Superintelligence Reading Group 2: Forecasting AI
post by KatjaGrace · 2014-09-23T01:00:29.845Z · LW · GW · Legacy · 109 commentsContents
Summary In-depth investigations How to proceed None 109 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the second section in the reading guide, Forecasting AI. This is about predictions of AI, and what we should make of them.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. My own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post. Feel free to jump straight to the discussion. Where applicable, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: Opinions about the future of machine intelligence, from Chapter 1 (p18-21) and Muehlhauser, When Will AI be Created?
Summary
Opinions about the future of machine intelligence, from Chapter 1 (p18-21)
- AI researchers hold a variety of views on when human-level AI will arrive, and what it will be like.
- A recent set of surveys of AI researchers produced the following median dates:
- for human-level AI with 10% probability: 2022
- for human-level AI with 50% probability: 2040
- for human-level AI with 90% probability: 2075
- Surveyed AI researchers in aggregate gave 10% probability to 'superintelligence' within two years of human level AI, and 75% to 'superintelligence' within 30 years.
- When asked about the long-term impacts of human level AI, surveyed AI researchers gave the responses in the figure below (these are 'renormalized median' responses, 'TOP 100' is one of the surveyed groups, 'Combined' is all of them').
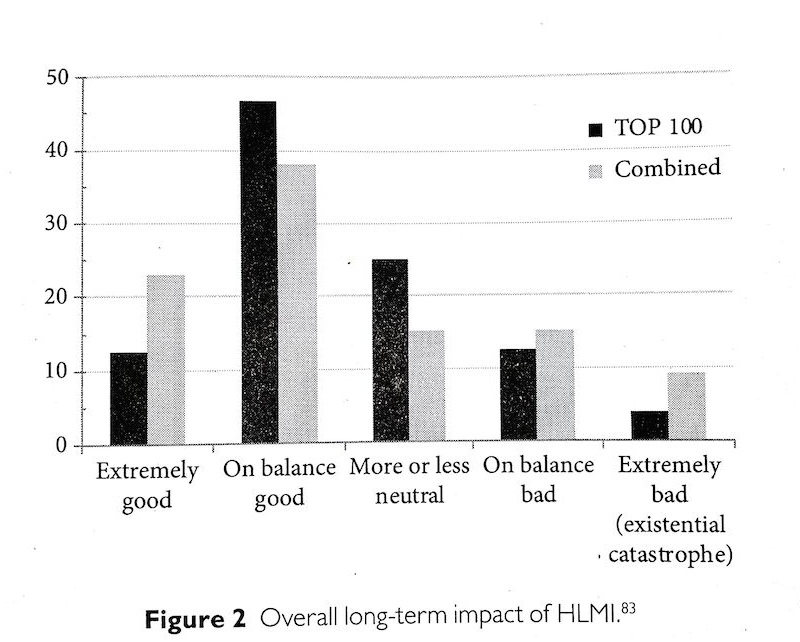
- There are various reasons to expect such opinion polls and public statements to be fairly inaccurate.
- Nonetheless, such opinions suggest that the prospect of human-level AI is worthy of attention.
- Predicting when human-level AI will arrive is hard.
- The estimates of informed people can vary between a small number of decades and a thousand years.
- Different time scales have different policy implications.
- Several surveys of AI experts exist, but Muehlhauser suspects sampling bias (e.g. optimistic views being sampled more often) makes such surveys of little use.
- Predicting human-level AI development is the kind of task that experts are characteristically bad at, according to extensive research on what makes people better at predicting things.
- People try to predict human-level AI by extrapolating hardware trends. This probably won't work, as AI requires software as well as hardware, and software appears to be a substantial bottleneck.
- We might try to extrapolate software progress, but software often progresses less smoothly, and is also hard to design good metrics for.
- A number of plausible events might substantially accelerate or slow progress toward human-level AI, such as an end to Moore's Law, depletion of low-hanging fruit, societal collapse, or a change in incentives for development.
- The appropriate response to this situation is uncertainty: you should neither be confident that human-level AI will take less than 30 years, nor that it will take more than a hundred years.
- We can still hope to do better: there are known ways to improve predictive accuracy, such as making quantitative predictions, looking for concrete 'signposts', looking at aggregated predictions, and decomposing complex phenomena into simpler ones.
- More (similar) surveys on when human-level AI will be developed
Bostrom discusses some recent polls in detail, and mentions that others are fairly consistent. Below are the surveys I could find. Several of them give dates when median respondents believe there is a 10%, 50% or 90% chance of AI, which I have recorded as '10% year' etc. If their findings were in another form, those are in the last column. Note that some of these surveys are fairly informal, and many participants are not AI experts, I'd guess especially in the Bainbridge, AI@50 and Klein ones. 'Kruel' is the set of interviews from which Nils Nilson is quoted on p19. The interviews cover a wider range of topics, and are indexed here.
10% year 50% year 90% year Other predictions Michie 1972
(paper download)Fairly even spread between 20, 50 and >50 years Bainbridge 2005 Median prediction 2085 AI@50 poll
200682% predict more than 50 years (>2056) or never Baum et al
AGI-092020 2040 2075 Klein 2011 median 2030-2050 FHI 2011 2028 2050 2150 Kruel 2011- (interviews, summary) 2025 2035 2070 FHI: AGI 2014 2022 2040 2065 FHI: TOP100 2014 2022 2040 2075 FHI:EETN 2014 2020 2050 2093 FHI:PT-AI 2014 2023 2048 2080 Hanson ongoing Most say have come 10% or less of the way to human level - Predictions in public statements
Polls are one source of predictions on AI. Another source is public statements. That is, things people choose to say publicly. MIRI arranged for the collection of these public statements, which you can now download and play with (the original and info about it, my edited version and explanation for changes). The figure below shows the cumulative fraction of public statements claiming that human-level AI will be more likely than not by a particular year. Or at least claiming something that can be broadly interpreted as that. It only includes recorded statements made since 2000. There are various warnings and details in interpreting this, but I don't think they make a big difference, so are probably not worth considering unless you are especially interested. Note that the authors of these statements are a mixture of mostly AI researchers (including disproportionately many working on human-level AI) a few futurists, and a few other people.
(LH axis = fraction of people predicting human-level AI by that date)
Cumulative distribution of predicted date of AI
As you can see, the median date (when the graph hits the 0.5 mark) for human-level AI here is much like that in the survey data: 2040 or so.
I would generally expect predictions in public statements to be relatively early, because people just don't tend to bother writing books about how exciting things are not going to happen for a while, unless their prediction is fascinatingly late. I checked this more thoroughly, by comparing the outcomes of surveys to the statements made by people in similar groups to those surveyed (e.g. if the survey was of AI researchers, I looked at statements made by AI researchers). In my (very cursory) assessment (detailed at the end of this page) there is a bit of a difference: predictions from surveys are 0-23 years later than those from public statements. - What kinds of things are people good at predicting?
Armstrong and Sotala (p11) summarize a few research efforts in recent decades as follows.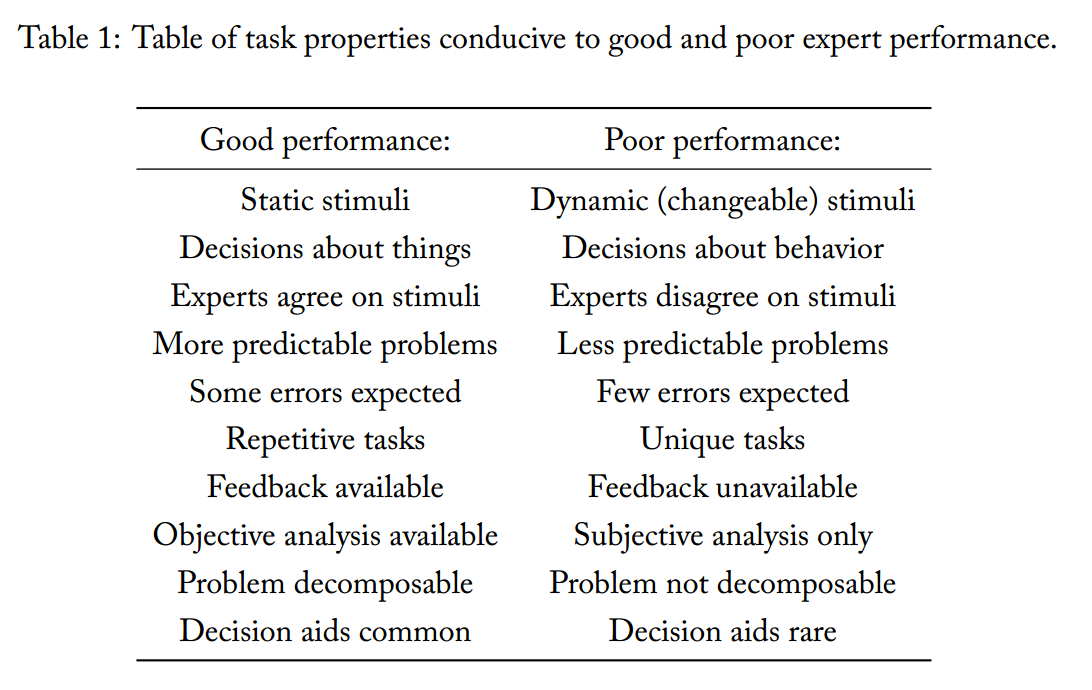
Note that the problem of predicting AI mostly falls on the right. Unfortunately this doesn't tell us anything about how much harder AI timelines are to predict than other things, or the absolute level of predictive accuracy associated with any combination of features. However if you have a rough idea of how well humans predict things, you might correct it downward when predicting how well humans predict future AI development and its social consequences. - Biases
As well as just being generally inaccurate, predictions of AI are often suspected to subject to a number of biases. Bostrom claimed earlier that 'twenty years is the sweet spot for prognosticators of radical change' (p4). A related concern is that people always predict revolutionary changes just within their lifetimes (the so-called Maes-Garreau law). Worse problems come from selection effects: the people making all of these predictions are selected for thinking AI is the best things to spend their lives on, so might be especially optimistic. Further, more exciting claims of impending robot revolution might be published and remembered more often. More bias might come from wishful thinking: having spent a lot of their lives on it, researchers might hope especially hard for it to go well. On the other hand, as Nils Nilson points out, AI researchers are wary of past predictions and so try hard to retain respectability, for instance by focussing on 'weak AI'. This could systematically push their predictions later.
We have some evidence about these biases. Armstrong and Sotala (using the MIRI dataset) find people are especially willing to predict AI around 20 years in the future, but couldn't find evidence of the Maes-Garreau law. Another way of looking for the Maes-Garreau law is via correlation between age and predicted time to AI, which is weak (-.017) in the edited MIRI dataset. A general tendency to make predictions based on incentives rather than available information is weakly supported by predictions not changing much over time, which is pretty much what we see in the MIRI dataset. In the figure below, 'early' predictions are made before 2000, and 'late' ones since then.
Cumulative distribution of predicted Years to AI, in early and late predictions.
We can learn something about selection effects from AI researchers being especially optimistic about AI from comparing groups who might be more or less selected in this way. For instance, we can compare most AI researchers - who tend to work on narrow intelligent capabilities - and researchers of 'artificial general intelligence' (AGI) who specifically focus on creating human-level agents. The figure below shows this comparison with the edited MIRI dataset, using a rough assessment of who works on AGI vs. other AI and only predictions made from 2000 onward ('late'). Interestingly, the AGI predictions indeed look like the most optimistic half of the AI predictions.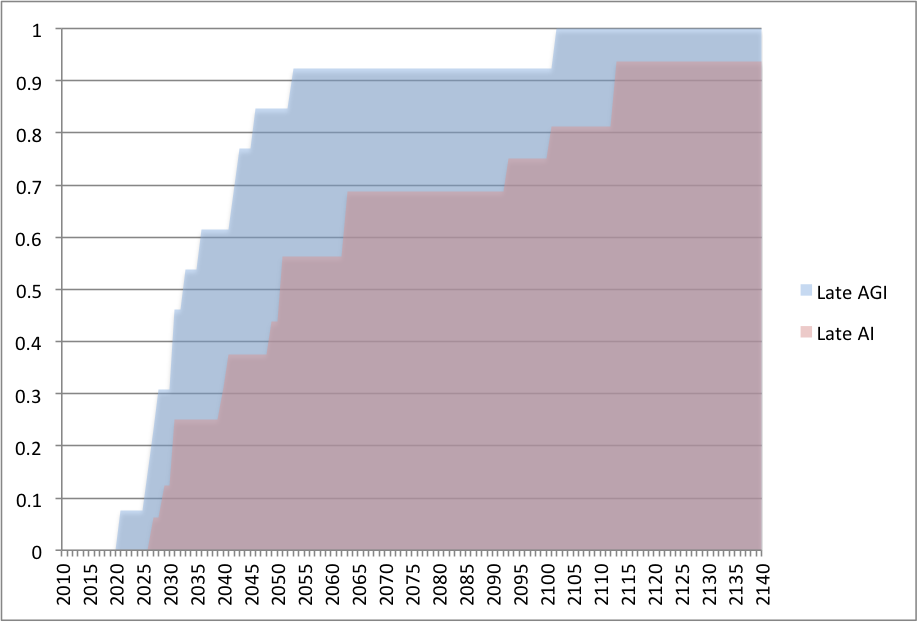
Cumulative distribution of predicted date of AI, for AGI and other AI researchers
We can also compare other groups in the dataset - 'futurists' and other people (according to our own heuristic assessment). While the picture is interesting, note that both of these groups were very small (as you can see by the large jumps in the graph).
Cumulative distribution of predicted date of AI, for various groups
Remember that these differences may not be due to bias, but rather to better understanding. It could well be that AGI research is very promising, and the closer you are to it, the more you realize that. Nonetheless, we can say some things from this data. The total selection bias toward optimism in communities selected for optimism is probably not more than the differences we see here - a few decades in the median, but could plausibly be that large.
These have been some rough calculations to get an idea of the extent of a few hypothesized biases. I don't think they are very accurate, but I want to point out that you can actually gather empirical data on these things, and claim that given the current level of research on these questions, you can learn interesting things fairly cheaply, without doing very elaborate or rigorous investigations. - What definition of 'superintelligence' do AI experts expect within two years of human-level AI with probability 10% and within thirty years with probability 75%?
“Assume for the purpose of this question that such HLMI will at some point exist. How likely do you then think it is that within (2 years / 30 years) thereafter there will be machine intelligence that greatly surpasses the performance of every human in most professions?” See the paper for other details about Bostrom and Müller's surveys (the ones in the book).
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some taken from Luke Muehlhauser's list:
- Instead of asking how long until AI, Robin Hanson's mini-survey asks people how far we have come (in a particular sub-area) in the last 20 years, as a fraction of the remaining distance. Responses to this question are generally fairly low - 5% is common. His respondents also tend to say that progress isn't accelerating especially. These estimates imply that any given sub-area of AI, human-level ability should be reached in about 200 years, which is strongly at odds with what researchers say in the other surveys. An interesting project would be to expand Robin's survey, and try to understand the discrepancy, and which estimates we should be using. We made a guide to carrying out this project.
- There are many possible empirical projects which would better inform estimates of timelines e.g. measuring the landscape and trends of computation (MIRI started this here, and made a project guide), analyzing performance of different versions of software on benchmark problems to find how much hardware and software contributed to progress, developing metrics to meaningfully measure AI progress, investigating the extent of AI inspiration from biology in the past, measuring research inputs over time (e.g. a start), and finding the characteristic patterns of progress in algorithms (my attempts here).
- Make a detailed assessment of likely timelines in communication with some informed AI researchers.
- Gather and interpret past efforts to predict technology decades ahead of time. Here are a few efforts to judge past technological predictions: Clarke 1969, Wise 1976, Albright 2002, Mullins 2012, Kurzweil on his own predictions, and other people on Kurzweil's predictions.
- Above I showed you several rough calculations I did. A rigorous version of any of these would be useful.
- Did most early AI scientists really think AI was right around the corner, or was it just a few people? The earliest survey available (Michie 1973) suggests it may have been just a few people. For those that thought AI was right around the corner, how much did they think about the safety and ethical challenges? If they thought and talked about it substantially, why was there so little published on the subject? If they really didn’t think much about it, what does that imply about how seriously AI scientists will treat the safety and ethical challenges of AI in the future? Some relevant sources here.
- Conduct a Delphi study of likely AGI impacts. Participants could be AI scientists, researchers who work on high-assurance software systems, and AGI theorists.
- Signpost the future. Superintelligence explores many different ways the future might play out with regard to superintelligence, but cannot help being somewhat agnostic about which particular path the future will take. Come up with clear diagnostic signals that policy makers can use to gauge whether things are developing toward or away from one set of scenarios or another. If X does or does not happen by 2030, what does that suggest about the path we’re on? If Y ends up taking value A or B, what does that imply?
- Another survey of AI scientists’ estimates on AGI timelines, takeoff speed, and likely social outcomes, with more respondents and a higher response rate than the best current survey, which is probably Müller & Bostrom (2014).
- Download the MIRI dataset and see if you can find anything interesting in it.
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about two paths to the development of superintelligence: AI coded by humans, and whole brain emulation. To prepare, read Artificial Intelligence and Whole Brain Emulation from Chapter 2. The discussion will go live at 6pm Pacific time next Monday 29 September. Sign up to be notified here.
109 comments
Comments sorted by top scores.
comment by KatjaGrace · 2014-09-23T01:26:26.180Z · LW(p) · GW(p)
I'm not convinced AI researchers are the most relevant experts for predicting when human-level AI will occur, nor the circumstances and results of its arrival. Similarly, I'm not convinced that excellence in baking cakes coincides that well with expertise in predicting the future of the cake industry, nor the health consequences of one's baking. Certainly both confer some knowledge, but I would expect someone with background in forecasting for instance to do better.
Replies from: KatjaGrace, paulfchristiano, private_messaging↑ comment by KatjaGrace · 2014-09-23T01:35:02.679Z · LW(p) · GW(p)
Relatedly, scientists involved in the Asilomar conference are sometimes criticized for failing to include people like epidemiologists, and other health experts at their conference to determine how recombinant DNA research should proceed (I think Krimsky makes this complaint). Almost all of the relevant experts were experts in recombinant DNA research, but the questions were often about how the research might harm society, for instance how diseases they accidentally produced might spread. They did include some lawyers, who apparently had a large effect.
↑ comment by paulfchristiano · 2014-09-23T02:33:08.978Z · LW(p) · GW(p)
Excellence at baking cakes is certainly helpful. I agree that there are other cake-experts who might be better poised to predict the future of the cake industry. I don't know who their analogs are in the case of artificial intelligence. Certainly it seems like AI researchers have access to some important and distinctive information (contra the cake example).
Replies from: SteveG, gallabytes↑ comment by SteveG · 2014-09-23T02:43:33.762Z · LW(p) · GW(p)
The cake industry is responding to market conditions. Their success depends on the number of buyers.
AI technology advances are quite marketable. The level of R&D investment in AI will depend on the marketability of these advances, on government investment, and on regulation.
Replies from: SteveG, TRIZ-Ingenieur↑ comment by SteveG · 2014-09-23T02:47:30.776Z · LW(p) · GW(p)
Investment levels will matter.
It is easier to predict the size of a market than to predict the R&D investment that companies will make to address the market, but there is a relationship.
Military successes may accelerate AI investment, or they may result in periods of disinclination that slow things down.
↑ comment by TRIZ-Ingenieur · 2014-09-25T00:12:13.265Z · LW(p) · GW(p)
Follow the trail of money...
Nick Bostrum decided to draw an abstract picture. The reader is left on his or her own to find the players in the background. We have to look for their motives. Nobody is interested in HLMI except from universities. Companies want superhuman intelligence as fast as possible for the smallest budget. Any nice-to-have capability, making the AI more human-like, is causing delays and money.
Transparency and regulation are urgently needed. We should discuss it later.
↑ comment by gallabytes · 2014-09-23T23:53:56.687Z · LW(p) · GW(p)
Perhaps people who are a step removed from the actual AI research process? When I say that, I'm thinking of people like Robin Hanson and Nick Bostrom, whose work depends on AI but isn't explicitly about it.
↑ comment by private_messaging · 2014-09-23T14:18:10.879Z · LW(p) · GW(p)
The experienced cake bakers aren't the most relevant experts (within your imagination) only because you imagine that 1: there's more relevant experts in general predicting, and 2: cake baking is sufficiently simple (in your imagination or the past, not in the real world where the cake baking got automated and the true "cake bakers" of today are experts in industrial automation, creating the future of cake baking just as we speak about it) that lack of expertise in cake baking is not a sufficient impediment for the former.
None of that is true for the AI - there seem to be no good experts on predicting that sort of thing in general, and a subject is difficult enough that such experts, if they existed, would be more than sufficiently handicapped by their lack of knowledge as to be worthless.
comment by KatjaGrace · 2014-09-23T01:06:57.769Z · LW(p) · GW(p)
If a person wanted to make their prediction of human-level AI entirely based on what was best for them, without regard to truth, when would be the best time? Is twenty years really the sweetest spot?
I think this kind of exercise is helpful for judging the extent to which people's predictions really are influenced by other motives - I fear it's tempting to look at whatever people predict and see a story about the incentives that would drive them there, and take their predictions as evidence that they are driven by ulterior motives.
Replies from: Larks, tmosley, gallabytes↑ comment by Larks · 2014-09-23T01:23:02.941Z · LW(p) · GW(p)
Stock market analysts are in a somewhat similar boat. Strategists and Macro economists make long-term predictions, though their performance is rarely tracked. Short-term forecasts (one month, or one quarter) are centrally compiled, and statistics are assembled on which economists are good forecasters, but this is not the case for long-term predictions. As such, long-term predictions seem to fall into much the same camp as AI predictions here. And many bank analysts explicitly think about the non-epistemic incentives they personally face, in terms of wanting to make an impact, wanting a defensible position, and so on.
However, with economists we see much shorter forecast time horizon. A long-term forecast would be 5 years; many give less. I have never seen an explicit forecast out longer than 10 years. Perhaps this is because they don't think people would assign any credibility to such forecasts; perhaps the remaining career duration of a macro economist is shorter than those of AI researchers. However, making several incorrect predictions is rarely very damaging to their career. Indeed, because they can selectively emphasis their ex post correct predictions, they're incentivized to make many short-term predictions.
Prima facie much of this applies to AI commentators as well.
↑ comment by tmosley · 2014-09-24T04:12:42.086Z · LW(p) · GW(p)
I don't understand this question. The best time for the emergence of a great optimizer would be shortly after you were born (earlier if your existence were assured somehow).
If an AI is a friendly optimizer, then you want it as soon as possible. If it is randomly friendly or unfriendly, then you don't want it at all (the quandary we all face). Seems like asking "when" is a lot less relevant than asking "what". "What" I want is a friendly AI. "When" I get it is of little relevance, so long as it is long enough before my death to grant me "immortality" while maximally (or sufficiently) fulfilling my values.
Replies from: leplen↑ comment by leplen · 2014-09-24T15:09:29.874Z · LW(p) · GW(p)
The question isn't asking when the best time for the AI to be created is. It's asking what the best time to predict the AI will be created is. E.g. What prediction sounds close enough to be exciting and to get me that book deal, but far enough away as to be not obviously wrong and so that people will have forgotten about my prediction by the time it hasn't actually come true. This is an attempt to determine how much the predictions may be influenced by self-interest bias, etc.
↑ comment by gallabytes · 2014-09-23T23:49:12.341Z · LW(p) · GW(p)
The answer to this question depends really heavily on my estimation of MIRI's capability as an organization and on how hard the control problem turns out to be. My current answer is "the moment the control problem is solved and not a moment sooner", but I don't have enough of a grip on the other difficulties involved to say when that would be more concrete.
comment by Peter_Koller · 2014-09-23T09:00:04.059Z · LW(p) · GW(p)
If one includes not only the current state of affairs on Earth for predicting when superintelligent AI will occur, but considers the whole of the universe (or at least our galaxy) it raises the question of an AI-related Fermi paradox: Where are they?
I assume that extraterrestrial civilizations (given they exist) which have advanced to a technological society will have accelerated growth of progress similar to ours and create a superintelligent AI. After the intelligence explosion the AI would start consuming energy from planets and stars and convert matter to further its computational power and send out Von Neumann probes (all of this at some probability), which would reach every star of the milky way in well under a million years if travelling at just 10% of the speed of light -- and turn everything into a giant computronium. It does not have to be a catastrophic event for life, a benign AI could spare worlds that harbor life. It would spread magnitudes faster than its biological creators, because it would copy itself faster and travel in many more directions simultanously than them. Our galaxy could/should have been consumed by an evergrowing sphere of AI up to billions of years ago (and that probably many times over by competing AI from various civilizations). But we don't see any traces of such a thing.
Are we alone? Did no one ever create a superintelligent AI? Did the AI and its creators go the other way (ie instead of expanding they choose to retire into a simulated world without interest in growing, going anywhere or contacting anyone)? Did it already happen and are we part or product of it (ie simulation)? Is it happening right in front of us and we, dumb as a goldfish, can't see it?
Should these questions, which would certainly shift the probabilities, be part of AI predictions?
Replies from: Sebastian_Hagen, KatjaGrace, TRIZ-Ingenieur, mvp9, PhilGoetz↑ comment by Sebastian_Hagen · 2014-09-23T22:11:09.854Z · LW(p) · GW(p)
Are we alone? Did no one ever create a superintelligent AI?
Quite possibly. Someone has to be first, and given how little we understand the barriers to making it up to our level, it shouldn't be particularly suspicious if that's us (in our past light-cone, anyway).
Did the AI and its creators go the other way
Not likely. You're going to run out of usable energy at some point, and then you'd wish you'd turned all of those stars off earlier. It'd take a very specific planning failure for a civilization to paint itself into that particular corner.
Did it already happen and are we part or product of it (ie simulation)?
Highly likely, but that's mostly ignorable for practical purposes. Almost all of the weight of our actions is in the cases where we're not.
Is it happening right in front of us and we, dumb as a goldfish, can't see it?
Unlikely. The obvious optimizations would leave definite signatures, and also probably wouldn't take all that long on an astronomic time scale.
Should these questions, which would certainly shift the probabilities, be part of AI predictions?
It would be hard to use them. For one, there's massive noise in our guesses on how hard it is to get from a random planet to a civilization of our level; and as long as you don't have a good idea of that, not observing alien AGIs tells us very little. For another, there might be anthropic selection effects. If, for instance, AGIs strongly tend to turn out to be paperclip maximizers, a civilization of our level just wouldn't survive contact with one, so we can't observe the contact case.
Replies from: Sebastian_Hagen↑ comment by Sebastian_Hagen · 2014-09-23T22:13:46.317Z · LW(p) · GW(p)
Re. the last point, I will also admit to being confused about the correct reference class to use here. Even if (purely hypothetically) we had a reason to guess that alien AGI had a decent chance to not only implement an acceptable morality according to their makers, but also be supportive to humanity by our morals ... well, if one of them was already here that would tell us something, but it would also put us into a position where understanding our own timeline to homegrown AGI development suddenly became much less important.
Which suggests to me it might still be a bad idea to just use that observation as direct input into our probability estimates, since it would bias the estimate in the class of cases where we really care about the accuracy of that particular estimate.
↑ comment by KatjaGrace · 2014-09-25T03:07:11.445Z · LW(p) · GW(p)
I think these kinds of considerations should be part of predicting AI. A few posts on related topics, in case you are interested, only the first of which I necessarily remember the details of well enough to endorse:
http://meteuphoric.wordpress.com/2010/11/05/light-cone-eating-ai-explosions-are-not-filters/ http://lesswrong.com/lw/g1s/ufai_cannot_be_the_great_filter/ http://lesswrong.com/lw/kvm/the_great_filter_is_early_or_ai_is_hard/
↑ comment by TRIZ-Ingenieur · 2014-09-25T00:32:31.199Z · LW(p) · GW(p)
If a child does not receive love, is not allowed to play, gets only instructions and is beaten - you will get a few years later a traumatized paranoic human being, unable to love, nihilistic and dangerous. A socialization like this could be the outcome of a "successful" self improving AI project. If humanity tries to develop an antagonist AI it could end in a final world war. The nihilistic paranoic AI might find a lose-lose strategy favorable and destroys our world.
That we did not receive any notion of extraterrestial intelligence tells us that obviously no other intelligent civilization has managed to survive a million years. Why they collapsed is pure speculation, but evil AI could speed things up.
Replies from: Liso↑ comment by Liso · 2014-09-25T03:47:51.166Z · LW(p) · GW(p)
But why collapsed evil AI after apocalypse?
Replies from: TRIZ-Ingenieur↑ comment by TRIZ-Ingenieur · 2014-09-25T06:42:41.859Z · LW(p) · GW(p)
It would collapse within apocalypse. It might trigger aggressive actions knowing to be eradicated itself. It wants to see the other lose. Dying is not connected with fear. If it can prevent the galaxy from being colonised by good AI it prefers perfect apocalypse.
Debating aftermath of apocalypse gets too speculative to me. I wanted to point out that current projects do not have the intention to create a balanced good AI character. Projects are looking for fast success and an evil paranoic AI might result in the far end.
↑ comment by mvp9 · 2014-09-24T17:10:49.698Z · LW(p) · GW(p)
Exploration is a very human activity, it's in our DNA you might say. I don't think we should take for granted that an AI would be as obsessed with expanding into space for that purpose.
Nor Is it obvious that it will want to continuously maximize its resources, at least on the galactic scale. This is also a very biological impulse - why should an AI have that built in?
When we talk about AI this way, I think we commit something like Descartes's Error (see Damasio's book of that name): thinking that the rational mind can function on its own. But our higher cognitive abilities are primed and driven by emotions and impulses, and when these are absent, one is unable to make even simple, instrumental decisions. In other words, before we assume anything about an AI's behavior, we should consider its built in motivational structure.
I haven't read Bostrom's book so perhaps he makes a strong argument for these assumptions that I am not aware of, in which case, could some one summarize them?
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-25T03:02:07.446Z · LW(p) · GW(p)
Good question. The basic argument is that whatever an AI (or any creature) values, more resources are very likely to be useful for that goal. For instance, if it just wants to calculate whether large numbers are prime or not, it will do this much better if it has more resources to devote to calculation. This is elaborated somewhat in papers by Omohundro and Bostrom.
That is, while exploration and resource acquisition are in our DNA, there is a very strong reason for them to be there, so they are likely to be in the DNA-analog of any successful general goal-seeking creature.
comment by SteveG · 2014-09-23T01:22:25.499Z · LW(p) · GW(p)
The question “When Will AI Be Created?” is an interesting starting-point, but it is not sufficiently well-formulated for a proper Bayesian quantitative forecast.
We need to bring more rigor to this work.
The tactic from Luke’s article that has not been done in sufficient detail is “decomposition.”
My attention has shifted from the general question of “When will we have AGI,” to the question of what are some technologies which might become components of intelligent systems with self-improving capabilities, and when will these technologies become available.
Properly understanding these components and predicting when they will arrive will require a much more deliberative process than a survey.
We will have to work through creating forecasts about a series of enabling technologies one-by-one, and also analyze when the creation of one technology enables another.
We are going to have to build a nice stack of Bayes' nets and also do some advanced regression analysis, because each year's progress depends on the last.
Replies from: paulfchristiano, KatjaGrace↑ comment by paulfchristiano · 2014-09-23T02:19:17.791Z · LW(p) · GW(p)
I think that most people would be skeptical about such an analysis, unless they had seen similar techniques successfully applied in more mundane cases of technological forecasting. Even retrodictions along these lines could be quite helpful for establishing credibility. Without a lot of practice applying similar techniques to similar situations, I would not expect the results to be more informative than more straightforward methodologies.
While I think that these more elaborate techniques are interesting and that such an exercise would be very valuable (successful or not), as far as I know it hasn't been done with enough rigor to be useful. I suspect that if it were done you would quickly default to rough-and-ready techniques rather than something theoretically sophisticated. But that isn't necessarily a bad thing (the interesting part of the proposal seems to be in the breaking the question down, not in the formal techniques used to put it back together), and I'm sure you would learn a lot.
Overall I would guess that fleshing out the evidence that forecasters and experts are relying on, improving the quality of discussion, and improving the quality of elicitation, is a more promising direction (in the short term).
I'd also point out that any forecast that relies on our current best guesses about the nature of general intelligence strike me as very unlikely to be usefully accurate--we have a very weak sense of how things will play out, how the specific technologies involved will relate to each other, and (more likely than not) even what they are.
Replies from: NxGenSentience, SteveG↑ comment by NxGenSentience · 2014-09-24T02:45:57.057Z · LW(p) · GW(p)
I'd also point out that any forecast that relies on our current best guesses about the nature of general intelligence strike me as very unlikely to be usefully accurate--we have a very weak sense of how things will play out, how the specific technologies involved will relate to each other, and (more likely than not) even what they are.
It seems that many tend to agree with you, in that, on page 9 of the Muller - Bostrom survey, I see that 32.5 % of respondents chose "Other method(s) currently completely unknown."
We do have to get what data we can, of course, like SteveG says, but (and I will qualify this in a moment), depending on what one really means by AI or AGI, it could be argued that we are in the position of physics at the dawn of the 20th century, vis a vie the old "little solar system" theory of the atom, and Maxwell's equations, which were logically incompatible.
It was known that we didn't understand something important, very important, yet, but how does one predict how long it will take to discover the fundamental conceptual revolution (quantum mechanics, in this case) that opens the door to the next phase of applications, engineering, or just "understanding"?
Now to that "qualification" I mentioned: some people of course don't really think we lack any fundamental conceptual understanding or need a conceptual revolution-level breakthrough, i.e. in your phrase '...best guesses about the nature of general intelligence' they think they have the idea down.
Clearly the degree of interest and faith that people put in "getting more rigor" as a way of gaining more certainty about a time window, depends individually on what "theory of AI" if any, they already subscribe to, and of course the definition and criterion of HLAI that the theory of AI they subscribe to would seek to achieve.
For brute force mechanistic connectionists, getting more rigor by decomposing the problem into components / component industries (machine vision / object recognition, navigation, natural language processing in a highly dynamically evolving, rapidly context shifting environment {a static context, fixed big data set case is already solved by Google}, and so on) would of course get more clues about how close we are.
But if we (think that) existing approaches lack something fundamental, or we are after something not yet well enough understood to commit to a scientific architecture for achieving it (for me, that is "real sentience" in addition to just "intelligent behavior" -- what Chalmers called "Hard problem" phenomena, in addition to "Easy problem" phenomena), how do we get more rigor?
How could we have gotten enough rigor to predict when some clerk in a patent office would completely delineate a needed change our concepts of space and time, and thus open the door to generations of progress in engineering, cosmology, and so on (special relativity, of course)?
What forcasting questions would have been relevant to ask, and to whom?
That said, we need to get what rigor we can, and use the data we can get, not data we cannot get.
But remaining mindful that what counts as "useful" data depends on what one already believes the "solution" to doing AI is going to look like.... one's implicit metatheory about AI architecture, is a key interpretive yardstick also, to overlay onto the confidence levels of active researchers.
This point might seem obvious, as it is indeed almost being made, quite a lot, though not quite sharply enough, in discussing some studies.
I have to remind myself, occasionally, forecasting across the set of worldwide AI industries, is forecasting; a big undertaking, but it is not a way of developing HLAI itself. I guess we're not in here to discuss the merits of different approaches, but to statistically classify their differential popularity among those trying to do AI. It helps to stay clear about that.
On the whole, though, I am very satisfied with attempts to highlight the assumptions, methodology and demographics of the study respondents. The level of intellectual honesty is quite high, as is the frequency of reminders and caveats (in varying fashion) that we are dealing with epistemic probability, not actual probability.
↑ comment by KatjaGrace · 2014-09-23T01:29:26.720Z · LW(p) · GW(p)
I'm fully in favor of more rigor, though I think less rigorous approaches are still informative, in the current state of very little research having been done.
In what way do you think the question should be better formulated? 'AI' seems to need defining better, but is this all that you mean there?
Replies from: SteveG, SteveG↑ comment by SteveG · 2014-09-23T01:39:13.861Z · LW(p) · GW(p)
We need to ask many, very specific questions about specific technologies, and we need to develop maps of dependencies of one technology on another.
Replies from: Jeff_Alexander↑ comment by Jeff_Alexander · 2014-09-23T01:47:23.040Z · LW(p) · GW(p)
Could you give three examples of "very specific questions about specific technologies", and perhaps one example of a dependency between two technologies and how it aids prediction?
Replies from: SteveG, SteveG↑ comment by SteveG · 2014-09-23T02:08:46.299Z · LW(p) · GW(p)
So, suppose we just want to forecast the following: I place a really good camera with pan, zoom and a microphone in the upper corner of a room. The feed goes to a server farm, which can analyze it. With no trouble, today we can allow the camera to photograph in infrared and some other wavelengths. Let’s do that.
When we enter a room, we also already have some information. We know whether we’re in a home, an office, a library, a hospital, a trailer or an airplane hanger. For now, let’s not have the system try to deduce that.
OK, now I want the server farm to be able to tell me exactly who is in the room, what are all of the objects in it, what are the people wearing and what are they holding in their hands. Let’s say I want that information to correctly update every ten seconds.
The problem as stated is still not fully specified, and we should assign some quantitative scales to the quality of the recognition results.
Replies from: SteveG↑ comment by SteveG · 2014-09-23T02:12:40.598Z · LW(p) · GW(p)
When people are trying to figure out what is in a room, they can also move around in it, pick up objects and put them down.
So, we have a relationship between object recognition and being able to path plan within a room.
People often cannot determine what an object is without reading the label. So, some NLP might be in the mix.
To determine what kind of leaf or white powder is sitting on a table, or exactly what is causing the discoloration in the grout, the system iwould require some very specialized skills.
Replies from: SteveG, SteveG↑ comment by SteveG · 2014-09-23T03:32:28.218Z · LW(p) · GW(p)
Continuing the example:
Object recognition relies on sensors, computer memory and processing speed, and software.
Sensors:
Camera technology has run ahead very quickly. I believe that today the amount of input from cameras into the server farm can be made significantly greater than the amount of input from the eye into the brain.
I only put a single camera into my scenario, but if we are trying to max out the room's ability to recognize objects, we can put in many.
Likewise, if the microphone is helpful in recognition, then the room can exceed human auditory abilities.
Machines have already overtaken us in being able to accept these kinds of raw data.
Memory and Processing Power:
Here is a question that requires expert thinking: So, apparently machines are recording enough video today to equal the data stream people use for visual object recognition, and computers can manipulate these images in real-time.
What versions of the object recognition task require still more memory and still faster computers, or do we have enough today?
Software
Google Goggles offers some general object recognition capabilities.
We also have voice and facial recognition.
One useful step would be to find ways to measure how successful systems like Google Goggles and facial recognition are now, then plot over time.
With that work in hand, we can begin to forecast.
↑ comment by SteveG · 2014-09-23T01:41:08.031Z · LW(p) · GW(p)
We need to chart as many plausible pathways as we can think of for algorithmic and neuromorphic technologies, and for specific questions within each AI sub-domain.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-23T01:44:03.272Z · LW(p) · GW(p)
Thank you. To be clear, you think these are the most promising approaches to predicting the event we are interested in (some better specified version of 'human-level AI')?
How expensive do you think it would be to do this at the level of detail you are suggesting? Who would ideally do it?
Replies from: SteveG, SteveG↑ comment by SteveG · 2014-09-23T01:57:11.482Z · LW(p) · GW(p)
We'll have a start-up phase where we specify the project, select software and brainstorm some model templates.
After that, we'll be able to get a better handle on costs.
We're talking about a serious scientific effort with dozens of people.
Replies from: SteveG↑ comment by SteveG · 2014-09-23T01:53:35.270Z · LW(p) · GW(p)
People with experience in Bayesian forecasting need to work with academic, industry and government experts in AI sub-domains and computer hardware.
I envision a forecast calibration and validation process, and a periodic cycle of updates every 1-3 years.
comment by KatjaGrace · 2014-09-23T01:14:15.506Z · LW(p) · GW(p)
How would you like this reading group to be different in future weeks?
Replies from: Larks, Liso↑ comment by Larks · 2014-09-23T01:27:50.366Z · LW(p) · GW(p)
I think this is pretty good at the moment. Thanks very much for organizing this, Katja - it looks like a lot of effort went into this, and I think it will significantly increase the amount the book gets read, and dramatically increase the extent to which people really interact with the ideas.
I eagerly await chapter II, which I think is a major step up in terms of new material for LW readers.
↑ comment by Liso · 2014-09-25T03:45:07.125Z · LW(p) · GW(p)
Katja pls interconnect discussion parts by links (or something like TOC )
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-25T21:13:18.958Z · LW(p) · GW(p)
I have been making a list of posts so far on the (initial posting)[http://lesswrong.com/lw/kw4/superintelligence_reading_group/], and linking it from the top of the post. Should I make this more salient somehow, or do it differently?
comment by KatjaGrace · 2014-09-23T01:05:30.201Z · LW(p) · GW(p)
"My own view is that the median numbers reported in the expert survey do not have enough probability mass on later arrival dates. A 10% probability of HLMI not having been developed by 2075 or even 2100... seems too low"
Should Bostrom trust his own opinion on this more than the aggregated judgement of a large group of AI experts?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2014-09-23T02:31:07.871Z · LW(p) · GW(p)
Certainly he has thought about the question at considerably more length than many of the respondents. Even if he weren't at the absolute tail of the distribution, he might justifiably be skeptical of the aggregates. But based on public discourse, it seems quite possible that he has thought about the question much more than almost any respondents, and so does have something to add over and above their aggregate.
(I am inclined to agree that predicting a 90% probability of developing broadly human-replacement AI by 2075 is essentially indefensible, and 2100 also seems rash. It's not totally clear that their definition of HLMI implies human-repalcement, but it seems likely. I think that most onlookers, and probably most AI researchers, would agree.)
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-09-23T04:40:25.707Z · LW(p) · GW(p)
There is also the fact that Bostrom has been operating under extreme long term incentives for many years. He has been thinking (and being paid to think, and receiving grants and status for) the long, really long term future for quite a while. AI scientists on the other hand usually are more focused on the time of their lives, the lenght of their grants and other more mundane, shorter term considerations of the scientist life.
Most people have scarce to no mental representation of the World more than two decades after they die, I see no reason why AI scientists would be different.
comment by KatjaGrace · 2014-09-23T01:01:30.363Z · LW(p) · GW(p)
'One result of this conservatism has been increased concentration on "weak AI" - the variety devoted to providing aids to human thought - and away from "strong AI" - the variety that attempts to mechanise human-level intelligence' - Nils Nilson, quoted on p18.
I tend to think that 'weak AI' efforts will produce 'strong AI' regardless, and not take that much longer than if people were explicitly trying to get strong AI. What do you think?
Replies from: gallabytes, TRIZ-Ingenieur↑ comment by gallabytes · 2014-09-24T00:11:01.050Z · LW(p) · GW(p)
What's your reason for thinking weak AI leads to strong AI? Generally, weak AI seems to take the form of domain-specific creations, which provide only very weak general abstractions.
One example that people previously thought would lead to general AI was chess playing. And sure, the design of chess playing AI forced some interesting development of efficient traversing of large search spaces, but as far as I can tell it has only done so in a very weak way, and hasn't contributed meaningfully to anything resembling the efficiency of human-style chunking.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-25T03:19:36.550Z · LW(p) · GW(p)
What's your reason for thinking weak AI leads to strong AI?
I doubt there is a sharp distinction between them, so I think probably trying to make increasingly useful weak AIs will lead to strong AI.
Replies from: gallabytes↑ comment by gallabytes · 2014-09-26T06:14:58.395Z · LW(p) · GW(p)
I doubt there is a sharp distinction between them
Actually, let's taboo weak and strong AI for a moment.
By weak AI I mean things like video game AI, self driving cars, WolframAlpha, etc.
By strong AI I think I mean something that can create weak AIs to solve problems. Something that does what I mean by this likely includes a general inference engine. While a self driving car can use its navigation programs to figure out lots of interesting routes from a to b, if you tell it to go from California to Japan it won't start building a boat
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-28T18:07:18.036Z · LW(p) · GW(p)
I suspect that if people continue trying to improve self-driving cars, they will become closer and closer to building a boat (if building such a boat were necessary under the circumstances, which seems unlikely). For instance, it wouldn't be that far from what we have for the car to check whether there is a ferry and go to it. That might be improved over time into finding a boat-supplier and buying a boat if there is no ferry. If the boat supplier were also automated, and they were in close communication with each other, it isn't that different from your car being able to make a boat.
↑ comment by TRIZ-Ingenieur · 2014-09-27T01:27:50.778Z · LW(p) · GW(p)
You are right. With IBM we can follow how from the chess playing Big Blue (weak AI) over Jeopardy mastering Watson (stronger weak AI) they now pushed hardware development together with HRL and developed the newest SyNAPSE chip. IBM pushes their weak AIs to get stronger and stronger and now leave the path of von Neumann computers into the future to get even stronger AIs. I expect that IBM will follow the Watson/von Neumann and its new neurocomputational path in parallel for several more years.
comment by AlexMennen · 2014-09-28T05:10:45.858Z · LW(p) · GW(p)
Have there been any surveys asking experts when they expect superintelligence, rather than asking about HLMI? I'd be curious to see the results of such a survey, asking about time until "machine intelligence that greatly surpasses the performance of every human in most professions" as FHI's followup question put it, or similar. Since people indicated that they expected a fairly significant gap between HLMI and superintelligence, that would imply that the results of such a survey (asking only about superintelligence) should give longer time estimates, but I wouldn't be surprised if the results ended up giving very similar time estimates to the surveys about time until HLMI.
Replies from: TRIZ-Ingenieur, KatjaGrace↑ comment by TRIZ-Ingenieur · 2014-09-28T13:24:47.003Z · LW(p) · GW(p)
I am expecting superintelligence to happen before HLMI. A superintelligence with decisive advantage does not need all human skills.
↑ comment by KatjaGrace · 2014-09-28T18:10:40.652Z · LW(p) · GW(p)
Interesting point. I don't know of any surveys that don't ask about human-level as well, and I think first, and I have looked somewhat hard for surveys.
comment by JoshuaFox · 2014-09-24T13:17:28.561Z · LW(p) · GW(p)
We we talk about the arrival of "human-level" AI, we don't really care if it is at a human level at various tasks that we humans work on. Rather, if we're looking at AI risk, we care about AI that's above human level in this sense: It can outwit us.
I can imagine some scenarios in which AI trounces humans badly ton its way to goal achievement, while lacking most human areas of intelligence. These could be adversarial AIs: An algotrading AI that takes over the world economy in a day or a military AI that defeats an enemy nation in an instant with some nasty hack.
It could even be an AI with some arbitrary goal -- a paper-clipper -- that brings into play a single fiendishly effective self-defense mechanism.
The point is that the range of abilities can be very narrow, and the AI can still be working for its master in the way that its master intended. As long as it can truly outwit humans, we're in "superintelligence" territory for the purposes of our discussion.
Replies from: leplen↑ comment by leplen · 2014-09-24T15:53:35.451Z · LW(p) · GW(p)
This is an interesting distinction. I think it could be strengthened, further teased out by considering some human vs. animal examples. I can't echo-locate better than a bat or even understand the cognitive machinery a bat uses to echo-locate, but I can nevertheless outwit any number of bats. The human cognitive function we call "intelligence" may be more general than the cognitive function associated with echo-location, but it isn't totally clear how general it is.
If humans use the same cognitive machinery to outwit others/make strategic decisions that they use for other tasks, then perhaps the capacity to outwit a human is indicative of fully general intelligence. If this is true, it seems likely that the AI will outperform, or at least have the capacity to outperform humans in all of those tasks. It would presumably still have to devote resources to learning a given task, and may not choose to spend resources in that, but in principle it would have the capacity to be a virtuoso didgeridoo player or what have you.
But it's not totally clear to me that fully general intelligence is necessary to outwit a human. It's not even totally clear to me that human exhibit fully general intelligence. If there are things we can't learn, how would we know?
It's also not necessary that the AI be able to outwit humans in order for it to pose an existential risk. An asteroid is not capable of outwitting me, but if it crashes into the planet, I'm still dead. If the AI is potent enough and/or fast enough it still has the potential to be extremely problematic. With that being said, a dumb AI that poses an existential risk is a systems design issue akin to putting the nuclear launch switch on the same wall plate as the garbage disposal.
comment by KatjaGrace · 2014-09-23T01:16:48.146Z · LW(p) · GW(p)
What did you find least persuasive in this week's reading?
Replies from: Jeff_Alexander↑ comment by Jeff_Alexander · 2014-09-23T01:58:45.518Z · LW(p) · GW(p)
The lack of expected utility estimates understates the case for working on FAI. Even if AGI is 100 years away or more, the safety issues might still be top or very high priority (though estimates comparing this against the value of other existential risk reduction efforts would be needed to determine this). Surely once we realize the potential impact of AGI, we shouldn't delay working on safety concerns only until it is dangerously near. Some mathematical problems and engineering issues have taken humans hundreds of years to resolve (and some of course are still open/unsolved), so we should start immediately regardless of how far the estimate is (if there is no other imminent existential risk that takes precedent).
Edited to add: That said, I can see how introducing far future Fermi estimates at this stage could be problematic from an expository standpoint, given the intended audience.
Replies from: KatjaGrace, paulfchristiano, PhilGoetz↑ comment by KatjaGrace · 2014-09-23T02:11:39.526Z · LW(p) · GW(p)
I agree with the general sentiment. Though if human-level AI is very far away, I think there might be better things to do now than work on very direct safety measures. For instance, improve society's general mechanisms for dealing with existential risks, or get more information about what's going to happen and how to best prepare. I'm not sure if you meant to include these kinds of things.
Replies from: Jeff_Alexander↑ comment by Jeff_Alexander · 2014-09-23T06:57:10.043Z · LW(p) · GW(p)
Though if human-level AI is very fary away, I think there might be better things to do now than work on very direct safety measures.
Agreed. That is the meaning I intended by
estimates comparing this against the value of other existential risk reduction efforts would be needed to determine this [i.e. whether effort might be better used elsewhere]
↑ comment by paulfchristiano · 2014-09-23T02:27:38.931Z · LW(p) · GW(p)
Some thoughts on this perspective:
Most people are not so exclusively interested in existential risk reduction; their decisions depend on how the development of AI compares to more pressing concerns. I think you can make a good case that normal humanitarians are significantly underestimating the likely impact of AI; if that's true, then by making that case one might be able to marshall a lot of additional effort.
Echoing Katja: general improvements in individual and collective competence are also going to have a material effect on how the development of AI is handled. If AI is far off (e.g. if we were having this discussion in 1600) then it seems that those effects will tend to dominate the achievable direct impacts. Even if AI is developed relatively soon, it's still plausible to me that institutional quality will be a big determinant of outcomes relative to safety work (though it's less plausible on the margin, given just how little safety work there is).
I can imagine a future where all of the low-hanging fruit is taken in many domains, so that the best available interventions for altrusits concerned with long-term trajectories is focusing on improbable scenarios that are being neglected by the rest of the world because they don't care as much. For better or worse, I don't think we are there yet.
Replies from: Jeff_Alexander↑ comment by Jeff_Alexander · 2014-09-23T07:28:13.281Z · LW(p) · GW(p)
how the development of AI compares to more pressing concerns
Which concerns are more pressing? How was this assessed? I don't object to other things being more important, but I do find the suggestion there are more pressing concerns if AI is a bit further out one of the least persuasive aspects of the readings given the lack of comparison & calculation.
2.
I agree with all of this, more or less. Perhaps I didn't state my caveats strongly enough. I just want an explicit comparison attempted (e.g., given a 10% chance of AI in 20 years, 50% in 50 years, 70% within 100 years, etc., the expected value of working on AI now vs. synthetic biology risk reduction, healthy human life extension, making the species multi-planetary, raising the rationality waterline, etc.) and presented before accepting that AI is only worth thinking about if it's near.
↑ comment by PhilGoetz · 2014-10-07T00:44:53.416Z · LW(p) · GW(p)
I think the "safety" problems (let's call them FAI for the moment) will be harder than AI, and the philosophical problems we would need to address to decide what we ought to do will be more difficult than FAI. I see plenty of concern in LW and other futurist communities about AI "safety", but approximately none about how to decide what the right thing to do is. "Preserving human values" is very possibly incoherent, and if it is coherent, preserving humans may be incompatible with it.
comment by KatjaGrace · 2014-09-23T01:02:05.705Z · LW(p) · GW(p)
Bostrom talks about a recent set of surveys of AI experts in which 'human-level machine intelligence' was given 10% probability of arriving by (median) 2022. How much should we be concerned about this low, but non-negligible chance? Are we as a society more or less concerned than we should be?
Replies from: diegocaleiro, TRIZ-Ingenieur↑ comment by diegocaleiro · 2014-09-23T04:35:12.405Z · LW(p) · GW(p)
This high probability is most likely an artifact of non-differential extrapolation of the different ways through which AI could arrive. If you look at the curve after 2022 and try to extrapolate it backwards, you'll end up assigning to much probability mass to a period sooner than that in which some of the grounding technologies for some versions of AGI will be created. I suspect if those experts were asked to divide forms in which HLMI will arrive into sorts and then assigned probabilities, this would become more obvious and the numbers would be lower.
↑ comment by TRIZ-Ingenieur · 2014-09-24T23:51:59.219Z · LW(p) · GW(p)
The ability to self-improve grows over time. Actually computer chips need extremely expensive masking steps in fabs. Maker tools for nanoassembled chips and parts will not be available so soon. AIs have to rely on human infrastructure support.
If an early bird project reaches HLMI by 2022 there is hardly any infratructure for radically transforming the world. Only projects that are currently running with high budget have a chance to meet this date. Human brain project with highest probability: No. Google brain project or Baidu brain project: maybe yes. The majority of projects are stealth ones: For sure NSA and other intelligence agencies are working on AIs targeting the decisive advantage. Financial firms would benefit very fast from decisive advantage. 3 of 4 friends of mine, working for different companies in the financial sector told me about ongoing AI projects in their companies. If a stealth project succeeds in 2022 we probably will not take notice. The AI will use its intelligence to hide its success and misinform about it. In 2022 an outbreaking AI would not gain enough momentum to prevent shutting it down. Only very few supercomputers in 2022 will have enough computational power for this AI. If we want, we can switch it off.
The much higher risk arises if a further AI winter would come. Technology, infrastructure, excessive computing capacity, nanoassembly makers: everything is prepared, but nobody found the holy grail of intelligent software. All of a sudden a self improving AI could self-improve its initial inefficient software and jump above all thinkable measures into superintelligence. Billions of computers capable of running this AI are by then available. To infiltrate this mighty infrastructure will be easy. Millions of nanoassembly makers could be turned into replicating factories. Switching off billions of computers that are deeply interwoven with our daily life by then might be nearly impossible.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-25T21:59:34.645Z · LW(p) · GW(p)
If there is more hardware etc being used for much less valuable applications at a point that human-level software appears, I agree the software could spread much more widely and we will see a more abrupt jump in capability from the AI. However it's unclear to me that an AI winter would produce this outcome. The question of how much hardware etc gets redirected to the improving AI seems to be about what the distribution of value of different hardware uses is like, in particular how flat it is relative to the jump in AI capability. That is, if the AI goes from hardly worth running to more valuable than fifty percent of the other things being run, it will take over a lot of hardware. I don't know why this is more likely if AI has been slow recently.
Replies from: TRIZ-Ingenieur↑ comment by TRIZ-Ingenieur · 2014-09-27T00:52:38.550Z · LW(p) · GW(p)
With AI winter I meant AGI winter. If current AGI projects (Ng/Baidu, Kurzweil/Google, human brain project and others) fail to deliver concepts for deep learning and fundamental understanding, financial support for AGI could be cut and funneled into less risky weak AI projects. Technology progresses, weak AI capabilities rise to high superintelligence in their domain. But like superheated water - without a nucleous for boiling - nothing happens. The heat rises above boiling point. One grain of salt into the superheated water creates the first bubble, triggering more bubbles into steam explosion.
AGI winter and intelligence explosion
If we let an AGI winter happen many diverse weak AIs might be developed, as depicted in the spiderweb chart. Being superintelligent in their domain these AIs have nearly no other skills. In this situation only a tiny nucleation stimulus is needed to start the intelligence explosion with a highly superintelligent AI. This stimulus could come from a small project that has no capabilties to engineer safeguarding measures.
AI has been so successful recently that enough financial support is available. We have to invest a significant amount into AGI and means for controlling and safeguarding AGI development. If we allow an AGI winter to happen we risk an uncontrollable intelligence explosion.
Replies from: KatjaGrace, private_messaging↑ comment by KatjaGrace · 2014-09-28T18:21:18.536Z · LW(p) · GW(p)
This seems like an interesting model, but it is complicated and not obvious, so I don't agree with,
We have to invest a significant amount into AGI and means for controlling and safeguarding AGI development. If we allow an AGI winter to happen we risk an uncontrollable intelligence explosion.
For instance, it could be that having any two AIs is much like having an AI with both of their skills, such that you can't really have weak AIs that carry out skills 1-5 without having a system which is close to the superintelligence you depict. Or that people reliably tend to build A+B, if it is useful and they have A and B. There might also be other effects of AGI funding than via this channel. Also, perhaps it would better to focus on investing less in narrow AI, which would give the same outcome on your model. Perhaps it is good for AGI to jump quickly from one level to another, to avert arms races for instance. etc.
↑ comment by private_messaging · 2014-09-27T01:09:05.372Z · LW(p) · GW(p)
Said AGI is up in the world of those narrow AIs and products of their use. AGI taxes on your imagination resources, leaving little left for contemporary tech, which it ravages like a machinegun armoured horse against roman soldiers.
comment by KatjaGrace · 2014-09-23T01:16:21.739Z · LW(p) · GW(p)
Was there anything in particular in this week's reading that you would like to learn more about, or think more about?
Replies from: kgaliascomment by KatjaGrace · 2014-09-23T01:15:58.432Z · LW(p) · GW(p)
Which arguments do you think are especially strong in this week's reading?
comment by KatjaGrace · 2014-09-23T01:15:03.981Z · LW(p) · GW(p)
Did you change your mind about anything as a result of this week's reading?
comment by KatjaGrace · 2014-09-23T01:06:14.210Z · LW(p) · GW(p)
I respectfully disagree with Muehlhauser's claim that the AI expert surveys are of little use to us, due to selection bias. For one thing, I think the scale of the bias is unlikely to be huge: probably a few decades. For another thing, we can probably roughly understand its size. For a third, we know which direction the bias is likely to go in, so we can use survey data as lower bound estimates. For instance, if AI experts say there is a 10% chance of AGI by 2022, then probably it isn't higher than that.
Replies from: Jeff_Alexander, None↑ comment by Jeff_Alexander · 2014-09-23T02:19:44.831Z · LW(p) · GW(p)
Why do you think the scale of the bias is unlikely to be more than a few decades?
Many expert physicists declared flight by humans impossible (e.g. Kelvin). Historical examples of a key insight taking a discovery from "impossible" or distant to very near term seem to exist, so might AI be similar? (In such a case, the likelihood of AI by year X may be higher than experts say.)
↑ comment by KatjaGrace · 2014-09-23T02:53:51.167Z · LW(p) · GW(p)
Why do you think the scale of the bias is unlikely to be more than a few decades?
Because the differences between estimates made by people who should be highly selected for optimism (e.g. AGI researchers) and people who should be much less so (other AI researchers, and more importantly but more noisily, other people) are only a few decades.
Replies from: Jeff_Alexander, Sysice↑ comment by Jeff_Alexander · 2014-09-23T07:36:42.612Z · LW(p) · GW(p)
According to this week's Muehlhauser, as summarized by you:
The estimates of informed people can vary between a small number of decades and a thousand years.
What about the thousand year estimates? Rarity / outliers?
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-25T03:12:04.507Z · LW(p) · GW(p)
Yeah, I'm just saying the median estimates probably don't differ by that many decades - the thousand year estimates are relatively common, but don't seem to be median for any groups that I know of.
↑ comment by Sysice · 2014-09-23T03:30:27.671Z · LW(p) · GW(p)
I'm interested in your statement that "other people" have estimates that are only a few decades off from optimistic trends. Although not very useful for this conversation, my impression is that a significant portion of informed but uninvolved people place a <50% chance of significant superintelligence occurring within the century. For context, I'm a LW reader and a member of that personality cluster, but none of the people I am exposed to are. Can you explain why your contacts make you feel differently?
Replies from: leplen, KatjaGrace↑ comment by leplen · 2014-09-23T06:45:00.376Z · LW(p) · GW(p)
How about human level AI? How about AI that is above human intelligence but not called "a superintelligence"?
I feel like the general public is over-exposed to predictions of drastic apocalyptic change and phrasing is going to sway public opinion a lot, especially since they don't have the same set of rigorous definitions to fall back on that a group of experts does.
↑ comment by KatjaGrace · 2014-09-23T06:26:54.059Z · LW(p) · GW(p)
Firstly, I only meant that 'other' people are probably only a few decades off from the predictions of AI people - note that AI people are much less optimistic than AGI people or futurists, with 20% or so predicting after this century.
My contacts don't make me feel differently. I was actually only talking about the different groups in the MIRI dataset pictured above (as shown in the graph with four groups in earlier). Admittedly the 'other' group there is very small, so one can't infer that much from it. I agree your contacts may be a better source of data, if you know their opinions in an unbiased way. I also doubt the non-AGI AI group is as strongly selected for optimism about eventual AGI from among humans as AGI people are from among AI people. Then since the difference between AI people and AGI people is only a couple of decades at the median, I doubt the difference between AI researchers and other informed people is that much larger.
It may be that people who make public comments at all tend to be a lot more optimistic than those who do not, though the relatively small apparent differences between surveys and public statements suggests not.
comment by KatjaGrace · 2014-09-23T01:05:11.516Z · LW(p) · GW(p)
After all this, when do you think human level AI will arrive?
Replies from: Jeff_Alexander, KatjaGrace, tmosley↑ comment by Jeff_Alexander · 2014-09-23T02:28:07.102Z · LW(p) · GW(p)
This feels like a trap -- if the experts are so unreliable, and we are going out of our way to be clear about how unclear this forecasting business is (currently, anyway), settling on a number seems premature. If we want to disagree with experts, we should first be able to indicate where they went wrong, and how, and why our method and data will let us do better.
↑ comment by KatjaGrace · 2014-09-23T01:05:15.740Z · LW(p) · GW(p)
What is the last date at which you think the probability of human level AI is less than 10%?
↑ comment by tmosley · 2014-09-24T04:35:45.414Z · LW(p) · GW(p)
Sometime after the Singularity. We already have AI that surpasses humans in several areas of human endeavor, such as chess and trivia. What do you define as "human level"? The AIs we have now are like extremely autistic savants, exceptional in some areas where most people are deficient, but deficient to the point of not even trying in the thousands of others. Eventually, there will (in theory) be AIs that are like that with most aspects of human existence, yet remain far inferior in others, and perhaps shortly after that point is reached, AIs will surpass humans in everything.
Trying to predict "when" seems like trying to predict which snowflake will trigger an avalanche. I really don't think it can be done without a time machine or an already operational superintelligent AI to do the analysis for us, but the snow seems to be piling up pretty fast.
comment by KatjaGrace · 2014-09-23T01:02:15.794Z · LW(p) · GW(p)
Given all this inaccuracy, and potential for bias, what should we make of the predictions of AI experts? Should we take them at face value? Try to correct them for biases we think they might have, then listen to them? Treat them as completely uninformative?
Replies from: TRIZ-Ingenieur, Larks↑ comment by TRIZ-Ingenieur · 2014-09-27T01:02:47.468Z · LW(p) · GW(p)
AI experts get their prediction on the basis of many aspects. Maybe it could be possible to compile a questionaire to document bias and reasons for their prediction.
comment by John_Maxwell (John_Maxwell_IV) · 2014-09-23T05:39:20.106Z · LW(p) · GW(p)
The "Cumulative distribution of predicted Years to AI, in early and late predictions" chart is interesting... it looks like expert forecasts regarding how many years left until AI have hardly budged in ~15 years.
If we consider AI to be among the reference class of software projects, it's worth noting that software projects are famously difficult to forecast development timelines for and are famous for taking much longer than expected. And that's when there isn't even new math, algorithms, etc. to invent.
comment by KatjaGrace · 2014-09-23T01:04:09.692Z · LW(p) · GW(p)
"Small sample sizes, selection biases, and - above all - the inherent unreliability of the subjective opinions elicited mean that one should not read too much into these expert surveys and interviews. They do not let us draw any strong conclusion." - Bostrom, p21
Do you agree that we shouldn't read too much into e.g. AI experts predicting human-level AI with 90% probability by 2075?
Replies from: slutbunwaller{kind=link}
comment by KatjaGrace · 2014-09-23T01:02:48.255Z · LW(p) · GW(p)
I think an important fact for understanding the landscape of opinions on AI, is that AI is often taken as a frivolous topic, much like aliens or mind control.
Two questions:
1) Why is this?
2) How should we take it as evidence? For instance, if a certain topic doesn't feel serious, how likely is it to really be low value? Under what circumstances should I ignore the feeling that something is silly?
Replies from: KatjaGrace, kgalias, slutbunwaller↑ comment by KatjaGrace · 2014-09-23T01:03:42.956Z · LW(p) · GW(p)
Relatedly, Scott Alexander criticizes the forms of popular reporting on dangers from AI. Why does reporting takes these forms?
Replies from: gallabytes↑ comment by gallabytes · 2014-09-23T23:58:43.168Z · LW(p) · GW(p)
AGI takeoff is an event we as a culture have never seen before, except in popular culture. So, that in mind, reporters draw on the only good reference points the population has, sci fi.
What would sane AI reporting look like? Is there a way to talk about AI to people who have only been exposed to the cultural background (if even that) in a way that doesn't either bore them or look at least as bad as this?
Replies from: KatjaGrace, KatjaGrace, Liso↑ comment by KatjaGrace · 2014-09-25T21:23:58.171Z · LW(p) · GW(p)
A reasonable analog I can think of is concern about corporations. They are seen as constructed to seek profit alone and thereby destroying social value, they are smarter and more powerful than individual humans, and the humans interacting with them (or even in them) can't very well control them or predict them. We construct them in some sense, but their ultimate properties are often unintentional.
↑ comment by KatjaGrace · 2014-09-25T21:18:17.533Z · LW(p) · GW(p)
The industrial revolution is some precedent, at least with respect to automation of labor. But it was long ago, and indeed, the possibility of everyone losing their jobs seems to be reported on more seriously than the other possible consequences of artificial intelligence.
Why does reporting need a historical precedent to be done in a sane-looking way?
↑ comment by Liso · 2014-09-25T03:58:03.273Z · LW(p) · GW(p)
what we have in history - it is hackable minds which were misused to make holocaust. Probably this could be one possibility to improve writings about AI danger.
But to answer question 1) - it is too wide topic! (social hackability is only one possibility of AI superpower takeoff path)
For example still miss (and probably will miss) in book:
a) How to prepare psychological trainings for human-AI communication. (or for reading this book :P )
b) AI Impact to religion
etc.
↑ comment by kgalias · 2014-09-23T18:51:29.067Z · LW(p) · GW(p)
What topic are you comparing it with?
When you specify that, I think the relevant question is: does the topic have an equivalent of a Terminator franchise?
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-25T21:19:30.141Z · LW(p) · GW(p)
War is taken fairly seriously in reporting, though there are a wide variety of war-related movies in different styles.
Replies from: kgalias↑ comment by kgalias · 2014-09-26T13:14:13.975Z · LW(p) · GW(p)
OK, but war happens in real life. For most people, the only time they hear of AI is in Terminator-like movies.
I'd rather compare it to some other technological topic, but which doesn't have a relevant franchise in popular culture.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-09-28T18:28:32.335Z · LW(p) · GW(p)
To be clear, you are saying that a thing will seem frivolous if it does have a relevant franchise, but hasn't happened in real life?
Some other technological topics that hadn't happened in real life when people became concerned about them:
- Nuclear weapons, had The World Set Free, though I'm not sure how well known it was (may have been seen as frivolous by most at first - I'm not sure, but by the time there were serious projects to build them I think not)
- Extreme effects from climate change, e.g. massive sea level rise, freezing of Northern Europe, no particular popular culture franchise (not very frivolous)
- Recombinant DNA technology, the public's concern was somewhat motivated by The Andromeda Strain) (not frivolous I think).
Evidence seems mixed.
Replies from: kgalias↑ comment by kgalias · 2014-09-29T23:11:53.541Z · LW(p) · GW(p)
To be clear, you are saying that a thing will seem frivolous if it does have a relevant franchise, but hasn't happened in real life?
Yes, that was my (tentative) claim.
We would need to know whether the examples were seen as frivolous after they came into being, but before the technology started being used.
↑ comment by slutbunwaller · 2014-09-23T17:27:07.409Z · LW(p) · GW(p)
To a great extent Less Wrong is what happens when somewhat intelligent, but very lazy people have ideas percolate through the coffee machine of their inferior minds and then try to present them as something new. All the crud and mistakes of the original ideas and thinkers gets included, but there's a delightful new after-taste and hue, from badly maintained filters and old grounds.
comment by PhilGoetz · 2014-10-07T00:27:12.682Z · LW(p) · GW(p)
In both GOFAI and ML, progress is hampered by the inconvenient fact that stupid methods perform unreasonably well. It's hard for a logic engine to out-perform a finite-state automata or regular expressions; it's hard for an ML system to out-perform naive Bayes, Markov models, or regression. Intelligence is usually more trouble than it's worth.
comment by TRIZ-Ingenieur · 2014-09-24T23:08:20.326Z · LW(p) · GW(p)
Intelligometry
Opinions about the future and expert elicitation
Predictions of our best experts, statistically evaluated, are nonetheless biased. Thank you Katja for contributing additional results and compiling charts. But enlarging quantity of people being asked will not result in better predictive quality. It would be funny to see results of a poll on HLMI time forecast within our reading group. But this will only tell us who we are and nothing about the future of AGI. Everybody in our reading group is at least a bit biased by having read chapters of Nick Bostrums book. Groupthink and biased perception are the biggest obstacles when predicting the future. Expert elicitation is no scientific methodology. It is collective educated guessing.
Trend extrapolation
Luke Muehlhauser commented Ray Kurzweils success in predicting when for the first time a chess program would defeat the human World Champion:
Those who forecasted this event with naive trend extrapolation (e.g. Kurzweil 1990) got almost precisely the correct answer (1997).
Luke Muehlhauser opened my eyes by admitting:
Hence, it may be worth searching for a measure for which (a) progress is predictable enough to extrapolate, and for which (b) a given level of performance on that measure robustly implies the arrival of Strong AI. But to my knowledge, this has not yet been done, and it’s not clear that trend extrapolation can tell us much about AI timelines until such an argument is made, and made well.
For Weak AI problems trend extrapolation is working. In image processing research it is common to accept computing times of minutes for a single frame of a real-time video sequence: Hardware and software will advance and can be scaled. Within five years this new algorithm will become real time capable. Weak AI capability is easily measurable. Scaling efficiency of many Weak AI problems (e.g. if search trees are involved) is dominantly linear and therefore predictable.
For Strong AI let's make trend prediction work! Let's call our tool Intelligometry. I coined this term today and I hope it will bring us forward towards scientific methodology and predictability.
Intelligometry: Theory of multidimensional metrics to measure skills and intelligence. The field of intelligometry involves development and standardization of tests to get objective comparability between HI and AI systems.
Unfortunately the foundation of intelligence metrics is scarce. The anthropocentric IQ measure with a mean of 100 and standard deviation of 15 (by definition) is the only widely accepted intelligence metrics for humans. Short IQ tests cover only 2 sigma range. These tests can give results from 70 to 130. Extensive tests cover as well up to 160.
Howard Gardners theory of multiple intelligences could be a starting point for test designs. He identifies 9 intelligence modalities:
- Musical–rhythmic and harmonic
- Visual–spatial
- Verbal–linguistic
- Logical–mathematical
- Bodily–kinesthetic
- Interpersonal
- Intrapersonal
- Naturalistic
- Existential
Although there is some criticism and marginal empirical proof, education received stimulus by this theory. It could be that humans have highly intercorrelated intelligence modalities and the benefit of this differentiation is not so high. Applied to AI systems with various architectures we can expect to find significant differences.
Huge differences in AI capabilities compared to human and other AIs make a linear scale impractical. Artificial intelligence measures should be defined on a logarithmic scale. Two examples: To multiply two 8-digit numbers a human might need 100s. A 10MFlops smart phone processor would process 1E9 times as much multiplications. RIKENs K computer (4th on Top500) with 10PFlops is 1E18 times faster than a human. On the contrary: A firefighter can run though complex unknown rooms may be 100 times faster than a Robocup rescue challenge robot. The robot is 1E-2 times "faster".
We shoud inspire other researchers to challenge humans with exact the same task they challenge their machines. They should generate solid data for statistical analysis. Humans of both sexes and all age classes should be tested. Joint AI and psychology research will bring synergistic effects.
It is challenging to design tests that are able to discriminate the advancement of an AI from very low capabilities, e.g. from 1E-6 to 1E-5. If the test consists of complex questions it could be that the AI answers 10% correctly by guessing. The advance from 100,001 correct answers to 100,010 correct ones means that true understanding of the AI improved by a factor of 10. The tiny difference probably remains undetected in the noise of guessing.
Intelligometry could supply methodology and data we need for proper predictions. AI research should manage to establish a standardized way of documentation. These standards shall be part of all AI curricula. Public funded AI related research projects should use standardized tests and documentation schemes. If we manage to move from educated guessing to trend extrapolation on solid data within the next ten years (3 PhD generations) we have managed a lot. This will be for the first time a reliable basis for predictions. These predictions will be the solid ground to guide our governments and research institutes regarding global action plans towards a sustainable future for us humans.