[Cross-post] Is the Fermi Paradox due to the Flaw of Averages?
post by Aryeh Englander (alenglander), Lonnie Chrisman (lonnie-chrisman), Yaakov T (jazmt) · 2023-01-18T19:22:01.944Z · LW · GW · 27 commentsThis is a link post for https://lumina.com/fermi-paradox-resolved-by-flaw-of-averages-2/
Contents
The Fermi Paradox The Flaw of Averages on Steroids The Drake Equation Past explanations of the Fermi Paradox Quantifying Uncertainty in the Drake Equation Version 1: LogNormal Version 2: Explore the model yourself Fraction of habitable planets that develop life, fl Number of detectable civilizations Bayesian updating on Fermi’s Observation How to compute the posteriors Updating on a positive observation Extraterrestrial microbes Summary None 27 comments
[This article is copy-pasted from the Lumina blog, very lightly edited for LessWrong.]
Where is everybody?
— Enrico Fermi
The omnipresence of uncertainty is part of why making predictions and decisions is so hard. We at Lumina advocate treating uncertainty explicitly in our models using probability distributions. Sadly this is not yet as common as it should be. A recent paper “Dissolving the Fermi Paradox” (2018) is a powerful illustration of how including uncertainty can transform conclusions on the fascinating question of whether our Earth is the only place in the Universe harboring intelligent life. The authors, Anders Sandberg, Eric Drexler and Toby Ord (whom we shall refer to as SDO), show elegantly that the apparent paradox is simply the result of the mistake of ignoring uncertainty, what Sam L. Savage calls the Flaw of Averages. In this article, we review their article and link to an Analytica version of their model that you can explore.
The Fermi Paradox
.jpg)
Enrico Fermi. From Wikimedia commons.
One day in 1950, Enrico Fermi, the Nobel prize-winning builder of the first nuclear reactor, was having lunch with a few friends in Los Alamos. They were looking at a New Yorker cartoon of cheerful aliens emerging from a flying saucer. Fermi famously asked “Where is everybody?”. Given the vast number of stars in the Milky Way Galaxy and the likely development of life and extraterrestrial intelligence, how come no ETs have come to visit or at least been detected? This question came to be called the “Fermi Paradox”. Ever since, it has bothered those interested in the existence of extraterrestrial intelligence and whether we are alone in the Universe.
The Flaw of Averages on Steroids

Dr. Sam Savage who coined the term “Flaw of Averages”
Sam L. Savage, in his book, The Flaw of Averages, shows how ignoring uncertainty and just working with a single mean or “most likely” value for each uncertain quantity can lead to misleading results. To illustrate how dramatically this approach can distort your conclusions, SDO offer a toy example. Suppose there are nine factors that multiplied together give the probability of extraterrestrial intelligence (ETI) arising on any given star. If you use a point estimate of 0.1 for each factors, you could infer that there is a probability of any given star harboring ETI. There are about stars in the Milky Way, so the probability that no star other than our own has a planet harboring intelligent life would be extremely small, . On the other hand, suppose that, based on what we know, each factor could be anywhere between 0 and 0.2, and assign a uniform uncertainty over this interval, using the probability distribution, Uniform(0, 0.2). If you combine these distributions probabilistically, using Monte Carlo simulation for example, the mean of the result is 0.21 – over 5,000,000,000,000,000,000,000,000,000,000,000,000,000,000 times more likely!
The Drake Equation
Frank Drake, a radio astronomer who worked on the search for extraterrestrial intelligence (SETI), tried to formalize Fermi’s estimate of the number of ETIs. He suggested that we can estimate N, the number of detectable, intelligent civilizations in the Milky Way galaxy from what is now called the “Drake equation”. It is sometimes referred to as the “second most-famous equation in science (after E= mc2)”:

Frank Drake (1930-2022).
Where
is the average rate of formation of stars in our galaxy,
is the fraction of stars with planets.
is the average number of those planets that could potentially support life.
is the fraction of those on which life had actually developed;
is the fraction of those with life that is intelligent; and
is the fraction of those that have produced a technology detectable to us.
is the average lifetime of such civilizations
Many have tried to refine this calculation since Drake first proposed it in 1961. Most have estimated a large number for N, the number of detectable extraterrestrial civilizations. The contradiction between expected proliferation of detectable ETs and their apparent absence is what came to be called the “Fermi paradox” after the famous lunch conversation.
Past explanations of the Fermi Paradox

Image: Wikimedia commons
Many have tried to resolve the apparent paradox: Maybe advanced civilizations avoid wasteful emission of electromagnetic radiation into space that we could detect. Maybe interstellar travel is simply impossible. Or if it is technically possible, all ETs have decided it’s not worth the effort. Or perhaps ETs do visit us but choose to be discreet, deeming us not ready for the shock of contact. Maybe there is a Great Filter that makes the progression of life to advanced stages exceedingly rare. Or perhaps, the development of life from lifeless chemicals (abiogenesis) and/or the evolution of technological intelligence are just so unlikely that we are in fact the only ones in the Galaxy. Or, even more depressingly, perhaps those intelligent civilizations that do emerge all manage to destroy themselves in short order before perfecting interstellar communication—as indeed we Earthlings may plausibly do ourselves.
Quantifying Uncertainty in the Drake Equation
SDO propose a nice way to resolve the apparent paradox without resorting to any speculative explanation. Recognizing that most of the factors of the Drake equation are highly uncertain, they express each factor as a probability distribution that characterizes the uncertainty based on their review of the relevant scientific literature. They then use simple Monte Carlo simulation to estimate the probability distribution on N, and hence the probability that — i.e. that there are zero ETIs to detect. They estimate this probability at about 52% (our reimplementation of their model comes up with 48%). In other words, we shouldn’t be surprised at our failure to observe any ETI because there is a decent probability that there aren’t any. Thus, we may view the Fermi paradox as due simply to Sam Savage’s “Flaw of Averages”: If you use only “best estimates” and ignore the range of uncertainty in each assumption, you’ll end up with a misleading result.
For most factors. the uncertainty ranges over many orders of magnitude. For all except one factor, SDO represent its uncertainty using a Log-Uniform distribution, assuming that each order of magnitude is equally likely over its range. In other words, the logarithm of the value is uniformly-distributed. This table summarizes their estimated uncertainty for each factor.
| Factor | Distribution | Description |
LogUniform(1, 100) | Rate of star formation (stars/year) | |
| | LogUniform(0.1, 1) | Fraction of stars with planets |
| | LogUniform(0.1, 1) | Number of habitable planetary objects per system with planets (planets/star) |
| | Version 1: LogNormal
| Fraction of habitable planets that develop life. Abiogenesis refers to the formation of life out of inanimate substances.
The scientific notation |
Version 2: “ version”
| ||
LogUniform(0.001, 1) | Fraction of planets with life that develops intelligence | |
LogUniform(0.01, 1) | Fraction of intelligent civilizations that are detectable | |
LogUniform(100, 1e10) | Duration of detectability (years) |
SDO present two ways to estimate , the fraction of habitable planets that develop life. Both use the form as the probability that one or more abiogenesis events occur, assuming a Poisson-process with rate . In Version 1 they estimate a Lognormal distribution directly for . Version 2 decomposes into a product of three other quantities, , and assigns a loguniform to each one. (It is not clear to us that these three subquantities are any easier to estimate!) At the risk of stating the obvious, the ranges for used by SDO are enormous in either version.
We couldn’t tell from the text of the paper alone which results used which version, so we included both versions in our model. This table gives some results from these models.
| N = # detectable civilizations in Milky Way | Pr(N<1) “we are alone” | Pr(N>100M) “Teeming with intelligent civilizations” | ||
|---|---|---|---|---|
| Median | Mean | |||
| Reported in SDO | 0.32 | 27 million | 52% | – |
| Version 1 with uncertainty | 1.8 | 27.8 million | 48% | 1.9% |
| Version 2 with uncertainty | 9.9e-67 | 8.9M | 84% | 0.6% |
| Version 1 with point estimates | 2000 | 0% | 0% | |
| Version 2 with point estimates | 1e-66 | 100% | 0% | |
| % | 500 | 8.9 million | 17% | 1.2% |
| Beta(1, 10) | 170 | 5 million | 23% | 1.4% |
The top row, “Reported in SDO”, shows the numbers from their text. The rest are from our Analytica implementation of their model. Their reported values seem more consistent with Version 1; but other results in their paper seem more consistent Version 2. We believe our implementation of both versions reflects those described in the paper. We even examined their Python code in a futile attempt to explain why our results aren’t an exact match. We have emailed the first author in the hope he can clarify the situation. While we can’t reproduce their exact results the discrepancies do not affect their broad qualitative conclusions.
The rows, Versions 1 and 2 with uncertainty, use SDO’s full distributions. The rows, Versions 1 and 2 with point estimates, use the median of their distributions as a point estimate for each of the seven factors of the Drake Equation or 9 parameters for Version 2. In Version 1 with uncertainty, the mean for is four orders of magnitude larger than the corresponding point estimate. In Version 2 with uncertainty, it is 73 orders of magnitude larger than the corresponding point estimate.
The Pr(N<1) column shows the probability that there is no other detectable civilization in the Milky Way. The fact that it is so high means that we should not be surprised by Fermi’s observation that we haven’t detected any extraterrestrial civilization. In each case with uncertainty, there is a substantial probability (from 17% to 84%) that no other detectable civilization exists. We added a last column with the probability that our galaxy is absolutely teeming with life— with over 100 million civilizations, or 1 out of every thousand stars having a detectable intelligent civilization. The uncertain models give us between 0.6% and 1.9% of this case.
Explore the model yourself
[Unfortunately we have not been able to figure out how to embed working Analytica models in a LessWrong post. See below for some images from the model, or click here to explore an interactive version of the model.]
Here are some things to try while exploring the model.
- Click on a term in the Drake Equation for a description.
- Select a particular “model” for , the fraction of planets or planetary objects where life begins, or keep it at All to run all of them.
- View each of the results in the UI above.
- Calculate and view the statistics view to see the Mean and Median. Select Mid to see what the result would be without including uncertainty.
- View the PDF for LogTen(N).
- Select a observation method (or multiple ones) and see how the results change in the posterior compared to the prior.
- Click on Model Internals to explore the full implementation.
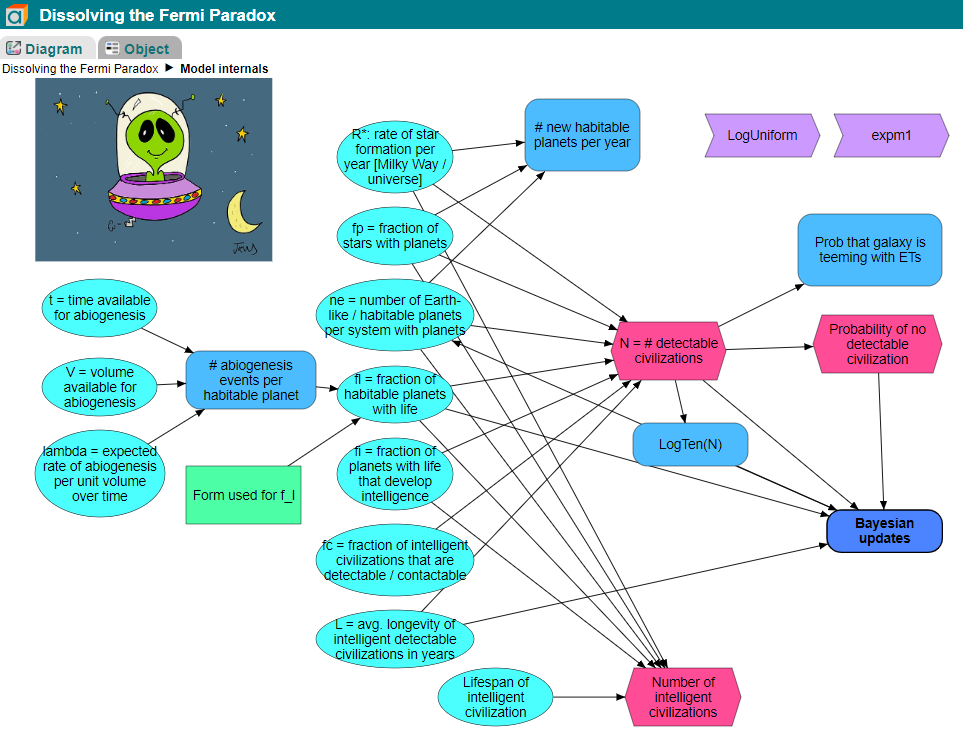
Model Internals. In the interactive version of the model, hovering the cursor over any node will display a description for that node. Clicking on any node will allow you to view properties, tables, and graphs associated with that node. For more about browsing or creating Analytica models, see the Analytica Tutorial.
Fraction of habitable planets that develop life,
Original DALL-E 2 artwork. Prompt=Abiogenesis
The largest source of uncertainty is factor , the fraction of habitable planets with life. Microscopic fossils imply that life started on Earth around 3.5 to 3.8 billion years ago, quite soon after the planet formed. This suggests that abiogenesis is easy and nearly inevitable on a habitable planet. On the other hand, every known living creature on Earth uses essentially the same DNA-based genetic code, which suggests abiogenesis occurred only once in the planet’s history. So perhaps it was an astoundingly rare event that just happened to occur on Earth. The fact that it did occur here doesn’t give us information about other than the fact that is not exactly zero due to anthropic bias—the observation that we exist would be the same whether life on Earth was an incredibly rare accident or whether it was inevitable.
SDO reflect the lack of information on by the immense range of uncertainty for in both versions of their model. Here is their probability density function (PDF) for :
 The PDF of
The PDF of
The PDF looks similar for Version 1 and Version 2, with spikes at and , and little probability mass between these extremes. In Version 1 the spikes are roughly equal, whereas in Version 2 the spikes at and have about 84% and 16% probability respectively. In other words, there is a 16% chance that almost every habitable planet develops life, and an 84% probability that essentially none do. (The Earth did, of course, but this isn’t inconsistent with since these values are positive, just extremely small.) Thus, the distribution nearly degenerates into a Bernoulli (point) probability distribution. A Bernoulli point probability would mean that 16% of habitable planets develop life, which is a somewhat different interpretation. To see this difference, we included in the results as a point of comparison (See the penultimate row of the table) above.
The core problem here is that the range they used for abiogenesis events per habitable planet, , just seems implausibly large in both versions, with the 25-75 quartile ranging from 2e-15 to 4e+14. We think this may be too extreme. The nice thing about having a live model to play with is that it is possible to repeat the results using more sane alternatives.
Number of detectable civilizations
Because the model includes information about how uncertain each factor is, we can plot the probability distribution for , the number of detectable civilizations in the Milky Way. Here is SDO’s distribution as a PDF:
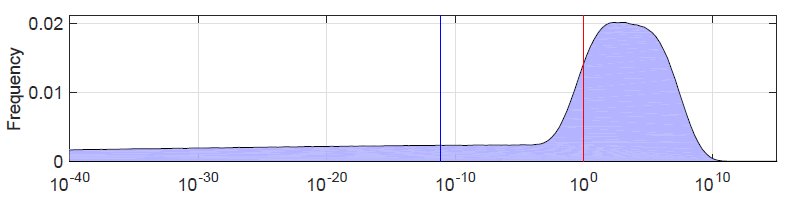 The probability density for Log(N) from SDO
The probability density for Log(N) from SDO
These two are from the Analytica model for the two versions for .
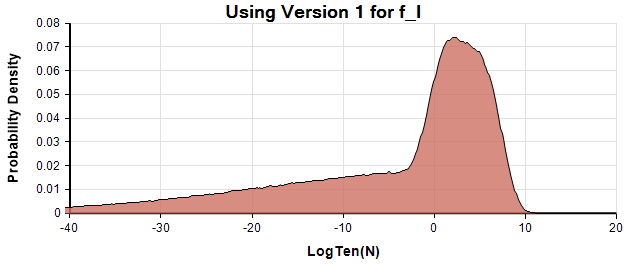 p(logten(N)) density plot using Version 1 of the model.
p(logten(N)) density plot using Version 1 of the model.
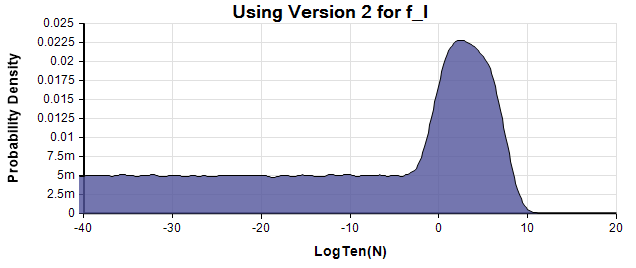 p(logten(N)) density plot using Version 2 of the model.
p(logten(N)) density plot using Version 2 of the model.
The similarity between the first and third density, a combination of roughly LogNormal centered around Log(N)=2, and a LogUniform down to suggests SDO used Version 2 of for this graph. However, as we mentioned, the numbers given in the text are more consistent with Version 1.
A probability density at a particular x value is obtained by estimating (by Monte Carlo simulation) the probability that the true value is within a small interval of width around x, and then dividing by to get the density. The probability density of is not the same as the density of since the denominator is different. Although SDO label it the graph as the probability density of , they are actually showing the density of , which is a sensible scale for order-of-magnitude of uncertainty. They label the vertical axis as “frequency” rather than probability density, likely an artifact of the binning algorithm used to estimate the densities.
Cumulative Probability Functions (CDFs) avoid these complications — the y-scale is cumulative probability, whether you plot or :
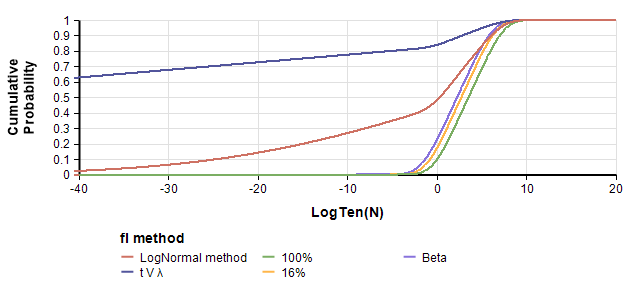 The CDF of N=# detectable civilizations in the Milky Way, for 5 variations of .
The CDF of N=# detectable civilizations in the Milky Way, for 5 variations of .
These CDFs show a dramatic difference between Version 1 (using the LogNormal method) and Version 2 (using the method), and between those versions and ours that remove the massive lower tails. An interesting aspect of these graphs are their qualitative shape. In the PDF, they all have the familiar bell-shaped body, but the extreme left tail stands out as unusual. The previous section points out that both versions of are so extreme the effective distribution is degenerate. We think this is a flaw. Hence, it is interesting to see how the graph changes when we set to a less degenerate distribution.
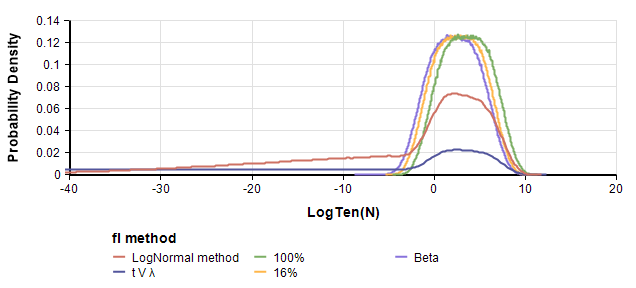 PDFs of Log(N) for 5 variations of
PDFs of Log(N) for 5 variations of
The LogNormal method for , and the method are their Versions 1 and 2. The other three methods are less extreme. 100% and 16% use these as point probabilities for , and Beta uses a Beta(1,10) distribution for . The key conclusion of the paper that there is a significant probability that N is zero remains robust with these less extreme distributions for .
Bayesian updating on Fermi’s Observation
Fermi’s question “where is everybody” refers to the observation that we haven’t detected any extraterrestrial civilizations. SDO apply Bayes’ rule to update the estimates with this observation. To apply Bayes’ rule, you need the likelihoods for each possible value of , where is the observation that no ETI has been detected. SDO explore four models for this updating:
- Random sampling assumes that we have sampled stars, none of which harbor a detectable civilization.
- Spatial Poisson assumes that there is no detectable civilization within a distance of Earth.
- Settlement attempts to incorporate the possibility that interstellar propagation would be likely among advanced civilizations. It introduces several new parameters, including settlement timescales and a geometric factor. It is conditioned on the observation that no spacetime volume near the Earth has been permanently settled.
- No K3 observed conditions on the observation that no Kardashev type 3 civilizations exist— civilizations that harness energy at the galactic scale. It presumes that if such a civilization exists, either in the Milky Way or even in another visible galaxy, we would have noticed it. Among other parameters, it includes one for the probability that a K3 civilization is theoretically possible.
We implemented all these update models in the Analytica model. Our match to the paper’s quantitative results is only approximate. We are not sure why the results are not precisely reproducible. It was quite challenging figuring out what parameters they used for each case, since the paper and its Supplement 2 left out many details. With the exception of the settlement update model, we were able to get fairly close at least in qualitative terms. We explored that space of possible parameter values for the Settlement model but were unable to match the qualitative shape of the posterior reported in the paper. The likelihood equation for the K3 update appears to be in error in the paper since it doesn’t depend at all on , but a more plausible version that does depend on appears in Supplement 2.
In our Analytica model, you can select which update model(s) you want to view, and graph them side-by-side, along with (or without) the prior. For example,
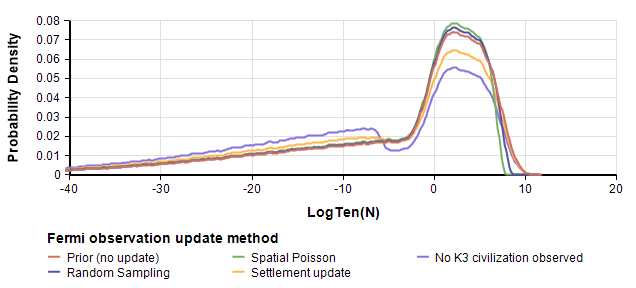 Prior and posteriors for logten(N) based on Version 1 of the prior. Each posterior uses one of the methods for P(¬D|N) described in the paper.
Prior and posteriors for logten(N) based on Version 1 of the prior. Each posterior uses one of the methods for P(¬D|N) described in the paper.
Once of the more interesting posterior results is .
 Priors and posteriors P(N<1) for different models of and different models of likelihood P(¬D|N).
Priors and posteriors P(N<1) for different models of and different models of likelihood P(¬D|N).
SDO report these numbers in Table 2 (in the same order as the rows of the above table) for P(N<1): 52%, 53%, 57%, 66%, 99.6%. We think they may have based their first 4 posteriors on Version 1. We are not sure about the K3 posterior, which differs substantially from our results.
In this table, we see that the models with a non-extreme, non-degenerate version of are not substantially changed by the posterior update on the negative Fermi observation. These are the models that use a point estimate for of 100% and 16%, as well as the one that uses .
How to compute the posteriors
We explored two ways to implement these posterior calculations in Analytica. We found their results to be consistent, so we stuck with the more interesting and flexible method. This is interesting in its own right, and very simple to code in Analytica. The calculation uses sample weighting, in which each Monte Carlo sample is weighted by . The value for is computed at each Monte Carlo sample, so from that is also computed for each selected posterior method. The variable that computes has the identifier P_obs_given_N. To compute the posteriors, all we had to do was set the system variable SampleWeighting to P_obs_given_N.
We also tried a second method for computing the posterior. It gives the same results, but is less elegant and more complex. This method extracts the histogram PDF(LogTen_N). It computes based on the value of N that appears in the PDF. The product of the PDF column for LogTen_N and is is the unnormalized PDF for .
We would expect this second method to perform better than the first method when the likelihood is extremely leptokurtic. In this model, this is not the case.
Updating on a positive observation
The Fermi observation is the negative observation that we have never detected another extraterrestrial civilization. We thought it would be interesting here to explore what happens when you condition on a positive observation.
Extraterrestrial microbes
.jpg)
Saturn’s moon Titan.
In March 2011, one of us (Lonnie Chrisman) attended a talk at Foothill College by NASA planetary scientist Dr. Chris McKay. Six years earlier, with the Huygens probe descending into the atmosphere of Saturn’s moon Titan, he and graduate student, Heather Smith, undertook a thought experiment. They asked: If there is life on Titan, what chemical signatures might we see? Especially, signatures that could not result from a known inanimate process? What would organisms eat? What would their waste products be?
At -190°C (-290°F), life on Titan would be very different, not based on water, but rather on liquid methane. Without knowing what such life forms would look like, they could still make some inferences about what chemical bonds organisms would likely utilize for metabolism. For example, the molecule with the most harvestable energy on Titan is acetylene (). They published a set of proposed signatures for life[1] and then moved on to other work. Five years later, analysis of data from the Huygen’s probe and Cassini mission to Saturn found some unexplained chemical signatures.[2]

Astro-geophysicist Dr. Chris McKay
These signatures matched those predicted as possible signatures of life by McKay and Smith 5 years earlier. One signature, a net downward flux of hydrogen, is particularly intriguing, since it implies that something is absorbing or converting hydrogen near the surface, for which no inorganic processes are known. The data remain ambiguous. For example, the Huygens probe did not detect a depletion of hydrogen near the surface, which is what would be expected if organisms on the surface are consuming hydrogen.
The interesting question here is how we should update our uncertainty based on a hypothetical future discovery of microbial life on an extraterrestrial body such as Titan. Such a discovery would influence our belief about , the number of planetary objects per star that are potentially habitable, as well as , the fraction of habitable planetary objects where life actually starts. In our own solar system, it would make Jupiter’s moons Europa and Enceladus more likely candidates. Adding moons to planets as possible sites for abiogenesis would increase our estimate for by something like a factor of 3:
LogUniform( 0.3, 3 )
To update , we’ll use , where D is the observation that this one additional planetary object is habitable and where life has emerged.
With these updates, the probability that there is no other intelligent contactable civilization would drop from 48.5% to 6.6%, and the probability that the galaxy is teeming with intelligent life would increase from under 2% to over 6%, using the Version 1 prior. Here is the table for different version of the prior (where only varies between the 5 priors).
| P(N<1): “we are alone” | P(N>100): galaxy teeming with life | |||
|---|---|---|---|---|
| Prior | Posterior | Prior | Posterior | |
| Version 1 | 48.5% | 6.6% | 1.9% | 6.2% |
| Version 2 | 84% | 6.6% | 0.6% | 6.2% |
| % | 10% | 6.5% | 3.7% | 6.3% |
| % | 17% | 12.7% | 1.2% | 2.5% |
Beta(1,10) | 23% | 13.6% | 1.4% | 2.4% |
It is interesting when comparing these priors how the extreme priors (Version 1 and Version 2) adjust to be nearly identical to the result obtained when setting %. The % models the most extreme assumption that life always starts on every habitable planet. This reinforces our earlier criticism that the paper’s two versions of are flawed. Because they are so extreme, they are roughly equivalent to saying life starts on a habitable planetary body either almost always or almost never. Thus the evidence that it happened on Titan would leave us with only the former option, that it happens almost always.
Summary
It is easy to be misled without realizing it when you estimate a single number (a point estimate) for an unknown quantity. Fermi’s question of why we never detected or encountered other extraterrestrial civilizations has spawned decades of conjecture for underlying reasons, yet Sandberg, Drexler and Ord show that there may be no paradox after all. We’ve reviewed and reimplemented the model they proposed. The possibility that there are no other detectable intelligent civilizations in the Milky Way is consistent with our level of uncertainty. The apparent paradox was simply the result of the “Flaw of Averages”.
We hope you are able to learn something by playing with the model. Enjoy!
Lonnie Chrisman is Lumina's Chief Technology Officer, where he heads engineering and development of Analytica. He has a Ph.D. in Artificial Intelligence and Computer Science from Carnegie Mellon University; and a BS in Electrical Engineering from University of California at Berkeley. Aryeh Englander works on Artificial Intelligence at the John Hopkins University Applied Physics Laboratory, and is doing a Ph.D. in Information Systems at the University of Maryland, Baltimore County (UMBC), with a focus on analyzing potential risks from very advanced AI. Yaakov Trachtman is an educator and independent researcher. Max Henrion is the Founder and CEO of Lumina Decision Systems. He was awarded the prestigious 2018 Frank Ramsey Medal, the highest award from the Decision Analysis Society. Max has an MA in Natural Sciences from Cambridge University, Master of Design from the Royal College of Art, London, and a PhD from Carnegie Mellon.
This research was conducted as part of the Modeling Transformative AI Risk (MTAIR) project [? · GW]. We are exploring a similar type of analysis as SDO use for the Fermi Paradox, but in the context of AI risk models. See also this EA Forum post [EA · GW] by Froolow [LW · GW].
- ^
C.P. McKay and H.D.Smith (2005), “Possibilities for methanogenic life in liquid methane on the surface of Titan“, ICARUS 178(1):274-276, doi.org/10.1016/j.icarus.2005.05.018
- ^
Darrell F.Strobel (2010), “Molecular hydrogen in Titan’s atmosphere: Implications of the measured tropospheric and thermospheric mole fractions“, ICARUS 208(2):878-886, doi.org/10.1016/j.icarus.2010.03.003
27 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2023-01-18T20:24:26.186Z · LW(p) · GW(p)
I think that conceptually, the SDO paper is just saying:
“Hey, for all we know, maybe one or more of the factors in the Drake equation is many orders of magnitude smaller than our best guess; and if it is, then there’s no more Fermi paradox”.
I think it’s a stretch to describe that sentence as “dissolving the Fermi paradox”. That sentence was always an obvious possibility. The whole crux of the Drake equation / Fermi paradox dispute here is that a bunch of people believe that the factors they’re assigning are not in fact orders of magnitude too high. I think SDO are just sidestepping the actual issue.
To be a bit mean, it’s kinda like if I were to say: “Drake & Sagan estimated 1,000–100,000,000 civilizations in the Milky Way galaxy. And Tipler & Barrow argued for different Drake equation parameters such that there’s <<1 civilization per galaxy. Well I’m too lazy to adjudicate this debate, so I’ll just say there’s a 50% chance that Drake & Sagan are right, and a 50% chance that Tipler & Barrow are right. And voila, now there’s a 50% chance that we’re alone. Hey look, I dissolved the Fermi paradox! Go me!”
(There’s some chance that I’m misunderstanding. Not an expert.)
Replies from: tailcalled↑ comment by tailcalled · 2023-01-18T22:06:17.263Z · LW(p) · GW(p)
Have any of the people who claim to know proof that none of the factors are orders of magnitude too high provided any description of that proof anywhere? Otherwise I don't see why I should trust them over the SDO paper (as the SDO paper makes weaker assertions).
comment by Closed Limelike Curves · 2023-01-19T18:29:04.939Z · LW(p) · GW(p)
The article provides one possible resolution to one Fermi paradox, but not another, and I think both a lot of literature and the comments here are pretty confused about the difference.
The possibly-resolved Fermi paradox: "Why do we see no life, when we'd expect to see tens of thousands of civilizations on average?" Assuming there really is no alien life, this paper answers that pretty convincingly: the distribution of civilizations is highly-skewed, such that the probability that only one civilization exists can be pretty large even if the average number of civilizations is still very high.
The unresolved Fermi paradox is "Why aren't there any aliens?" This paper doesn't answer that question (nor does it try to). It's just pointing out that there's a ton of possible reasons, so it's not all that surprising that some combination of them might be very restrictive
.
comment by ponkaloupe · 2023-01-18T23:10:30.602Z · LW(p) · GW(p)
On the other hand, every known living creature on Earth uses essentially the same DNA-based genetic code, which suggests abiogenesis occurred only once in the planet’s history.
well this alone doesn’t suggest abiogenesis occurred only once: just that if any other abiogenesis occurred it was outcompeted by DNA replicators.
when i was in school there was a theory that RNA was a remnant of pre-DNA abiogenesis: either that it bootstrapped DNA life, or that it was one such distinct line which “lost” to DNA. in the latter case, hard to say how many other lines there were which left no evidence visible today, or even how many lines/abiogenesis events would have occurred if not for DNA replicators altering the environment and available resources. hopefully research has provided better predictions here that i just haven’t heard about yet.
comment by Shmi (shminux) · 2023-01-18T21:02:26.223Z · LW(p) · GW(p)
So... do you have a plausible answer to the question "where is everybody?" Using distributions instead of point estimates (something I agree with, and something that is used in cosmology and astrophysics routinely, anyway) can change the overall probability, but how does it help the original question?
Replies from: ponkaloupe↑ comment by ponkaloupe · 2023-01-18T22:48:05.048Z · LW(p) · GW(p)
this does help the original question: “where is everybody” can reasonably be answered with “they’re on the other side of a coin flip”. in the point estimate version it was “they’re on the other side of some hundreds of consecutive coin flips”. so it helps the original question in that there’s far less that needs to be explained.
Replies from: shminux↑ comment by Shmi (shminux) · 2023-01-19T02:42:33.076Z · LW(p) · GW(p)
Well, there are two answers here, that we are alone, and that we are not... I don't get the sense of the answer from the OP.
comment by avturchin · 2023-01-19T16:14:39.346Z · LW(p) · GW(p)
Self-indication assumption in anthropics implies that we should find ourselves in the universe with the highest concentration of observers (as most of them are there). This affects distribution of some random variables in the Drake equation in upper direction. Especially chances of abiogenesis and interstellar panspermia which can compensate rareness of abiogenesis.
Also, 84 per cent of no aliens in Milky Way galaxy is means that they are almost certainly exist in Virgo supercluster with its 2000 galaxies.
Replies from: cousin_it, ben-lang↑ comment by cousin_it · 2023-01-21T10:20:09.859Z · LW(p) · GW(p)
Also, 84 per cent of no aliens in Milky Way galaxy is means that they are almost certainly exist in Virgo supercluster with its 2000 galaxies.
No. Or rather, it depends on where the 84% comes from. If it's an unknown factor that applies to each galaxy independently, then yeah. But if it's an unknown factor that applies to either all galaxies or none, then adding more galaxies doesn't help much.
Replies from: lonnie-chrisman, avturchin↑ comment by Lonnie Chrisman (lonnie-chrisman) · 2023-01-23T19:00:50.389Z · LW(p) · GW(p)
The Drake parameter R* = The rate of star formation (new stars / year). It is set to LogUniform(1,100), meant to be representative of the Milky Way. I can easily replace that in the model with 2000*LogUniform(1,100) to explore your question. The other Drake parameter that might need some thought is f_c = The fraction of intelligent civilizations that are detectable / contactable. For now, let's not alter this one. The other Drake parameters shouldn't really change, at least assuming they are similar galaxies.
With that change to R*, P(N<1) -- the probability there isn't another in the Virgo cluster, becomes 81% (for the 2nd model version with the t V λ decomposition for f_l, which had previously been 84%). The 1st model version that used a LogNormal for f_l changes from 48.5% to 38%.
The versions that explored a less extreme model of f_l (the rate of abiogenesis) see a much bigger change. For example, when f_l is set to 100%, it changes from 10% for Milky Way to 0.05% for Virgo. The Beta distribution version of f_l goes from 23% to 1%.
Your intuition might be that the prob. of being alone would drop by a factor of 2000, which obviously isn't what happens. What you do see is the distribution for N = # of detectable civilizations (which is a probability dist, not a point prob) shifts right by a factor of 2000. But that doesn't mean the area under N<1 sees that same change.
↑ comment by Ben (ben-lang) · 2023-01-20T10:12:14.856Z · LW(p) · GW(p)
I always find anthropic arguments a bit mysterious. I completely agree that if all people live in one of two houses, one with 1 resident and the other with 100, then if we are a randomly chosen person we will most-likely have a lot of people sharing our home.
But when you substitute the word "house" for "universe" something important is different. Only one of the two universes actually exists. The other one is hypothetical. Its in fact more hypothetical than a normal "could have been", because we don't even know if chemistry/star formation or whatever could have been different, even in principle. So when we count frequencies to estimate the probability in the "universe" case we are counting people who are by-definition hypothetical.
In the situation where God flicks a coin, and on heads creates a house with 100 people, and on tails creates a house with 1 person. Then I am not sure either way about an anthropic argument that says "I have just found out I exist, which means I am very likely in the crowded house timeline". But I think that without the guarantee that such a coin toss ever happened, that is without any reason to think the 100 person house was ever a possibility - then my own feeling is that anthropic arguments don't work. Although I find them enough of a logical minefield that I would not put my certainty super high.
Replies from: avturchin, cubefox↑ comment by avturchin · 2023-01-20T22:37:42.010Z · LW(p) · GW(p)
This problem disappears if we assume very large universe with different regions. All regions are real and are like houses. I look more formally in it here: https://www.lesswrong.com/posts/KhwLtJXoAhqfmguzh/sia-becomes-ssa-in-the-multiverse
↑ comment by cubefox · 2023-01-20T21:42:15.423Z · LW(p) · GW(p)
If probability did require some form of objective randomness, then a lot of our probabilistic reasoning would not be justified. Which seems wrong.
For example, assume the universe is deterministic. Assume that our evidence supports the hypothesis that it will rain tomorrow. We conclude that it will probably rain tomorrow. Yet if it won't rain tomorrow, since the universe is deterministic, it was not possible that it will rain tomorrow. Hence, by your reasoning, it was wrong to think it would probably rain tomorrow. But that's absurd. Whether rain is likely or not depends on our evidence for rain, not on whether the universe is deterministic.
Or another example: Suppose you have a lot of evidence (from testimony, say) that a particular mathematical conjecture is true. Then it is probably true, relative to your evidence. Now assume, unbeknownst to you, it is false. Then it isn't possible that it is true, and by your original reasoning, it would be wrong to say that your evidence indicates that it is true. But that's obviously mistaken: Of course the truth value of mathematical conjectures is predetermined, but that doesn't affect their probability -- the probability depends on the evidence at hand.
Replies from: ben-lang↑ comment by Ben (ben-lang) · 2023-01-21T21:29:05.186Z · LW(p) · GW(p)
Its not about the objective randomness, to me its about the fact that the frequency is by necessity hypothetical. Yes their will only be one tomorrow, and rain might be pre-determined. But we can make arguments about "in a sample of days like tomorrow we know that some % will see rain." But their can only be one universe, even in principle, so the idea of generalizing to a class of universes and taking our universe as a member of that class I think can cause problems.
Replies from: lonnie-chrisman↑ comment by Lonnie Chrisman (lonnie-chrisman) · 2023-01-23T19:55:29.011Z · LW(p) · GW(p)
While writing this posting, Max and I had several discussions about anthropic bias. It left me pretty uncomfortable with the application of it here as well, although I often took the position of defending it during our debates. I strongly relate to your use of the word "mysterious".
A prior that "we are not exceptionally special" seems to work pretty good across lots of beliefs that have occurred throughout history. I feel like that prior works really well but is at odds with the anthropic bias argument.
I'm still haven't resolved whether the anthropic argument is valid here in my own mind. But I share Ben's discomfort.
comment by cubefox · 2023-01-19T15:10:28.239Z · LW(p) · GW(p)
There is one serious flaw with the SDO paper. The issue is that for = "# detectable civilizations in the Milky Way", they interpret as "the probability that there is no other detectable civilization in the Milky Way". But this interpretation is mistaken, since doesn't take into account the fact that we (our civilization) exist, i.e. that the number of civilizations in the Milky Way, , is at least 1.
Essentially the same was already pointed out by Alexey Turchin at the time. [LW(p) · GW(p)] SDO should have updated their probability distribution not just on the Fermi observation, but also on the fact that we exist.
In fact, doing so would change their conclusion. Since small values for would make our existence unlikely, our existence makes such small values unlikely. (It's a theorem of probability theory that implies .)
Edit: What they'd want for "the probability that there is no other detectable civilization in the Milky Way" would be something like .
Replies from: Sune↑ comment by Sune · 2023-01-19T21:05:54.430Z · LW(p) · GW(p)
The milky way was “choosen” because it happens to be the galaxy we are in, so we shouldn’t update on that as if if had first chosen a galaxy to study and then found life in it. Similarly, we can’t even be sure we can update on the fact that there is life at least one place in the universe, because we don’t know how many empty multiverses are out there. The only thing we can conclude from us self existing is that life is possible in the universe.
Replies from: cubefox↑ comment by cubefox · 2023-01-20T21:14:39.963Z · LW(p) · GW(p)
The milky way was “choosen” because it happens to be the galaxy we are in, so we shouldn’t update on that as if if had first chosen a galaxy to study and then found life in it.
This doesn't follow; one way or the other we have to update on the fact that our civilization exists. The order is not relevant.
Similarly, we can’t even be sure we can update on the fact that there is life at least one place in the universe, because we don’t know how many empty multiverses are out there. The only thing we can conclude from us self existing is that life is possible in the universe.
Anthropic reasoning (see SIA, Sleeping beauty paradox) suggests otherwise. That's what I was talking about above: If hypothesis makes evidence unlikely, then observing evidence makes hypothesis unlikely.
Replies from: Sune↑ comment by Sune · 2023-01-21T08:17:49.754Z · LW(p) · GW(p)
Yes, the ordering does matter. Compare two hypotheses, one, , says that one average there will be 1 civilisation in each galaxy. The other, says that on average there will be civilisations in each galaxy. Suppose the second hypothesis is true.
If you now do the experiment of choosing a random galaxy, and counting the number of civilisations in that galaxy, you will probably not find any civilisation, which correctly supports .
If you do the second experiment of first finding yourself in some galaxy and then counting the number of civilisation in the galaxy, you will at least find your own civilisation and probably not any other. If you don’t correct for the fact that this experiment is different, you would update strongly in the direction of even when is true and the evidence of the experiment is as favourably towards as possible. This cannot be the correct reasoning, since correct reasoning should not consistently lead you to wrong conclusions.
You might argue that there is another possible state which is even more favourable evidence towards : that you do not exist. However, in a universe with galaxies, the probability of this is .
Replies from: cubefox↑ comment by cubefox · 2023-01-21T11:57:50.420Z · LW(p) · GW(p)
The crucial point is that on our existence (say, ) is much more likely than on . That is, . If our prior is , then . That is, our existence implies that is more likely.
As a sanity check, this also doesn't reliably lead us to wrong conclusions: If we have two possible universes, one where is true and one where is true, and in both possible universes the civilizations reason as above and regard as more likely, much more civilizations will reach the true rather than the false conclusion, since the possible universe where is true has much more civilizations (or a much higher density etc).
Replies from: Sune↑ comment by Sune · 2023-01-22T09:54:49.223Z · LW(p) · GW(p)
Now I see, yes you are right. If you want the beliefs to be accurate at the civilisation level, that is the correct way of looking at it. This corresponds to the 1/3 conclusion in the sleeping beauty problem.
I was thinking of it on the universe level, were we are a way for the universe to understand itself. If we want the universe to form accurate beliefs about itself, then we should not include our own civilisation when counting the number of the civilisations in the galaxy. However, when deciding if we should be surprised that we don’t see other civilisations, you are right that should include ourselves in the statistics.
comment by Noosphere89 (sharmake-farah) · 2023-01-19T03:54:13.748Z · LW(p) · GW(p)
To distill the most important point of Sandberg, Drexler and Ord's paper:
The Fi term has such massive uncertainty that given our state of knowledge, anything from hundreds of millions of years to greater than 10^200 years are reasonably possible, and since we don't know much about abiogenesis, there is a reasonable chance that abiogenesis takes way longer than people think, and thus the most likely great filter is "We've way overestimated how easy abiogenesis can actually happen."
The headline conclusion is that there's a 39%-85% that we are alone in the observable universe.
IMO the major takeaways from the paper is the following:
-
We should mostly ignore aliens in our scenarios, since they most likely don't exist.
-
We should be pretty hopeful, as there's no great future filter, at least assuming X-risk is avoided in this millennium.
-
Our civilization is special in that if we collapse or go extinct, no one else of moral value will take over the universe to make it aligned with their values. That is, the universe will continue it's natural course iff we go extinct or collapse hard enough.
comment by Zach Stein-Perlman · 2023-01-18T20:16:06.173Z · LW(p) · GW(p)
The largest source of uncertainty is factor , the fraction of habitable planets with life. . . . The fact that it did occur here doesn’t give us information about other than the fact that is not exactly zero due to anthropic bias—the observation that we exist would be the same whether life on Earth was an incredibly rare accident or whether it was inevitable.
I think the latter sentence here is a strong claim and a controversial assumption. In particular, I disagree; I favor the self-indication assumption [? · GW] and its apparent implication that we should weight a possible universe by the number of experiences identical to ours in it, so (roughly) weight a possible universe by the number of planets in it where human-level civilization appears.
Replies from: JBlack↑ comment by JBlack · 2023-01-19T01:48:39.462Z · LW(p) · GW(p)
"Experiences identical to ours" includes "experiences of not seeing lots of alien civilizations", which means that universes obviously teeming with life should be excluded, not weighted more highly. Assuming you favour SIA.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2023-01-19T01:50:27.380Z · LW(p) · GW(p)
You’re right that we exclude universes obviously teeming with life. But we (roughly) upweight universes with lots of human-level civilizations that don’t see each other, or where civilizations that don't see another are likely to appear.
Replies from: JBlack↑ comment by JBlack · 2023-01-19T03:58:29.643Z · LW(p) · GW(p)
Yes, that's true.
As a simplified example, suppose we have prior reason to suspect that there is a single per-universe parameter p giving an independent per planet chance of technological civilization arising within 10 billion years or so that is log-uniform over [10^-100, 10^-0].
A civilization makes the Fermi observation: that they are not themselves (yet) starfaring and see no evidence of civilizations elsewhere. What update should they make to get a posterior credence distribution for the parameter?
By what criteria should we judge it to be a correct update?
The distribution of number of such civilizations per galaxy doesn't much depend upon p for values above 10^-11 or so, but drops off quite linearly below that.