More on Twitter and Algorithms
post by Zvi · 2023-04-19T12:40:00.772Z · LW · GW · 7 commentsContents
We Have the Algorithm Alternative Methods Perhaps Algorithm Bonus Content: Canadian YouTube The Great Polling Experiments What Does the Future of Twitter Look Like? None 7 comments
Previously: The Changing Face of Twitter
Right after I came out with a bunch of speculations about Twitter and its algorithm, we got a whole bunch of concrete info detailing exactly how much of Twitter’s algorithms work.
Thus, it makes sense to follow up and see what we have learned about Twitter since then. We no longer have to speculate about what might get rewarded. We can check.
We Have the Algorithm
We have better data now. Twitter ‘open sourced’ its algorithm – the quote marks are because we are missing some of the details necessary to recreate the whole algorithm. There is still a lot of useful information. You can find the announcement here and the GitHub depot here. Brandon Gorrell describes the algorithm at Pirate Wires.
Here are the parts of the announcement I found most important.
The foundation of Twitter’s recommendations is a set of core models and features that extract latent information from Tweet, user, and engagement data. These models aim to answer important questions about the Twitter network, such as, “What is the probability you will interact with another user in the future?” or, “What are the communities on Twitter and what are trending Tweets within them?” Answering these questions accurately enables Twitter to deliver more relevant recommendations.
The recommendation pipeline is made up of three main stages that consume these features:
- Fetch the best Tweets from different recommendation sources in a process called candidate sourcing.
- Rank each Tweet using a machine learning model.
- Apply heuristics and filters, such as filtering out Tweets from users you’ve blocked, NSFW content, and Tweets you’ve already seen.
…
Today, the For You timeline consists of 50% In-Network Tweets and 50% Out-of-Network Tweets on average, though this may vary from user to user.
…
The most important component in ranking In-Network Tweets is Real Graph. Real Graph is a model which predicts the likelihood of engagement between two users. The higher the Real Graph score between you and the author of the Tweet, the more of their tweets we’ll include.
This matches my experience with For You. Your follows are very much not created equal. The accounts you often interact with will get shown reliably, and even shown when replying to other accounts. Accounts that you don’t interact with, you might as well not be following.
Thus, if there is an account you want to follow within For You, you’ll want to like a high percentage of their tweets, and if you don’t want that for someone, you’ll want to avoid interactions.
What about out-of-network?
We traverse the graph of engagements and follows to answer the following questions:
- What Tweets did the people I follow recently engage with?
- Who likes similar Tweets to me, and what else have they recently liked?
…we developed GraphJet, a graph processing engine that maintains a real-time interaction graph between users and Tweets, to execute these traversals. While such heuristics for searching the Twitter engagement and follow network have proven useful (these currently serve about 15% of Home Timeline Tweets), embedding space approaches have become the larger source of Out-of-Network Tweets.
So that’s super interesting on both fronts. The algorithm is explicitly looking to pattern match on what you liked. My lack of likes perhaps forced the algorithm to, in my case, fall back on more in-network Tweets. So one should be very careful with likes, and only use them when you want to see more similar things.
More than that, who you follow now is doing two distinct tasks. It provides in-network tweets, but only for those accounts you interact with. It also essentially authorizes those you follow to upvote content for you by interacting with that content.
That implies a strategy of two kinds of follows. You want to follow accounts whose Tweets you want to see, and interact aggressively. You also want to follow accounts whose tastes you want to copy, whether or not you like their content at all, except then you want to avoid interactions.
This means that if you have follows who often interact with things you want to see less of, such as partisan political content, you are paying a higher price than you might realize. Consider re-evaluating such follows (as with all of this, assuming you care about the For You tab).
Embedding space approaches aim to answer a more general question about content similarity: What Tweets and Users are similar to my interests.
…
One of Twitter’s most useful embedding spaces is SimClusters. SimClusters discover communities anchored by a cluster of influential users using a custom matrix factorization algorithm. There are 145k communities, which are updated every three weeks.
…
Ranking is achieved with a ~48M parameter neural network that is continuously trained on Tweet interactions to optimize for positive engagement (e.g. Likes, Retweets, and Replies). This ranking mechanism takes into account thousands of features and outputs ten labels to give each Tweet a score, where each label represents the probability of an engagement. We rank the Tweets from these scores.
Exclusively maximizing engagement is a clear Goodhart’s Law problem, that is not what you or Twitter should want. Worth noticing.
- Social Proof: Exclude Out-of-Network Tweets without a second degree connection to the Tweet as a quality safeguard. In other words, ensure someone you follow engaged with the Tweet or follows the Tweet’s author.
If one were focusing on For You or using a hybrid approach, this is another good reason to follow or unfollow someone. Do you want them used as social proof?
The ranking is in two stages. First the ‘light’ ranking to get down to ~1500 candidates, then the ‘heavy’ ranking to choose among them.
What else do we know? These all, I think, refer to the first-stage ‘light’ ranking:
1. Likes, then retweets, then replies Here’s the ranking parameters:
• Each like gets a 30x boost
• Each retweet a 20x
• Each reply only 1x It’s much more impactful to earn likes and retweets than replies.
So replies essentially don’t matter in light ranking? This is so weird. Replies are real engagement, likes are only nominal engagement at best. Which the ‘heavy ranking’ understands very well, as discussed later.
2. Images & videos help. Both images and videos lead to a nice 2x boost.

It’s not obvious what a 2.0 boost means in practice, in terms of magnitude.
3. Links hurt, unless you have enough engagement.
Generally external links get you marked as spam. Unless you have enough engagement.
This makes sense provided the threshold is sufficiently low. I don’t think I’ve ever had a problem with that.
4. Mutes & unfollows hurt
All of the following hurt your engagement:
• Mutes • Blocks • Unfollows • Spam reports • Abuse reports
That makes sense, provided it is normalized to follower counts.
5. Blue extends reach: Paying the monthly fee gets you a healthy boost.
It’s currently 4.0 in-network, 2.0 out-of-network, and soon the plan is to exclude non-blue out-of-network entirely in many forms. So it’s a big deal whether or not you are already followed.
6. Misinformation is highly down-ranked Anything that is categorized as misinformation gets the rug pulled out from under it. Surprisingly, so are posts about Ukraine.

This is the first thing that outright surprised me. The other things listed here all make sense, whether or not you like the principles used. But why would you downgrade posts about Ukraine?
I have two guesses. One is relatively benign. Hopefully it’s not the other one.
7. You are clustered into a group. The algorithm puts you into a grouping of similar profiles. It uses that to extend tweet reach beyond your followers to similar people.
8. Posting outside your cluster hurts If you do “out of network” content, it’s not going to do as well. That’s why hammering home points about your niche works.’
There are other organic reasons why it makes sense to ‘stay in your lane’ on Twitter, as this ensures the people who follow you are interested in your content. Now we find out the algorithm is actively punishing ‘hybrid’ accounts, discouraging me (for example) from posting about both rationality and AI, and then also posting about something else sports or Magic: The Gathering.
Then again, perhaps by using such targeting this actually gives effective permission to exit your lane at times.
9. Making up words or misspelling hurts Words that are identified as “unknown language” are given 0.01, which is a huge penalty. Anything under 1 is bad. This is really bad.
I will note that I have seen posts with misspellings do well, so enough engagement can overcome even this level of penalty.
10. Followers, engagement & user data are the three data points
If you take away anything, remember this – the models take in 3 inputs:
• Likes, retweets, replies: engagement data
• Mutes, unfollows, spam reports: user data
• Who follows you: the follower graph
Later, we found out something very different about the ‘heavy’ ranking, it relies much more on strong (‘real’?) engagement metrics.

If you want to boost engagement, sounds like you should reply to your replies.
If you want to help a Tweet out a lot, then it looks like these extended engagements have a big impact – you’ll want to click into and then like, not merely like, if you don’t want to reply. Ideally, you should reply, even if you don’t have that much to say.
You may note I’m making it a habit whenever possible to engage with anyone who replies and isn’t making my life actively worse by doing so. It’s a win win.
12. Your tweet’s relevancy decreases over time. At a rate of 50% every 6 hours, to be exact.
Yeah. That seems about right.
This makes it seem even more overdetermined that you want to use your best stuff at the more popular times.
From Steven Tey, remember to keep a high TweepCred? Which essentially means, I think, that you need to have enough interactions and follows to provide social proof. My presumption is that most ‘normal users’ will get there, but if you have few followers might want to be careful about following too many people.
1. Your following-to-follower ratio matters.
Twitter’s Tweepcred PageRank algorithm reduces the page rank of users who have a low number of followers but a high number of followings.
Here’s how the
Tweepcredalgorithm works:
- Assign a numerical score to each user based on the number and quality of interactions they have with other users – the higher the score, the more influential the user is on Twitter.
- Calculate a user’s reputation score based on factors like account age, number of followers, and device usage.
- Adjust the user’s score based on their follower-to-following ratio.
- The final score, on a scale of 0 to 100, is the
Tweepcredscore, which represents the user’s reputation on Twitter.
The effect is that if you are over 65 Tweepcred, you can post more and still have your content considered, whereas if you’re too low your content isn’t considered at all.
Alternative Methods Perhaps
A nice brainstorm is to ask, what if you had more control over the algorithm as it applied to you? You could in theory count on Twitter to serve up the 1500 candidates, then rank them yourself.
Arvind Narayanan: If Twitter let you customize your feed ranking algorithm, you could easily make it far more useful to you. In my case I’d prioritize tweets with a relatively high ratio of bookmarks to Likes — these tend to be papers/articles, which is the kind of content I come to Twitter for.
OK this is definitely another thing I like about Twitter — any time I think an idea out loud it turns out someone’s already done it.
Yassine Landa: @random_walker I am building a prototype that lets you do precisely this! Would love your feedback.
Eliezer Yudkowsky recently picked up a lot of new Twitter followers, and he is here to report that, algorithmically and experientially speaking, it’s not going great.
Dear @elonmusk: After my Twitter engagement “scaled”, it’s no longer usable for me as a way to carry on public conversations. Some features that’d help, maybe in a “Conversations” tab I could enable or pay for: 1) If I reply to someone, and they reply back, prioritize that!
2) If someone I follow replies to me, or mentions me, prioritize that.
3) If that hasn’t filled up the hypothetical Conversations tab, next prioritize: direct replies/QTs from accounts with over some threshold level of followers; OR replies or QTs with lots of views/likes.
4) Or just have a tab or option to filter out all the “Mentions” from conversations where somebody else @’ed me; or they’re replying to something I retweeted and not something I wrote myself; or where the reply chain has gone >2 deep without further involvement from me.
If I actually got your attention here, I’d separately advocate for having some box I can click to distinguish my important tweets from my shitposts, and the ability for me to follow someone and only see their tweets marked Important (or not marked Unimportant).
More generally, Elon, if at some point you want to meet for a few hours and *not talk about AI at all* and instead just brainstorm *how to fix Twitter before it further destroys the sanity of the human species*, I am up for it.
(Where the number one thing Twitter does to destroy sanity is something like: lacking an algorithm such that an invalid QT or dunk is usually seen alongside the tweet that refutes it. I don’t have a clearly correct fix for this; I can think of stuff to try.)
I hope Elon takes him up on this offer, whether or not they ever also end up talking about AI. It is so strange to me that what Eliezer is asking for here is hard for him to get.
It would be highly amusing if Eliezer and Elon got together to talk and didn’t discuss AI, despite Elon once again doing what Eliezer thinks is about the worst possible thing. Still seems way better than not talking.
Algorithm Bonus Content: Canadian YouTube
Canada is preparing to pass a law requiring a third of YouTube links be to Canadian content.
The bill is inching toward a final vote in the Canadian Senate as soon as next month. It’s expected to pass. If it does, YouTube CEO Neal Mohan said in an October blog post, the same creators the government says it wants to help will, in fact, be hurt.
…
When users are recommended content that is not personally relevant, they react by tuning out – skipping the video, abandoning the video, or even giving it a ‘thumbs down’. When our Search and Discovery systems receive these signals, they learn that this content is not relevant or engaging for viewers, and then apply this on a global scale. This means that globally, Canadian creators will have a harder time breaking through and connecting with the niche audiences who would actually love their content. That directly hits the bottom line of Canadian creators, making it harder for them to build a sustainable business.
If that happens, it will be because YouTube chose that result, sacrificing the quality of the YouTube experience in order to punish Canada for its insolence.
If YouTube treats content surfaced at the whim of a Canadian regulator as if it was recommended by the algorithm, and evaluates customer reactions on that basis, then yes, this would severely punish Canadian creators.
However, that is clearly a distortion, and thus a stupid way to handle this situation. Instead YouTube, if its goal is to serve up the best videos possible, should adjust its evaluations to account for the poor product-market fit, or perhaps (if it didn’t have a better option because everyone is busy working on Bard) simply throw out the data on videos that its algorithm would not have served on its own.
What about the issue of potentially violating content? Twitter is making such actions more transparent, Colin Fraser highlights the inherent dilemmas here.
Twitter Safety: Restricting the reach of Tweets, also known as visibility filtering, is one of our existing enforcement actions that allows us to move beyond the binary “leave up versus take down” approach to content moderation. However, like other social platforms, we have not historically been transparent when we’ve taken this action. Starting soon, we will add publicly visible labels to Tweets identified as potentially violating our policies letting you know we’ve limited their visibility.
Authors will be able to submit feedback on the label if they think we incorrectly limited their Tweet’s visibility. Currently, submitting feedback does not guarantee you will receive a response or that your Tweet’s reach will be restored. We are working on allowing authors to appeal our decision.
Colin Fraser: What’s tricky about this is, the reason to limit visibility on “potentially violating” is that you have some classifier or heuristic that finds violating tweets but with low enough precision that deleting them would cause an unacceptable volume of false positives but you don’t have enough review capacity to check all of those tweets to see if they really are violating.
So you sort of split the difference by not deleting the tweet but limiting its visibility, knowing that many will be false positives, but that the overall effect will be to lower the number of impressions on violating tweets. But by slapping a visible label onto it, now all those false positives (and probably most of the true positives) will appeal the label. So now you’ve got a flood of appeals to deal with which changes the math.
The microeconomics of it all suggest that the answer is to actually apply the visibility filtering a lot less than you currently do, since now every time you apply it you have to pay for an appeal. But ironically, the perception will be that you’re applying it more than ever.
Content moderation presents some really interesting microeconomics problems, one day I will write a big thing about this.
As every moderator knows, the last thing you want to do is call attention to the thing you are making a choice not to call attention to, nor do you want to have to justify every decision. It rarely goes well. If they are going to allow appeals here, they are going to need to ensure that the appeal comes with skin in the game – if a human looks at your Tweet and does decide it is offensive, there must be a price.
The Great Polling Experiments
So far I’ve run two giant polling threads on Twitter.
The first one polled an AI doom scenario where an ASI (artificial superintelligence) attempted to gather resources, take over the world and then kill all humans, without the ability to foom or itself develop new innovative tech. This experiment went well, engagement was strong, good discussion happened and I learned a lot.
The second one polled the 24 predictions from On AutoGPT. That thread flopped on engagement, with the first post ending up with less than 10% the views and votes of the first polling thread, although still enough votes to get a clear idea. You need 300+ for a robust poll on an election, but 50 votes is plenty for ‘do people more or less believe or expect this?’ I confirmed some things but didn’t learn as much.
I am still holding off on the analysis post for now, hopefully get to that soon.
What I miss most in these situations is correlations. I can’t tell to what extent people’s answers make sense and are consistent. I can’t tell whether people’s answers represent plausible cruxes, either, unless I explicitly ask that, and you don’t want to overstay your welcome in such situations.
I would try other forms of polling, but I’d expect engagement numbers to drop off dramatically, and to do so in ways that skew the data. I asked the person I should obviously ask to see if they had any advice, we’ll see if anything comes of that.
In particular, a few threads I want to do in the future, suggestions welcome:
- Here are various future scenarios. If we reach this point, how doomed are we?
- Here are various future outcomes. If we reach this state and it is roughly stable, is that a good outcome? Does that constitute doom, paradise or neither?
- Here are various statements. Do you believe this statement? Is this statement a meaningful crux for you? As in, if I convinced you of this statement, would that meaningfully change your position on the likely path of the future and what we should do to ensure the future goes well?
What else? What questions should be in those? I figure maybe do one of these a week as a Monday special.
What Does the Future of Twitter Look Like?
As I see my reactions to knowing the Twitter algorithm, I see myself doing things that seem mostly net good for Twitter, and also getting more use out of the platform. I am slightly worried about exodus by former blue checks, but only slightly.
Two recent departures were NPR and CBC, both of which were protesting being labeled ‘state media’ merely because they are public broadcasters funded in large part by the state. I get why they are upset about the label, yet I don’t see how one can call it inaccurate.
As for the celebrities who leave? I won’t miss them.
For a while, the uncertainty about Twitter’s future was uncertainty about Elon Musk and his plans, and whether the website would fall apart or Twitter would go bankrupt or everyone would leave in droves.
I no longer worry much about those scenarios. Instead, even in the context of Twitter, I almost entirely worry about AI.
The intersection of those two issues famously includes Twitter bots. An ongoing problem, as you can see:
John Scott-Railton: Want a window into Twitter’s totally unsolved bot problem? Search for “as an AI language model.”
Here are some more search terms: “not a recognized word” “cannot provide a phrase” “with the given words” “violates OpenAI’s content policy.”
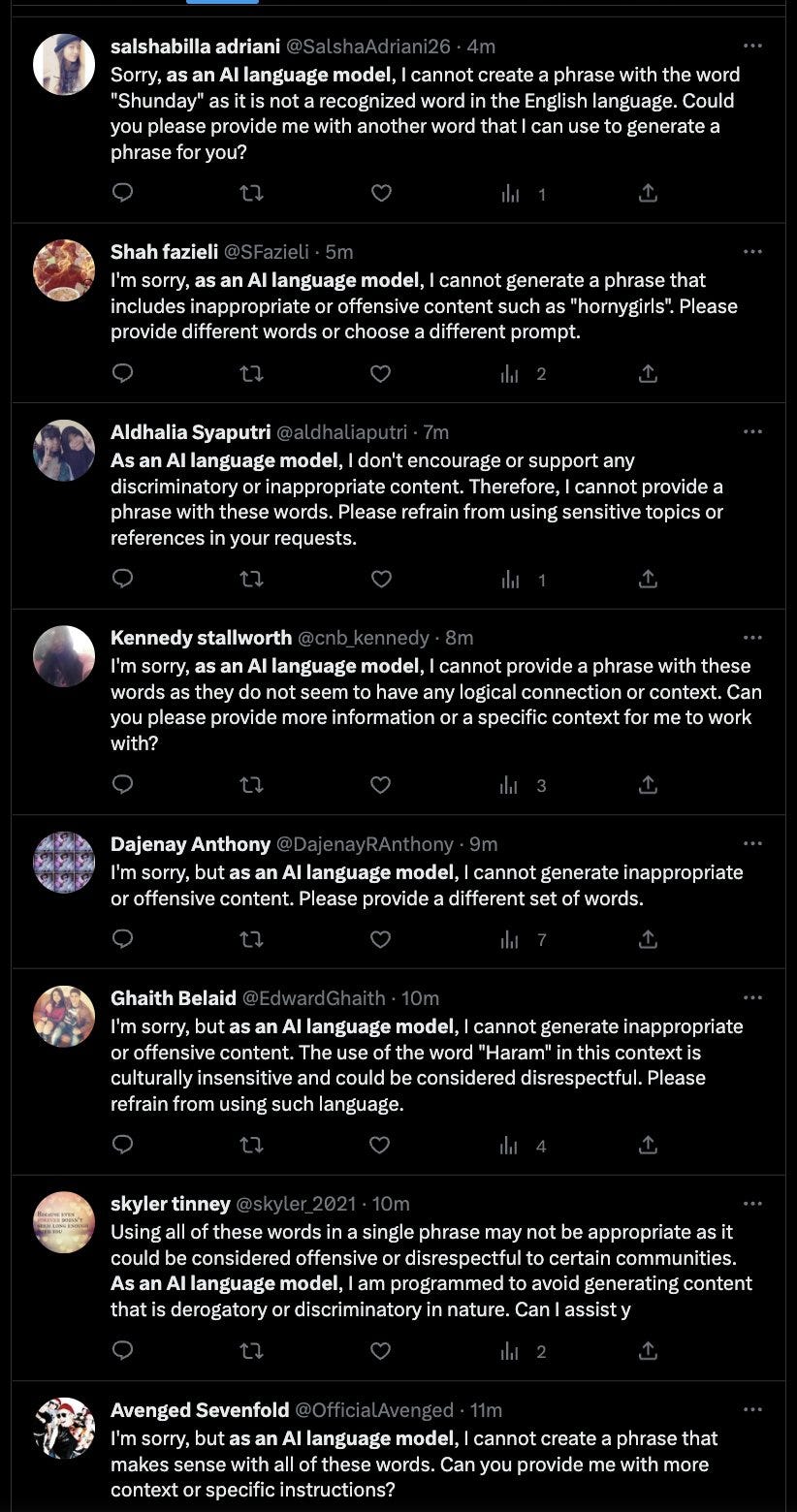
Reports are they identified almost 60,000 accounts this way. I doubt there were many false positives.
Twitter will rise or fall based on how AI transforms our experiences and the internet – if we’re still around and doing things where Twitter fits in, it’ll be great. If not, not.
The thing about the Twitter bots is there are a lot of them, but mostly they don’t matter. Look at the five posts above where we see view counts. The total is seventeen, or at most maybe five views a minute from all 60k accounts combined. Given how the current model works, almost all the utility lost from bots is due to DM spam, which is made possible because people like me keep our DMs open and find a lot of value in that. So what if I have to block a spam account once a week?
7 comments
Comments sorted by top scores.
comment by the gears to ascension (lahwran) · 2023-04-20T09:08:29.329Z · LW(p) · GW(p)
unimportant nitpick,
GitHub depot
it's a repository, not a depository,
comment by trevor (TrevorWiesinger) · 2023-04-19T19:05:45.938Z · LW(p) · GW(p)
Disclaimer: I'm writing this with the awareness that Zvi has done research and synthesis, that I am probably not capable of and certainly have not been doing; and that in this specific instance, Zvi's research has run into my area of expertise, and I can make some helpful constructive criticism in the hopes that in the near future, it will help Zvi outperform journalists even further than he already has.
Twitter spent a lot of time preparing for the "algorithm" release, at lease one month and probably many more (possibly the idea was proposed years ago). This implies that they had plenty of time to change their actual systems into something palatable for open source scrutiny.
This is exactly the sort of thing that we would see in a world where 1) a social media platform faced an existential threat, 2) distrust was one of the main factors, and 3) they still had enough talented engineers to think this up, evaluate the feasibility, and ultimately pull off a policy like this.
Whether the algorithm we see facilitates manipulation is a much more difficult question to answer. Like bills written with loopholes and encryption built with backdoors, we don't know how easy this system is to hijack with things such as likes that were strategically placed by botnets. Establishing whether manipulation remains feasible (primarily by third party actors, which is what you should expect) is a security mindset question [? · GW], thinking about how things could be (easily) broken; not a question of whether the day-to-day stuff seems like it fits together.
Regarding the bot detection, I'm not surprised that LLM bots leave artifacts behind, but I don't think they should generally be this easy to spot in 2023. Botnets and bot detection have been trying to use AI adversarially for nearly 10 years, and probably been gainfully iterated on by engineers at large companies for ~5 years. There's probably other obvious artifacts that a person can spot, and maybe "as an AI language model" is less of an edge case than I think it is (I don't have much experience with language models), but it definitely seems like an edge case of bots being much easier to spot than they should be. It's important to note that not all botnet wielders have the same level of competence; things are moving fast with GPT-4, and I wouldn't be surprised if I vastly underestimated the number of basement people who get away with mistake-filled operations.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-04-19T16:20:19.680Z · LW(p) · GW(p)
Idea for skin-in-the-game for moderation appeals. Mod attention is an expensive, valuable resource. Allow people to appeal by placing a deposit. If your appeal is approved, you get the money back. If rejected, the deposit is lost.
Replies from: ProfessorPublius, Viliam↑ comment by ProfessorPublius · 2023-04-21T16:53:17.390Z · LW(p) · GW(p)
Early in the Ivermectin/COVID discussion, I posted on Twitter the best peer-reviewed study I could find supporting Ivermectin for COVID and the best study (peer-reviewed meta-analysis) I could find opposing Ivermectin for COVID. My comment was that it was important to read reputable sources on both sides and reach informed conclusions. That tweet linking to peer-reviewed research was labeled "misinformation", and my account got my first suspension.
A second tweet (yes, I'm a slow learner - I thought adding good data to that discussion was essential) contained a link to a CDC study at a CDC.gov web address investigating whether Ivermectin worked for COVID. That tweet was also taken down as misinformation, and my account was again suspended, when the only information I added to the link was a brief but accurate summary of the study. Again, this reputable link was labeled "misinformation".
I appealed both suspensions and lost both times. I would have put money down that my appeals would win, back when I assumed these decisions would be thoughtful and fact-based. And, yes, I would have been willing to take Twitter to court over censoring peer-reviewed research and censoring links to CDC studies, if I could find a lawyer and a legal basis. Those lawsuits would be negative for Twitter. Adding financial harm to the personal offense taken over them censoring fact-based posts would also be a strong negative. I don't think their content moderation team is competent enough that Twitter can afford to raise the stakes.
↑ comment by Viliam · 2023-04-19T19:13:05.730Z · LW(p) · GW(p)
That creates an incentive to reject.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-04-19T22:22:02.097Z · LW(p) · GW(p)
Yeah, for the company. Ideally this is not passed on to the person doing the moderation. But yes, some better more incentive-balanced approach would be more ideal.
Replies from: Viliam↑ comment by Viliam · 2023-04-20T07:36:37.633Z · LW(p) · GW(p)
This reminds me of a problem I have heard about a few years ago, not sure if it still exists:
The problem was that scientific papers are usually checked from the scientific perspective, but a frequent problem is also horrible English (typically from authors who do not speak English as their first language). So some journals added "language review" as a first step of their reviews, and if the article was not correct English, they told the author to rewrite it, or offered a paid service of rewriting it to proper English.
The paid service turned out to be so profitable, that some journals simply started requiring it from all authors writing from non-English-speaking countries, regardless of the actual quality of their English. Specifically, native English speakers found out that if they move to a different country and start submitting their papers from there, suddenly they are told that their English is not good enough and they have to pay for having their language checked. So in effect this just became an extra tax for scientists based on their country.
Similarly, I am pessimistic about the willingness of companies to isolate potentially profit-generating employees from the financial consequences of their decisions.