Some Summaries of Agent Foundations Work
post by mattmacdermott · 2023-05-15T16:09:56.364Z · LW · GW · 1 commentsContents
Why Agent Foundations? Normative and Descriptive Agent Foundations Normative Subproblems Descriptive Subproblems Descriptive Selection Theorems Agents Over Cartesian World Models Boundaries Cartesian Frames Basic Foundations for Agent Models Shard Theory The Causal Incentives Agenda Normative Decision Theory Logical Induction Infra-Bayesianism Tiling Agents None 1 comment
This is a bunch of not-very-technical summaries of agent foundations work from LessWrong and the Alignment Forum.
I was hoping to turn it into a comprehensive literature review, categorising things in an enlightening way and listing open problems. It turns out that's pretty hard to do! It's languished in my drafts for long enough now, so I'm just going to post it as it is. Hopefully someone else can produce a great overview of the field instead.
Why Agent Foundations?
My own answer to this question is that most AI threat models depend on a powerful agent pursuing a goal we don't want it to, and mathematical models of agency seem useful both for understanding and dealing with these risks. Existing models of agency from fields like reinforcement learning and game theory don't seem up to the job, so trying to develop better ones might pay off.
Normative and Descriptive Agent Foundations
One account of why our usual models of agency aren't up to the job is the Embedded Agency [? · GW] sequence - the usual models assume agents are unchanging, indivisible entities which interact with their environments through predefined channels, but real-world agents are a part of their environment. The sequence identifies four rough categories of problems that arise when we switch to trying to model embedded agents, explained in terms of Marcus Hutter's model of the theoretically perfect reinforcement learning agent, AIXI.
I find these subproblems to be a useful framing for thinking about agents foundations, but as I explained in a previous post [AF · GW], I think they take a strongly normative stance, asking what high-level principles an agent should follow in order be theoretically perfect. Some other agent foundations takes a more descriptive stance, asking what mechanistic and behavioural properties agents in the real world tend to have. You could also call this a distinction between top-down and bottom-up approaches to modelling agency.
Here are the problems from the Embedded Agency sequence:
Normative Subproblems
- Decision Theory. AIXI's actions affect the world in a well-defined way[1], but embedded agents have to figure out whether they care about the causal, evidential, or logical implications of their choices.
- Embedded World-Models. AIXI can hold every possible model of the world in its head in full detail and consider every consequence of its actions, but embedded agents are part of the world, and have limited space and compute with which to model it. This gives rise to the non-realisability problem - what happens when the real world isn't in your hypothesis class?
- Robust Delegation. AIXI is unchanging and the only comparable agent in town, but embedded agents can self-modify and create other agents. They need to ensure their successors are aligned.
- Subsystem Alignment. AIXI is indivisible, but embedded agents are chunks of the world made up of subchunks. What if those subchunks are agents with their own agendas?
I think the embedded agency subproblems are also a useful way to categorise descriptive work, but the names and descriptions feel too normative, so I renamed them for the descriptive case. I also suggested a fifth problem, which is about figuring out how our models actually correspond to reality. I called it 'Identifying Agents', but now I prefer something like 'Agents in Practice'.
Descriptive Subproblems
- I/O Channels. Actions, observations, and Cartesian boundaries aren't primitive: descriptive models need to define them. How do we move from a non-agentic model of the world to one with free will and counterfactuals?
- Internal Components. Presumably agents contain things like goals and world-models, but how do these components work mathematically? And are there others?
- Future Agents. What is the relationship between an agent and its future self, or its successors? To what extent can goals be passed down the line?
- Subagents and Superagents. Do agents contain subagents? When can the interaction of a group of agents be thought of as a superagent? How do the goals of subagents relate to the goals of superagents?
- Agents in Practice. Can we determine which parts of the world contain agents, and read off their internal components? Should we expect our models of agency to be very accurate, like the models of physics, or just a rough guide, like the models of economics? And how close are agents in practice to normative ideals?
The rest of the post organises work according to whether it takes a normative or descriptive approach, and which of the subproblems it's aimed at. I'm not necessarily convinced these are reality-carving distinctions - they're just a framing I was trying out.
Let's start with the descriptive stuff.
Descriptive
Selection Theorems
Subproblems: Internal components.
Summary: You can think of John Wentworth's selection theorems [? · GW] agenda as a descriptive take on coherence theorems. Coherence theorems say things like 'agents without property X are bad in way Y, so you should have property X.' That sounds pretty normative. Selection theorems say instead 'agents without property X get selected against in way Z, so we should expect agents to have property X.'
You could also think of selection theorems as a place where normative and descriptive thinking about agency joins up. A normative coherence theorem like 'agents with cyclic preferences get money-pumped, which seems bad' is not too far from being a descriptive selection theorem. We just need a story about why agents who get money-pumped are selected against, e.g. because we're in an RL training setup where agents with less 'money' are in a worse position to get reward.
But while coherence theorems are usually about behavioural properties, in the selection theorems frame it's quite natural to ask what structural properties of agents are selected for. John's aim is to prove selection theorems which tell us what to expect the internal components of agents produced by our ML setups to look like. Knowing that certain data structures representing goals or world models will be selected for under certain conditions seems broadly useful: it could help with transferable interpretability [LW · GW], for example, or clarify whether corrigibility, ambitious value learning, or human imitation is a more natural alignment alignment target.
Existing selection theorems include the Kelly criterion [? · GW], the Gooder Regulator Theorem [LW · GW] and a proof that Q-learning agents in Newcomblike environments learn 'ratifiable' policies. John has a post about how to work on selection theorems [LW · GW] and there's a bounty [LW · GW] out on proving a selection theorem of a particular form.
Agents Over Cartesian World Models
Subproblems: Internal Components.
Summary: In this post [LW · GW], Mark Xu and Evan Hubinger add some embeddedness to the standard RL model of a partially observable Markov decision process by adding an internal agent state to go with the usual external environment state. They then consider four types of consequentialist agents - those that assign utility to environment states, internal states, actions and observations respectively. They also extend the formalism to handle nonconsequentialist 'structural agents' that care not about things in the world directly but about the way the world works.
I found this to be one of those posts that doesn't say anything groundbreaking but ends up being weirdly clarifying just by going through a taxonomy of different ways something can be. Now when people talk about utility functions I usually take a moment to make a mental note of what type signature they're assuming.
Boundaries
Subproblems: I/O Channels.
Summary: But can we avoid taking Cartesian boundaries as a primitive notion, and define them instead?
Andrew Critch's Boundaries sequence [? · GW] offers a formal definition of the boundary of an organism in terms of an approximate directed Markov blanket in a dynamic causal model - meaning a set of variables which approximately causally separate the inside of the organism (the viscera) from the outside (the environment). The boundary has a passive part which directs causal influence inwards and an active part which directs causal influence outwards. You can think of these parts as transmitting actions and observations respectively.
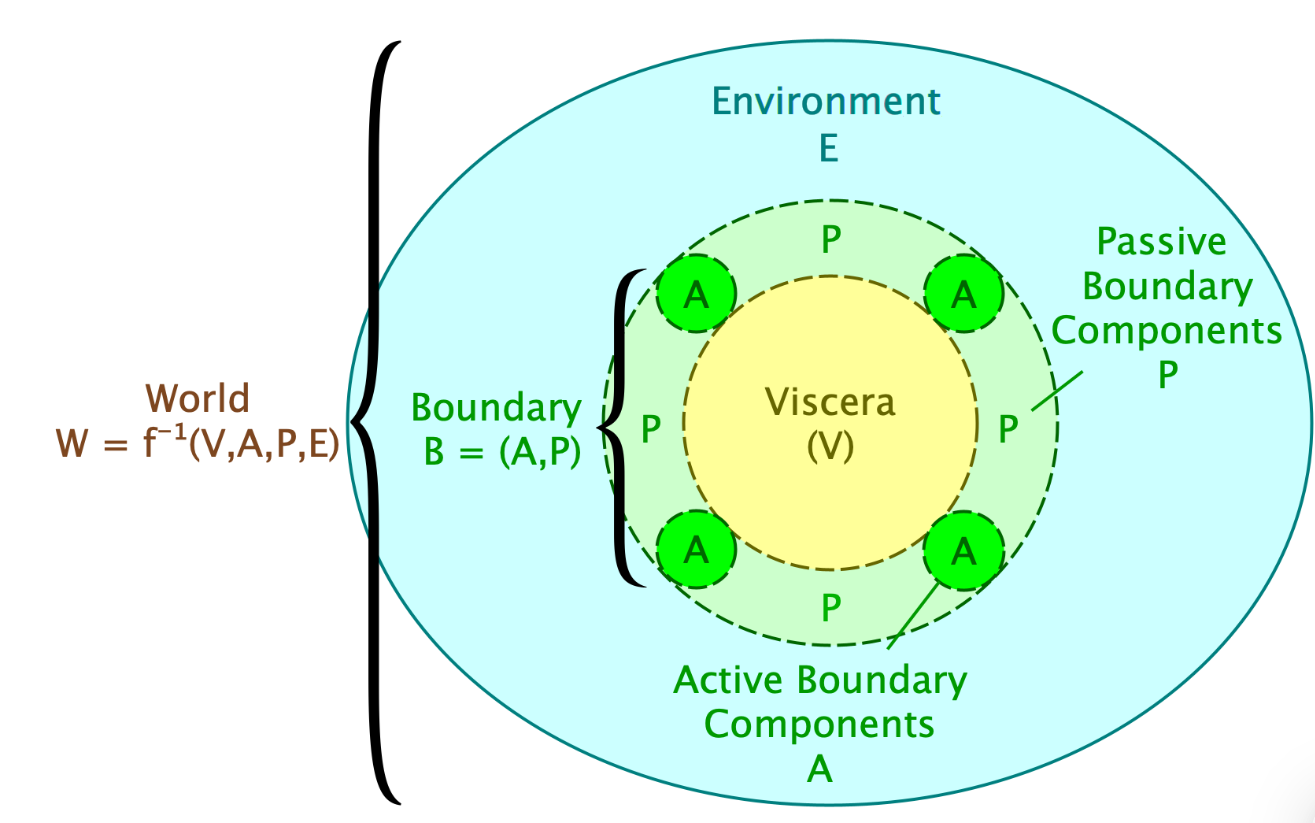
The organism implements a decision rule which updates the state of the viscera and active boundary given their current states, plus the state of the passive boundary. Importantly, we only assume the boundary approximately screens off the inside of the organism from the outside. The more 'infiltration' of information there is from the environment into the active boundary and viscera, the less well the decision rule will describe the evolution of their state. Decision rules which lead to high levels of infiltration will soon cease to describe reality, so we can assume the ones we encounter in practice will be self-perpetuating (do I smell a selection theorem?).
Critch thinks the boundaries concept is useful for thinking about topics as diverse as [? · GW]corrigibility, mesa-optimisers, AI boxing, consequentialism, mild optimisation, and counterfactuals. The idea that boundaries are important has been gaining some steam - this post [LW · GW] by Chipmonk collates recent discussion on the topic.
Cartesian Frames
Subproblems: I/O Channels, Subagents and Superagents.
Summary: Where Critch thinks about partioning the world into agent, environment, and boundary, Scott Garrabrant's Cartesian frames is about factorising the world's state space into substates chosen by an agent and its environment respectively.
We start with a set of possible ways the world could be, and write down of a set of ways an agent could be, a set of ways an environment could be, and a function which assigns a world to each agent-environment combination. The tuple is a Cartesian frame, and the point is that there are many different Cartesian frames for a given each corresponding to a different agent-environment distinction. The agent in one Cartesian frame might be a subagent of the agent in another - or they might overlap in a different way. We can write a Cartesian frame as a matrix, like this:
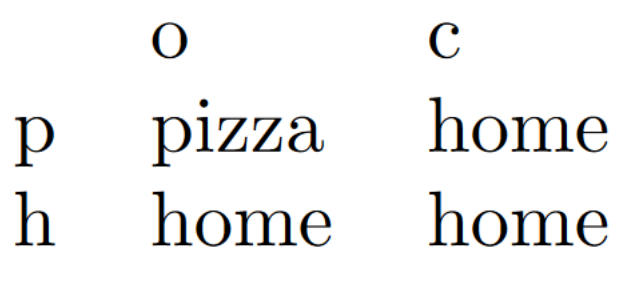
Here Alice and Bob are collectively deciding whether order a takeway. Rows are elements of : they could decide to get pizza (p) or cook at home (h). Columns are elements of , which correspond to different ways the environment could be: the pizza place could be open (o) or closed (c). Entries in the matrix are the worlds that arise under each combination: unless they decide on pizza and the restaurant is open, they will eat at home.
Or instead of thinking of Alice and Bob as a collective agent, we could make Alice our agent and treat Bob as part of the environment:
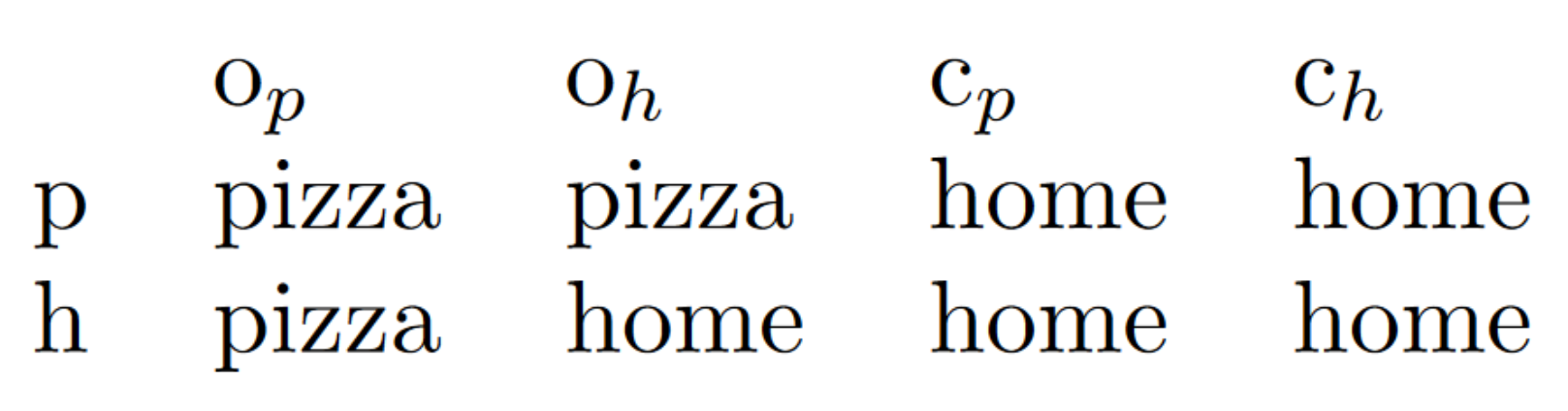
Now o means the pizza place is open but Bob votes for home, and so on. Different carvings produce agents that can force different facts about the world to be true - Alice and Bob collectively can ensure they eat at home, but Alice can't ensure it on her own. The question of how subagents relate to superagents feels like the most obvious place where this stuff might produce important insights.
Mathematically, a Cartesian frame is a thing called a Chu Space. Scott's aim is to be able to start with a Cartesian frame and do a bunch of category theory to reconstruct familiar notions like actions, observations, the passing of time [LW · GW], and so on. Interesting things might fall out of considering the way Cartesian frames relate to each other - for example, we might be able to distinguish fundamental features that arise no matter how we carve up the world, from features which are artefacts of a particular way of looking at things.
Basic Foundations for Agent Models
Subproblems: I/O Channels, Internal Components, Subagents and Superagents.
Summary: The stated aim [AF · GW] of this sequence by John Wentworth is to prove a selection theorem of the form: if a system robustly steers far away parts of the world into a relatively-small chunk of their state space, the system is very likely doing search over an internal world model. I believe the quest is ongoing.
John's methodology is to start with a low-level model of the world, and try to derive familiar concepts of agency from that. He argues that causal models are a good place to start, since they don't assume assume a universal notion of time [? · GW] and allow us to easily rewrite chunks at different levels of abstraction [? · GW].
Then he gets to work: showing that maximising expected utility can be thought of as minimising the world's description length [? · GW] with respect to a particular model; suggesting a definition of actions and observations as information well-preserved at a distance [? · GW], which implies a flexible Cartesian boundary; identifying the problem of finding a 'measuring stick of utility [? · GW]' to prove coherence theorems with respect to; and thinking about how such a measuring stick might arise in agents consisting of distributed subagents [? · GW].
Shard Theory
Subproblems: Internal Components.
Summary: Shard theory [? · GW] is an informal model of the internal components of agents, meant to describe both reinforcement learners and humans. The model looks something like this:
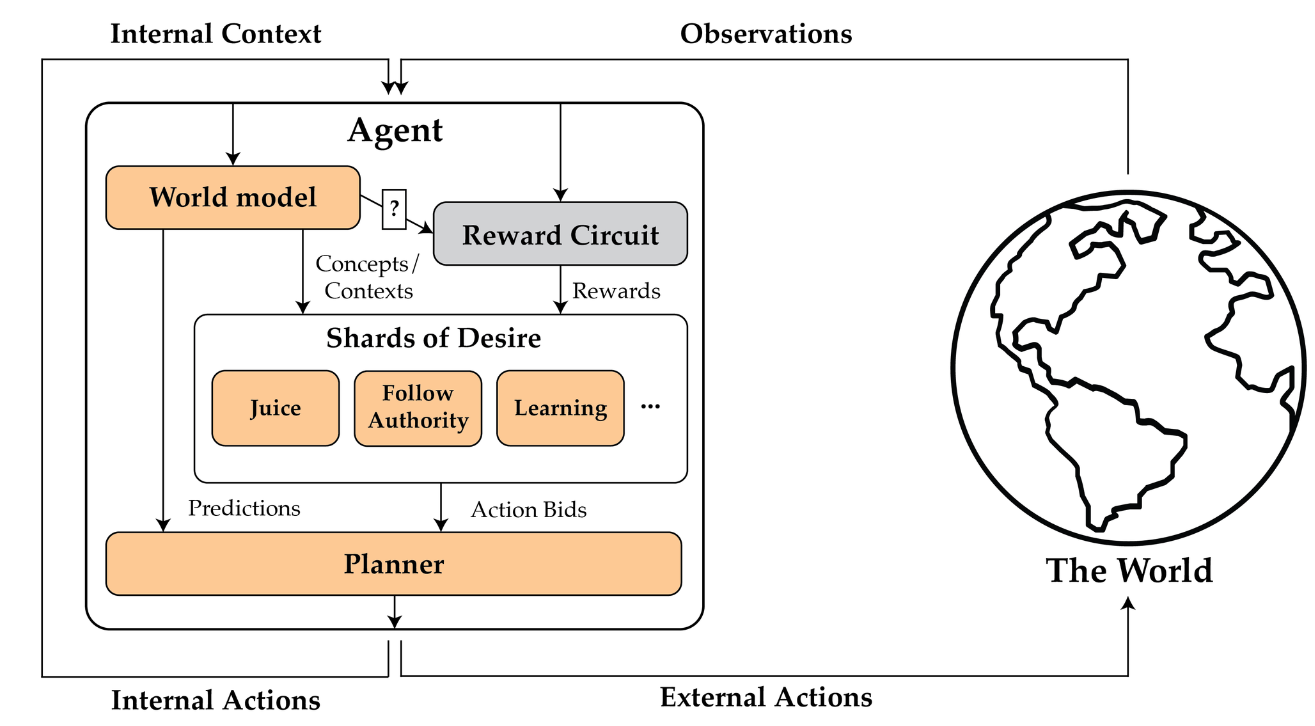
Goals are represented as 'shards of desire' for concepts in the agent's world model, like juice or following the rules. In a given context set by the world-model, some subset of shards are active. An active shard influences the agent's planning algorithm towards taking actions that lead to things the shard values, as predicted by the world-model.
Suppose your mum tells you you're not allowed any more juice. Your follow-the-rules shard bids for you to comply, and wins out. But when you happen to open the fridge and see the carton, your juice shard becomes more active, and suddenly a quick swig doesn't seem like such a bad idea. These contextually activated desires arise from your reward circuitry reinforcing different cognition in different contexts - wanting juice often leads to reward when you're standing in front of the fridge, but not so much in other situations.
If shard theory's model is correct, there are various implications. We shouldn't think of RL agents as reward maximisers [? · GW], and at first they won't look much like they're maximising any utility function at all - but over time, more agentic shards may take over and eventually coalesce into a reflective equilibrium that looks more like traditional models of agency. But the values of the final agent will be highly path dependent, and we can probably do a lot to shape them with clever training schedules.
This last point seems to be the main theory of change for shard theory - I don't think its proponents are hoping to understand shards so well mathematically that we can directly tinker with them inside neural networks. Instead they hope to develop arguments about what sorts of training regimes should lead RL agents to internalise the concepts we care about.
The Causal Incentives Agenda
Subproblems: Agents in Practice.
Summary: The causal incentives approach to the alignment problem is mostly defined by the tools it attacks it with, causal influence diagrams, which look like this:
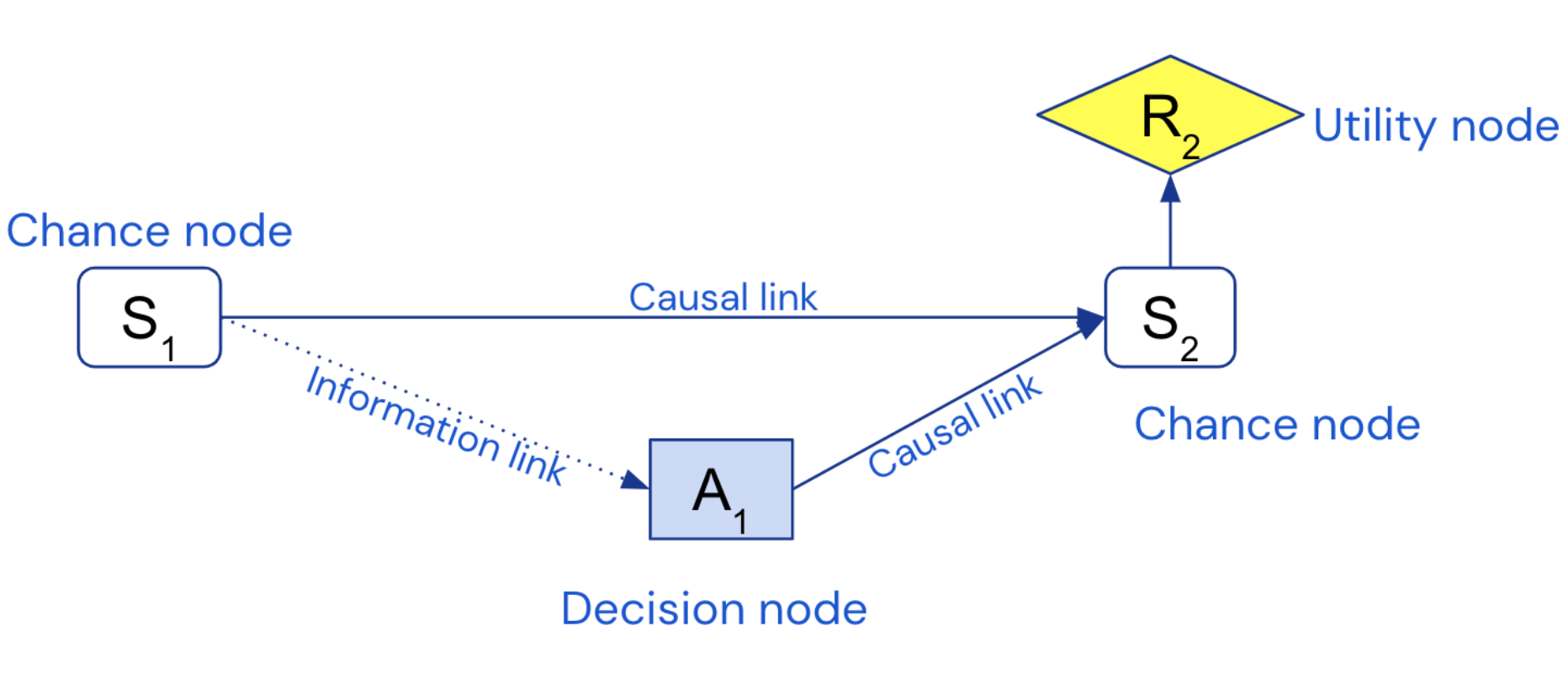
A causal influence diagram is a Pearl-style causal model with the variables partitioned into chance, utility and decision nodes. The decision nodes are special in that we don't define a conditional probability distribution over them. Usually you take some ML training setup or other strategic interaction between agents, model it as a CID, figure out how the decision variables would have to be distributed to maximise expected utility, and study the properties of the model that arises. One thing CIDs have been used for is to develop a formal theory of agents' incentives (spoiler: human deciding reward => incentive to manipulate human). Another paper, Discovering Agents [AF · GW], suggests a behavioural definition of agency and an algorithm for identifying them in principle. I think all of this comes under descriptive agent foundations, since it's concerned with how we should expect agents to behave - in specific situations in the case of agent incentives, and at the most abstract level in the case of discovering agents.
More generally, the philosophy behind causal incentives is that many important properties to do with agency and alignment are causal in nature, and therefore that causal influence diagrams are a good language with which to develop a formal calculus of alignment. Most causal incentives work is about turning intuitive ideas into formal definitions in a spirit of conceptual clarification. An underlying assumption is that it's most fruitful to look at what goes on outside an agent - its training data, the way its rewards are calculated, the situations it finds itself in - and that if there are important properties of the agent's internals, they can probably be derived as a consequence. This sounds like a selection theorems-esque stance, and indeed some recent causal incentives work is moving in that direction.
A difference between the use of causal models in this work and in the Basic Foundations for Agent Models sequence is that while John assumes a model of the world at a low level of abstraction and tries to derive things like actions, observations, and utilities, causal incentives work assumes a model in which the variables are already at that level of abstraction.
Normative
Decision Theory
Subproblems: Decision Theory.
Summary: The usual setup for decision theory [? · GW] is that you're selecting from a set of actions, and you have some beliefs about the way your utility depends on your choice. You want to maximise expected utility, but the question is which dependencies you should factor in when calculating it. The traditional academic debate is whether you should only care about the causal effects of your decision, or also about the evidence it provides. Work on decision theory from the alignment community is more about two other ideas.
The first is a debate about whether you should be 'updateless' - meaning that instead of choosing the action which is best in the current moment, you choose the action which you ideally would have precomitted to if you'd had the opportunity. Making binding precomittments has undeniable strategic advantages; the question is whether you should choose the action you would have been best off precomitting to even if you haven't. And which point in time should you choose the best precomittment with respect to: the day you decided your decision theory, the moment of your birth, or a point before the universe began? Another question is whether updatelessness is a matter of strategy, or preferences - perhaps you should only be updateless if you care about counterfactual versions of you just as much as yourself [LW · GW].
The second is the idea of 'logical dependence'. One way to think about this that instead of imagining that you're deciding whether you taking an action right here right now, you could imagine you're deciding whether agents like you take the action in situations like this. This is an intuitively compelling idea which 'performs well' in thought experiments, but has proved hard to formalise. Updateless decision theory (UDT) [LW · GW] aims to formalise it in terms of your decision resolving logical uncertainty about the output of your source code. Functional decision theory (FDT) aims to formalise it as an alternative notion of causality to the ordinary 'physical' Pearlian notion. Proof-based decision theory [LW · GW] aims to formalise it in Peano arithmetic. So far, none of these efforts say much about how an agent in the real world could obtain beliefs about which variables logically depend on its decision.
Logical Induction
Subproblems: Embedded World-Models.
Summary: AIXI uses Solomonoff induction, which comes with all the standard guarantees of Bayesian reasoning. Bayesian reasoners are logically omniscient, instantly realising the full consequences of their observations and their beliefs accordingly. They can never be Dutch booked.
Agents in the real world do not automatically realise all of the logical consequences of their observations. They have limited compute with which to figure that stuff out, and they have to apply it tactically. Logical induction is a way of doing it. It can't prevent agents from being Dutch-booked, but it can minimise the damage.
An agent satisfies the logical induction criterion, if, roughly, that there's no efficiently computable way to exploit it to earn unbounded profits with finite risk tolerance. In a 2016 paper, Garrabrant et al. state the criterion, give a computable induction algorithm that satisifes it, and show that lots of desirable properties follow.
Infra-Bayesianism
Subproblems: Decision Theory, Embedded World-Models.
Infra-Bayesianism feels like the most direct attempt to figure out an embedded version of AIXI.
It directly attacks the problem of non-realisability - the thing where unlike AIXI, an agent in the real world cannot maintain fully-detailed hypotheses about the way its environment works, since one small and simple part of the world cannot model the large and complex whole.
The basic idea is to replace precise hypotheses like "I'm 99% sure that's a dog and I'm 50% sure it's friendly," with imprecise ones like "I'm 99% sure that's a dog and I simply don't know whether it's friendly." We can achieve this by just saying our hypothesis is the whole set of probability distributions which put 99% on the thing being a dog.
All of the subsequent maths of infra-Bayesianism is about figuring out how to recover stuff like belief updates, policy-selection and so on, given this change. For example, now that we lack a precise probabilistic belief about whether the dog is friendly, we can't compare the expected value of patting it versus not. Infra-Bayesianism's way around this it to assume the worst and evaluate each policy by the least expected value it achieves across the set of probability distributions we're indifferent between. Patting an unfriendly dog will turn out much worse than failing to pat a friendly one, so we leave it well alone.
The maths gets pretty heavy, but apparently something like updateless decision theory falls out naturally, and it seems like there might be provable performance guarantees.
Infra-Bayesian physicalism combines this stuff with some ideas about Occam's razor and anthropics, which I can't claim to understand.
Tiling Agents
Subproblems: Robust Delegation.
Summary: This is some old MIRI work from 2013 which aims to directly address the question of how an agent can self-modify while being confident its successors will share its goal.
It all takes place within a very specific formalism - an agent has a set of axioms, and only takes an action if it can prove in first-order logic that the action leads to the satisfaction of its goal. In order to take the action 'construct successor', the agent needs to prove that the successor's actions will lead to the satisfaction of the goal. Naively, the agent could just construct a successor that uses very same action-selection criterion. But there's a problem - Löb's theorem says if the agent's axioms are consistent, it will only be able to prove the action-selection criterion actually works if the successor's axioms are strictly mathematical weaker than its own. Not much of a successor!
Yudkoskwy and co. find some ways around the Löbian obstacle in settings with nice properties, and start to generalise the results to probabilistic settings, but ultimately conclude the underyling problems are only 'partially adressed'.
Produced as part of the SERI ML Alignment Theory Scholars Program - Winter 2022 Cohort.
Thanks to Lawrence Chan, Carson Jones, Dávid Matolcsi and Magdalena Wache for feedback.
- ^
A more careful wording would be the AIXI model assumes the agent's actions affect the world in well-defined way.
1 comments
Comments sorted by top scores.
comment by Roman Leventov · 2023-05-19T08:12:07.709Z · LW(p) · GW(p)
Existing models of agency from fields like reinforcement learning and game theory don't seem up to the job, so trying to develop better ones might pay off.
One account of why our usual models of agency aren't up to the job is the Embedded Agency [? · GW] sequence - the usual models assume agents are unchanging, indivisible entities which interact with their environments through predefined channels, but real-world agents are a part of their environment. The sequence lists identifies four rough categories of problems that arise when we switch to trying to model embedded agents, explained in terms of Marcus Hutter's model of the theoretically perfect reinforcement learning agent, AIXI.
Reinforcement learning and game theory are mathematical formalisms/frameworks (and some associated algorithms, such as many specific RL learning algorithms) But they are not science in themselves. "Embedded Agency" basically says "Let's do cognitive science rather than develop mathematical formalisms in isolation from science".
Then, there is a question of whether we want to predict something about any intelligent[1] systems (extremely general theory of cognition/agency) so that our predictions (or ensuing process frameworks of alignment) are robust to paradigm shifts in ML/AI, perhaps even right during the recursive self-improvement phase, or we want to prove something about intelligent systems engineered in a particular way.
For the first purpose, I know of three theories/frameworks that are probably not worse than any of the theories that you mentioned:
- Free Energy Principle, Ramstead et al., 2023 (the latest and most up-to-date overview)
- Thermodynamic ML, Boyd et al., 2022
- Maximal Coding Rate Reduction Principle (MCR^2), Ma et al., 2022
For the second purpose, there is nothing wrong with building an AI as an RL system (for example) and then basing a process framework of alignment (corrigibility, control, etc.) of it exactly on the RL formalism because the system was specifically built to conform to it. From this perspective, RL, game theory, control theory, H-JEPA [LW · GW], Constitutional AI for LLMs, and many other theories, formalisms, architectures, and algorithms will be instrumental to developing a safe AI in practice. Cf. "For alignment, we should simultaneously use multiple theories of cognition and value [LW · GW]".
- ^
Often these theories extend to describe not just 'intelligent', whatever that means, but any non-equilibrium, adaptive systems (or, postulate that any non-equilibrium system is intelligent, in some sense).