Posts
Comments
I want to add that both static word embeddings (like w2v or glove) and token embeddings from Transformer-based models tend to fill a high dimensional simplex, where each of the "corners" (cones adjustment to the vertices of that simplex) filled with words with high specificity and well-formed context, and the rest of words/tokens fill the volume of that simplex.
It's hard to catch these structures by PCA or t-SNE, but once you find the correct projection, the structure reveals itself (to do so, you have to find three actual vertices, draw a plane through them, and project everything on it):
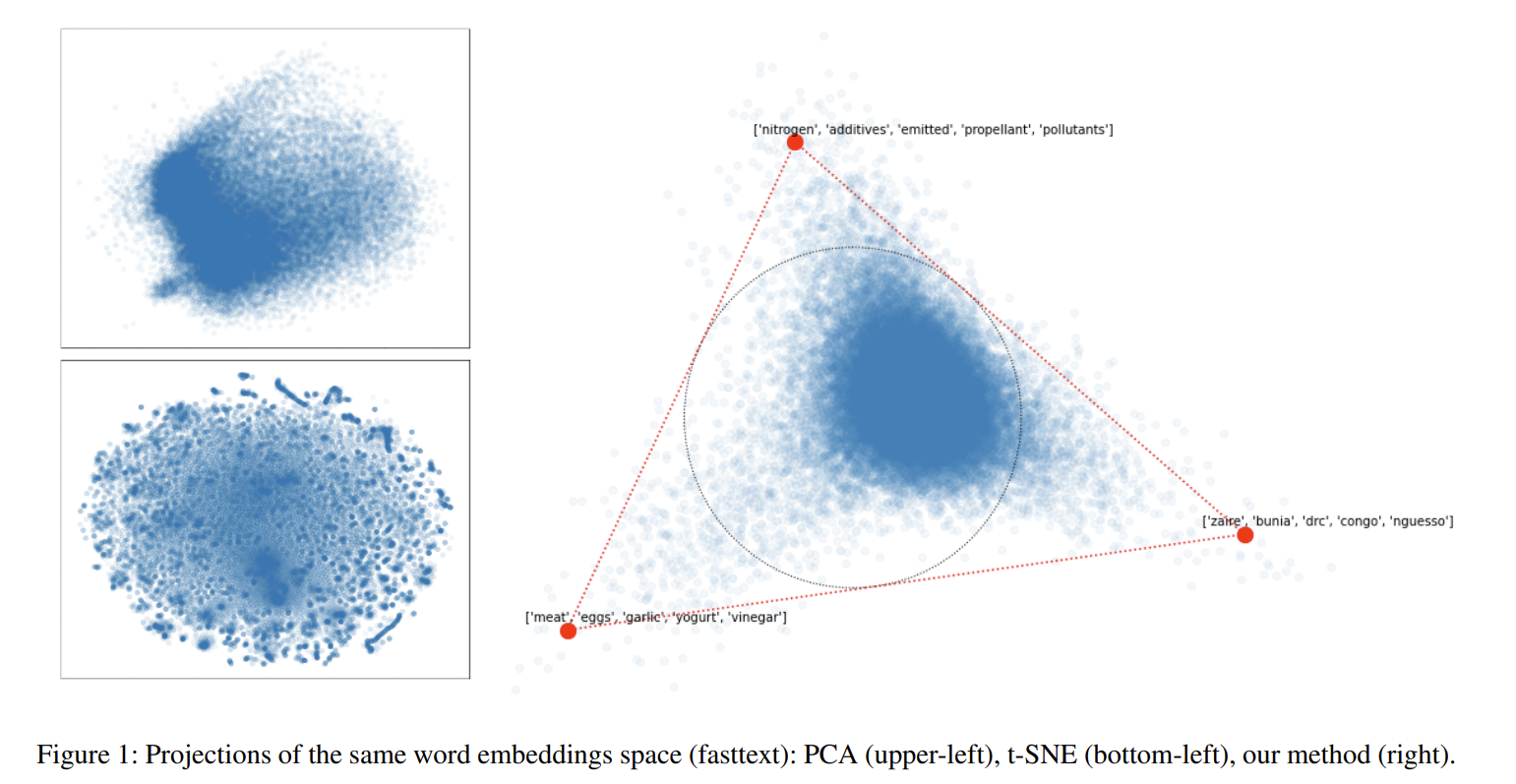
(from https://arxiv.org/abs/2106.06964)
Note the center of this simplex is not in the origin of the embedding space, there is a bias parameter in the linear projection of the token embedding vectors, so the weird tokens from the post probably do have the smallest norm after extracting that bias vector.
Overall, these tokens are probably ones which are never occurred in the training data at all. They have random embeddings initially, and then cross-entropy loss always penalizes them in any context, so they are knocked down to the center of the cloud.