4 Key Assumptions in AI Safety
post by Prometheus · 2022-11-07T10:50:40.211Z · LW · GW · 5 commentsContents
AGI will happen before other dangerous, potentially catastrophic AIs AGI will be agentic AGI will be a goal-directed RL system AGI will be coherent None 5 comments
AGI is already a very difficult topic, with a large amount of uncertainty, and not enough research being done for its core problems. However, I think even with this understanding, its vastness in scope of possibilities might still be severely under-realized. I’ve listed four major assumptions I think many make about what transformative AI will look like. Many of these are assumptions I have made in the past, as well as others. Some in the field have voiced their uncertainty, and it’s hard for me to determine just how many are working under these assumptions. I will also note that while I view these to be assumptions, that does not mean they are incorrect assumptions, only that acknowledging them as such might help us steer toward avenues currently under researched. My views are also continuously evolving, so I welcome any feedback if I’m somehow missing something crucial. I also expect to find a number of comments explaining that some actually are working on research outside of these assumptions, and welcome them to point me to the work they are doing.
AGI will happen before other dangerous, potentially catastrophic AIs
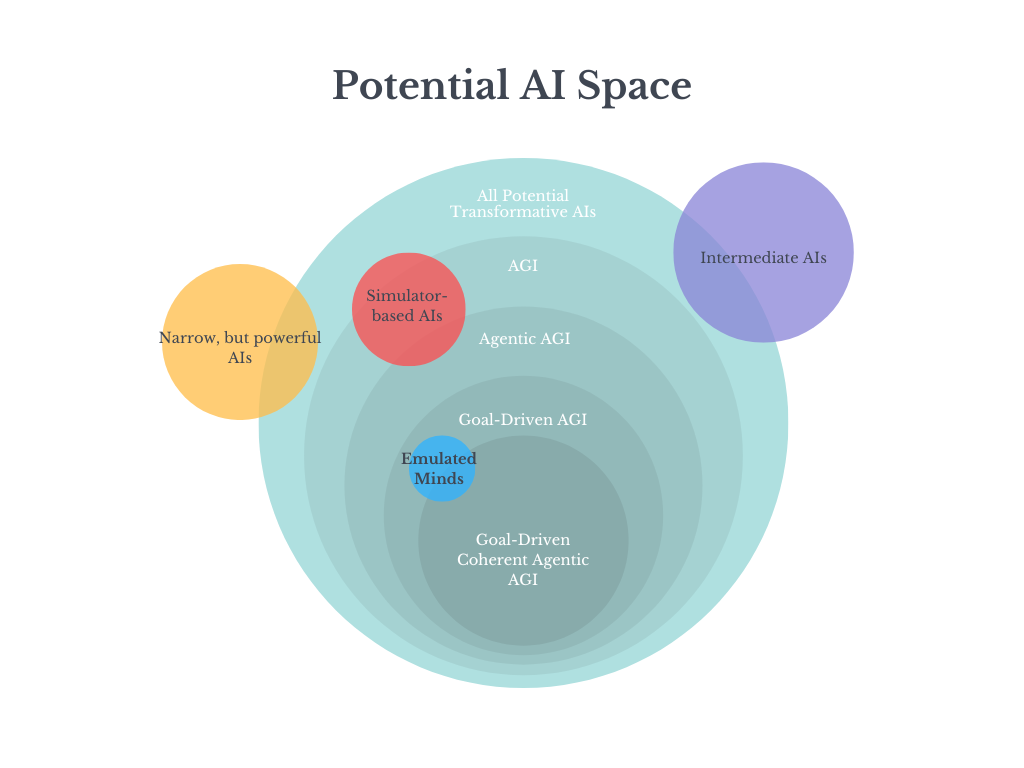
This is the biggest assumption, and I think the most probable to be wrong. What we are currently seeing is narrow AIs becoming more and more general, and more and more powerful. Alpha Go Zero was more general and powerful and Alpha Go, Alpha Zero more so than Go Zero, and Mu Zero more powerful and general than any of them. A few years ago, Natural Language Processing was limited to word-to-vector and markov chains. Now we have extremely sophisticated NLP trained on enormous word corpuses, and math transformers that can can generalize out of distribution. If this trend continues, we will develop very powerful AIs that are capable of posing an existential risk before we arrive at full AGI. I think these other Transformative AIs can be called Intermediate AIs.
There seems to be an assumption that AGI will occur with a breakthrough that is radically different from what we currently have. But if things continue to scale, I do not believe any breakthrough is needed to create very dangerous and powerful systems. With the rate of scale, we will likely see GPT-3s at 100x scale [LW · GW] in just a few years.
What makes this very dangerous, is that we might cross a dangerous point of no return without even realizing it. We’re starting to see an “intelligence of the gaps”, where intelligence equates to anything that isn’t yet achieved or understood.
“Chess can only be played by a general intelligence.”
“It’s just using a crude algorithm, it doesn’t really understand the game.”
“Go is different. That would take a powerful intelligence.”
“It’s just copying other people’s strategies.”
“Okay, maybe it’s not copying any strategies, but it still doesn’t count as intelligence. It’s only good at playing Go.”
“It’s only good at playing Go and Chess.”
“It’s only good at playing Go, Chess, and Atari games.”
“Language is the bedrock of human intelligence.”
“It doesn’t actually understand language, it’s just predicting word tokens.”
“You need intelligence to create art.”
“That’s not art. It’s just imitation.”
“Those aren’t real jokes, it doesn’t actually understand humor.”
“It’s just copying other people’s code.”
Creating AGI has been compared to the difference between the flight of a bird (organic flight) and a plane (artificial flight)*. But we might also have differences in achieving flight, such as the difference between a plane and a hobby drone. Our idea of flight, if we only have birds to go off of, will assume you need wings, and that it needs to make use of air flows over the control surfaces on their wings and tails, and that you would need to use this air flow if you want to change altitude, direction, and velocity. A drone can fly with just thrust and propellers. “Look at that drone! That’s not flight! That’s just some kind of hack imitating flight!” A hobby drone does not have all the capabilities of an airplane. It’s not as big as you might expect a flying machine to be. But many things an airplane can do can be repurposed to be achieved by a drone, or a whole fleet of them. And both drones and planes can scale.
I don’t think the most likely outcome in the future is that some lab is going to “crack general intelligence”. I think it’s much more likely that AIs continue to gain more and more capabilities of humans, only much faster and better. And I think this will cross a dangerous threshold before a “true AGI” is achieved.
I also believe these AIs could be Transformative. Many consider Transformative AI to be PASTA, but I think this definition is also too narrow. What do we call an AI that is incapable of general improvements to science, but is extremely capable of predicting protein structures?** Before a full TAI occurs, we might see AIs that are very capable of making huge developments in various fields. This alone could take us to a world that starts to quickly get very weird and dangerous.***
It is also possible that a non-AGI will still be able to become very good at deceptive tactics, or self-optimize itself. Deception could simply be a less narrow and more powerful form of chat/spam bots we see today. We already see how GPT-3 can fool many humans. Models that over time will be accessible to more people, be cheaper and faster to train, and better optimized, could see a new form of deceptive tactics occurring. Self-optimization could occur from an Intermediate AI’s base selecting for a mesaoptimizer. I do not see why the mesa has to have general intelligence to find a path of self-optimization, just as Alpha Zero did not need general intelligence to predict its own behavior, or Mu Zero to learn rules to a variety of games without a perfect simulator. This could create a runaway takeoff of Intermediate AIs.
I’m aware that many people would not define AGI as needing to have full human range in capability. But many tend to also assume that a more general intelligence will still possess features such as self-awareness, which I don’t think will necessarily occur before we have dangerous TAI.
AGI will be agentic
There seems to be a core assumption that General Intelligence == Agency. While agentic behavior can come out of general intelligent systems (us), we do not know if it’s actually required. GPT is a very powerful AI system, and yet it appears to be systematically myopic and non-agentic [LW · GW]. And yet non-myopic behavior seems to be exhibited. It “plans” for how words can fit into sentences, how sentences fit into paragraphs, and paragraphs fit into stories. All of this occurs despite it only being “concerned” with predicting the next token.
If AGI will not be agentic, a great amount of Alignment research might be far too narrow. The space of possible AGIs might be far, far wider, with current research only taking a narrow chunk. Since many have their own definition of what constitutes agency, the next two assumptions I think address features that are normally associated with this word. I’ve listed them separately, since not all believe the next two assumptions are required for a form of agency. For instance, I think you could have an agent that has behaviors that lead to certain outcomes, but doesn’t possess any kind of end goal it is optimizing toward (more explained in Assumption 3). I think it is also possible to have an agent that is not coherent, since humans seem agentic and incoherent in goal seeking (more explained in Assumption 4). Overall, it’s not that I think there’s too much research into how an AI Agent might behave, it’s that I think there is too little research into how an AI non-agent might behave.
AGI will be a goal-directed RL system
This was the assumption when RLs were the only AIs really doing anything interesting. But I think major updates need to be made in how we frame what an AGI could be, as we see more and more powerful AI systems being developed without the use of Reinforcement Learning.
It is many times assumed that an AGI will also be goal-directed. This is normally phrased with the following argument [? · GW]:
Very intelligent AI systems will be able to make long-term plans in order to achieve their goals, and if their goals are even slightly misspecified then the AI system will become adversarial and work against us.
But not all AIs need to be goal directed [AF · GW] or have preferences. It might just have a set of different behaviors [LW(p) · GW(p)] that are strengthened and reinforced without having a goal it is optimizing for [LW · GW]. Instead of optimizing for eating bananas, it might instead optimize certain behaviours [LW · GW]. For example 1: if tree is visible in optics, reach out hand; 2: if banana in hand, peel; and 3: if peeled banana in hand, bite.**** There is nothing in this that results in the AGI seeking to eat as many bananas as it can, or plant an endless array of banana trees, or turn the whole Universe into bananas. I do not expect an AGI has to be bounded within human levels, but a lot of current work assumes an AGI will have some kind of final goal.
It is believed by some that an AGI might develop long-term policies [AF · GW] that behave in an obedient fashion for a time, because they believe that they will get higher reward in the future to maximize their “actual goals”. But from a behavioral perspective, that same “deceptive” behavior is being strengthened and reinforced the whole time, which it seems will make that behavior more likely to happen in the future.
This is not to say that this will make the AGI safe, only that current work of “getting the AGI to have a goal that’s aligned with what we actually want” might not be the core problem, and might be too narrow in scope.
AGI will be coherent
Even if we get an agentic goal-directed AGI, this does not mean it will be coherent. In terms of coherence, I mean that an AGI’s behavior and policies are maximizing for a specific goal. I am a generally intelligent system, and I am certainly far from coherent in my goal seeking. Right now, I want to write this article, but I also concurrently want to get coffee, and also want to sleep. These are all separate goals, even if they originated from “make more copies of genes”. And I am not going to sleep for 48 hours straight, drink 3 gallons of coffee in one go, or keep writing until the muscles in my fingers tear. An AGI trained on any variety of complex tasks might develop multiple goals, without trying to maximize just one into infinity.
All of this doesn’t downplay the risk of AI. It actually makes the uncertainty even higher. I am likely wrong about a number of these points, but am uncertain about which points I am wrong about. I worry that AI Safety might be developing models that are too narrow, and that new researchers will simply build on top of them, without considering that they might be wrong. What I hope to see is more researchers tackling AI not just from different angles, but at different parts of the “potential AI space”.
*Saying “artificial flight” feels very strange. And if we survive past the inception of powerful AIs, “artificial intelligence” will likely also start to feel strange.
**I do not believe AlphaFold is at this level yet. But we’re already seeing attempts made, with some degree of success.
***I was originally going to go into more detail of how the “dangerous” part might be done, but I don’t really want to give anyone ideas, since I don’t know how long these sorts of capabilities will only be in the hands of a few large organizations, or what future capabilities might look like. Unfortunately, I don’t think any of my ideas for this are that original, I just don’t want to spread them further.
****Yes, I know robots don’t eat bananas. Or maybe that’s just an assumption I’m making.
5 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-11-07T16:17:13.245Z · LW(p) · GW(p)
There seems to be a core assumption that General Intelligence == Agency. While agentic behavior can come out of general intelligent systems (us), we do not know if it’s actually required.
Yeah, it is - just part of the definition. Intelligence is steering the future - which requires both predicting possible futures and then selecting some over others.
GPT is a very powerful AI system, and yet it appears to be systematically myopic and non-agentic. And yet non-myopic behavior seems to be exhibited. It “plans” for how words can fit into sentences, how sentences fit into paragraphs, and paragraphs fit into stories. All of this occurs despite it only being “concerned” with predicting the next token.
GPT by itself is completely non agentic - it is purely a simulator. However any simulator of humans will then necessarily have agentic simulacra. That is just required for accurate simulation, but it doesn't make the simulator itself an agent. But humans could use a powerful simulator to enhance their decision making, at which point the simulator and the human become a cybernetic agent.
Replies from: gbear605, Prometheus↑ comment by gbear605 · 2022-11-07T22:38:39.950Z · LW(p) · GW(p)
That seems like a really limiting definition of intelligence. Stephen Hawking, even when he was very disabled, was certainly intelligent. However, his ability to be agentic was only possible thanks to the technology he relied on (his wheelchair and his speaking device). If that had been taken away from him, he would no longer have had any ability to alter the future, but he would certainly still have been just as intelligent.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-11-07T22:41:39.460Z · LW(p) · GW(p)
It's just the difference between potential and actualized.
↑ comment by Prometheus · 2022-11-08T02:38:14.460Z · LW(p) · GW(p)
Perhaps it's better to avoid the word intelligence, then. Semantics isn't really important. What is important is I can imagine a non-agentic simulator or some other entity having severely transformative chances, some of which could be catastrophic.