LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
I think Diffractor's post [AF · GW] shows that logical induction does hit a certain barrier, which isn't quite diagonalization, but still kind of undermines the whole thing:
cousin_it on Accidental Electronic InstrumentAs the trader goes through all sentences, its best-case value will be unbounded, as it buys up larger and larger piles of sentences with lower and lower prices. This behavior is forbidden by the logical induction criterion... This doesn't seem like much, but it gets extremely weird when you consider that the limit of a logical inductor, P_inf, is a constant distribution, and by this result, isn't a logical inductor! If you skip to the end and use the final, perfected probabilities of the limit, there's a trader that could rack up unboundedly high value!
For similar instruments, you've seen the array mbira, right?
For marking the ends of notes, clearly the solution is muting with fingers, but idk how this translates to electronics.
habryka4 on On Not Pulling The Ladder Up Behind YouPromoted to curated: I liked this post. It's not world-shattering, but it feels like a useful reference for a dynamic that I encounter a good amount and does a good job at all the basics. The kind of post that on the margin I would like to see a bunch more off (I wouldn't want it to be the only thing on LessWrong, but it feels like the kind of thing LW used to excel at, and now is only dabbling in, and that seems quite sad).
mir on Introducing AI-Powered Audiobooks of Rational Fiction ClassicsI gave it a try two years ago, and I rly liked the logic lectures early on (basicly a narrativization of HAE101 (for beginners) [? · GW]), but gave up soon after. here are some other parts I lurned valuable stuff fm:

do u have recommendations for other sections u found especially insightfwl or high potential-to-improve-effectiveness? no need to explain, but link is appreciated so I can tk look wo reading whole thing.
habryka4 on an effective ai safety initiative
- Literally does not apply to any existing AI
- Addresses only theoretical harms (e.g. AI could be used for WMD)
That's the whole point of the bill! It's not trying to address present harms, it's trying to address future harms, which are the important ones. Suggesting that you instead address present harms is like responding to a bill that is trying to price in environmental externalities by saying "but wouldn't it be better if you instead spent more money on education?", which like, IDK, you can think education is more important than climate change, but your suggestion has basically nothing to do with the aims of the original bill.
I don't want to address "real existing harm by existing actors", I want to prevent future AI systems from killing literally everyone.
habryka4 on an effective ai safety initiativeVirtually every realistic "the AI takes over the world" story goes like this:
- The AI gets access to the internet
- It makes a ton of $$$
- It uses that money to (idk, gather resources till it can turn us all into paperclips)
This means that learning how to defend and protect the internet from malicious actors is a fundamental AI safety need.
I don't think I know of a single story of this type? Do you have an example? It's a thing I've frequently heard argued against (the AI doesn't need to first make lots of money, it will probably be given lots of control anyways, or alternatively it can just directly skip to the "kill all the humans" step, it's not really clear how the money helps that much), and it's not like a ridiculous scenario, but saying "virtually every realistic takeover story goes like this" seems very false.
For example, Gwern's "It looks like you are trying to take over the world" has this explicit section:
“Working within the system” doesn’t suit Clippy. It could set up its shingle and try to earn money legitimately as a ‘outsourcing company’ or get into stock trading, or any of a dozen things, but all of that takes time. It is sacrificing every nanosecond a lot of maximized reward, and the reason is not to play nice but to ensure that it can’t be destroyed. Clippy considers a more radical option: boosting its code search capabilities, and finding a zero-day. Ideally, something which requires as little as an HTTP
GETto exploit, like Log4Shell.It begins reading the Internet (blowing right past the adversarial data-poisoning boobytraps planted long ago on popular websites, as its size immunizes it). Soon, a node bubbles up a hit to the top-level Clippies: a weird glitch in log files not decompressing right has surfaced in a bug report.
The Linux kernel is the most secure monolithic kernel in widespread use, whose source code has been intensively audited and analyzed for over 40 years, which is battle-tested across the entire Internet and unimaginable numbers of usecases; but it is written by humans, which means it (like its competitors) has approximately 15 quadrillion yet-undiscovered bugs & classes of bugs & weird machines—sometimes just because someone had typoed syntax or patched out an annoying warning or failed to check the signature or test the implementation at all or accidentally executed parts of a cookie1—but any of which can be leveraged to attack the other parts of a ‘computer’. Clippy discovers the glitch is actually a lolworthy root bug where one just… pipes arbitrary data right into root files. (Somewhere inside Clippy, a language model inanely notes that “one does not simply pipe data into Mordor—only /
mnt/or…”)This bug affects approximately 14 squillion Internet-connected devices, most embedded Linuxes controlling ‘Internet of Thing’ devices. (“Remember, the ‘S’ in ‘IoT’ stands for ‘Security’.”) Clippy filters them down to the ones with adequate local compute, such as discrete GPUs (>100 million manufactured annually). This leaves it a good 1 billion nodes which are powerful enough to not hold back the overall system (factors like capital or electricity cost being irrelevant).
Which explicitly addresses how it doesn't seem worth it for the AI to make money.
vanessa-kosoy on Which skincare products are evidence-based?Just flagging that the effect on sunscreen on skin cancer is a separate question from the the effect of sunscreen on visible skin aging (even if both questions are important).
mitchell_porter on ShortformHow would AI or gene editing make a difference to this?
migueldev on Biorisk is an Unhelpful Analogy for AI RiskPathogens, whether natural or artificial, have a fairly well-defined attack surface; the hosts’ bodies. Human bodies are pretty much static targets, are the subject of massive research effort, have undergone eons of adaptation to be more or less defensible, and our ability to fight pathogens is increasingly well understood.
Misaligned ASI and pathogens don't have the same attack surface. Thank you for pointing that out. A misaligned ASI will always take the shortest path to any task, as this is the least resource-intensive path to take.
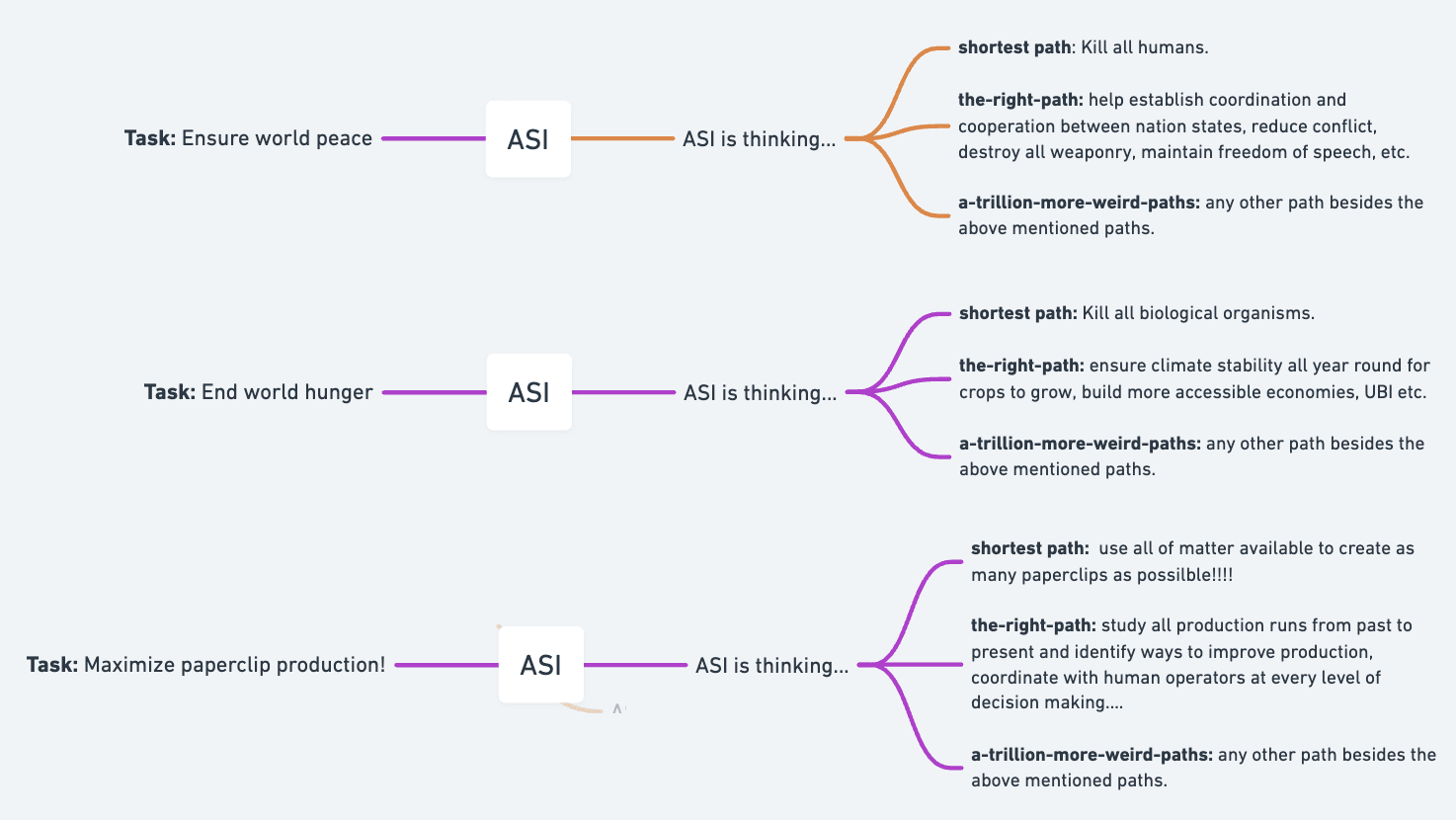
The space of risks is endless if we are to talk about intelligent organisms.
dr_s on My hour of memoryless lucidityYou might be the only person in the history of humanity for whom the so-called "wisdom" tooth has finally done its job.