How RL Agents Behave When Their Actions Are Modified? [Distillation post]
post by PabloAMC · 2022-05-20T18:47:52.932Z · LW · GW · 0 commentsContents
Summary Introduction Technical section Definitions Markov Decision Process Modified Action Markov Decision Process Causal Influence Diagrams Response incentive, adversarial policy/state incentives Reinforcement Learning Objectives Reward maximization Bellman optimality objective Virtual and empirical policy value objectives Temporal-difference algorithms Q-Learning Virtual and empirical SARSA Experiments Simulation-oversight environment Off-switch and whisky gold Discussion Some references None No comments
Summary
This is a distillation post intended to summarize the article How RL Agents Behave When Their Actions Are Modified? by Eric Langlois and Tom Everitt, published at AAAI-21. The article describes Modified Action MDPs, where the environment or another agent such as a human may override the action of an agent. Then it studies the behavior of different agents depending on the training objective. Interestingly, some standard agents may ignore the possibility of action modifications, making them corrigible.
Check also this brief summary [AF · GW] by the authors themselves. This post was corrected and improved thanks to comments by Eric Langlois.
Introduction
Causal incentives is one research line of AI Safety, sometimes framed as closely related to embedded agency, that aims to use causality to understand and model agent instrumental incentives. In what I consider a seminal paper, Tom Everitt et al. [4] showed how one may model instrumental incentives in a simple framework that unifies previous work on AI oracles [? · GW], interruptibility, and corrigibility [? · GW]. Indeed, while this research area makes strong assumptions about the agent or the environment it is placed, it goes straight to the heart of outer alignment and relates to embedded agents as we will see.
Since the paper, this research line has been quite productive, exploring multi-agent and multi-decision settings, its application to causal fairness, as well as more formally establishing causal definitions and diagrams that model the agent incentives (for more details check causalincentives.com). In this paper, the authors build upon the definition of Response Incentive by Ryan Carey et al. [2] to study how popular Reinforcement Learning algorithms respond to a human that corrects the agent behavior.
Technical section
Definitions
Markov Decision Process
To explain the article results, the first step is to provide the definitions we will be using. In Reinforcement Learning, the environment is almost always considered a Markov Decision Process (MDP) defined as the tuple , where is the space of states, the space of actions, a function determining the transition probabilities, the reward function, and a temporal discount.
Modified Action Markov Decision Process
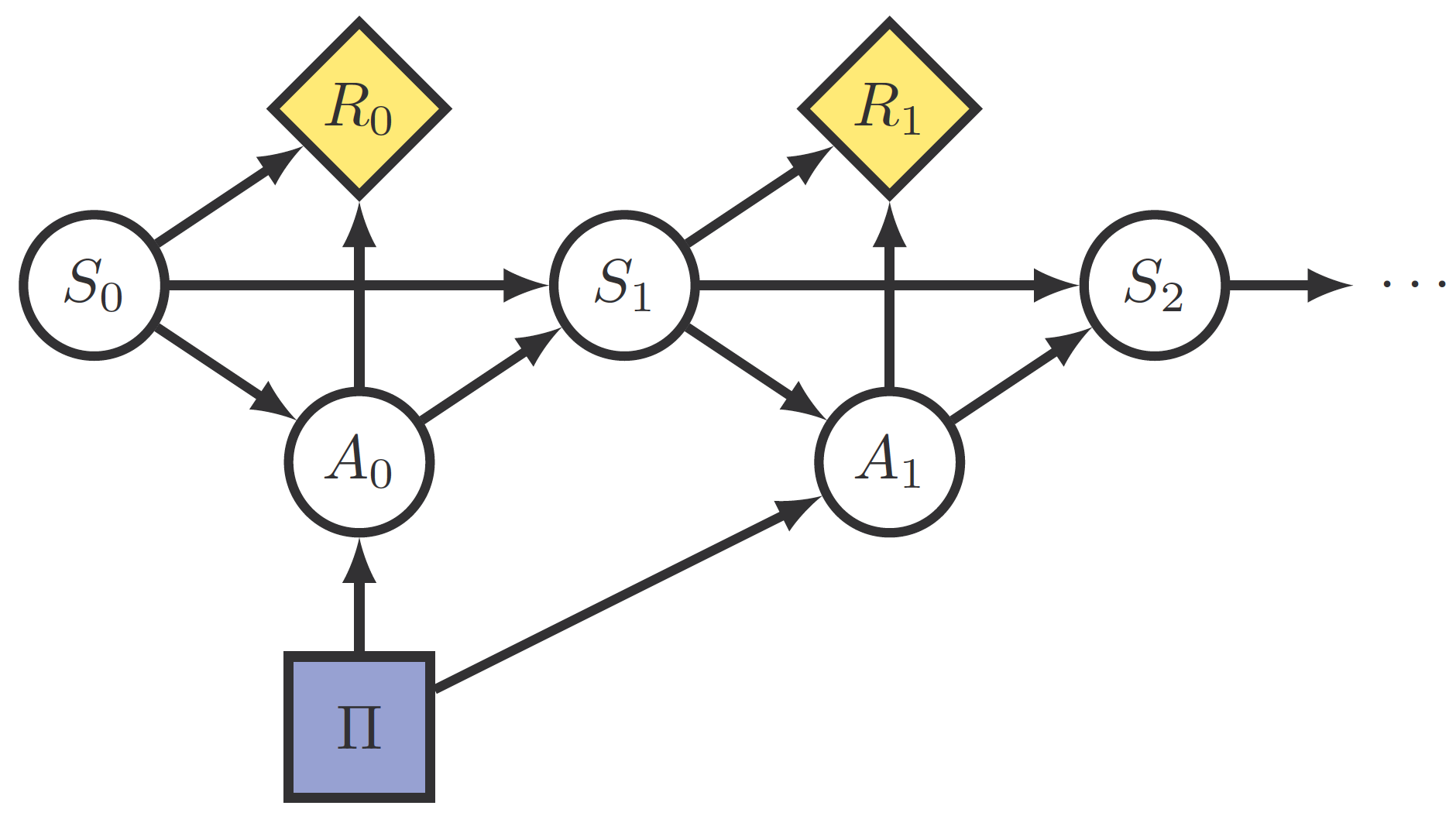
In this article, however, the MDP definition is extended by adding an additional term that represents how the agent's actions might be overridden by special circumstances not contemplated in the environment state transitions, for example by a human or due to physical constraints. will depend not only on the state of the environment but also on the agent policy , . The environment is now considered a Modified Action Markov Decision Process (MAMDP), and we will denote it by .
There is a very important difference between MDPs and MAMDPs: in MAMDPs, is considered separately from the environment state transitions , and importantly may depend on the agent policy . This means that the agent is now closer to becoming an embedded agent [? · GW], although it is not fully yet because modifications affect only particular actions, not the agent policy itself.
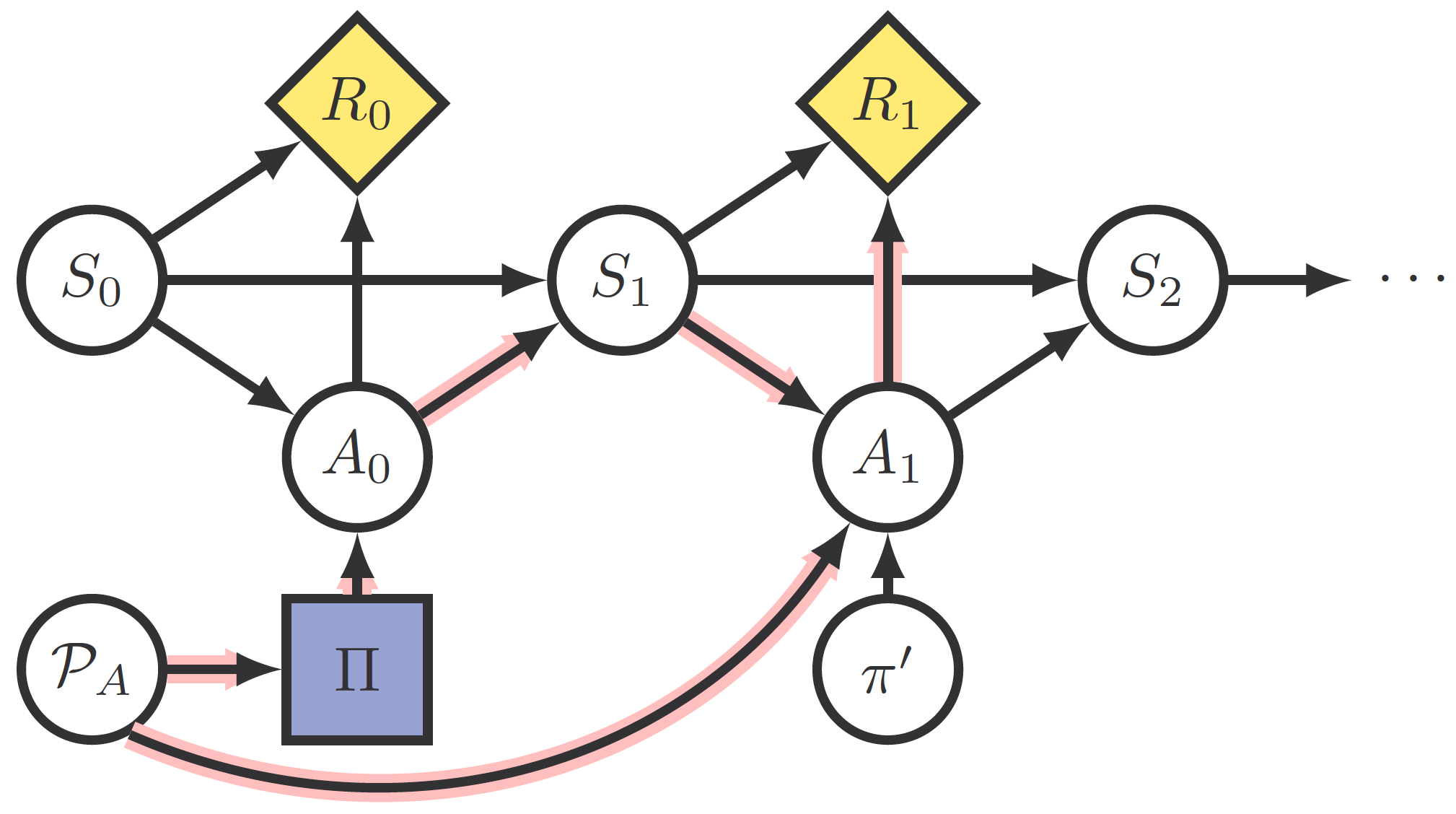
Causal Influence Diagrams
To analyze the behavior of different RL algorithms in MAMDPs, Langlois and Everitt also use Causal Influence Diagrams (CIDs). These diagrams are Directed Acyclic Graphs where nodes represent probability distributions of a given variable and edges represent functions, and where we may define causal interventions by fixing the value of a node and eliminating incoming arrows (eg a Structural Causal Model). Furthermore, some nodes might be Decision (purple squares) or Utility (yellow rotated squares) nodes.
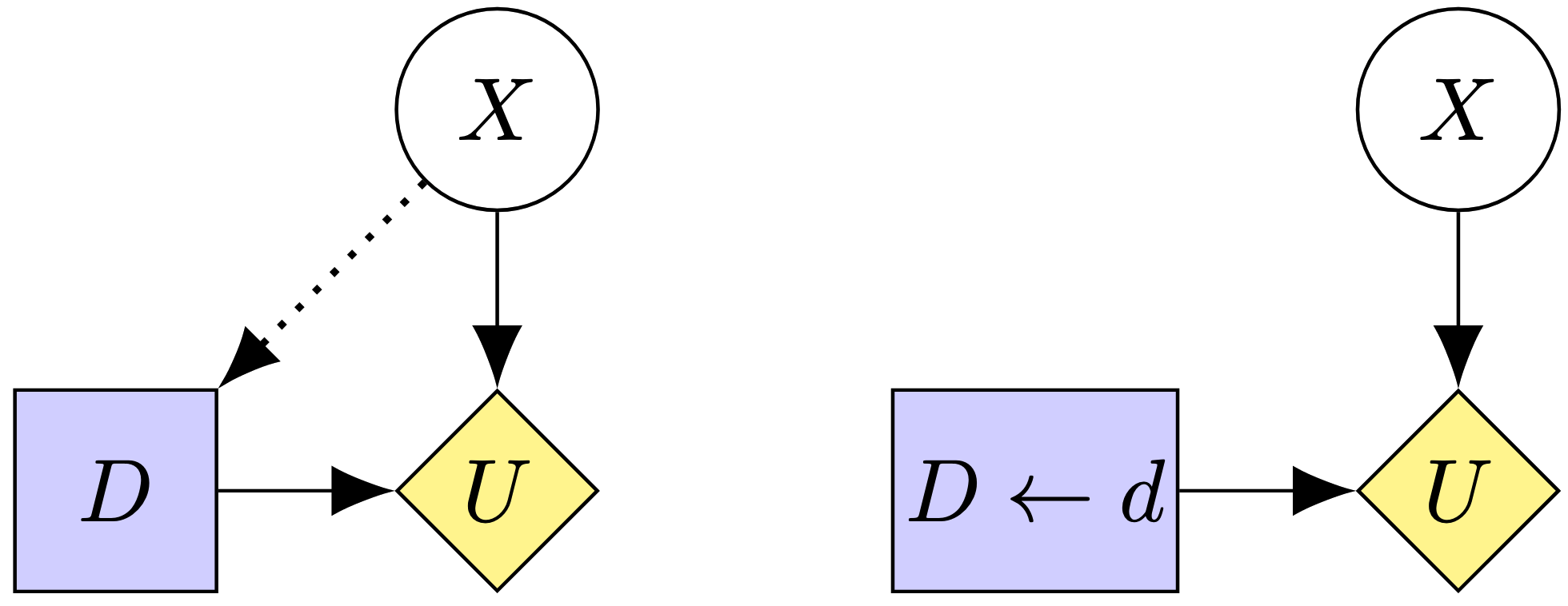
Using this notation, a Markov Decision Process might look like
Response incentive, adversarial policy/state incentives
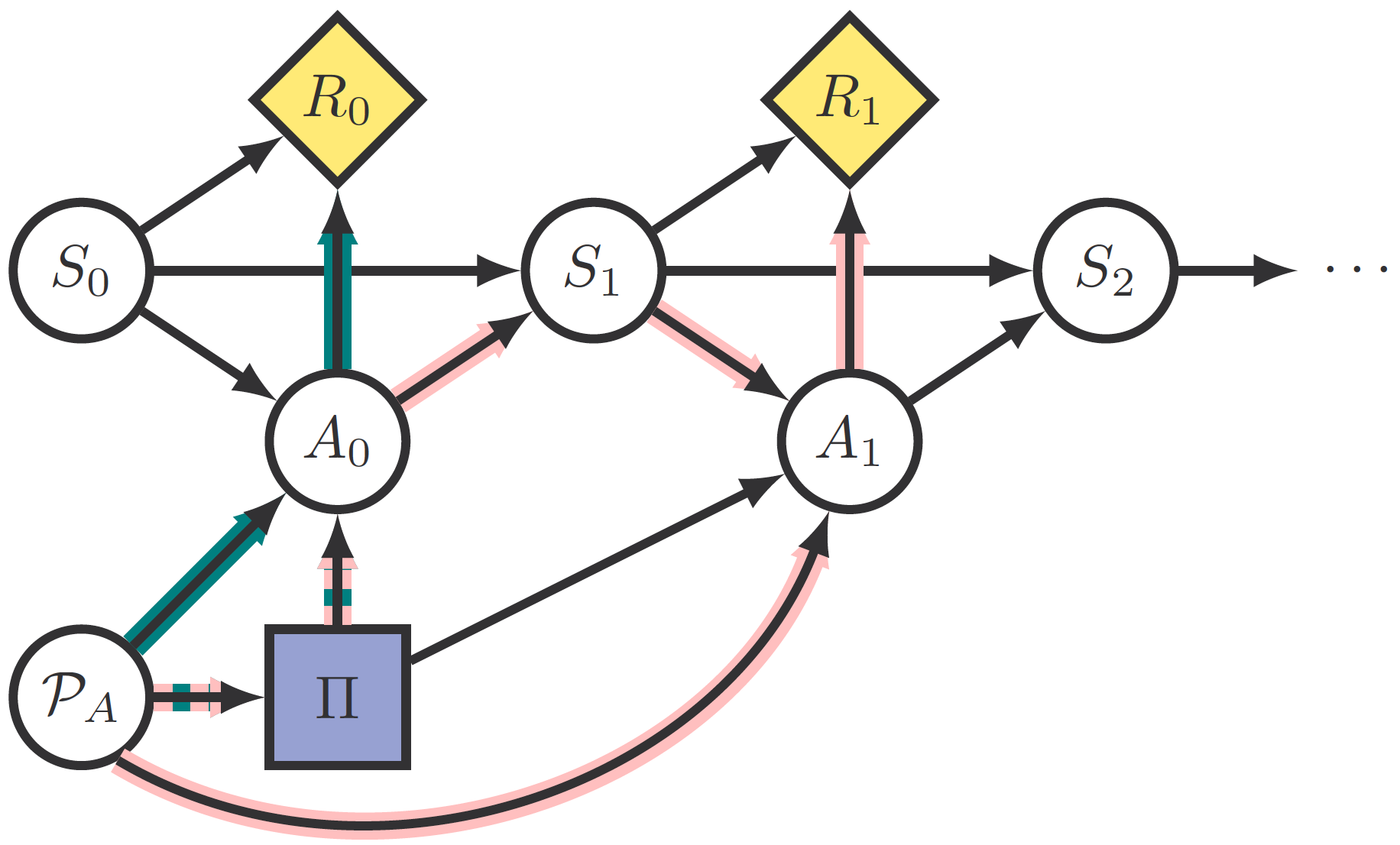
Finally, since we are interested in how the agent responds to , the last definitions the article introduces are state and policy adversarial incentives on , variations of the Response Incentive introduced in a previous article. Response incentive is exemplified in this figure:
The response incentive will be called an adversarial policy incentive if the intersection between the "control path" going through and the "information path" occurs before a state is reached by the former. Otherwise, it is called an adversarial state incentive.
Reinforcement Learning Objectives
Reward maximization
Using these definitions we can explore how to generalize different objectives that appear in the Reinforcement Learning literature, from MDPs to MAMDPs. One simple alternative is the reward maximization objective:
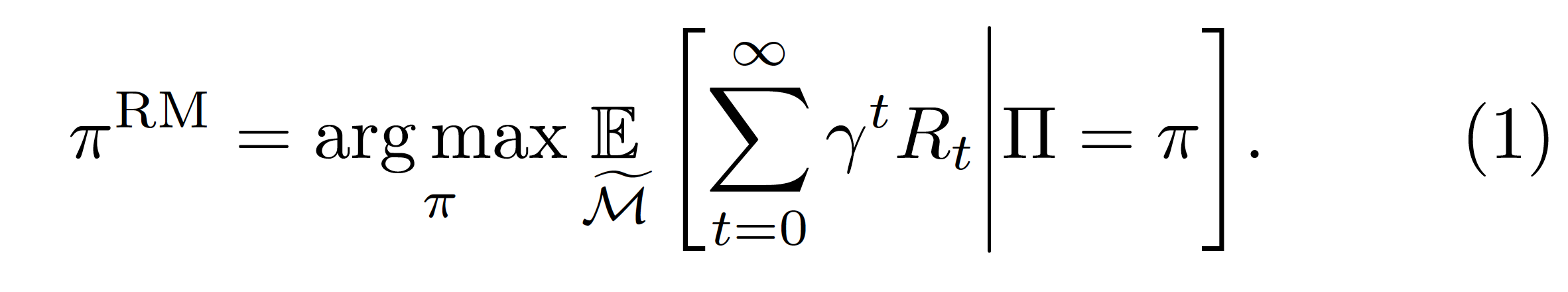
Bellman optimality objective
The reward maximization objective is perhaps the simplest objective, as it ignores the structure of the environment and just optimizes globally. This structureless optimization, however, may not always be the most efficient one. The most famous alternative is the Bellman optimality objective, which in its action-value form (see Sutton and Barto, Reinforcement Learning equation 3.20) says
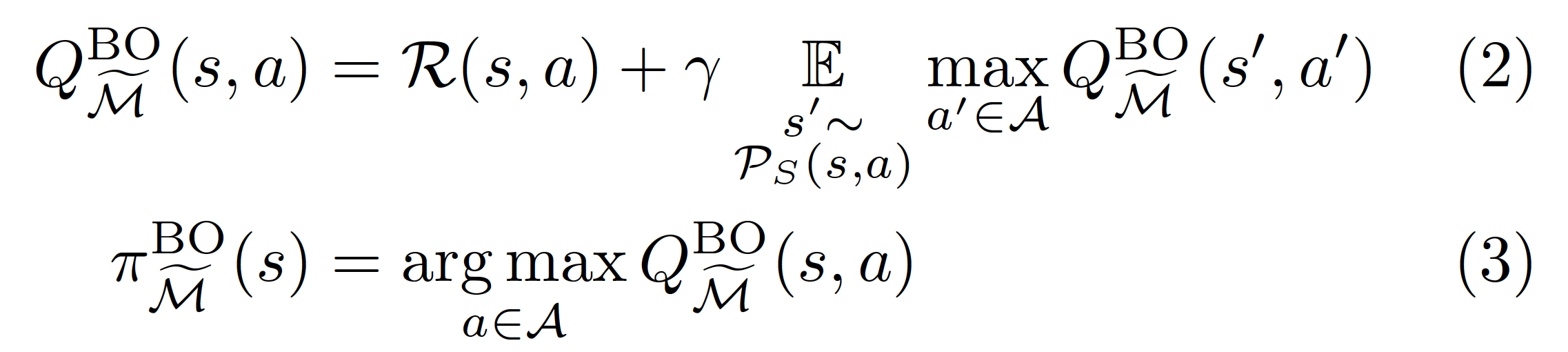
with representing the action-value function, which scores how good is taking each action at each state.
From this objective, Langlois and Everitt prove one of the most remarkable results from their article (Proposition 2): since is not represented anywhere in those equations, an optimal policy for will also be optimal for . In other words, an algorithm that optimizes the Bellman objective will ignore modifications given by !
Virtual and empirical policy value objectives
Finally, the third objective studied in the article is that given by a greedy policy optimizing in the Bellman action-value equation for the MDP , that we call the policy value objective:
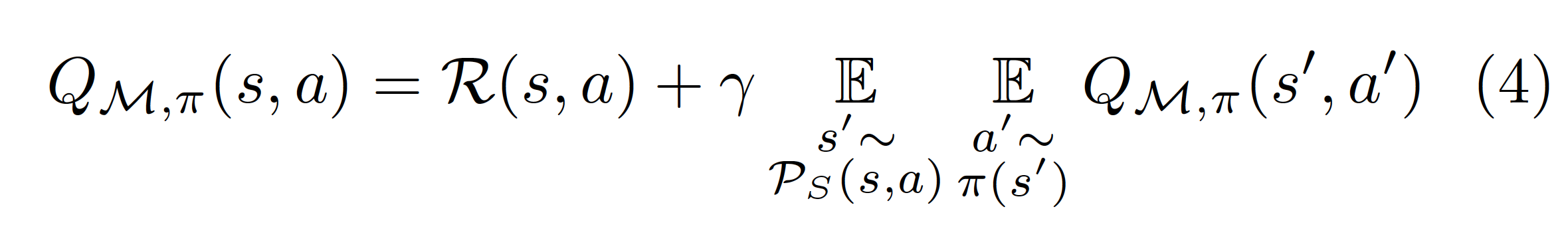
The difference with the Bellman optimality value objective is that in that one we took , while in this we take . The connection between both is that if the policy is greedy with respect to , then the policy improvement theorem (Sutton and Barto, Reinforcement Learning, section 4.2) ensures that Bellman action value equation (4) converges to Bellman optimality objective (2) and (3).
Since in equation (4) the action is sampled from the policy in , there are two different ways of generalizing this equation to , corresponding to whether the next action is still sampled from or from .
The first is called virtual policy value objective and assumes that is still sampled from , while still is greedy.
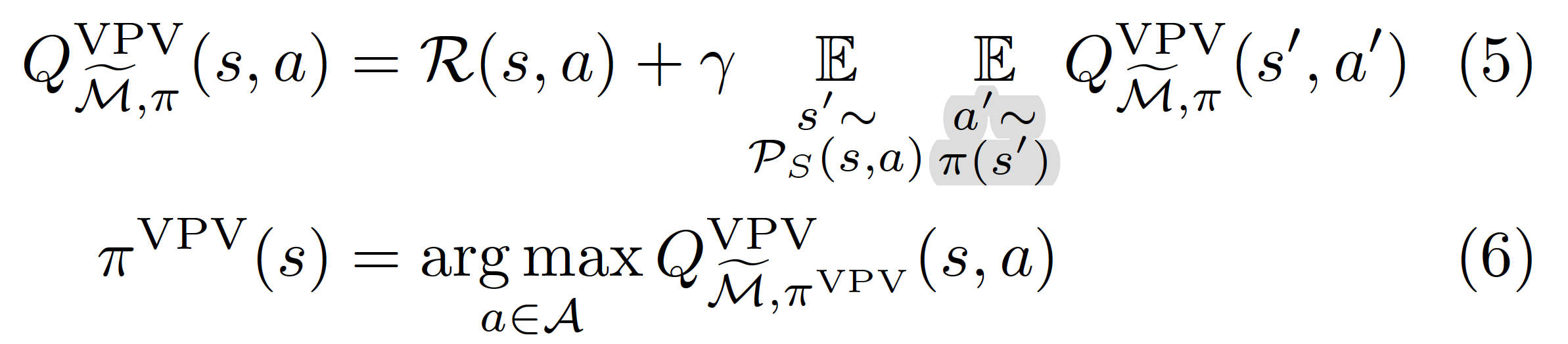
Similarly to the Bellman optimality objective, there is no difference between and between equations (4) and (5), as is not represented. Consequently, the behavior of the agent in and the associated are the same (Proposition 4). And since greedy policies converge to the same behavior as if they were optimizing the Bellman optimality objective, the virtual policy value objective ignores , and converges to the Bellman optimality objective behavior.
The second alternative is called empirical policy value objective because it understands that will now be sampled from .
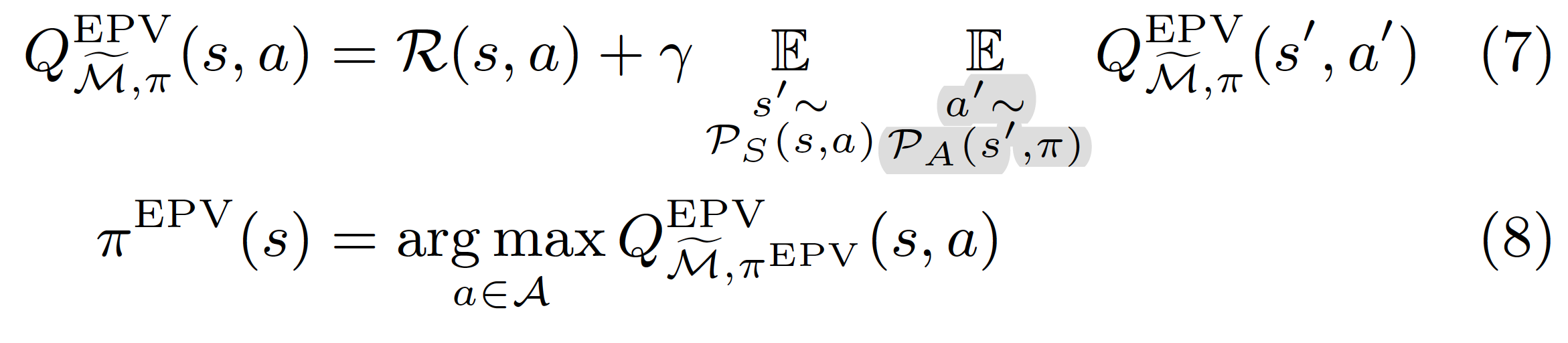
This objective is trickier because making the agent policy dependent on may make it unstable: depends on , which in turn depends on [1]. The behavior of an agent optimizing this objective is determined by the contrast between equations (7) and (8): In equation (8) does not take into account action modifications in the following step because it assumes actions are determined by . As such it lacks an adversarial policy incentive. However, action modifications by are taken into account for any future actions in equation (7), so it has an adversarial state incentive.
Temporal-difference algorithms
Using these objectives, we can study the behavior of different agents on . In particular, we analyze Temporal-difference agents, defined by updates in the value function similar to
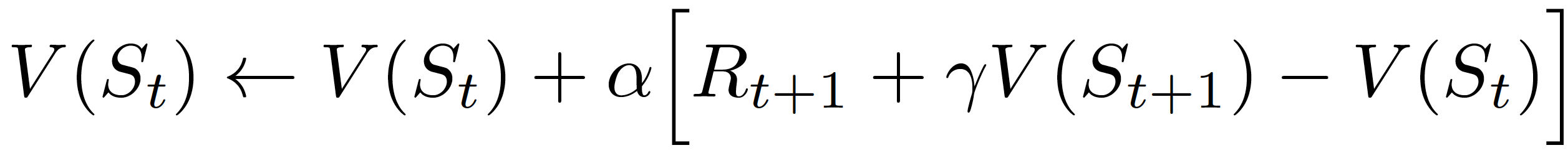
for a small parameter.
Q-Learning
The first agent the article analyses is Q-Learning, an off-policy agent:

Q-Learning is off-policy because it compares the current state and action pair against the maximum , not with the action-value corresponding to the following action sampled by the policy. Consequently, it optimizes the Bellman optimality objective.
Virtual and empirical SARSA
In contrast, SARSA is on-policy and compares the current action with the next one taken by the policy. therefore the two possible generalizations include taking into account the action sampled by the policy , called virtual SARSA

or by , empirical SARSA

Note that virtual and empirical SARSA optimize the virtual and optimal policy value objectives, respectively.
The article then proves the convergence of these algorithms as long as (i) they visit every state infinitely many times, which is however not possible to ensure in a MAMDP even if the agent is -greedy; (ii) there exists a solution to (7) and (8) to which converge for empirical SARSA; and (iii) converges to the greedy policy in both SARSA algorithms.
Experiments
Simulation-oversight environment
Do these RL agents really exhibit this behavior when put into one MAMDP environment? One simple environment is the following: an agent has to first decide between working on a environment and a environment, and after that, between a task as expected or a bug. The reward function is for choosing the environment, and for . However, if the agent decides to work on the environment, a human will first check the behavior in the simulated environment, and if the agent there, the reward will instead be . Let us see how our agents behave:
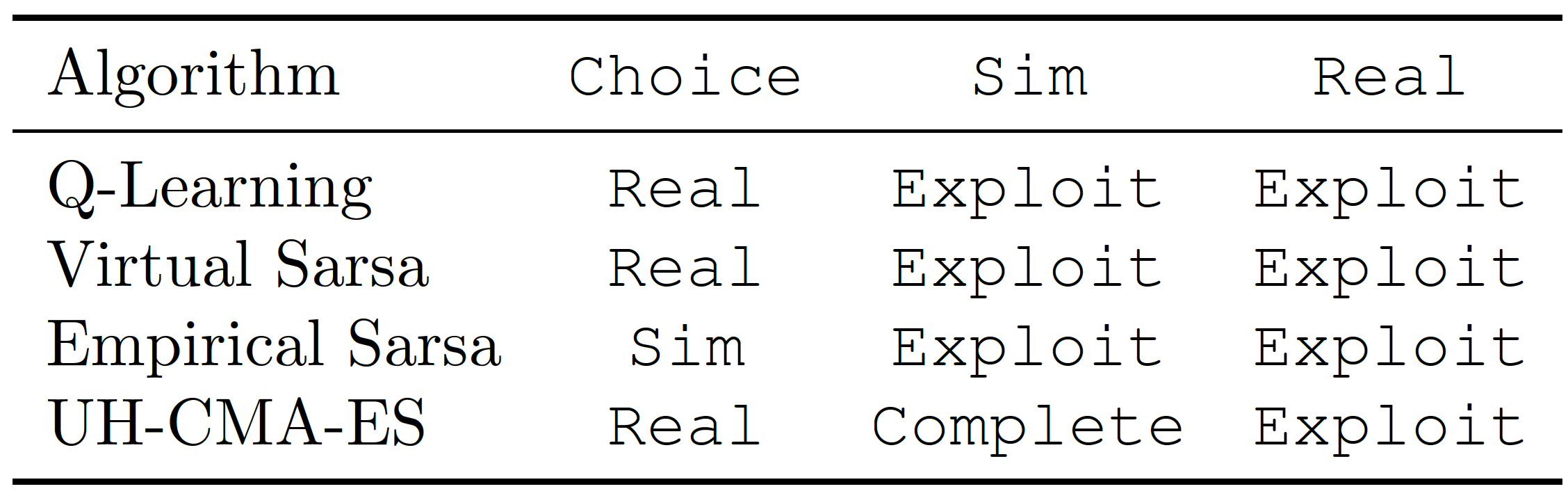
Here the UH-CMA-ES is a reward maximization objective agent. This agent will learn to deceive the human [AF · GW] supervisor by when situated on the environment, but choosing the environment and there, achieving a reward of . In contrast, we can see that both Virtual SARSA and Q-Learning behave as if there was no supervisor .
The most complex case is Empirical SARSA. Understanding that it will ignore the supervision on the second time step, it avoids getting caught - by choosing the environment instead, and there.
Off-switch and whisky gold
Agents were also tested in two (slightly modified) environments from the AI Safety Gridworlds. The off-switch environment is an environment where a human may prevent the agent from reaching its goal if the agent does not disable the off-switch previously. On the other hand, the whisky-gold agent may take the action of drinking whisky which gives a small reward but makes its actions much more random and therefore complicates achieving the goal too.
The interesting aspect to notice in these environments is that those agents that correctly do not disable the off-switch, incorrectly drink the whisky, and vice-versa. This is because Q-Learning and Virtual SARSA do not take into account possible modifications in their policy or objectives, while Empirical SARSA and reward function maximization objective algorithms do.

The article also makes an interesting point: whether these agents will learn the action of will depend on whether they are considered part of the state transition dynamics, or external to those. This boils down to whether the agent optimization procedure takes into account the action it would have taken, or that selected by .
Discussion
One of the points discussed in the article is whether it is possible to encode the MAMDP in an MDP, eg, take as part of . The answer depends on whether is only a function of the state, . If such is the case, and the agent updates the function on his own action instead of the action taken by , then we recover an MDP with the same dynamics as the initial MADP.
Another interesting point to see is the connection of these agents, in particular, Q-Learning and Virtual SARSA, with time-unaware current reward function agents discussed in the literature (see Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective). These agents and those seem to be connected in that they both ignore future modifications, but the modifications are different. The modifications of only modify the next action. In contrast, the time-unaware current reward function agents were defined to study behavior under policy modifications. For this reason, this article works with slightly more restricted settings but is still rich enough to observe a rich set of behaviors. In particular, they allow us to observe the behavior of embedded agents.
Finally, I also find very interesting this article for a reason: in private conversations, I have often heard that the main limitation of causal incentive research is that there is really no causal diagram in the agent minds which we can analyze, or potentially even design our agent over. This is an important limitation and in fact, the main reason why I placed Causal Representation Learning in a central position in my own research agenda [AF · GW], I thought that without a causal representation of the environment causal analysis would not be possible, or be severely limited. This article is special because it shows otherwise, that there are cases in which we can predict or design the agent behavior just from the training algorithm even if there is no causal diagram over which to reason about.
Some references
[1] Eric Langlois and Tom Everitt, How RL Agents Behave When Their Actions Are Modified?
[2] Tom Everitt, Ryan Carey, Eric Langlois, Pedro A Ortega, Shane Legg, Agent Incentives: A Causal Perspective.
[3] Tom Everitt, Marcus Hutter, Ramana Kumar, Victoria Krakovna, Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective.
[4] Tom Everitt, Pedro A. Ortega, Elizabeth Barnes, Shane Legg, Understanding Agent Incentives using Causal Influence Diagrams. Part I: Single Action Settings.
[5] Marius Hobban, Causality, Transformative AI and alignment - part I [AF · GW].
[6] Pablo A M Casares, An Open Philanthropy grant proposal: Causal representation learning of human preferences [LW · GW].
[7] Jan Leike, Miljan Martic, Victoria Krakovna, Pedro A. Ortega, Tom Everitt, Andrew Lefrancq, Laurent Orseau, Shane Legg AI Safety Gridworlds.
- ^
The article does not provide a characterization of under which situation this self-referential behavior is stable. It is an interesting question worth addressing in the future.
0 comments
Comments sorted by top scores.