Posts
Comments
>APS is less understood and poorly forecasted compared to AGI.
I disagree with this. I have come to dislike the term AGI because (a) its meaning is so poorly defined, (b) the concept most people have in mind will never be achieved, nor needs to be to get to the capability level that is necessary for catastrophic scenarios, and (c) the concept of "AGI" doesn't get at the part of advanced AI that is relevant for reasoning about x-risk.
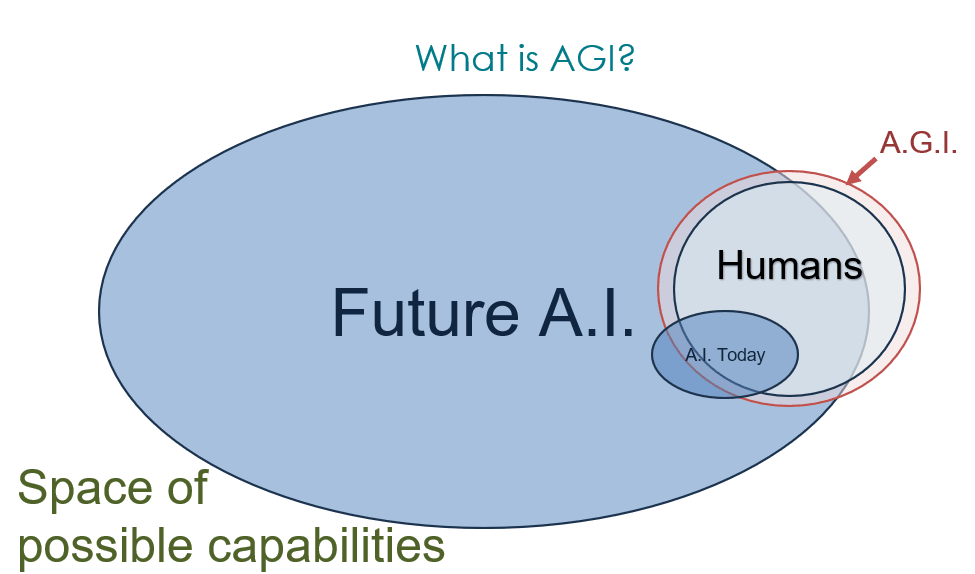
In this diagram, the AGI circle captures the concept that AGI is a system that subsumes all human capabilities. Realistically, this will never exactly happen. Is completing that AGI circle really the relevant concept? If we can shift that big Future AI bubble to the left and reduce the overlap with AGI, does that make us safer? No.
Granted, the APS concept is also highly deficient at this point in time. It also is too vague & ambiguous in its current form, especially in terms of how differently people interpret each of the six propositions. But, compared to the AGI term, it is at least a more constructive and relevant term.
I do like the idea of adopting a concept of "general intelligence" that is contrasted to "narrow intelligence." It applies to a system can operate across a broad spectrum different domains and tasks, including ones it wasn't specifically designed or trained for, and avoid brittleness when slightly out-of-distribution. IMHO, GPT-4 crossed that line for the first time this year. I.e., I don't think it can be considered narrow (and brittle) anymore. However, this is not a dangerous line -- GPT-4 is not an x-risk. So "general" is a useful concept, but misses something relevant to x-risk (probably many things).
While writing this posting, Max and I had several discussions about anthropic bias. It left me pretty uncomfortable with the application of it here as well, although I often took the position of defending it during our debates. I strongly relate to your use of the word "mysterious".
A prior that "we are not exceptionally special" seems to work pretty good across lots of beliefs that have occurred throughout history. I feel like that prior works really well but is at odds with the anthropic bias argument.
I'm still haven't resolved whether the anthropic argument is valid here in my own mind. But I share Ben's discomfort.
The Drake parameter R* = The rate of star formation (new stars / year). It is set to LogUniform(1,100), meant to be representative of the Milky Way. I can easily replace that in the model with 2000*LogUniform(1,100) to explore your question. The other Drake parameter that might need some thought is f_c = The fraction of intelligent civilizations that are detectable / contactable. For now, let's not alter this one. The other Drake parameters shouldn't really change, at least assuming they are similar galaxies.
With that change to R*, P(N<1) -- the probability there isn't another in the Virgo cluster, becomes 81% (for the 2nd model version with the t V λ decomposition for f_l, which had previously been 84%). The 1st model version that used a LogNormal for f_l changes from 48.5% to 38%.
The versions that explored a less extreme model of f_l (the rate of abiogenesis) see a much bigger change. For example, when f_l is set to 100%, it changes from 10% for Milky Way to 0.05% for Virgo. The Beta distribution version of f_l goes from 23% to 1%.
Your intuition might be that the prob. of being alone would drop by a factor of 2000, which obviously isn't what happens. What you do see is the distribution for N = # of detectable civilizations (which is a probability dist, not a point prob) shifts right by a factor of 2000. But that doesn't mean the area under N<1 sees that same change.
At the moment, I am particularly interested in the structure of proposed x-risk models (more than the specific conclusions). Lately, there has been a lot of attention on Carlsmith-style decompositions, which have the form "Catastrophe occurs if this conjunction of events occur". I found it interesting that this post took the upside-down version of that, i.e., "Catastrophe is inevitable unless (one of) these things happen".
Why do I find this distinction relevant? Consider how non-informed our assessments for most of these factors in these models actually are. Once you include this meta-uncertainty, Jensen's inequality implies that the mean & median risk of catastrophe decreases with greater meta-uncertainty, whereas when you turn the argument upside down, it also inverts Jensen's inequality, such that mean & median risk of catastrophe would increase with greater meta-uncertainty.
This is a complex topic that has more nuances than are warranted in a comment. I'll mention that Michael's actual argument uses "unless **one of** these things happen", which is additive (thus not subject to the Jensen's inequality phenomena). But because the model is structured in this polarity, Jensen's would kick in as soon as he introduces a conjunction of factors, which I see as something that would naturally occur with this style of model structure. Even though this post's is additive, I give this article credit for triggering this insight for me.
Also, thank you for your Appendices A & B that describe your opinions about which approaches to alignment you see as promising and non-promising.