Posts
Comments
Looking forward to getting clarity!
"we would have ended up with similar forecasts in terms of their qualitative conclusions about how plausible AGI in/by 2027 is" if this is with regard to perturbation studies of the two super-exponential terms, I believe based on the work I've shared in part here it is false, but happy to agree to disagree on the rest :)
I honestly think that's pretty irrelevant since the data are purely produced through non-reproducible intuited or verbally justified parameter estimates, so intentionality is completely opaque to readers, which is really the bigger core problem with the exercise.
Okay, we have a more fundamental disagreement than I previously realized. Can you tell me which step of the following argument you disagree with:
- It's important to forecast AGI timelines.
- In order to forecast AGI timelines while taking into account all significantly relevant factors, one needs to use intuitive estimations for several important parameters.
- Despite (2), it's important to try anyways and make the results public to (a) advance the state of public understanding of AGI timelines and (b) make our reasoning for our timelines more transparent than if we gave a vague justification with no model.
- Therefore, it's a good and important thing to make and publish models like ours
I have nothing against publishing models like this! I think the focus should be on modeling assumptions like super-exponentiality and treated as modeling exercises first-and-foremost. Assumptions that highly constrain the model should be first and foremost rather than absent from publicly facing write-ups and only in appendices. Perturbation tests should be conducted and publicly shown. It is true that I don't think this represents high-quality quantitative work, but that doesn't mean I don't think any of it is relevant, even if I think the presentation does not demonstrate a good sense of responsibility. The hype and advertising-ness of the presentation is consistent, and while I have been trying to avoid particular comment thereon, it is a constant weight hanging over the discussion. Publication of a model and breathless speculation are not the same, and I really do not want to litigate the speculative aspects but they are the main thing everyone is talking about including in the New York Times.
I think this is not true, but I don't think it is worth litigating separately from the research progress super-exponential factor which is also modeled as already happening. so it is easeir (though I don't think easy) to defend both individually based on small potatoes evidence of a speedup, but I can't imagine how both could be defended at once, so that has to come first so we don't double count evidence.
I don't understand why you think we shouldn't account for research progress speedups due to AI systems on the way to superhuman coder. And this is clearly a separate dynamic from the trend being possibly superexopnential without these speedups taken into account (which, again, we already see some empirical evidence for this possibility). I'd appreciate if you made object-level arguments against one or both of these factors being included.
I think this has a relatively simple crux
- Research progress has empirically slowed according to your own source of EpochAI (Edit: as a percentage of all progress which is the term used in the model. It is constant in absolute terms)
- You assume the opposite which would explain away the METR speed-up on its own
- So justifying the additional super-exponential term with the METR speed-up is double counting evidence
Then, split out the
calculate_base_timefunction from thecalculate_sc_arrival_yearfunction and plot those results (here is my snippet to adjust the base time to decimal year and limit to the super-exponential group:base_time_in_months[se_mask] / 12 + 2025). You'll have to do some simple wrangling to expose the se_mask and get the plotting function to work but nothing substantive.Could you share the code on a fork or PR?
I can drop my versions of the files in a drive or something, I'm just editing on the fly, so they aren't intended to be snapshotted, but here you go!
https://drive.google.com/drive/folders/1_e-hnmSy2FoMSD4UiWKWKNKnsapZDm1M?usp=drive_link
Edit:
Imagine if climate researchers had made a model where carbon impact on the environment gets twice-to-infinity times larger in 2028 based on "that's what we think might be happening in Jupiter."
A few thoughts:
- Climate change forecasting is fundamentally more amenable to grounded quantitative modeling than AGI forecasting, and even there my impression is that there's substantial disagreement based on qualitative arguments regarding various parameter settings (though I'm very far from an expert on this).
- Forecasts which include intuitive estimations are commonplace and often useful (see e.g. intelligence analysis, Superforecasting, prediction markets, etc.).
- I'd be curious if you have the same criticism of previous timelines forecasts like Bio Anchors.
- I don't understand your analogy re: Jupiter. In the timelines model, we are trying to predict what will happen in the real world on Earth.
4. The analogy is that the justification uses analogy to humans which are notably not LLMs. If it is purely based on the METR "speed-up" that should be made more clear as it is a (self-admittedly) weak argument.
Thanks a lot for digging into this, appreciate it!
Of course, appreciate the response!
being bad at 10% and 90% work
Is the 10% supposed to say 50%?
This was a rebuttal to Ryan's defense of the median estimates by saying that, well, the 10/90th might not be as accurate esp with weird parameters, but the 50th might be fine. So I was trying to show that the 50th was the heart of the problem in response.
Yup, very open to the criticism that the possibility and importance of superexponentiality should be highlighted more prominently. Perhaps it should be highlighted in the summary? To be clear, I was not intentionally trying to hide this. For example, it is mentioned but not strongly highlighted in the corresponding expandable in the scenario ("Why we forecast a superhuman coder in early 2027").
Not implying intentional hiding! I honestly think that's pretty irrelevant since the data are purely produced through non-reproducible intuited or verbally justified parameter estimates, so intentionality is completely opaque to readers, which is really the bigger core problem with the exercise. Imagine if climate researchers had made a model where carbon impact on the environment gets twice-to-infinity times larger in 2028 based on "that's what we think might be happening in Jupiter." Nobody here would care about intentionality and I don't think we should care or think it matters most in this case either.
I will defend the basic dynamics though of substantial probability of a superexponentiality leading to a singularity on an extended version of the METR time horizon dataset being reasonable. And I don't think it's obvious whether we model that dynamic as too fast or too slow in general.
I think this is not true, but I don't think it is worth litigating separately from the research progress super-exponential factor which is also modeled as already happening. so it is easeir (though I don't think easy) to defend both individually based on small potatoes evidence of a speedup, but I can't imagine how both could be defended at once, so that has to come first so we don't double count evidence.
Here is the parameter setting for the "singularity-only" version:
eli_wtf:
name: "Eli_wtf 15 Min Horizon Now"
color: "#800000"
distributions:
h_SC_ci: [1, 14400] # Months needed for SC
T_t_ci: [4, 4.01] # Horizon doubling time in months
cost_speed_ci: [0.5, 0.501] # Cost and speed adjustment in months
announcement_delay_ci: [3, 3.01] # Announcement delay in months (1 week to 6 months)
present_prog_multiplier_ci: [0.03, 0.3] # Progress multiplier at present - 1
SC_prog_multiplier_ci: [1.5, 40.0] # Progress multiplier at SC - 1
p_superexponential: 0.45 # Probability of superexponential growth
p_subexponential: 0.1 # Probability of subexponential growth
se_speedup_ci: [0.05, 0.5] # UNUSED; 80% CI for superexponential speedup (added to 1)
sub_slowdown_ci: [0.01, 0.2] # UNUSED; 80% CI for subexponential slowdown (subtracted from 1)
se_doubling_decay_fraction: 0.1 # If superexponential, fraction by which each doubling gets easier
sub_doubling_growth_fraction: 0.1 # If subexponential, fraction by which each doubling gets harderThen, split out the calculate_base_time function from the calculate_sc_arrival_year function and plot those results (here is my snippet to adjust the base time to decimal year and limit to the super-exponential group: base_time_in_months[se_mask] / 12 + 2025 ). You'll have to do some simple wrangling to expose the se_mask and get the plotting function to work but nothing substantive.
I don't think the defense of being bad at 10% and 90% work because those are defined by the non-super-exponential scenarios, and they are detached from the crux of the problem. Those are the more honest numbers as they actually respond to parameter changes in ways at least attempting to be related to extrapolation.
40-45% of the population, who almost necessarily define the median alone, have a honest, to-infinity singularity at 25-90 months that then gets accelerated a bit further by the secondary super-exponential factor, research progress multipliers. This basically guarantees to a median result in 2-5 years (honestly tighter than that unless you are doing nanoseconds), give or take the additive parameters, that has nothing to do with what people think the model is saying.
If the model is about "how far we are to super-human effort and are extrapolating how long it takes to get there", a median-defining singularity that is not mentioned except in a table is just not good science.
For another look, here is a 15 millisecond-to-4 hour time horizon comparison just in the super-exponentiated plurality.
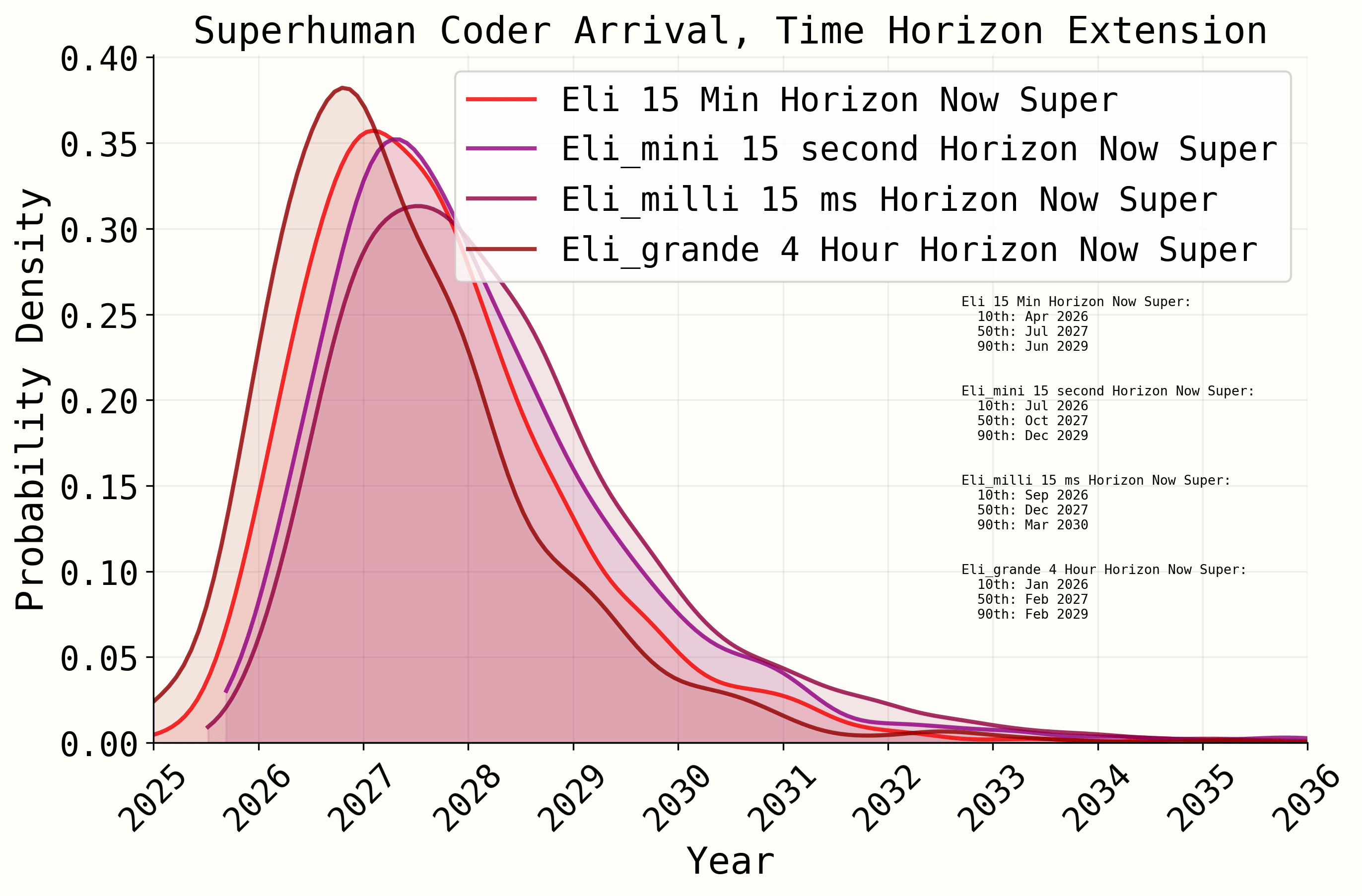
This is a prediction with output deviations representing maybe hundredth-SD movements over parameter changes of 10^6 (on the baseline parameter) in an estimation task that includes terms with doubly-exponentiated errors.
I don't think something like this is defensible based on the justification given in the appendix, which is that forecasters (are we forecasting or or trend-extrapolating pre-super-coders?) think the trend might go straight to infinity before 10 doublings (only 1024x) because humans are better going from 1-2 year tasks than 1-2 month tasks.
Edit: as I am newbie-rate-limited may not be able to talk immediately!
Here is the pure singularity isolated (only the first super-exponential function applied) and the same with normal parameters, which mostly just hide what's happening:
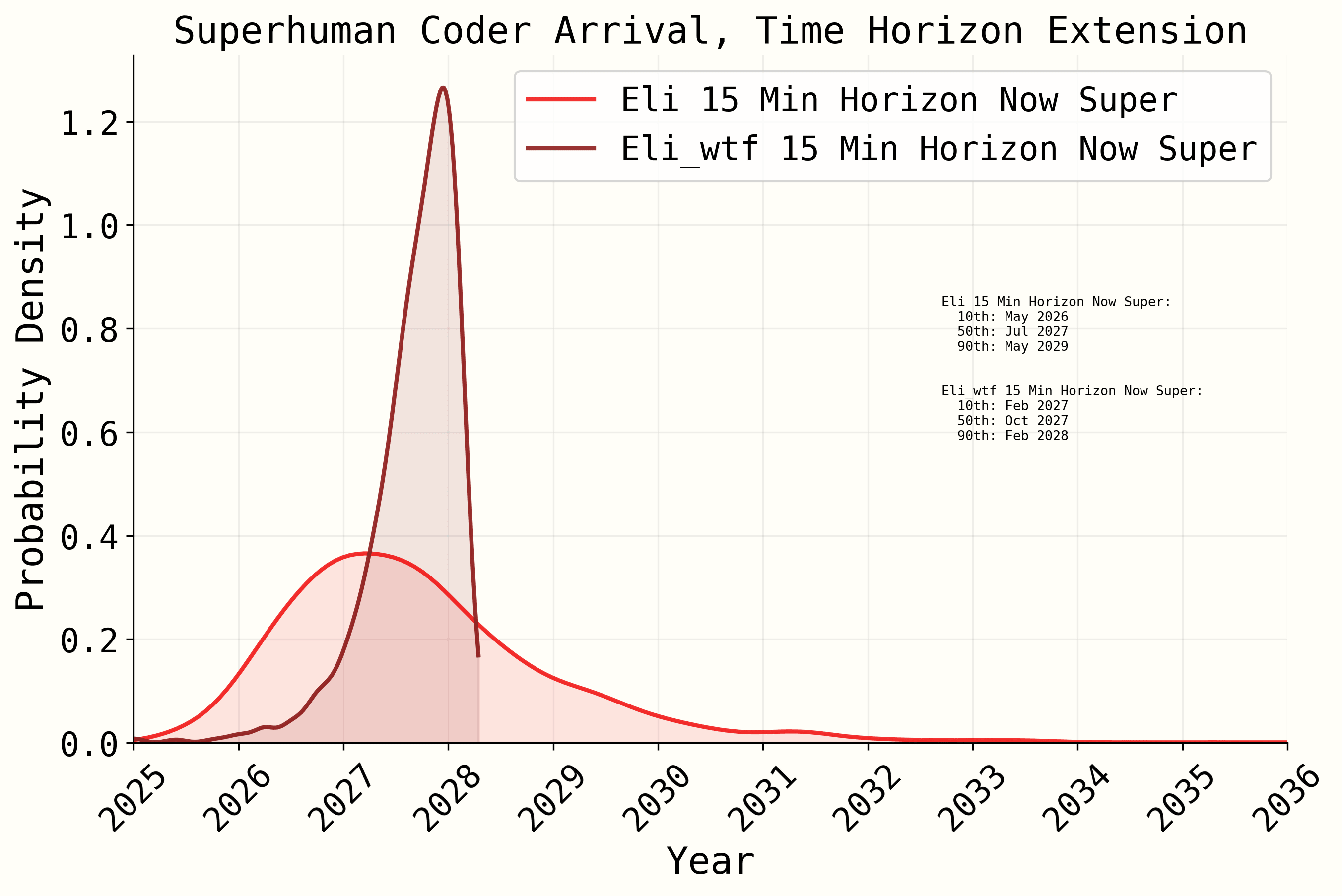
I took a look at the timeline model, and I unfortunately have to report some bad news...
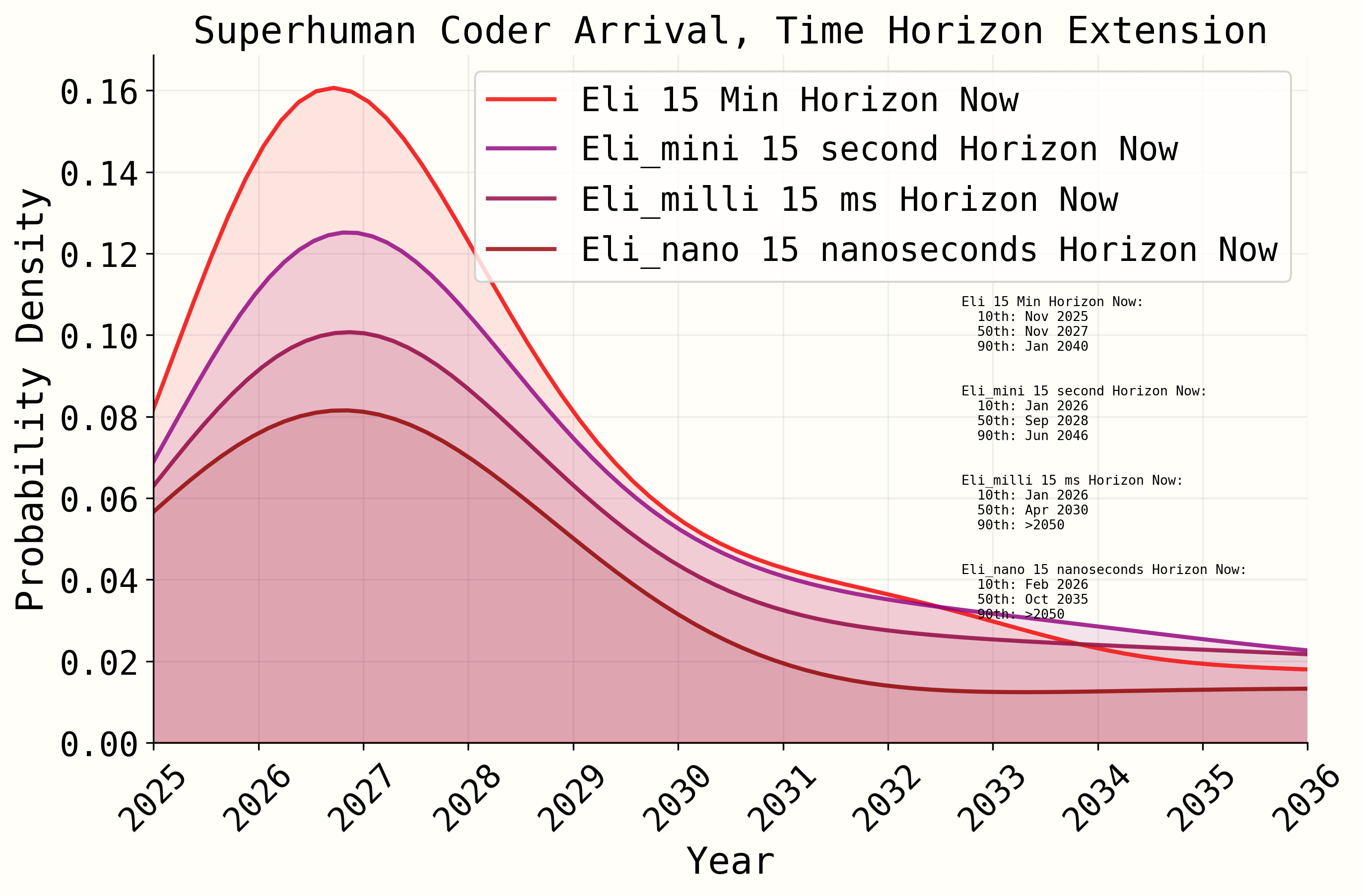
The model is almost entirely non-sensitive to what the current length of task an AI is able to do.
The reasons are pretty clear, there are three major aspects that force the model into a small range, in order:
- The relatively unexplained additional super-exponential growth feature causes an asymptote at a max of 10 doubling periods. Because super-exponential scenarios hold 40-45% of the weight of the distribution, it effectively controls the location of the 5th-50th percentiles, where the modal mass is due to the right skew. This makes it extremely fixed to perturbations.
- The second trimming feature is the algorithmic progression multipliers which divide the (potentially already capped by super-exponentiation) time needed by values that regularly exceed 10-20x IN THE LOG SLOPE.
- Finally, while several trends are extrapolated, they do not respond to or interact with any resource constraints, neither that of the AI agents supposedly representing the labor inputs efforts, nor the chips their experiments need to run on. This causes other monitoring variables to become wildly implausible, such as effective compute equivalents given fixed physical compute.
The more advanced model has fundamentally the same issues, but I haven't dug as deep there yet.
Hope to hear back, I am pretty worried given all the efforts that have gone into this :/
Thanks for this! Lots to think about!
I'm a little worried I don't think the argument from algorithmic progress works as stated.
Let's assume Agent-0 or 1 take us from today where AI tools generously can reduce labor hours for a researcher writing code full-time by 5-15% to a world where it can reduce a researcher's total labor time by 80% (where checking code and tests visually, hitting confirmations, and skimming their own research papers as they get produced independently are the only tasks an AI researcher is doing). With that kind of best-case situation, doesn't it still only affect OpenAI's total velocity marginally, since all of their statements suggest the major input constraint is chips?
I think there's a bit of a two-step going on:
- Propose algorithmic progress as a separable firm-level intermediate product that lacks (or has minimal) chip constraints, instead mostly "AI Researcher" labor input.
- Then we assert massive increases in labor productivity and/or quality of AI Researcher labor (based on industry-secret future agent improvements).
- Then we get a virtuous cycle where the firm can reinvest the algorithmic progress back into labor productivity and quality increases.
I think there's a few counterarguments:
- Most of the increases in algorithmic progress in your own source came at high costs of compute (e.g. Chinchilla scaling laws), so it's unlikely sustained algorithmic progress does not require a very large chip input.
-
- If labor productivity and quality were about to massively increase, and labor input increases can enable a firm-level virtuous cycle while not being subject to chip constraints and there are large uncertainties around said productivity and quality increases, OpenAI would be increasing mass of labor at any cost.
- OpenAI is not focused on hiring, they are focused on acquiring chips, even in the medium term, so they do not believe this flywheel will occur anytime soon.
- Another big problem is that algorithmic progress is very much not firm-level, and attempts to monopolize algorithmic improvements are very hard to enforce even in the short-term (outside things that get very authoritarian and censorious fast)
- Your estimate that algorithmic progress currently is half of capabilities progress is likely inflated by 3-10x, as the vast majority of percentage-wise algorithmic progress happens before the transformer is released, and post-2018 algorithmic progress estimated as a percentage of progress is about 5-15% (see below)
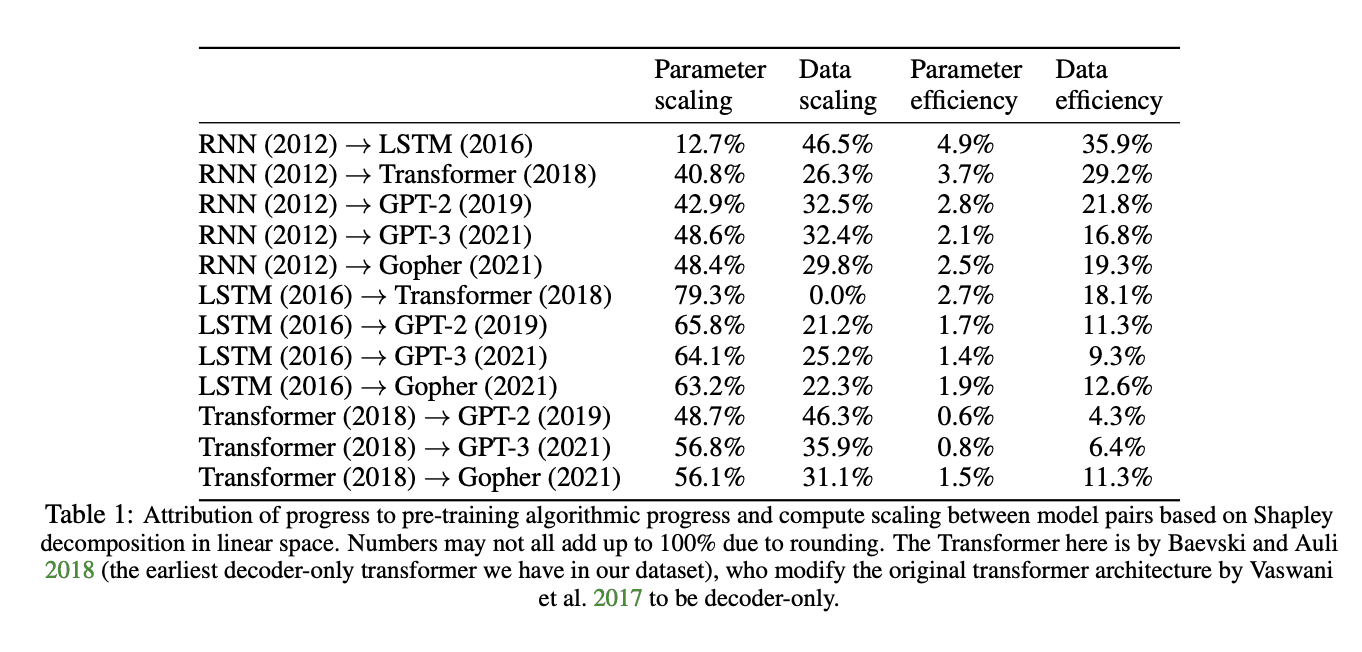
5. The doubling rate of algorithmic progress in terms of effective compute (via that paper) appears quite stable even as the amount of AI researcher labor dedicated to it has multiplied to a huge degree, so even if we do grant an immediate 5x increase in effective AI researcher labor at OpenAI, there's little reason to expect it to do much beyond a one-time jump of a year's purely algorithmic progress or so (or about ~1.5-8x effective compute or a couple months total progress) (given OpenAI fraction of labor pool etc. and with some lag for adjustment).
To achieve an ongoing 1.5x AI R&D progress multiplier (and this multiplier applies to the 5-15% of all progress not the 50% of all progress), you need:
- The productivity gain for AI researchers to be enough for OpenAI's AI Research labor to equal the rest of the world (give-or-take, but 5x productivity seems a reasonable lower estimate).
- Then, through hiring and/or even further productivity/labor quality multiplier improvements, OpenAI needs to increase their labor input by a yearly factor approx. equaling the yearly growth rate in total AI Researcher labor since 2018, probably upwards of an additional 1.5-2x increase in effective AI Researcher labor per subsequent year ongoing forever.
- This all is assuming there is zero marginal decline in input efficiency of AI Researcher labor, so if you need even a few percent more chips per labor unit the virtuous cycle burns out very fast.
The basic story is just that there is no plausible amount of non-breakthrough R&D that will make up for the coming slowing of compute doubling times. Attempts to hold on to monopolistic positions through hoarding research or chips will fail sooner than later because we are not getting capabilities explosion in the next 2-3 years (or 10, but ymmv).