[Discussion] How Broad is the Human Cognitive Spectrum?
post by DragonGod · 2023-01-07T00:56:21.456Z · LW · GW · 8 commentsThis is a question post.
Contents
Epistemic Status
Related Posts
Preamble: Why Does This Matter?
Introduction
Challenge
Lacklustre Empirical Support From AI's History
Conclusions
None
Answers
10 Pablo Villalobos
8 JBlack
4 bbartlog
1 Noosphere89
None
8 comments
Epistemic Status
Discussion question [LW(p) · GW(p)].
Related Posts
- Where The Falling Einstein Meets The Rising Mouse (Slatestarcodex)
- The range of human intelligence (AI Impacts)
Preamble: Why Does This Matter?
This question is important for building intuitions for thinking about takeoff dynamics; the breadth of the human cognitive spectrum (in an absolute sense) determines how long we have between AI that is capable enough to be economically impactful and AI that is capable enough to be existentially dangerous.
Our beliefs on this question factor into our beliefs on:
- The viability of iterative alignment strategies [LW · GW]
- Feasibility of attaining alignment escape velocity
- Required robustness to capability amplification of alignment techniques
Introduction
The Yudkowsky-Bostrom intelligence chart often depicts the gap between a village idiot and Einstein as very miniscule (especially compared to the gap between the village idiot and a chimpanzee):

Challenge
However, this claim does not feel to me to track reality very well/have been borne out empirically. It seems that for many cognitive tasks, the median practitioner is often much[1] closer to beginner/completely unskilled/random noise than they are to the best in the world ("peak human"):
- Mathematics
- Theoretical physics
- Theoretical research in general
- Fictional writing
- Writing in general
- Programming
- Music
- Art
- Creative pursuits in general
- Starcraft
- Games in general
- Invention/innovation in general
- Etc.
It may be the case that median practitioners being much closer to beginners than the best in the world is the default/norm, rather than any sort of exception.
Furthermore, for some particular tasks (e.g. chess) peak human seems to be closer to optimal performance than to median human.
I also sometimes get the sense that for some activities, median humans are basically closer to an infant/chimpanzee/rock/ant (in that they cannot do the task at all) than they are to peak human. E.g. I think the median human basically cannot:
- Invent general relativity pre 1920
- Solve the millennium prize problems
- Solve major open problems in physics/computer science/mathematics/other quantitative fields
And the incapability is to the extent where they cannot usefully contribute to the problems[2].
Lacklustre Empirical Support From AI's History
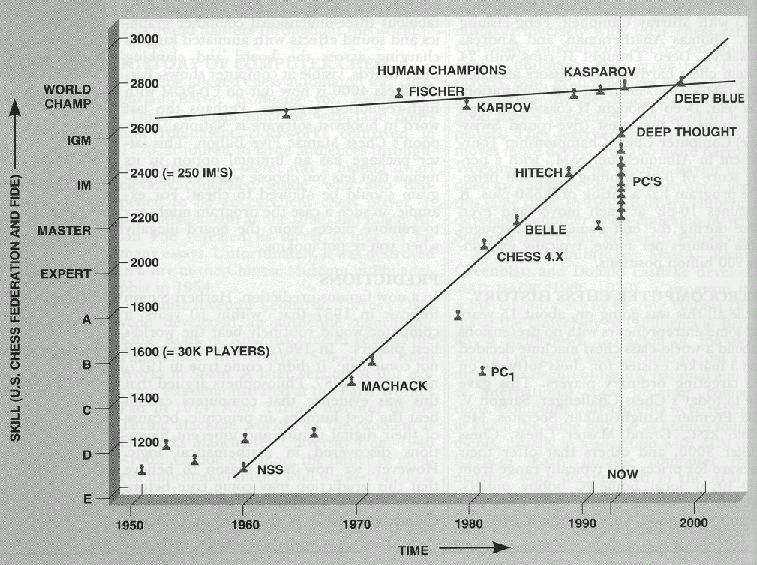
I don't necessarily think the history of AI has provided empirical validation for the Yudkowsky intelligence spectrum. For many domains, it seems to take AI quite a long time (several years to decades) to go from parity with dumb humans to exceeding peak human (this was the case for Checkers, Chess, and Go it also looks like it will be the case for driving as well)[3].
{kind=link}
{kind=link}
I guess generative art might be one domain in which AI quickly went from subhuman to vastly superhuman.
Conclusions
The traditional intelligence spectrum seems to track reality better for many domains:

- ^
My intuitive sense is that the scale difference between the two gaps is often not like 2x or 3x but measured in orders of magnitude.
I.e. the gap between Magnus Carlsen and the median human in chess ability is 10x - 1000x the gap between the median human and a dumb human.
- ^
Though I wouldn't necessarily claim that the median human is closer to infants than to peak humans on those domains, but the claim doesn't seem obviously wrong to me either.
- ^
I'm looking at the time frame from the first artificial system reaching a certain minimal cognitive level at the domain until an artificial system becomes superhuman. So I do not consider AlphaZero/MuZero surpassing humans in however many hours of self play to count as validation given that the first Chess/Go systems to reach dumb human level were decades prior.
Though perhaps the self play leap at Chess/Go may be more relevant to forecasting how quickly transformative systems would cross the human frontier.
Answers
I think the median human performance on all the areas you mention is basically determined by the amount of training received rather than the raw intelligence of the median human.
1000 years ago the median human couldn't write or do arithmetic at all, but now they can because of widespread schooling and other cultural changes.
A better way of testing this hypothesis could be comparing the learning curves of humans and monkeys for a variety of tasks, to control for differences in training.
Here's one study I could find (after ~10m googling) comparing the learning performance of monkeys and different types of humans in the oddity problem (given a series of objects, find the odd one): https://link.springer.com/article/10.3758/BF03328221
If you look at Table 1, monkeys needed 1470 trials to learn the task, chimpanzees needed 1310, 4-to-6 yo human children needed 760, and the best humans needed 138. So it seems the gap between best and worst humans is comparable in size to the gap between worst humans and monkeys.
Usual caveats apply re: this is a single 1960s psychology paper.
↑ comment by DragonGod · 2023-01-07T16:19:30.246Z · LW(p) · GW(p)
I agree that training/learning/specialisation seem more likely to explain the massive gaps between the best and mediocre than innate differences in general cognitive prowess. But I am also genuinely curious what the difference in raw g factor is between median human and +6 SD human and median human and -2 SD human.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T16:36:44.826Z · LW(p) · GW(p)
Answer: We know that classical computers and the very taut constraints on energy use completely rule out anything more than an order of magnitude, so 10x is the cap here on general intelligence.
My conjecture here is that the difference is probably closer to 2x-2.5x here, and that the IID distribution (also called the normal distribution.) works really well here.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T16:52:57.020Z · LW(p) · GW(p)
This has some underlying assumptions (around how hardware differences bound cognitive differences) that I'm not sure are quite true?
And those assumptions don't explain well why Magnus Carlsen is several orders of magnitude better than the median human at Chess.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T17:18:13.873Z · LW(p) · GW(p)
And those assumptions don't explain well why Magnus Carlsen is several orders of magnitude better than the median human at Chess.
The basic, boring answer is specialization does this. I.E if you can specialize into a given role, then you can get away with min-maxing your abilities. Indeed I think this is the basic reason why little human differences snowball.
There's also log-normal/power law distributions, where the majority of tasks have a heavy tail, that is the extreme outliers perform way better than the average, so this takes care of why small differences in general intelligence can lead to large differences in impact.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T17:21:56.824Z · LW(p) · GW(p)
The basic, boring answer is specialization does this. I.E if you can specialize into a given role, then you can get away with min-maxing your abilities. Indeed I think this is the basic reason why little human differences snowball.
I do think specialisation plays a large part in it.
There's also log-normal/power law distributions, where the majority of tasks have a heavy tail, that is the extreme outliers perform way better than the average, so this takes care of why small differences in general intelligence can lead to large differences in impact
Sorry, maybe I'm too dumb, but I don't understand how this explains away the phenomenon. This seems to describe the thing that's happening, but doesn't explain why it happens. Saying X happens is not an explanation for why X happens.
Why is it that for many cognitive tasks, the best in the world are so far better than the median? Stating that they are is not an explanation of the phenomenon.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T17:32:36.905Z · LW(p) · GW(p)
Sorry, maybe I'm too dumb, but I don't understand how this explains away the phenomenon. This seems to describe the thing that's happening, but doesn't explain why it happens. Saying X happens is not an explanation for why X happens.
Why is it that for many cognitive tasks, the best in the world are so far better than the median? Stating that they are is not an explanation of the phenomenon.
My point is that while intelligence is well approximated by a normal distribution (Not perfectly, and there may even be mild log-normal distributions), the others aren't well approximated by a normal distribution at all, which means that the controlling variable of intelligence has very small variance, but the variables that are controlled have very large deviations ala power laws are very heavy tailed log-normals, thus the distribution has very high variance, often multiple orders of magnitude variance large.
Replies from: green_leaf, DragonGod↑ comment by green_leaf · 2023-01-08T03:37:50.646Z · LW(p) · GW(p)
Intelligence being on a normal distribution is entirely unconnected to the magnitude of cognitive differences between humans - the units of the standard deviation are IQ points (1 SD = 15 IQ points), but IQ points aren't a linear measure of intelligence as applied to optimization power/learning ability/etc. - for that reason, it's meaningless to consider how large a percentage of people fits into how many SDs.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-08T14:30:43.947Z · LW(p) · GW(p)
Still, it's very hard to generate orders of magnitude differences, because normal distributions have very thin tails.
Replies from: DragonGod, green_leaf↑ comment by DragonGod · 2023-01-08T14:46:49.309Z · LW(p) · GW(p)
Uh, I was under the impression that IQ was somewhat fat tailed.
[Epistemic status: pretty low confidence. That's just a meme I've absorbed and not something I've independently verified. I wouldn't be surprised to learn that I'm mistaken in an important aspect here.
Replies from: TAG↑ comment by green_leaf · 2023-01-09T18:56:07.724Z · LW(p) · GW(p)
That doesn't follow. They have thin tails (in some well-specified mathematical sense), but that's unconnected to them generating or not generating orders of magnitude differences.
↑ comment by DragonGod · 2023-01-07T17:37:04.894Z · LW(p) · GW(p)
Does raw g factor show a normal distribution? Or is that just an artifact of the normalisation that is performed when computing IQ test scores?
And even with a normal distribution, do we know that it is not fat tailed? How large a difference in raw scores is there between +4 SD humans and median? What about -2 SD humans and median?
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T17:59:21.247Z · LW(p) · GW(p)
And even with a normal distribution, do we know that it is not fat tailed? How large a difference in raw scores is there between +4 SD humans and median? What about -2 SD humans and median?
These can be calculated directly, which is 60% better and 30% worse respectively, or 1.6x for the 4SD case and 0.7x for the -2SD case respectively.
I think this is probably pretty accurate, though normalization may be a big problem here.
I remember reading a Gwern post that shows a lot of studies on human ability, and they show very similar if not better results for my theory that humans abilities have a very narrow range.
My cruxes on this are the following, such that if I changed my mind on this, I'd agree with a broad range theory:
-
The normal/very thin tailed log-normal distribution is not perfect, but it well approximates the actual distribution of abilities. That is, there aren't large systematic errors in how we collect our data.
-
The normal or very thin tailed log-normals don't approximate the tasks we actually do, that is at least 1% of the top do contribute 10-20% or more to success.
↑ comment by gwern · 2023-01-09T02:58:18.982Z · LW(p) · GW(p)
I remember reading a Gwern post that shows a lot of studies on human ability, and they show very similar if not better results for my theory that humans abilities have a very narrow range.
You are probably thinking of my mentions of Wechsler 1935 that if you compare the extremes (defined as best/worst out of 1000, ie. ±3 SD) of human capabilities (defined as broadly as possible, including eg running) where the capability has a cardinal scale, the absolute range is surprisingly often around 2-3x. There's no obvious reason that it should be 2-3x rather than 10x or 100x or lots of other numbers*, so it certainly seems like the human range is quite narrow and we are, from a big picture view going from viruses to hypothetical galaxy-spanning superintelligences, stamped out from the same mold. (There is probably some sort of normality + evolution + mutation-load justification for this but I continue to wait for someone to propose any quantitative argument which can explain why it's 2-3x.)
You could also look at parts of cognitive tests which do allow absolute, not merely relative, measures, like vocabulary or digit span. If you look at, say, backwards digit span and note that most people have a backwards digit span of only ~4.5 and the range is pretty narrow (±<1 digit SD?), obviously there's "plenty of room at the top" and mnemonists can train to achieve digit spans of hundreds and computers go to digit spans of trillions (at least in the sense of storing on hard drives as an upper bound). Similarly, vocabularies or reaction time: English has millions of words, of which most people will know maybe 25k or closer to 1% than 100% while a neural net like GPT-3 probably knows several times that and has no real barrier to being trained to the point where it just memorizes the OED & other dictionaries; or reaction time tests like reacting to a bright light will take 20-100ms across all humans no matter how greased-lightning their reflexes while if (for some reason) you designed an electronic circuit optimized for that task it'd be more like 0.000000001ms (terahertz circuits on the order of picoseconds, and there's also more exotic stuff like photonics).
* for example, in what you might call 'compound' capabilities like 'number of papers published', the range will probably be much larger than '2-3x' (most people published 0 papers and the most prolific author out of 1000 people probably publishes 100+), so it's not like there's any a priori physical limit on most of these. But these could just break down into atomic: if paper publishing is log-normal because it's intelligence X ideas X work X ... = publications, then a range of 2-3x in each one would quickly give you the observed skewed range. But the question is where does that consistent 2-3x comes from, why couldn't it be utterly dominated by one step where there's a range of 1-10,000, say?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-09T03:08:09.887Z · LW(p) · GW(p)
That's what I was thinking about. Do you still have it on gwern.net? And can you link it please?
Some important implications here:
-
Eliezer's spectrum is far more right than Dragon god's spectrum of intelligence, and the claim of a broad spectrum needs to be reframed more narrowly.
-
This does suggest that AI intelligence could be much better than RL humans, even with limitations. That is, we should expect quite large capabilities differentials compared to human on human capabilities differentials.
↑ comment by DragonGod · 2023-01-07T18:22:24.466Z · LW(p) · GW(p)
These can be calculated directly, which is 60% better and 30% worse respectively, or 1.6x for the 4SD case and 0.7x for the -2SD case respectively.
Sorry, can you please walk me through these calculations.
I remember reading a Gwern post that shows a lot of studies on human ability, and they show very similar if not better results for my theory that humans abilities have a very narrow range.
Do you remember the post?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T18:39:41.674Z · LW(p) · GW(p)
Sorry, can you please walk me through these calculations.
Basically, the standard deviation here is 15, and the median is 100, so what I did was first multiply the standard deviation, then add or subtract based on whether the standard deviation number is positive or negative.
Do you remember the post?
I wish I did, but I don't right now.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T20:15:26.655Z · LW(p) · GW(p)
Basically, the standard deviation here is 15, and the median is 100, so what I did was first multiply the standard deviation, then add or subtract based on whether the standard deviation number is positive or negative.
But 15 isn't the raw difference in IQ test scores. The raw difference in underlying test scores are (re?)normalised to a distribution with a mean of 100 and standard deviation of 15.
We don't know what percentage difference in underlying cognitive ability/g factor 15 represents.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T20:33:33.486Z · LW(p) · GW(p)
We don't know what percentage difference in underlying cognitive ability/g factor 15 represents.
Yeah, this is probably a big question mark here, and an important area to study.
There is a big circularity here:
I think the median human basically cannot:
- Invent general relativity pre 1920
- Solve the millennium prize problems
- Solve major open problems in physics/computer science/mathematics/other quantitative fields
These tasks are defined by being at or above the extreme top end of human ability! No matter how narrow the range of human ability was on any absolute scale, these statements would be true. They are useless for supporting the conclusion.
↑ comment by DragonGod · 2023-01-08T10:31:17.614Z · LW(p) · GW(p)
Upvoted, this is a valid objection.
I guess we could abstract away the specific relative difficulty and talk about stuff like "algorithms/pure mathematics research" and the ability to perform those tasks of dumb humans, median humans and the very best in the field.
I still feel like the dumb humans can't do those tasks at all, median humans can contribute to those tasks but are (potentially much) closer to dumb humans than to peak humans in their contributions?
Replies from: JBlack↑ comment by JBlack · 2023-01-09T03:34:44.795Z · LW(p) · GW(p)
Yes, that seems pretty reasonable. Mathematical research does seem to require some minimal threshold of capability that lies within the human range, while quite a lot of other tasks seem to have a more linear return on intelligence from levels far below human.
This brings up a question: how far does this non-linearity extend? Would a somewhat superhuman entity with an otherwise generally human-like mind have the capacity for developing mathematical insights completely beyond the most capable humans? A positive answer would point toward the human cognitive range being somewhat narrow in the field of mathematics, just with a minimum threshold. The reverse would indicate that human capability covers much of the possible breadth of performance in that sort of task. Either possibility appears to be plausible.
Are there different tasks that have a similar minimal threshold that is beyond the most capable humans? Being human, we can't actually answer this one since we would not even recognize it as being possible at all.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-09T13:44:30.119Z · LW(p) · GW(p)
I think to the extent that non-linearity is observed, it's the fact that humans are way better at culture than other species, which allows us to invest in language.
We tried to model a complex phenomenon using a single scalar, and this resulted in confusion and clouded intuition.
It's sort of useful for humans because of restriction of range, along with a lot of correlation that comes from looking only at human brain operations when talking about 'g' or IQ or whatever.
Trying to think in terms of a scalar 'intelligence' measure when dealing with non-human intelligences is not going to be very productive.
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-07T18:20:53.205Z · LW(p) · GW(p)
I somewhat disagree here. Yes, If we truly tried to create a scalar intelligence that was definable across the entirety of the mathematical multiverse, the No Free Lunch theorem would tell us this can't happen.
However, instrumental convergence exists, so general intelligence can be done in practice.
From tailcalled here:
https://www.lesswrong.com/posts/GZgLa5Xc4HjwketWe/instrumental-convergence-is-what-makes-general-intelligence [LW · GW]
Specifically, there are common subtasks to real world tasks.
My intuitive sense is that the scale difference between the two gaps is often not like 2x or 3x but measured in orders of magnitude.
I think this cannot happen, due to physical limits that are very taut for human brains.
(AI will have limits, but they're quite a bit slacker here due to the fact that they can run on more energy without damaging it.)
From Jacob Cannell's post on brain efficiency:
So true 8-bit equivalent analog multiplication requires about 100k carriers/switches and thus 10^-15 J/op using noisy subthreshold ~0.1eV per carrier, for a minimal energy consumption on order 0.1W to 1W for the brain's estimated 10^14 -10^15 synaptic ops/s. There is some room for uncertainty here, but not room for many OOM uncertainty. It does suggest that the wiring interconnect and synaptic computation energy costs are of nearly the same OOM. I take this as some evidence favoring the higher 10^15 op/s number, as computation energy use below that of interconnect requirements is cheap/free.
Basically, orders of magnitude difference can't happen, only at best 1 OOM better can happen.
And in practice, I think human intelligence has significantly narrower bands than this, to the point where I think 2x differences are crazily high, and anything beyond that is beyond the human distribution.
This is because intelligence is well approximated by a normal distribution, and normal distributions with the population we have would have 6.4 standard deviations away from average at the top, which is essentially a little over 2x.
Thus I think Eliezer got this point much more right than most of his other points.
↑ comment by DragonGod · 2023-01-07T02:02:43.789Z · LW(p) · GW(p)
I think this cannot happen, due to physical limits that are very taut for human brains.
I was saying that e.g. the gap between Magnus Carlsen and the median human in chess ability is 10x - 1000x the gap between the median human and a dumb human.
I think this is just straightforwardly true and applies to many other fields.
Basically, orders of magnitude difference can't happen, only at best 1 OOM better can happen.
And in practice, I think human intelligence has significantly narrower bands than this, to the point where I think 2x differences are crazily high, and anything beyond that is beyond the human distribution.
This is because intelligence is well approximated by a normal distribution, and normal distributions with the population we have would have 6.4 standard deviations away from average at the top, which is essentially a little over 2x.
Thus I think Eliezer got this point much more right than most of his other points.
I think this just does not make sense as an inference from the post you cited/stand as a chain of reasoning in itself and it isn't well supported empirically.
Magnus Carlsen is not 2x as good in Chess as a median human.
The normal distribution of IQ is an induced one. The raw scores do not necessarily conform to the particular normal distribution we're familiar with. 200 IQ does not necessarily correspond to 2x g factor.
Replies from: gjm↑ comment by gjm · 2023-01-07T04:05:01.760Z · LW(p) · GW(p)
How are you measuring the gap between chess players?
Here is one way: say that A is one unit better than B if A beats B about 2/3 of the time. ("One unit" is also called "100 Elo rating points".) Now we can measure the difference between any two players by considering chains of one-unit-better players joining them, or by doing statistical magic to get a unified rating scale for everyone.
In the rating system used by FIDE (the international chess federation), Magnus Carlsen's rating is about 2850. I think a player making literally random moves would have a rating somewhere around zero. (This isn't because the zero point is deliberately set there or anything, it's just coincidence, and I might well be out by a couple of hundred points.) Beginners who have played only a few games and play hilariously badly might be rated somewhere around 200. The median human ... doesn't actually play chess. The median actually-chess-playing human (who probably has more aptitude for the game than the median human, since people prefer to play games they might be good at) is maybe somewhere around 1000 or so.
So, very crudely: dumb human = 0; median human = 1000; best human = 3000. The median-Magnus gap is larger than the dumb-median gap, but it's not anywhere near 10x larger.
On the other hand, you might choose some very different thing to measure. For instance: number of hours at current skill level to think up a chess opening move that's in a position already reached at least 10x in strong players' games, that has never been played before, and that is at least as good as all the other moves that have been played. I'm sure Magnus is at least 100x better than the median chess player by this metric. In general, "ability to do things only the best can do" will always be much much better at the top than everywhere else. If you measure a theoretical physicist by the rate at which they can make Nobel-worthy discoveries then the very best ones are probably 100x better than the median professional theoretical physicist, who in turn is well over 1000x better than the median human. On the other hand, it's probably also true that the median human is well over 1000x better than the stupidest human by this measure; it's not at all obvious what the (best:median) / (median:worst) ratio is like.
Any question like "by what factor are the best better than the average?" is liable to be very sensitive to exactly what you're measuring and how you quantify it.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T09:41:55.539Z · LW(p) · GW(p)
Uh, I wasn't using 0 as the set point for dumb human. And I'm not sure "median chess player" is necessarily a good set point for the ability of the median human. I think the median chess player is significantly better at chess than the median human.
It feels like a distortion/cheating to set dumb human at random play and median human at "median chess player". I feel like you should set dumb human at dumb chess player or median human at an actual median human for consistency.
But on second thought, this doesn't actually matter for my argument.
As for how to measure gaps, I think the negative of the logarithm of the probability of winning is good?
(The intuition is that an improvement in accuracy from and frok are the same linear increase in ability).
A difference of bits would thus corresponds to a larger gap (smaller numbers are better, but here we're only looking at the gaps, not the raw differences in ability).
That was the intuition driving the Magnus Carlsen statement; that linear differences in ELO represent exponential gaps in ability.
Using your numbers of and .
There are units between dumb human and median human and units between median human and dumb human. But that unit difference is not a linear gap but exponential and represents several orders of magnitude.
More concretely, every points of ELO correspond to a increase in expected score.
So there is (very) roughly:
- A difference in expected score between median human and dumb human
- A difference in expected score between median human and peak human.
larger gap, so a 2.5 orders of magnitude larger gap.
Replies from: gjm↑ comment by gjm · 2023-01-07T13:29:29.425Z · LW(p) · GW(p)
I wasn't claiming that you were "using 0 as the set point for dumb human"; I'm not sure where you get that from. All I said is that with typical chess Elo ratings, a random player (which is what I'm using to stand in for "really stupid human") happens to end up not too far from a rating of 0.
One difficulty here is that, as I mentioned, the median human being doesn't actually play chess, so the interpretation of terms like "median human" and "dumb human" isn't clear.
If we look at the whole human population and actual chess-playing ability then the worst and the median are both at the "don't actually know the rules" level. I don't even know how you assess games involving such players. It might in that case be true that (best:median)/(median:worst) is infinite but I think it's clear that this isn't actually telling us anything meaningful about chess ability.
If we look at the whole human population and something like "chess-playing ability if you tell them the rules but otherwise don't intervene at all" then again the differences between people who previously didn't know the rules will be very small, and again I don't think it will tell us anything interesting.
If we look at the whole human population and something like "chess-playing ability if the ones who previously didn't know the rules or hardly ever played spent a month playing casually in their spare time before being assessed" then my guess is that we'd have worst still close to a rating of 0 on typical Elo scales, median maybe somewhere around 800?, and best still Magnus at 2850.
If we look at just the population of people who ever actually play chess (and go back to no interventions) then I guess we get worst still not much over 0 (maybe 100 or so?), median somewhere around 1000 or so, and best still Magnus at 2850.
Etc.
The Elo rating system is basically log odds rather than log probabilities, but it's close enough to what you have in mind. (And I claim log odds is clearly better than log probability, and I think odds rather than probability is actually what you meant since e.g. the logarithms of 99% and 99.9% are not much different.)
Your meaning isn't 100% clear to me, since first of all you say negative log [odds] "is good" as a way to measure gaps -- which is equivalent to measuring Elo rating differences, which is what I did -- but then afterwards you say: no, but actually we should look at the thing that's the logarithm of: "linear differences in ELO represent exponential gaps in ability". So you don't think log odds is a good measure of gap after all?
Anyway, if you measure gap by winning-odds-ratio then I'll agree that the Carlsen-median gap is many times bigger than the median-worst gap. But:
1. If you measure that way then gaps are multiplicative rather than additive, which means that e.g. diagrams like the intelligence scales you sketch in the OP are misleading. And, I claim, ratios of gap sizes are likewise misleading.
2. The original point of your remarks about Carlsen being so dramatically better than average chess players was in support of the thesis that there isn't much more "room at the top" for super-skilled computers, and if you measure that way then there's quite a lot of room.
Expanding on 1: suppose A < B < C and "the B-C gap is 100x bigger than the A-B gap". Does this mean that the A-C gap is barely bigger than the B-C gap? Yes for e.g. ELO rating differences: if the ratings are 1000, 1010, 2000 then C will beat A and B at about the same rate. But no for odds ratio. Suppose the B:A odds ratio is 2 and the C:B odds ratio is 200. In the Elo model these are multiplicative, so the C:A odds ratio is 400. And 400 is not barely bigger than 200.
Expanding on 2: so far as I can see no one's made a really serious effort at measuring current top chess engine strength on a scale compatible with, say, FIDE's, but according to someone at https://chess.stackexchange.com/questions/40485/what-is-stockfish-15s-fide-calibrated-elo-rating TCEC ratings shouldn't be crazily wrong and they put Stockfish 15 at about 3620, versus Carlsen at about 2850. That's a 600ish-point rating difference, which converted at the "400 points = 10x score increase) says that today's superhuman robots are say 13x better than the best human.
I don't see any perspective from which this looks much like a scale with "village idiot" at one end, "Einstein" at the other, and no substantial room for better-than-Einstein scores.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T13:41:58.891Z · LW(p) · GW(p)
The point about using 0 elo as a stand in for dumb human doesn't seem to be germane to our actual disagreements, so I wouldn't address it.
The Elo rating system is basically log odds rather than log probabilities, but it's close enough to what you have in mind. (And I claim log odds is clearly better than log probability, and I think odds rather than probability is actually what you meant since e.g. the logarithms of 99% and 99.9% are not much different.)
Your meaning isn't 100% clear to me, since first of all you say negative log [odds] "is good" as a way to measure gaps -- which is equivalent to measuring Elo rating differences, which is what I did -- but then afterwards you say: no, but actually we should look at the thing that's the logarithm of: "linear differences in ELO represent exponential gaps in ability". So you don't think log odds is a good measure of gap after all?
I think it is a good measure of the gap, but the scale is not a linear scale but a logarithmic scale. Hence a linear difference on that scale represents an exponential difference in the underlying quantity.
1. If you measure that way then gaps are multiplicative rather than additive, which means that e.g. diagrams like the intelligence scales you sketch in the OP are misleading. And, I claim, ratios of gap sizes are likewise misleading.
I'm not sure I understand this point well.
Expanding on 2: so far as I can see no one's made a really serious effort at measuring current top chess engine strength on a scale compatible with, say, FIDE's, but according to someone at https://chess.stackexchange.com/questions/40485/what-is-stockfish-15s-fide-calibrated-elo-rating TCEC ratings shouldn't be crazily wrong and they put Stockfish 15 at about 3620, versus Carlsen at about 2850. That's a 600ish-point rating difference, which converted at the "400 points = 10x score increase) says that today's superhuman robots are say 13x better than the best human.
But that point difference is much smaller than the point difference between Carlsen and the median chess player (using as the baseline for median). That was the argument I made; that Carlsen was closer to optimal play[1] than to median, not that optimal play was not much better than Carlsen.
I don't see any perspective from which this looks much like a scale with "village idiot" at one end, "Einstein" at the other, and no substantial room for better-than-Einstein scores.
This wasn't a point I was trying to make in the post, nor is it a point I actually believe. I do believe there is a lot of room above humans, I just think the human spectrum is itself very large.
- ^
I should caveat this that by "optimal play", I meant something more like "optimal play given bounded resources", not necessarily optimal play with unbounded computational resources.
↑ comment by gjm · 2023-01-07T18:06:55.833Z · LW(p) · GW(p)
The point about using 0 elo as a stand in for dumb human doesn't seem to be germane to our actual disagreements, so I wouldn't address it.
Fine with me, but I just want to note again that I am not using 0 Elo as a "stand-in" nor saying you were doing that, I'm estimating roughly where a dumb human happens to end up on the scale, and for the case of FIDE chess ratings I think it turns out to be near zero. To be clear, I'm not trying to reopen any discussion about whether that's right (since I agree it isn't particularly important for our actual disagreement), it's just that it seems like you're being quite insistent about describing something I did in a way that doesn't match what I think I was actually doing, and I would prefer the last thing about it in the discussion not to misrepresent my intentions.
(I notice that that sounds more annoyed than I actually am. Not annoyed, just wanting to avoid future misunderstandings.)
Replies from: DragonGod↑ comment by gjm · 2023-01-07T18:01:10.728Z · LW(p) · GW(p)
I'm not sure there exactly is an "underlying quantity" here. Differences in rating, hence odds ratios in results, are fairly well defined (though, note, it's not like there's any sort of necessary principle along the lines of "if when A plays lots of games against B their odds are a:b, and if when B plays lots of games against C their odds are b:c, then when A plays lots of games against C their odds are a:c", which the Elo scale and the usual ways of updating Elo ratings in the light of results are effectively assuming IIUC). But I don't think there's an absolute thing that the differences are sensibly regarded as differences in or ratios of.
I guess you could try to pick some "canonical" single player -- a truly random player, or a literally perfect player -- and look at odds ratios there. But I think the assumption I mentioned in the previous paragraph really does break down in that case.
I'm not sure I understand this point well.
I expanded on it a couple of paragraphs below. If that still didn't clarify, can you say a bit about what doesn't make sense?
That ~600 point difference is much smaller than the 1800+ point difference between Carlsen and the median chess player [...] the argument that I made [] that Carlsen was closer to optimal play than to median, not that optimal play was not much better than Carlsen.
Hmm, maybe I misunderstood something? You wrote
It seems that for many cognitive tasks, the median practitioner is often much closer to beginner/completely unskilled/random noise than they are to the best in the world [... footnote:] My intuitive sense is that [...] the gap between Magnus Carlsen and the median human in chess ability is 10x - 1000x the gap between the median human and a dumb human.
It's the "10x-1000x" I'm disputing, not any version of "much closer" that's compatible with the "right" numbers being on the order of 0 / 1000 / 3000.
As for any relationship to optimal play, I was getting that from assuming that what you said about chess was intended as support for drawing a scale with "idiot" on the left and "Einstein" on the right rather than one with "mouse" on the left and "vast superhuman intelligence" on the right. (My own feeling is that what we actually want is more likely a scale with all four of those points on it, and no pair super-close together. Idiots really are much smarter than mice; Einstein really is much smarter than an idiot; God really is much smarter than Einstein; and for many purposes none of those gaps is so large or so small as to make the others negligible. For difficult enough tasks, idiots and mice may be indistinguishable, or even idiots and mice and average people, but those are also the tasks for which I expect hypothetical superintelligences to have big advantages over the smartest humans.)
So I took you to be suggesting that the median-Carlsen gap is large enough that at least one of these pictures is not misleading: ||---------| (vertical bars are idiot, median, Carlsen) or |------------|| (vertical bars are median, Carlsen, superhuman machine). And I don't agree with either; I think the idiot-median-Carlsen-machine picture is more like |-----|----------|-----| except that I don't know how much room there is for that last gap to grow as the machines continue to improve.
And my reason for thinking this is that (1) if you use something like log odds (roughly equivalent to Elo ratings) to measure the gap sizes, then that's what happens, and (2) if you use the odds themselves[1] then indeed the larger gaps become larger by huge factors, but in that case the |-----|--------| pictures where you put gaps next to one another and compare their sizes are completely misleading, because the correct way to combine two gaps is not to put them side by side (which amounts to adding up their sizes), and (3) these large-factor gaps don't seem to me to be reason to prefer your "just idiot...Einstein" scale to the sort that Yudkowsky likes to draw, because the point Yudkowsky is trying to make by drawing them is about what happens to the right of Einstein, and there is good reason to think that there's plenty -- in particular, there's a large-odds-ratio gap -- to the right of Carlsen.
[1] Insert Schiller quote here :-).
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T18:30:44.749Z · LW(p) · GW(p)
It's the "10x-1000x" I'm disputing, not any version of "much closer" that's compatible with the "right" numbers being on the order of 0 / 1000 / 3000.
I think that's basically correct. Magnus Carlsen's expected score vs a median human is 100s of times greater than a median human's expected score vs a dumb human (as inferred from their ELO, I sketched a rough calculation at the end of this post [LW(p) · GW(p)]).
As for the remainder of your reply, the point of Yudkowsky's I was contending with is the claim that Einstein is very close to an idiot in absolute terms (especially compared to the difference between an idiot and a chimpanzee).
I wasn't touching on how superintelligences compare to Einstein.
Replies from: gjm↑ comment by gjm · 2023-01-07T20:30:04.123Z · LW(p) · GW(p)
I don't think you mean exactly that
Magnus Carlsen's expected score vs a median human is 100s of times greater than a median human's expected score vs a dumb human
since to a good approximation Carlsen gets 100 wins, 0 draws, 0 losses against a median human for a total score of 100, and a median human gets at least an expected score of 50 against a dumb human.
I do not dispute that there are ways of doing the accounting that make the Carlsen-median gap 100x (or 1000x or whatever) bigger than the median-dumbest gap. My claim is that for most purposes those ways of doing the accounting are worse.
I can't tell whether you think my reasons for thinking that are too stupid to deserve a response, or think they miss the point in some fundamental way, or don't understand them, or just aren't very interested in discussing them. But that's where the actual disagreement lies.
As for mouse/chimp/idiot/Einstein, my general model of these things is that for most mental tasks there's a minimum level of brainpower needed to do them at all, which for things we think of as interesting mental tasks generally lies somewhere between "idiot" and "Einstein" (because if even idiots could do them easily we wouldn't think of them as interesting mental tasks, and if even Einsteins couldn't do them we mostly wouldn't think of them at all), and sometimes but maybe not always a maximum level of brainpower needed to do them about as well as possible, which might or might not also be somewhere between "idiot" and "Einstein", and then the biggest delta is the one between not being able to Do The Thing and being able to do it, and after that any given increment matters a lot until you get to the maximum, and after that nothing matters much.[1] So when we pay attention to some specific task we think of as a difficult thing humans can do, we should expect to find "mouse", "chimp", "idiot", and some further portion of the human population all clustered together and "Einstein" some way away. But there are also tasks that pretty much all humans can do, some of which distinguish (e.g.) mice from chimps, and I think it's fair to say that there is a real sense in which humans are closer to chimps than chimps are to mice even though for human-ish mental tasks there's no difference to speak of between mice and chimps; and for some tasks there is probably huge scope for doing better than the best humans. (Some of those tasks may be ones it has never occurred to us to try because they are beyond our conception.) I think the question of how much room there is above "Einstein" on the scale is highly relevant if you are asking how close "idiot" and "Einstein" are.
[1] Of course this is a simplification; minima and maxima for this sort of thing are usually "soft" rather than "hard", and most interesting tasks actually involve a variety of skills whose minima and maxima won't all be in the exact same place, and brainpower isn't really one-dimensional, etc., etc., etc. I assume you appreciate all these things as well as I do :-).
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T20:51:23.863Z · LW(p) · GW(p)
I don't think you mean exactly that
Magnus Carlsen's expected score vs a median human is 100s of times greater than a median human's expected score vs a dumb human
since to a good approximation Carlsen gets 100 wins, 0 draws, 0 losses against a median human for a total score of 100, and a median human gets at least an expected score of 50 against a dumb human.
What's your issue with the below calculation.
- points ELO represents a difference in expected score
- "It then follows that for each 400 rating points of advantage over the opponent, the expected score is magnified ten times in comparison to the opponent's expected score."
- Median - dumb ELO difference is points: difference in expected score
- Magnus - median ELO difference is points: difference in expected score
- Magnus - median gap is median-human gap
I do not dispute that there are ways of doing the accounting that make the Carlsen-median gap 100x (or 1000x or whatever) bigger than the median-dumbest gap. My claim is that for most purposes those ways of doing the accounting are worse.
I can't tell whether you think my reasons for thinking that are too stupid to deserve a response, or think they miss the point in some fundamental way, or don't understand them, or just aren't very interested in discussing them. But that's where the actual disagreement lies.
You've not addressed what you think is wrong with the above calculation, so I'm just confused. I think it's basically a canonical quantification of chess ability?
I think the question of how much room there is above "Einstein" on the scale is highly relevant if you are asking how close "idiot" and "Einstein" are.
We could also just ask whether idiot was closer to chimpanzee than to Einstein. I'm mostly interested in how long it takes AI to cross the human cognitive frontier, not whether strongly superhuman AI is possible (I think it is).
Replies from: gjm↑ comment by gjm · 2023-01-07T22:13:29.601Z · LW(p) · GW(p)
My issue with the calculation isn't with the calculation. It is indeed correct (with the usual assumptions, which are probably somewhat wrong but it doesn't much matter) that if Magnus plays many games against a median chessplayer then he will probably get something like 10^4.6 times as many points as they do, and that if a median chessplayer plays a maximally-dumb one then they will probably get something like 10^2.5 times as many points as the maximally-dumb one, and that the ratio between those two ratios is on the order of 100x. I don't object to any of that, and never have.
I feel, rather, that that isn't a very meaningful calculation to be doing, if what you want to do is to ask "how much better is Carlsen than median, than median is better than dumbest?".
More specifically, my objections are as follows. (They overlap somewhat.)
0. The odds-ratio figure you are using is by no means the canonical way to quantify chess ability. Consider: the very first thing you said on the topic was "As for how to measure gaps, I think the negative of the logarithm of the [odds] is good". I agree with that: I think log-odds is better for most purposes.
1. For multiplicative things like these odds ratios, I think it is generally misleading to say "gap 1 is 10x as big as gap 2" when you mean that the odds ratio for gap 2 is 10x bigger. I think that e.g. "gap 1 is twice as big as gap 2" should mean that gap 2 is like one instance of gap 1 and then another instance of gap 1, which for odds ratios means that the odds ratio for gap 2 is the square of the odds ratio for gap 1. By that way of thinking, the median-Magnus gap is less than twice the size of the dumbest-median gap. Your terminology requires you to say that the median-Magnus gap simultaneously (a) is hundreds of times bigger than the dumbest-median gap and (b) is not large enough to fit two copies of the dumbest-median gap into (i.e., find someone X as much better than median as median is than dumber; and then find someone Y as much better than X as median is than dumber; if you do that, Y will be better than Magnus).
2. If you are going to draw diagrams like the Yudkowsky scale, which implicitly compare "gap sizes" by placing gaps next to one another, then you had better be using a measure of difference that behaves additively rather than multiplicatively. Because that's the only way for the relative distances of A,B,C along the scale to convey accurately the relationship between the A-B, B-C, and A-C gaps. (You could of course make a scale where position is proportional to, say, "odds ratio against median player". That will make the dumbest-median gap very small and the median-Magnus gap very large. But it will also make an "odds ratio 10:1" gap vary hugely in size depending on where on the scale it is, which I don't think is what you want to do.)
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T22:46:36.441Z · LW(p) · GW(p)
#0. Regarding the log of the odds ratios, I want to clarify that I never meant it as a linear scale. I was working with the intuition that linear gaps in logarithmic scales are exponential.
#1. I get what you're saying, but I think this objection would apply to any logarithmic scale; do you endorse that conclusion/generalisation of your objection?
If the gap between two points on a logarithmic scale is , and that represents a change of in the underlying quantity, a gap of would represent a change of in the underlying quantity.
Talking about change may help elide the issues from different intuitions about what gaps should mean.
My claim above was that the underlying quantity was (a linear measure of) "chess ability", and the ELO scale had that kind of logarithmic relationship to it.
2. I was implicitly making the transformation above where I converted a logarithmic scale into a linear/additive scale.
I agree that it doesn't make sense to use non linear scales when talking about gaps. I also agree that ELO score is one such nonlinear scale.
My claim about the size of the gap was after converting the nonlinear ELO rating to the ~linear "expected score". Hence I spoke about gaps in expected score.
I think the crux is this: What do you think is the best/most sensible linear measure of chess ability?
(By linear measure, i mean that a difference of is times as big as a difference of .)
Replies from: gjm↑ comment by gjm · 2023-01-08T02:06:21.925Z · LW(p) · GW(p)
I am not sure exactly what you're asking me whether I endorse, but I do indeed think that for "multiplicative" things that you might choose to measure on a log scale, "twice as big a gap" should generally mean 2x on the log scale or squaring on the ratio scale.
If you think it doesn't make sense to use nonlinear scales when talking about gaps, and think Elo rating is nonlinear while exp(Elo rating) is linear, then you are not agreeing but radically disagreeing with me. I think Elo rating differences are a pretty good way of measuring gaps in chess ability, and I think exp(Elo rating) is much worse.
I think Elo rating is nearer to being a linear measure of chess ability than odds ratio, to whatever extent that statement makes sense. I think that if you spend a while doing puzzles every day and your rating goes up by 50 points (~1.33x improvement in odds ratio), and then you spend a while learning openings and your rating goes up by another 50 points, then it's more accurate to say that doing both those things brought twice the improvement that doing just one did (i.e., 100 points versus 50 points) than to say it brought 1.33x the improvement that doing just one did (i.e., 1.78x odds versus 1.33x odds). I think that if you're improving faster and it's 200 points each time (~3x odds) then it doesn't suddenly become appropriate to say that doing both things brought 3x the improvement of doing one of them. I think that if you're enough better than me that you get 10x more points than I do when we play, and if Joe Blow is enough better than you that he gets 10x more points than you do when we play, then the gap between Joe and me is twice as big as the gap between you and me or the gap between Joe and you, because the big gap can be thought of as made up of two identical smaller gaps, and not 10x as big.
8 comments
Comments sorted by top scores.
comment by Viliam · 2023-01-08T23:41:22.143Z · LW(p) · GW(p)
I suspect that if you pick specifically human activities (fiction writing, programming), the gap between individual humans will seem much bigger than if you pick activities that also other animals do (finding a path in a maze you are in).
Replies from: DragonGodcomment by beren · 2023-01-08T00:53:00.749Z · LW(p) · GW(p)
I've had similar questions to this before in terms of how human individual differences appear so great when the actual seeming differences in neurophysiology between +3 and -3 SD humans are so small. My current view on this is that:
a.) General 'peak' human cognition is pretty advanced and the human brain is large even by current ML standards so by the scaling laws we should be pretty good vs existing ML systems at general tasks. This means that human intelligence is pretty 'far out' compared to current ML often and that scaling ML tasks much beyond humans is often expensive unless it is a super specialised task where ML systems have a much lower constant factor due to better adapted architecture/algorithm. Specialized ML systems will still hit a scaling wall at some point but it could be quite a way from peak human cognition.
b.) Most human variation is caused by deleterious mutations away from the 'peak' and because it is so much easier to destroy than to gain performance, human performance is basically from 0 -> human peak. The higher up human peak is the larger this will seem. Median human is a bad benchmark because the median human operates at substantially less than our true scaling law potential. Because of this scaling ML systems often lie in the range of human performance for a long time as they climb up to our peak level.
c.) In some sense the weird thing is that humans are so bad instead of a tight normal distribution around peak performance. This has got to do with it being easier to mess up performance than to improve it. I wonder what the distribution of some SOTA ML architecture would be if we randomly messed with its architecture and training.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-08T02:19:32.968Z · LW(p) · GW(p)
a.) General 'peak' human cognition is pretty advanced and the human brain is large even by current ML standards so by the scaling laws we should be pretty good vs existing ML systems at general tasks. This means that human intelligence is pretty 'far out' compared to current ML often and that scaling ML tasks much beyond humans is often expensive unless it is a super specialised task where ML systems have a much lower constant factor due to better adapted architecture/algorithm. Specialized ML systems will still hit a scaling wall at some point but it could be quite a way from peak human cognition.
I think that this is correct with one caveat:
- We are closing the gap between human brains and ML models, and I think this will probably happen a decade or so away from now.
I think that ML and human brains will converge to the same or similar performance this century, and the big difference is more energy can be added in pretty reliably to the ML model while humans don't enjoy this advantage.
Replies from: beren↑ comment by beren · 2023-01-08T12:07:08.063Z · LW(p) · GW(p)
Yes definitely. Based on my own estimates of approximate brain scale it is likely that current largest. ML projects (GPT4) are within an OOM or so of effective parameter count already (+- 1-2 OOM) and we will definitely have brain-scale ML systems being quite common within a decade and probably less -- hence short timelines. Strong agree that it is much easier to add compute/energy to ML models vs brains.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-08T16:28:50.027Z · LW(p) · GW(p)
Have you written your estimates of brain scale up anywhere?
Replies from: beren↑ comment by beren · 2023-01-08T22:05:42.549Z · LW(p) · GW(p)
I've written up some of my preliminary thought and estimates here: https://www.beren.io/2022-08-06-The-scale-of-the-brain-vs-machine-learning/.
Jacob Cannell's post on brain efficiency https://www.lesswrong.com/posts/xwBuoE9p8GE7RAuhd/brain-efficiency-much-more-than-you-wanted-to-know [LW · GW] is also very good
Replies from: DragonGod