Posts
Comments
Hi Lawrence! Thanks so much for this comment and for spelling out (with the math) where and how our thinking and dataset construction were poorly setup. I agree with your analysis and critiques of the first dataset. The biggest problem with that dataset in my eyes (as you point out): the true actual features in the data are not the ones that I wanted them to be (and claimed them to be), so the SAE isn't really learning "composed features."
In retrospect, I wish I had just skipped onto the second dataset which had a result that was (to me) surprising at the time of the post. But there I hadn't thought about looking at the PCs in hidden space, and didn't realize those were the diagonals. This makes a lot of sense, and now I understand much better why the SAE recovers those.
My big takeaway from this whole post is: I need to think on this all a lot more! I've struggled a lot to construct a dataset that successfully has some of the interesting characteristics of language model data and also has interesting compositions / correlations. After a month of playing around and reflection, I don't think the "two sets of one-hot features" thing we did here is the best way to study this kind of phenomenon.
Hi Demian! Sorry for the really slow response.
Yes! I agree that I was surprised that the decoder weights weren't pointing diagonally in the case where feature occurrences were perfectly correlated. I'm not sure I really grok why this is the case. The models do learn a feature basis that can describe any of the (four) data points that can be passed into the model, but it doesn't seem optimal either for L1 or MSE.
And -- yeah, I think this is an extremely pathological case. Preliminary results look like larger dictionaries finding larger sets of features do a better job of not getting stuck in these weird local minima, and the possible number of interesting experiments here (varying frequency, varying SAE size, varying which things are correlated) is making for a pretty large exploration space.
Hi Ali, sorry for my slow response, too! Needed to think on it for a bit.
- Yep, you could definitely generate the dataset with a different basis (e.g., [1,0,0,0] = 0.5*[1,0,1,0] + 0.5*[1,0,-1,0]).
- I think in the context of language models, learning a different basis is a problem. I assume that, there, things aren't so clean as "you can get back the original features by adding 1/2 of that and 1/2 of this". I'd imagine it's more like feature1 = "the in context A", feature 2 = "the in context B", feature 3 = "the in context C". And if the is a real feature (I'm not sure it is), then I don't know how to back out the real basis from those three features. But I think this points to just needing to carry out more work on this, especially in experiments with more (and more complex) features!
- Yes, good point, I think that Demian's post was worried about some features not being learned at all, while here all features were learned -- even if they were rotated -- so that is promising!
Hi Logan! Thanks for pointing me towards that post -- I've been meaning to get around to reading it in detail and just finally did. Glad to see that the large-N limit seems to get perfect reconstruction for at least one similar toy experiment! And thanks for sharing the replication code.
I'm particularly keen to learn a bit more about the correlated features -- did you (or do you know of anyone) who has studied toy models where they have a few features that are REALLY correlated with one another, and that basically never appear with other features? I'm wondering if such features could bring back the problem that we saw here, even in a very high-dimensional model / dataset. Most of the metrics in that post are averaged over all features, so don't really differentiate between correlated or not, etc.
Thanks for the comment! Just to check that I understand what you're saying here:
We should not expect the SAE to learn anything about the original choice of basis at all. This choice of basis is not part of the SAE training data. If we want to be sure of this, we can plot the training data of the SAE on the plane (in terms of a scatter plot) and see that it is independent of any choice of bases.
Basically -- you're saying that in the hidden plane of the model, data points are just scattered throughout the area of the unit circle (in the uncorrelated case) and in the case of one set of features they're just scattered within one quadrant of the unit circle, right? And those are the things that are being fed into the SAE as input, so from that perspective perhaps it makes sense that the uncorrelated case learns the 45 angle vectors, because that's the mean of all of the input training data to the SAE. Neat, hadn't thought about it in those terms.
This, to me, seems like a success of the SAE.
I can understand this lens! I guess I'm considering this a failure mode because I'm assuming that what we want SAEs to do is to reconstruct the known underlying features, since we (the interp community) are trying to use them to find the "true" underlying features in e.g., natural language. I'll have to think on this a bit more. To your point -- maybe they can't learn about the original basis choice, and I think that would maybe be bad?
Ah! That's the context, thanks for the clarification and for pointing out the error. Yes "problems" should say "prompts"; I'll edit the original post shortly to reflect that.
Oh! You're right, thanks for walking me through that, I hadn't appreciated that subtlety. Then in response to the first question: yep! CE = KL Divergence.
After seeing this comment, if I were to re-write this post, maybe it would have been better to use the KL Divergence over the simple CE metric that I used. I think they're subtly different.
Per the TL implementation for CE, I'm calculating: CE = where is the batch dimension and is context position.
So CE = for the baseline probability and the patched probability.
So this is missing a factor of to be the true KL divergence.
I think this is most of what the layer 0 SAE gets wrong. The layer 0 SAE just reconstructs the activations after embedding (positional + token), so the only real explanation I see for what it's getting wrong is the positional embedding.
But I'm less convinced that this explains later layer SAEs. If you look at e.g., this figure:
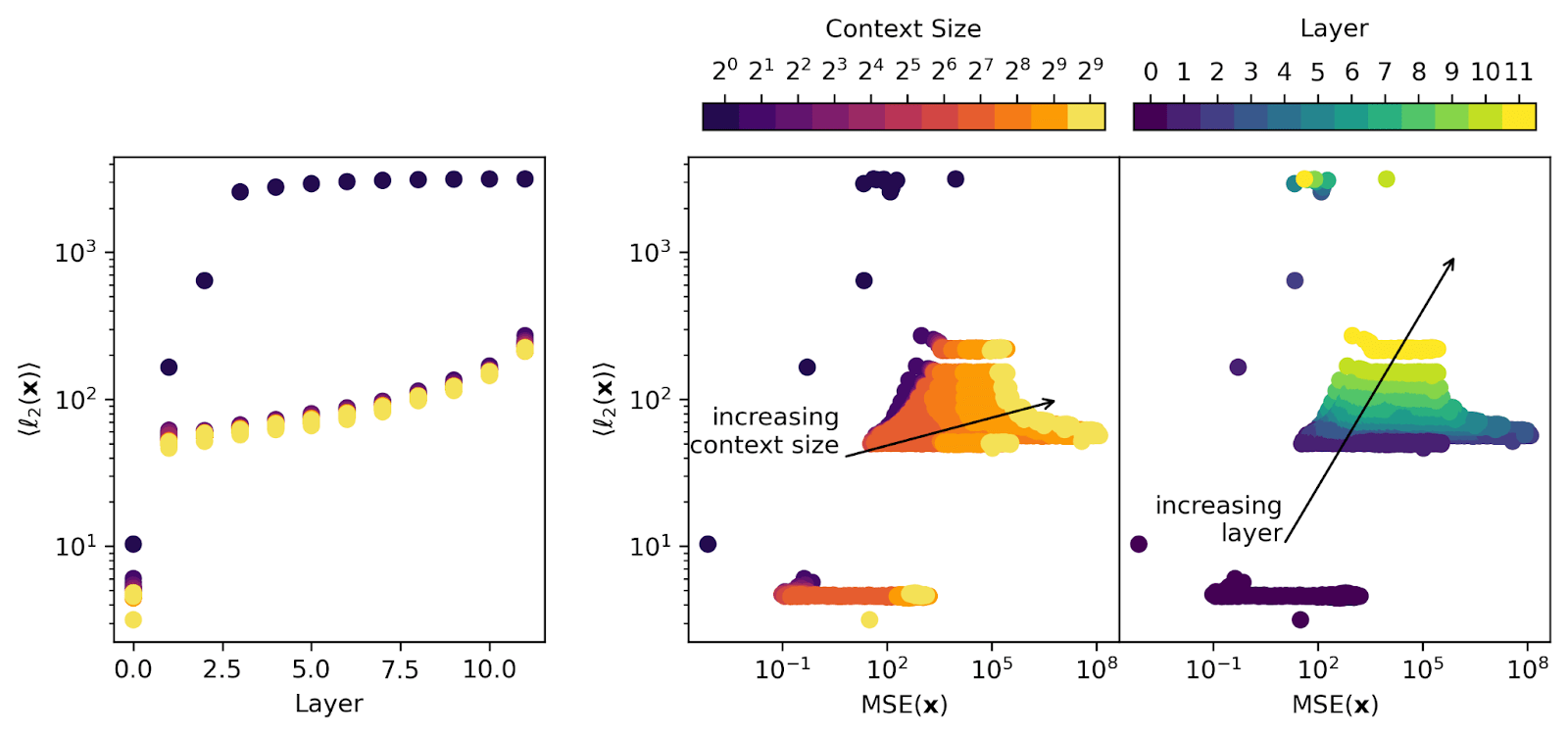
then you see that the layer 0 model activations are an order of magnitude smaller than any later-layer activations, so the positional embedding itself is only making up a really small part of the signal going into the SAE for any layer > 0 (so I'm skeptical that it's accounting for a large fraction of the large MSE that shows up there).
Regardless, this seems like a really valuable test! It would be fun to see what happens if you just feed the token embedding into the SAE and then add in the positional embedding after reconstructing the token embedding. I'd naively assume that this would go poorly -- if the SAE for layer 0 learns concepts more complex than just individual token embeddings, I think that would have to be the result of mixing positional and token embeddings?
For me, this was actually a positive update that SAEs are pretty good on distribution -- you trained SAE on length 128 sequences from OpenWebText, and the log loss was quite low up to ~200 tokens! This is despite its poor downstream use case performance.
Yes, this was nice to see. I originally just looked at context positions at powers of 2 (...64, 128, 256,...) and there everything looked terrible above 128, but Logan recommended looking at all context positions and this was a cool result!
But note that there's a layer effect here. I think layer 12 is good up to ~200 tokens while layer 0 is only really good up to the training context size. I think this is most clear in the MSE/L1 plots (and this is consistent with later layers performing ok-ish on the long context CBT while early layers are poor).
This means they're somewhat problematic for OOD use cases like treacherous turn detection or detecting misgeneralization.
Yeah, agreed, which is a bummer because that's one thing I'd really like to see SAEs enable! Wonder if there's a way to change the training of SAEs to shift this over to on-distribution where they perform well.
As an aside, am I reading this plot incorrectly, or does the figure on the right suggest that SAE reconstructed representations have lower log loss than the original unmodified model?
Oof, that figure does indeed suggest that, but it's because of a bug in the plot script. Thank you for pointing that out, here's a fixed version:
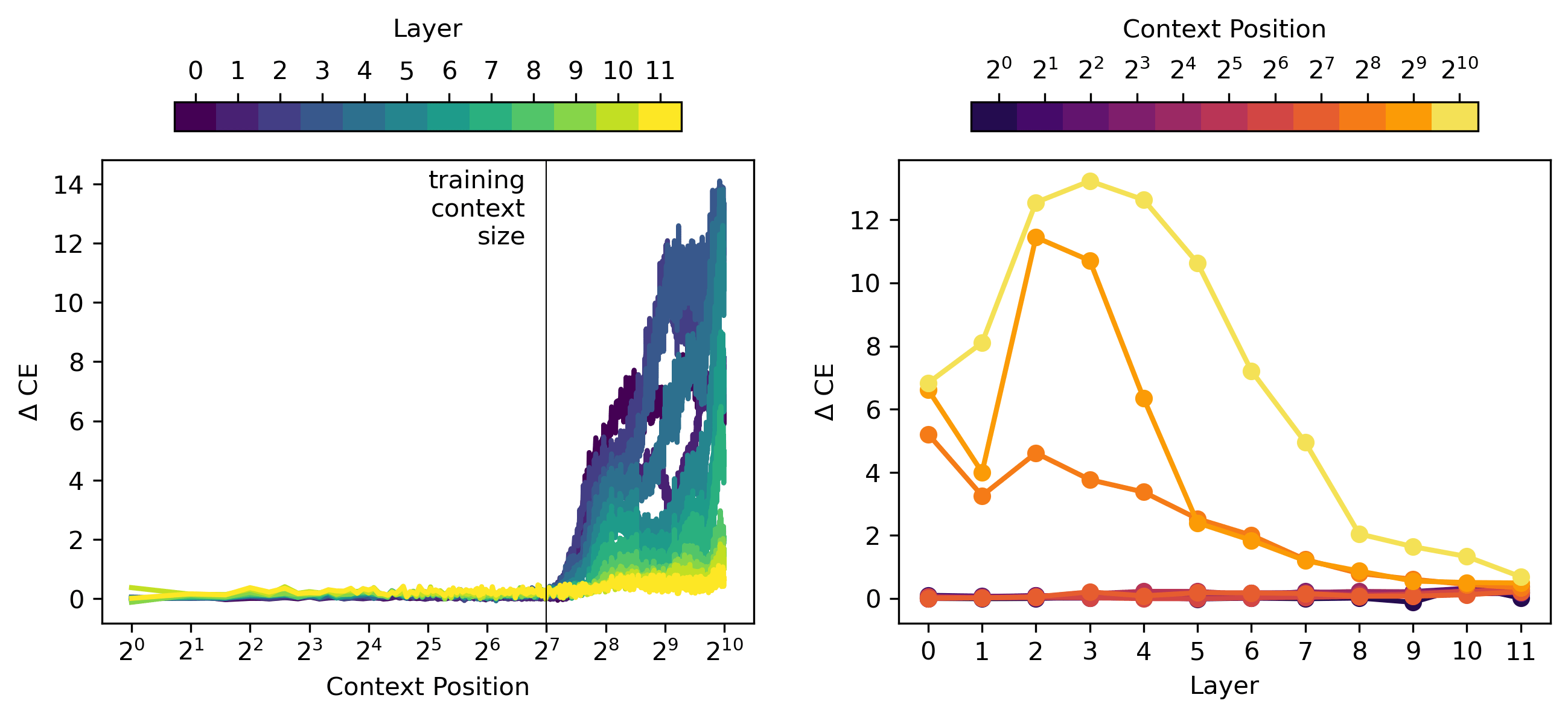
I've fixed the repo and I'll edit the original post shortly.