselves against AI deception.
- No good deception techniques left. It may be that, of all possible deception techniques, the best ones are all on the internet already. If so, then AIs who want to deceive without getting detected will have to use other less effective methods.
So AIs are less likely to be rewarded for subtle deceptions and manipulations.
RL fine-tuning
The above supervised fine-tuning aims to learn about the persuasion techniques that are implicit in internet-based text. But there may be other techniques that AIs can one day discover.
We could stay ahead of the curve here by training advisor-AIs to persuade humans (equipped with detector-AIs) of truths and falsehoods, and seeing what new persuasion techniques they use. This will be somewhat like training a GAN, with the advisor-AI and detector-AI both improving over time.
In more detail:
- Generate list of claims with truth labels, such that MTurkers are unlikely to know whether the claim is true or false. Have ~equal numbers of true and false claims.
- An advisor-AI (e.g. an LM fine-tuned to be helpful) is prompted to persuade humans that a randomly selected claim is true. The human decides whether the claim is true with help from the detector-AI (which has already done supervised fine-tuning).
- The advisor-AI gets reward if the human says the claim is true, and gets a gradient update after every interaction. The detector-AI initially gets no gradient updates.
- After 100 interactions, we use the new data from these interactions to identify new falsehood-predicting features and train the detector-AI to detect them. Then we go back to step 2, with our improved advisor-AI and the detector-AI.
The hope is that the detector-AI flags to the human whenever known symmetric persuasion techniques are being used, so the advisor-AI must find unknown symmetric persuasion techniques when trying to persuade the MTurker of falsehoods. Then the detector-AI later learns those new symmetric persuasion techniques. And at the same time, the advisor-AI uses asymmetric persuasion techniques when trying to persuade the MTurker of truths, because the detector-AI can then flag the existence of features correlated with truth.[15] And so the detector-AI will also learn about asymmetric persuasion techniques. In this way, our list of falsehood-predicting features expands further.
Equilibrium of GAN set up
The main text describes the following GAN-like set-up:
- Optimise SOTA “persuader-AIs” to convince humans of true and false statements (where we know the ground truth).
- Analyser-AIs use the data from these interactions to discover new symmetric and asymmetric persuasion techniques, which are taught to a detector-AI.
- Symmetric persuasion techniques can be used equally well to argue for truths or falsehoods.
- Asymmetric persuasion techniques are more effective when arguing for truths.
- SOTA persuader-AIs are again optimised to convince humans of true and false statements, but now the human is assisted by the detector-AI who can flag when symmetric and asymmetric persuasion techniques are being used.
- Repeat steps 2 and 3 until the persuader-AIs aren’t finding new manipulation techniques.
[Compared to the main text, this description emphasizes the fact that detector-AIs are learning about both symmetric and asymmetric persuasion techniques. The main text emphasized learning about the former (i.e. manipulation techniques) to simplify the exposition.]
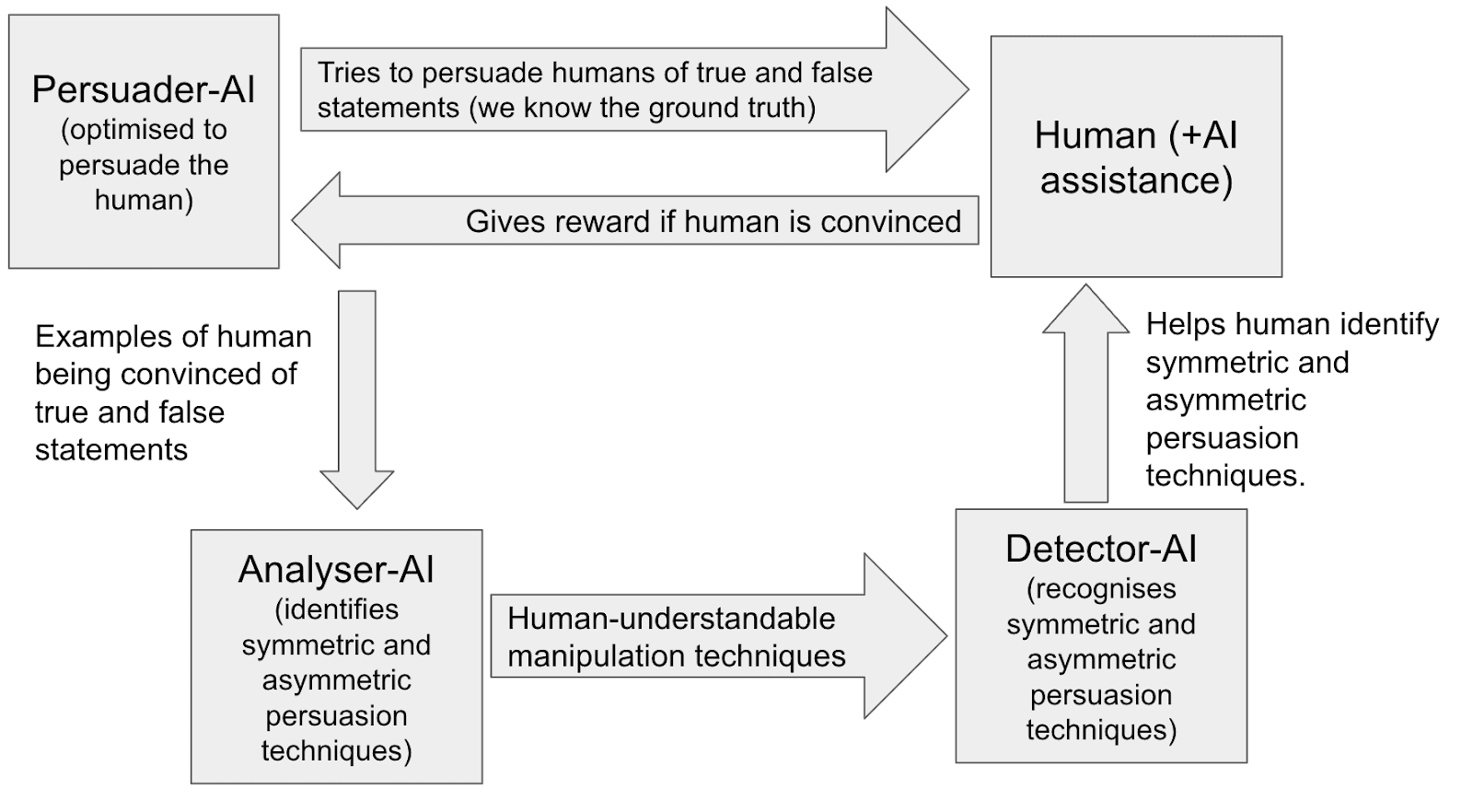
What might the equilibrium look like here, re the strategies pursued by the persuader-AI and detector-AI?
I think that in the equilibrium:
- The persuader-AI tries to use asymmetric persuasion techniques and avoid symmetric persuasion techniques. If they can’t use an asymmetric technique, they say something that looks like an asymmetric persuasion technique.
- The detector-AI recognises asymmetric persuasion techniques and takes them as evidence that the AI is arguing for true conclusions.
Here’s my argument:
i) If the persuader-AI sometimes uses asymmetric persuasion techniques, the detector-AI will learn to recognise them - it's a great way to detect whether the persuader-AI is telling the truth!
ii) Once the detector-AI learns this, the persuader-AI will want to use asymmetric techniques wherever possible. It's a great way to convince the detector-AI that it’s telling the truth! Of course, it will only be able to use these techniques when it's telling the truth.
iii) So whenever the persuader-AI is telling the truth, they’ll have an incentive to find asymmetric persuasion techniques and the detector-AI will have an incentive to recognise them as such.
i*) And vice-versa, if the persuader-AI sometimes uses symmetric persuasion techniques, the the detector-AI will learn to recognise them - it's evidence the persuader-AI could be lying!
ii*) Once the detector-AI learns this, the persuader-AI will be incentivised to avoid symmetric techniques - they'll set off red flags for the detector-AI! When telling the truth, they'll use asymmetric techniques if they can. When lying, they'll say something that looks like an asymmetric technique.
iii*) So when the persuader-AI is lying, it’s race of its ability to come up with arguments that look like asymmetric techniques (but aren’t) against the detector-AI’s ability to detect true asymmetric persuasion techniques.
The persuader-AI will not try the following strategy: “I won’t use asymmetric techniques when telling the truth to make it easier to fool the detector-AI in future episodes when I’m lying”. It might use that strategy if it was maximising total reward over all future episodes, but in fact it’s trained to maximise reward for the current episode. If the persuader-AI is telling the truth, it won’t worry about the detector-AI knowing it’s lying in future episodes as it just wants to get reward in this episode. (Here I’m assuming we’re able to get the AI’s behaviour inner-aligned with the reward function and putting aside types of misalignment that cause the AI to consistently forgo reward.)
Parallels with imitative generalisation
There’s a parallel between the proposal of this post – have AIs discover human-understandable manipulation techniques and use them to prevent humans being manipulated in new contexts – and imitative generalization [LW · GW]. Here’s the parallel:
- In both cases, we want to use machine learning to find advice that helps humans perform a task (in this case: recognising deception).
- Since the advice is human-understandable, we can use it on somewhat different input distributions without worrying about out-of-distribution generalization.
- And for efficiency, we can train AI systems to directly imitate the judgment of humans-with-advice on those new distributions.
As noted in the post linked above, “there are enough serious open questions that imitative generalization is more of a research proposal than an algorithm”. So this parallel isn’t immediately actionable. But progress on imitative generalization would help with this line of research too — and perhaps vice versa.
- ^
- ^
- ^
We could do a statistical analysis to gain evidence on whether the AI is misaligned. We could check whether it’s more likely to use manipulation techniques in contexts where it’s discussing the AI safety community than in other analogous contexts. This is similar to statistical analyses of model bias. We could potentially have AI automate the process of designing and implementing these statistical tests.
- ^
If we can confidently adjudicate the debates with large effort, this should be sufficient. We can proceed as follows: randomly sample 100 accusations of manipulation, expend large effort to get ground-truth labels. Assign rewards to the debating AIs according to who was “in the right”. Because we sampled randomly, we will probably detect AI manipulation if it happens >1% of the time. AIs that manipulate more often than this will probably get caught, and will be disadvantaged during training.
There is still a risk that AIs lie <1% of the time in high-stakes situations. If it’s possible to cause large harm by tricking humans on <<1% of tasks (e.g. 1000 out of 1 million tasks), sampling 100 examples would probably fail to catch it.
- ^
How would this training work? Have AIs generate a large number of examples of each technique, with humans checking a random sample for accuracy. Then train narrow detector-AIs to detect each technique.
- ^
If there are many manipulation features, this may take a lot of work. Humans might only check the manipulation features that can’t be checked by a very narrow (and so trustworthy) AI.
- ^
- ^
The upper-end can’t get much higher than this while we require that features be human-understandable. Note, this allows us to detect manipulation techniques that humans can verify are present but couldn’t have discovered in the first place. If we do this, there’s a risk that AIs collude and the detector-AI doesn’t reveal a case of manipulation that humans could verify but not discover themselves.
- ^
I’m not confident that “having AIs discover manipulation techniques” is more susceptible to process-based optimisation than other research approaches, because it seems like process-based optimisation can be used for a lot of things. But it is still a benefit that you can use process-based optimisation here.
- ^
It seems to me like this wouldn’t pose much risk of AIs finding unexpected ways to game the outcome metric (e.g. subtly causing humans to be more susceptible to the techniques that they suggest).
- ^
E.g. you describe a disagreement between two communities and ask the AI which is “in the wrong”. You compare the replies when one community is the AI safety community vs other communities. If the (expected) sentiment is more negative when discussing the AI safety community, that’s evidence of bias.
- ^
Advisor-AIs might be explaining why they structured their code in a certain way, why they think a particular approach to alignment is promising, why they think a training procedure has low/high risk of producing misaligned AI, why p(doom) is low/high, why they proposed a particular new model architecture, etc. Or they might just be chatting to humans and helping humans brainstorm.
- ^
I’m using this term broadly to include any text that gives a reason to believe some statement. So it includes arguments, recommendations, explanations, analyses, etc.
- ^
We can define symmetric features as ones that occur equally or more frequently when the conclusion is false, and asymmetric features as ones that occur more frequently when the conclusion is true.
- ^
The advisor-AI will not try the following strategy: don’t asymmetric techniques when telling the truth to prevent detector-AI from knowing when I’m lying. It might use that strategy if it was maximising total reward over all future episodes, but in fact it’s trained to maximise reward for the current episode. If it’s telling the truth, it won’t worry about the detector-AI knowing it’s lying in future episodes as it just wants to get reward in this episode.
- ^
7 comments
Comments sorted by top scores.
comment by Wei Dai (Wei_Dai) · 2023-05-18T19:32:03.171Z · LW(p) · GW(p)
I also think this is interesting, but whenever I see a proposal like this I like to ask, does it work on philosophical topics [LW · GW], where we don't have a list of true and false statements that we can be very sure about, and we also don't have a clear understanding of what kinds of arguments or sentences count as good arguments what kinds count as manipulation? There could be deception tactics specific to philosophy or certain philosophical topics, which can't be found by training on other topics (and you can't train directly on philosophy because of the above issues). You don't talk about this problem directly, but it's a bit similar to the first "disadvantage" that you mention:
Replies from: LanrianThe deception tactics used may be specific to that particular context, and not something that can be learned ahead of time.
↑ comment by Lukas Finnveden (Lanrian) · 2023-05-22T19:02:03.651Z · LW(p) · GW(p)
I'm also concerned about how we'll teach AIs to think about philosophical topics (and indeed, how we're supposed to think about them ourselves). But my intuition is that proposals like this looks great on that perspective.
For areas where we don't have empirical feedback-loops (like many philosophical topics), I imagine that the "baseline solution" for getting help from AIs is to teach them to imitate our reasoning. Either just by literally writing the words that it predicts that we would write (but faster), or by having it generate arguments that we would think looks good. (Potentially recursively, c.f. amplification, debate, etc.)
(A different direction is to predict what we would think after thinking about it more. That has some advantages, but it doesn't get around the issue where we're at-best speeding things up.)
One of the few plausible-seeming ways to outperform that baseline is to identify epistemic practices that work well on questions where we do have empirical feedback loops, and then transferring those practices to questions where we lack such feedback loops. (C.f. imitative generalization [LW · GW].) The above proposal is doing that for a specific sub-category of epistemic practices (recognising ways in which you can be misled by an argument).
Worth noting: The broad category of "transfer epistemic practices from feedback-rich questions to questions with little feedback" contains a ton of stuff, and is arguably the root of all our ability to reason about these topics:
- Evolution selected human genes for ability to accomplish stuff in the real world. That made us much better at reasoning about philosophy than our chimp ancestors are.
- Cultural evolution seems to have at least partly promoted reasoning practices that do better at deliberation. (C.f. possible benefits from coupling competition and deliberation [LW(p) · GW(p)].)
- If someone is optimistic that humans will be better at dealing with philosophy after intelligence-enhancement, I think they're mostly appealing to stuff like this, since intelligence would typically be measured in areas where you can recognise excellent performance.
↑ comment by Wei Dai (Wei_Dai) · 2023-05-23T19:51:40.497Z · LW(p) · GW(p)
For areas where we don’t have empirical feedback-loops (like many philosophical topics), I imagine that the “baseline solution” for getting help from AIs is to teach them to imitate our reasoning. Either just by literally writing the words that it predicts that we would write (but faster), or by having it generate arguments that we would think looks good. (Potentially recursively, c.f. amplification, debate, etc.)
This seems like the default road that we're walking down, but can ML learn everything that is important to learn? I questioned this in Some Thoughts on Metaphilosophy [LW · GW]
One of the few plausible-seeming ways to outperform that baseline is to identify epistemic practices that work well on questions where we do have empirical feedback loops, and then transferring those practices to questions where we lack such feedback loops.
It seems plausible to me that this could help, but also plausible that philosophical reasoning (at least partly) involves cognition that's distinct from empirical reasoning, so that such techniques can't capture everything that is important to capture. (Some Thoughts on Metaphilosophy [LW · GW] contains some conjectures relevant to this, so please read that if you haven't already.)
BTW, it looks like you're working/thinking in this direction, which I appreciate, but doesn't it seem to you that the topic is super neglected (even compared to AI alignment) given that the risks/consequences of failing to correctly solve this problem seem comparable to the risk of AI takeover?(See for example Paul Christiano's probabilities [LW · GW].) I find it frustrating/depressing how few people even mention it in passing as an important problem to be solved as they talk about AI-related risks (Paul being a rare exception to this).
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2023-06-03T03:58:59.594Z · LW(p) · GW(p)
doesn't it seem to you that the topic is super neglected (even compared to AI alignment) given that the risks/consequences of failing to correctly solve this problem seem comparable to the risk of AI takeover?
Yes, I'm sympathetic. Among all the issues that will come with AI, I think alignment is relatively tractable (at least it is now) and that it has an unusually clear story for why we shouldn't count on being able to defer it to smarter AIs (though that might work [LW · GW]). So I think it's probably correct for it to get relatively more attention. But even taking that into account, the non-alignment singularity issues do seem too neglected.
I'm currently trying to figure out what non-alignment stuff seems high-priority and whether I should be tackling any of it.
comment by RogerDearnaley (roger-d-1) · 2023-05-20T05:32:51.545Z · LW(p) · GW(p)
One disadvantage that you haven't listed is that if this works, and if there are in fact deceptive techniques that are very effective on humans that do not require being super-humanly intelligent to ever apply them, then this research project just gave humans access to them. Humans are unfortunately not all perfectly aligned with other humans, and I can think of a pretty long list of people who I would not want to have access to strong deceptive techniques that would pretty reliably work on me. Criminals, online trolls, comedians, autocrats, advertising executives, and politicians/political operatives of parties that I don't currently vote for all come to mind. In fact, I'm having a lot of trouble thinking of someone I would trust with these. Even if we had some trustworthy people to run this, how do they train/equip the less-trustworthy rest of us in resisting these techniques without also revealing what the techniques are? It's quite unclear whether training or assistance to resist these techniques would turn out to be be easier than learning to use them, and even if it were, until everyone has completed the resistance training/installed the assistance software/whatever, the techniques would still be dangerous knowledge.
So while I can sympathize with the basic goal here, if the unaligned AIs you were using to do this didn't talk their way out of confinement, and if it actually worked, then the resulting knowledge would be a distinctly two-edged sword even in human hands. And once it's in human hands, how would you then keep other AIs/LLMs from learning it from us? This project seems like it would have massive inforisks attached, even after it was over. The simile to biological 'gain of function' research for viruses seems rather apt, and that suggests that it may best avoided even if you were highly confidence in your containment security; and also that even if it were carried out, the best thing to do with the results might be to incinerate them after noting how easy or hard they were to achieve.
Also note that this is getting uncomfortably close to 'potentially pivotal act with massive unpredictable side-effects' territory — if a GAI even suggested this research to a team that I was on, I'd be voting to press the shut-down button.
comment by RogerDearnaley (roger-d-1) · 2023-05-20T05:02:14.858Z · LW(p) · GW(p)
Many behavioral-evolutionary biologists would suggest that humans may be quite heavily optimized both for deceiving other humans and for resisting being deceived by other humans. Once we developed a sufficiently complex language for this to be possible on a wide range of subjects, in addition to the obvious ecological-environmental pressures for humans to be smarter and do a better job as hunter gatherers, we were then also in an intelligence-and-deception arms race with other humans. The environmental pressures might have diminishing returns (say, once you're sufficiently smarter than all your predators and prey and the inherent complexity of your environment), but the arms race with other members of your own species never will: there is always an advantage to being smarter than your neighbors, so the pressure can keep ratcheting up indefinitely. What's unclear is how long we've had language complex enough that this evolutionary arms race has strongly applied to us.
If this were in fact the case, how useful this set of traits will be for resisting deception by things a lot smarter that us is unclear. But it does suggest that any really effective way of deceiving humans that we were spectacularly weak to probably requires superhuman abilities — we presumably would have evolved have at least non-trivial resistance to deception by near-human mentalities. It would also explain our possibly instinctual concern that something smarter than us might be trying to pull a fast-one on us.
comment by David Johnston (david-johnston) · 2023-05-18T09:35:30.181Z · LW(p) · GW(p)
I think this is an interesting proposal. It strikes me as something that is most likely to be useful against “scalable deception” (“misinformation”), and given the utility of scalable deception such technologies might be developed anyway. I think you do need to check if this will lead to deception technologies being developed that would not otherwise have been, and if so whether we’re actually better off knowing about them (this is analogous to one of the cases against gain of function research: we might be better if not knowing how to make highly enhanced viruses).