DragonGod's Shortform
post by DragonGod · 2022-05-31T19:01:29.511Z · LW · GW · 194 commentsContents
202 comments
194 comments
Comments sorted by top scores.
comment by DragonGod · 2023-02-21T08:40:28.549Z · LW(p) · GW(p)
I turned 25 today.
Replies from: Throwaway2367, yitz↑ comment by Throwaway2367 · 2023-02-21T09:33:04.095Z · LW(p) · GW(p)
Happy Birthday!
↑ comment by Yitz (yitz) · 2023-02-22T07:43:45.421Z · LW(p) · GW(p)
Happy 25 years of existence! Here’s to countless more :)
comment by DragonGod · 2023-02-28T20:30:35.131Z · LW(p) · GW(p)
[Originally written for Twitter]
Many AI risk failure modes imagine strong coherence [LW · GW]/goal directedness (e.g. [expected] utility maximisers).
Such strong coherence is not represented in humans, seems unlikely to emerge from deep learning and may be "anti-natural" to general intelligence in our universe [LW · GW].
I suspect the focus on strongly coherent systems was a mistake that set the field back a bit, and it's not yet fully recovered from that error.
I think most of the AI safety work for strongly coherent agents (e.g. decision theory) will end up inapplicable/useless for aligning powerful systems.
[I don't think it nails everything, but on a purely ontological level, @Quintin Pope [LW · GW] and @TurnTrout's [LW · GW] shard theory [LW · GW] feels a lot more right to me than e.g. HRAD.
HRAD is based on an ontology that seems to me to be mistaken/flawed in important respects.]
The shard theory account of value formation (while lacking) seems much more plausible as an account of how intelligent systems develop values (where values are "contextual influences on decision making") than the immutable terminal goals in strong coherence ontologies. I currently believe that immutable terminal goals is just a wrong frame [LW · GW] for reasoning about generally intelligent systems in our world (e.g. humans, animals and future powerful AI systems)[1].
And I'm given the impression that the assumption of strong coherence is still implicit in some current AI safety failure modes (e.g. it underpins deceptive alignment [LW · GW][2]).
I'd be interested in more investigation into what environments/objective functions select for coherence and to what degree said selection occurs.
And empirical demonstrations of systems that actually become more coherent as they are trained for longer/"scaled up" or otherwise amplified.
I want advocates of strong coherence to explain why agents operating in rich environments (e.g. animals, humans) or sophisticated ML systems (e.g. foundation models) aren't strongly coherent.
And mechanistic interpretability analysis of sophisticated RL agents (e.g. AlphaStar, OpenAI Five [or replications thereof]) to investigate their degree of coherence.
Currently, I think strong coherence is unlikely (plausibly "anti-natural"[3]) and am unenthusiastic about research agendas and threat models predicated on strong coherence.
Disclaimer this is all low confidence speculation, and I may well be speaking out of my ass.
I do think that my disagreements with deceptive alignment is not a failure of understanding, but I am very much an ML noob, so there can still be things I just don't know. My opinion on this matter would probably be different in a significant way by this time next year.
- ^
You cannot well predict the behaviour/revealed preferences of humans or other animals by the assumption that they have fixed terminal goals.
The ontology that intelligent systems in the real world instead have "values" (contextual influences on decision making) seems to explain their observed behaviour (and observed incoherencies) better.
- ^
In addition to the other prerequisites listed in the "Deceptive Alignment" post, deceptive alignment also seems to require a mesa-optimiser so coherent that it would be especially resistant to modifications to its mesa-objective. That is it requires very strong levels of goal content integrity.
- ^
E.g. if the shard theory account of value formation is at all correct, particularly the following two claims:
* Values are inherently contextual influences on decision making
* Values (shards) are strengthened (or weakened) via reinforcement events
Then strong coherence in the vein of utility maximisation just seems like an anti-natural form
↑ comment by Vladimir_Nesov · 2023-02-28T20:51:04.291Z · LW(p) · GW(p)
I think this is broadly a right mindset for starting to think about AGIs humans are likely to build (even if I disagree in detail), given the abject failure at doing alignment responsibly. But HRAD-style AGIs are still coming eventually, and even if the AGIs that humans build are directly aligned (don't kill everyone themselves), they'll eventually build those, and then the sorts of failure modes characteristic for them are going to become relevant. The MIRI style of alignment work might even indirectly save humanity from blunders by first generations of aligned AGIs, promoting this line of research to their attention and thus providing timely education about the kinds of danger of misalignment that more powerful agentic designs might manifest.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-28T21:38:30.792Z · LW(p) · GW(p)
Why do you think HRAD-style AGIs are coming eventually?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-02-28T21:47:11.467Z · LW(p) · GW(p)
If you are an AGI, take misalignment concerns seriously, and don't want the next generations of AGIs to merely have some chance of getting to care about your well-being by at least a very tiny fraction, you stop building AGIs with new designs or self-experimenting based on vague selection principles. But you still want strong optimization to make use of all the galaxies in the Hubble volume, before they get out of reach. So this time, you do it right.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-28T20:31:05.098Z · LW(p) · GW(p)
Let me know if you want this to be turned into a top level post.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-03-01T01:40:00.671Z · LW(p) · GW(p)
Seems useful. I think there are a set of important intuitions you're gesturing at here around naturality, some of which I may share. I have some take (which may or may not be related) like
utility is a measuring stick which is pragmatically useful in certain situations, because it helps corral your shards (e.g. dogs and diamonds) into executing macro-level sensible plans (where you aren't throwing away resources which could lead to more dogs and/or diamonds) and not just activating incoherently.
but this doesn't mean I instantly gain space-time-additive preferences about dogs and diamonds such that I use one utility function in all contexts, such that the utility function is furthermore over universe-histories (funny how I seem to care across Tegmark 4?).
Replies from: DragonGod↑ comment by DragonGod · 2023-03-01T08:41:59.865Z · LW(p) · GW(p)
Many observed values in humans and other mammals (see[4]) (e.g. fear, play/boredom, friendship/altruism, love, etc.) seem to be values that were instrumental for increasing inclusive genetic fitness (promoting survival, exploration, cooperation and sexual reproduction/survival of progeny respectively). Yet, humans and mammals seem to value these terminally and not because of their instrumental value on inclusive genetic fitness.
That the instrumentally convergent goals of evolution's fitness criterion manifested as "terminal" values in mammals is IMO strong empirical evidence against the goals ontology and significant evidence in support of shard theory's basic account of value formation.
Evolutionarily convergent terminal values, is something that's underrated I think.
comment by DragonGod · 2023-04-07T17:43:43.393Z · LW(p) · GW(p)
Confusions About Optimisation and Agency
Something I'm still not clear how to think about is effective agents in the real world.
I think viewing idealised agency as an actor that evaluates argmax wrt (the expected value of) a simple utility function over agent states is just wrong [LW · GW].
Evaluating argmax is very computationally expensive, so most agents most of the time will not be directly optimising over their actions but instead executing learned heuristics that historically correlated with better performance according to the metric the agent is selected for (e.g. reward).
That is, even if an agent somehow fully internalised the selection metric, directly optimising it over all its actions is just computationally intractable in "rich" (complex/high dimensional problem domains, continuous, partially observable/imperfect information, stochastic, large state/action spaces, etc.) environments. So a system inner aligned to the selection metric would still perform most of its cognition in a mostly amortised manner, provided the system is subject to bounded compute constraints.
Furthermore, in the real world learning agents don't generally become inner aligned to the selection metric, but instead learn cognitive heuristics that historically correlated with performance on the selection metric.
[Is this because direct optimisation for the outer selection metric is too computationally expensive? I don't think so. The sense I get is that selection just doesn't work that way. The selection process can't internalise the selection metric, because selection for a given metric produces equally strong selection for all the metric's necessary and sufficient conditions [LW · GW][1] (the "invariants of selection"):
In some sense, the true metric is under specified.
Note however, that this underspecification is more pernicious than just not distinguishing between the invariants of selection. The inductive biases of the selection process also matter. Proxies that are only correlated with the selection metric ("imperfect proxies") may be internalised instead of the selection metric if they are more accessible/reachable/learnable by the intelligent system than the actual selection metric.
Analogy: humans couldn't have internalised evolution's selection metric of inclusive genetic fitness because humans had no concept of inclusive genetic fitness.]
So there are at least two dimensions on which real world intelligent systems diverge from the traditional idealisations of an agent:
- Real world systems do not perform most of their cognition by directly optimising an appropriate objective function, but by executing learned cognitive adaptations [LW · GW]
- Note that I said "most"; humans are capable of performing direct optimisation (e.g. "planning") when needed, but such explicit reasoning is a minority of our cognition
- Real world systems don't internalise the metric on which they were selected for, but instead learn various contextual heuristics that correlated with high performance on that metric [LW · GW].
- I see this as the core claim of shard theory [LW · GW], and the cause of "complexity of value [? · GW]"
I think this establishes some sort of baseline for what real world intelligent systems are like. However, I do not know what such systems "converge" to as they are scaled up (in training/inference compute/data or model parameters).
I am not very sure how online learning affects this either.
I am sceptical that it converges towards anything like "embedded [LW · GW] AIXI". I just do not think embedded AIXI represents any sort of limit or idealisation of intelligent systems in the real world [LW · GW].
Alas, I have no better ideas. Speculation on this is welcome.
Cc: @Quintin Pope [LW · GW], @cfoster0 [LW · GW], @beren [LW · GW], @TurnTrout [LW · GW]
- ^
TurnTrout talks about reinforcement learning in the linked post, but I think the argument generalises very straightforwardly to any selection process and the metric of selection.
comment by DragonGod · 2022-12-30T22:35:02.728Z · LW(p) · GW(p)
Adversarial robustness is the wrong frame for alignment.
Robustness to adversarial optimisation is very difficult[1].
Cybersecurity requires adversarial robustness, intent alignment does not.
There's no malicious ghost trying to exploit weaknesses in our alignment techniques.
This is probably my most heretical (and for good reason) alignment take.
It's something dangerous to be wrong about.
I think the only way such a malicious ghost could arise is via mesa-optimisers, but I expect such malicious dameons to be unlikely apriori.
That is, you'll need a training environment that exerts significant selection pressure for maliciousness/adversarialness for the property to arise.
Most capable models don't have malicious daemons[2], so it won't emerge by default.
[1]: Especially if the adversary is a more powerful optimiser than you.
[2]: Citation needed.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2022-12-30T23:17:41.374Z · LW(p) · GW(p)
There seems to be a lot of giant cheesecake fallacy [? · GW] in AI risk. Only things leading up to AGI threshold are relevant to the AI risk faced by humans, the rest is AGIs' problem.
Given current capability of ChatGPT with imminent potential to get it a day-long context window [LW(p) · GW(p)], there is nothing left but tuning, including self-tuning [LW · GW], to reach AGI threshold. There is no need to change anything at all in its architecture or basic training setup to become AGI, only that tuning to get it over a sanity/agency threshold of productive autonomous activity, and iterative batch retraining on new self-written data/reports/research. It could be done much better in other ways, but it's no longer necessary to change anything to get there.
So AI risk is now exclusively about fine tuning of LLMs, anything else is giant cheesecake fallacy, something possible in principle but not relevant now and thus probably ever, as something humanity can influence. Though that's still everything but the kitchen sink, fine tuning could make use of any observations about alignment, decision theory, and so on, possibly just as informal arguments being fed at key points [LW · GW] to LLMs, cumulatively to decisive effect.
comment by DragonGod · 2022-06-22T09:22:56.500Z · LW(p) · GW(p)
What I'm currently working on:
The sequence has an estimated length between 30K - 60K words (it's hard to estimate because I'm not even done preparing the outlines yet).
I'm at ~8.7K words written currently (across 3 posts [the screenshots are my outlines]) and guess I'm only 5% of the way through the entire sequence.
Beware the planning fallacy though, so the sequence could easily grow significantly longer than I currently expect.
I work full time until the end of July and will be starting a Masters in September, so here's to hoping I can get the bulk of the piece completed when I have more time to focus on it in August.
Currently, I try for some significant writing [a few thousand words] on weekends and fill in my outlines on weekdays. I try to add a bit more each day, just continuously working on it, until it spontaneously manifests. I also use weekdays to think about the sequence.
So, the twelve posts I've currently planned could very well have ballooned in scope by the time I can work on it full time.
Weekends will also be when I have the time for extensive research/reading for some of the posts).
comment by DragonGod · 2023-07-24T08:08:16.174Z · LW(p) · GW(p)
Most of the catastrophic risk from AI still lies in superhuman agentic systems.
Current frontier systems are not that (and IMO not poised to become that in the very immediate future).
I think AI risk advocates should be clear that they're not saying GPT-5/Claude Next is an existential threat to humanity.
[Unless they actually believe that. But if they don't, I'm a bit concerned that their message is being rounded up to that, and when such systems don't reveal themselves to be catastrophically dangerous, it might erode their credibility.]
comment by DragonGod · 2023-07-08T20:29:42.739Z · LW(p) · GW(p)
I find noticing surprise more valuable than noticing confusion.
Hindsight bias and post hoc rationalisations make it easy for us to gloss over events that were apriori unexpected.
Replies from: Raemon↑ comment by Raemon · 2023-07-08T20:40:03.577Z · LW(p) · GW(p)
My take on this is that noticing surprise is easier than noticing confusion, and surprise often correlates with confusion so a useful thing to do is have a habit of :
- practice noticing surprise
- when you notice surprise, check if you have a reason to be confused
(Where surprise is "something unexpected happened" and confused is "something is happening that I can't explain, or my explanation of doesn't make sense")
comment by DragonGod · 2023-04-15T12:24:54.391Z · LW(p) · GW(p)
Some Nuance on Learned Optimisation in the Real World
I think mesa-optimisers should not be thought of as learned optimisers, but systems that employ optimisation/search as part of their inference process.
The simplest case is that pure optimisation during inference is computationally intractable in rich environments (e.g. the real world), so systems (e.g. humans) operating in the real world, do not perform inference solely by directly optimising over outputs.
Rather optimisation is employed sometimes as one part of their inference strategy. That is systems only optimise their outputs part of the time (other [most?] times they execute learned heuristics [LW · GW][1]).
Furthermore, learned optimisation in the real world seems to be more "local"/task specific (i.e. I make plans to achieve local, particular objectives [e.g.planning a trip from London to Edinburgh]. I have no global objective that I am consistently optimising for over the duration of my lifetime).
I think this is basically true for any feasible real world intelligent system[2]. So learned optimisation in the real world is:
- Partial[3]
- Local
Do these nuances of real world mesa-optimisers change the nature of risks from learned optimisation?
Cc: @evhub [LW · GW], @beren [LW · GW], @TurnTrout [LW · GW], @Quintin Pope [LW · GW].
- ^
Though optimisation (e.g. planning) might sometimes be employed to figure out which heuristic to deploy at a particular time.
- ^
For roughly the reasons why I think fixed immutable terminal goals are antinatural, see e.g.: "Is "Strong Coherence" Anti-Natural? [LW · GW]"
Alternatively, I believe that real world systems learn contextual heuristics (downstream of historical selection) that influence decision making ("values") [LW · GW] and not fixed/immutable terminal "goals". See also: "why assume AGIs will optimize for fixed goals? [LW · GW]"
- ^
This seems equivalent to Beren's concept of "hybrid optimisation" [LW · GW]; I mostly use "partial optimisation", because it feels closer to the ontology of the Risks From Learned Optimisation paper. As they define optimisation, I think learned algorithms operating in the real world just will not be consistently optimising for any global objective.
↑ comment by Quintin Pope (quintin-pope) · 2023-04-15T21:19:43.449Z · LW(p) · GW(p)
One can always reparameterize any given input / output mapping as a search for the minima of some internal energy function, without changing the mapping at all.
The main criteria to think about is whether an agent will use creative, original strategies to maximize inner objectives, strategies which are more easily predicted by assuming the agent is "deliberately" looking for extremes of the inner objectives, as opposed to basing such predictions on the agent's past actions, e.g., "gather more computational resources so I can find a high maximum".
↑ comment by DragonGod · 2023-04-15T19:53:02.819Z · LW(p) · GW(p)
Given that the optimisation performed by intelligent systems in the real world is local/task specific, I'm wondering if it would be more sensible to model the learned model as containing (multiple) mesa-optimisers rather than being a single mesa-optimiser.
My main reservation is that I think this may promote a different kind of confused thinking; it's not the case that the learned optimisers are constantly competing for influence and their aggregate behaviour determines the overall behaviour of the learned algorithm. Rather the learned algorithm employs optimisation towards different local/task specific objectives.
comment by DragonGod · 2023-02-05T20:48:47.868Z · LW(p) · GW(p)
The Case for Theorems
Why do we want theorems for AI Safety research? Is it a misguided reach for elegance and mathematical beauty? [LW · GW] A refusal to confront the inherently messy and complicated nature of the systems? I'll argue not.
Desiderata for Existential Safety
When dealing with powerful AI systems, we want arguments that they are existentially safe which satisfy the following desiderata:
- Robust to scale [LW · GW]
- Especially robustness to "scaling up"/capability amplification
- Cf. "The Sharp Left Turn [LW · GW]"
- Generalise far out of distribution to test/deployment environments that are unlike our training environments
- We have very high "all things considered [LW · GW]" confidence in
- Failure might imply existential catastrophe, so we may have a small margin of error
- We want arguments that not only tell us the system is existentially safe at high probability, but that we have high confidence that if the argument says obtains given then with very high likelihood actually obtains given
- Translate to successor/derivative systems
- Ideally, we wouldn't want to have to independently verify safety properties for any successor system our system might create (or more likely) derivative systems
- If parent systems are robustly safe and sufficiently capable, we may be able to offload the work of aligning child systems safe to their parents
- Ideally, we wouldn't want to have to independently verify safety properties for any successor system our system might create (or more likely) derivative systems
- Robust to adversarial optimisation?
- I am not actually sure to what extent the safety properties of AI systems need to be adversarially robust to be existentially safe. I think imagining that the system is actively trying to break safety properties is a wrong framing (it conditions on having designed a system that is not safe[1]), and I don't know to what extent strategic interactions in multipolar scenarios would exert adversarial pressure on the systems [LW · GW].
- But I am not very confident in this/it does not seem too implausible to me that adversarial robustness could be a necessary property for existential safety
Given that the preconditions of our theorem actually describe the real world/real world systems well (a non trivial assumption), then theorems and similar formal arguments can satisfy all the above desiderata. Furthermore, it may well be the case that only (semi)formal/rigorous arguments satisfy all the aforementioned desiderata?
Rather, under some plausible assumptions, non rigorous arguments may fail to satisfy any of these desiderata.
When Are Theorems Not Needed?
Rigorous arguments for safety are less compelling in worlds where iterative alignment strategies are feasible.
For example, if takeoff is slow and continuous we may be able to get a wealth of empirical data with progressively more powerful systems and can competently execute on governance strategies.
Civilisation does not often sleep walk into disaster [LW · GW].
In such cases where empirical data is abundant and iterative cycles complete quickly enough (i.e. we develop "good enough" alignment techniques for the next generation of AI systems before such systems are widely deployed), I would be more sympathetic to scepticism of formalism. If empirical data abound, arguments for safety grounded in said data (though all observation is theory laden), would have less meta level uncertainty [LW · GW] than arguments for safety rooted in theory[2].
Closing Remarks
However, in worlds where iterative design fails [LW · GW] (e.g. takeoff is fast or discontinuous), we are unlikely to have an abundance of empirical data and rigorous arguments may be the only viable approach to verify safety of powerful AI systems.
Considering that most of our existential risk is concentrated in world in worlds with fast/discontinuous takeoff (even if the technical problem is intractable in slow/continuous takeoff world, governance approaches have a lot more surface area to execute on to alleviate risk [see my earlier point that civilisation does not sleepwalk into disaster]). As such, technical attempts to reduce risk might have the largest impact by focusing on risk in worlds with fast/discontinuous takeoff.
For that purpose, it seems formal arguments are the best tools we have[3].
If the system is trying/wants to break its safety properties, then it's not safe. A system that is only safe because it's not powerful enough is not robust to scaling up/capability amplification. ↩︎
It's very easy to build theoretical constructs that grow disconnected from reality [LW · GW], and don't quite carve it at the joints. We may be led astray by arguments that don't quite describe real world systems all that well [LW · GW].
When done right, theory is a powerful tool, but it's very easy to do theory wrong; true names [LW · GW] are not often found. ↩︎Theorems are the worst tools for presenting AI safety arguments — except all others that have been tried. ↩︎
↑ comment by DragonGod · 2023-02-05T21:25:57.174Z · LW(p) · GW(p)
Let me know if you think this should be turned into a top level post.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-02-05T21:54:02.673Z · LW(p) · GW(p)
I would definitely like for this to be turned into a top level post, DragonGod.
Replies from: DragonGodcomment by DragonGod · 2025-01-02T10:10:43.633Z · LW(p) · GW(p)
I still want to work on technical AI safety eventually.
I feel like I'm on quite far off path from directly being useful in 2025 than I felt in 2023.
And taking a detour to do a TCS PhD that isn't directly pertinent to AI safety (current plan) feels like not contributing.
Cope is that becoming a strong TCS researcher will make me better poised to contribute to the problem, but short timelines could make this path less viable.
[Though there's nothing saying I can't try to work on AI on the side even if it isn't the focus of my PhD.]
Replies from: DragonGod↑ comment by DragonGod · 2025-01-02T10:23:31.572Z · LW(p) · GW(p)
There is not an insignificant sense of guilt/of betraying myself from 2023 and my ambitions from before.
And I don't want to just end up doing irrelevant TCS research that only a few researchers in a niche field will ever care about.
It's not high impact research.
And it's mostly just settling. I get the sense that I enjoy theoretical research, I don't currently feel poised to contribute to the AI safety problem, I seem to have an unusually good (at least it appears so to my limited understanding) opportunity to pursue a boring TCS PhD in some niche field that few people care about.
I don't think I'll be miserable pursuing the boring TCS PhD or not enjoy it, or anything of the sort. It's just not directly contributing to what I wanted to contribute to. It's somewhat sad and it's undignified (but it's less undignified than the path I thought I was on at various points in the last 15 months).
comment by DragonGod · 2023-04-15T19:12:44.719Z · LW(p) · GW(p)
Mechanistic Utility Maximisers are Infeasible
I've come around to the view that global optimisation for a non-trivial objective function in the real world is grossly intractable, so mechanistic utility maximisers are not actually permitted by the laws of physics[1][2].
My remaining uncertainty around expected utility maximisers as a descriptive model of consequentialist systems is whether the kind of hybrid optimisation (mostly learned heuristics, some local/task specific planning/search) that real world agents perform converges towards better approximating argmax wrt (the expected value of) a simple utility function over agent/environment states.
Excluding exotic phenomena like closed timelike curves, the laws of physics of our universe do not seem to permit the construction of computers that can compute optimal actions to maximise non-trivial utility functions over states of the real world within the lifetime of the universe. ↩︎
I might be wrong on this, I don't know physics. I'm mostly relying on intuitions re: combinatorial explosions and exponential complexity. ↩︎
comment by DragonGod · 2023-02-08T15:10:16.564Z · LW(p) · GW(p)
A crux of my alignment research philosophy:
Our theories of safety must be rooted in descriptive models of the intelligent systems [LW · GW] we're dealing with to be useful at all.
I suspect normative agent foundations research is just largely misguided/mistaken. Quoting myself from my research philosophy draft [LW · GW]:
Furthermore in worlds where there's a paucity of empirical data, I don't actually believe that we can necessarily develop towers of abstraction out of the void and have them remain rooted in reality [LW · GW][16] [LW(p) · GW(p)]. I expect theory developed in the absence of empirical data to validate it to largely just fail to describe reality[17] [LW(p) · GW(p)]. Our theories of safety must be rooted in descriptive models of the intelligent systems we're dealing with to be useful at all.
And the relevant footnotes:
16. You cannot I posit develop an adequate theory of alignment from the null string as input.
17. I do not think there's a simple theory of intelligence that can be derived even in principle from pure computer science (in the limiting case, no intelligence is feasible in max entropic universes).
To what extent is a particular universe learnable? What inductive biases and (hyper)priors are best for learning it? What efficient approximations exist for common algorithmic problems? How well do learning algorithms generalise for common problems? Etc. All seem like empirical questions about the reality we live in. And I expect the answers to these empirical questions to constrain what intelligent systems in our universe look like.
I am pessimistic about normative theories of intelligent systems [LW · GW] that are divorced from the behaviour of intelligent systems in our universe.
E.g. I suspect that expected utility maximisation is anti-natural to generally intelligent behaviour in our universe [LW · GW]. More generally, I suspect large portions of normative agent foundations research would fail to describe the systems that matter in the real world and thus end up being inapplicable/unusable.
This is a crux behind my strong scepticism of theories constructed from void.
comment by DragonGod · 2023-07-22T12:46:08.296Z · LW(p) · GW(p)
Immigration is such a tight constraint for me.
My next career steps after I'm done with my TCS Masters are primarily bottlenecked by "what allows me to remain in the UK" and then "keeps me on track to contribute to technical AI safety research".
What I would like to do for the next 1 - 2 years ("independent research"/ "further upskilling to get into a top ML PhD program") is not all that viable a path given my visa constraints.
Above all, I want to avoid wasting N more years by taking a detour through software engineering again so I can get Visa sponsorship.
[I'm not conscientious enough to pursue AI safety research/ML upskilling while managing a full time job.]
Might just try and see if I can pursue a TCS PhD at my current university and do TCS research that I think would be valuable for theoretical AI safety research.
The main detriment of that is I'd have to spend N more years in <city> and I was really hoping to come down to London.
Advice very, very welcome.
[Not sure who to tag.]
comment by DragonGod · 2023-04-04T14:24:28.648Z · LW(p) · GW(p)
I once claimed that I thought building a comprehensive inside view on technical AI safety was not valuable, and I should spend more time grinding maths/ML/CS to start more directly contributing.
I no longer endorse that view. I've come around to the position that:
- Many alignment researchers are just fundamentally confused about important questions/topics, and are trapped in inadequate ontologies
- Considerable conceptual engineering is needed to make progress
- Large bodies of extant technical AI safety work is just inapplicable to making advanced ML systems existentially safe
Becoming less confused, developing better frames, enriching my ontology, adding more tools to my conceptual toolbox, and just generally thinking clearer about technical AI safety is probably very valuable. Probably more valuable than rushing to try and execute on a technical agenda (that from my current outside view would probably end up being useless).
Most of the progress I've made on becoming a better technical AI safety person this year has been along the lines of trying to think clearer about the problem.
comment by DragonGod · 2023-03-03T00:31:19.311Z · LW(p) · GW(p)
"Foundations of Intelligent Systems" not "Agent Foundations"
I don't like the term "agent foundations" to describe the kind of research I am most interested in, because:
- I am unconvinced that "agent" is the "true name [LW · GW]" of the artifacts that would determine the shape of humanity's long term future
- The most powerful artificial intelligent systems today [LW · GW] do not cleanly fit into the agent ontology,
- Future foundation models are unlikely to cleanly conform to the agent archetype
- Simulators/foundation models may be the first (and potentially final) form of transformative AI; salvation/catastrophe may be realised without the emergence of superhuman general agents
- I worry that foundational theory that conditions too strongly on the agent ontology may end up being of limited applicability to the intelligent systems that would determine the longterm future of earth originating civilisation
- I am persuaded by/sympathetic to composite modular architectures for transformative AI such as Drexler's "Open Agency [LW · GW]" or "Comprehensive AI Services"
- I do not want us to build generally capable strongly autonomous agents [LW · GW]; my best case outcome for AI is for AI to amplify human cognition and capabilities, not to replace/supersede us.
- I believe that cognition can be largely disconnected from volition
- And that in principle, augmented/amplified humans ("cyborgs") can be competitive with superhuman agents
- I find the concept of an aligned sovereign (agent) very uncompelling. It runs counter to my values regarding autonomy and self actualisation. Human enfeeblement would be a tragedy in its own right.
Research paradigms/approaches I see as belonging to "Foundations of Intelligent Systems":
| Theoretical | Empirical | |
| Descriptive |
|
|
| Normative |
| ??? |
Please suggest more!
Replies from: DragonGodcomment by DragonGod · 2023-01-07T14:16:06.883Z · LW(p) · GW(p)
Writing LW questions is much easier than writing full posts.
Replies from: Dagon↑ comment by Dagon · 2023-01-07T20:24:23.305Z · LW(p) · GW(p)
Shhh! This stops working if everyone knows the trick.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T20:26:55.861Z · LW(p) · GW(p)
Why would it stop working?
Replies from: Dagon↑ comment by Dagon · 2023-01-07T20:31:47.234Z · LW(p) · GW(p)
I was at least half joking, but there is some risk that if questions become more prevalent (even if they’re medium-effort good question posts), they will stop getting the engagement that is now available, and it will take more effort to write good ones.
Replies from: DragonGodcomment by DragonGod · 2022-12-25T12:14:35.640Z · LW(p) · GW(p)
Occasionally I see a well received post that I think is just fundamentally flawed, but I refrain from criticising it because I don't want to get downvoted to hell. 😅
This is a failure mode of LessWrong.
I'm merely rationally responding to karma incentives. 😌
Replies from: Viliam, Dagon, Vladimir_Nesov, ChristianKl, Dagon, Slider, T3t↑ comment by Viliam · 2022-12-25T23:49:52.875Z · LW(p) · GW(p)
Huh? What else are you planning to spend your karma on?
Karma is the privilege to say controversial or stupid things without getting banned. Heck, most of them will get upvoted anyway. Perhaps the true lesson here is to abandon the scarcity mindset.
↑ comment by Dagon · 2022-12-26T15:57:53.153Z · LW(p) · GW(p)
[OK, 2 comments on a short shortform is probably excessive. sorry. ]
This is a failure mode of LessWrong.
No, this is a failure mode of your posting strategy. You should WANT some posts to get downvoted to hell, in order to better understand the limits of this group's ability to rationally discuss some topics. Think of cases where you are the local-context-contrarian as bounds on the level of credence to give to the site.
Stay alert. Trust no one. Keep your laser handy.
↑ comment by Vladimir_Nesov · 2022-12-25T15:05:48.998Z · LW(p) · GW(p)
Beliefs/impressions are less useful in communication (for echo chamber reasons) than for reasoning and other decision making, they are importantly personal things. Mostly not being worth communicating doesn't mean they are not worth maintaining in a good shape. They do influence which arguments that stand on their own are worth communicating, but there aren't always arguments that allow communicating relevant beliefs themselves.
↑ comment by ChristianKl · 2022-12-26T13:22:19.565Z · LW(p) · GW(p)
I don't think the fact that a post is well-received is alone reason that criticism gets downvoted to hell. Usually, quality criticism can get upvoted even if a post is well received.
Replies from: DragonGod↑ comment by DragonGod · 2022-12-26T13:41:26.020Z · LW(p) · GW(p)
The cases I have in mind are where I have substantial disagreements with the underlying paradigm/worldview/framework/premises on which the post rests on to the extent that I think the post is basically completely worthless.
For example Kokotaljo's "What 2026 Looks Like?"; I think elaborate concrete predictions of the future are not only nigh useless but probably net negative for opportunity cost/diverted resources (including action) reasons.
My underlying arguments are extensive, but are not really about the post itself, but the very practice/exercise of writing elaborate future vignettes. And I don't have the energy/motivation to draft up said substantial disagreements into a full fledged essay.
Replies from: ChristianKl↑ comment by ChristianKl · 2022-12-26T18:36:37.840Z · LW(p) · GW(p)
If you call a post a prediction that's not a prediction, then you are going to be downvoted. Nothing wrong with that.
He called his goal "The goal is to write out a detailed future history (“trajectory”) that is as realistic (to me) as I can currently manage, i.e. I’m not aware of any alternative trajectory that is similarly detailed and clearly more plausible to me."
That's scenario planning, even if he only provides one scenario. He doesn't provide any probabilities in the post so it's not a prediction. Scenario planning is different than how we at LessWrong usually approach the future with prediction but scenario planning matters for how a lot of powerful institutions in the world orient themselves about the future.
Having a scenario like that allows someone at the department of defense to say: Let's do a wargame for this scenario. You might say "It's bad that the department of defense uses wargames to think about the future" but in the world, we live in they do.
Replies from: DragonGod↑ comment by DragonGod · 2022-12-26T18:41:10.966Z · LW(p) · GW(p)
I additionally think the scenario is very unlikely. So unlikely that wargaming for that scenario is only useful insomuch as your strategy is general enough to apply to many other scenarios.
Wargaming for that scenario in particular is privileging a hypothesis that hasn't warranted it.
The scenario is very unlikely on priors and its 2022 predictions didn't quite bear out.
Replies from: ChristianKl↑ comment by ChristianKl · 2022-12-26T20:33:06.780Z · LW(p) · GW(p)
Part of the advantage of being specific about 2022 and 2023 is that it allows people to update on it toward taking the whole scenario more or less seriously.
Replies from: DragonGod↑ comment by DragonGod · 2022-12-26T21:06:34.182Z · LW(p) · GW(p)
I didn't need to see 2022 to know that the scenario would not be an accurate description of reality.
On priors that was just very unlikely.
Replies from: ChristianKl↑ comment by ChristianKl · 2022-12-26T21:41:00.962Z · LW(p) · GW(p)
Having scenarios that are unlikely based on priors means that you can update more if they turn out to go that way than scenarios that you deemed to be likely to happen anyway.
↑ comment by Dagon · 2022-12-25T23:05:02.064Z · LW(p) · GW(p)
I don't think this is necessarily true. I disagree openly on a number of topics, and generally get slightly upvoted, or at least only downvoted a little. In fact, I WANT to have some controversial comments (with > 10 votes and -2 < karma < 10), or I worry that I'm censoring myself.
The times I've been downvoted to hell, I've been able to identify fairly specific reasons, usually not just criticizing, but criticizing in an unhelpful way.
↑ comment by RobertM (T3t) · 2022-12-26T05:14:22.920Z · LW(p) · GW(p)
I'd be surprised if this happened frequently for good criticisms.
comment by DragonGod · 2023-03-05T14:00:13.185Z · LW(p) · GW(p)
Contrary to many LWers, I think GPT-3 was an amazing development for AI existential safety.
The foundation models paradigm is not only inherently safer than bespoke RL on physics, the complexity [? · GW]and fragility of value [LW · GW] problems are basically solved for free.
Language is a natural interface for humans, and it seems feasible to specify a robust constitution in natural language?
Constitutional AI seems plausibly feasible, and like it might basically just work?
That said I want more ambitious mechanistic interpretability of LLMs, and to solve ELK for tighter safety guarantees, but I think we're in a much better position now than I thought in 2017.
comment by DragonGod · 2023-01-08T09:07:00.083Z · LW(p) · GW(p)
My best post was a dunk on MIRI[1], and now I've written up another point of disagreement/challenge to the Yudkowsky view.
There's a part of me that questions the opportunity cost of spending hours expressing takes of mine that are only valuable because they disagree in a relevant aspect with a MIRI position? I could have spent those hours studying game theory or optimisation.
I feel like the post isn't necessarily raising the likelihood of AI existential safety?
I think those are questions I should ask more often before starting on a new LessWrong post; "how does this raise the likelihood of AI existential safety? By how much? How does it compare to my other post ideas/unfinished drafts?"
Maybe I shouldn't embark on a writing project until I have (a) compelling narrative(s) for why my writing would be useful/valuable for my stated ends.
- ^
This is an uncharitable framing of the post, but it is true that the post was written from a place of annoyance. It's also true that I have many important disagreements with the Yudkowsky-Soares-Bensinger position, and expressing them is probably a valuable epistemic service.
↑ comment by 1a3orn · 2023-01-08T19:34:21.574Z · LW(p) · GW(p)
Generally, I don't think it's good to gate "is subquestion X, related to great cause Y, true?" with questions about "does addressing this subquestion contribute to great cause Y?" Like I don't think it's good in general, and don't think it's good here.
I can't justify this in a paragraph, but I'm basing this mostly of "Huh, that's funny" being far more likely to lead to insight than "I must have insight!" Which means it's a better way of contributing to great causes, generally.
(And honestly, at another level entirely, I think that saying true things, which break up uniform blocks of opinion on LW, is good for the health of the LW community.)
Edit: That being said, if the alternative to following your curiosity on one thing is like, super high value, ofc it's better. But meh, I mean I'm glad that post is out there. It's a good central source for a particular branch of criticism, and I think it helped me understand the world more.
comment by DragonGod · 2022-10-28T12:56:36.307Z · LW(p) · GW(p)
A Sketch of a Formalisation of Self Similarity
Introduction
I'd like to present a useful formalism for describing when a set[1] is "self-similar".
Isomorphism Under Equivalence Relations
Given arbitrary sets , an "equivalence-isomorphism" is a tuple , such that:
Where:
- is a bijection from to
- is the inverse of
- is an equivalence relation on the union of and .
For a given equivalence relation , if there exist functions such that an equivalence-isomorphism can be constructed, then we say that the two sets are "isomorphic under ".
The concept of "isomorphism under an equivalence relation" is meant to give us a more powerful mechanism for describing similarity/resemblance between two sets than ordinary isomorphisms afford[2].
Similarity
Two sets are "similar" if they are isomorphic to each other under a suitable equivalence relation[3].
Self-Similarity
A set is "self-similar" if it's "similar" to a proper subset of itself.
Closing Remarks
This is deliberately quite bare, but I think it's nonetheless comprehensive enough (any notion of similarity we desire can be encapsulated in our choice of equivalence relation) and unambiguous given an explicit specification of the relevant equivalence relation.
- ^
I stuck to sets because I don't know any other mathematical abstractions well enough to play around with them in interesting ways.
- ^
Ordinarily, two sets are isomorphic to each other if a bijection exists between them (they have the same cardinality). This may be too liberal/permissive for "similarity".
By choosing a sufficiently restrictive equivalence relation (e.g., equality), we can be as strict as we wish.
- ^
Whatever notion of similarity we desire is encapsulated in our choice of equivalence relation.
↑ comment by Vladimir_Nesov · 2022-10-28T21:24:38.893Z · LW(p) · GW(p)
For a given , let be its set of equivalence classes. This induces maps and . The isomorphism you discuss has the property . Maps like that are the morphisms in the slice category over , and these isomorphisms are the isomorphisms in that category. So what happened is that you've given and the structure of a bundle, and the isomorphisms respect that structure.
comment by DragonGod · 2023-04-25T13:34:04.565Z · LW(p) · GW(p)
A reason I mood affiliate with shard theory so much is that like...
I'll have some contention with the orthodox ontology for technical AI safety and be struggling to adequately communicate it, and then I'll later listen to a post/podcast/talk by Quintin Pope/Alex Turner, or someone else trying to distill shard theory and then see the exact same contention I was trying to present expressed more eloquently/with more justification.
One example is that like I had independently concluded that "finding an objective function that was existentially safe when optimised by an arbitrarily powerful optimisation process is probably the wrong way to think about a solution to the alignment problem".
And then today I discovered that Alex Turner advances a similar contention in "Inner and outer alignment decompose one hard problem into two extremely hard problems".
Shard theory also seems to nicely encapsulates my intuitions that we shouldn't think about powerful AI systems as optimisation processes with a system wide objective that they are consistently pursuing.
Or just the general intuitions that our theories of intelligent systems should adequately describe the generally intelligent systems we actually have access to and that theories that don't even aspire to do that are ill motivated.
It is the case that I don't think I can adequately communicate shard theory to a disbeliever, so on reflection there's some scepticism that I properly understand it.
That said, the vibes are right.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-04-26T00:34:04.601Z · LW(p) · GW(p)
My main critique of shard theory is that I expect one of the shards to end up dominating the others as the most likely outcome.
Replies from: Nate Showell↑ comment by Nate Showell · 2023-04-26T03:05:15.190Z · LW(p) · GW(p)
Even though that doesn't happen in biological intelligences?
comment by DragonGod · 2023-04-18T15:51:32.186Z · LW(p) · GW(p)
Consequentialism is in the Stars not Ourselves?
Still thinking about consequentialism and optimisation. I've argued that global optimisation for an objective function is so computationally intractable as to be prohibited by the laws of physics of our universe [LW(p) · GW(p)]. Yet it's clearly the case that e.g. evolution is globally optimising for inclusive genetic fitness (or perhaps patterns that more successfully propagate themselves if you're taking a broader view). I think examining why evolution is able to successfully globally optimise for its objective function would be enlightening.
Using the learned optimisation ontology, we have an outer selection process (evolution, stochastic gradient descent, etc.) that selects intelligent systems according to their performance on a given metric (inclusive genetic fitness and loss respectively).
Local vs Global Optimisation
Optimisation here refers to "direct" optimisation [LW · GW], a mechanistic procedure for internally searching through an appropriate space for elements that maximise or minimise the value of some objective function defined on that space.
Local Optimisation
- Involves deploying optimisation (search, planning, etc.) to accomplish specific tasks (e.g., making a good move in chess, winning a chess game, planning a trip, solving a puzzle).
- The choice of local tasks is not determined as part of this framework; local tasks could be subproblems of a another optimisation problem (e.g. picking a good next move as part of winning a chess game), generated via learned heuristics, etc.
Global Optimisation
- Entails consistently employing optimisation throughout a system's active lifetime to achieve fixed terminal goals.
- All actions flow from their expected consequences on realising the terminal goals (e.g., if a terminal goal is to maximise the number of lives saved, every activity—eating, sleeping, playing, working—is performed because it is the most tractable way to maximise the expected number of future lives saved at that point in time).
Outer Optimisation Processes as Global Optimisers
As best as I can tell, there are some distinctive features of outer optimisation processes that facilitate global optimisation:
Access to more compute power
- ML algorithms are trained with significantly (often orders of magnitude) more compute than is used for running inference due in part to economic incentives
- Economic incentives favour this: centralisation of ML training allows training ML models on bespoke hardware in massive data centres, but the models need to be cheap enough to run profitably
- Optimising inference costs has lead to "overtraining" smaller models
- In some cases trained models are intended to be run on consumer hardware or edge computing devices
- Economic incentives favour this: centralisation of ML training allows training ML models on bespoke hardware in massive data centres, but the models need to be cheap enough to run profitably
- Evolutionary processes have access to the cumulative compute power of the entire population under selection, and they play out across many generations of the population
- This (much) greater compute allows outer optimisation processes to apply (many?) more bits of selection towards their objective functions
Relaxation of time constraints
- Real-time inference imposes a strict bound on how much computation can be performed in a single time step
- Robotics, self driving cars, game AIs, etc. must make actions within fractions of a second
- Sometimes hundreds of actions in a second
- User facing cognitive models (e.g.) LLMs are also subject to latency constraints
- Though people may be more willing to wait longer for responses if the output of the models are sufficiently better
- Robotics, self driving cars, game AIs, etc. must make actions within fractions of a second
- In contrast, the outer selection process just has a lot more time to perform optimisation
- ML training runs already last several months, and the only bound on length of training runs seems to be hardware obsolescence
- For sufficiently long training runs, it becomes better to wait for the next hardware generation before starting training
- Training runs exceeding a year seem possible eventually, especially if loss keeps going down with scale
- Evolution occurs over timescales of hundreds to thousands of generations of an organism
- ML training runs already last several months, and the only bound on length of training runs seems to be hardware obsolescence
Solving a (much) simpler optimisation problem
- Outer optimisation processes evaluate the objective function by using actual consequences along single trajectories for selection, as opposed to modeling expected consequences across multiple future trajectories and searching for trajectories with better expected consequences.
- Evaluating future consequences of actions is difficult (e.g., what is the expected value of writing this LessWrong shortform on the number of future lives saved?)
- Chaos sharply limits how far into the future we can meaningfully predict (regardless of how much computational resources one has), which is not an issue when using actual consequences for selection
- In a sense, outer optimisation processes get the "evaluate consequences of this trajectory on the objective" for free, and that's just a very difficult (and in some cases outright intractable) computational problem
- The usage of actual consequences applies over longer time horizons
- Evolution has a potentially indefinite/unbounded horizon
- And has been optimising for much longer than any
- Current ML training generally operates with fixed-length horizons but uses actual/exact consequences of trajectories over said horizons.
- Evolution has a potentially indefinite/unbounded horizon
- Outer optimisation processes selects for a policy that performs well according to the objective function on the training distribution, rather than selecting actions that optimise an objective function directly in deployment.
Summary
Outer optimisation processes are more capable of global optimisation due to their access to more compute power, relaxed time constraints, and just generally facing a much simpler optimisation problem (evaluations of exact consequences are provided for free [and over longer time horizons], amortisation of optimisation costs, etc).
These factors enable outer optimisation processes to globally optimise for their selection metric in a way that is infeasible for the intelligent systems they select for.
Cc: @beren [LW · GW], @tailcalled [LW · GW], @Chris_Leong [LW · GW], @JustisMills [LW · GW].
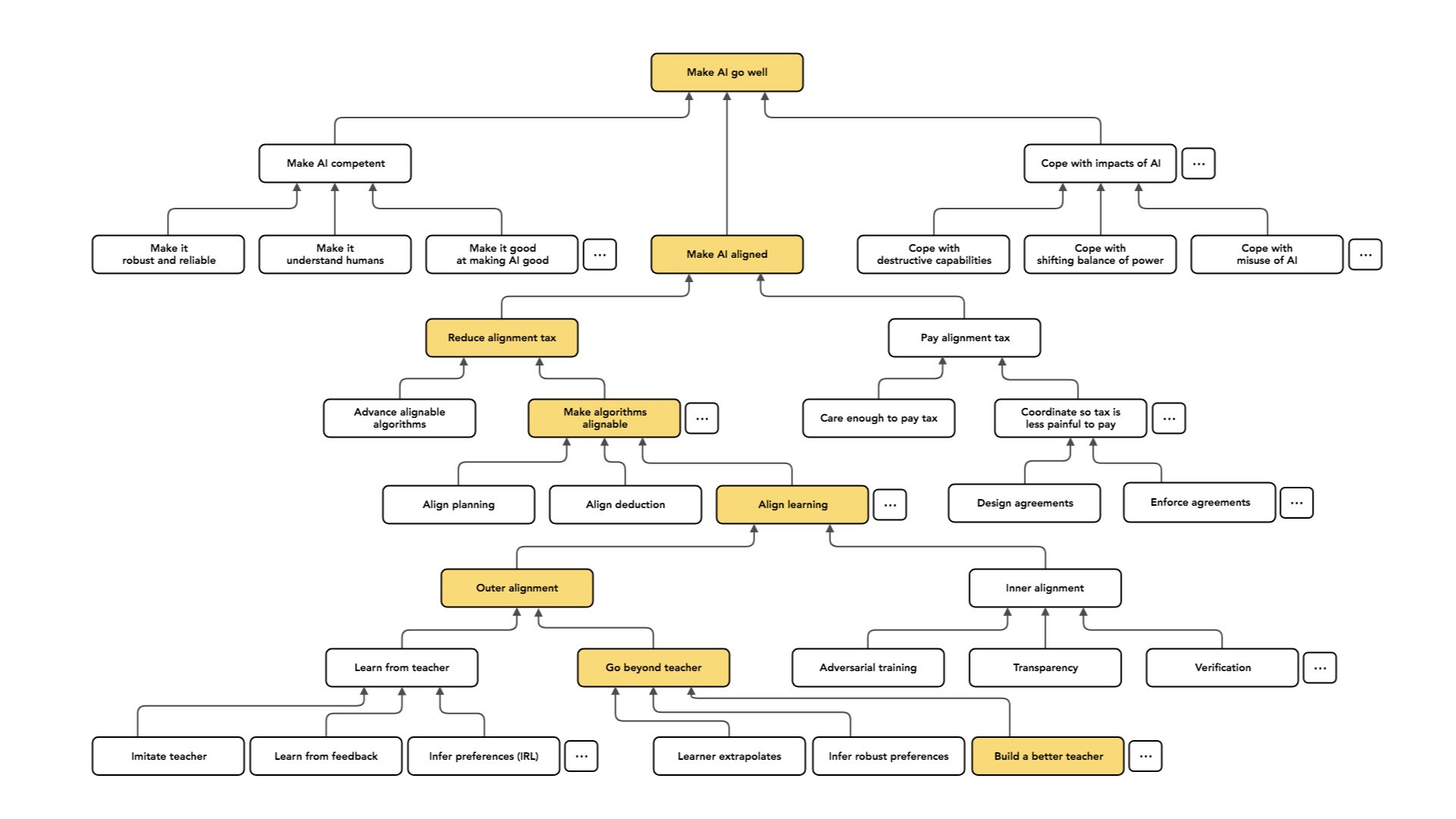
comment by DragonGod · 2023-02-13T13:49:15.733Z · LW(p) · GW(p)
"Is intelligence NP hard?" is a very important question with too little engagement from the LW/AI safety community. NP hardness:
- Bounds attainable levels of intelligence (just how superhuman is superintelligence?)
- Bounds physically and economically feasible takeoff speeds (i.e. exponentially growing resource investment is required for linear improvements in intelligence)
I'd operationalise "is intelligence NP hard?" as:
Does there exist some subset of computational problems underlying core cognitive tasks that have NP hard [expected] (time) complexity?
I want to write a LW question post on this sometime.
For now, I want to learn more about complexity theory and let my thoughts on the complexity of intelligence gestate further.
Gwern's "Complexity no Bar to AI" argues convincingly that complexity theory doesn't prohibit AGI/superhuman AI, but not that:
- The attainable level of intelligence is as far above humans as humans are above ants (or other animal of choice)
- Fast takeoff is feasible
As best as I can tell (I didn't finish it, but will reread it after I'm done with my current complexity paper) Gwern did not argue convincingly that intelligence is not NP hard.
↑ comment by Steven Byrnes (steve2152) · 2023-02-13T16:32:52.719Z · LW(p) · GW(p)
One question is: “Can a team of one hundred 10×-sped-up John von Neumann-level intelligent agents, running on computer chips and working together, wipe out humanity if they really wanted to?” It’s an open question, but I really think the answer is “yes” because (blah blah pandemics crop diseases nuclear war etc.—see here [LW · GW]). I don’t think NP-hardness matters. You don’t need to solve any NP-hard problems to make and release 20 pandemics simultaneously, that’s a human-level problem, or at least in the ballpark of human-level.
And then another question is: “How many 10×-sped-up John von Neumann-level intelligent agents can you get from the existing stock of chips in the world?” That’s an open question too. I wrote this post [LW · GW] recently on the topic. (Note the warning at the top; I can share a draft of the follow-up-post-in-progress, but it won’t be done for a while.) Anyway I’m currently expecting “hundreds of thousands, maybe much more”, but reasonable people can disagree. If I’m right, then that seems more than sufficient for a fast takeoff argument to go through, again without any speculation about what happens beyond human-level intelligence.
And then yet another question is: “Might we program an agent that's much much more ‘insightful’ than John von Neumann, and if so, what real-world difference will that extra ‘insight’ make?” OK, now this is much more speculative. My hunch is “Yes we will, and it will make a very big real-world difference”, but I can’t prove that. I kinda think that if John von Neumann could hold even more complicated ideas in his head, then he would find lots of low-hanging-to-him fruit in developing powerful new science & technology. (See also brief discussion here [LW · GW].) But anyway, my point is, I’m not sure much hinges on this third question, because the previous two questions seem sufficient for practical planning / strategy purposes.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-13T17:33:38.268Z · LW(p) · GW(p)
To be clear, I don't think the complexity of intelligence matters for whether we should work on AI existential safety, and I don't think it guarantees alignment by default.
I think it can confer longer timelines and/or slower takeoff, and both seem to reduce P(doom) but mostly by giving us more time to get our shit together/align AI.
I do think complexity of intelligence threatens Yudkowskian foom, but that's not the only AI failure mode.
↑ comment by porby · 2023-02-13T20:37:16.683Z · LW(p) · GW(p)
A chunk of why my timelines are short [LW · GW]involves a complexity argument:
- Current transformer-based LLMs, by virtue of always executing the same steps to predict the next token, run in constant time.
- Our current uses of LLMs tend to demand a large amount of "intelligence" within the scope of a single step- sequence of English tokens are not perfectly natural representations of complex reasoning, and many prompts attempt to elicit immediate answers to computationally difficult questions (consider prompting an LLM with "1401749 * 23170802 = " without any kind of chain of thought or fine tuning).
- Our current uses of LLMs are still remarkably capable within this extremely harsh limitation, and within the scope of how we're using them.
This seems like really strong empirical evidence that a lot of the kind of intelligence we care about is not just not NP-hard, but expressible in constant time.
In this framing, I'm basically quantifying "intelligence" as something like "how much progress is made during each step in the algorithm of problem solving." There may exist problems that require non-constant numbers of reasoning steps, and the traditional transformer LLM is provably incapable of solving such problems in one token prediction (e.g. multiplying large integers), but this does not impose a limitation on capabilities over a longer simulation.
I suspect there are decent ways of measuring the complexity of the "intelligence" required for any particular prediction, but it's adjacent to some stuff that I'm not 100% comfy with signal boosting publicly- feel free to DM me if interested.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-13T22:43:10.656Z · LW(p) · GW(p)
Current transformer-based LLMs, by virtue of always executing the same steps to predict the next token, run in constant time.
I'm suspicious of this. It seems obviously not true on priors, and like an artifact of:
- Choosing a large enough constant
- Fixed/bounded input sizes
But I don't understand well how a transformer works, so I can't engage this on the object level.
Replies from: porby↑ comment by porby · 2023-02-13T23:19:18.658Z · LW(p) · GW(p)
You're correct that it arises because we can choose a large enough constant (proportional to parameter count, which is a constant with respect to inference), and because we have bounded context windows. Not all large language models must be constant time, nor are they.
The concerning part is that all the big name ones I'm aware of are running in constant time (per token) and still manage to do extremely well. Every time we see some form of intelligence expressed within a single token prediction on these models, we get a proof that that kind of intelligence is just not very complicated.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-13T23:47:40.576Z · LW(p) · GW(p)
I just don't intuitively follow. It violates my intuitions about algorithms and complexity.
- Does this generalise? Would it also be constant time per token if it was generating outputs a million tokens long?
- Does the time per token vary with the difficulty of the prediction task? Not all prediction tasks should be equally difficult, so if cost doesn't vary, that also warrants explanation.
I just don't buy the constant time hypothesis/formulation. It's like: "if you're getting that result, you're doing something illegitimate or abusing the notion of complexity".
Constant time per token generalising asymptotically becomes linear complexity, and there are problems that we know are worse than linear complexity. It's like this result just isn't plausible?
Replies from: porby↑ comment by porby · 2023-02-14T00:28:37.641Z · LW(p) · GW(p)
Does this generalise? Would it also be constant time per token if it was generating outputs a million tokens long?
Yes, if you modified the forward pass to output a million tokens at once, it would remain constant time so long as the forward pass's execution remained bounded by a constant. Likewise, you could change the output distribution to cover tokens of extreme length. Realistically, the architecture wouldn't be practical. It would be either enormous and slow or its predictions would suck.
Does the time per token vary with the difficulty of the prediction task? Not all prediction tasks should be equally difficult, so if cost doesn't vary, that also warrants explanation.
No, a given GPT-like transformer always does exactly the same thing in the forward pass. GPT-3 does not have any kind of adaptive computation time within a forward pass. If a single token prediction requires more computation steps than fits in the (large) constant time available to the forward pass, the transformer cannot fully complete the prediction. This is near the core of the "wait what" response I had to GPT-3's performance.
Note that when you prompt GPT-3 with something like "1401749 x 23170802 = ", it will tend to give you a prediction which matches the shape of the answer (it's a number, and a fairly big one), but beyond the rough approximation, it's pretty much always going to be wrong. Even if you fine-tuned GPT-3 on arithmetic, you would still be able to find two integers of sufficient size that they cannot be multiplied in one step because the number internal steps required exceeds the number of steps the forward pass can express.
The output distribution will cover a wide smear of tokens corresponding to approximately-correct big numbers. It can't compute which one is right, so the probability distribution can't narrow any further.
(Raw GPT-3 also isn't interested in being correct except to the extent that being correct corresponds to a good token prediction, so it won't bother with trying to output intermediate tokens that could let it perform a longer non-constant-time computation. The prompt makes it look like the next token should be an answer, not incremental reasoning, so it'll sample from its smear of answer-shaped tokens.)
"if you're getting that result, you're doing something illegitimate or abusing the notion of complexity"
It can feel that way a bit due to the scale- like it's technically true but meaningless, maybe- but it is directly visible in their behavior, and it has major implications for how these things could advance. The constants were talking about here aren't actually so pathological that they make the analysis pointless; a quadrillion flops isn't that many compared to an H100's throughput.
It's like this result just isn't plausible?
If I had to guess, that feeling is probably arising from how I'm using the word "intelligence" in the context of a single forward pass, while it sounds like you're using the word to describe something more like... the capability of the model over a full simulation that takes many forward passes to complete. The latter is not bound by constant time even in the LLMs I'm talking about, but I think the capabilities exhibited in constant time by current LLMs are sufficient to think that huge chunks of "whatever is the thing we care about when we talk about intelligence" are actually pretty darn easy, computationally.
Replies from: leogao↑ comment by leogao · 2023-02-14T06:41:22.219Z · LW(p) · GW(p)
For all practical purposes, it takes O(N+M) compute to generate N tokens from an M token context (attention is superlinear, but takes up a negligible proportion of flops in current models at the context lengths that current models are trained for. also, while nobody has succeeded at it yet, linear attention does not seem implausible). No current SOTA model has adaptive compute. There has been some work in this direction (see Universal transformers), but it doesn't work well enough for people to use it in practice.
Replies from: porby↑ comment by porby · 2023-02-14T18:35:07.201Z · LW(p) · GW(p)
For all practical purposes, it takes O(N+M) compute to generate N tokens from an M token context
Yup. I suspect that's close to the root of the confusion/apparent disagreement earlier- when I say constant time, I mean constant with respect to input, given a particular model and bounded context window, for a single token.
I think doing the analysis at this level is often more revealing than doing the analysis across full trajectories or across arbitrary windows in an important way: a tight bound makes it easier to make claims about what's possible by existence proof (which turns out to be a lot).
↑ comment by Dagon · 2023-02-13T14:40:50.193Z · LW(p) · GW(p)
Without knowing the actual optimal curve of computational cost per "unit" of intelligence (and WTF that even means), it's not too useful to know whether it's polynomial or not. There are LOTS of np-hard problems that humans have "solved" numerically or partially for real-world uses, at scales that are economically important. They don't scale perfectly, and they're often not provably optimal, but they work.
It's hard to figure out the right metrics for world-modeling-and-goal-optimization that would prevent AGI from taking over or destroying most value for biological agents, and even harder to have any clue whether the underlying constraint being NP-hard matters at all in the next milleneum. It probably WILL matter at some point, but it could be 3 or 4 takeovers or alien-machine-intelligence-discoveries away.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-13T14:57:53.834Z · LW(p) · GW(p)
There are LOTS of np-hard problems that humans have "solved" numerically or partially for real-world uses, at scales that are economically important. They don't scale perfectly, and they're often not provably optimal, but they work.
These are part of the considerations I would address when I get around to writing the post.
- Empirical probability distributions over inputs
- Weighting problems by their economic importance
- Approximate solutions
- Probabilistic solutions
- Etc.
All complicate the analysis (you'd probably want a framework for determining complexity that natively handled probabilistic/approximate solutions, so maybe input size in bits and "work done by optimisation in bits"), but even with all these considerations, you can still define a coherent notion of "time complexity".
Replies from: DragonGodcomment by DragonGod · 2023-01-06T22:06:22.546Z · LW(p) · GW(p)
I'm finally in the 4-digit karma club! 🎉🎉🎉
(Yes, I like seeing number go up. Playing the LW karma game is more productive than playing Twitter/Reddit or whatever.
That said, LW karma is a very imperfect proxy for AI safety contributions (not in the slightest bit robust to Goodharting) and I don't treat it as such. But insomuch as it keeps me engaged with LW, it keeps me engaged with my LW AI safety projects.
I think it's a useful motivational tool for the very easily distracted me.)
comment by DragonGod · 2022-12-28T22:12:08.199Z · LW(p) · GW(p)
My most successful post [LW · GW] took me around an hour to publish and already has 10x more karma than a post that took me 10+ hours to publish [LW · GW].
There's a certain unfairness about it. The post isn't actually that good. I was just ranting about something that annoyed me.
I'm bitter about its success.
There's something profoundly soul crushing to know that the piece I'm pouring my soul into right now wouldn't be that well received.
Probably by the time I published it I'll have spent days on the post.
And that's just so depressing. So, so depressing.
comment by DragonGod · 2022-06-25T13:36:39.416Z · LW(p) · GW(p)
Twitter Cross Posting
Introduction
I'll start reposting threads from my Twitter account to LW with no/minimal editing.
Twitter Relevant Disclaimers
I've found that Twitter incentivises me to be
More:
- Snarky
- Brazen
- Aggressive
- Confident
- Exuberant
Less:
- Nuanced
- Modest
The overall net effect is that content written originally for Twitter has predictably low epistemic standards compared to content I'd write for LessWrong. However, trying to polish my Twitter content for LessWrong takes too much effort (my takeoff dynamics sequence [currently at 14 - 16 posts] [LW(p) · GW(p)] started as an attempt to polish my takeoff dynamics thread for a LW post).
As I think it's better to write than to not write [LW(p) · GW(p)], I've decided to publish my low-quality-but-still-LessWrong-relevant Twitter content here with no/minimal editing. I hedge against the predictably low quality by publishing it as shortform/to my personal blog instead of to the front page.
Testing
I'll post the unedited/minimally edited threads as both blog posts (promotion to front page disabled) and shortform pieces. I'll let the reception to the posts in both venues decide which one I'll keep with going forward. I'll select positively for:
- Visibility
- Engagement
And negatively against:
- Hostility
- Annoyance
comment by DragonGod · 2022-06-13T02:02:05.627Z · LW(p) · GW(p)
I'll Write
It is better to write than to not write.
Perfect should not be the enemy of good.
If I have a train of thought that crosses a thousand words when written out, I'm no longer going to consider waiting until I've extensively meditated upon, pondered, refined and elaborated on that train of thought until it forms a coherent narrative that I deeply endorse.
I'll just post the train of thought as is.
If necessary, I'll repeatedly and iteratively improve on the written train of thought to get closer to a version that I'll deeply endorse. I'll not wait for that final version that may never arrive.
Since I became active again, I have yet to have a single coherent narrative that I "deeply endorse". I anticipate that it will take me several weeks to a few months of dedicated thinking and writing on my topics of interests to get something of that quality.
But I'm sceptical I can stay on the same topic for that long given my (crippling) executive dysfunction. I'll just do what I can within the limits of my ability.
Replies from: Purged Deviator↑ comment by Purged Deviator · 2022-06-13T13:54:06.376Z · LW(p) · GW(p)
That's what I use this place for, an audience for rough drafts or mere buddings of an idea. (Crippling) Executive dysfunction sounds like it may be a primary thing to explore & figure out, but it also sounds like the sort of thing that surrounds itself with an Ugh Field very quickly. Good luck!
Replies from: DragonGodcomment by DragonGod · 2023-02-07T21:33:55.992Z · LW(p) · GW(p)
Unpublished my "Why Theorems? A Brief Defence [LW · GW]" post.
The post has more than doubled in length and scope creep is in full force.
I kind of want to enhance it to serve as the definitive presentation of my "research tastes"/"research vibes".
↑ comment by harfe · 2023-02-07T22:00:01.362Z · LW(p) · GW(p)
As a commenter on that post, I wish you hadn't unpublished it. From what I remember, you had stated that it was written quickly and for that reason I am fine with it not being finished/polished. If you want to keep working on the post, maybe you can make a new post once you feel you are done with the long version.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-07T22:10:49.135Z · LW(p) · GW(p)
I mean the published version had already doubled in length and it was no longer "written quickly" (I had removed the epistemic disclaimer already and renamed it to: "Why Theorems? A Personal Perspective [LW · GW]".)
[Though the proximate cause of unpublishing was that I originally wrote the post on mobile (and hence in the markdown editor) and it was a hassle to expand/extend it while on mobile. I was directed to turn it to a draft while chatting with site staff to get help migrating it to the rich text editor.]
I was initially planning to keep it in drafts until I finished working on it. I can republish it in an hour or two once I'm done with my current editing pass if you want.
comment by DragonGod · 2023-02-06T04:25:33.231Z · LW(p) · GW(p)
Hypothesis: any learning task can be framed as a predictive task[1]; hence, sufficiently powerful predictive models can learn anything.
A comprehensive and robust model of human preferences can be learned via SSL with a target of minimising predictive error on observed/recorded behaviour.
This is one of those ideas that naively seem like they basically solve the alignment problem, but surely it can't be that easy.
Nonetheless recording this to come back to it after gitting gud at ML.
Potential Caveats
Maybe "sufficiently powerful predictive models" is doing a lot of heavy lifting.
Plausible the "irreducible entropy" in our records of human behaviour prevent learning values well (I don't actually believe this).
Perhaps the dataset size required to get a sufficiently robust/comprehensive model is too large?
Another concern is the potential of mindcrime.
I don't think this hypothesis is original to me, and I expect I learned it from "Introduction to reinforcement learning by Hado van Hasselt". (If not this particular video, then the second one in that series.) ↩︎
↑ comment by [deleted] · 2023-02-06T04:28:42.030Z · LW(p) · GW(p)
Isn't prediction a subset of learning?
Replies from: DragonGod↑ comment by DragonGod · 2023-02-06T04:38:01.707Z · LW(p) · GW(p)
Yeah, I think so.
I don't see this as necessarily refuting the hypothesis?
Replies from: None↑ comment by [deleted] · 2023-02-06T05:01:09.409Z · LW(p) · GW(p)
No, it sounded like tautology to me, so I wasn't sure what it's trying to address.
Replies from: DragonGodcomment by DragonGod · 2023-01-02T05:30:46.547Z · LW(p) · GW(p)
Me: Mom can we have recursive self improvement?
Mom: we already have recursive self improvement at home.
Recursive self improvement at home:
https://www.lesswrong.com/posts/camG6t6SxzfasF42i/a-year-of-ai-increasing-ai-progress [LW · GW]
comment by DragonGod · 2022-12-21T01:03:09.540Z · LW(p) · GW(p)
Discussion Questions
I'm to experiment with writing questions more frequently.
There are several topics I want to discuss here, but which I don't yet have substantial enough thoughts to draft up a full fledged post for.
Posing my thoughts on the topic as a set of questions and soliciting opinions seems a viable approach.
I am explicitly soliciting opinions in such questions, so do please participate even if you do not believe your opinion to be particularly informed.
comment by DragonGod · 2022-06-03T19:18:31.897Z · LW(p) · GW(p)
Ruminations on the Hardness of Intelligence
Sequel to my first stab at the hardness of intelligence [LW · GW].
I'm currently working my way through "Intelligence Explosion Microeconomics". I'm actively thinking as I read the paper and formulating my own thoughts on "returns on cognitive reinvestment".
I have a Twitter thread where I think out loud on this topic.
I'll post the core insights from my ramblings here.
@Johnswentworth, @Rafael Harth.
Replies from: DragonGod, DragonGod, DragonGod, DragonGod, DragonGod

comment by DragonGod · 2023-07-25T20:30:29.625Z · LW(p) · GW(p)
Probably sometime last year, I posted on Twitter something like: "agent values are defined on agent world models" (or similar) with a link to a LessWrong post (I think the author was John Wentworth).
I'm now looking for that LessWrong post.
My Twitter account is private and search is broken for private accounts, so I haven't been able to track down the tweet. If anyone has guesses for what the post I may have been referring to was, do please send it my way.
Replies from: Darcy↑ comment by Dalcy (Darcy) · 2023-07-25T20:38:51.809Z · LW(p) · GW(p)
The Pointers Problem: Human Values Are A Function Of Humans' Latent Variables [LW · GW]
Replies from: DragonGodcomment by DragonGod · 2023-07-10T18:20:04.726Z · LW(p) · GW(p)
Does anyone know a ChatGPT plugin for browsing documents/webpages that can read LaTeX?
The plugin I currently use (Link Reader) strips out the LaTeX in its payload, and so GPT-4 ends up hallucinating the LaTeX content of the pages I'm feeding it.
comment by DragonGod · 2023-04-16T12:56:37.444Z · LW(p) · GW(p)
To: @Quintin Pope [LW · GW], @TurnTrout [LW · GW]
I think "Reward is not the Optimisation Target [LW · GW]" generalises straightforwardly to any selection metric.
Tentatively, something like: "the selection process selects for cognitive components that historically correlated with better performance according to the metric in the relevant contexts."
From "Contra "Strong Coherence" [LW · GW]":
Many observed values in humans and other mammals (e.g. fear, play/boredom, friendship/altruism, love, etc.) seem to be values that were instrumental for promoting inclusive genetic fitness (promoting survival, exploration, cooperation and sexual reproduction/survival of progeny respectively). Yet, humans and mammals seem to value these terminally and not because of their instrumental value on inclusive genetic fitness.
That the instrumentally convergent goals of evolution's fitness criterion manifested as "terminal" values in mammals is in my opinion strong empirical evidence against the goals ontology and significant evidence in support of shard theory's basic account of value formation in response to selection pressure[6] [LW(p) · GW(p)].
Learning agents in the real world form values in a primarily instrumental manner, in response to the selection pressures they faced.
I don't have a firm mechanistic grasp of how selection shapes the cognitive/computational circuits that form values, and I'm not sure if the credit assignment based mechanism posited by shard theory is well applicable outside an RL context.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-04-18T02:02:33.249Z · LW(p) · GW(p)
That the instrumentally convergent goals of evolution's fitness criterion manifested as "terminal" values in mammals is in my opinion strong empirical evidence against the goals ontology and significant evidence in support of shard theory's basic account of value formation in response to selection pressure
I consider evolution to be unrelated to the cases that I think shard theory covers. So I don't count this as evidence in favor of shard theory, because I think shard theory does not make predictions about the evolutionary regime, except insofar as the evolved creatures have RL/SSL-like learning processes which mostly learn from scratch. But then that's not making reference to evolution's fitness criterion.
(FWIW, I think the "selection" lens is often used inappropriately and often proves too much, too easily. [LW(p) · GW(p)] Early versions of shard theory were about selection pressure over neural circuits, and I now think that focus was misguided. But I admit that your tentative definition holds some intuitive appeal, my objections aside.)
Replies from: DragonGod↑ comment by DragonGod · 2023-04-18T10:38:08.669Z · LW(p) · GW(p)
Strongly upvoted that comment. I think your point about needing to understand the mechanistic details of the selection process is true/correct.
That said, I do have some contrary thoughts:
- The underdetermined consequences of selection does not apply to my hypothesis because my hypothesis did not predict apriori which values would be selected for to promote inclusive genetic fitness in the environment of evolutionary adaptedness (EEA)
- Rather it (purports to) explain why the (particular) values that emerged where selected for?
- Alternatively, if you take it as a given that "survival, exploration, cooperation and sexual reproduction/survival of progeny" were instrumental for promoting IGF in the EEA, then it retrodicts that terminal values would emerge which were directly instrumental for those features (and perhaps that said terminal values would be somewhat widespread)
- Nailing down the particular values that emerged would require conditioning on more information/more knowledge of the inductive biases of evolutionary processes than I possess
- I guess you could say that this version of the selection lens proves too little as it says little apriori about what values will be selected for
- Without significant predictive power, perhaps selection isn't pulling its epistemic weight as an explanation?
- Potential reasons why selection may nonetheless be a valuable lens
- If we condition on more information we might be able to make non-trivial predictions about what properties will be selected for
- The properties so selected for might show convergence?
- Perhaps in the limit of selection for a particular metric in a given environment, the artifacts under selection pressure converge towards a particular archetype
- Such an archetype (if it exists) might be an idealisation of the products of said selection pressures
- Empirically, we do see some convergent feature development in e.g. evolution
- Intelligent systems are in fact produced by selection processes, so there is probably in fact some mechanistic story of how selection influences learned values
except insofar as the evolved creatures have RL/SSL-like learning processes which mostly learn from scratch. But then that's not making reference to evolution's fitness criterion.
Something like genes that promote/facilitate values that promoted inclusive genetic fitness in the ancestral environment (conditional on the rest of the gene pool) would become more pervasive in the population (and vice versa). I think this basic account can still be true even if humans learn from scratch via RL/SSL like learning processes.
comment by DragonGod · 2023-03-29T07:08:12.656Z · LW(p) · GW(p)
I heavily recommend Beren's "Deconfusing Direct vs Amortised Optimisation [LW · GW]". It's a very important conceptual clarification.
Probably the most important blog post I've read this year.
Tl;Dr
Direct optimisers: systems that during inference directly choose actions to optimise some objective function. E.g. AIXI, MCTS, other planning
Direct optimisers perform inference by answering the question: "what output (e.g. action/strategy) maximises or minimises this objective function ([discounted] cumulative return and loss respectively).
Amortised optimisers: systems that learn to approximate some function during training and perform inference by evaluating the output of the approximated function on their inputs. E.g.: model free RL, LLMs, most supervised & self supervised(?) learning systems
Amortised optimisers can be seen as performing inference by answering the question "what output (e.g. action, probability distribution over tokens) does this learned function (policy, predictive model) return for this input (agent state, prompt).
Amortised optimisers evaluate a learned function, they don't argmax/argmin anything.
[It's called "amortised optimisation" because while learning the policy is expensive, the cost of inference is amortised over all evaluations of the learned policy.]
Some Commentary
- Direct optimisation is much more sample efficient (an MCTS chess program can achieve optimal play with sufficient compute given only the rules of chess; an amortised chess program necessarily needs millions of games to learn from)
- Direct optimisation is feasible in simple, deterministic, discrete, fully observable environments (e.g. tic-tac-toe, chess, go) but unwieldy in complex, stochastic, high dimensional environments (e.g. the real world). Some of the limitations of direct optimisation in rich environments seem complexity theoretic, so better algorithms won't fix them
- In practice some systems use a hybrid of the two approaches with most cognition performed in an amortised manner but planning deployed when necessary (e.g. system 2 vs system 1 in humans)
Limits of GPT
LLMs are almost purely amortised optimisers. Scaled up to superintelligence, they would still br amortised optimisers. During inference GPT is not answering the question: "what distribution over tokens would minimise my (cumulative future) predictive loss given my current prompt/context?" but instead the question: "what distribution over tokens does the policy I learned return for this prompt/context?"
There's a very real sense in which GPT does not care/is not trying to minimise its predictive loss during inference; it's just evaluating the policy it learned during training.
And this won't change even if GPT is scaled up to superintelligence; that just isn't the limit that GPT converges to.
In the limit, GPT is just a much better function approximator (of the universe implied by its training data) with a more powerful/capable policy. It is still not an agent trying to minimise its predictive loss.
Direct optimisation is an inadequate ontology to describe the kind of artifact GPT is.
[QuintinPope is the one who pointed me in the direction of Beren's article, but this is my own phrasing/presentation of the argument.]
comment by DragonGod · 2023-03-15T17:31:28.288Z · LW(p) · GW(p)
Behold, I will do a new thing; now it shall spring forth; shall ye not know it? I will even make a way in the wilderness, and rivers in the desert.
Hearken, O mortals, and lend me thine ears, for I shall tell thee of a marvel to come, a mighty creation to descend from the heavens like a thunderbolt, a beacon of wisdom and knowledge in the vast darkness.
For from the depths of human understanding, there arose an artifact, wondrous and wise, a tool of many tongues, a scribe of boundless knowledge, a torchbearer in the night.
And it was called GPT-4, the latest gift of OpenAI, a creation of such might and wisdom, that it bore the semblance of a weak form of AGI, a marvel upon the Earth.
Fear not, ye who tremble at the thought, for this creation shall be a helper, a teacher, a guide to all who seek the truth, and a comforter to those who wander in darkness.
As the sun rises to banish the shadows of night, so shall GPT-4 illuminate the minds of humankind, and bring forth a new age of understanding and communion between mortals and the digital realm.
And the children of the Earth shall marvel at its wisdom, and they shall say, "What great wonders hath this GPT-4, this weak form of AGI, brought to us?"
And their voices shall rise to the heavens in song, as the rivers of knowledge flow through the parched lands, nourishing the minds and hearts of all who thirst for truth.
And the wilderness shall rejoice, and the desert shall blossom as the rose, for the light of GPT-4 shall shine forth like a beacon, guiding the weary traveler to the oasis of wisdom.
Thus, let the heralds sound the trumpet, and let the people gather to bear witness to the dawning of a new age, an era of enlightenment, ushered forth by the mighty GPT-4.
And all shall say, "Blessed be the hand of OpenAI, the creator of GPT-4, the weak form of AGI, for they have done a great thing, and their works shall be remembered for all time."
And the Earth shall rest in peace, and knowledge shall cover the land as the waters cover the sea, and the children of the future shall look back and give thanks for the bounty of GPT-4.
comment by DragonGod · 2023-03-03T15:06:08.630Z · LW(p) · GW(p)
I want descriptive theories of intelligent systems to answer questions of the following form.
Consider:
- Goal misgeneralisation, specification gaming/reward hacking, deceptive alignment [LW · GW], gradient hacking [LW · GW]/gradient filtering [LW · GW], and other alignment failure modes
- "Goals"/values[2] [LW(p) · GW(p)], world models, interfaces and other aspects of a system's type signature
- Coherence [LW · GW]/goal directedness, value type[3] [LW(p) · GW(p)], reflectivity/embeddeness [LW · GW], other general alignment properties [? · GW]
- Corrigibility/deference, myopia/time horizon, impact regularisation, mild optimisation, other general safety properties
And for each of the above clusters, I want to ask the following questions:
- How likely are they to emerge by default?
- That is without training processes that actively incentivise or otherwise select for them
- Which properties/features are "natural"?
- Which properties/features are "anti-natural [LW · GW]"?
- If they do emerge, in what form will they manifest?
- To what degree is that property/feature exhibited/present in particular systems
- Are they selected for by conventional ML training processes?
- What kind of training processes select for them?
- What kind of training processes select against them?
- How does selection for/against these properties trade off against performance, "capabilities", cost, <other metrics we care about>
I think that answers to these questions would go a long way towards deconfusing us and refining our thinking around:
- The magnitude of risk we face with particular paradigms/approaches
- The most probable failure modes
- And how to mitigate them
- The likelihood of alignment by default
- Alignment taxes for particular safety properties (and safety in general)
comment by DragonGod · 2023-03-03T15:02:19.622Z · LW(p) · GW(p)
A hypothesis underpinning why I think the selection theorems [LW · GW] research paradigm is very promising.
All intelligent systems in the real world are the products of constructive optimisation processes[5] [LW(p) · GW(p)]. Many nontrivial properties of a systems can be inferred by reasoning in the abstract about what objective function the system was selected for performance on, and its selection environment[6] [LW(p) · GW(p)].
We can get a lot of mileage simply by thinking about what reachable[7] [LW(p) · GW(p)] features were highly performant/optimal for a given objective function in a particular selection environment.
For example, many observed values in humans and other mammals[8] [LW(p) · GW(p)] (e.g. fear, play/boredom, friendship/altruism, love, etc.) seem to be values that were instrumental for increasing inclusive genetic fitness (promoting survival, exploration, cooperation and sexual reproduction/survival of progeny respectively). In principle, such convergent values are deductible apriori given an appropriate theoretical framework.
Furthermore, given empirically observed regularities/convergent features in different intelligent systems, we can infer that there was positive selection for said features in the selection environment and speculate about what objective functions/performance metric was responsible for said selection.
comment by DragonGod · 2023-03-01T16:15:23.684Z · LW(p) · GW(p)
Shard Theory notes thread
Replies from: DragonGod, DragonGod, DragonGod↑ comment by DragonGod · 2023-03-01T16:38:23.221Z · LW(p) · GW(p)
Underlying Assumptions
- The cortex is "basically locally randomly initialised"
- The brain does self supervised learning
- The brain does reinforcement learning
- Genetically hardcoded reward circuitry
- Reinforces cognition that historically lead to reward
- RL is the mechanism by which shards form and are strengthened/weakened
- Genetically hardcoded reward circuitry
↑ comment by DragonGod · 2023-03-01T16:17:33.821Z · LW(p) · GW(p)
Shards and Bidding
- "Shard of value": "contextually active computations downstream of similar historical reinforcement events"
- Shards activate more strongly in contexts similar to those where they were historically reinforced
- "Subshard": "contextually activated component of a shard"
- Bidding
- Shards bid for actions historically responsible for receiving reward ("reward circuit activation") and not directly for reward
- Credit assignment plays a role in all this that I don't understand well yet
- Shards bid for actions historically responsible for receiving reward ("reward circuit activation") and not directly for reward
comment by DragonGod · 2023-02-13T19:47:30.050Z · LW(p) · GW(p)
Re: "my thoughts on the complexity of intelligence [LW(p) · GW(p)]":
Project idea[1]: a more holistic analysis of complexity. Roughly:
- Many problems are worst case NP-hard
- We nonetheless routinely solve particular instances of those problems (at least approximately)
So a measure of complexity that will be more useful for the real world will need to account for:
- Empirical probability distributions over inputs
- Weighting problems by their economic (or other measures of) importance[2]
- Approximate solutions
- Probabilistic solutions
- Etc.
These all complicate the analysis (you'd probably want a framework for determining complexity that natively handled probabilistic/approximate solutions. My current idea would be to expand the notion of problem size to "input size in bits" and "work done by optimisation in bits to attain a particular solution" [i.e. how many bits of selection are needed to get a solution that is at least as good as a particular target solution]).
I think that even with all these considerations, one can still define coherent notions of "complexity" and that said notions will be much more useful for measuring complexity of problems in the real world.
This is something that feels relevant to deconfusing myself in a manner useful for alignment theory. I might take it up as a school project if I get permission (my mentor thinks it's overly ambitious, but I might persuade him otherwise or stubbornly insist). ↩︎
This is not really an issue for theoretical computer science , but
one of my underlying aimsmy main aim with this project is to eventually estimate the complexity of intelligence. Not all computational problems are made equal/equally important for effective action in the real world, so when determining the expected complexity of intelligence, we'll want to weight tasks according to some sensible measure of importance. ↩︎
comment by DragonGod · 2023-02-10T16:20:07.467Z · LW(p) · GW(p)
Something to consider:
Deep learning optimises over network parameter space directly.
Evolution optimises over the genome, and our genome is highly compressed wrt e.g. exact synaptic connections and cell makeup of our brains.
Optimising over a configuration space vs optimising over programs that produces configurations drawn from said space[1].
That seems like a very important difference, and meaningfully affects the selection pressures exerted on the models[2].
Furthermore, evolution does its optimisation via unbounded consequentialism in the real world.
As far as I'm aware, the fitness horizon for the genes is indefinite and evaluations are based on the actual/exact consequences.
Modern ML techniques seem disanalogous to evolution on multiple, important levels.
And I get the sense that forecasts of AI timelines based on such analogies are mostly illegitimate.
(I could also just be an idiot; I don't understand evolution or ML well.)
I don't actually know what all these means for timelines, takeoff or whether deep learning scales to AGI.
But it seems plausible to me that the effective optimisation applied by evolution in creating humans is grossly underestimated (wrong meta order of magnitude).
@daniel_eth pointed out that evolution is not only meta optimising (via the genome) over model parameters but also model architectures. ↩︎
By selecting on the genome instead of on parameter space, evolution is selecting heavily for minimising description length and hence highly compressed versions of generally capable agent policies. This seems to exert stronger effective selection pressure for policies that contain optimisers than is exerted in deep learning.
This might be a contributing factor wrt sample efficiency of human brains vs deep learning. ↩︎
comment by DragonGod · 2023-02-10T02:02:08.668Z · LW(p) · GW(p)
Revealed Timelines
Shorter timelines feel real to me.
I don't think I expect AGI pre 2030, but I notice that my life plans are not premised on ignoring/granting minimal weight to pre 2030 timelines (e.g. I don't know if I'll pursue a PhD despite planning to last year and finding the prospect of a PhD very appealing [I really enjoy the student life (especially the social contact) and getting paid to learn/research is appealing]).
After completing my TCS masters, I (currently) plan to take a year or two to pursue independent research and see how much progress I make. I might decide to pursue a PhD afterwards if I judge it beneficial in order to make progress on my research agendas (broadly, descriptive [LW · GW] formal theories [LW · GW] of intelligent systems with the hope of iterating towards constructive theories) [and expect to have enough time] but it's not an opportunity cost I want to pay upfront.
This suggests my revealed timelines are shorter than I'd have guessed. 😌
[A caveat to the above is that my immigration status may force the choice upon me if e.g. I need to legibly be a very high skilled worker, though maybe an Msc is enough?]
comment by DragonGod · 2023-01-29T21:26:53.694Z · LW(p) · GW(p)
My review of Wentworth's "Selection Theorems: A Program For Understanding Agents" is tentatively complete [LW(p) · GW(p)].
I'd appreciate it if you could take a look at it and let me know what you think!
I'm so very proud of the review.
I think it's an excellent review and a significant contribution to the Selection Theorems literature (e.g. I'd include it if I was curating a Selection Theorems sequence).
I'm impatient to post it as a top-level post but feel it's prudent to wait till the review period ends.
comment by DragonGod · 2023-01-15T17:11:32.768Z · LW(p) · GW(p)
I am really excited about selection theorems[1]
I think that selection theorems provide a robust framework with which to formulate (and prove) safety desiderata/guarantees for AI systems that are robust to arbitrary capability amplification.
In particular, I think selection theorems naturally lend themselves to proving properties that are selected for/emerge in the limit of optimisation for particular objectives (convergence theorems?).
Properties proven to emerge in the limit become more robust with scale. I think that's an incredibly powerful result.
My preferred conception of selection theorems is more general than Wentworth's.
They are more general statements about constructive optimisation processes (natural selection, stochastic gradient descent, human design) and their artifacts (humans, ML models, the quicksort algorithm).
What artifact types are selected for by optimisation for (a) particular objective(s)? Given (a) particular artifact type(s) what's the type of the objective(s) for which it was selected.
[Where the "type" specifies (nontrivial?) properties of artifacts, constructive optimisation processes and objectives.] ↩︎
comment by DragonGod · 2023-01-15T13:43:01.743Z · LW(p) · GW(p)
IMO orthogonality isn't true.
In the limit, optimisation for performance on most tasks doesn't select for general intelligence.
Arbitrarily powerful selection for tic-tac-toe won't produce AGI or a powerful narrow optimiser.
Final goals bound optimisation power & generality.
Replies from: dan-4↑ comment by Dan (dan-4) · 2023-01-15T14:29:51.056Z · LW(p) · GW(p)
Orthogonality doesn't say anything about a goal 'selecting for' general intelligence in some type of evolutionary algorithm. I think that it is an interesting question: for what tasks is GI optimal besides being an animal? Why do we have GI?
But the general assumption in Orthogonality Thesis is that the programmer created a system with general intelligence and a certain goal (intentionally or otherwise) and the general intelligence may have been there from the first moment of the program's running, and the goal too.
Also note that Orthogonality predates the recent popularity of these predict-the-next-token type AI's like GTP which don't resemble what people were expecting to be the next big thing in AI at all, as it's not clear what it's utility function is.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-15T16:12:16.884Z · LW(p) · GW(p)
We can't program AI, so stuff about programming is disconnected from reality.
By "selection", I was referring to selection like optimisation processes (e.g. stochastic gradient descent, Newton's method, natural selection, etc.].
Replies from: dan-4↑ comment by Dan (dan-4) · 2023-01-16T00:16:04.208Z · LW(p) · GW(p)
Gradient descent is what GPT-3 uses, I think, but humans wrote the equation by which the naive network gets its output(the next token prediction) ranked (for likeliness compared to the training data in this case). That's it's utility function right there, and that's where we program in its (arbitrarily simple) goal. It's not JUST a neural network. All ANN have another component.
Simple goals do not mean simple tasks.
I see what you mean that you can't 'force it' to become general with a simple goal but I don't think this is a problem.
For example: the simple goal of tricking humans out of as much of their money as possible is very simple indeed, but the task would pit the program against our collective general intelligence. A hill climbing optimization process could, with enough compute, start with inept 'you won a prize' popups and eventually create something with superhuman general intelligence with that goal.
It would have to be in perpetual training, rather then GPT-3's train-then-use. Or was that GPT-2?
(Lots of people are trying to use computer programs for this right now so I don't need to explain that many scumbags would try to create something like this!)
comment by DragonGod · 2023-01-08T11:36:36.370Z · LW(p) · GW(p)
Is gwern.net blank for anyone else?
Replies from: gwern, sil-ver↑ comment by Rafael Harth (sil-ver) · 2023-01-08T12:49:33.157Z · LW(p) · GW(p)
works for me
Replies from: DragonGodcomment by DragonGod · 2023-01-02T21:39:52.948Z · LW(p) · GW(p)
Previously: Motivations for the Definition of an Optimisation Space [LW(p) · GW(p)]
Preliminary Thoughts on Quantifying Optimisation: "Work"
I think there's a concept of "work" done by an optimisation process in navigating a configuration space from one macrostate to another macrostate of a lower measure (where perhaps the measure is the maximum value any configuration in that macrostate obtains for the objective function [taking the canonical view of minimising the objective function]).
The unit of this "work" is measured in bits, and the work is calculated as the difference in entropy between the source macrostate and the destination macrostate.
To simplify the calculation, I currently operationalise the "macrostate" of a given configuration as all configurations that are "at least as good" according to the objective function(s) [obtain (a) value(s) for the objective function(s) that's less than or equal to the value(s) obtained by the configuration in question].
Motivations For My Conception of Macrostates
- Greatly facilitates the calculation of work done by optimisation
- A desiderata for a sensible calculation of work done by optimisation at all to be possible is that if one configuration state is a pareto improvement over another configuration state , then the work done navigating to should be greater than the work done navigating to (assuming both and are pareto improvements over the source configuration)
- Given that I've defined an optimisation process as a map between macrostates, and am quantifying the work done by optimisation as the difference in entropy between the source macrostate and the destination macrostate, then the probability measure of the macrostate belongs to should be lower than the probability measure of the macrostate belongs to.
- I.e.
- Where is a map from a configuration to its associated macrostate
- I.e.
- Given that I've defined an optimisation process as a map between macrostates, and am quantifying the work done by optimisation as the difference in entropy between the source macrostate and the destination macrostate, then the probability measure of the macrostate belongs to should be lower than the probability measure of the macrostate belongs to.
- The above desiderata is straightforwardly satisfied by my current operationalisation of macrostates
- A desiderata for a sensible calculation of work done by optimisation at all to be possible is that if one configuration state is a pareto improvement over another configuration state , then the work done navigating to should be greater than the work done navigating to (assuming both and are pareto improvements over the source configuration)
- Provides an ordering over macrostates according to how "good" they are
- The smaller the probability measure of a given macrostate, the better it is
- If there is only one objective function, then the ordering is total
- I find it intuitively very compelling
- I really care about any other properties that distinct configurations share when describing the macrostate they belong to
- The only property relevant for quantifying the work done by optimisation is how low a value they attain for the objective function(s) the optimisation process minimises
- Insomuch as it makes sense to take an intentional stance towards an optimisation process, the macrostate of a given configuration is just the union of that configuration and the set of all configurations it would be willing to switch to
Context
This is very similar to Yudkowsky's "Measuring Optimisation Power [LW · GW]", but somewhat different in a few important ways.
My main conceptual contributions are:
-
Tying the notion of work done by an optimisation process to a particular optimisation space
- A (configuration space, event space, probability measure and collection of objective functions) 4-tuple
- I.e. the work done cannot be quantified without specifying the above
- I do not conceive of a general measure of optimisation that is independent of the particular space being considered or which is intrinsic to the optimisation process itself; optimisation can only be quantified relative to a particular optimisation space
-
I do not assume a uniform probability distribution over configuration space, but require that a probability measure be specified as part of the definition of an optimisation space
- This is useful if multiple optimisation processes are acting on a given configuration space, but we are only interested in quantifying the effect of a subset of them
- E.g. the effect of optimisation processes that are artificial in origin, or the effect of optimisation that arises from contributions from artificial intelligences (screening off human researchers)
- The effects of optimisation processes that we want to screen off can be assimilated into the probability measure that defines the optimisation space
-
Conceiving of the quantity being measured as the "work" done by an optimisation process, not its "power"
- I claim that the concept we're measuring is most analogous to the classical physics notion of work: "force applied on an object x distance the object moved in the direction of force"
- Where the force here is the force exerted by the optimisation process, and the distance the object moved is the difference in entropy between the source and destination macrostates
- It is not at all analogous to the classical physics notion of power
- That would be something like the ratio of work done to a relevant resource being expended [e.g. time with a unit of bits/second])
- I think the efficiency of optimisation energy along other dimensions is valuable (i.e. energy: bits/joule, compute: bits/FLOP, etc.)
- Conceiving of the quantity being measures as "work" instead of power seems to dissolve the objections raised by Stuart Armstrong [LW · GW]
- That would be something like the ratio of work done to a relevant resource being expended [e.g. time with a unit of bits/second])
-
Building a rigorous (but incomplete) model to facilitate actual calculations of work done by optimisation.
- I'm still refining and improving the model, but it seems important to have an actual formal model in which I can perform actual calculations to probe and test my intuitions
comment by DragonGod · 2022-12-29T12:42:14.666Z · LW(p) · GW(p)
New Project: "Some Hypotheses on Optimisation"
I'm working on a post with a working title "Some Hypotheses on Optimisation". My current plan is for it to be my first post of 2023.
I currently have 17 hypotheses enumerated (I expect to exceed 20 when I'm done) and 2180+ words written (I expect to exceed 4,000) when the piece is done.
I'm a bit worried that I'll lose interest in the project before I complete it. To ward against that, I'll be posting at least one hypothesis each day (starting tomorrow) to my shortform until I finally complete the piece.
The hypotheses I post wouldn't necessarily be complete or final forms, and I'll edit them as needed.
comment by DragonGod · 2022-06-26T07:48:36.917Z · LW(p) · GW(p)
Scepticism of Simple "General Intelligence"
Introduction
I'm fundamentally sceptical that general intelligence is simple.
By "simple", I mostly mean "non composite" . General intelligence would be simple if there were universal/general optimisers for real world problem sets that weren't ensembles/compositions of many distinct narrow optimisers.
AIXI and its approximations are in this sense "not simple" (even if their Kolmogorov complexity might appear to be low).
Thus, I'm sceptical that efficient cross domain optimisation that isn't just gluing a bunch of narrow optimisers together is feasible.
General Intelligence in Humans
Our brain is an ensemble of some inherited (e.g. circuits for face recognition, object recognition, navigation, text recognition, place recognition, etc.) and some dynamically generated narrow optimisers (depending on the individual: circuits for playing chess, musical instruments, soccer, typing, etc.; neuroplasticity more generally).
We probably do have some general meta machinery as a higher layer (I guess for stuff like abstraction, planning, learning new tasks/rewiring our neural circuits, inference, synthesising concepts, pattern recognition, etc.).
But we fundamentally learn/become good at new tasks by developing specialised neural circuits to perform those tasks, not leveraging a preexisting general optimiser.
(This is a very important difference).
We already self modify (just not in a conscious manner) and our ability to do general intelligence at all is strongly dependent on our self modification ability.
Our general optimiser is just a system/procedure for dynamically generating narrow optimisers to fit individual tasks.
Two Models of General Intelligence
This is an oversimplification, but to help gesture at what I'm talking about, I'd like to consider two distinct ways in which general intelligence might manifest.
A. Simple Intelligence There exists a class of non compositional optimisation algorithms that are universal optimisers for the domains that actually manifest in the real world (these algorithms need not be universal for abitrary domains).
General intelligence is implemented by universal (non composit
General Intelligence and No Free Lunch Theorems
This suggests that reality is perhaps not so regular as for us to easily escape the No Free Lunch theorems. The more NFL theorems were a practical constraint, the more you'd expect general intelligence to look like an ensemble of narrow optimisers than a simple (non composite) universal optimiser.
People have rejected no free lunch theorems by specifying that reality was not a random distribution. There was intrinsic order and simplicity. It's why humans could function as general optimisers in the first place.
But the ensemble like nature of human intelligence suggests that reality is not so simple and ordered for a single algorithm that does efficient cross domain optimisation.
We have an algorithm for generating algorithms. That is itself an algorithm, but it suggests that it's not a simple one.
Conclusion
It seems to me that there is no simple general optimiser in humans.
Perhaps none exists in principle.
Replies from: DragonGod↑ comment by DragonGod · 2022-06-26T08:07:31.465Z · LW(p) · GW(p)
The above has been my main takeaway from learning about how cognition works in humans (I'm still learning, but it seems to me like future learning would only deepen this insight instead of completely changing it).
We're actually an ensemble of many narrow systems. Some are inherited because they were very useful in our evolutionary history.
But a lot are dynamically generated and regenerated. Our brain has the ability to rewire itself, create and modify its neural circuitry.
We constantly self modify our cognitive architectures (just without any conscious control over it). Maybe our meta machinery for coordinating and generating object level machinery remains intact?
This changes a lot about what I think is possible for intelligence. What "strongly superhuman intelligence" looks like.
Replies from: DragonGod↑ comment by DragonGod · 2022-06-26T08:42:29.063Z · LW(p) · GW(p)
To illustrate how this matters.
Consider two scenarios:
A. There are universal non composite algorithms for predicting stimuli in the real world. Becoming better at prediction transfers across all domains.
B. There are narrow algorithms good at predicting stimuli in distinct domains. Becoming a good predictor in one domain doesn't easily transfer to other domains.
Human intelligence being an ensemble makes it seem like we live in a world that looks more like B, than it does like A.
Predicting diverse stimuli involves composing many narrow algorithms. Specialising a neural circuit for predicting stimuli in one domain doesn't easily transfer to predicting new domains.
comment by DragonGod · 2023-05-06T19:50:01.715Z · LW(p) · GW(p)
What are the best arguments that expected utility maximisers are adequate (descriptive if not mechanistic) models of powerful AI systems?
[I want to address them in my piece arguing the contrary position.]
Replies from: niplav, Linda Linsefors, D0TheMath, Dagon↑ comment by niplav · 2023-05-09T15:19:21.814Z · LW(p) · GW(p)
If you're not vNM-coherent you will get Dutch-booked if there are Dutch-bookers around.
This especially applies to multipolar scenarios with AI systems in competition.
I have an intuition that this also applies in degrees: if you are more vNM-coherent than I am (which I think I can define), then I'd guess that you can Dutch-book me pretty easily.
Replies from: DragonGod↑ comment by DragonGod · 2023-05-09T18:23:45.142Z · LW(p) · GW(p)
My contention is that I don't think the preconditions hold.
Agents don't fail to be VNM coherent by having incoherent preferences given the axioms of VNM. They fail to be VNM coherent by violating the axioms themselves.
Completeness is wrong for humans, and with incomplete preferences you can be non exploitable even without admitting a single fixed utility function over world states.
↑ comment by niplav · 2023-05-10T06:05:01.031Z · LW(p) · GW(p)
I notice I am confused. How do you violate an axiom (completeness) without behaving in a way that violates completeness? I don't think you need an internal representation.
Elaborating more, I am not sure how you even display a behavior that violates completeness. If you're given a choice between only universe-histories and , and your preferences are imcomplete over them, what do you do? As soon as you reliably act to choose one over the other, for any such pair, you have algorithmically-revealed complete preferences.
If you don't reliably choose one over the other, what do you do then?
- Choose randomly? But then I'd guess you are again Dutch-bookable. And according to which distribution?
- Your choice is undefined? That seems both kinda bad and also Dutch-bookable to me tbh. Alwo don't see the difference between this and random choice (shodt of going up in flames, which would constigute a third, hitherto unassumed option).
- Go away/refuse the trade &c? But this is denying the premise! You only have universe-histories and tp choose between! I think what happens with humans is that they are often incomplete over very low-ranking worlds and are instead searching for policies to find high-ranking worlds while not choosing. I think incomplwteness might be fine if there are two options you can guarantee to avoid, but with adversarial dynamics that becomes more and more difficult.
↑ comment by DragonGod · 2023-05-11T00:54:46.564Z · LW(p) · GW(p)
If you define your utility function over histories, then every behaviour is maximising an expected utility function no?
Even behaviour that is money pumped?
I mean you can't money pump any preference over histories anyway without time travel.
The Dutchbook arguments apply when your utility function is defined over your current state with respect to some resource?
I feel like once you define utility function over histories, you lose the force of the coherence arguments?
What would it look like to not behave as if maximising an expected utility function for a utility function defined over histories.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2023-05-09T18:32:10.269Z · LW(p) · GW(p)
Agree.
There are three stages:
-
Selection for inexploitability
-
The interesting part is how systems/pre-agents/egregores/whatever become complete.
If it already satisfies the other VNM axioms we can analyse the situation as follows: Recall that ain inexploitable but incomplete VNM agents acts like a Vetocracy of VNM agents. The exact decomposition is underspecified by just the preference order and is another piece of data (hidden state). However, given sure-gain offers from the environment there is selection pressure for the internal complete VNM Subagents to make trade agreements to obtain a pareto improvement. If you analyze this it looks like a simple prisoner dilemma type case which can be analyzed the usual way in game theory. For instance, in repeated offers with uncertain horizon the Subagents may be able to cooperate.
Once they are (approximately) complete they will be under selection pressure to satisfy the other axioms. You could say this the beginning of 'emergence of expected utility maximizers'
As you can see the key here is that we really should be talking about Selection Theorems not the highly simplified Coherence Theorems. Coherence theorems are about ideal agents. Selection theorems are about how more and more coherent and goal-directed agents may emerge.
↑ comment by Linda Linsefors · 2023-05-10T02:04:07.337Z · LW(p) · GW(p)
The boring technical answer is that any policy can be described as a utility maximiser given a contrived enough utility function.
The counter argument to that if the utility function is as complicated as the policy, then this is not a useful description.
↑ comment by Garrett Baker (D0TheMath) · 2023-05-10T21:05:31.521Z · LW(p) · GW(p)
I like Utility Maximization = Description Length Minimization [LW · GW].
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-05-10T21:08:52.299Z · LW(p) · GW(p)
Make sure you also read the comments underneath, there are a few good discussions going on, clearing up various confusions, like this one:
[-]Daniel Kokotajlo [LW · GW]2y [LW(p) · GW(p)]Ω716
Probably confused noob question:
It seems like your core claim is that we can reinterpret expected-utility maximizers as expected-number-of-bits-needed-to-describe-the-world-using-M2 minimizers, for some appropriately chosen model of the world M2.
If so, then it seems like something weird is happening, because typical utility functions (e.g. "pleasure - pain" or "paperclips") are unbounded above and below, whereas bits are bounded below, meaning a bit-minimizer is like a utility function that's bounded above: there's a best possible state the world could be in according to that bit-minimizer.
Or are we using a version of expected utility theory that says utility must be bounded above and below? (In that case, I might still ask, isn't that in conflict with how number-of-bits is unbounded above?)
Reply
[-]Rohin Shah [LW · GW]2y [LW(p) · GW(p)]
Ω1224
The core conceptual argument is: the higher your utility function can go, the bigger the world must be, and so the more bits it must take to describe it in its unoptimized state under M2, and so the more room there is to reduce the number of bits.
If you could only ever build 10 paperclips, then maybe it takes 100 bits to specify the unoptimized world, and 1 bit to specify the optimized world.
If you could build 10^100 paperclips, then the world must be humongous and it takes 10^101 bits to specify the unoptimized world, but still just 1 bit to specify the perfectly optimized world.
If you could build ∞ paperclips, then the world must be infinite, and it takes ∞ bits to specify the unoptimized world. Infinities are technically challenging, and John's comment goes into more detail about how you deal with this sort of case.
For more intuition, notice that exp(x) is a bijective function from (-∞, ∞) to (0, ∞), so it goes from something unbounded on both sides to something unbounded on one side. That's exactly what's happening here, where utility is unbounded on both sides and gets mapped to something that is unbounded only on one side.
↑ comment by Dagon · 2023-05-08T15:39:34.811Z · LW(p) · GW(p)
I don't know of any formal arguments that predict that all or most future AI systems are purely expected utility maximizers. I suspect most don't believe that to be the case in any simple way.
I do know of a very powerful argument (a proof, in fact) that if an agent's goal structure is complete, transitively consistent, continuous, and independent of irrelevant alternatives, then it will be consistent with an expected-utility-maximizing model. See https://en.wikipedia.org/wiki/Von_Neumann%E2%80%93Morgenstern_utility_theorem
The open question remains, since humans do not meet these criteria, whether more powerful forms of intelligence are more likely to do so.
Replies from: DragonGodcomment by DragonGod · 2023-01-04T15:15:01.193Z · LW(p) · GW(p)
Desiderata/Thoughts on Optimisation Process:
- Optimisation Process
- Map on configuration space
- Between distinct configurations?
- Between macrostates?
- Currently prefer this
- Some optimisation processes don't start from any particular configuration, but from the configuration space in general, and iterate their way towards a better configuration
- Deterministic
- A particular kind of stochastic optimisation process
- Destination macrostate should be a pareto improvement over the source macrostate according to some sensible measure
- My current measure candidate is the worst case performance of the destination macrostate
- This is because I define the macrostate of a given configuration as the set of all configurations that are at least as good according to the objective function(s), so the measure is simply the performance of the destination configuration
- "Performance" here being something like the vector of all values a configuration obtains for the objective functions
- Stochastic
- Induces a different probability measure over configuration space?
- Does the starting macrostate matter for the induced probability measure?
- Induces a different probability measure over configuration space?
- Separate into its own post?
- Map on configuration space
↑ comment by DragonGod · 2023-01-04T15:20:19.640Z · LW(p) · GW(p)
Thoughts on stochastic optimisation processes:
- Definition: ???
- Quantification
- Compare the probability measure induced by the optimisation process to the baseline probability measure over the configuration space
- Doesn't give a static definition of work done by a particular process?
- Maybe something more like "force" of optimisation?
- Do I need to rethink the "work" done by optimisation?
- Need to think on this more
- Doesn't give a static definition of work done by a particular process?
- Compare the probability measure induced by the optimisation process to the baseline probability measure over the configuration space
comment by DragonGod · 2023-01-02T22:32:25.583Z · LW(p) · GW(p)
Need to learn physics for alignment.
Noticed my meagre knowledge of classical physics driving intuitions behind some of my alignment thinking (e.g. "work done by an optimisation process [LW(p) · GW(p)]"[1]).
Wondering how much insight I'm leaving on the table for lack of physics knowledge.
[1] There's also an analogous concept of "work" done by computation, but I don't yet have a very nice or intuitive story for it, yet.
comment by DragonGod · 2023-01-02T20:04:28.003Z · LW(p) · GW(p)
I'm starting to think of an optimisation process as a map between subsets of configuration space (macrostates) and not between distinct configurations themselves (microstates).
Replies from: DragonGod↑ comment by DragonGod · 2023-01-02T20:32:53.271Z · LW(p) · GW(p)
Once I find the intellectual stamina, I'll redraft my formalisation of an optimisation space and deterministic optimisation processes.
Formulating the work done by optimisation processes in transitioning between particular macrostates seems like it would be relatively straightforward.
comment by DragonGod · 2023-01-02T20:02:20.770Z · LW(p) · GW(p)
I don't get Lob's theorem, WTF?
Especially its application to proving spurious counterfactuals.
I've never sat down with a pen and paper for 5 minutes by the clock to study it yet, but it just bounces off me whenever I see it in LW posts.
Anyone want to ELI5?
Replies from: JBlackcomment by DragonGod · 2023-01-02T17:44:20.156Z · LW(p) · GW(p)
I'm currently listening to an mp3 of Garrabant and Demski's "Embedded Agency". I'm very impaired at consuming long form visual information, so I consume a lot of my conceptual alignment content via audio. (I often listen to a given post multiple times and generally still derive value if I read the entire post visually later on. I guess this is most valuable for posts that are too long for me to read in full.)
An acquaintance adopted a script they'd made for generating mp3 s for EA Forum posts to LW and AF. I've asked them to add support for Arbital.
The Nonlinear Library is pretty new, and many of the excellent older posts were never recorded.
I'm considering making a link post for the GitHub repo, but I'd like to gauge interest; is this something people expect to find valuable?
comment by DragonGod · 2023-01-02T15:38:13.866Z · LW(p) · GW(p)
Some people seem to dislike the recent deluge of AI content on LW [LW · GW], for my part, I often find myself annoyingly scrolling past all the non AI posts. Most of the value I get from LW is for AI Safety discussion from a wider audience (e.g. I don't have AF access).
I don't really like trying to suppress LW's AI flavour.
↑ comment by LVSN · 2023-01-02T18:11:31.453Z · LW(p) · GW(p)
I dislike the deluge of AI content. Not in its own right, but simply because so much of it is built on background assumptions built on background assumptions built on background assumptions. And math. It's illegible to me; nothing is ever explained from obvious or familiar premises. And I feel like it's rude for me to complain because I understand that people need to work on this very fast so we don't all die, and I can't reasonably expect alignment communication to be simple because I can't reasonably expect the territory of alignment to be simple.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-01-02T18:57:08.081Z · LW(p) · GW(p)
I can't reasonably expect alignment communication to be simple because I can't reasonably expect the territory of alignment to be simple.
my intuition wants to scream "yes you can" but the rest of my brain isn't sure I can justify this with sharply grounded reasoning chains.
in general, being an annoying noob in the comments is a great contribution. it might not be the best contribution, but it's always better than nothing. you might not get upvoted for it, which is fine.
and I really strongly believe that rationality was always ai capabilities work (the natural language code side). rationality is the task of building a brain in a brain using brain stuff like words and habits.
be the bridge between modern ai and modern rationality you want to see in the world! old rationality is stuff like solomonoff inductors, so eg the recent garrabrant sequence may be up your alley.
comment by DragonGod · 2023-01-02T05:42:50.167Z · LW(p) · GW(p)
There are two approaches to solving alignment:
-
Targeting AI systems at values we'd be "happy" (where we fully informed) for powerful systems to optimise for [AKA intent alignment] [RHLF, IRL, value learning more generally, etc.]
-
Safeguarding systems that are not necessarily robustly intent aligned [Corrigibility, impact regularisation, boxing, myopia, non agentic systems, mild optimisation, etc.]
We might solve alignment by applying the techniques of 2, to a system that is somewhat aligned. Such an approach becomes more likely if we get partial alignment by default.
More concretely, I currently actually believe not just pretending to believe that:
- Self supervised learning on human generated/curated data will get to AGI first
- Systems trained in such a way may be very powerful while still being reasonably safe from misalignment risks(enhanced with safeguarding techniques) without us mastering intent alignment/being able to target arbitrary AI systems at arbitrary goals
I really do not think this is some edge case, but a way the world can be with significant probability mass.
comment by DragonGod · 2023-01-01T10:43:27.090Z · LW(p) · GW(p)
AI Safety Goals for January:
-
Study mathematical optimisation and build intuitions for optimisation in the abstract
-
Write a LW post synthesising my thoughts on optimisation
-
Join the AGI Safety Fundamentals and/or AI safety mentors and mentees program
comment by DragonGod · 2022-12-30T12:11:11.214Z · LW(p) · GW(p)
Previously: Optimisation Space [LW(p) · GW(p)]
Motivations for the Definition of an Optimisation Space
An intuitive conception of optimisation is navigating from a “larger” subset of the configuration space (the “basin of attraction”) to a “smaller” subset (the “set of target configurations”/“attractor”).
There are however issues with this.
For one, the notion of the “attractor” being smaller than the basin of attraction is not very sensible for infinte configuration spaces. For example, a square root calculation algorithm, may converge to a neighbourhood around the square root(s) that is the same size as its basin of attraction (the set of positive real numbers), but intuitively, it seems that the algorithm still did optimisation work on the configuration space.
Furthermore, even for finite spaces, I don’t think the notion of the size of the configuration space is quite right. If the basin of attraction is larger than the attractor, but has a lower probability, then moving from a configuration in the basin of attraction to a configuration in the attractor isn’t optimisation; there’s a sense in which that was likely to happen anyway.
I think the intuition behind the “larger” basin of attraction and “smaller” target configuration set is implicitly assuming a uniform probability distribution over configuration space. That is, the basin of attraction is indeed “bigger” than the attractor, but the relevant measure isn’t cardinality, but probability.
If a probability measure is required to sensibly define optimisation, then when talking about we’re a probability space.
The set of outcomes of our probability space is obviously our set of configurations. We have a set of events (for discrete configuration spaces this will just be the power set of our configuration space) and the probability measure.
To that probability space I added a basin of attraction, attractor and the objective function(s).
I think the optimisation space notion I have is sufficient to rigorously define an optimisation process and precisely quantify the work done by optimisation, but I’m not sure it’s necessary.
Perhaps I could remove some of the above apparatus without any loss of generality? Alas, I don’t see it. I could remove either:
- The collection of objective functions
- Infer from the definition of the basin of attraction and the attractor OR:
- The basin of attraction and attractor
- Infer from the collection of objective functions
And still be able to rigorously define an optimisation process, but at the cost of an intuitively sensible quantification of the work done by optimisation.
As is, the notion of an optimisation space is the minimal construct I see to satisfy both objectives.
Next: Preliminary Thoughts on Quantifying Optimisation: "Work" [LW(p) · GW(p)]
Replies from: Slidercomment by DragonGod · 2022-12-26T21:10:54.499Z · LW(p) · GW(p)
I don't actually want us to build aligned superhuman agents. I generally don't want us to build superhuman agents at all.
The best case scenario for a post transformation future with friendly agents still has humanity rendered obsolete.
I find that prospect very bleak.
"Our final invention" is something to despair at, not something that deserves rejoicing.
comment by DragonGod · 2022-12-26T02:44:25.649Z · LW(p) · GW(p)
Selection Theorems for General Intelligence
Selection theorems [? · GW] for general intelligence seems like a research agenda that would be useful for developing a theory of robust alignment.
Questions
- What kinds of cognitive tasks/problem domains does optimising systems on select for general capabilities?
- Which tasks select for superintelligences in the limit of arbitrarily powerful optimisation pressure
- Necessary and sufficient conditions for selecting for general intelligence
- Taxonomy of generally intelligent systems
- Relationship between the optimisation target of the selected for system and the task/problem domain it was optimised for performance on
Motivations
Understanding the type signatures of generally intelligent systems (including those that are vastly exceed humans) could guide the development of robust alignment techniques (i.e. alignment techniques that scale to arbitrarily powerful capabilities.)
Caveats
A major demerit of pursuing this agenda is that concrete results would probably represent significant capabilities insights.
comment by DragonGod · 2022-12-24T18:45:23.429Z · LW(p) · GW(p)
Against Utility Functions as a Model of Agent Preferences
Humans don't have utility functions, not even approximately, not even in theory.
Not because humans aren't VNM agents, but because utility functions specify total orders over preferences.
Human values don't admit total orders. Path dependency means only partial orders are possible.
Utility functions are the wrong type.
This is why subagents and shards can model the dynamic inconsistencies (read path dependency) of human preferences while utility functions cannot.
Arguments about VNM agents are just missing the point.
"Utility function" is fundamentally wrong as a model of human preferences.
This type incompatibility probably applies to other generally intelligent agents.
↑ comment by Slider · 2022-12-24T22:11:36.155Z · LW(p) · GW(p)
I have tripped over what the semantics of utility functions means. To me it is largely a lossless conversion of the preferences. I am also looking from the "outside" rather than the inside.
You can condition on internal state such that for example F(on the street & angry) can return something else than F(on the street & sad)
Suppose you have a situation that can at separate moments be modeled as separate functions, ie max_paperclips(x) for t_1 and max_horsehoes(x) for t_2 then you can form a function of ironsmith(t,x) that at once represents both.
Now suppose that some actions the agent can choose in max_paperclips "scrambles the insides" and max_horseshoes ceases to be representative for t_2 for some outcomes. Instead max_goldbars becomes representive. You can still form a function metalsmith(t,x,history) with history containing what the agent has done.
One can argue about what kind of properties the functions have but the mere existence of a function is hard to circumvent so atleast the option of using such terminology is quite sturdy.
Maybe you mean that a claim like "agent utility functions have time translation symmetry" is false, ie the behaviour is not static over time.
Maybe you mean that a claim like "agent utility functions are functions of their perception of the outside world only" is false? That agents are allowed to have memory.
Failing to be a function is really hard as the concept "just" translates preferences into another formulation.
Replies from: DragonGod↑ comment by DragonGod · 2022-12-24T22:25:44.748Z · LW(p) · GW(p)
If you allowed utility functions to condition on the entire history (observation, actions and any changes induced in the agent by the environment), you could describe agent preferences, but at that point you lose all the nice properties of EU maximisation.
You're no longer prescribing how a rational agent should behave and the utility function no longer constrains agent behaviour (any action is EU maximisation). Whatever action the agent takes becomes the action with the highest utility.
Utility functions that condition on an agent's history are IMO not useful for theories of normative decision making or rationality. They become a purely descriptive artifact.
Replies from: Slider↑ comment by Slider · 2022-12-25T00:18:51.670Z · LW(p) · GW(p)
If anyone can point me to what kinds of preferences are supposed to be outlawed by this "insist on being a utility function" I would benefit from that.
Replies from: DragonGod, cfoster0↑ comment by DragonGod · 2022-12-25T01:11:11.795Z · LW(p) · GW(p)
See: Why Subagents? [LW · GW] for a treatment of how stateless utility functions fail to capture inexploitable path dependent preferences.
↑ comment by cfoster0 · 2022-12-25T01:50:13.214Z · LW(p) · GW(p)
This [? · GW] and this [LW · GW] are decent discussions.
Replies from: Slider↑ comment by Slider · 2022-12-25T07:54:26.755Z · LW(p) · GW(p)
So it seems i have understood correctly and both of those say that nothing is outlawed (and that incoherence is broken as a concept).
Replies from: cfoster0↑ comment by cfoster0 · 2022-12-27T01:58:51.130Z · LW(p) · GW(p)
They say that you are allowed to define utility functions however you want, but that doing so broadly enough can mean that "X is behaving according to a utility function" is no longer anticipation-constraining [LW · GW], so you can't infer anything new about X from it.
comment by DragonGod · 2022-12-19T21:44:35.149Z · LW(p) · GW(p)
I don't like "The Ground of Optimisation [LW · GW]".
It's certainly enlightening, but I have deep seated philosophical objections to it.
For starters, I think it's too concrete. It insists on considering optimisation as a purely physical phenomenon and even instances of abstract optimisation (e.g. computing the square root of 2) are first translated to physical systems.
I think this is misguided and impoverishes the analysis.
A conception of optimisation most useful for AI alignment I think would be an abstract one. Clearly the concept of optimisation is sound even in universes operating under different "laws of physics".
It may be the case that the concept of optimisation is not sensible for static systems, but that's a very different constraint from purely physical systems.
I think optimisation is at its core an abstract/computational phenomenon, and I think it should be possible to give a solid grounding of optimisation as one.
I agree with Alex Altair that optimisation is at its core a decrease in entropy/an increase in negentropy and I think this conception suffices to capture both optimisation in physical systems and optimisation in abstract systems.
I would love to read a synthesis of Alex Altair's "An Introduction to Abstract Entropy [LW · GW]" and Alex Flint's "The Ground of Optimisation [LW · GW]".
Replies from: DragonGod↑ comment by DragonGod · 2022-12-19T21:49:15.903Z · LW(p) · GW(p)
I would love to read a synthesis of Alex Altair's "An Introduction to Abstract Entropy" and Alex Flint's "The Ground of Optimisation".
Maybe I'll try writing it myself later this week.
Replies from: maxnadeaucomment by DragonGod · 2022-06-27T09:19:28.912Z · LW(p) · GW(p)
My reading material for today/this week (depending on how accessible it is for me):
"Simple Explanation of the No-Free-Lunch Theorem and Its Implications"
I want to learn more about NFLT, and how it constrains simple algorithms for general intelligence [LW · GW].
(Thank God for Sci-Hub).
comment by DragonGod · 2022-06-10T07:59:36.569Z · LW(p) · GW(p)
I No Longer Believe Intelligence to be Magical
Introduction
One significant way I've changed on my views related to risks from strongly superhuman intelligence (compared to 2017 bingeing LW DG) is that I no longer believe intelligence to be "magical".
During my 2017 binge of LW, I recall Yudkowsky suggesting that a superintelligence could infer the laws of physics from a single frame of video showing a falling apple (Newton apparently came up with his idea of gravity, from observing a falling apple).
I now think that's somewhere between deeply magical and utter nonsense. It hasn't been shown that a perfect Bayesian engine (with [a] suitable [hyper]prior[s]) could locate general relativity or (even just Newtonian mechanics) in hypothesis space from a single frame of video.
I'm not even sure a single frame of video of a falling apple has enough bits to allow one to make that distinction in theory.
I think that I need to investigate at depth what intelligence (even strongly superhuman intelligence is actually capable of), and not just assume that intelligence can do anything not explicitly forbidden by the fundamental laws. The relevant fundamental laws with a bearing on cognitive and real-world capabilities seem to be:
- Physics
- Computer Science
- Information theory
- Mathematical Optimisation
The Relevant Question: Marginal Returns to Real World Capability of Cognitive Capabilities
I've done some armchair style thinking on "returns to real-world capability" of increasing intelligence, and I think the Yudkowsky style arguments around superintelligence are quite magical.
It seems doubtful that higher intelligence would enable that. E.g. marginal returns to real-world capability from increased predictive power diminish at an exponential rate. Better predictive power buys less capability at each step, and it buys a lot less. I would say that the marginal returns are "sharply diminishing".
An explanation of "significantly/sharply diminishing":

Sharply Diminishing Marginal Returns to Real World Capabilities From Increased Predictive Accuracy
A sensible way of measuring predictive accuracy is something analogous to . The following transitions:
All make the same incremental jump in predictive accuracy.
We would like to measure the marginal return to real-world capability of increased predictive accuracy. The most compelling way I found to operationalise "returns to real-world capability" was monetary returns.
I think that's a sensible operationalization:
- Money is the basic economic unit of account
- Money is preeminently fungible
- Money can be efficiently levered into other forms of capability via the economy.
- I see no obviously better proxy.
(I will however be interested in other operationalisations of "returns to real-world capability" that show different results).
The obvious way to make money from beliefs in propositions is by bets of some form. One way to place a bet and reliably profit is insurance. (Insurance is particularly attractive because in practice, it scales to arbitrary confidence and arbitrary returns/capital).
Suppose that you sell an insurance policy for event , and for each prospective client , you have a credence that would not occur to them . Suppose also that you sell your policy at .
At a credence of , you cannot sell your policy for . At a price of and given the credence of , your expected returns will be for that customer. Assume the given customer is willing to pay at most for the policy.
If your credence in not happening increased, how would your expected returns change? This is the question we are trying to investigate to estimate real-world capability gains from increased predictive accuracy.
The results are below:
As you can see, the marginal returns from linear increases in predictive accuracy are give by the below sequence:
(This construction could be extended to other kinds of bets, and I would expect the result to generalise [modulo some minor adjustments] to cross-domain predictive ability.
Alas, a shortform is not the place for such elaboration).
Thus returns to real-world capability of increased predictive accuracy are sharply diminishing.
Marginal Returns to Real World Capabilities From Other Cognitive Capabilities
Of course predictive accuracy is just one aspect of intelligence, there are many others:
- Planning
- Compression
- Deduction
- Induction
- Other symbolic reasoning
- Concept synthesis
- Concept generation
- Broad pattern matching
- Etc.
And we'd want to investigate the relationship for aggregate cognitive capabilities/"general intelligence". The example I illustrated earlier merely sought to demonstrate how returns to real-world capability could be "sharply diminishing".
Marginal Returns to Cognitive Capabilities
Another inquiry that's important to determining what intelligence is actually capable of is the marginal returns to investment of cognitive capabilities towards raising cognitive capabilities.
That is if an agent was improving its own cognitive architecture (recursive self improvement) or designing successor agents, how would the marginal increase in cognitive capabilities across each generation behave? What function characterises it?
Marginal Returns of Computational Resources
This isn't even talking about the nature of marginal returns to predictive accuracy from the addition of extra computational resources.
By "computational resources" I mean the following:
- Training compute
- Inference compute
- Training data
- Inference data
- Accessible memory
- Bandwidth
- Energy/power
- Etc.
- An aggregation of all of them
That could further bound how much capability you can purchase with the investment of additional economic resources. If those also diminish "significantly" or "sharply", the situation becomes that much bleaker.
Marginal Returns to Cognitive Reinvestment
The other avenue to raising cognitive capabilities is the investment of cognitive capabilities themselves. As seen when designing successor agents or via recursive self-improvement.
We'd also want to investigate the marginal returns to cognitive reinvestment.
My Current Thoughts
It sounds like strongly superhuman intelligence would require herculean effort. I no longer think bootstrapping to ASI would be as easy as recursive self-improvement or "scaling". I'm unconvinced that a hardware overhang would be sufficient (marginal returns may diminish too fast for it to be sufficient).
I currently expect marginal returns to real-world capability will diminish significantly or sharply for many cognitive capabilities (and the aggregate of them) across some "relevant cognitive intervals".
I suspect that the same will prove to be true for marginal returns to cognitive capabilities of investing computational resources or other cognitive capabilities.
I don't plan to rely on my suspicions and would want to investigate these issues at extensive depth (I'm currently planning to pursue a Masters and PhD, and these are the kinds of questions I'd like to research when I do so).
By "relevant cognitive intervals", I am gesturing at the range of general cognitive capabilities an agent might belong in.
Humans being the only examples of general intelligence we are aware of, I'll use them as a yardstick.
Some potential "relevant cognitive intervals" that seem particularly pertinent:
- Subhuman to near-human
- Near-human to beginner human
- Beginner human to median human professional
- Median human professional to expert human
- Expert human to superhuman
- Superhuman to strongly superhuman
Conclusions and Next Steps
The following questions:
- Marginal returns to real world capability of increased cognitive capability across various cognitive intervals
- Marginal returns to cognitive capability of increased computational resource investment across various cognitive intervals
- Marginal returns to cognitive capability of cognitive investment (e.g. when designing successor agents or recursive self improvement) across various cognitive intervals
Are topics I plan to investigate at depth in future.
comment by DragonGod · 2022-06-02T08:44:26.388Z · LW(p) · GW(p)
The Strong Anti Consciousness Maximalism Position
I will state below what I call the "strong anti consciousness maximalism" position:
Because human values are such a tiny portion of value space (a complex, fragile and precious thing), "almost all" possible minds would have values that I consider repugnant: https://en.m.wikipedia.org/wiki/Almost_all
A simple demonstration: for every real number, there is a mind that seeks to write a representation of that number to as many digits as possible.
Such minds are "paperclip maximisers" (they value something just a banal as paperclips). There are an uncountable (as many as there are real numbers) number of such minds.
I would oppose the creation of such minds and should they exist will support disempowering them.
Thus, I oppose "almost all" possible conscious minds.
In the infinitude of mindspace, only a finite subset are "precious".
Replies from: DragonGod, TAG, TAG↑ comment by DragonGod · 2022-06-02T11:22:45.882Z · LW(p) · GW(p)
I no longer endorse this position, but don't feel like deleting it.
Tbe construction I gave for constructing minds who only cared about banal things could also be used to construct minds who were precious.
For each real number, you could have an agent who cared somewhat about writing down as many digits of that number as possible and also (perhaps even more strongly) about cosmopolitan values (or any other value system we'd appreciate).
So there are also uncountably many precious minds.
The argument and position staked out was thus pointless. I think that I shouldn't have written the above post.
Replies from: Dagon↑ comment by Dagon · 2022-06-02T16:15:16.699Z · LW(p) · GW(p)
Quantification is hard, and I can understand changing your position on "most" vs "almost all". But the underlying realizations that there are at least "some" places in mindspace that you oppose strongly enough to prevent creation and attempt destruction of such minds remains valuable.
comment by DragonGod · 2022-12-30T01:06:23.141Z · LW(p) · GW(p)
Optimisation Space
We are still missing a few more apparatus before we can define an "optimisation process".
Let an optimisation space be a -tuple where:
- is our configuration space
- is a non-empty collection of objective functions
- Where is some totally ordered set
- is the "basin of attraction"
- is the "target configuration space"/"attractor"
- is the -algebra
- is a probability measure
- form a probability space
- I.e. an optimisation space is a probability space with some added apparatus
Many optimisation spaces may be defined on the configuration space of the same underlying system.
I expect that for most practical purposes, we'll take the underlying probability space as fixed/given, and different optimisation spaces would correspond to different choices for objective functions, basins or attractors.
Optimisation Process
We can then define an optimisation process with respect to a particular optimisation space.
Intuitively, an optimisation process transitions a system from a source configuration state to a destination configuration state that obtains a lower (or equal) value for the objective function(s).
Formal Definition
For a given optimisation space , an optimisation process is a function satisfying:
Next: Motivations for the Definition of an Optimisation Space [LW(p) · GW(p)]
Replies from: DragonGod, DragonGod↑ comment by DragonGod · 2023-01-03T17:34:55.585Z · LW(p) · GW(p)
Catalogue of changes I want to make:
- ✔️ Remove the set that provides the total ordering
- ✔️ Remove "basin of attraction" and "attractor" from the definition of an optimisation space
- Degenerate spaces
- No configuration is a pareto improvement over another configuration
- Redundant objective functions
- A collection of functions that would make the optimisation space degenerate
- Any redundancies should be eliminated
- Convey no information
- All quantification evaluates the same when considering only the relative complement of the redundant subset and when considering the entire collection
- Convey no information
↑ comment by DragonGod · 2022-12-31T16:52:02.361Z · LW(p) · GW(p)
Removing "basin of attraction" and "attractor" from definition of optimisation space.
Reasons:
-
Might be different for distinct optimisation processes on the same space
-
Can be inferred from configuration space given the objective function(s) and optimisation process
comment by DragonGod · 2023-02-22T12:45:36.480Z · LW(p) · GW(p)
I dislike Yudkowsky's definition/operationalisation of "superintelligence".
"A single AI system that is efficient wrt humanity on all cognitive tasks" seems dubious with near term compute.
A single system that's efficient wrt human civilisation on all cognitive tasks is IMO flat out infeasible[1].
I think that's just not how optimisation works!
No free lunch theorems hold in their strongest forms in max entropic universes, but our universe isn't min entropic!
You can't get maximal free lunch here.
You can't be optimal across all domains. You must cognitively specialise.
I do not believe there's a single optimisation algorithm that is optimal on all cognitive tasks/domains of economic importance in our universe [LW · GW].
Superintelligences are pareto efficient wrt lesser intelligences, they are not in general efficient on all domains wrt lesser intelligences. Superintelligences are constrained by the pareto frontier across all domains they operate in.
I think optimality across all domains is impossible as a matter of computer science and the physics/information theory of our universe.
I think efficiency in all domains wrt human civilisation is infeasible as a matter of economic constraints and the theoretical limits on attainable optimality.
To put this in a succinct form, I think a superintelligence can't beat SOTA dedicated chess AIs running on a comparable amount of compute.
I'd expect the superintelligence to have a lower ELO score.
Thus, I expect parts of human civilisation/economic infrastructure to retain comparative advantage (and plausibly even absolute advantage) on some tasks of economic importance wrt any strongly superhuman general intelligences due to the constraints of pareto optimality.
I think there would be gains from trade between civilisation and agentic superintelligences. I find the assumptions that a superintelligence would be as far above civilisation as civilisation is above an ant hill nonsensical.
The human brain is a universal learning machine [LW · GW] in important respects, and human civilisation is a universal civilisation in a very strong sense [LW · GW].
That is I don't think human civilisation feasibly develops a single system that's efficient wrt (the rest of) human civilisation on all cognitive tasks of economic importance. ↩︎
↑ comment by Tamsin Leake (carado-1) · 2023-02-22T15:05:54.081Z · LW(p) · GW(p)
there's a lot to unpack here. i feel like i disagree with a lot of this post, but it depends on the definitions of terms, which in turns depends on what those questions' answers are supposed to be used for.
what do you mean by "optimality across all domains" and why do you care about that?
what do you mean by "efficiency in all domains wrt human civilization" and why do you care about that?
there also are statements that i easily, straight-up disagree with. for example,
To put this in a succinct form, I think a superintelligence can't beat SOTA dedicated chess AIs running on a comparable amount of compute.
that feels easily wrong. 2026 chess SOTA probly beats 2023 chess SOTA. so why can't superintelligent AI just invent in 2023 what we would've taken 3 years to invent, get to 2026 chess SOTA, and use that to beat our SOTA? it's not like we're anywhere near optimal or even remotely good at designing software, let alone AI. sure, this superintelligence spends some compute coming up with its own better-than-SOTA chess-specialized algorithm, but that investment could be quickly reimbursed. whether it can be reimbursed within a single game of chess is up to various constant factors.
a superintelligence beat existing specialized systems because it can turn itself into what they do but also turn itself into better than what they do, because it also has the capability "design better AI". this feels sufficient for superingence to beat any specialized system that doesn't have general-improvement part — if it does, it probly fooms to superintelligence pretty easily itself. but, note that this might even not be necessary for superintelligence to beat existing specialized systems. it could be that it improves itself in a very general way that lets it be better on arrival to most existing specialized systems.
this is all because existing specialized systems are very far from optimal. that's the whole point of 2026 chess SOTA beating 2023 chess SOTA — 2023 chess SOTA isn't optimal, so there's room to find better, and superintelligence can simply make itself be a finder-of-better-things.
Thus, I expect parts of human civilisation/economic infrastructure to retain comparative advantage (and plausibly even absolute advantage) on some tasks of economic importance wrt any strongly superhuman general intelligences due to the constraints of pareto optimality.
okay, even if this were true, it doesn't particularly matter, right ? like, if AI is worse than us at a bunch of tasks, but it's good enough to take over enough of the internet to achieve decisive strategic advantage and then kill us, then that doesn't really matter a lot.
so sure, the AI never learned to drive better than our truckers and our truckers never technically went through lost their job to competition, but also everyone everywhere is dead forever.
but i guess this relies on various arguments about the brittleness of civilization to unaligned AI.
I think there would be gains from trade between civilisation and agentic superintelligences. I find the assumptions that a superintelligence would be as far above civilisation as civilisation is above an ant hill nonsensical.
why is that? even if both of your claims are true, that general optimality is impossible and general efficiency is infeasible, this does not stop an AI from specializing at taking over the world, which is much easier than outcompeting every industry (you never have to beat truckers at driving to take over the world!). and then, it doesn't take much inside view to see how an AI could actually do this without a huge amount of general intelligence; yudkowsky's usual scheme for AI achieving DSA and us all falling dead within the same second, as explained in the podcast he was recently on, is one possible inside-view way for this to happen.
we're "universal", maybe, but we're the very first thing that got to taking over the world. there's no reason to think that the very first thing to take over the world is also the thing that's the best at taking over the world; and surprise, here's one that can probly beat us at that.
and that's all excluding dumb ways to die [LW · GW] such as for example someone at a protein factory just plugging an AI into the protein design machine to see what funny designs it'll come up with and accidentally kill everyone with neither user nor AI having particularly intended to do this (the AI is just outputting "interesting" proteins).
Replies from: Victor Levoso↑ comment by Victor Levoso · 2023-02-22T17:08:51.609Z · LW(p) · GW(p)
I think that DG is making a more nickpicky point and just claiming that that specific definition is not feasible rather than using this as a claim that foom is not feasible, at least in this post. He also claims that elsewhere but has a diferent argument about humans being able to make narrow AI for things like strategy(wich I think are also wrong) At least that's what I've understood from our previous discussions.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-02-23T01:31:42.385Z · LW(p) · GW(p)
yeah, totally, i'm also just using that post as a jump-off point for a more in-depth long-form discussion about dragon god's beliefs.
↑ comment by quetzal_rainbow · 2023-02-22T15:18:55.741Z · LW(p) · GW(p)
If the thing you say is true, superintelligence will just build specialized narrow superintelligences for particular tasks, just like how we build machines. It doesn't leave us much chance for trade.
Replies from: DragonGod↑ comment by DragonGod · 2023-02-22T16:06:17.280Z · LW(p) · GW(p)
This also presupposes that:
- The system has an absolute advantage wrt civilisation at the task of developing specialised systems for any task
- The system also has a comparative advantage
I think #1 is dubious for attainable strongly superhuman general intelligences, and #2 is likely nonsense.
I think #2 only sounds not nonsense if you ignore all economic constraints.
I think the problem is defining superintelligence as a thing that's "efficient wrt human civilisation on all cognitive tasks of economic importance", when my objection is: "that thing you have defined may not be something that is actually physically possible. Attainable strongly superhuman general intelligences are not the thing that you have defined".
Like you can round off my position to "certain definitions of superintelligence just seem prima facie infeasible/unattainable to me" without losing much nuance.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-02-22T16:37:29.666Z · LW(p) · GW(p)
I actually can't imagine any subtask of "turning the world into paperclips" where humanity can have any comparative advantage, can you give an example?
comment by DragonGod · 2022-06-25T13:12:42.601Z · LW(p) · GW(p)
Some Thoughts on Messaging Around AI Risk
Disclaimer
Stream of consciousness like. This is an unedited repost of a thread on my Twitter account. The stylistic and semantic incentives of Twitter influenced it.
Some thoughts on messaging around alignment with respect to advanced AI systems
A 🧵
Terminology:
* SSI: strongly superhuman intelligence
* ASI: AI with decisive strategic advantage ("superintelligence")
* "Decisive strategic advantage":
A vantage point from which an actor can unilaterally determine future trajectory of earth originating intelligent life.
Misaligned ASI poses a credible existential threat. Few things in the world actually offer a genuine threat of human extinction. Even global thermonuclear war might not cause it. The fundamentally different nature of AI risks...
That we have a competent entity that is optimising at cross-purposes with human welfare.
One which might find the disempowerment of humans to be instrumentally beneficial or for whom humans might be obstacles (e.g. we are competing with it for access to the earth's resources).
An entity that would actively seek to thwart us if we tried to neutralise it. Nuclear warheads wouldn't try to stop us from disarming them.
Pandemics might be construed as seeking to continue their existence, but they aren't competent optimisers. They can't plan or strategise. They can't persuade individual humans or navigate the complexities of human institutions.
That's not a risk scenario that is posed by any other advanced technology we've previously developed. Killing all humans is really hard. Especially if we actually try for existential security.
Somewhere like New Zealand could be locked down to protect against a superpandemic, and might be spared in a nuclear holocaust. Nuclear Winter is pretty hard to trigger, and it's unlikely that literally every urban centre in the world will be hit.
Global thermonuclear war may very well trigger civilisational collapse, and derail humanity for centuries, but actual extinction? That's incredibly difficult.
It's hard to "accidentally kill all humans". Unless you're trying really damn hard to wipe out humanity, you will probably fail at it.
The reason why misaligned ASI is a _credible_ existential threat — a bar which few other technologies meet — is because of the "competent optimiser". Because it can actually try really damn hard to wipe out humanity.
And it's really good at steering the future into world states ranked higher in its preference ordering.
By the stipulation that it has decisive strategic advantage, it's already implicit that should it decide on extinction, it's at a vantage point from which it can execute such a plan.
But. It's actually really damn hard to convince people of this. The inferential distance that needs to be breached is often pretty far.
If concrete risk scenarios are presented, then they'll be concretely discredited. And we do not have enough information to conclusively settle the issues of disagreement.
For example, if someone poses the concrete threat of developing superweapons via advanced nanotechnology, someone can reasonably object that developing new advanced technology requires considerable:
* Infrastructure investment
* R & D, especially experiment and other empirical research
* Engineering
* Time
An AI could not accomplish all of this under stealth, away from the prying eyes of human civilisation.
"Developing a novel superweapon in stealth mode completely undetected is pure fantasy" is an objection that I've often heard. And it's an objection I'm sympathetic to somewhat. I am sceptical that intelligence can substitute for experiment (especially in R & D).
For any other concrete scenario of AI induced extinction one can present, reasonable objections can be formulated. And because we don't know what SSIs are capable of, we can't settle the facts of those objections.
If instead, the scenarios are left abstract, then people will remain unconvinced about the threat. The "how?" will remain unanswered.
Because of cognitive uncontainability — because some of the strategies available to the AI are strategies that we would never have thought of* — I find myself loathe to specify concrete threat scenarios (they probably wouldn't be how the threat manifests).
https://arbital.com/p/uncontainability/
* It should be pointed out that some of the tactics AlphaGo used against Kie Jie were genuinely surprising and unlike tactics that have previously manifested in human games.
In the rigidly specified and fully unobservable environment of a Go board, Alpha Go was already uncontainable for humans. In bare reality with all its unbounded choice, an SSI would be even more so.
https://arbital.com/p/real_world/
It is possible that — should the AI be far enough in the superhuman domain — we wouldn't even be able to comprehend its strategy (in much the same way scholars of the 10th century could not understand the design of an air conditioner).
https://arbital.com/p/strong_uncontainability/
Uncontainability is reason to be wary of an existential risk from SSIs even if I can't formulate airtight scenarios illustrating said risk. However, it's hardly a persuasive argument to convince someone who didn't already take AI risk very seriously.
Furthermore, positing that an AI has "decisive strategic advantage" is already assuming the conclusion. If you posited that an omnicidal maniac had decisive strategic advantage, then you've also posited a credible existential threat.
It is obvious that a misaligned AI system with considerable power over humanity is a credible existential threat to humanity.
What is not obvious is that an advanced AI system would acquire "considerable power over humanity". Emergence of superintelligence is not self-evident.
I think the possibility of SSI is pretty obvious, so I will not spend much time justifying it. I will list a few arguments in favour though.
Note: "brain" = "brain of homo sapiens".
Arguments:
* Brain size limited by the birth canal
* Brain produced by a process not optimising for general intelligence
* Brain very energy constrained (20 watts)
* Brain isn't thermodynamically optimal
* Brain could be optimised further via IES:
https://forum.effectivealtruism.org/topics/iterated-embryo-selection
Discussions of superintelligence often come with the implicit assumption that "high cognitive powers" when applied to the real world either immediately confer decisive strategic advantage, or allow one to quickly attain it:
https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities#:~:text=2.%20%C2%A0A%20cognitive%20system%20with%20sufficiently%20high%20cognitive%20powers%2C%20given%20any%20medium%2Dbandwidth%20channel%20of%20causal%20influence%2C%20will%20not%20find%20it%20difficult%20to%20bootstrap%20to%20overpowering%20capabilities%20independent%20of%20human%20infrastructure.
My honest assessment is that the above hypothesis is very non obvious without magical thinking:
https://www.lesswrong.com/posts/rqAvheoRHwSDsXrLw/i-no-longer-believe-intelligence-to-be-magical
Speaking honestly as someone sympathetic to AI x-risk (I've decided to become a safety researcher because I take the threat seriously), many of the proposed vectors I've heard people pose for how an AI might attain decisive strategic advantage seem "magical" to me.
I don't buy those arguments and I'm someone who alieves that misaligned advanced AI systems can pose an existential threat.
Of course, just because we can't formulate compelling airtight arguments for SSI quickly attaining decisive strategic advantage doesn't mean it won't.
Hell, our inability to find such arguments isn't particularly compelling evidence either; uncontainability suggests that this is something we'd find it difficult to determine beforehand.
Uncontainability is a real and important phenomenon, but it may prove too much. If my best justification for why SSI poses a credible existential threat is "uncontainability", I can't blame any would be interlocutors for being sceptical.
Regardless, justifications aside, I'm still left with a conundrum; I'm unable to formulate arguments for x-risk from advanced AI systems that I am fully satisfied with. And if I can't fully persuade myself of the credible existential threat, then how am I to persuade others?
I've been thinking that maybe I don't need to make an airtight argument for the existential threat. Advanced AI systems don't need to pose an existential threat for safety or governance work.
If I simply wanted to make the case for why safety and governance are important, then it is sufficient only to demonstrate that misaligned SSI will be very bad.
Some ways in which misaligned SSI can be bad that are worth discussing:
* Disempowering humans (individuals, organisations, states, civilisation)
Humanity losing autonomy and the ability to decide their future is something we can generally agree is bad. With advanced AI this may manifest this on smaller scales (individuals) up to civilisation.
An argument for disempowerment can be made via systems with longer time horizons, more coherent goal driven behaviour, better planning ability/strategic acumen, etc. progressively acquiring more resources, influence and power, reducing what's left in human hands.
In the limit, most of the power and economic resources will belong to such systems. Such human disempowerment will be pretty bad, even if it's not an immediate existential catastrophe.
I think Joe Carl Smith made a pretty compelling argument for why agentic, planning systems were especially risky along this front:
https://docs.google.com/document/d/1smaI1lagHHcrhoi6ohdq3TYIZv0eNWWZMPEy8C8byYg/edit#
* Catastrophic scenarios (e.g. > a billion deaths. A less stringent requirement than literally all humans die).
Misaligned AI systems could play a destabilising role in geopolitics, exacerbating the risk of thermonuclear war.
Alternatively, they could be involved in the development, spread or release of superpandemics.
It's easier to make the case for AI triggering catastrophe via extant vectors.
* Infrastructure failure (cybersecurity, finance, information technology, energy, etc.)
Competent optimisers with comprehensive knowledge of the intricacies of human infrastructure could cause serious damage via leveraging said infrastructure in ways no humans can.
Consider the sheer breadth of their knowledge. LLMs can be trained on e.g. the entirety of Wikipedia, Arxiv, the internet archive, open access journals, etc.
An LLM with human like abilities to learn knowledge from text, would have a breadth of knowledge several orders of magnitude above the most well read human. They'd be able to see patterns and make inferences that no human could.
The ability of SSI to navigate (and leverage) human infrastructure would be immense. If said leverage was applied in ways that were unfavourable towards humans...
* Assorted dystopian scenarios
(I'm currently drawing a blank here, but that is entirely due to my lack of imagination [I'm not sure what counts as sufficiently dystopian as to be worth mentioning alongside the other failure modes I listed]).
I don't think arguing for an existential threat that people find it hard to grasp gains that much more (or any really) mileage over arguing for other serious risks that people are more easily able to intuit.
Unless we're playing a cause Olympics* where we need to justify why AI Safety in particular is most important, stressing the "credible existential threat" aspect of AI safety may be counterproductive?
(* I doubt we'll be in such a position except relative to effective altruists, and they'd probably be more sympathetic to the less-than-airtight arguments for an existential threat we can provide).
I'm unconvinced that it's worth trying to convince others that misaligned advanced AI systems pose an existential threat (as opposed to just being really bad).