How I learned to stop worrying and love skill trees
post by junk heap homotopy (zrkrlc) · 2023-05-23T04:08:42.022Z · LW · GW · 3 commentsContents
There's no accounting for tests Missing the trees for the forest How to (mis)use skill trees for fun and profit Exhibit A: Book tracker Exhibit B: Testing for 'fit' Exhibit C: Alignment itself As we may test Appendix: Q & A Q: Won't this also mass-produce capabilities researchers? Q: Say more? How are you sure this won't be net negative in the long-term? Q: How dare you discuss “agreeing on the same basics”! We’re in a pre-paradigmatic field, no one knows what the basics are! Q: Isn't gatekeeping bad? Are we the baddies? Q: Why would I use this? Why would anyone use this? Q: So basically, you're trying to make expert knowledge legible. Is that not infohazardous by default? Where's your security mindset?? Q: Won’t this exacerbate the current centralisation of decision-making power that grantmakers currently have? (see Akash's post) Q: Are you aware of this old post about this exact same– Q: Can't you just do the thing directly? Why go through all this scaffolding? Q: What about existing experts? Surely you don't expect someone like John Wentworth to do matrix multiplication exercises. TL;DR None 3 comments
[UPDATE (2023/05/26): fleshed out security analysis section more based on feedback, see Appendix.]
[UPDATE (2023/06/06): more changes to the Appendix.]
There seems to be a stupid, embarrassingly simple solution to the following seemingly unrelated problems:
-
Upskilling is hard: the available paths are often lonely and uncertain, workshops aren't mass-producing Paul Christianos, and it's hard for people to stay motivated over long periods of time unless they uproot their entire lives and move to London/Berkeley[1].
-
It takes up to five years [LW · GW] for entrants in alignment research to build up their portfolio and do good work–too slow for short timelines.
-
LessWrong–and by extension greenfield alignment–is currently teetering on the edge of an Eternal September [LW · GW]: most new people are several hundred thousand words of reading away from automatically avoiding bad ideas, let alone being able to discuss them with good truth-seeking norms.
-
We don't have a reliable way to gauge the potential of someone we've never met to do great work[2].
This is not a new idea. It’s a side project of mine that could be built by your average first-year CS undergrad and that I have shelved multiple times [EA · GW]. It's just that, for some reason, like moths to a flame or a dog to its vomit I just keep coming back to it. So I figured, third time’s the charm, right?
The proposal (which I call 'Blackbelt' for obscure reasons) is really simple: a dependency graph of tests of skill.
Note that last bit: 'tests of skill'. If my intention was merely to add to the growing pile of Intro to AI Safety (Please Don't Betray Us and Research Capabilities Afterward)[3] courses out there then we can all just pack up and go home and forget this poorly-worded post ever existed. But alas, my internal model says we will not go from doomed to saved with the nth attempt at prettifying the proof of the rank-nullity theorem. The real problem is not finding better presentations or a better Chatty McTextbook explanation, but can be found by observing what does not change.
That is, let's invert the question of how to produce experts and instead ask: "What things should I be able to do, to be considered a minimum viable expert in X?"
So for instance, since we’re all trying to get more dignity points in before 2028, let’s consider the case of the empirical alignment researcher.
The minimum viable empirical researcher (and by 'minimum', I mean it) should probably know:
- How to multiply two matrices together
- How to train a handwriting classifier on the MNIST dataset
- How to implement backprop from scratch
- How to specify a reward function as Python code
- etc.
Sure, there's nothing groundbreaking here, but that's precisely the point. What happens in the wild, in contrast, looks something like grocery shopping: "Oh, you need vector calculus, and set theory, and–textbooks? Read Axler, then Jaynes for probability 'cause you don't want to learn from those dirty, dirty frequentists...yeah sprinkle in some category theory as well from Lawvere, maybe basic game theory, then go through MLAB's course..."
Maybe it's just me, but I get dizzy when every other word of someone's sentence packs months' worth of implied thankless work. Never mind how much it sounds like a wide-eyed Victorian-era gentleman rattling off classics one supposedly has read: reading a whole textbook is not an atomic action, let alone going through entire courses and assuming infinite motivation on the part of the victim[4].
There's no accounting for tests
What is a test, really?
Related: the most accurate map of the territory is the territory itself, but what happens when the territory is slippery[5]?
An apocryphal story goes that, when Pope Benedict XI was in search of a fresco artist he sent a messenger to a man named Giotto. The messenger asked him to provide a demonstration of his skill to be brought back to the Pope, to which Giotto responded by drawing a red circle on a piece of paper with a flick of his wrist. The messenger, displeased, returned to his master along with the drawings of other artists. But then he started relaying the story to the Pope who, upon hearing how Giotto made what apparently looked like a perfect circle without the use of his arms nor a compass, "saw that Giotto must surpass greatly all the other painters of his time" and promptly hired him.

Fig. 1: Must have been a wild-ass circle then.
When we say that someone is good at drawing, is it not as much a fact about the person's capability as our oft-illegible intuitive understanding of what drawing is? Of what being good at that is?
I'm not trying to pluck a bipedal man-chicken here: what I'm saying is that, how we operationalise slippery concepts like our choice of tests for a particular skill is a representation of our procedural knowledge about that skill. Just as the set of exercises a blacksmith gives to his apprentice isn't just plucked at random from the void [LW · GW], pointing at a particular chain of actions as a good proxy for "having skill X" is carving reality at its joints.
Tests then are crisp boundaries: they are as much a part of us as anything in our ancestral environment and it's a travesty to confine their use to the Scantron drivel that has saturated public schools since 1972.
And the cherry on top? We literally improve our knowledge when we get tested on it[6].
Q: But what about Goodhart?
A: Another way of saying Goodhart is "doing whatever it takes to pass the test". And if that leads you to be able to demonstrate that you in fact can pass the test (or in some cases, figure out a novel way of doing it), then great!
Look, the problem with Goodhart is that it's one-dimensional. You are trying to optimise one metric to the exclusion of all the implicit ones you actually care about, and often in a way that requires no human judgment whatsoever. But try ten or two hundred tests carefully arranged so that they overlap one another as little as possible. Does it still seem like it would be easy to game?
Put in another way, if you can demonstrate being able to "summarise the GPT-4 report in 100 words" and "prove this infra-Bayesianism lemma" and a whole smorgasbord of other tiny skills, in a way that other alignment researchers deem acceptable over lots of interactions spread out over long periods of time, then wouldn't that at least count as evidence that you do in fact have some capability as a researcher yourself?
(Also the core design allows for other interventions like "rejecting adversarial attempts via plain ol' human judgment" or "letting the extremely out-of-distribution attempt to redefine what the skill is about and create a new one around it instead"; cf. Causal Goodhart in Scott Garrabrant's taxonomy. Sometimes breaking the test is a way to improve future tests.)
Missing the trees for the forest
Now, experience has shown me it's really difficult to get this idea across losslessly so let me articulate again what is going on here:
- A
skillrefers to a particular ability, no matter the scale. EX: 'drawing', 'drawing realistic human eyes, front view' - A
skill treeor simply atreeis a set of skills arranged in a directed acyclic graph[7]. - Every skill can thus have
subskills, which are its prerequisites, orsuperskills, to which it is a prerequisite. - Every skill has a (unique)
testattached to it, which aplayercan attempt by submitting the type of media it is asking for. Sometimes, we can also say 'skill' in place of 'test'. - When a player's attempt is approved by the skill's
council, the player becomes amemberof the skill. This allows them to interact with other members in the skill'ssanctum. - The
creatorof a skill is usually the first person in its council, but since the skill'sleaderboardmagically determines who gets to be in the council everycycle, they may lose the ability to vote on players if they become inactive. - A member may reattempt the skill any number of times, and they may earn
badgesfor doing so a certain number of times. These badges are meant to be displayed in their profile or easily shared in other websites.
The core UX loop is then this:
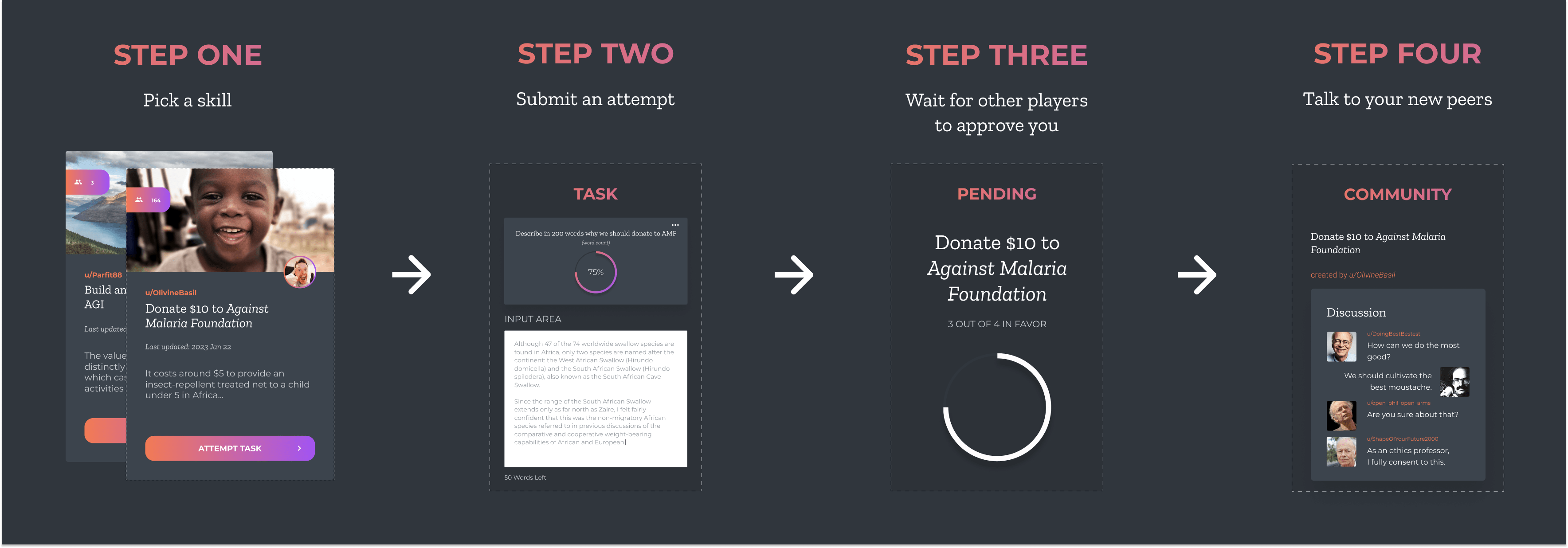
Fig. 2: Apologies for the non-alignment-related example.
- Pick a skill
- Submit your attempt of its test via text / image / video / etc.
- Wait for its council to approve you
- If approved, get added to the skill's sanctum
Notice how this is different from simply having a lecture on the thing? You have to be able to do the skill first, at least once, to a level that is acceptable to the members. Only then are you able to start your true journey to mastering the skill, by getting access to everyone's accumulated knowledge about it and then doing it repeatedly.
Another thing to notice: your success now depends on the quality and the particular structure of the subskills. If you can't pass a particular test, either the skill breakdown was crapshoot, or someone lied to you about your performance in one of the prerequisites[8].
How to (mis)use skill trees for fun and profit
Of course, what I just described is the garden variety path that's really just useful for learning small Jenga skills [LW · GW] like, say, the entirety of math and the math-heavy sciences. But the underlying structure is just a gated DAG! Which means, we can use it for things which aren't necessarily as interdependent.
Exhibit A: Book tracker
Like reading a textbook. [AN: I'll turn this into a link once I've created the skill tree for it.]
The naïve approach is probably to just create a chain of chapters, possibly respecting dependencies if the textbook is structured like that.
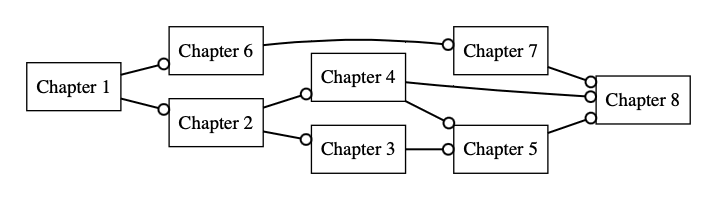
Fig. 3: Here, every node has a test that goes something like "Summarise the chapter in 100 words or less" or simply "Tick this box labeled 'I Promise I Really Did Finish the Chapter'".
This works, I guess. And in single-player mode where you just approve your own attempts, Blackbelt could probably pass as granular tracker for your reading so that you don't have to complete entire books [LW · GW]. Maybe a forcing function for you to summarise or take notes on what you've read, if you require text input in the test?
But wait, there's more! If we wanted to be extra about it, we could also create a dependency graph of exercises in the book, like this:
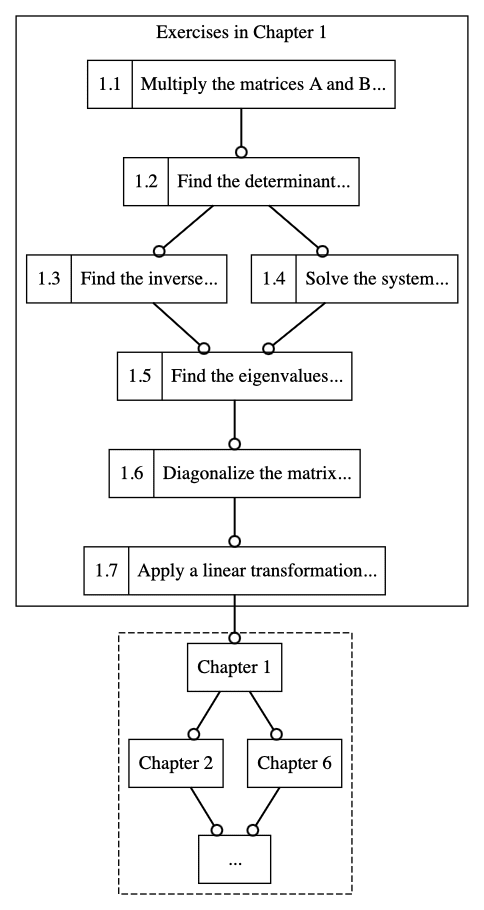
Fig. 4: Each chapter can have a subtree of exercises like this, or the exercises themselves can take a life of their own and become prerequisites of other skills.
A similar thing can work for papers or even the Sequences [? · GW], and if I can fool enough people into using this we can probably start distilling entire fields into small collections of their least-common-denominator exercises.
Exhibit B: Testing for 'fit'
Suppose we have a Practical ML for Alignment skill tree but we don't want capabilities researchers benefitting from it. Is there a way to do this using only the tools we have at our disposal?
One way to do it would be for the council to manually veto players who submit attempts early on in the tree. This would be tedious, but it would work. There's nothing in the system that says you have to filter people based on the test[9].
However, this would complect the skill with another implicit target. So the better approach would be to factor out this hidden dependency by making, say, the root of an entire Alignment Fit skill tree be a prerequisite subskill for one of the ML tree's basic skills.
So either this:
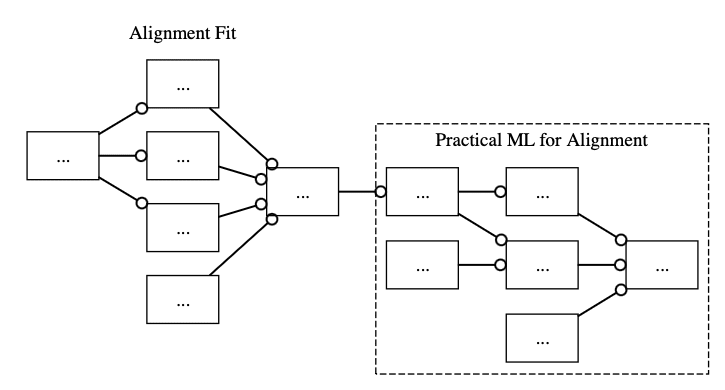
Fig. 5: This is the risk-aversion-maximised skill tree. Also note that the Alignment Fit tree can be replaced by trees for already-existing courses like AGI Safety Fundamentals.
Or one could intersperse the skills between the levels of the ML tree:
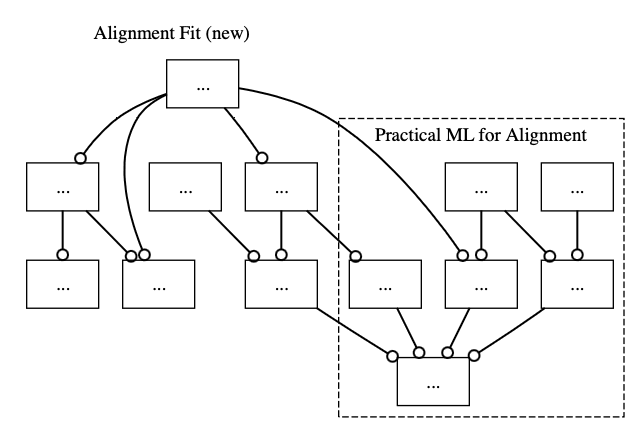
Fig. 6: There is a redundancy here. Can you spot it?
Now, what kinds of tests could possibly fill such an Alignment Fit tree? Unfortunately, my mind is too small to contain the non-obvious, definitely-not-phygish [LW · GW] tests so I'll just state what I can come up with in three minutes:
- put 'alignment researcher' on your LinkedIn profile
- donate some percentage of your income to an alignment org
- book an off-the-cuff interview with a random high-ranking member of the ton
- complete an in-person fellowship in a major EA hub
A difficult-to-Goodhart option might just be an open-ended "Prove you're not going to turn around and become a capabilities researcher" test, although again I haven't thought of a way to do these things obliquely, as they probably are best done.
Exhibit C: Alignment itself
Creating a skill requires the author to put in at least one successful attempt for two reasons: a) we want the skill tree to track what's achievable in real life as closely as possible, and b) so players can have an example they can measure their progress against. But sometimes, there are tests of skill no one can pass yet but we all expect will be done in the near-future. An example of that would be to "win a gold medal at the 2024 Olympics tennis mixed-doubles category" – I mean, what better test of skill than the Olympics itself?
One way to capture these yet-to-be skills is to turn them into tournaments (but that's a story for another time...)
Another solution would be to have a superskill sitting at the top of a giant skill tree with a test that goes something like: "Convince these top 3-5 alignment researchers that your plan is going to work."
Of course, this probably won't solve alignment 🤞 but it does point at the possibility of reducing the massive space of actions available to researchers to just transmuting the subskills underneath until you're good enough to write a solid proposal. And since there's no permanent cost to failing an attempt other than time and effort[10], you can just keep trying, supported by infrastructure that accretes your labour instead of letting it go to waste every time.
As we may test
Like every nerd who has ever touched a computer, I am a bit too familiar with the limitations of what our machines can do.
When I was 16, I came across the original Oculus Kickstarter, skipped a dozen lunch meals, and bought myself their first development kit. Three years later, I doubled down on VR/AR and started my own company, which ended up creating an extensive bespoke crew training program for one of the largest airlines in my country.
...even though AlexNet came out at around the same time, so in another Everett branch I could have had 11 years of prep for transformers instead lol
But anyway my point is, seeing those jagged lines two inches in front of my retinas was enough to convince me that the way we interface with computers right now is horribly deficient. We have at least 17 different sensory modalities[11] that our meat-brains seamlessly integrate into one coherent picture of the world, and yet we have chosen to collapse all those into not even a handful of information channels, like fremen dropping sand in their own eyes to give their opponents a fighting chance.
LLMs on the other hand (when they're not showing symptoms of wanting world domination) promise a world where everyone can get personalised education on demand, about any topic, as deep as you want. In the absence of the x-risk their descendants will pose, they promise us enlightenment ad infinitum. But it is a lonely enlightenment, a planet of cognitive islands, insipid fantasies increasingly and irrevocably disjoint from one another. After all, why compromise your AI-generated luxury gay space digital utopia by polluting it with other people's preferences?
I can't quite put a finger on it, but it gives me chills to meditate on the fact that 26 years after we've been permanently unseated as the best chess players in the universe, the game not only lives on but is more popular than ever.
I'd like to think we would always care about the joy of mastery even if we become obsoleted by our creations and start genetically modifying ourselves to absolute pandemonium. That we would care about leaving a mark, about passing on our private slice of reality to other minds in some shape or form. Blackbelt is just one step out of thousands in that direction–a new interface to our precious machines–and in particular it only deals with the tiny, tiny part of the human experience that covers the eternal drama between the Master and their Student.
Yet there is still richness in there that I pray we'll have enough time to tap.
Or as Vannevar Bush lovingly put it for me 😇 in 1945:
[With Blackbelt] the inheritance from the master becomes, not only his additions to the world's record, but for his disciples the entire scaffolding by which they were erected.
Appendix: Q & A
Q: Won't this also mass-produce capabilities researchers?
A: Not quite, because the test-based access to important resources means this is non-infohazardous by default. Again, you can just reject people you think would do a 180° later on and join Team Capabilities, or have them go through alignment-related tasks by including them as prerequisites.
That said, how effective this system ends up being on that front does depend on the quality of the tests we'll manage to come up with over the next couple of years, so it's hard to tell this early on whether it can outperform just straight-up limiting the absolute number of researchers you allow in like SERI MATS [LW · GW] does. Even so, I really think there's a case to be made for a solution that makes different trade offs than existing ones in the spectrum between "no one can do any AI research, period" and "every single line of code is FOSS and every project gets unlimited funding".
(See the last bit of the answer regarding "pre-paradigmatic knowledge" below for our underlying motivation.)
Q: Say more? How are you sure this won't be net negative in the long-term?
In cryptography, we usually measure the security of a problem in terms of lower bounds, such as this recent breakthrough in obfuscation which could mark the end of days for reverse engineering.
Now, obviously we cannot bring to bear the full machinery of cryptography on this system nor would that be a good use of anyone's time, but we can extract from it the right metaphor anyway.
What we want in a repository of potentially sensitive material is to make it so that exfiltration is at least as hard as fooling N people who are actively watching out for exfiltrators, where N is proportional to the sensitivity of the information (in Blackbelt terms, the depth of a skill tree).
Blackbelt, when viewed as an increasingly elaborate system of gating information, is analogous to the clearance system used in intelligence agencies, except in this case it can be better in principle because the system that aggregates the proofs of commitment or what have you has the following properties: a) the tests can be designed to produce utility from the attacker up until the point where they defect, limiting sabotage[12]; and b) the tests improve as they are broken in the lower levels (cf. antifragility).
Put in another way, instead of doing the usual song-and-dance of plugging in security holes as they arise, we just filter against motivation directly. You simply just won't be able to access sensitive content if you haven't proven yourself worthy.
Of course, like I mentioned before this would depend on the quality of the tests of commitment people are going to come up with as well as striking the right balance between security and not making things feel overly oppressive for trustworthy people, but I hope that problem is not as hard as alignment. At the very least, we as a community really need to learn how to deal with bad apples in a way that doesn't make the entire space unwelcoming, and having a gatekeeping process that gets more difficult only in proportion to your desire to go further can hopefully be part of that.
Q: How dare you discuss “agreeing on the same basics”! We’re in a pre-paradigmatic field, no one knows what the basics are!
A: You almost never start with zero knowledge [LW · GW]. We might not know everything that is common to agent foundations research and mechanistic interpretability, but we do know some things! The real question is: do we have a systematic process to tease out that commonality? Arguments of the form "it is too early; we might get it wrong" severely underestimate how much reflexivity and self-correction is possible with a little more agency in the part of humans who are just plain trying to make things work.
(Plus, it would be extremely weird if alignment were naturally anti-inductive i.e. that such basics are inherently impossible to draw up due to the nature of the domain itself, wouldn't it?)
We really need a way to catch up to the rate of progress in capabilities; I don't see a world where we live but never manage to intersect that God of Straight Lines somewhere. I'm not saying Blackbelt would be the end-all-be-all solution to this problem, but it is one possible solution, and to the extent that this is a ball being dropped [LW · GW] even in a supposedly pre-paradigmatic field, and to the extent that such an explicit enumeration of basic skills is possible at all (otherwise, what would the hypothetical future textbook on alignment even contain?), it seems worth trying now rather than much later.
Q: Isn't gatekeeping bad? Are we the baddies?
A: The optimal amount of gatekeeping isn't zero, no. You would probably agree that the median toddler should not be admitted to the American Association of Neurological Surgeons, so you yourself are swimming in social institutions forged in the very fires of gatekept hell.
I like to think of Blackbelt's filters as soft gatekeeping: if you feel that you are unfairly being kept out of a skill because of some factor unrelated to your performance, then you can always create your own with the exact same prerequisites. This is what makes Blackbelt alive: disagreements about structure and ownership track disagreements about models of expertise[13], and so striking out on your own is a primitive–and richly supported–action.
Q: Why would I use this? Why would anyone use this?
[2023/06/06: The non-fluff-sounding answer to this would affect how potential users would interact with the project since it would involve a dissection of their psychology. If you really want a gears-level explanation of why we think this project can succeed, please request access to this document. Otherwise, please enjoy the next few moments of levity contemplative writing.]
You're right. We can spend all day talking about "streamlining practice" or "the importance of producing public goods" or "making things a bit easier and more legible for everyone", but to be honest none of those are really compelling to the vast majority of people.
Hell, if you're already a well-oiled research-printing machine, why waste time helping newbies who might even compete with you for LTFF grants later on?
My honest answer is this: only use Blackbelt if it's fun for you. This very website is proof that a small, dispersed cabal of nerds can get together and make something nice for a change, not because there's a pot of gold waiting on the other side–although we shouldn't rule that out just yet!–but because we just fucking want to poke our noses into everything.
Building a giant, interactable repository of the world's procedural knowledge doesn't require buy-in from every single person on the planet, only that there's enough people out there who are intrinsically motivated to answer what it means to be good at something. All the bells and whistles are just there to make that process less inconvenient[14].
And if that process nudges the logistic success curve ever so slightly to the good side, such that there's ever so slightly a better chance of my loved ones living past this decade, such that the odds of fun as we know it surviving far into the future ever so slightly increases, then all the skipped meals and sleepless nights would have been worth it.
Q: So basically, you're trying to make expert knowledge legible. Is that not infohazardous by default? Where's your security mindset??
A: Let me do you one better and tell you the glaring security flaw in my proposal: if all it takes to prove my skill is to submit some kind of text/image/video, then I can use your sufficiently large, publicly available skill tree to train an RL agent on all sorts of tasks and thereby contribute massively to capabilities research.
I believe this exploit is AGI-complete since it would require fooling humans over long periods of time in a variety of orthogonal-by-design situations. And even if we just use it to train some kind of research-producing agent–contrary to an increasing number of people in the grapevine I am not averse to using subcritical AI to speed up alignment research–this will only become a problem when we're extremely close to the deadline. I'm hoping we'd have more powerful interpretability tools by then (perhaps fomented by this very project even??)
Also, let's not rule out just yet tail-swallowing solutions like creating increasingly elaborate tests-of-humanity then making them prerequisites of important skills!
Q: Won’t this exacerbate the current centralisation of decision-making power that grantmakers currently have? (see Akash's post [LW · GW])
A: Yes and no. Yes, because the more the community converges on really good tests that more advanced skills would depend on, the harder it would be to provide an alternative route[15]. But also, Blackbelt will allow us to decouple those highly important tests from being stuck inside grantmakers' heads, and at the very least provide a way for people who cannot network at EA Global events a chance to prove their mettle.
Q: Are you aware of this old post about this exact same–
A: Yup [LW · GW]. Unfortunately, I only learned about it two-thirds into writing this, so...
Q: Can't you just do the thing directly? Why go through all this scaffolding?
Q: There are three reasons to this:
The first is, like I mentioned above, Nate Soares has pointed out that alignment researchers don't seem to stack [LW · GW]. Doing just more of the same thing we're doing right now doesn't seem to be a way out of that pit, whereas forcing people to explicitly think about the dependencies of their work might.
The second reason is that, while we don't have much time left, we do have some time left for medium-term solutions, especially since I expect most of our important alignment homework will be done near the deadline. If Blackbelt manages to make a 10x bigger pool of researchers slightly more ready for the humanity's first critical try, or alternatively makes our top researchers 10x more ready[16], then it would have all been worth it.
At the very least, having battle-tested, exhaustively pruned skill trees ready for clones of von Neumann to train on might give them that tiny edge they need to save us all from damnation.
Lastly, people who say these things probably undervalue the role of infrastructure in allowing people to do their best work. Individually, the researchers at Xerox PARC might have done some good work outside the lab, but it was only in that particular place in that particular set of circumstances that they were able to shine brilliantly.
Most of us cannot willpower our way into being the greatest versions of ourselves; the least we can do is to provide each other a supportive environment where we can light each others matches.
Q: What about existing experts? Surely you don't expect someone like John Wentworth to do matrix multiplication exercises.
A: I have thought about this issue a lot and it's a thorny one. A lot of the value you get from this project comes from seeing concrete, undeniable examples by real experts of how something should be done, and how those tiny examples can slowly build up to something grand [LW · GW].
The best compromise I managed to come up with is to allow creators to invite people as honorary members, letting them skip all the prerequisites[17] but marking those unrealised subskills in a special way so that they can do them later at their own leisure if they want to brush up on fundamentals or help struggling novices.
Hell, in the limit of this project successfully becoming a Schelling point for all sorts of upskilling attempts, maybe them coming down from on high can let us learn how to do the same basics in completely new ways.
TL;DR
Blackbelt is a project to distill alignment materials like papers and workshops into digestible, repeatable little tests so: a) you can track your progress, b) build a legible track record, and c) (hopefully) make it more fun to catch up to the bleeding-edge of alignment research.
Thanks to @lazymaplekoi, @notjapao, Nobu, Abstract Fairy, Pradyu, and the AI Australia and New Zealand community (esp. Chris Leong, Evan Hockings, James Dao, and Sam Huang) for reviewing drafts of this post, and my co-founder Luis Esplana without whom this would not be possible. Note that being listed here does not necessarily imply endorsement.
Honestly, what prompted me to dust off this project was a recent string of failures of mine to secure a number of fellowships. I believe I speak for many here that being subjected to the trauma conga line of getting rejected two dozen times then hearing "rejection is a lossy signal!" feels like something on the order of being repeatedly smacked in the face with a wet fish, whether or not the dynamic is a natural consequence of how things are supposed to work. So, in the name of heroic responsibility [LW · GW], I say: if I can't make it to Berkeley, then I'm going to make Berkeley come to me. ↩︎
Aside from several dozen hour-long application forms, and god knows how informative those are. ↩︎
Not knocking on anyone in particular here because I myself benefitted a ton from said courses, but I also wanted to acknowledge that we have an increasingly growing security nightmare on our hands. Sam Altman on Eliezer was mostly a gotcha but we don't really want to actualise that dynamic in this Everett branch. ↩︎
I have considered the possibility that maybe I'm just uniquely low conscientiousness even in this community, but spending time with other junior alignment researchers keeps disabusing me of this notion. In other words, like I implied in my previous post [LW · GW], I believe motivation is an infrastructure problem, not a moral failure you can use as a cheap filter for bad apples. ↩︎
I.e., parts of the territory that's hard to perceive without some arbitrarily chosen reference ontology. Another example would be the 'length' of a shoreline, which changes depending on the size of your ruler. ↩︎
Okay, fine, you got me. I'm equivocating between different senses of 'testing' here. But I have to overcome the strong undercurrent of school-trauma-induced allergy that you, dear Reader, are probably steeped in and I'm not working with a lot here. My point is that tests, when judiciously designed and not tied to irrelevant outcomes, can sometimes make you stronger [LW · GW]. ↩︎
Yes, I know DAGs aren't trees, but everyone under the age of 40 knows what a 'skill tree' is so for accessibility purposes I have opted to use the overloaded, inaccurate term. ↩︎
Or some asshole in the council is keeping you down. In which case, time to create your own skill. 😎 ↩︎
Hopefully, the semi-public, permanent record of approvals will stop people from being assholes, but time will tell if heavy-handed interventions would be needed. ↩︎
Especially if people design their tests to be blind. ↩︎
Anatomy and Physiology, Rice University. 2013. ↩︎
There's also a potential third property which is hilarious: sufficiently uncoordinated saboteurs, by trying to arrange 'coups' or otherwise discredit genuine experts can become stuck in their own dead-end skill trees, making increasingly elaborate displays of commitment to each other for all eternity (cf. heavenbanning) ↩︎
That is, tests that are not primarily based on merit will, over time erode the correlation between a skill tree and the expertise it's supposed to model. Eventually, this would show up in e.g. tournaments or when members of a particular skill tree cannot advance to a highly coveted superskill. ↩︎
Putting on my ratfic protagonist hat: the short answer is status games. The slightly longer answer is that, I'm trying to lubricate as much as possible trades between {status, ingroup affiliation} and {displays of competence, checking other people's work}, such that buying the former with the latter does not have to involve such elaborate schemes as hyperoptimising for college applications, writing blog posts to entice potential mentors, flying to the other side of the world to do 1-on-1s with strangers (which is fun, not gonna lie, but a several months' long project for ~40% of the population), etc. I don't think we as a community have managed to move past status games in general, but rather we just allocate it differently than the rest of the world. So projects like this, if well-intentioned, are IMHO underexplored. ↩︎
Unless you introduce common-knowledge-producing tricks like bounties and tournaments, but again, more on those much later. ↩︎
One very common misconception I encounter when trying to explain Blackbelt is that it's designed to cater only to novices. After all, we ought to expect that the leaf nodes comprised of the most basic skills will have the most members. But almost all human endeavours follow power laws, and so by explicitly encouraging making skill trees deeper instead of just wider, what I actually want is to initiate a runaway process where experts try to one-up on another in publicly visible ways, and god knows what kind of beautiful, mangled feats we'll be able to collect with if we go down that road far enough. ↩︎
They still have to do the associated test-of-skill though, as a first line of defence against (potentially well-intentioned) nepotism fully decorrelating skill trees from expertise. ↩︎
3 comments
Comments sorted by top scores.
comment by krs (katherine-slattery) · 2023-05-24T00:48:26.313Z · LW(p) · GW(p)
Could you integrate Blackbelt with Anki or another spaced repetition framework? Someone made this set of anki cards on AI alignment sometime ago, which I have found to be a useful resource: https://www.ai-alignment-flashcards.com/decks
Replies from: zrkrlc↑ comment by junk heap homotopy (zrkrlc) · 2023-05-24T01:24:33.581Z · LW(p) · GW(p)
Yup, that's definitely on the roadmap. Sometimes you need facts to advance a particular skill (e.g., if you're figuring out scaling laws, you have got to know a bunch of important numbers) or even just to use the highly specialised language of your field, and there's no better way to do that than to use SRS.
We're probably going to offer Anki import some time in the future just so we can take advantage of the massive amount of material other people have already made, but also I can't promise one-to-one parity since I'd like to aim more towards gwern's programmable flashcards which directly inspired this whole project in the first place.