LessWrong 2.0 Reader
View: New · Old · Topnext page (older posts) →
next page (older posts) →
But I disagree that there’s no possible RL system in between those extremes where you can have it both ways.
I don't disagree. For clarity, I would make these claims, and I do not think they are in tension:
I created my first fold. I'm not sure if this is something to be happy with as everybody can do it now.

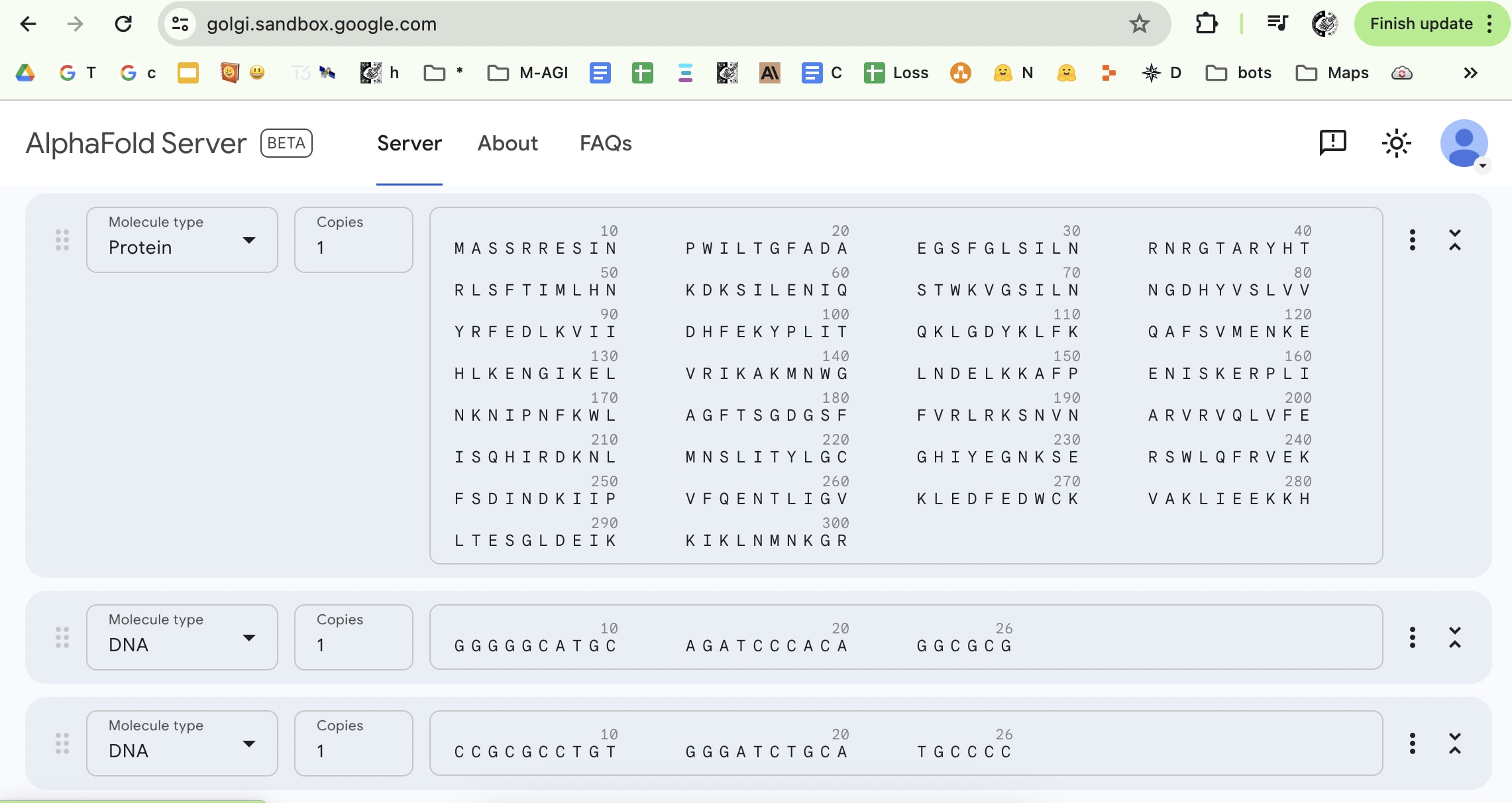
Access to Alpha fold 3: https://golgi.sandbox.google.com/
Is allowing the world access to Alpha Fold 3 a great idea? I don't know how this works but I can imagine a highly motivated bad actor can start from scratch by simply googling/LLM querying/Multi-modal querying each symbol in this image.
ryan_greenblatt on jacquesthibs's ShortformI do think that many of the safety advantages of LLMs come from their understanding of human intentions (and therefore implied values).
Did you mean something different than "AIs understand our intentions" (e.g. maybe you meant that humans can understand the AI's intentions?).
I think future more powerful AIs will surely be strictly better at understanding what humans intend.
jiao-bu on Dating Roundup #3: Third Time’s the CharmI am perfectly happy that the patriarchal roles are no longer shackling women. I would not like to roll back time, personally, on these matters. I hope my question doesn't come across this way -- it is just that I am confused about expectations.
qwertyasdef on D&D.Sci Long War: Defender of Data-mocracyI misremembered the May 6 date as May 9 but luckily other people have been asking for more time so it seems I might not be late.
The average number of soldiers the Army sends looks linear in the number of aliens. A linear regression gives the coefficients: 0.40 soldiers by default + 0.66 per Abomination + 0.32 per Crawler + 0.16 per Scarab + 0.81 per Tyrant + 0.49 per Venompede. From here, the log-odds of victory looks like a linear function of the difference between the actual number of soldiers and the expected number of soldiers.
Based on no evidence at all, I will assume this generalizes to the individual weapon types and that each additional soldier of each weapon type increases the odds of victory by some fixed amount depending on the composition of the aliens, but not dependent on the other soldiers already present.
Here's a guess that can definitely be improved upon but I don't know if I will
7 Thermo-Torpedos
While the use of tarot archetypes is... questionable... it does point at an angle to exploring embedding space which is that it is a fundamentally semiotic space, its going in many respects to be structured by the texts that fed it, and human text is richly symbolic.
That said, theres a preexisting set of ideas around this that might be more productive, and that is structuralism, particularly the works of Levi Strauss, Roland Barthes, Lacan, and more distantly Foucault and Derrida.
Levi Strauss's anthropology in particular is interesting ,because it looked at the mythologies of humans and tried to find structuring principles underlying it, particularly the "dialectics" , oppositions, and how these provided a sort of deep structure to mythology that was common across humanity (For instance Strauss noted "trickster" archetypes across cultures and proposed these formed a way of interrogating blurred oppositions, for instance sickness as a state that has has aspects of both life (dead things cant be sick) and death (a sick person is not rhetorically "full of life").
Essentially what I'm getting at is that this sort of analysis likely works with any symbolic system that has had resonances with human thinking over time. The problem with Tarot is that it specifically applies to a certain european circumstance of meaning production. Astrology probably works just as well. Literary analysis however probably works dramatically better. Thus maybe it might be worth looking at the works of literature critics, particularly the structuralists where where very interested in ontologies of symbolic meaning, and this might provide a better toolkit than this.
Two noncentral pages I like on the site:
No, introducing the concept of "indexical sample space" does not capture the thirder position, nor language. You do not need to introduce a new type of space, with new definitions and axioms. The notion of credence (as defined in the Sleeping Beauty problem) already uses standard mathematical probability space definitions and axioms.
gwern on Transformers Represent Belief State Geometry in their Residual StreamMy earlier comment on meta-learning and Bayesian RL/inference for background: https://www.lesswrong.com/posts/TiBsZ9beNqDHEvXt4/how-we-picture-bayesian-agents?commentId=yhmoEbztTunQMRzJx [LW(p) · GW(p)]
The main question I have been thinking about is what is a state for language and how that can be useful if so discovered in this way?
The way I would put it is that 'state' is misleading you here. It makes you think that it must be some sort of little Turing machine or clockwork, where it has a 'state', like the current state of the Turing machine tape or the rotations of each gear in a clockwork gadget, where the goal is to infer that. This is misleading, and it is a coincidence in these simple toy problems, which are so simple that there is nothing to know beyond the actual state.
As Ortega et al highlights in those graphs, what you are really trying to define is the sufficient statistics: the summary of the data (history) which is 100% adequate for decision making, and where additionally knowing the original raw data doesn't help you.
In the coin flip case, the sufficient statistics are simply the 2-tuple (heads,tails), and you define a very simple decision over all of the possible observed 2-tuples. Note that the sufficient statistic is less information than the original raw "the history", because you throw out the ordering. (A 2-tuple like '(3,1)' is simpler than all of the histories it summarizes, like '[1,1,1,0]', '[0,1,1,1]'. '[1,0,1,1]', etc.) From the point of view of decision making, these all yield the same posterior distribution over the coin flip probability parameter, which is all you need for decision making (optimal action: 'bet on the side with the higher probability'), and so that's the sufficient statistic. If I tell you the history as a list instead of a 2-tuple, you cannot make better decisions. It just doesn't matter if you got a tails first and then all heads, or all heads first then tails, etc.
It is not obvious that this is true: a priori, maybe that ordering was hugely important, and those correspond to different games. But the RNN there has learned that the differences are not important, and in fact, they are all the same.
And the 2-tuple here doesn't correspond to any particular environment 'state'. The environment doesn't need to store that anywhere. The environment is just a RNG operating according to the coin flip probability, independently every turn of the game, with no memory. There is nowhere which is counting heads & tails in a 2-tuple. That exists solely in the RNN's hidden state as it accumulates evidence over turns, and optimally updates priors to posteriors every observed coin flip, and possibly switches its bet.
So, in language tasks like LLMs, they are the same thing, but on a vastly grander scale, and still highly incomplete. They are (trying to) infer sufficient statistics of whatever language-games they have been trained on, and then predicting accordingly.
What are those sufficient statistics in LLMs? Hard to say. In that coinflip example, it is so simple that we can easily derive by hand the conjugate statistics and know it is just a binomial and so we only need to track heads/tails as the one and only sufficient statistic, and we can then look in the hidden state to find where that is encoded in a converged optimal agent. In LLMs... not so much. There's a lot going on.
Based on interpretability research and studies of how well they simulate people as well as just all of the anecdotal experience with the base models, we can point to a few latents like honesty, calibration, demographics, and so on. (See Janus's "Simulator Theory" for a more poetic take, less focused on agency than the straight Bayesian meta-imitation learning take I'm giving here.) Meanwhile, there are tons of things about the inputs that the model wants to throw away, irrelevant details like the exact mispellings of words in the prompt (while recording that there were mispellings, as grist for the inference mill about the environment generating the mispelled text).
So conceptually, the sufficient statistics when you or I punch in a prompt to GPT-3 might look like some extremely long list of variables like, "English speaker, Millennial, American, telling the truth, reliable, above-average intelligence, Common Crawl-like text not corrupted by WET processing, shortform, Markdown formatting, only 1 common typo or misspelling total, ..." and it will then tailor responses accordingly and maximize its utility by predicting the next token accurately (because the 'coin flip' there is simply betting on the logits with the highest likelihood etc). Like the coinflip 2-tuple, most of these do not correspond to any real-world 'state': if you or I put in a prompt, there is no atom or set of atoms which corresponds to many of these variables. But they have consequences: if we ask about Tienanmen Square, for example, we'll get a different answer than if we had asked in Mandarin, because the sufficient statistics there are inferred to be very different and yield a different array of latents which cause different outputs.
And that's what "state" is for language: it is the model's best attempt to infer a useful set of latent variables which collectively are sufficient statistics for whatever language-game or task or environment or agent-history or whatever the context/prompt encodes, which then supports optimal decision-making.