Posts
Comments
Sharing https://earec.net, semantic search for the EA + rationality ecosystem. Not fully up to date, sadly (doesn't have the last month or so of content). The current version is basically a minimal viable product!
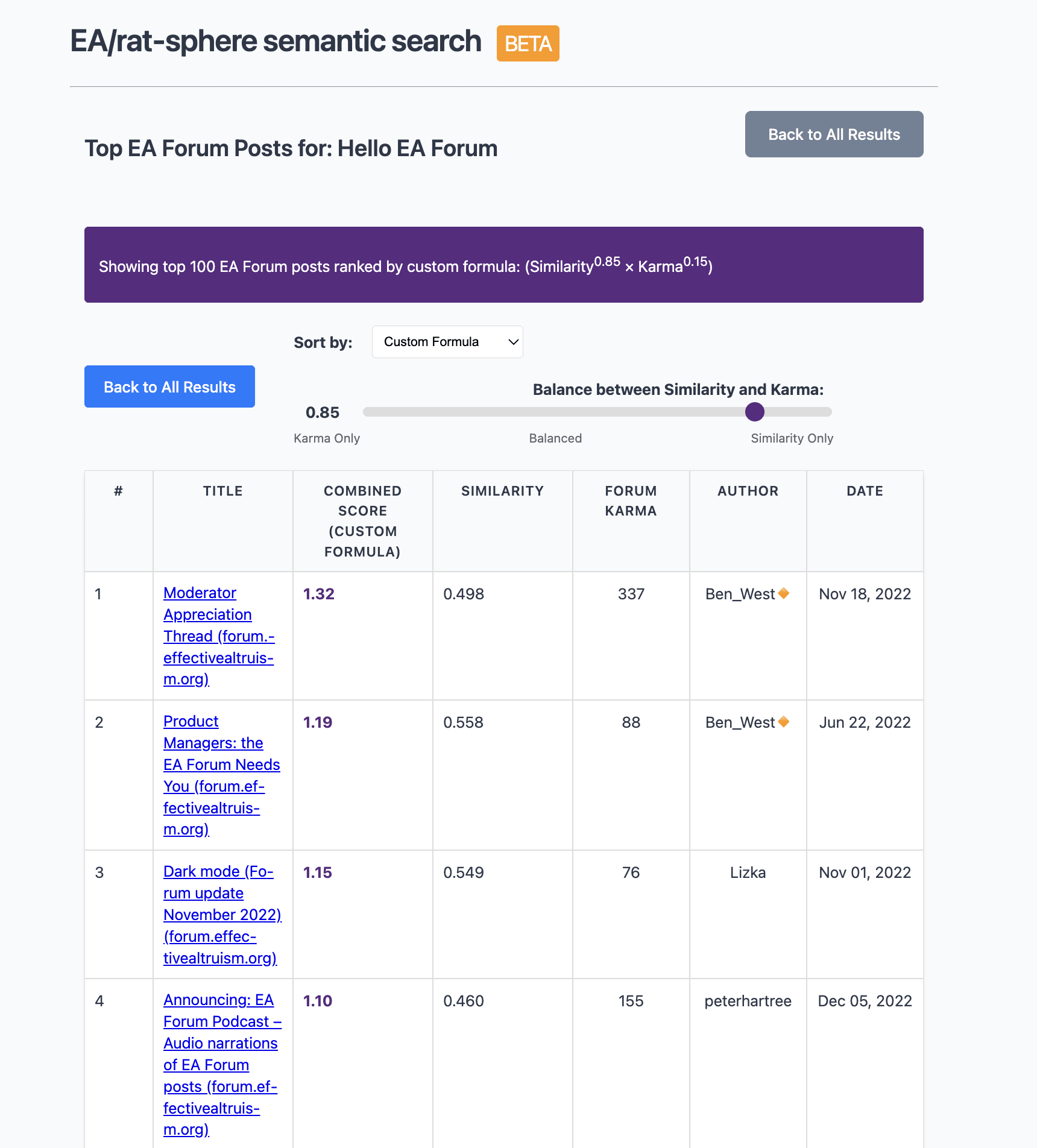
On the results page there is also an option to see EA Forum only results which allow you to sort by a weighted combination of karma and semantic similarity thanks to the API.
Unfortunately there's no corresponding system for LessWrong because of (perhaps totally sensible) rate limits (the EA Forum offers a bots site for use cases like this with much more permissive access).
Final feature to note is that there's an option to have gpt-4o-mini "manually" read through the summary of each article on the current screen of results, which will give better evaluations of relevance to some query (e.g. "sources I can use for a project on X") than semantic similarity alone.
Still kinda janky - as I said, minimal viable product right now. Enjoy and feedback is welcome!
Thanks to @Nathan Young for commissioning this!
I mean the reason is that I've never heard of that haha. Perhaps it should be
Ngl I did not fully understand this, but to be clear I don't think understanding alignment through the lense of agency is "excessively abstract." In fact I think I'd agree with the implicit default view that it's largely the single most productive lense to look through. My objection to the status quo is that it seems like the scale/ontology/lense/whatever I was describing is getting 0% of the research attention whereas perhaps it should be getting 10 or 20%.
Not sure this analogy works, but if NIH was spending $10B on cancer research, I would (prima facie, as a layperson) want >$0 but probably <$2B spent on looking at cancer as an atomic-scale phenomenon, and maybe some amount at an even lower-scale scale
Note: I'm probably well below median commenter in terms of technical CS/ML understanding. Anyway...
I feel like a missing chunk of research could be described as “seeing DL systems as ‘normal,’ physical things and processes that involve electrons running around inside little bits of (very complex) metal pieces” instead of mega-abstracted “agents.”
The main reason this might be fruitful is that, at least intuitively and to my understanding, failures like “the AI stops just playing chess really well and starts taking over the world to learn how to play chess even better” involve a qualitative change beyond just “the quadrillion parameters adjust a bit to minimize loss even more” that eventually cashes out in some very different way that literal bits of metal and electrons are arranged.
And plausibly abstracting away from the chips and electrons means ignoring the mechanism that permits this change. Of course, this probably only makes sense if something resembling deep learning scales to AGI, but it seems that some very smart people think that it may!
Banneker Key! Yeah I was in a very similar position, but basically made the opposite choice (largely because financial costs not internalized)
Yeah that's gotta be it, nice catch!
One answer to the question for me:
While writing, something close to "how does this 'sound' in my head naturally, when read, in an aesthetic sense?"
I've thought for a while that "writing quality" largely boils down to whether the writer has an intuitively salient and accurate intuition about how the words they're writing come across when read.
Ah late to the party! This was a top-level post aptly titled "Half-baked alignment idea: training to generalize" that didn't get a ton of attention.
Thanks to Peter Barnett and Justis Mills for feedback on a draft of this post. It was inspired by Eliezer's Lethalities post and Zvi's response.
Central idea: can we train AI to generalize out of distribution?
I'm thinking, for example, of an algorithm like the following:
- Train a GPT-like ML system to predict the next word given a string of text only using, say, grade school-level writing (this being one instance of the object level)
- Assign the system a meta-level award based on how well it performs (without any additional training) at generalizing; in this case, that is, predicting the next word from more advanced, complex writing (perhaps using many independent tests of this task without updating/learning between each test, and allowing parameters to update only after the meta-level aggregate score is provided)
- Note: the easy→hard generalization is not a necessary feature. Generalization could be from fiction→nonfiction writing or internet→native print text, for instance.
- After all these independent samples are taken, provide the AI its aggregate or average score as feedback
- (Maybe?) repeat all of step I on a whole new set of training and testing texts (e.g., using text from a different natural language like Mandarin)
- Repeat this step an arbitrary number of times
- For example, using French text, then Korean, then Arabic, etc.
- Each time a “how well did you generalize” score is provided (which is given once per natural language in this example), the system should improve at the general task of generalizing from simple human writing to more complex human writing, (hopefully) to the point of being able to perform well at generalizing from simple Hindi (or whatever) text to advanced Hindi prediction even if it had never seen advanced Hindi text before.
- ^Steps 1-3 constitute the second meta-level of training an AI to generalize, but we can easily treat this process as a single training instance (e.g., rating how well the AI generalizes to Hindi advanced text after having been trained on doing this in 30 other languages) and iterate over and over again. I think this would look like:
- Running the analogs of steps 1-4 on generalizing from
- (a) simple text to advanced text in many languages
- (b) easy opponents to hard ones across many games,
- (c) photo generation of common or general objects ("car") to rare/complex/specific ones ("interior of a 2006 Honda Accord VP"), across many classes of object
- And (hopefully) the system would eventually be able to generalize from simple Python code training data to advanced coding tasks even though it had never seen any coding at all before this.
And, of course, we can keep on adding piling layers on.
A few notes
- I think the following is one way of phrasing what I hope might happen with method: we are using RL to teach an ML system how to do ML in such a way that it sacrifices some in-distribution predictive power for the ability to use its “knowledge” more generally without doing anything that seems dumb to us.
- Of course, there are intrinsic limits to any system’s ability to generalize. The system in question can only generalize using knowledge X if X exists as information in the object-level training provided to it.
- This limits what we should expect of the system.
- For example, I am almost certain that even an arbitrarily smart system will not be able to generate coherent Mandarin text from English training data, because the meaning of Mandarin characters doesn’t exist as “latent knowledge” in even a perfect understanding of English.
Anyone here know Python?
My hands-on experience with ML extends to linear regression in R and not an inch more, so I'm probably not the best person to test this theory out. I've heard some LWers know a bit of Python, though.
If that's you, I'd be fascinated and thankful to see if you can implement this idea using whatever data and structure you think would work best, and would be happy to collaborate in whatever capacity I can.
Appendix: a few brief comments (from someone with much more domain knowledge than me) and responses (from me):
Comment
Is this just the same as training it on this more complex task (but only doing one big update at the end, rather than doing lots of small updates)?
Response (which may help to clarify why I believe the idea might work)
I don't think so, because the parameters don't change/update/improve between each of those independent tests. Like GPT-3 in some sense has a "memory" of reading Romeo and Juliet, but that's only because its parameters updated as a result of seeing the text.
But also I think my conception depends on the system having "layers" of parameters corresponding to each layer of training.
So train on simple English-->only "Simple English word generation" parameters are allowed to change...but then you tell it how well it did at generalizing out of distribution, and now only its "meta level 1 generalization" parameters are allowed to change.
Then you do the whole thing again but with German text, and its "Meta level 1 generalization" parameters are allowed to change again using SGD or whatever. If this works, it will be the reason why it can do well at advanced Hindi text without ever having read advanced Hindi.
Treat this whole process as the object level, and then it updates/improves "meta level 2 generalization" parameters.
Comment:This looks vaguely like curriculum learning, which apparently doesn't really work in LLMs https://arxiv.org/abs/2108.02170, I think a similar experiment would be like train on simple+advanced text for English, French, Mandarin etc, but only simple Hindi, and then see if it can do complex Hindi.
Response
I think that's a pretty different thing because there are no meta level parameters. Seems like fundamentally just a flavor of normal RL
Or do pretraining with English, French, Mandarin, and Hindi, but only do fine tuning with English, French, Mandarin, and see if it can then do the tasks it was fine tuned for in Hindi.
My prediction: it learns to generalize a bit (the scores on the novel Hindi tasks are higher than if there was no fine tuning with the other languages) but worse than the other languages generalize. As the models are scaled up, this 'generalization gap' gets smaller.
Seems like this might depend on the relative scaling of different meta level parameters (which I described above)?
Like for example whenever you scale the # of object level params by a factor of 2, you have to scale the number of nth meta level parameters by 2^(n+1).
Thank you, Solenoid! The SSC podcast is the only reason I to consume all of posts like Biological Anchors: A Trick That Might Or Might Not Work
Thanks. It's similar in one sense, but (if I'm reading the paper right) a key difference is that in the MAML examples, the ordering of the meta-level and object level training is such that you still wind up optimizing hard for a particular goal. The idea here is that the two types of training function in opposition, as a control system of sorts, such that the meta-level training should make the model perform worse at the narrow type of task it was trained on.
That said, for sure, the types of distribution shift thing is an issue. It seems like this meta-level bias might be less bad than at the object level, but I have no idea.
Training to generalize (and training to train to generalize, etc.)
Inspired by Eliezer's Lethalities post and Zvi's response:
Has there been any research or writing on whether we can train AI to generalize out of distribution?
I'm thinking, for example:
- Train a GPT-like ML system to predict the next word given a string of text only using, say, grade school-level writing (this is one instance of the object level
- Assign the system a meta-level award based on how well it performs (without any additional training) at generating the next word from more advanced, complex writing (likely using many independent tests of this task)
- After all these independent samples are taken, provide the its aggregate or average score as feedback
- (Maybe?) repeat steps I and I.I on a whole new set of training and testing texts (e.g., using text from a different natural language like Mandarin), and do this step and arbitrary number of times
- Repeat this step using French text, then Korean, then Arabic, etc.
- After each of the above steps, the system should (I assume) improve at the general task of generalizing from simple human writing to more complex human writing, (hopefully) to the point of being able to perform well at generalizing from simple Hindi (or whatever) text to advanced Hindi prediction even if it had never seen advanced Hindi text before.
- ^Steps 1-3 constitute the second meta-level of training an AI to generalize, but we can easily treat this process as a single training instance (e.g., rating how well the AI generalizes to Hindi advanced text after having been trained on doing this in 30 other languages) and iterate over and over again. I think this would look like:
- Running the analogs of steps 1-4 on generalizing from
- (a) simple text to advanced text in many languages
- (b) easy opponents to hard ones across many games,
- (c) photo generation of common or general objects ("car") to rare/complex/specific ones ("interior of a 2006 Honda Accord VP"), across many classes of object
- And (hopefully) the system would eventually be able to generalize from simple python code training data to advanced coding tasks even though it had never seen any coding at all before this.
- Running the analogs of steps 1-4 on generalizing from
And, of course, we can keep on adding piling layers on.
A few minutes of hasty Googling didn't turn up anything on this, but it seems pretty unlikely to be an original idea. But who knows! I wanted to get the idea written down and online before I had time to forget about it.
On the off chance it hasn't been beaten thought about to death yet by people smarter than myself, I would consider together longer, less hastily written post on the idea
MichaelStJules is right about what I meant. While it's true that preferring not to experience something doesn't necessarily imply that the thing is net-negative, it seems to me very strong evidence in that direction.
Entirely agree. There are certainly chunks of my life (as a privileged first-worlder) I'd prefer not to have experienced, and these generally these seem less bad than "an average period of the same duration as a Holocaust prisoner." Given that animals are sentient, I'd put it at at ~98% that their lives are net negative.
Good point; complex, real world questions/problems are often not Googleable, but I suspect a lot of time is spent dealing with mundane, relatively non-complex problems. Even in your example, I bet there is something useful to be learned from Googling "DIY cabinet instructions" or whatever.
Interesting, but I think you're way at the tail end of the distribution on this one. I bet I use Google more than 90%+ of people, but still not as much as I should.
Yes - if not heretical, at least interesting to other people! I'm going to lean into the "blogging about things that seem obvious to me" thing now.
Fair enough, this might be a good counterargument though I'm very unsure. How much do mundane "brain workouts" matter? Tentatively, the lack of efficacy of brain training programs like Luminosity would suggest that they might not be doing much.
The if long COVID usually clears up after eight weeks, that would definitely weaken my point (which would be good news!) I haven’t decided if it would change my overall stance on masking though
Good point. Implicitly, I was thinking “wearing masks while indoors within ~10 feet of another person or outdoors if packed together like at a rally or concert”
I think so, thanks!
Good idea, think I will.
I've been wondering the exact same thing, thanks for asking.
Would you be willing to post this as a general post on the main forum? I think lots of people including myself would appreciate!
Thanks, but I have hardly any experience with Python. Need to start learning.
Yup, fixing. Gotta get better at proofreading.
From my perspective, this is why society at large needs to get better at communicating the content - so you wouldn't have to be good at "anticipating the content."
The meaningfulness point is interesting, but I'm not sure I fully agree. Some topics can me meaningful but not interesting (high frequency trading to donate money) and visa-versa (video game design? No offense to video game designers).
By your description, it feels like the kind of book where an author picks a word and then rambles about it like an impromptu speaker. If this had an extraordinary thesis requiring extraordinary evidence like Manufacturing Consent then lots of anecdotes would make sense. But the thesis seems too vague to be extraordinary.
I get the impression of the kind of book which where a dense blogpost is stretched out to the length of a book. This is ironic for a book about subtraction.
Yup, very well-put.
Your point about anecdotes got me thinking; an "extraordinary thesis" might be conceptualized as claiming that the distribution of data significantly shifted away from some "obvious" average. If so, showing the existence of a few data points greater than, say, 4 standard deviations from the "obvious" average actually can be strong evidence in its favor. However, the same is not true for a few examples ~2 standard deviations away. Maybe Klotz's error is using anecdotes that aren't far enough away from what intuitively makes sense.
Probably didn't explain that very well, so here is a Tweet from Spencer Greenberg making the point:
1. By Bayes Factor: suppose hypothesis “A” says a data point is nearly impossible, and hypothesis “B” says the data point is quite likely. Then the existence of that one data point (by Bayes’ rule) should move you substantially toward believing hypothesis B (relative to A).
Example: you have had a rash on your arm for 10 years (with no variability). You buy some “rash cream” off of a shady website, and within 2 hours of applying it, the rash is gone. You can be confident the cream works because it’s otherwise highly unlikely for the rash to vanish.
Looks like I’m in good company!
I don't think it is operationalizable, but I fail to see why 'net positive mental states' isn't a meaningful, real value. Maybe the units would be apple*minutes or something, where one unit is equivalent to the pleasure you get by eating an apple for one minute. It seems that this could in principle be calculated with full information about everyone's conscious experience.
Are you using 'utility' in the economic context, for which a utility function is purely ordinal? Perhaps I should have used a different word, but I'm referring to 'net positive conscious mental states,' which intuitively doesn't seem to suffer from the same issues.
Interesting, thanks. Assuming this effect is real, I wonder how much is due to the physical movement of walking rather than the low-level cognitive engagement associated with doing something mildly goal-oriented (i.e. trying to reach a destination), or something else.
Thanks for your perspective.
I've never been able to do intellectual work with background music, and am baffled by people e.g. programmers who work with headphones playing music all day. But maybe for them it does just use different parts of the brain
For me, there is a huge qualitative difference between lyrical music or even "interesting" classical and electronic music, and very "boring," quiet lyric-less music. Can't focus at all listening to lyrics, but soft ambient music feels intuitively helpful (though this could be illusory). This is especially the case when its a playlist or song I've heard a hundred times before, so the tune is completely unsurprising.
Yes, I was incorrect about Matuschak's position. He commented on reddit here:
"I think Matuschak would say that, for the purpose of conveying information, it would be much more efficient to read a very short summary than to read an entire book."
FWIW, I wouldn't say that! Actually, my research for the last couple years has been predicated on the value of embedding focused learning interactions (i.e spaced repetition prompts) into extended narrative. The underlying theory isn't (wasn't!) salience-based, but basically I believe that strong understanding is produced with a rich network of connections and a meaningful emotional connection, both of which are promoted by narrative (but usually not by a very short summary).
Super interesting and likely worth developing into a longer post if you're so inclined. Really like this analogy.
Great post and thanks for linking to it! Seems like books' function and utility has gotten more attention than I would have expected.
But then readers would have to repeat this sentence for as long as it takes to read the blog post to get the same effect. Not quite as fun.
Yes this is an excellent point; books increase the fidelity of idea transmission because they place something like a bound on how much an idea can be misinterpreted, since one can always appeal to the author's own words (much more than a blog post or Tweet).
It’s not that individual journalists don’t trust Wikipedia, but that they know they can’t publish an article in which a key fact comes directly from Wikipedia without any sort of corroboration. I assume, anyway. Perhaps I’m wrong.
Great post! Is ego depletion just another way of conceptualizing rising marginal cost of effort? Like, maybe it is a fact of human psychology that the second hour of work is more difficult and unpleasant than the first.
I don't know much more than you could find searching around r/nootropics, but my sense is that the relationship between diet and cognition is highly personal, so experimentation is warranted. Some do best on keto, others as a vegan, etc. With respect to particular substances, it seems that creatine might have some cognitive benefits, but once again supplementation is highly personal. DHA helps some people and induces depression in others, for example.
Also, inflammation is a common culprit/risk factor for many mental issues, so I'd expect that a generally "healthy" diet (at least, not the standard American diet), and perhaps trying an elimination diet to see if eliminating certain foods produces a marked benefit could be helpful. Supplements like resveratrol might help with this as well. Also might be worth experimenting with fasting of different lengths; some people find that they become extremely productive after fasting for 12-14 hours. There are a million studies on all these topics that will come up in a Google search.
Yes, you're correct. As others have correctly noted, there is no unambiguous way of determining which effects are "direct" and which are not. However, suppose decriminalization does decrease drug use. My argument emphasizes that we would need to consider the reduction in time spent enjoying drugs as a downside to decriminalization (though I doubt this would outweigh the benefits associated with lower incarceration rates). It seems to me that this point would frequently be neglected.
There is a good amount of this discussion at r/nootropics - of which some is evidence based and some is not. For example, see this post.
Thanks very much. Just fixed that.
This is a good point. Could also be that discussing only points that might impact oneself seems more credible and less dependent on empathy, even if one really does care about others directly.
Fair point, but you'd have to think that the tendencies of the patent officers changed over time in order to foreclose that as a good metric.
I meant objective in the sense that the metric itself is objective, not that it is necessarily a good indicator of innovation. Yes, you're right. I do like Cowen and Southewood's method of only looking at patents registered all of the U.S., Japan, and E.U.
Basically agree with this suggestion: broader metrics are more likely to be unbiased over time. Even the electric grid example, though, isn't ideal because we can imagine a future point where going from $0.0001 to $0.000000001 per kilowatt-hour, for example, just isn't relevant.
Total factor productivity and GDP per capita are even better, agreed.
While a cop-out, my best guess is that a mixture of qualitative historical assessments (for example, asking historians, entrepreneurs, and scientists to rank decades by degree of progress) and using a variety of direct and indirect objective metrics (ex. patent rates, total factor productivity, cost of energy, life expectancy) is the best option. Any single or small group of metrics seems bound to be biased in one way or another. Unfortunately, it's hard to figure out how to weight and compare all of these things.
Thank you! Should have known someone would have beat me to it.
I was thinking the third bullet, though the question of perverse incentives needs fleshing out, which I briefly alluded to at the end of the post:
“Expected consequences”, for example, leaves under-theorized when you should seek out new, relevant information to improve your forecast about some action’s consequences.
My best guess is that this isn't actually an issue, because you have a moral duty to seek out that information, as you know a priori that seeking out such info is net-positive in itself.