Probability vs Likelihood
post by abramdemski · 2020-11-10T21:28:03.934Z · LW · GW · 10 commentsContents
Why It Matters Base-Rate Neglect Conjunction Fallacy Using the Words Ambiguity & Context-Sensitivity Exchanging Virtual Evidence Propagating Posterior Probabilities Propagating Likelihoods None 10 comments
This expands on some issues I mentioned in Radical Probabilism [LW · GW].
A rationality pet-nitpick of mine, which is shared by almost no one, is the probable/likely distinction. I got my introduction to Bayesian thinking, in part, from Probabilistic Reasoning in Intelligent Systems by Judea Pearl. In the book, Pearl makes a simple distinction between probability and likelihood which I find to be quite wonderful: the likelihood of X given Y is just the probability of Y given X!
Probability of X given Y:
Likelihood of X given Y:
Why invent new terminology for something so simple?
What we're basically doing here is making a type distinction between probability and likelihoods, to help us remember that likelihoods can't be converted to probabilities without combining them with a prior.
In the context of the book, it's because Bayesian networks pass two types of messages: "probability" type messages pass prior-like information down the Bayesian network, and "likelihood" type messages pass evidence-like information up the network.
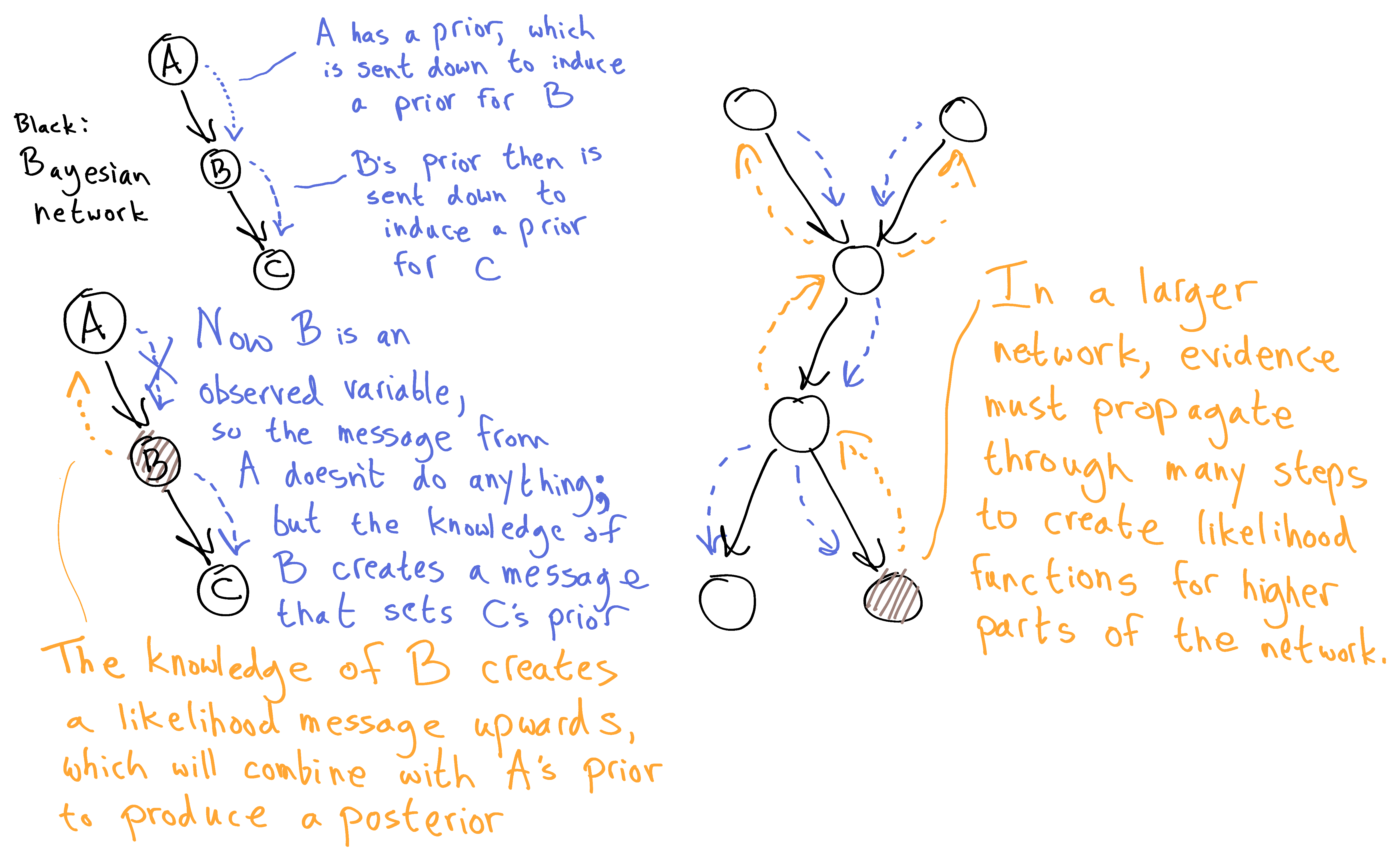
At each individual node, we need to combine a prior with evidence in order to get a posterior. However, we only start with prior information for the top nodes of the network, and we only start with evidence information for the observed nodes. In order to get the information we need for other nodes, we have to propagate information around the network via the two types of messages.
Another important aspect of the probability/likelihood distinction is that we swap our views of what varies and what remains fixed. When we regard P(A|B) as a probability function, rather than just a single probability judgement, we generally think of varying A. But when we use P(A|B) to construct a likelihood function for hypothesis testing, we think of A as the fixed evidence, and more readily vary B, which is now thought of as the hypothesis. Pearl's notation helps us track which thing we're holding steady vs which thing we're varying: we think of the first argument as what we're varying, and the second argument as what we're holding steady. Critically, probability functions sum to 1, while likelihood functions need not do so.
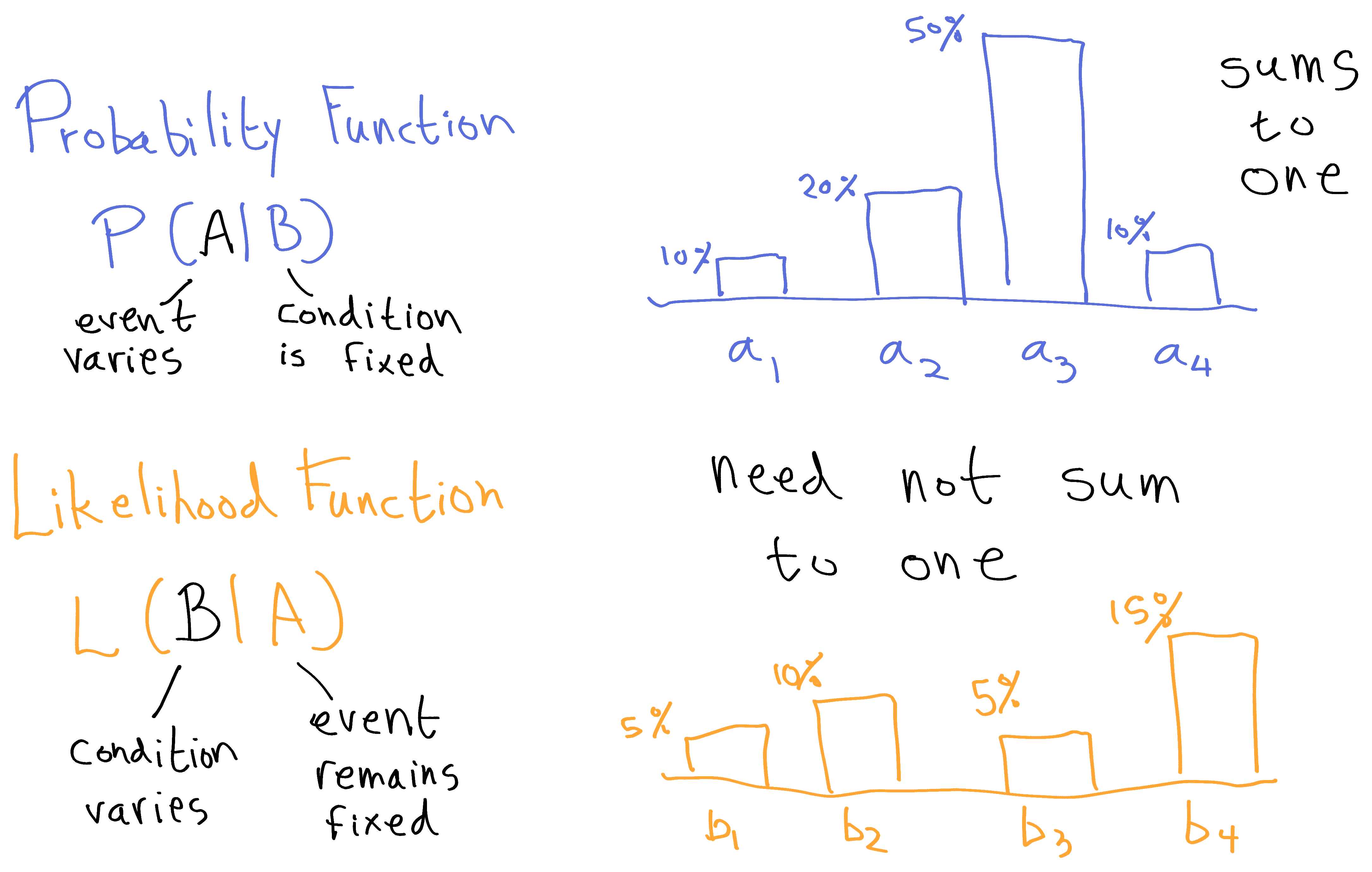
(Likelihood functions can sum to less than 1 if the event was improbable according to all the hypotheses, or more than 1 if the event was quite probable according to all the hypotheses.)
The downward messages in a Bayesian network are probability functions; the upward messages are likelihood functions. At each node, we combine these two pieces of information via Bayes' Law to get a posterior probability function. (Important note: the posterior probability is not the information we then pass on; this would create a double-counting problem, just like two people reinforcing each other's opinions and then each taking the strength of the other's opinion as yet more evidence in the same direction, even though no new evidence has entered the system. Think of the posteriors as private conclusions, people have reached, while their public messages only ever convey information which the recipient of that message hasn't seen yet.)
Here's the posterior calculation for one node:
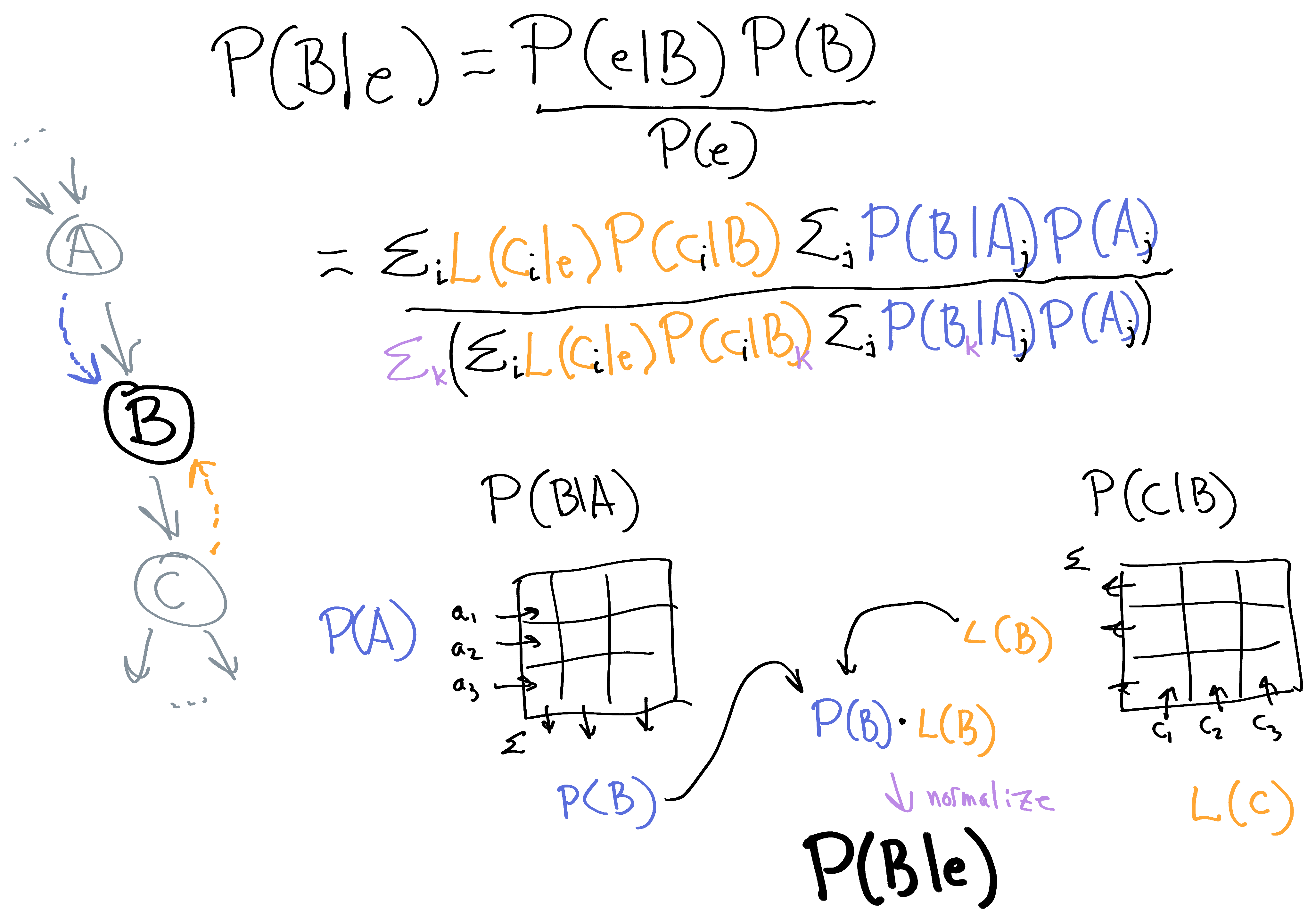
I suspect it's quite intuitive how the node needs to transform the P(A) message through the P(B|A) matrix to get the P(A) it needs. What might be less intuitive is how the L(C) message is transformed in the same way through the P(C|B) matrix, to get L(B). B then sends the P(B) message down to node C, and the L(B) message up to node A.
You can see how the probability messages are transformed incrementally to become the right prior information needed to apply Bayes' Rule at a given node; and similarly, the likelihood messages are transformed incrementally to produce the right evidence information needed at a given node.
OK, so a likelihood/probability distinction helps us organize Bayes Net calculations. Are there any other reasons why we should take this distinction seriously?
Why It Matters
A major problem people have in applying Bayesian reasoning (at least in the kind of artificial example problem you might see as a brain teaser / textbook question / etc) is neglecting the givens: failing to use one or another of the numbers given to you in the problem which are needed to compute the Bayesian update. It's understandable; there can be a lot of numbers to keep track of. At least for me, it helps a lot to organize those numbers into probability functions and likelihood functions (which lets me think in terms of 2 vectors rather than 4+ numbers right there), with the symmetric picture above, where our goal is to combine prior and likelihood together to get a posterior. As I mentioned earlier, thinking of probability/likelihood as a type distinction helps avoid mistakes combining the wrong numbers: "a likelihood needs to combine with a prior before it can be regarded as a proper probability".
Base-Rate Neglect
I have a pet theory that some biases can be explained as a mix-up between probability and likelihood. (I don't know if this is a good explanation.) For example, base-rate neglect is just straightforwardly the mistake of treating a likelihood as a probability. A simple example of base-rate neglect would be to think someone is lying to you because they deny lying when you ask, just like a liar would. L(lying|response) is high, but this doesn't mean P(lying|response) is high.
Conjunction Fallacy
Another bias which seems to fit this pattern is the conjunction fallacy. Consider the classic example:
Linda is 31 years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations.
Which is more probable?
- Linda is a bank teller.
- Linda is a bank teller and is active in the feminist movement.
People rate "Linda is a bank teller" as less probable than "Linda is a bank teller and is active in the feminist movement". Notice that the second is more likely given everything we're told about Linda: L(teller & feminist | bio) > L(feminist | bio). So we can understand this as a probability/likelihood confusion -- indeed, it's just an example of base-rate neglect.
(Keep in mind there's a long list of failed attempted explanations of this human behavior, though, so don't rush to put a bunch of credence on mine.)
An optimistic theory is that a person makes these mistakes because we have a thing in our head roughly corresponding to likelihood, due to Bayes-net-like cognition. Then we have an explicit concept of probability. But if you don't also have an explicit concept of likelihood, the thing in your head corresponding to likelihood doesn't have anywhere good to land when you do explicit reasoning; so, it gets articulated as probability instead.
If so, having an explicit concept of likelihood should make these mistakes easier to avoid, as you can label the thing in your head correctly: you are experiencing the feeling of likelihood, not probability.
Using the Words
Practically everyone uses the terms probable/likely & probability/likelihood as interchangeable terms, except in very formal situations (when talking specifically about likelihood functions for hypothesis testing). I'm proposing that we make this distinction all the time, for the good of our probabilistic reasoning skills. It's a big ask! This is a significantly different way of speaking than we're used to.
It's fortunate that these words really are interchangeable in English; at least I'm not taking away someone's ability to mean something [LW · GW]. It's a simple matter of saying "probable"/"probably" in every case where you would have used any of the four words, and using "likely"/"likelihood" to indicate the thing which you would have previously labelled as base-rate-negligent probability. (Or do you call it something else? Frankly, I'm not sure how Bayesian people get by without a word for likelihood... what do you call it? How do you refer to a theory which fits the data well? How do you say that adding details can make a story more plausible in the sense of explaining what we know, while making it less probable overall?)
So, to help ease the transition, I'll try to come up with a number of examples.
- A scenario is unlikely if it doesn't explain the evidence well. For example, in a COVID epidemic, if you get sick, the prior probability that it's COVID might be relatively high; but if your symptoms don't match COVID, it's unlikely; you can therefore conclude that the probability is lower.
- A scenario is likely if it explains the data well. For example, many conspiracy theories are very likely because they have an answer for every question: a powerful group is conspiring to cover up the truth, meaning that the evidence we see is exactly what they'd want us to see.
- You are trying to figure out who killed the butler. You find a kitchen knife with the butler's blood on it, placed behind a bush as if hastily hidden. It has the chef's fingerprints on it. Thus it's likely that the chef killed the butler, raising the probability of that hypothesis. However, another similarly likely hypothesis is that someone framed the chef by using gloves to wield a knife which the chef had touched for other reasons. Because the chef regularly touches the kitchen knives, this alternate hypothesis is relatively probable. Furthermore, because the chef has no motive, the chef being the murderer is overall improbable.
- You are studying the life of the early solar system. You have a set of four scenarios mutually exclusive and jointly exhaustive (or close enough to exhaustive that you're willing to treat it that way). Each scenario implies something about the distribution of orbits in the Kuiper belt. When you measure the Kuiper belt, you see something you were't expecting under any of your hypotheses. This is an improbable observation, which now makes all four hypotheses unlikely. However, some hypotheses are more unlikely than others. Because you didn't favor any of the hypotheses especially to begin with, your Bayesian update now strongly favors the least unlikely hypothesis, making that hypothesis quite probable. You begin to focus on the sub-scenarios within than scenario which make the observation you saw the most probable (that is, the most likely sub-scenarios). Out of these sub-scenarios, you narrow things down further by considering which scenarios are actually probable. You publish an analysis which takes all these considerations into account in order to report the most probable scenarios for the early solar system.
- You have several hypotheses about life on Venus. In order to test these hypotheses, you measure the chemical composition of the atmosphere of Venus. Unfortunately, your measurements are very probable under all of your hypotheses, so all of your hypotheses remain likely. Your best guess is still your prior probability on each hypothesis.
I found as I was writing the above examples that I wished there were three words, not two, so that I could more conveniently distinguish prior probability from posterior probability. It's very understandable that there's not, though, because one man's posterior is another man's prior -- these concepts flow into one another based on context. Likelihood is more clearly distinguished, since it does not sum to 1.*
Ambiguity & Context-Sensitivity
A given conversational context has contextual assumptions, information which we've already updated on, which gives us the prior; then we have information we're treating as observations in the context, which gives us our likelihoods; then we have the information we're treating as unknowns (hypotheses), which are what the prior and likelihoods are about. Whenever we say "probability" or "likelihood", the reader/listener has to infer from context what the assumptions/observations/unknowns are.
What's treated as assumption in one part of a conversation may be treated as unknown in another part; observations at one point may become assumptions later on; and so on. There is no strict rule that observations or assumptions are certain: as we see with a complex Bayesian network, we can get likelihood messages which propagate up from some distance away, which acts as uncertain evidence. Similarly, prior messages act as uncertain assumptions.
(None of the things we routinely treat as evidence are certain. If I say I read the number 98 off a thermometer, what I mean is that I'm quite confident it was 98. In Radical Probabilism [LW · GW], I attempted to convey Richard Jeffrey's view that none of our observations are certain.)
Nor does there need to be a strict temporal order behind these three categories. This will often be the case, when we treat the past as given, and update on present observations, to predict an unknown future. However, we can also try to explain the past (treating some elements of the present as assumptions, and others as unknowns), or uncover the past (treating it as unknown), or many other combinations.
You can think of a Bayes Net as a tool for keeping track of what constitutes assumptions/observations in a consistent way for a bunch of possible unknowns, so that we can split up our reasoning into a bunch of individual reasoning tasks that we can understand with this trichotomy.
Exchanging Virtual Evidence
One of Pearl's analogies for Bayesian Networks is a network of people trying to communicate about something. You can think of it as a network of experts. Each expert is in charge of one special variable, and the experts only talk to other experts if their specialties are closely related. If we take this analogy seriously, a striking fact is that these people are communicating with virtual evidence. (I discussed virtual evidence in my post on Radical Probabilism [LW · GW]; the discussion there is a prerequisite for this section.)
Take the Bayes Net A->B->C. Expert B understands everything going on here, because B has to talk to everyone. However, A doesn't understand C at all, and vice versa; if they talked to each other, they would be mutually unintelligible. So, B has the job of translating between them. B accepts messages from C, takes just the information about B which the message implies, and passes that along to A (who understands B-talk). And similarly in the other direction.
All of the experts trust one another, but because they can't understand the ontology of distant evidence, they have to accept the virtual evidence implied by the likelihood functions they're handed by those around them: they accept "there was some evidence which induced this likelihood function", without worrying about whether the evidence is represented as a proposition.
So that's one of the core uses of virtual evidence: conveying information when there's trust of rationality, but no common language with which to describe all evidence.
(Again, one of Jeffrey's insights is that it's not important that the evidence is represented as a proposition anywhere in the network; we don't need to require every update to come with a crisp thing-which-we-updated-on. Virtual evidence is just a likelihood function which we don't attribute to any particular proposition.)**
Notice that for Bayesian networks, it's much much more efficient to pass information this way; if we instead attempted to convey all the information explicitly, and make our experts all understand each other, we would be back to calculating probabilities by taking a global exponential-sized sum over possibilities.
However, as I mentioned briefly earlier, we have to get things just right to avoid double-counting information when we use message-passing like this.
Propagating Posterior Probabilities
In Aumann's agreement theorem, Aumann famously considers the case of Bayesians passing information back and forth only by stating their new posterior probability after each communication they receive. Bayesians could possibly communicate this way in situations of incompatible ontologies, rather than using virtual evidence. But I'll argue it's not very efficient.
As I mentioned earlier, we want to avoid double-counting evidence. The outgoing messages in a Bayesian network are always (proportional to) the posterior probability of a node, divided by the incoming message along that same link. What this intuitively means is that when Alice talks to Bob, Alice has to "factor out" the information she got from Bob in the first place; she only wants to tell Bob her other information, which Bob doesn't know yet.
If Alice and Bob communicate with posterior probabilities, then it's always up to the listener to factor out their own message.
For example, suppose Alice tells Bob that it's a beautiful day outside. Bob nods. This tells Alice that Bob agrees: it's a beautiful day outside. But Bob is reporting honest posterior probabilities, so Bob's nod of assent probably just reflects his having updated on Alice. So Alice does not further update; Bob is not giving Alice any further evidence. If Bob had nodded vigorously, then Alice would interpret Bob's position as stronger even then hers; she would thus infer that Bob had independent evidence that it's a beautiful day outside. In that case, she would update.
The point is that in this situation, Alice has a somewhat difficult job interpreting Bob's message. Bob gives her his posterior, and she has to figure out what portion of that is new evidence for her.
Propagating Likelihoods
If Alice and Bob instead communicate factoring out each other's information, then they exchange virtual updates for each other, which are easy to take into account.
If Alice tells Bob "it's nice out" and Bob nods, Alice then knows that Bob has independent confirmation that it's nice out.
This is a much better case for Alice. She can form her posterior simply by multiplying in Bob's apparent likelihood function, and renormalizing.
Unfortunately, in realistic cases, we have a worst-case scenario: we don't really have one protocol. Whet someone expresses agreement or disagreement with a proposition, it's not really clear whether they're giving their all-things-considered posterior, or factoring out the information they got from us in the first place in order to give us a clean update.
So, realistically, when Bob nods, Alice doesn't have a great idea of what it means at all.
I know the examples with Alice trying to interpret Bob's nods are slightly absurd; Bob is obviously not giving Alice enough information there, so of course there are potential interpretation issues. But I'm using these examples because I think these ideas about virtual evidence and so on are mainly important in cases where there's not enough time to communicate fully.
Even if you're having a long, thorough discussion about some topic of interest, there will be many many small acts of communication with ambiguity and insufficient follow-up. Maybe an hour-long discussion on topic X involves 125 smaller propositions. 5 of these are major propositions, which get about 10 minutes each. Those 10-minute discussions involve about 20 smaller propositions each. These smaller propositions are given varying amounts of time, so many of them only get a few seconds.
So lots of propositions only get a brief response like a nod, or "sure", or one sentence.
In that brief amount of time, we form an impression of what each other think of that proposition. We make some small update one way or another, based on a vague impression, dozens or hundreds of times in an hour-long conversation.
I don't think it's psychologically or socially realistic for humans to only exchange virtual evidence. It's too socially useful to express positive sentiment when someone tells us something (reinforcing that we like them, we think they're reasonable, etc).
But I am interested in trying to do more little things to signal what type of information I'm giving off.
Using phrases like "all things considered," signals that I'm giving my posterior.
Using phrases like "if you hadn't told me that," signals that I'm factoring out what you told me.
If I say "I think that's very likely", it can mean that viewing what you told me as a hypothesis, it fits evidence in my possession well. Whereas "I think that's very probable" is more probably a posterior (although the ambiguity of whether "probable" stands for posterior or prior probability hurts us here).***
*: Not that I'd complain if someone came up with a decent proposal for a 3rd word.
**: There's a complication here. Notice that the messages in a Bayesian network are of two kinds: probability messages and likelihood messages. Yet I'm referring to them all as "virtual updates" and claiming that virtual updates are a kind of likelihood. In a Bayesian network, it's more natural to view some messages as probabilities, providing the priors for the local node posterior calculations. In a network of experts, it's more natural to think that every expert already has a prior when they start out, and so, only virtual evidence is communicated between the experts.
***: But it gets even more complicated than implied by (1), because as I argued, what's natural to think of as evidence/assumption/unknown will shift around in any given conversation, and must be inferred from context. I can't use "likely" to signal that I'm trying to convey virtual evidence to you if we're in a context where we're considering some hypothesis together, in light of some evidence; "likely" will sound like I mean something makes that evidence probable, rather than saying that my personal evidence makes your statement probable.
10 comments
Comments sorted by top scores.
comment by [deleted] · 2020-11-11T16:55:39.699Z · LW(p) · GW(p)
I find it helpful to have more real world examples to anchor on so here's another COVID-related example of what I'm pretty sure is likelihood / probability confusion.
Sensitivity and specificity (terrible terms IMO but common) model and respectively and therefore are likelihoods. If I get a positive test, I likely have COVID, but it still may not be very probable that I have COVID if I live in, e.g. Taiwan, where the base rate of having COVID is very low.
comment by Oliver Sourbut · 2020-11-16T11:27:41.538Z · LW(p) · GW(p)
I like the emphasis on a type distinction between likelihoods and probabilities, thanks for articulating it!
You seem to ponder a type distinction between prior and posterior probabilities (and ask for English language terminology which might align with that). I can think of a few word-pairings which might be relevant.
Credibility ('credible'/'incredible')
Could be useful for talking about posterior, since it nicely aligns with the concept of a credible interval/region on a Bayesian parameter after evidence.
After gathering evidence, it becomes credible that...
...strongly contradicts our results, and as such we consider it incredible...
Plausibility ('plausible'/'implausible')
Not sure! To me it could connote a prior sort of estimate
It seems implausible on the face of it that the chef killed him. But let's consult the evidence.'
The following are plausible hypotheses:...
But perhaps unhelpfully I think it could also connote the relationship between a model and an evidence, which I think would correspond to likelihood.
Ah, that's a more plausible explanation of what we're seeing!
Completely implausible: the chef would have had to pass the housekeeper in the narrow hallway without her noticing...
Aleatoric and epistemic uncertainty
There's also a probably-meaningful type distinction between aleatoric uncertainty (aka statistical uncertainty) and epistemic uncertainty, where aleatoric uncertainty refers to things which are 'truly' random (at the level of abstraction we are considering them), even should we know the 'true underlying distribution' (like rolling dice), and epistemic uncertainty refers to aspects of the domain which may in reality be fixed and determined, but which we don't know (like the weighting of a die).
I find it helpful to try to distinguish these, though in the real world the line is not necessarily clear-cut and it might be a matter of level of abstraction. For example it might in principle be possible to compute the exact dynamics of a rolling die in a particular circumstance, reducing aleatoric uncertainty to epistemic uncertainty about its exact weighting and starting position/velocity etc. The same could be said about many chaotic systems (like weather).
Replies from: abramdemski↑ comment by abramdemski · 2020-11-16T16:11:27.887Z · LW(p) · GW(p)
Thanks for making some suggestions!
Another possibility which occurs to me is to use "elegance" for prior probability. This is a common way to refer to the subjective simplicity of a hypothesis in science, so it fits pretty well!
We might then insist that "probability" should always incorporate everything we know to the best of our ability, and "elegance" be used to refer to prior probability.
This seems really weird in certain cases, though, such as "I know my swimming led to my getting bit by a shark, but you can't blame me; it wasn't very elegant!"
comment by riceissa · 2021-02-24T20:22:05.341Z · LW(p) · GW(p)
Regarding base-rate neglect, I've noticed that in some situations my mind seems to automatically do the correct thing. For example if a car alarm or fire alarm goes off, I don't think "someone is stealing the car" or "there's a fire". L(theft|alarm) is high, but P(theft|alarm) is low, and my mind seems to naturally know this difference. So I suspect something more is going on here than just confusing probability and likelihood, though that may be part of the answer.
comment by riceissa · 2021-02-24T19:59:39.003Z · LW(p) · GW(p)
I understood all of the other examples, but this one confused me:
A scenario is likely if it explains the data well. For example, many conspiracy theories are very likely because they have an answer for every question: a powerful group is conspiring to cover up the truth, meaning that the evidence we see is exactly what they'd want us to see.
If the conspiracy theory really was very likely, then we should be updating on this to have a higher posterior probability on the conspiracy theory. But in almost all cases we don't actually believe the conspiracy theory is any more likely than we started out with. I think what's actually going on is the thing Eliezer talked about in Technical Explanation where the conspiracy theory originally has the probability mass very spread out across different outcomes, but then as soon as it learns the actual outcome, it retroactively concentrates the probability mass on that outcome. So I want to say that the conspiracy theory is both unlikely (because it did not make an advance prediction) and improbable (very low prior combined with the unlikeliness). I'm curious if you agree with that or if I've misunderstood the example somehow.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-26T17:06:51.186Z · LW(p) · GW(p)
Ah, yeah, I agree with your story.
Before the data comes in, the conspiracy theorist may not have a lot of predictions, or may have a lot of wrong predictions.
After the data comes in, though, the conspiracy theorist will have all sorts of stories about why the data fits perfectly with their theory.
My intention in what you quote was to consider the conspiracy theory in its fulness, after it's been all fleshed out. This is usually the version of conspiracy theories I see.
That second version of the theory will be very likely, but have a very low prior probability. And when someone finds a conspiracy theory like that convincing, part of what's going on may be that they confuse likelihood and probability. "It all makes sense! All the details fit!"
Whereas the original conspiracy theorist is making a very different kind of mistake.
Replies from: riceissacomment by adamShimi · 2020-11-11T18:29:36.069Z · LW(p) · GW(p)
I usually want to read your posts on Probability and Bayesianism, but stop in the middle, not because it's not clear, but because I feel like I need to be working on something else. This is pretty much the first post of this sequence that I finished, and I'm glad that I did, because it makes me feel that my Bayesian understanding just improved!
What we're basically doing here is making a type distinction between probability and likelihoods, to help us remember that likelihoods can't be converted to probabilities without combining them with a prior.
It probably depends on the background of the reader, but for someone with a theoretical computer science one like me, that's an amazingly helpful explanation.
Trying to understand your second picture, when comparing and , there should be at least one value at which they agree, right? In your picture it's the 10%. As far as I understand, it's because P(A|B) assumes some fixed (let's say ), and assumes some fixed (let's say ). By your definition, , so there should be at least one value of equal to a value of . For your drawing, we have , and is either or .
Is that correct, or am I completely of the mark?
I have a pet theory that some biases can be explained as a mix-up between probability and likelihood. (I don't know if this is a good explanation.)
This looks like a very interesting theory, and the two examples given are pretty convincing. So I'm curious whether you know of cases where it fails to explain the bias you mentioned?
This it likely that the chef killed the butler,
Typo
Replies from: abramdemski↑ comment by abramdemski · 2020-11-12T01:49:50.499Z · LW(p) · GW(p)
Trying to understand your second picture, when comparing and , there should be at least one value at which they agree, right?
Ahh, I knew there was a bit of a risk there... I didn't really start with a conditional distribution and pull out rows/columns, I just made up numbers to illustrate the summing to 1 / not summing to 1 distinction. Fortunately, as you mentioned, I happened to place one matching number in the two, allowing us to deduce that I'm illustrating the probabilities of different A given B=, and then the likelihoods of different B given A=, as you demonstrated.
This looks like a very interesting theory, and the two examples given are pretty convincing. So I'm curious whether you know of cases where it fails to explain the bias you mentioned?
No, but I must admit that I haven't read deeply into the literature.
Typo
Thanks!
comment by Mart_Korz (Korz) · 2023-06-10T12:27:30.352Z · LW(p) · GW(p)
I have a pet theory that some biases can be explained as a mix-up between probability and likelihood. (I don't know if this is a good explanation.)
At least not clearly distinguishing probability and likelihood seems common. One point-in-favour is our notation of conditional probabilities (e.g. ) where is a symbol with mirror-symmetry. As Eliezer writes in a lecture in plane crash, this is a didactically bad idea and an asymmetric symbol would be a lot easier to understand: is less optically obvious than[1]
Of course, our written language has an intrinsic left-to-right directional asymmetry, so that the symmetric isn't a huge amount of evidence[2].