Pointing to a Flower
post by johnswentworth · 2020-05-18T18:54:53.711Z · LW · GW · 18 commentsContents
“Why Not Just… ” Drawing Abstract Object Boundaries Test Cases Problems Testable Case? Summary None 18 comments
Imagine I have a highly detailed low-level simulation (e.g. molecular dynamics) of a garden. The initial conditions include a flower, and I would like to write some code to “point” to that particular flower. At any given time, I should be able to use this code to do things like:
- compute a bounding box around the flower
- render a picture which shows just the flower, with the background removed
- list all of the particles which are currently inside the flower
Meanwhile, it should be robust to things like:
- most of the molecules in the flower turning over on a regular basis
- the flower moving around in space and/or relative to other flowers
- the flower growing, including blooming/wilting/other large morphological change
- other flowers looking similar
That said, there’s a limit to what we can expect; our code can just return an error if e.g. the flower has died and rotted away and there is no distinguishable flower left. In short: we want this code to capture roughly the same notion of “this flower” that a human would.
We’ll allow an external user to draw a boundary around the flower in the initial conditions, just to define which object we’re talking about. But after that, our code should be able to robustly keep track of our particular flower.
How could we write that code, even in principle?
“Why Not Just… ”
There’s a lot of obvious hackish ways to answer the question - and obvious problems/counterexamples for each of them. I’ll list a few here, since the counterexamples make good test cases for our eventual answer, and illustrate just how involved the human concept of a flower is.
- Flower = molecules inside the flower-boundary at time zero. Problem: most of the molecules comprising a flower turn over on a regular basis.
- Flower = whatever’s inside the boundary which defined the flower at time zero. Counterexample: the flower might move.
- Flower = things which look (in a rendered image) like whatever was inside the boundary at time zero. Counterexample: the flower might bloom/wilt/etc. Another counterexample: there may be other, similar-looking flowers.
- Flower = instance of a recurring pattern in the data, defined by clustering. Counterexample: there may not be any other flowers. (More generally: we can recognize “weird” objects in the world which don’t resemble anything else we’ve ever seen.)
- Flower = region of high density contiguous in space-time with our initial region. Counterexample: we can dunk the flower in a bucket of water.
- Flower = contents of lipid bilayer membranes which also contain DNA sequence roughly identical to the consensus sequence of all DNA within the initial boundary, plus anything within a few microns of those membranes. Counterexample: it’s still the same flower if we blow it up via expansion microscopy and the individual cells lyse in the process. (Also this wouldn’t generalize to non-biological objects, or even clonal organisms.)
Drawing Abstract Object Boundaries
The general conceptual challenge here is how to define an abstract object - an object which is not an ontologically fundamental component of the world, but an abstraction on top of the low-level world.
In previous [? · GW] posts [? · GW] I’ve outlined a fairly-general definition of abstraction: far-apart components of a low-level model are independent given some high-level summary data. We imagine breaking our low-level system variables into three subsets:
- Variables X which we want to abstract
- Variables Y which are “far away” from X
- Noisy “in-between” variables Z which moderate the interaction between X and Y
The noise in Z wipes out most of the information in X, so the only information from X which is relevant to Y is some summary f(X).
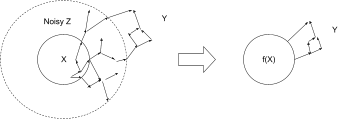
(I’ve sketched this as a causal DAG for concreteness, which is how I usually visualize it.) I want to claim that this is basically the right way to think about abstraction quite generally - so it better apply to questions like “what’s an abstract object?”.
So what happens if we apply this picture directly to the flower problem?
First, we need to divide up our low-level variables into the flower (X), things far away from the flower (Y), and everything in-between (noisy Z). I’ll just sketch this as the flower itself and a box showing the boundary between “nearby” and “far away”:
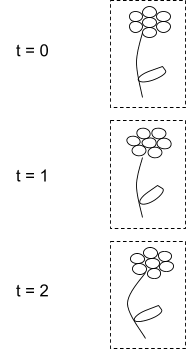
Notice the timesteps in the diagram - both the flower and the box are defined over time, so we imagine the boundaries living in four-dimensional spacetime, not just at one time. (Our user-drawn boundary in the initial condition constrains the full spacetime boundary at time zero.)
Now the big question is: how do we decide where to draw the boundaries? Why draw boundaries which follow around the actual flower, rather than meandering randomly around?
Let’s think about what the high-level summary f(X) looks like for boundaries which follow the flower, compared to boundaries which start around the flower (i.e. at the user-defined initial boundary) but don’t follow it as it moves. In particular, we’ll consider what information about the initial flower (i.e. flower at time zero) needs to be included in f(X).
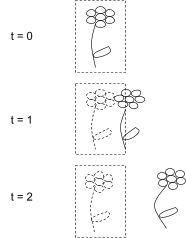
The “true” flower moves, but the boundaries supposedly defining the “flower” don’t follow it. What makes such boundaries “worse” than boundaries which do follow the flower?
There’s a lot of information about the initial flower which could be included in our summary f(X): the geometry of the flower’s outer surface, its color and texture, temperature at each point, mechanical stiffness at each point, internal organ structure (e.g. veins), relative position of each cell, relative position of each molecule, … Which of these need to be included in the summary data for boundaries moving with the flower, and which need to be included in the summary data for boundaries not moving with the flower?
For example: the flower’s surface geometry will have an influence on things outside the outer boundary in both cases. It will affect things like drag on air currents, trajectories of insects or raindrops, and of course the flower-image formed on the retina of anyone looking at it. So the outer surface geometry will be included in the summary f(X) in both cases. On the other hand, relative positions of cells inside the flower itself are mostly invisible from far away if the boundary follows the flower.
But if the boundary doesn’t follow the flower… then the true flower is inside the boundary at the initial time, but counts as “far away” at a later time. And the relative positions of individual cells in the true flower will mostly stay stable over time, so those relative cell positions at time zero contain lots of information about relative cell positions at time two… and since the cells at time two counts as “far away”, that means we need to include all that information in our summary f(X).
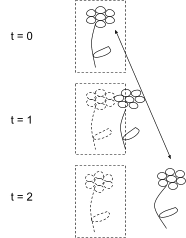
Strong correlation between low-level details (e.g. relative positions of individual cells) inside the spacetime boundary and outside. That information must be included in the high-level summary f(X).
The takeaway from this argument is: if the boundary doesn’t follow the true flower, then our high-level summary f(X) must contain far more information. Specifically, it has to include tons of information about the low-level internal structure of the flower. On the other hand, as long as the true flower remains inside the inner boundary, information about that low-level structure will mostly not propagate outside the outer boundary - such fine-grained detail will usually be wiped out by the noisy variables “nearby” the flower.
This suggests a formalizable approach: the “true flower” is defined by a boundary which is locally-minimal with respect to the summary data f(X) required to capture all its mutual information with “far-away” variables.
Test Cases
Before we start really attacking this approach, let’s revisit the problems/counterexamples from the hackish approaches:
- Molecular turnover: not a problem. The relevant information does not follow the individual molecules.
- Flower might move: not a problem. We basically discussed that directly in the previous section.
- Flower might bloom/wilt/etc: not a problem. Mutual information still follows the same pattern, although note that once the flower rots away altogether, we can draw a time-boundary indicating that the flower no longer exists, and indeed we expect everything significantly after that in time to be roughly independent of our former flower.
- Similar-looking flowers: not a problem. We’re explicitly relying on the low-level internal structure to define the flower boundary.
- No other flowers: not a problem. We’re not relying on clustering or any other data from other flowers.
- Dunk flower in a bucket of water: not a problem. Noisy water molecules “nearby” the flower will wipe out low-level detailed information about as well as noisy air molecules, if not better.
- Expansion microscopy: not a problem. The information in the flower’s low-level structure sticks around in its expanded form. Indeed, expansion microscopy wouldn’t be very useful otherwise.
Main takeaway: this approach is mainly about information contained in the low-level structure of the flower (i.e. cells, organs, etc). Physical interactions which maintain that low-level structure will generally maintain the flower-boundary - and a physical interaction which destroys most of a flower’s low-level structure is generally something we’d interpret as destroying the flower.
Problems
Let’s start with the obvious: though it’s formalizable, this isn’t exactly formalized. We don’t have an actual test-case following around a flower in-silico, and given how complicated that simulation would be, we’re unlikely to have such a test case soon. That said, next section will give a computationally simpler test-case which preserves most of the conceptual challenges of the flower problem.
First, though, let’s look at a few conceptual problems.
What about perfect determinism?
This approach relies on high mutual information between true-flower-at-time-zero and true-flower-at-later-times. That requires some kind of uncertainty or randomness.
There’s a lot places for that to come from:
- We could have ontologically-basic randomness, e.g. quantum noise
- We could have deterministic dynamics but random initial conditions
- More realistically, we could have some sort of observer in the system with Bayesian uncertainty about the low-level details of the world.
That last is the “obvious” answer, in some sense, and it’s a good answer for many purposes. I’m still not completely satisfied with it, though - it seems like a superintelligence with extremely precise knowledge of every molecule in a flower should still be able to use the flower-abstraction, even in a completely deterministic world.
Why/how would a “flower”-abstraction make sense under perfect determinism? What notion of locality is even present in such a system? When I probe my intuition, my main answer is: causality. I’m imagining a world without noise, but that world still has a causal structure similar to our world, and it’s that causal structure which makes the “flower” make sense.
Indeed, causal abstraction allows us to apply the ideas above directly to a deterministic world. The only change is that f(X) no longer only summarizes probabilistic information; it must also summarize any information needed to predict far-away variables under interventions (on either internal or far-away variables).
Of course, in practice, we’ll probably also want to include those interventional-information constraints even in the presence of uncertainty.
What about fine-grained information carried by, like, microwaves or something?
If we just imagine a physical outer boundary some distance from a flower (let’s say 3 meters), surely some clever physicists could figure out a way to map out the flower’s internal structure without crossing within that boundary. Isn’t information about the low-level structure constantly propagating outward via microwaves or something, without being wiped out by noisy air molecules on the way?
Two key things to keep in mind here:
- The boundary need not be a physical boundary; the “boundaries” just denote subsets of the variables of the model. If the model includes microwaves, we can just declare them all to be “nearby” the flower. Whenever they actually interact with molecules outside the flower, barring instruments specifically set up to detect them, the information they carry should be wiped out quite quickly by statistical-mechanical noise.
- In practice, we don’t just want to abstract one object. We want a whole high-level world model, full of abstract objects. The “far-away variables” will be variables within all the other high-level objects. So in order for microwaves to matter, they need to carry information from one object to another, without that information being wiped out by low-level noise.
Note that we’re talking about noise a lot here - does this problem play well with deterministic universes, where causality constrains f(X) more than plain old information? I expect the answer is yes - chaos makes low-level interventions look basically like noise for our purposes. But that’s another very hand-wavy answer.
What if we draw a boundary which follows around every individual particle which interacts with the flower?
Presumably we could get even less information in f(X) by choosing some weird boundary. The easy way to solve this is to add boundary complexity to the information contained in f(X) when judging how “good” a boundary is.
Humans seem to use a flower-abstraction without actually knowing the low-level flower-structure.
Key point: we don’t need to know the low-level flower-structure in order to use this approach. We just need to have a model of the world which says that the flower has some (potentially unknown) low-level structure, and that the low-level structure of flower-at-time-zero is highly correlated with the low-level structure of flower-at-later-times.
Indeed, when I look at a flower outside my apartment, I don’t know its low-level details. But I do expect that, for instance, the topology of the veins in that flower is roughly the same today as it was yesterday.
In fact, we can go a step further: humans lack-of-knowledge of the low-level structure of particular flowers is one of the main reasons we should expect our abstractions to look roughly like the picture above. Why? Well, let’s go back to the original picture from the definition:
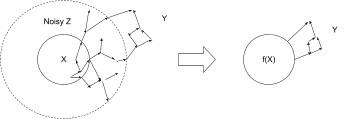
Key thing to notice: since Y is independent of all the low-level details of X except the information contained in f(X), f(X) contains everything we can possibly learn about X just by looking at Y.
In terms of flowers: our “high-level summary data” f(X) contains precisely the things we can figure out about the flower without pulling out a microscope or cutting it open or otherwise getting “closer” to the flower.
Testable Case?
Finally, let’s outline a way to test this out more rigorously.
We’d like some abstract object which we can simulate at a “low-level” at reasonable computational cost. It should exhibit some of the properties relevant to our conceptual test-cases from earlier: components which turn over, moves around, change shape/appearance, might be many or just one, etc. Just those first two properties - components which turn over and object moving around - immediately suggest a natural choice: a wave.
- In a particle view, the underlying particles comprising the wave change over time
- The wave moves around in space and relative to other waves
- The wave may change shape (due to obstacles, dissipation, nonlinearity, etc)
- There may be other similar-looking waves in the environment or no other waves
I’d be interested to hear if this sounds to people like a sensible/fair test of the concept.
Summary
We want to define abstract objects - objects which are not ontologically fundamental components of the world, but are instead abstractions on top of a low-level world. In particular, our problem asks to track a particular flower within a molecular-level simulation of a garden. Our method should be robust to the sorts of things a human notion of a flower is robust to: molecules turning over, flower moving around, changing appearance, etc.
We can do that with a suitable notion of abstraction [? · GW]: we have summary data f(X) of some low-level variables X, such that f(X) contains all the information relevant to variables “far away”. We’ve argued that, if we choose X to include precisely the low-level variables which are physically inside the flower, and mostly use physical distance to define “far-away” (modulo microwaves and the like), then we’d expect the information-content of f(X) to be locally minimal. Varying our choice of X subject to the same initial conditions - i.e. moving the supposed flower-boundary away from the true flower - requires f(X) to contain more information about the low-level structure of the flower.

18 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2020-05-19T21:48:49.016Z · LW(p) · GW(p)
I think the human brain answer is close to "Flower = instance of a recurring pattern in the data, defined by clustering" with an extra footnote that we also have easy access to patterns that are compositions of other known patterns. For example, a recurring pattern of "rubber" and recurring pattern of "wine glass" can be glued into a new pattern of "rubber wine glass", such that we would immediately recognize one if we saw it. (There may be other footnotes too.)
Given that I believe that's the human brain answer, I'm immediately skeptical that a totally different approach could reliably give the same answer. I feel like either there's gotta be lots of cases where your approach gives results that we humans find unintuitive, or else you're somehow sneaking human intuition / recurring patterns into your scheme without realizing it. Having said that, everything you wrote sounds reasonable, I can't point to any particular problem. I dunno.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-19T22:25:37.153Z · LW(p) · GW(p)
I didn't really talk about it in the OP, but I think the OP's approach naturally pops out if we're doing roughly-Bayesian-clustering (especially in a lazy way).
The key question is: if we don't directly observe the low-level structure of the flower, why do we believe that it's consistent over time (to some extent) in the first place? The answer to that question is that there's some clustering/Bayesian model comparison going on. We deduce the existence of some hidden variables which cause those predictable patterns in our observations, and those hidden variables are exactly the low-level structure which the OP talks about.
The neat thing about the approach in the OP is that we're talking about seeing the underlying structure behind the cluster more directly; we've removed the human observer from the picture, and grounded things at a lower level, so it's less dependent on the exact data which the observer receives.
Another way to put it: the OP's approach is to look for the sort of structures which roughly-Bayesian-clustering could, in principle, be able to identify.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-05-20T10:25:55.032Z · LW(p) · GW(p)
If you're saying that "consistent low-level structure" is a frequent cause of "recurring patterns", then sure, that seems reasonable.
Do they always go together?
-
If there are recurring patterns that are not related to consistent low-level structure, then I'd expect an intuitive concept that's not an OP-type abstraction. I think that happens: for example any word that doesn't refer to a physical object: "emotion", "grammar", "running", "cold", ...
-
If there are consistent low-level structures that are not related to recurring patterns, then I'd expect an OP-type abstraction that's not an intuitive concept. I can't think of any examples. Maybe consistent low-level structures are automatically a recurring pattern. Like, if you make a visualization in which the low-level structure(s) is highlighted, you will immediately recognize that as a recurring pattern, I guess.
↑ comment by johnswentworth · 2020-05-20T16:29:56.487Z · LW(p) · GW(p)
Yeah, these seem right.
comment by Charlie Steiner · 2020-05-19T09:04:16.191Z · LW(p) · GW(p)
I think a wave would be a good test in a lot of ways, but by being such a clean example it might miss some possible pitfalls. The big one is, I think, the underdetermination of pointing at a flower - a flower petal is also an object even by human standards, so how could the program know you're not pointing at a flower petal? Even more perversely, humans can refer to things like "this cubic meter of air."
In some sense, I'm of the opinion that solving this means solving the frame problem - part of what makes a flower a flower isn't merely its material properties, but what sorts of actions humans can take in the environment, what humans care about, how our language and culture shape how we chunk up the world into labels, and what sort of objects we typically communicate about by pointing versus other signals.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-19T16:53:24.564Z · LW(p) · GW(p)
Those examples bring up some good points that didn't make it into the OP:
- Objects are often composed of subobjects - a flower petal is an object in its own right. Assuming the general approach of the OP holds, we'd expect a boundary which follows around just the petal to also be a local minimum of required summary data. Of course, that boundary would not match the initial conditions of the problem in the OP - that's why we need the boundary at time zero to cover the flower, not just one petal.
- On the other hand, the north half of the flower is something we can point to semantically (by saying "north half of the flower"), but isn't an object in its own right - it's not defined by a locally-minimal boundary. "This cubic meter of air" is the same sort of thing. In both cases, note that there isn't really a well-defined object which sticks around over time - if I point to "this cubic meter of air", and then ask where that cubic meter of air is five minutes later, there's not a natural answer. Could be the same cubic meter (in some reference frame), the same air molecules, the cubic meter displaced along local wind currents, ...
Regarding the frame problem: there are many locally-minimal abstract-object-boundaries out there. Humans tend to switch which abstractions they use based on the problem at hand - e.g. thinking of a flower as a flower or as petals + leaves + stem or as a bunch of cells or... That said, the choice is still very highly constrained: if just draw a box around a random cubic meter of air, then there is no useful sense in which that object sticks around over time. It's not just biological hard-wiring that makes different human cultures recognize mostly-similar things as objects - no culture has a word for the north half of a flower or a particular cubic meter of air. The cases where different cultures do recognize entirely different "objects" are interesting largely because they are unusual.
(We could imagine a culture with a word for the north half of a flower, and we could guess why such a word might exist: maybe the north half of the flower gets more sun unless it's in the shade, so that half of the flower in particular contains relevant information about the rest of the world. We can immediately see that the approach of the OP applies directly here: the north half of the flower specifically contains information about far-away things. The subjectivity is in picking which "far-away" things we're interested in.)
Point is: I do not think that the set of possible objects is subjective in the sense of allowing any arbitrary boundary at all. However, which objects we reason about for any particular problem does vary, depending on what "far-away" things we're interested in.
A key practical upshot is that, since the set of sensible objects doesn't include things like a random chunk of space, we should be able to write code which recognizes the same objects as humans without having to point to those objects perfectly. A pointer (e.g. the initial boundary in the OP) can be "good enough", and can be refined by looking for the closest local minimum.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2020-05-19T21:43:52.447Z · LW(p) · GW(p)
So I'm betting, before really thinking about it, that I can find something as microphysically absurd as "the north side of the flower." How about "the mainland," where humans use a weird ontology to draw the boundary in, that makes no sense to a non-human-centric ontology? Or parts based on analogy or human-centric function, like being able to talk about "the seat" of a chair that is just one piece of plastic.
On the Type 2 error side, there are also lots of local minima of "information passing through the boundary" that humans wouldn't recognize. Like "the flower except for cell #13749788206." Often, the boundary a human draws is a fuzzy fiction that only needs to get filled in as one looks more closely - maybe we want to include that cell if it goes on to replicate, but are fine with excluding it if it will die soon. But humans don't think about this as a black box with Laplace's Demon inside, they think about it as using future information to fill in this fuzzy boundary when we try to look at it closer.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-19T22:52:54.895Z · LW(p) · GW(p)
I don't think "the mainland" works as an example of human-centric-ontology (pretty sure the OP approach would consider that an object), but "seat of a chair" might, especially for chairs all made of one piece of plastic/metal. At the very least, it is clear that we can point to things which are not "natural" objects in the OP's sense (e.g. a particular cubic meter of air), but then the question is: how do we define that object over time? In the chair example, my (not-yet-fully-thought-out) answer is that the chair is clearly a natural object, and we're able to track the "seat" over time mainly because it's defined relative to the chair. If the chair dramatically changes its form-factor, for instance, then there may no longer be a natural-to-a-human answer to the question "which part of this object is the seat?" (and if there is a natural answer, then it's probably because the seat was a natural object to begin with, for instance maybe it's a separate piece which can detach).
I do agree that there are tons of "objects" recognized by this method which are not recognized by humans - for instance, objects like cells, which we now recognize but once didn't. But I think a general pattern is that, once we point to such an example, we think "yeah, that's weird, but it's definitely a well-defined object - e.g. I can keep track of it over time". The flower-minus-one-cell is a good example of this: it's not something a human would normally think of, but once you point to it, a human would recognize this as a well-defined thing and be able to keep track of it over time. If you draw a boundary around a flower and one cell within that flower, then ask me to identify the flower-minus-a-cell some time later, that's a well-defined task which I (as a human) intuitively understand how to do.
I also agree that humans use different boundaries for different tasks and often switch to using other boundaries on the fly. In particular, I totally agree that there's some laziness in figuring out where the boundaries go. This does not imply that object-notions are ever fuzzy, though - our objects can have sharply-defined referents even if we don't have full information about that referent or if we're switching between referents quite often. That's what I think is mostly going on. E.g. in your cell-which-may-or-may-not-replicate example, there is a sharp boundary, we just don't yet have the information to determine where that boundary is.
comment by Florian Dietz (florian-dietz) · 2020-05-21T12:55:10.315Z · LW(p) · GW(p)
I don't think this problem has an objectively correct answer.
It depends on the reason because of which we keep track of the flower.
There are edge cases that haven't been listed yet where even our human intuition breaks down:
What if we teleport the flower Star-Trek style? Is the teleported flower the original flower, or 'just' an identical copy?
The question is also related to the Ship of Theseus.
If we can't even solve the problem in real-life because of such edge cases, then it would be dangerous to attempt to code this directly into a program.
Instead, I would write the program to understand this: Pragmatically, a lot of tasks get easier if you assume that abstract objects / patterns in the universe can be treated as discrete objects. But that isn't actually objectively correct. In edge cases, the program should recognize that it has encountered an edge case, and the correct response is neither Yes or No, but N/A.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-21T16:21:58.922Z · LW(p) · GW(p)
I'd distinguish between "there isn't an objectively correct answer about what the flower is" and "there isn't an objectively correct algorithm to answer the question". There are cases where the OP method's answer isn't unique, and examples of this so far (in the other comments) mostly match cases where human intuition breaks down - i.e. the things humans consider edge cases are also things the algorithm considers edge cases. So it can still be the correct algorithm, even though in some cases the "correct" answer is ambiguous.
comment by wizzwizz4 · 2020-05-19T18:26:38.056Z · LW(p) · GW(p)
This implies a solution to the "weak" Ship of Theseus problem: yes, it's the same ship.
I think this also implies a solution to the "strong" Ship of Theseus problem: "a new ship is created from the old parts" – but I'm less confident both that it implies this, and that it's the right conclusion to make. Consider also: mitosis. Which one is "the bacterium"™? But it doesn't quite make sense (to my fuzzy intuition) to say "the bacterium doesn't exist any more".
I think any such algorithm should be able to cope with both "the flower doesn't exist any more" and "the flower is now two flowers". I don't understand this one well enough to make suggestions.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-19T19:44:41.022Z · LW(p) · GW(p)
This is a good point. For all three of these (new ship from old parts, mitosis, and two flowers) the algorithm's answer would be that there are multiple admissible notions of what-the-relevant-object-is, i.e. multiple locally-minimal boundaries consistent with the initial conditions. And indeed, human intuition also recognizes that there are multiple reasonable notions of what-the-object-is. Different object-notions would be relevant to different queries (i.e. different sets of variables considered "far away").
E.g. in the strong ship of Theseus problem, low-level internal structure of the materials carries over from old to new ship, but their exact connections might not (i.e. nails might be in different places or boards in different order or even just new pitch on the hull). One ship-notion considers anything depending on those connections to be "nearby" (so that information can be safely thrown away), while the other ship-notion considers at least some things depending on those connections to be "far away" (so that information cannot be safely thrown away). On the other hand, if the ship is perfectly reconstructed down to a molecular level, then all of the information is carried over from old to new, and then the algorithm would unambiguously say it's the same ship.
comment by Dagon · 2020-05-18T19:54:12.386Z · LW(p) · GW(p)
This seems like a fairly small extension of a very well-studied problem in image recognition. Training a CNN to distinguish whatever your reference humans want to consider a flower, using 2- or 3-d image data (or additional dimensions or inputs, such as cell structures) seems pretty close to solved.
Abstraction is a sidetrack from that aspect of the problem. Humans seem to use abstraction for this, but that's because we introspect our operation badly. Humans use abstraction to COMMUNICATE and (perhaps) EXTRAPOLATE beyond the observed classification instances. The abstraction is a very efficient compression, necessary because it's impractical to communicate an entire embedding from one brain to another. And the compression may also be an important similarity mechanism to guess, for instance, what will happen if we eat one.
But abstraction is not fundamental to recognition - we have very deep neural networks for that, which we can't really observe or understand on their own level.
Replies from: johnswentworth, romeostevensit↑ comment by johnswentworth · 2020-05-18T20:42:01.663Z · LW(p) · GW(p)
The post already addresses multiple failure modes for 2d image recognition-style approaches, and I'll throw in one more for for 3d: underlying ontology shifts. Everything in the OP holds just fine if the low-level physics simulator switches from classical to quantum. Try that with a CNN.
Also, the problem statement does not say train to recognize a flower. There is no training data, other than whatever boundary is originally drawn around the one flower.
Replies from: Dagon↑ comment by Dagon · 2020-05-18T21:13:03.796Z · LW(p) · GW(p)
Sure, but the argument applies for whatever sensory input humans are using - audio, touch, and smell are similar (at this level) to vision - they're fairly deep neural networks with different layers performing different levels of classification. And the abstraction is a completely different function than the perception.
My main point is that introspectable abstraction is not fundamental to perception and distinguishing flower from not-flower. It _is_ important to communication and manipulation of the models, but your example of computing the 4D (including time as a dimension) bounding box for a specific flower is confusing different levels.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-18T21:30:25.467Z · LW(p) · GW(p)
I think you're confused about the problem. Recognizing a flower in an image is something solved by neural nets, yes. But the CNNs which solve that problem have no way to tell apart two flowers which look similar, absent additional training on that specific task - heck, they don't even have a notion of what "different flowers" means other than flowers looking different in an image.
I totally agree that abstraction (introspectable or not) is not fundamental to perception. Yet humans pretty clearly have a notion of "flower" which involves more than just what-the-flower-looks-like. That is the rough notion which the OP is trying to reconstruct.
Replies from: Dagon↑ comment by Dagon · 2020-05-21T15:24:50.499Z · LW(p) · GW(p)
The "absent training on that specific task" matters a lot here, as does the precise limits of "specific". There are commercially-available facial-identification (not just recognition) systems that are good enough for real-money payments, and they don't train on the specific faces to be recognized. Likewise commercial movement-tracking systems that care about history and continuity, in addition to image similarity (so, for instance, twins don't confuse them).
A flower-identification set of models would be easier than this, I expect.
↑ comment by romeostevensit · 2020-05-19T00:43:43.291Z · LW(p) · GW(p)
> and (perhaps) EXTRAPOLATE beyond the observed classification instances.
seems to be rolling a lot under the rug. Sample complexity reduction is likely a big chunk of transfer learning.