How Many Bits Of Optimization Can One Bit Of Observation Unlock?
post by johnswentworth · 2023-04-26T00:26:22.902Z · LW · GW · 15 commentsThis is a question post.
Contents
Toy Example
Operationalization
None
Answers
20 johnswentworth
5 johnswentworth
3 Ben Amitay
None
15 comments
So there’s this thing where a system can perform more bits of optimization on its environment by observing some bits of information from its environment. Conjecture: observing an additional bits of information can allow a system to perform at most additional bits of optimization. I want a proof or disproof of this conjecture.
I’ll operationalize “bits of optimization” in a similar way to channel capacity, so in more precise information-theoretic language, the conjecture can be stated as: if the sender (but NOT the receiver) observes bits of information about the noise in a noisy channel, they can use that information to increase the bit-rate by at most bits per usage.
For once, I’m pretty confident that the operationalization is correct, so this is a concrete math question.
Toy Example
We have three variables, each one bit: Action (), Observable (), and outcome (). Our “environment” takes in the action and observable, and spits out the outcome, in this case via an xor function:
We’ll assume the observable bit has a 50/50 distribution.
If the action is independent of the observable, then the distribution of outcome is the same no matter what action is taken: it’s just 50/50. The actions can perform zero bits of optimization; they can’t change the distribution of outcomes at all.
On the other hand, if the actions can be a function of , then we can take either or (i.e. not-), in which case will be deterministically 0 (if we take ), or deterministically 1 (for ). So, the actions can apply 1 bit of optimization to , steering deterministically into one half of its state space or the other half. By making the actions a function of observable , i.e. by “observing 1 bit”, 1 additional bit of optimization can be performed via the actions.
Operationalization
Operationalizing this problem is surprisingly tricky; at first glance the problem pattern-matches to various standard info-theoretic things, and those pattern-matches turn out to be misleading. (In particular, it’s not just conditional mutual information, since only the sender - not the receiver - observes the observable.) We have to start from relatively basic principles.
The natural starting point is to operationalize “bits of optimization” in a similar way to info-theoretic channel capacity. We have 4 random variables:
- “Goal”
- “Action”
- “Observable”
- “Outcome”
Structurally:
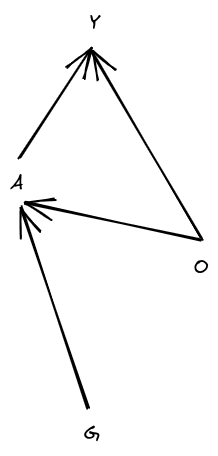
(This diagram is a Bayes net; it says that and are independent, is calculated from and and maybe some additional noise, and is calculated from and and maybe some additional noise. So, .) The generalized “channel capacity” is the maximum value of the mutual information , over distributions .
Intuitive story: the system will be assigned a random goal , and then take actions (as a function of observations ) to steer the outcome . The “number of bits of optimization” applied to is the amount of information one could gain about the goal by observing the outcome .
In information theoretic language:
- is the original message to be sent
- is the encoded message sent in to the channel
- is noise on the channel
- is the output of the channel
Then the generalized “channel capacity” is found by choosing the encoding to maximize .
I’ll also import one more assumption from the standard info-theoretic setup: is represented as an arbitrarily long string of independent 50/50 bits.
So, fully written out, the conjecture says:
Let be an arbitrarily long string of independent 50/50 bits. Let , , and be finite random variables satisfying
and define
Then
Also, one slightly stronger bonus conjecture: is at most under the unconstrained maximal .
(Feel free to give answers that are only partial progress, and use this space to think out loud. I will also post some partial progress below. Also, thankyou to Alex Mennen for some help with a couple conjectures along the path to formulating this one.)
Answers
Alright, I think we have an answer! The conjecture is false.
Counterexample: suppose I have a very-high-capacity information channel (N bit capacity), but it's guarded by a uniform random n-bit password. O is the password, A is an N-bit message and a guess at the n-bit password. Y is the N-bit message part of A if the password guess matches O; otherwise, Y is 0.
Let's say the password is 50 bits and the message is 1M bits. If A is independent of the password, then there's a chance of guessing the password, so the bitrate will be about * 1M , or about one-billionth of a bit in expectation.
If A "knows" the password, then the capacity is about 1M bits. So, the delta from knowing the password is a lot more than 50 bits. It's a a multiplier of , rather than an addition of 50 bits.
This is really cool! It means that bits of observation can give a really ridiculously large boost to a system's optimization power. Making actions depend on observations is a potentially-very-big game, even with just a few bits of observation.
Credit to Yair Halberstadt in the comments [LW(p) · GW(p)] for the attempted-counterexamples which provided stepping stones to this one.
↑ comment by dr_s · 2023-04-27T09:17:41.092Z · LW(p) · GW(p)
This is interesting, but it also feels a bit somehow like a "cheat" compared to the more "real" version of this problem (namely, if I know something about the world and can think intelligently about it, how much leverage can I get out of it?).
The kind of system in which you can pack so much information in an action and at the cost of a small bit of information you get so much leverage feels like it ought to be artificial. Trivially, this is actually what makes a lock (real or virtual) work: if you have one simple key/password, you get to do whatever with the contents. But the world as a whole doesn't seem to work as a locked system (if it did, we would have magic: just a tiny, specific formula or gesture and we get massive results down the line).
I wonder if the key here isn't in the entropy. Your knowing O here allows you to significantly reduce the entropy of the world as a whole. This feels akin to being a Maxwell demon. In the physical world though there are bounds on that sort of observation and action exactly because to be able to do them would allow you to violate the 2nd principle of thermodynamics. So I wonder if the conjecture may be true under some additional constraints which also include these common properties of macroscopic closed physical systems (while it remains false in artificial subsystems that we can build for the purpose, in which we only care about certain bits and not all the ones defining the underlying physical microstates).
Replies from: johfst, johnswentworth↑ comment by jeremy (johfst) · 2023-04-28T07:55:33.183Z · LW(p) · GW(p)
I'm not sure about that; it seems like there's lots of instances where just a few bits of knowledge gets you lots of optimization power. Knowing Maxwell's equations lets you do electronics, and knowing which catalyst to use for the Haber process lets you make lots of food and bombs. If I encoded the instructions for making a nanofactory, that would probably be few bits compared to the amount of optimization you could do with that knowledge.
Replies from: dr_s↑ comment by dr_s · 2023-04-28T09:08:51.048Z · LW(p) · GW(p)
The important thing is that your relevant information isn't about the state of the world, it's about the laws. That's the evolution map , not the region (going by the nomenclature I used in my other comment). Your knowledge about when using the Haber process is actually roughly proportional to the output: you need to know that inside tank X there is such-and-such precursor, and it's pure to a certain degree. That's like knowing that a certain region of the bit string is prepared purely with s. But the laws are an interesting thing because they can have regularities (in fact, we do know they have them), so that they can be represented in compressed form, and you can exploit that knowledge. But also, to actually represent that knowledge in bits of world-knowledge you'd need to represent the state of all the experiments that were performed and from which that knowledge was inferred and generalized. Though volume wise, that's still less than the applications... unless you count each application also as a further validation of the model that updates your confidence in it, at which point by definition the bits of knowledge backing the model are always more than the bits of order you got out of it.
↑ comment by johnswentworth · 2023-04-27T15:46:11.669Z · LW(p) · GW(p)
Ah, interesting. If I were going down that path, I'd probably aim to use a Landauer-style argument. Something like, "here's a bound on mutual information between the policy and the whole world, including the agent itself". And then a lock/password could give us a lot more optimization power over one particular part of the world, but not over the world as a whole.
... I'm not sure how to make something like that nontrivial, though. Problem is, the policy itself would then presumably be embedded in the world, so is just .
Replies from: dr_s↑ comment by dr_s · 2023-04-27T16:35:50.314Z · LW(p) · GW(p)
Here's my immediate thought on it: you define a single world bit string , and , and are just designated subsections of it. You are able to know only the contents of , and can set the contents of (this feels like it's reducing the entropy of the whole world btw, so you could also postulate that you can only do so by drawing free energy from some other region, your fuel : for each bit of you set deterministically, you need to randomize two of , so that the overall entropy increases). After this, some kind of map is applied repeatedly, evolving the system until such time comes to check that the region is indeed as close as possible to your goal configuration . I think at this point the properties of the result will depend on the properties of the map - is it a "lock" map like your suggested one (compare a region of with , and if they're identical, clone the rest of into , possibly using up to keep the entropy increase positive?). Is it reversible, is it chaotic?
Yeah, not sure, I need to think about it. Reversibility (even acting as if these were qubits and not simple bits) might be the key here. In general I think there can't be any hard rule against lock-like maps, because the real world allows building locks. But maybe there's some rule about how if you define the map itself randomly enough, it probably won't be a lock-map (for example, you could define a map as a series of operations on two bits writing to a third one ; decide a region of your world for it, encode bit indices and operators as bit strings, and you can make the map's program itself a part of the world, and then define what makes a map a lock-like map and how probable that occurrence is).
↑ comment by johnswentworth · 2023-04-26T21:02:22.702Z · LW(p) · GW(p)
The new question is: what is the upper bound on bits of optimization gained from a bit of observation? What's the best-case asymptotic scaling? The counterexample suggests it's roughly exponential, i.e. one bit of observation can double the number of bits of optimization. On the other hand, it's not just multiplicative, because our xor example at the top of this post showed a jump from 0 bits of optimization to 1 bit from observing 1 bit.
Replies from: M. Y. Zuo, FireStormOOO, Will_BC↑ comment by M. Y. Zuo · 2023-04-26T22:29:53.886Z · LW(p) · GW(p)
Isn't it unbounded?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-04-26T22:33:43.886Z · LW(p) · GW(p)
In an absolute sense, yes, but I expect it can be bounded as a function of bits of optimization without observation. For instance, if we could only at-most double the number of bits of opt by observing one bit, then that would bound bit-gain as a function of bits of optimization without observation, even though it's unbounded in an absolute sense.
Unless you're seeing some stronger argument which I have not yet seen?
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2023-04-26T22:42:30.977Z · LW(p) · GW(p)
The scaling would also be unbounded, at least that would be my default assumption without solid proof otherwise.
In other words I don't see any reason to assume there must be any hard cap, whether at 2x or 10x or 100x, etc...
Replies from: johnswentworth, johnswentworth, johnswentworth↑ comment by johnswentworth · 2023-04-26T23:34:46.503Z · LW(p) · GW(p)
↑ comment by johnswentworth · 2023-04-26T23:14:47.258Z · LW(p) · GW(p)
↑ comment by johnswentworth · 2023-04-26T23:06:58.872Z · LW(p) · GW(p)
Here are two intuitive arguments:
- If we can't observe O, we could always just guess a particular value of O and then do whatever's optimal for that value. Then with probability P[O], we'll be right, and our performance is lower bounded by P[O]*(whatever optimization pressure we're able to apply if we guess correctly).
- The log-number of different policies bounds the log-number of different outcome-distributions we can achieve. And observing one additional bit doubles the log-number of different policies.
↑ comment by FireStormOOO · 2023-04-27T00:57:25.346Z · LW(p) · GW(p)
It's possible to construct a counterexample where there's a step from guessing at random to perfect knowledge after an arbitrary number of observed bits; n-1 bits of evidence are worthless alone and the nth bit lets you perfectly predict the next bit and all future bits.
Consider for example shifting bits in one at a time into the input of a known hash function that's been initialized with an unknown value (and known width) and I ask you to guess a specified bit from the output; in the idealized case, you know nothing about the output of the function until you learn the final bit in the input (all unknown bits have shifted out) b/c they're perfectly mixed, and after that you'll guess every future bit correctly.
Seems like the pathological cases can be arbitrarily messy.
Replies from: yair-halberstadt↑ comment by Yair Halberstadt (yair-halberstadt) · 2023-04-27T14:13:17.775Z · LW(p) · GW(p)
I don't think that matters, because knowing all but the last bit, I can simply take two actions - action assuming last bit is true, and action assuming it's false.
Replies from: FireStormOOO↑ comment by FireStormOOO · 2023-04-27T16:15:21.968Z · LW(p) · GW(p)
Not sure I'm following the setup and notation quite close enough to argue that one way or the other, as far as the order we're saying the agent receives evidence and has to commit to actions. Above I was considering the simplest case of 1 bit evidence in, 1 bit action out, repeat.
I pretty sure that could be extended to get that one small key/update that unlocks the whole puzzle sort of effect and have the model click all at once. As you say though, not sure that gets to the heart of the matter regarding the bound; it may show that no such bound exists on the margin, the last piece can be much more valuable on the margin than all the prior pieces of evidence, but not necessarily in a way that violates the proposed bound overall. Maybe we have to see that last piece as unlocking some bounded amount of value from your prior observations.
↑ comment by Will_BC · 2023-05-11T15:15:14.531Z · LW(p) · GW(p)
I think it depends on the size of the world model. Imagine an agent with a branch due to uncertainty between two world models. It can construct these models in parallel but doesn't know which one is true. Every observation it makes has two interpretations. A single observation which conclusively determines which branch world model was correct I think could produce an arbitrarily large but resource bounded update.
Eliminating G
The standard definition of channel capacity makes no explicit reference to the original message ; it can be eliminated from the problem. We can do the same thing here, but it’s trickier. First, let’s walk through it for the standard channel capacity setup.
Standard Channel Capacity Setup
In the standard setup, cannot depend on , so our graph looks like
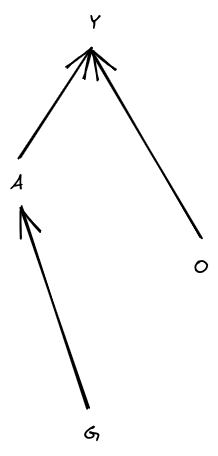
… and we can further remove entirely by absorbing it into the stochasticity of .
Now, there are two key steps. First step: if is not a deterministic function of , then we can make a deterministic function of without reducing . Anywhere is stochastic, we just read the random bits from some independent part of instead; will have the same joint distribution with any parts of which was reading before, but will also potentially get some information about the newly-read bits of as well.
Second step: note from the graphical structure that mediates between and . Since is a deterministic function of and mediates between and , we have .
Furthermore, we can achieve any distribution (to arbitrary precision) by choosing a suitable function .
So, for the standard channel capacity problem, we have , and we can simplify the optimization problem:
Note that this all applies directly to our conjecture, for the part where actions do not depend on observations.
That’s how we get the standard expression for channel capacity. It would be potentially helpful to do something similar in our problem, allowing for observation of .
Our Problem
The step about determinism of carries over easily: if is not a deterministic function of and , then we can change to read random bits from an independent part of . That will make a deterministic function of and without reducing .
The second step fails: does not mediate between and .
However, we can define a “Policy” variable
is also a deterministic function of , and does mediate between G and Y. And we can achieve any distribution over policies (to arbitrary precision) by choosing a suitable function .
So, we can rewrite our problem as
In the context of our toy example: has two possible values, and . If takes the first value, then is deterministically 0; if takes the second value, then is deterministically 1. So, taking the distribution to be 50/50 over those two values, our generalized “channel capacity” is at least 1 bit. (Note that we haven’t shown that no achieves higher value in the maximization problem, which is why I say “at least”.)
Back to the general case: our conjecture can be expressed as
where the first optimization problem uses the factorization
and the second optimization problem uses the factorization
I didn't think much about the mathematical problem, but I think that the conjecture is at least wrong in spirit, and that LLMs are good counterexample for the spirit. An LLM by its own is not very good at being an assistant, but you need pretty small amounts of optimization to steer the existing capabilities toward being a good assistant. I think about it as "the assistant was already there, with very small but not negligible probability", so in a sense "the optimization was already there", but not in a sense that is easy to capture mathematically.
15 comments
Comments sorted by top scores.
comment by beren · 2023-04-26T09:12:47.501Z · LW(p) · GW(p)
Interesting thoughts! By the way, are you familiar with Hugo Touchette's work on this? which looks very related and I think has a lot of cool insights about these sorts of questions.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-04-26T18:13:18.427Z · LW(p) · GW(p)
Hadn't seen that before, thankyou.
comment by Yair Halberstadt (yair-halberstadt) · 2023-04-26T10:52:49.134Z · LW(p) · GW(p)
I presume I'm not understanding something, so why isn't this a trivial counterexample:
I know a channel either strips out every 11, or every 00. This forces me to perform some sort of encoding scheme to ensure we send the same message either way. Observing a single bit of information (whether 11 or 00 is stripped out), allows me to use a much simpler encoding, saving a large number of bits.
Replies from: johnswentworth, Thomas Sepulchre↑ comment by johnswentworth · 2023-04-26T18:12:44.561Z · LW(p) · GW(p)
After chewing it on it a bit, I find it very plausible that this is indeed a counterexample. However, it is not obvious to me how to prove that there does not exist some clever encoding scheme which would achieve bit-throughput competitive with the O-dependent encoding without observing O. (Note that we don't actually need to ensure the same Y pops out either way, we just need the receiver to be able to distinguish between enough possible inputs A by looking at Y.)
Replies from: yair-halberstadt↑ comment by Yair Halberstadt (yair-halberstadt) · 2023-04-26T18:50:23.261Z · LW(p) · GW(p)
Ok simpler example:
You know the channel either removes all 0s or all 1s, but you don't know which.
The most efficient way to send a message is to send n 1s, followed by n 0s, where n is the number the binary message you want to send represents.
If you know whether 1s or 0s are stripped out, then you only need to send n bits of information, for a total saving of n bits.
EDIT: this doesn't work, see comment by AlexMennen.
Replies from: AlexMennen, johnswentworth, johnswentworth↑ comment by AlexMennen · 2023-04-26T19:33:33.392Z · LW(p) · GW(p)
I don't think this one works. In order for the channel capacity to be finite, there must be some maximum number of bits N you can send. Even if you don't observe the type of the channel, you can communicate a number n from 0 to N by sending n 1s and N-n 0s. But then even if you do observe the type of the channel (say, it strips the 0s), the receiver will still just see some number of 1s that is from 0 to N, so you have actually gained zero channel capacity. There's no bonus for not making full use of the channel; in johnswentworth's formulation of the problem, there's no such thing as some messages being cheaper to transmit through the channel than others.
Replies from: yair-halberstadt↑ comment by Yair Halberstadt (yair-halberstadt) · 2023-04-26T19:45:32.032Z · LW(p) · GW(p)
A fair point. Or a similar argument, you can only transfer one extra bit of information this way, since the message representing a number of size 2n is only 1 bit larger than the message representing n.
↑ comment by johnswentworth · 2023-04-26T20:11:53.038Z · LW(p) · GW(p)
Trying to patch the thing which I think this example was aiming for:
Let A be an n-bit number, O be 0 or 1 (50/50 distribution). Then let Y = A if , else Y = 0. If the sender knows O, then they can convey n-1 bits with every message (i.e. n bits minus the lowest-order bit). If the sender does not know O, then half the messages are guaranteed to be 0 (and which messages are 0 communicates at most 1 bit per, although I'm pretty sure it's in fact zero bits per in this case, so no loophole there). So at most ~n/2 bits per message can be conveyed if the sender does not know O.
So, sender learning the one bit O doesn't add one bit to the capacity, it doubles the capacity.
I'm now basically convinced that that's the answer; the conjecture is false.
I now expect that the upper limit to bits of optimization gained from one bit of observation is ~doubling the number of bits of optimization (as in this example). Though we also know that observing one bit can take us from zero bits of optimization to one bit of optimization, so it's not as simple as just doubling; there's at least a small additional term in there.
Replies from: yair-halberstadt↑ comment by Yair Halberstadt (yair-halberstadt) · 2023-04-27T05:50:47.236Z · LW(p) · GW(p)
That sounds about right.
Tripling is I think definitely a hard max since you can send 3 messages, action if true, action if false, + which is which - at least assuming you can reliably send a bit at all without the observation.
More tightly it's doubling + number of bits required to send a single bit of information.
↑ comment by johnswentworth · 2023-04-26T19:46:39.921Z · LW(p) · GW(p)
Damn, that one sounded really promising at first, but I don't think it works. Problem is, if A is fixed-length, then knowing the number of 1's also tells us the number of 0's. And since we get to pick P[A] in the optimization problem, we can make A fixed-length.
EDIT: oh, Alex beat me to the punch.
↑ comment by Thomas Sepulchre · 2023-04-26T12:00:13.733Z · LW(p) · GW(p)
The post says
Let be an arbitrarily long string of independent 50/50 bits.
I believe that, in your example, the bits are not independent (indeed, the first and second bits are always equal), thus it isn't a counterexample.
Sorry if I misunderstood
Replies from: johnswentworth↑ comment by johnswentworth · 2023-04-26T16:37:47.465Z · LW(p) · GW(p)
G can still be independent bits in the proposed counterexample. The mechanism is just about how Y is constructed from A: A is a sequence of bits, Y is A with either 11's removed or 00's removed.
comment by tailcalled · 2023-04-26T08:35:18.501Z · LW(p) · GW(p)
Channel capacity between goals and outcomes is sort of a counterintuitive measure of optimization power to me, and so if there are any resources on it, I would appreciate them.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-04-29T17:26:45.504Z · LW(p) · GW(p)
I don't know of a good existing write-up on this, and I think it would be valuable for someone to write.
comment by dr_s · 2023-04-26T09:45:52.517Z · LW(p) · GW(p)
Just to clarify, why are both and treated as random variables? The way I understand it:
- is our Goal, so the string we want to get
- is whatever bits of the world we actually observe
- is the action we choose (depending on what we observe)
- is what we get as an outcome of the action
being called "observation", I feel like I'd assume it to be fully known. If can still not be fully determined by and then there's got to be some random noise (which we could represent as yet another string of bits, , representing the part of the world that we can't observe). What about being probabilistic, is this an allowance for our algorithm being imperfect and making mistakes? I feel like we could introduce yet another random variable for that independent from everything, and make and fully deterministic. Defined that way, the proposed theorem feels like it ought to be trivially true, though I haven't given it nearly enough thought yet to call that an answer. I'll give it a go later.