Posts
Comments
The main problem with wireheading, manipulation... seems related to a confusion between the goal in the world and its representation inside the agent. Perhaps a way to deal with this problem is to use the fact that the agent may be aware of it being an embedded agent. That means that it could be aware of the goal representing an external fact of the world, and we could potentially penalize the divergence between the goal and its representation during training.
Something I believe could also be helpful is to have a non-archival peer review system that helps improve the quality of safety writings or publications; and optionally makes a readable blog post etc.
Hey Antb, I'm Pablo, Spanish and based in Spain. As far as I know these are the following AI Safety researchers:
- Jaime Sevilla leads the organization Epoch AI, mostly interested in forecasting AI.
- Juan Rocamonde and Adrià Garriga work full time on AI alignment in FAR.ai and Redwood Research.
- There is a professor, called Jose Hernández Orallo, working between Cambridge and Valencia who has been for quite a while in AI Safety. I know him and he is an excellent researcher. Part of the existential AI Safety FLI community, and mostly interested in measuring intelligence.
- There are also a couple of other professors at the Carlos III university in Madrid who could be friendly to these topics (see eg https://e-archivo.uc3m.es/handle/10016/29354), but it is unclear to what extent they would put this as their main research field.
- I work part-time as a science communicator in FAR.ai
In summary: if you want to stay in Spain probably you should go to Jose's group. I am happy to introduce you to Jose, with whom I did an internship a year and a half ago. We also have a Spanish-speaking EA community in case you're interested. Hope this is useful.
For the record, I think Jose Orallo (and his lab), in Valencia, Spain and CSER, Cambridge, is quite interested in this same exact topics (evaluation of AI models, specifically towards safety). Jose is a really good researcher, part of the FLI existential risk faculty community, and has previously organised AI Safety conferences. Perhaps it would be interesting for you to get to know each other.
Ok, so perhaps: specific tips on how to become a distiller: https://www.lesswrong.com/posts/zo9zKcz47JxDErFzQ/call-for-distillers In particular:
- How to plan what to write about?
- Here to write about it (lesswrong or somewhere else too)?
- How much time do you expect this to take? Thanks Steven!
Are there examples or best practices you would recommend for this?
I think value learning might be causal because human preferences cannot be observed, and therefore can act as a confounder, similar to the work in
Zhang, J., Kumor, D., Bareinboim, E. Causal Imitation Learning with Unobserved Confounders. In Advances in Neural Information Processing Systems 2020.
At least that was one of my motivations.
I think predicting things you have no data on ("what if the AI does something we didn't foresee") is sort of an impossible problem via tools in "data science." You have no data!
Sure, I agree. I think I was quite inaccurate. I am referring to transportability analysis, to be more specific. This approach should help in new situations where we have not directly trained our system, and in which our preferences could change.
While I enjoyed this post, I wanted to indicate a couple of reasons why you may want to instead stay in academia or industry, rather than being an independent researcher:
- The first one is that it gives more financial stability.
- The second is that academia or industry set the bar high. If you get to publish in a good conference and get substantial citations, you know that you are making progress.
Now, many will argue that Safety is still preparadigmatic and consequently there might be contributions that do not really fit well into standard academic journals or conferences. My answer to this point is that we should aim to make AI Safety become paradigmatic. We should really try to get our hands dirty into technical problems and solve them. I think there is a risk of staying at the conceptual level of research agendas for too long and not getting much done. In fact, I have anecdotic experience (https://twitter.com/CraigGidney/status/1489803239956508672?s=20&t=nNSjfZjqYfbUQ4hvmghoHw) of well-known researchers in a field other than AI Safety that do not get to work on it because they find it hard to measure progress or to have intuitions of what works. I argue: we want to make the field paradigmatic so that it becomes just another academic research field.
I also want to cite another important point against becoming an independent researcher: if you work alone it may take you longer to do any high-quality research done. Developing intuitions takes time, and supervision makes everything so much easier. I know that the community is short of supervision, but perhaps taking a good supervisor who does not directly work on AI Safety, but is happy for you to do so and whose research seems useful as tools might be a great idea.
So in summary: we want high-quality research, we want to be able to measure its high quality, and we want to make the field more concrete and grounded so that we can attract tons of academics.
Hi Ilya! Thanks a lot for commenting :)
(a) I think "causal representation learning" is too vague, this overview (https://arxiv.org/pdf/2102.11107.pdf) talks about a lot of different problems I would consider fairly unrelated under this same heading.
Yes, you're right. I had found this, and other reviews by similar authors. In this one, I was mostly thinking of section VI (Learning causal variables) and its applications to RL (section VII-E). Perhaps section V on causal discovery is also relevant.
(b) I would try to read "classical causal inference" stuff. There is a lot of reinventing of the wheel (often, badly) happening in the causal ML space.
Probably there is, I have to get to speed on quite a few things if I get the grant. But thanks for the nudge!
(c) What makes a thing "causal" is a distinction between a "larger" distribution we are interested in, and a "smaller" distribution we have data on. Lots of problems might look "causal" but really aren't (in an interesting way) if formalized properly.
I think this makes sense. But part of the issue here is that AI will probably change things that we have not foreseen, so it could be good to take this point of view, in my opinion. Do you have `interesting' examples of not-causal problems?
Thanks again!
Hey Koen, Thanks a lot for the pointers! The literature I am most aware of are https://crl.causalai.net/, https://githubmemory.com/repo/zhijing-jin/Causality4NLP_Papers and Bernhard Scholkopf's webpage
Alternatively you may want to join here: https://join.slack.com/t/ai-alignment/shared_invite/zt-fkgwbd2b-kK50z~BbVclOZMM9UP44gw
My prediction. Some comments
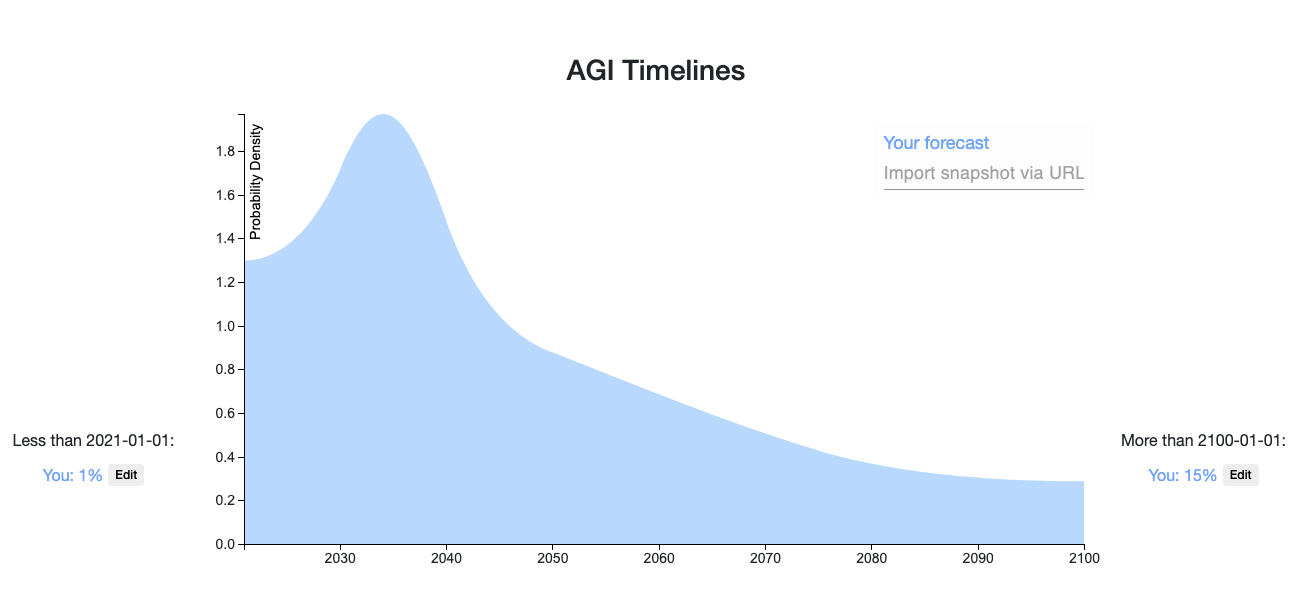
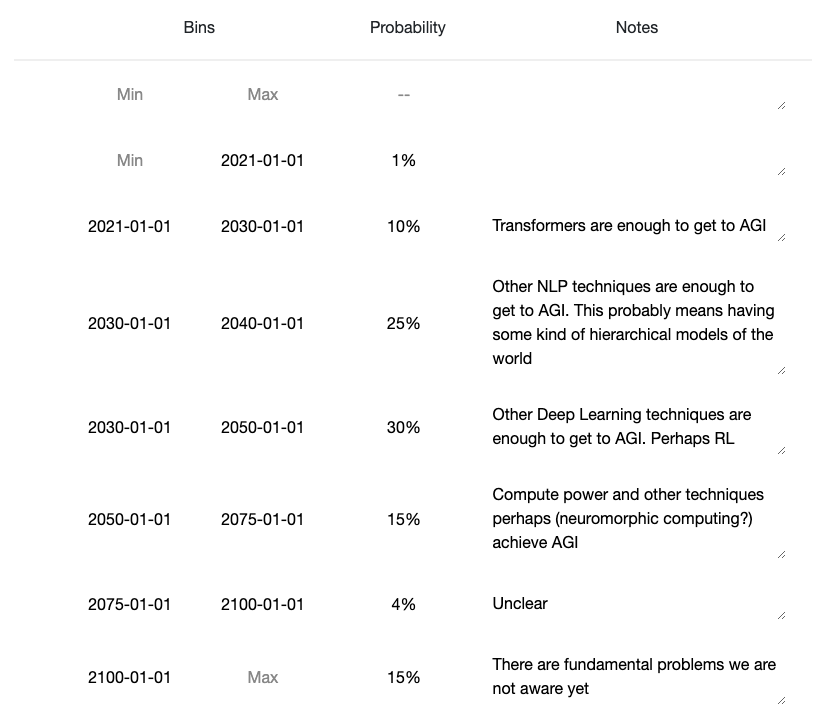
- Your percentiles:
- 5th: 2023-05-16
- 25th: 2033-03-31
- 50th: 2046-04-13
- 75th: 2075-11-27
- 95th: above 2100-01-01
- You think 2034-03-27 is the most likely point
- You think it's 6.9X as likely as 2099-05-29