Posts
Comments
Is humanity expanding beyond Earth a requirement or a goal in your world view?
A novel theory of victory is human extinction.
I do not personally agree with it, but it is supported by people like Hans Moravec and Richard Sutton, who believe AI to be our "mind children" and that humans should "bow out when we can no longer contribute".
I recommend the follow up work happens.
This would depend on whether algorithmic progress can continue indefinitely. If it can, then yes the full Butlerian Jihad would be required. If it can't, either due to physical limitations or enforcement, then only computers over a certain scale would be required to be controlled/destroyed.
There is a AI x-risk documentary currently being filmed. An Inconvenient Doom. https://www.documentary-campus.com/training/masterschool/2024/inconvenient-doom It covers some aspects on AI safety, but doesn't focus on it exactly.
I also agree 5 is the main crux.
In the description of point 5, the OP says "Proving this assertion is beyond the scope of this post,", I presume that the proof of the assertion is made elsewhere. Can someone post a link to it?
I'm thirty-something. This was about 7 years ago. From the inhibitors? Nah. From the lab: probably.
We still smell plenty of things in a university chemistry lab, but I wouldn't bother with that kind of test for an unknown compound. Just go straight to NMR and mass spec, maybe IR depending on what you guess you are looking for.
As a general rule don't go sniffing strongly, start with carefully wafting. Or maybe don't, if you truly have no idea what it is.
Most of us aren't dead. Just busy somewhere else.
I used to work in a chemistry research lab. For part of that I made Acetylcholinesterase inhibitors for potential treatment of Parkinson's Alzhiemer's. These are neurotoxins. As a general rule I didn't handle more than 10 lethal doses at once, however on one occasion I inhaled a small amount of the aerosolized powder and started salivating and I pissed my pants a little.
As for tasting things, we made an effort to not let that happen. However as mentioned above, some sweeteners are very potent, a few micrograms being spilt on your hands, followed by washing, could leave many hundred nanograms behind. I could see how someone would notice this if they ate lunch afterwards.
While tasting isn't common, smelling is. Many new chemicals would be carefully smelt as this often gave a quick indication if something novel had happened. Some chemical reactions can be tracked via smell. While not very precise, it is much faster than running an NMR.
I think this distinction between "control" and "alignment" is important and not talked about enough.
Meta question: is the above picture too big?
Ok so the support score is influenced non-linearly by donor score. Is there a particular donor that has donated to the highest ranked 22 projects, that did not donate to the 23 or lower ranked projects?
I have graphed donor score vs rank for the top GiveWiki donors. Does this include all donors in the calculation or are there hidden donors?
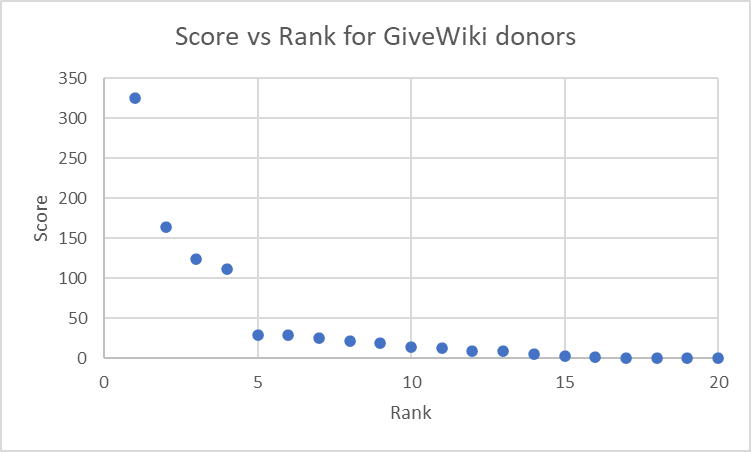
We see a massive drop in score from the 22nd to the 23rd project. Can you explain why this is occurring?
Thank you for writing this Igor. It helps highlight a few of biases that commonly influence peoples decision making around x-risk. I don't think people talk about this enough.
I was contemplating writing a similar post to this around psychology, but I think you have done a better job than I was going to. Your description of 5 hypothetical people communicates the idea more smoothly than what I was planning. Well done. The fact that I feel a little upset that I didn't write something like this sooner, and the fact that the other comment has talked about motivated reasoning, produces an irony that it not lost on me.
I agree with your sentiment that most of this is influenced by motivated reasoning.
I would add that "Joep" in the Denial story is motivated by cognitive dissonance, or rather the attempt to reduce cognitive dissonance by discarding one of the two ideas "x-risk is real and gives me anxiety" and "I don't want to feel anxiety".
In the People Don't Have Images story, "Dario" is likely influenced by the availability heuristic, where he is attempting to estimate the likelihood of a future event based on how easily he can recall similar past events.
I would agree that people lie way more than they realise. Many of these lies are self-deception.
We can't shut it all down.
Why do you personally think this is correct? Is it that humanity is unknowing of how to shut it down? Or uncapable? Or unwilling?
This post makes a range of assumptions, and looks at what is possible rather than what is feasible. You are correct that this post is attempting to approximate the computational power of a Dyson sphere and compare this to the approximation of the computational power of all humans alive. After posting this, the author has been made aware that there are multiple ways to break the Landauer Limit. I agree that these calculations may be off by an order of magnitude, but this being true doesn't break the conclusion that "the limit of computation, and therefore intelligence, is far above all humans combined".
Yea you could, but you would be waiting a while. Your reply and 2 others have made me aware that this post's limit is too low.
[EDIT: spelling]
I just read the abstract. Storing information in momentum makes a lot of sense as we know it is a conserved quantity. Practically challenging. But yes, this does move the theoretical limit even further away from all humans combined.
OK I take your point. In your opinion would this be an improvement "Humans have never completed at large scale engineering task without at least one mistake on the first attempt"?
For the argument with AI, will the process that is used to make current AI scale to AGI level? From what I understand that is not the case. Is that predicted to change?
Thank you for giving feedback.
But isn't that also using a reward function? The AI is trying to maximise the reward it receives from the Reward Model. The Reward Model that was trained using Human Feedback.
Hi Edward, I can estimate you personally care about censorship, and outside the field of advanced AI that seems like a valid opinion. You are right that humans keep each other aligned by mass consensus. When you read more about AI you will be able to see that this technique no longer works for AI. Humans and AI are different.
Having AI alignment is a strongly supported opinion in this community and is also supported by many people outside this community as well. This is link is an open letter where a range of noteworthy people talk about the dangers of AI and how alignment may help. I recommend you give it a read. Pause Giant AI Experiments: An Open Letter - Future of Life Institute
AI risk is an emotionally challenging topic, but I believe that you can find the way to understand it more.
Yea, I have to say many of my opinions on AI are from Eliezer. I have read much of his work and compared it to the other expects I have read about and talked with, and I have to say, he seems to understand the problem very well.
I agree, aligned AGI seems like a very small island in the sea of possibly. If we have multiple tries at getting it right (for example with AGI in a perfectly secure simulation), I think we have a chance. But with only effectively one try, the probability of success seems astronomically low.
Which x-risks do you think AI will reduce? I have heard arguments that it would improve our ability to respond to potential asteroid impacts. However this reduction in x-risk seems very small in comparison to the x-risk that unaligned AGI poses. What makes you estimate that AI may reduce x-risk?
How would an AI be directed without using a reward function? Are there some examples I can read?
Okay, how much risk is worth the benefit? Would you advocate for a comparison of expected gains and expected losses?
For example if humanity wanted a 50% chance of surviving another 10 years in the presence of a meta-stably-aligned ASI, the ASI would need a daily non-failure rate of x^(365.25*10)=0.5, x=0.99981 or better.
Deep Learning is notorious for continuing to work while there are mistakes in it; you can accidentally leave all kinds of things out and it still works just fine. There are of course arguments that value is fragile and that if we get it 0.1% wrong then we lose 99.9% of all value in the universe, just as there are arguments that the aforementioned arguments are quite wrong. But "one mistake" = "failure" is not a firm principle in other areas of engineering, so it's unlikely to be the case.
Ok the "An AGI that has at least one mistake in its alignment model will be unaligned" premise seems like the weakest one. Is there any agreement in the AI community about how much alignment is "enough"? I suppose it depends on the AI capabilities and how long you want to have it running for. Are there any estimates?
It's a feature of human cognition that we can make what feel like good arguments for anything.
I would tend to agree, the confirmation bias is profound in humans.
you instead asked "hey, what would AI doom predict about the world, and are those predictions coming true?"
Are suggesting a process such as: assume a future -> predict what would be required for this -> compare prediction with reality.
Rather than: observe reality -> draw conclusions -> predict the future
Thank you for your reply 1a3orn, I will have a read over some of the links you posted.
Thank you David Mears for writing this linkpost. Thank you to Philosophy Bear for writing the original post.
I agree that this survey is urgently needed.
I have had a similar issue. The model outputs the comment:
Incorrect API key provided: sk-5LW5C***************************************HGYd. You can find your API key at https://platform.openai.com/account/api-keys.
Disagree vote this post if you disagree that the topic of predicting AI development is challenging.
Disagree vote this post if you disagree with liking the simplicity of the original post.
The above reply has two disagreement votes. I am trying to discern which reasons they are for. Disagree vote this post if you disagree that Mitchell_Porters suggestion was helpful.
For those who are downvoting this post: A short one sentence comment will help the original poster make better articles in the future.
This too seems like an improvement. However I would leave out the "kills us all" bit as this is meant to be the last line of the argument.
A fair comment. Would the following be an improvement? "Some technical alignment engineers predict with current tool and resources technical alignment will take 5+ years?"
Oops I realized I have used "flaws" rather than "weaknesses". Do you consider these to be appropriate synonyms? I can update if not.
I think it was a helpful suggestion. I am happy that you liked the simplicity of the argument. The idea was it was meant to be as concise as possible to make the flaws seem more easy to spot. The argument relies on a range of assumptions but I deliberately left out the more confident assumptions. I find the topic of predicting AI development challenging, and was hoping this argument tree would be an efficient way of recognizing the more challenging parts.
As requested I have updated the title. How does the new one look?
Edit: this is a reply to the reply below, as I am commenting restricted but still want to engage with the other commenters: deleted
Edit2: reply moved to actual reply post
Thank you Jacob for taking the time for a detailed reply. I will do my best to respond to your comments.
The doubling time for AI compute is ~6 months
Source?
Source: https://www.lesswrong.com/posts/sDiGGhpw7Evw7zdR4/compute-trends-comparison-to-openai-s-ai-and-compute. They conclude 5.7 months from the years 2012 to 2022. This was rounded to 6 months to make calculations more clear. They also note that "OpenAI’s analysis shows a 3.4 month doubling from 2012 to 2018"
In 5 years compute will scale 2^(5÷0.5)=1024 times
This is a nitpick, but I think you meant 2^(5*2)=1024
I actually wrote it the (5*2) way in my first draft of this post, then edited it to (5÷0.5) as this is [time frame in years]÷[length of cycle in years], which is technically less wrong.
In 5 years AI will be superhuman at most tasks including designing AI
This kind of clashes with the idea that AI capabilities gains are driven mostly by compute. If "moar layers!" is the only way forward, then someone might say this is unlikely. I don't think this is a hard problem, but I thing its a bit of a snag in the argument.
I think this is one of the weakest parts of my argument, so I agree it is definitely a snag. The move from "superhuman at some tasks" to "superhuman at most tasks" is a bit of a leap. I also don't think I clarified what I meant very well. I will update to add ", with ~1024 times the compute,".
An AI will design a better version of itself and recursively loop this process until it reaches some limit
I think you'll lose some people on this one. The missing step here is something like "the AI will be able to recognize and take actions that increase its reward function". There is enough of a disconnect between current systems and systems that would actually take coherent, goal-oriented actions that the point kind of needs to be justified. Otherwise, it leaves room for something like a GPT-X to just kind of say good AI designs when asked, but which doesn't really know how to actively maximize its reward function beyond just doing the normal sorts of things it was trained to do.
Would adding that suggested text to the previous argue step help? Perhaps "The AI will be able to recognize and take actions that increase its reward function. Designing a better version of itself will increase that reward function" But yea I tend to agree that there needs to be some sort of agentic clause in this argument somewhere.
Such any AI will be superhuman at almost all tasks, including computer security, R&D, planning, and persuasion
I think this is a stronger claim than you need to make and might not actually be that well-justified. It might be worse than humans at loading the dishwasher bc that's not important to it, but if it was important, then it could do a brief R&D program in which it quickly becomes superhuman at dish-washer-loading. Idk, maybe the distinction I'm making is pointless, but I guess I'm also saying that there's a lot of tasks it might not need to be good at if its good at things like engineering and strategy.
Would this be an improvement? "Such any AI will be superhuman, or able to become superhuman, at almost all tasks, including computer security, R&D, planning, and persuasion"
Overall, I tend to agree with you. Most of my hope for a good outcome lies in something like the "bots get stuck in a local maximum and produce useful superhuman alignment work before one of them bootstraps itself and starts 'disempowering' humanity". I guess that relates to the thing I said a couple paragraphs ago about coherent, goal-oriented actions potentially not arising even as other capabilities improve.
I would speculate that most of our implemented alignment strategies would be meta-stable, they only stay aligned for a random amount of time. This would mean we mostly rely on strategies that hope to get x before we get y. Obviously this is a gamble.
I am less and less optimistic about this as research specifically designed to make bots more "agentic" continues. In my eyes, this is among some of the worst research there is.
I speculate that a lot of the x-risk probability comes from agentic models. I am particularly concerned with better versions of models like AutoGPT that don't have to be very intelligent (so long as they are able to continuously ask GPT5+ how to act intelligent) to pose a serious risk.
Meta question: how do I dig my way out of a karma grave when I can only comment once per hour and post once per 5 days?
Meta comment: I will reply to the other comments when the karma system allows me to.
Edit: formatting
You are correct, I was not being serious. I was a little worried someone might think I was, but considered it a low probably.
Edit: this little stunt has cost me a 1 hour time limit on replies. I will reply to the other replies soon
I would like to thank you, whpearson, for writing this post as I found it very validating to read.
I realise this may be considered a Necro post as the thread is 5 years old, however I wanted to show my appreciation to you for writing it. I have often thought of many choices I make in my life in terms of activation energy and freed energy, when deciding to make them. I have also used it to estimate the likelihood of society engaging in behaviours, and the viability of potential business projects. Having read your post and seen how you applied the concepts (activation and freed energy) to something outside of chemistry, namely economics, made me feel validated in my own behaviours of doing a very similar thing. I realize others may have also written about this concept, but yours is the first I have read. If you would like to talk more about this concept and related ones, I would be happy to have a conversation.
Thank you for writing this post.